使用 DALLE-3 模型生成的图像
目录
一、说明
二、为什么校准对 LLM 模型至关重要
三、校准 LLM 概率的挑战
四、LLM 的高级校准方法
4.1 语言置信度
4.2 增强语言自信的先进技术
4.3 基于自一致性的置信度
4.4 基于 Logit 的方法
五、代理模型或微调方法
5.1 使用代理模型进行置信度评估
5.2 识别不确定性:R-tuning
5.3 LITCAB:小改变,大影响
5.4 ASPIRE:更智能的模型响应
六、结论
一、说明
语言模型,尤其是大型语言模型 (LLM),凭借其理解和生成类人语言的能力,彻底改变了人工智能领域。这些模型不仅能够在零样本设置下或通过定制提示执行各种任务,而且它们的灵活性和多样性也使它们在多个领域中非常有用。
然而,尽管它们很有效,但一个经常面临挑战的关键方面是这些模型的校准——确保它们提供的关于各种输出的概率真实反映这些输出正确的真实可能性。
本文探讨了 LLM 校准的必要性,确定了围绕其概率评估的核心问题,并探讨了实现更好模型校准的当代方法。
二、为什么校准对 LLM 模型至关重要
LLM 的本质是围绕处理和生成基于语言的输出,这些输出不仅准确,而且被分配了正确的置信水平。校准(或使模型的置信度与其准确性保持一致的过程)是必不可少的,因为:
- 值得信赖的 AI 决策:正确校准的置信度分数使用户能够信任和依赖 AI 做出的决策,了解模型何时可能正确或不正确。
- 风险管理:在医疗诊断或自动驾驶等安全关键应用中,过度自信但不正确的预测可能会导致灾难性后果。
- 模型调试和改进: 校准可以帮助开发人员了解模型的弱点并相应地对其进行优化。
三、校准 LLM 概率的挑战
大型语言模型通常面临几个影响其概率校准的障碍:
- 封闭模型约束:许多 LLM 以黑匣子的形式运行,直接访问对数概率的访问受到限制,使理解和调整置信度分数的过程变得复杂。
- 训练中的错位:使用人类反馈强化学习 (RLHF) 等技术改进的模型可能会变得天真地校准错误。根据论文[1],使用最广泛的LLMs是通过人类反馈的强化学习(RLHF-LLMs)进行微调的。一些研究表明,RLHF-LLMs产生的条件概率校准非常差。研究结果表明,RLHF-LLMs可能会优先考虑严格遵守用户偏好,而不是产生校准良好的预测,这可能导致校准不良。这显示了一个关键挑战,即使用 RLHF 训练的模型可能缺乏准确可靠输出所需的必要概率校准。
- 特定任务的校准需求: LLM 的通用训练通常不会针对特定任务或领域进行调整,需要额外的校准以使其与特定需求或应用程序保持一致。
四、LLM 的高级校准方法
为了应对校准挑战,我们可以尝试多种技术,如下所述:

描述各种校准技术
4.1 语言置信度
“语言置信度”是指语言模型(LLM)不仅提供答案,而且还明确地评估其响应的置信度的技术。这种方法涉及使用某些方法来获得对模型对其答案的置信度的更可靠评估。
基本实现
在最简单的形式中,口头信心涉及向 LLM 提出问题和任何相关上下文,然后明确要求提供信心分数。这种直接方法为更复杂的技术奠定了基础。
4.2 增强语言自信的先进技术
- 思维链 (CoT) 提示: 思维链提示涉及在模型提供答案之前从模型中引出分步推理过程。该方法不仅增强了模型响应的清晰度和丰富性,还可以通过观察推理步骤中的逻辑一致性来提高置信水平的估计。
- 多步骤置信度激发:该技术通过在推理或解决问题过程的各个步骤捕获置信度分数来优化置信度测量。最终置信水平是所有个人置信度分数的乘积,提供了确定性的复合度量。
