目录
读取本地文件
从网站读取文件
java爬虫
总结
读取本地文件
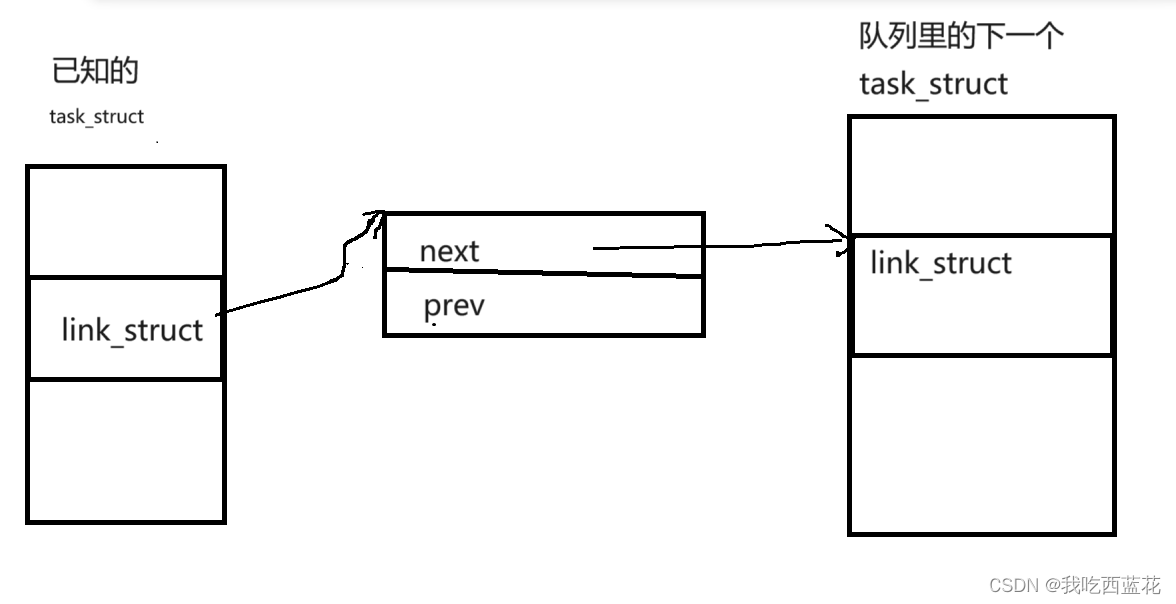
import java.io.File;
import java.io.PrintWriter;
import java.util.Scanner;public class ReplaceText {public static void main() throws Exception{File file = new File("basic\\test.txt");if(!file.exists()) {System.exit(0);}File targetFile = new File("basic\\target.txt");if(targetFile.exists()) {System.exit(1);}String oldString = "case";String newString = "CASE";try(Scanner input = new Scanner(file);PrintWriter output = new PrintWriter(targetFile);) {while (input.hasNext()) {String src = input.nextLine();String dist = src.replaceAll(oldString, newString);output.println(dist);}input.close();output.close();}}
}输出结果:
从网站读取文件
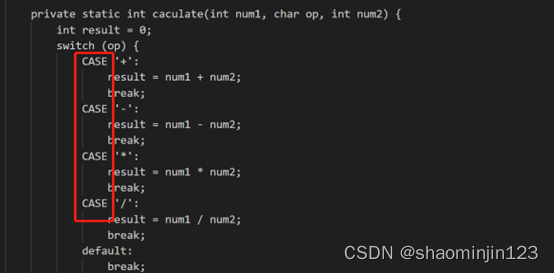
import java.io.IOException;
import java.util.Scanner;public class ReadFileFromUrl {public static void main() {System.out.println("Input the URL:");String addr = new Scanner(System.in).next();try {java.net.URL url = new java.net.URL(addr);int count = 0;Scanner input = new Scanner(url.openStream());while (input.hasNext()) {count = count + input.nextLine().length();}System.out.println("The website has " + count + " charactors.");} catch (java.net.MalformedURLException e) {// TODO: handle exceptionSystem.out.println("Invalid url!");} catch (IOException e) {System.out.println("No such file!");}}
}
输出结果:

java爬虫
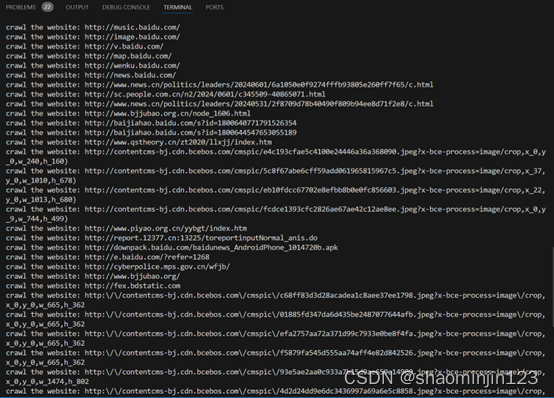
package crawler;import java.util.ArrayList;
import java.util.Scanner;public class MyCrawler{public static void main() {String addr = new Scanner(System.in).next();crawler(addr);}private static void crawler(String url) {ArrayList<String> pendingUrls = new ArrayList<>();ArrayList<String> traversedUrls = new ArrayList<>();pendingUrls.add(url);while (!pendingUrls.isEmpty() && traversedUrls.size() < 100) {String urlString = pendingUrls.remove(0);if (!traversedUrls.contains(urlString)) {traversedUrls.add(urlString);System.out.println("crawl the website: " + urlString);}for(String s: getSubUrl(url)) {if(!traversedUrls.contains(s))pendingUrls.add(s);}}}private static ArrayList<String> getSubUrl(String urlString) {ArrayList<String> list = new ArrayList<>();try {java.net.URL url = new java.net.URL(urlString);int count = 0;Scanner input = new Scanner(url.openStream());while (input.hasNext()) {String line = input.nextLine();count = line.indexOf("http:", count);while (count > 0) {int endIndex = line.indexOf("\"", count);if (endIndex > 0) {list.add(line.substring(count, endIndex));count = line.indexOf("http:", endIndex);} else {count = -1;}}}} catch (Exception e) {// TODO: handle exceptionSystem.out.println("Error : " + e.getMessage());}return list;}}
输出结果:
总结
本文从读取本地文件,读取网站文件和爬虫,一步一步地实现简单的网络爬虫功能。