MLPerf 基准测试
什么是 MLPerf?MLPerf™ 基准测试由来自学术界、研究实验室和行业的 AI 领导者联盟 MLCommons 开发,旨在对硬件、软件和服务的训练和推理性能进行无偏评估。它们都在规定的条件下进行。为了保持在行业趋势的前沿,MLPerf 不断发展,定期举行新的测试,并添加代表 AI 技术水平的新工作负载。
Nidia介绍:https://www.nvidia.cn/data-center/resources/mlperf-benchmarks/
MLCommons 基准测试工作的基础源自 MLPerf,并以此为基础进行构建,MLPerf 旨在为 ML 提供一套具有代表性的基准测试套件,公平地评估系统性能,以满足五个高级目标*:
- 在鼓励机器学习创新的同时,实现对竞争系统的公平比较。
- 通过公平、实用的测量来加速机器学习的进展。
- 强制重复性以确保可靠的结果。
- 为商业和研究界提供服务。
- 保持基准测试工作量可承受,以便所有人都能参与。
每个基准测试套件均由工作组专家社区定义,他们为 AI 系统制定公平的基准测试。工作组定义要运行的 AI 模型、运行模型所依据的数据集、设置允许对模型进行哪些更改的规则,并测量给定硬件运行模型的速度。通过在这个 AI 模型三脚架内工作,MLCommons AI 系统基准测试不仅可以测量硬件的速度,还可以测量训练数据的质量以及 AI 模型本身的质量指标。
官网:https://mlcommons.org/benchmarks/
MLPerf Storage
MLPerf Storage 基准测试套件可测量在训练模型时存储系统提供训练数据的速度。https://mlcommons.org/benchmarks/storage/
github下载:https://github.com/mlcommons/storage
基准输出指标
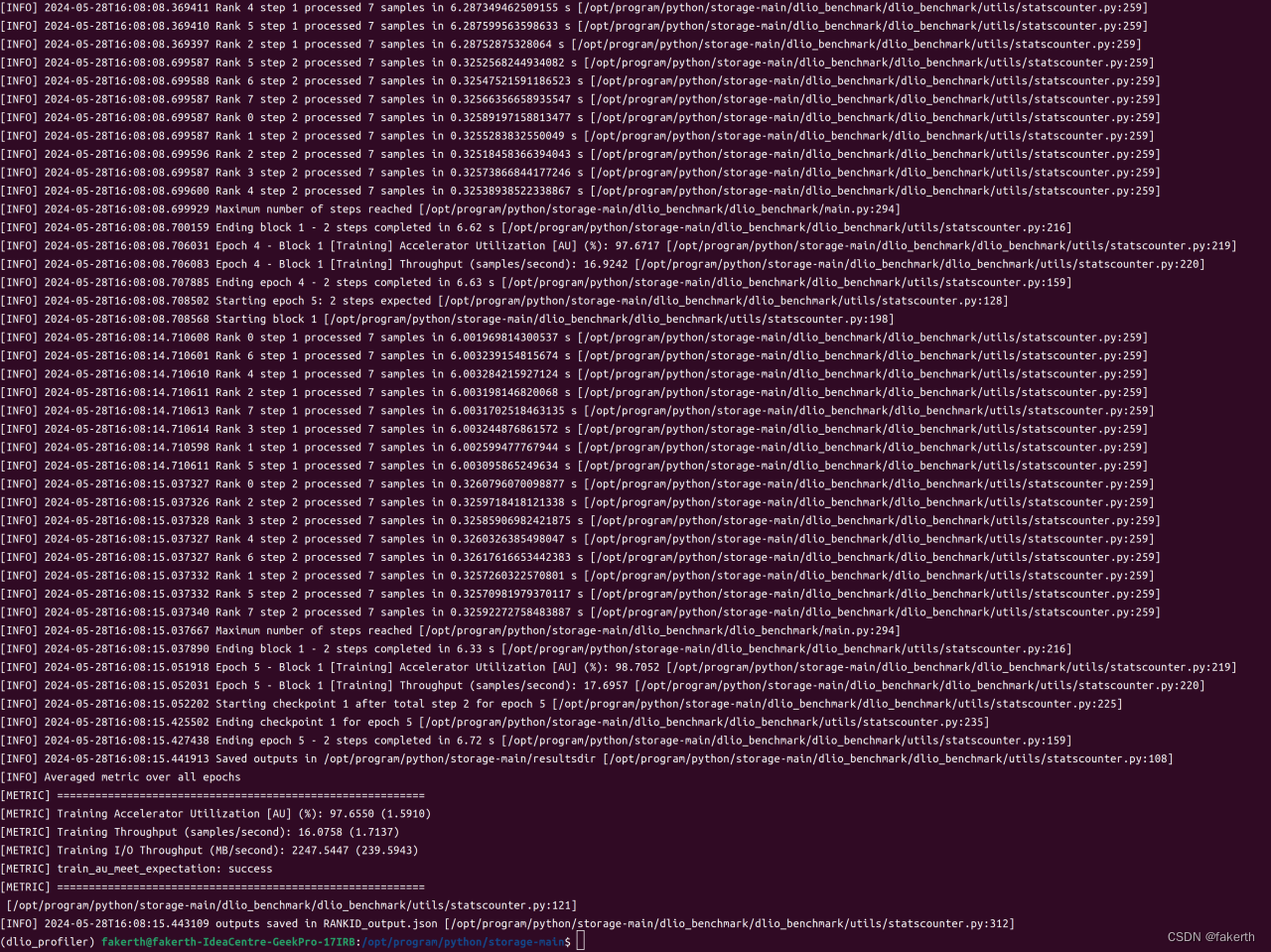
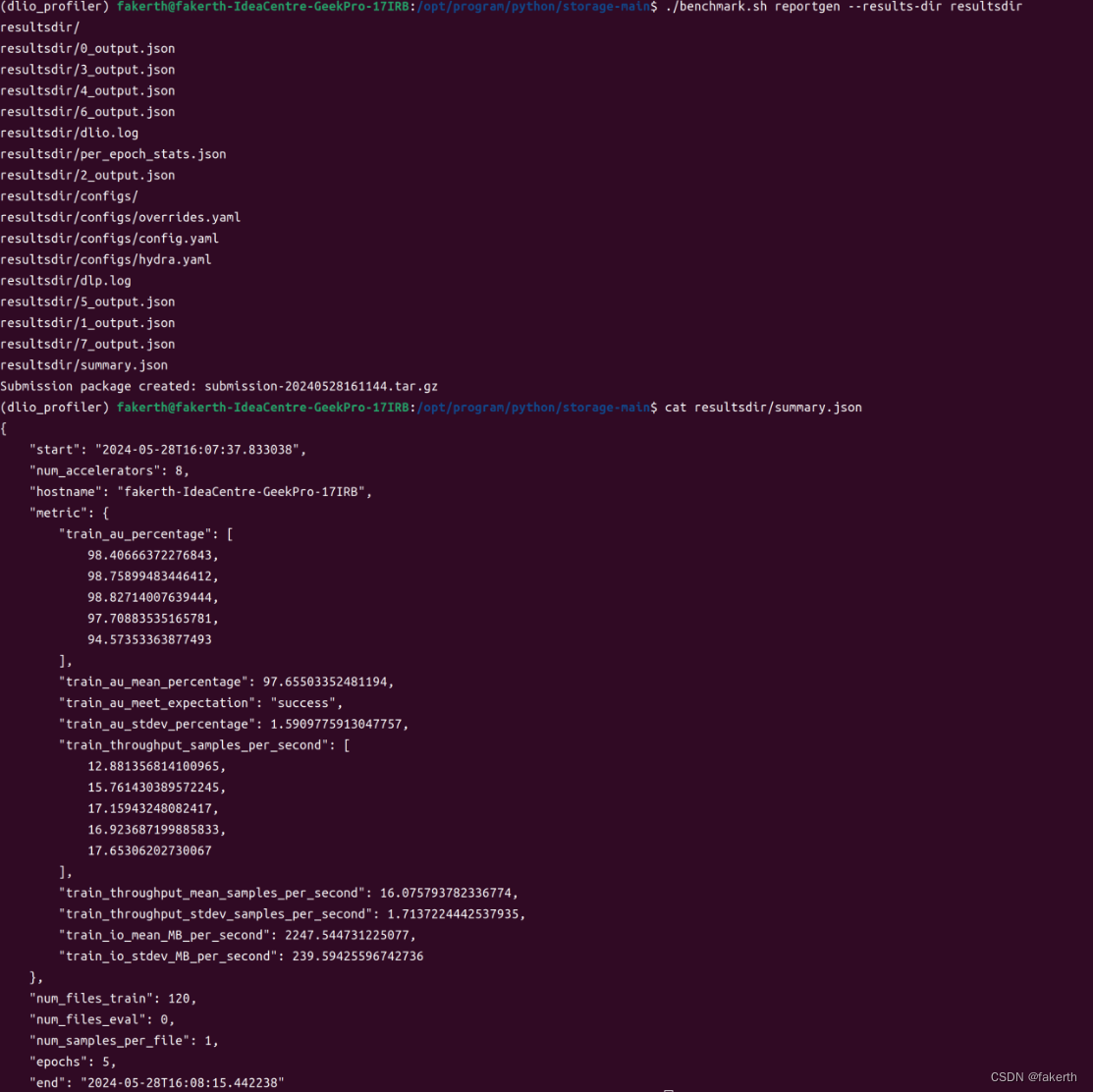
对于每个工作负载,基准测试输出指标是每秒样本数,但要满足最低加速器利用率(AU),越高越好。要通过基准测试运行,AU应达到 90% 或更高。AU计算如下。总理想计算时间来自批处理大小、总数据集大小、模拟加速器数量和睡眠时间:total_compute_time = (records/file * total_files)/simulated_accelerators/batch_size * sleep_time。然后AU计算如下:
AU (percentage) = (total_compute_time/total_benchmark_running_time) * 100
请注意,休眠时间是通过在真实硬件上运行包括计算步骤在内的工作负载来确定的,并且取决于加速器类型。在此预览包中,我们包含了 NVIDIA V100 GPU 的休眠时间,这是在 NVIDIA DGX-1 系统中测量的。除此之外AU,提交的内容还需要报告详细信息,例如 DLIO 主机上运行的 MPI 进程数量,以及 DLIO 主机上的主内存数量。
先决条件:
基准测试脚本只需在一个参与的客户端主机(任意)上运行,该主机内部调用mpirun以启动跨多个客户端主机的分布式训练。启动器客户端主机也参与分布式训练过程。
- 挑选一个主机作为启动器客户端主机。必须从启动器客户端主机到所有其他参与的客户端主机设置无密码 ssh。 ssh-copy-id是一个有用的工具。
- 代码和数据位置(后面部分将讨论)在每个客户端主机(包括启动器主机)中必须完全相同。这是因为在分布式训练过程中,每个参与的客户端主机都会自动触发相同的基准测试命令。
安装
ubuntu
提前安装mpich
git clone -b v1.0-rc1 --recurse-submodules https://github.com/mlcommons/storage.git
cd storage
pip3 install -r dlio_benchmark/requirements.txt
redhat
提前安装mpich,hwloc
git clone -b v1.0-rc1 --recurse-submodules https://github.com/mlcommons/storage.git
cd storage
pip3 install -r dlio_benchmark/requirements.txt
参考
安装mpich与hwloc参考:https://blog.csdn.net/weixin_43912621/article/details/139168124
测试
第一步,根据客户端配置计算基准测试运行所需的最小数据集大小:
./benchmark.sh datasize --workload unet3d --accelerator-type a100 --num-accelerators 8 --num-client-hosts 2 --client-host-memory-in-gb 128
第二步,为基准测试运行生成数据:
./benchmark.sh datagen --hosts 10.117.61.121,10.117.61.165 --workload unet3d --accelerator-type h100 --num-parallel 8 --param dataset.num_files_train=1200 --param dataset.data_folder=unet3d_data
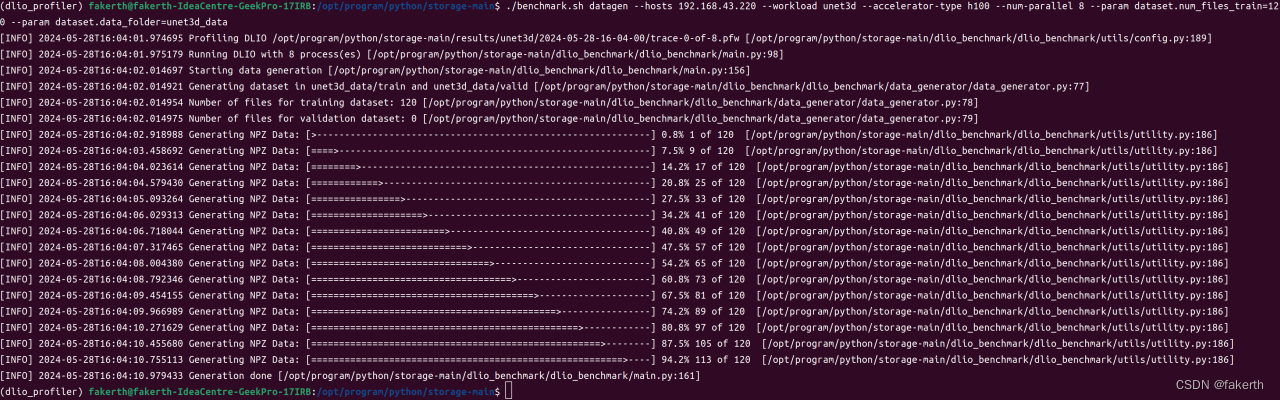
第三步,运行基准测试:
./benchmark.sh run --hosts 10.117.61.121,10.117.61.165 --workload unet3d --accelerator-type h100 --num-accelerators 2 --results-dir resultsdir --param dataset.num_files_train=1200 --param dataset.data_folder=unet3d_data
第四步,生成最终报告:
./benchmark.sh reportgen --results-dir resultsdir
关于conda环境迁移遇到的问题
ModuleNotFoundError:No module named dlio_profiler_py,但是conda list却显示已安装dlio_profiler_py。
# 查看是否链接悬空
ll storage10/lib/python3.10/site-packages/dlio_profiler_py.cpython-310-x86_64-linux-gnu.so
# 创建软连接
ln -s storage10/lib/python3.10/site-packages/dlio_profiler/lib64/dlio_profiler_py.cpython-310-x86_64-linux-gnu.so storage10/lib/python3.10/site-packages/dlio_profiler_py.cpython-310-x86_64-linux-gnu.so
# 添加环境变量
export LD_LIBRARY_PATH=storage10/lib/python3.10/site-packages/dlio_profiler/lib/:LD_LIBRARY_PATH
export LD_LIBRARY_PATH=storage10/lib/python3.10/site-packages/dlio_profiler/lib64/:LD_LIBRARY_PATH
python输出包所在的位置
import numpy
print(numpy.__file__)