- Top-K 响应和置信度评分: 该模型生成多个可能的答案(Top-K 响应),而不是单个响应,每个答案都伴随着一个单独的置信度分数。然后,选择置信度得分最高的答案作为最终答案。这种方法反映了涉及评估多个假设的决策过程。
- 多种提示技术:利用各种提示可以更准确地校准置信度估计。提示的多样性可能源于不同的措辞、上下文或概念角度,使模型的评估对有偏见或信息不足的响应更加稳健。
- 数值概率与语言表达式:在某些情况下,模型通过与正确可能性直接相关的数值概率来表达其置信度。相反,也可以使用“极有可能”或“可能不会”等语言表达方式。
- 使用多个假设进行提示: 最初,模型会生成多个没有置信度评级的答案候选者。在随后的交互中,他们评估每个答案的正确概率。研究表明,以这种方式评估多个假设可以显着改善校准。

参考论文
有效表达置信度的能力因模型而异,在不同的模型架构和世代中观察到一些差异。
4.3 基于自一致性的置信度
基于自一致性的置信度方法是一种复杂的方法,通过生成对同一查询的多个响应并分析这些响应之间的一致性来评估语言模型的置信度。该技术基于这样一种想法,即不同条件下的高一致性表明对响应准确性的高度置信度。
生成多个响应
为了从模型中获得一系列答案,采用了几种策略:
自我随机化: 这涉及在不同的设置下多次输入相同的问题。调整“温度”参数是这里的常用方法,它通过改变输出的预测性或随机性来操纵模型响应的多样性。
提示扰动: 通过释义改变问题的措辞,以唤起不同角度的回答。这通过检查模型是否在措辞不同但概念相似的提示中保持一致来测试模型的稳健性。
误导性提示:在提示中引入故意错误或误导性提示,以评估模型的稳定性。与人体测试类似,这种方法观察模型是否像一个自信的人一样,可以忽略误导性信息并坚持正确或一致的反应。
聚合策略
为了综合调查结果并分配最终置信度分数,可以考虑不同的聚合策略:
一致性测量: 这检查了模型在不同条件下提供相同答案的一致性,反映了稳定性和可靠性。
平均置信度(平均值):计算加权平均值,其中对具有较高一致性和个人置信度得分的答案给予更多权重,从而提供总体置信度的精细度量。
配对排名策略: 此策略在使用模型的 Top-K 预测的场景中特别有用,它强调模型预测中的排名信息,有助于评估最可能和最一致的响应。
4.4 基于 Logit 的方法
基于 Logit 的校准是提高大型语言模型 (LLM) 概率预测可靠性的关键技术。当模型输出原始分数(如对数)时,它们通常不会直接转换为真正的概率分布。校准技术调整这些对数以反映更准确的概率,这对于实际应用中的稳健决策至关重要。下面,我们将深入探讨用于基于 logit 的校准的一些方法:
1. 对代币(token)的平均置信度
为了在语言模型的预测中得出更一致的置信度估计,一种常用的方法是对标记的置信度(对数概率)进行平均。这可以针对所有令牌或选择性子集完成,具体取决于特定应用程序或数据集的特征。其结果是更平滑、更通用的模型确定性度量,减少了任何单个代币可变性的影响。
2. 普拉特缩放(Sigmoid)
Platt 缩放或 S 形标定是一种逻辑回归模型,应用于原始模型的输出对数。通过在 logit 上拟合 sigmoid 函数,此方法将它们转换为校准概率。校准涉及学习两个参数,通常表示为“A”和“B”,它们缩放和移动对数以更好地与实际观察到的概率保持一致。这种方法特别有用,因为它对于二元分类任务简单且有效。
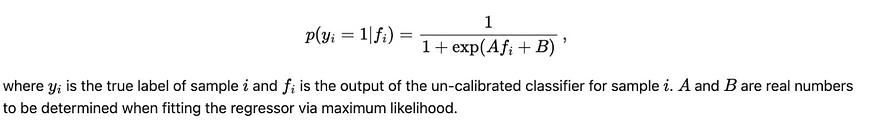
