物理执行计划
回到SqlQueryExecution.startExecution() ,执行计划划分以后,
// 初始化连接,获取Connect 元数据,添加会话,初始ConnectId
metadata.beginQuery(getSession(), plan.getConnectors());
// 构建物理执行计划
// plan distribution of query
planDistribution(plan);
//检测Query Split 情况及自身状态
// 创建OutputBuffers
createInitialEmptyOutputBuffers
// 创建调度器,内部通过 QueryStateMachine 存放调度状态,递归创建Stages
createSqlQueryScheduler
createStages()
createStreamingLinkedStages()
//提交调度任务至缓存
queryScheduler.set(scheduler);
// if query is not finished, start the scheduler, otherwise cancel it 开始执行
SqlQueryScheduler scheduler = queryScheduler.get();
if (!stateMachine.isDone()) {scheduler.start();
}
// 调度发起,生成并调度物理执行计划树
SqlQueryScheduler.schedule(Collection<SqlStageExecution> stages)
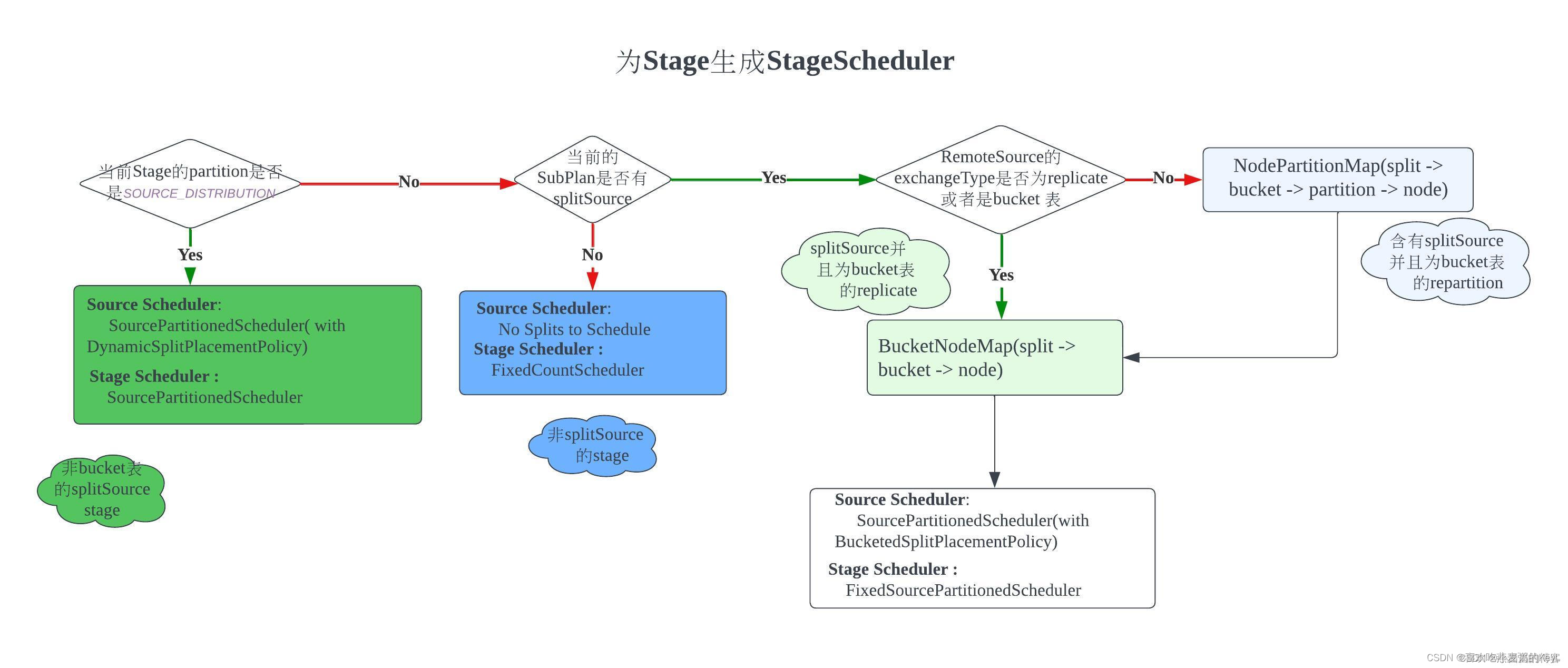
构造stage:
Fragment内部有Partition概念,根据 PartitionHandle类型,选择策略,确定split和task的调度方式
PartitionHandle 分成两类
一种是引擎Connector的分区策略
例如:Hive查询遇到bucket表Scan操作,Presto会使用HivePartitioningHandle获取到具体bucket数量,依次来确认调度分区NodePartitionMap
一种是Presto内置的分区策略
在Connector不提供Handle情况下,默认初始化SystemPartitioningHandle,组装成PartitioningHandle
例如:对于非Partition表,系统封装成SOURCE_DISTRIBUTION 读取。
Partition 策略:
SOURCE_DISTRIBUTION、SCALED_WRITER_DISTRIBUTION、SINGLE_DISTRIBUTION等
读取数据:
有splitSource,非partition表:
非桶表:分发执行
桶表:根据桶数创建单独task
有splitSource,bucket 表,RemoteSourceNode指向子Stage:
if 子Stage的ExchangeType是replicate:
上游数据复制到下游
else:
//即repartition 或 gather
上游数据根据分区策略,交付给对应分区即可。
没有splitSource的stage:
不存在Split的调度,只存在Task的调度。
对于非bucket表,在planFragment 阶段Stage的partitioning就被定义为 SOURCE_DISTRIBUTION,意味着split均匀分配给所有节点,
SOURCE_DISTRIBUTION 需逐个节点调度分配,检查当前机器是否存在task,创建并执行该split(优化:逐个节点调优于逐个split调度)
Split放置、分配策略:
1.将所有可远程访问且没有地址信息的split进行worker分配。(所有Worker中,选择已调度split最小且总和小于机器单节点split的节点进行分发)
2.未分配的split(split地址不可访问或所有节点均达到最大限制):
2.1 地址不可访问:将split分配到自身的Ip地址上去
2.2 可访问,尝试为该节点重新随机选择节点(不再考虑节点的worker上运行的split是否已经超过限制)/* 可能会抛出单节点split异常,负载过大*/
摘抄出处:Presto(Trino)分布式(物理)执行计划的生成和调度_presto fixedsourcepartitionedscheduler-CSDN博客