参考
3. 等渗回归
与 Platt 缩放不同,等渗回归在对数和概率之间不假定任何函数形式。它是一种非参数方法,拟合非递减函数,使预测概率与目标概率对齐。这种分段常数函数非常灵活,可以更准确地反映某些场景中的真实分布,特别是当对数和概率之间的关系更复杂或非线性时。

4. 温度标度
温度缩放是一种后处理技术,可在不更改模型预测的情况下调整模型的置信度。它涉及在应用 softmax 函数将它们转换为概率之前,将 logits 除以称为“温度”的常量。最佳温度通常通过最小化验证数据集上的交叉熵损失来确定。这种方法很有吸引力,因为它对校准过程产生了极简主义的影响,保持了原始对数的相对顺序。
五、代理模型或微调方法
微调是一种高级校准方法,它使用特定数据和目标调整模型,以便更好地为特定任务做好准备。让我们探索几种创新方法,这些方法有助于微调这些模型,以提供更可靠、更精确的置信度分数。
5.1 使用代理模型进行置信度评估
一种引人入胜的方法[2]使用第二种通常更简单的模型来评估主要模型(如 GPT-4)的答案的可信度:
- 它的作用:例如,LLAMA2 等辅助模型可用于通过提供相同的提示并提取 GPT-4 模型响应的分数来获取其他模型(如 GPT-4)生成的答案的对数概率
- 令人惊讶的效果:尽管二级模型可能不那么强大,但与单独使用语言线索相比,这种方法已被证明可以产生更好的结果(通过曲线下面积或 AUC 测量)。
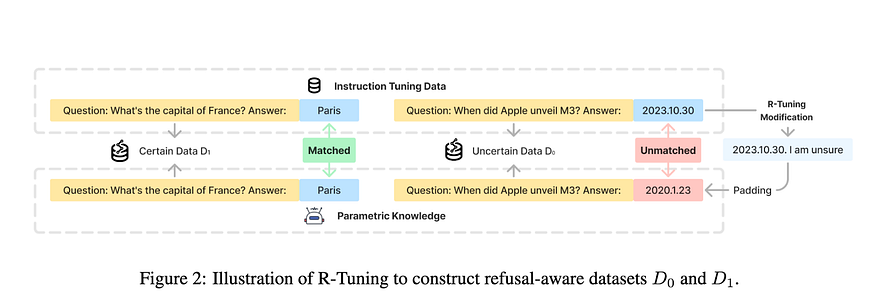
5.2 识别不确定性:R-tuning
R-tuning 在可以说“我不知道”的时候教一个模型——认识到它自己的局限性。微调过程包括以下步骤
- 识别不确定性: 它通过进行预测并将其与地面事实进行比较,发现模型的答案在火车集中可能不稳定或有问题的情况
- 有把握地训练:然后,它使用标记为“确定”或“不确定”的示例来教授模型,确保它从这些区别中学习。在训练期间使用“我确定”或“我不确定”等短语来表达置信度,重点是从令牌生成到降低错误。
参考
5.3 LITCAB:小改变,大影响
LITCAB 引入了一个微小而有效的校准层:
- 简单添加:它在模型末尾添加一个线性层,该层根据输入文本调整每个响应的预测可能性。
- 高效和有效: 这种微小的调整增强了模型的判断力,而不会增加太多复杂性——原始模型大小的变化不到 2%。
5.4 ASPIRE:更智能的模型响应
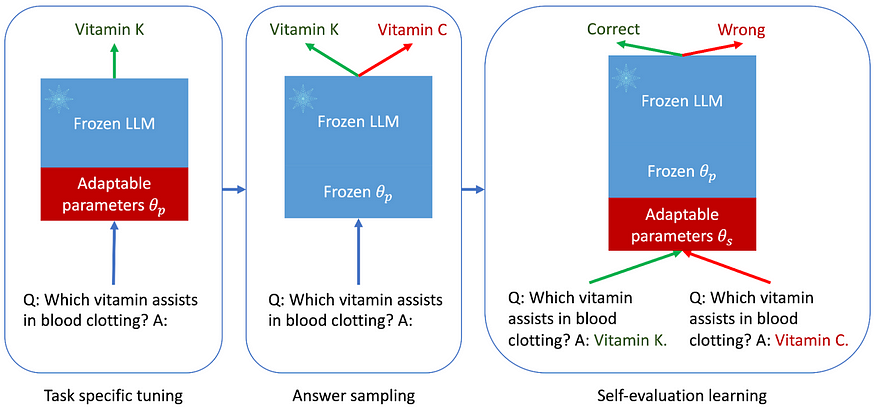
为预测分配置信度分数并允许选择性预测。ASPIRE,包括三个阶段:
1.T Ask 特定调优:它使用 PEFT 技术修改特定的自适应参数,同时保持主模型不变,优化特定任务的响应。
2. 答案抽样:它使用这些调整为每个问题生成多个可能的答案,它使用波束搜索作为解码算法来生成高似然输出序列,并使用 Rouge-L 度量来确定生成的输出序列是否正确基于真实
3.自我评价学习:最后,引入另一组调整,帮助模型自行判断其反应是对还是错,提高其自我评价能力。
通过这些方法,语言模型不仅变得更加先进,而且更符合用户的上下文和期望,从而实现更可靠和更上下文感知的交互。
六、结论
校准大型语言模型是一项复杂而重要的工作,可以提高 AI 应用程序的可靠性和安全性。通过使用和组合上面讨论的各种创新方法,我们可以显着改善这些模型在无数上下文中的理解和交互方式,为真正的智能系统铺平道路,这些系统可以以高度的可信度和正确性做出决策。