目录
1.索引是什么,解决了什么问题
2.索引付出了什么代价
3.如何使用sql索引,有何注意事项
普通索引:
唯一索引:
主键索引(Primary Key Index):
删除索引:
创建主键索引的基本语法:
4.索引背后的数据结构
1.索引是什么,解决了什么问题
在数据库中,索引是一种数据结构,它被设计用来提高数据检索的速度。类似于书籍的目录,索引使得数据库能够快速定位到数据存储的位置,从而加速查询过程。
- 提高了查询速度:在数据库中假设有上千万条数据,在没有索引的情况下,我们可能需要遍历整张表,那么这个操作就会非常消耗时间。但是呢,通过创建索引,我们就能直接定位到所需数据的存储位置,从而减少查询时间
- 唯一性约束:唯一索引可以确保表中的某一列或多列数据的唯一性,防止重复插入数据
2.索引付出了什么代价
- 付出了更多的存储空间,可以理解成用空间来换取时间
- 可能会影响增删改的效率,但是整体来说利大于弊,对于这条下面单独讲解
为什么可能会影响增删改的效率呢?原因有以下几点
- 索引维护成本 : 每次当插入新纪录,删除现有记录或更新索引字段的值,数据库都需要相应的更新索引结构以保证其准确性
- 磁盘I/O操作增多 : 索引的维护通常涉及磁盘I/O操作,因为索引结构往往存储在磁盘上
3.如何使用sql索引,有何注意事项
普通索引:
默认类型,允许重复值和空值
基本语法:
create index 下标名 on 表名(列名);举例说明:
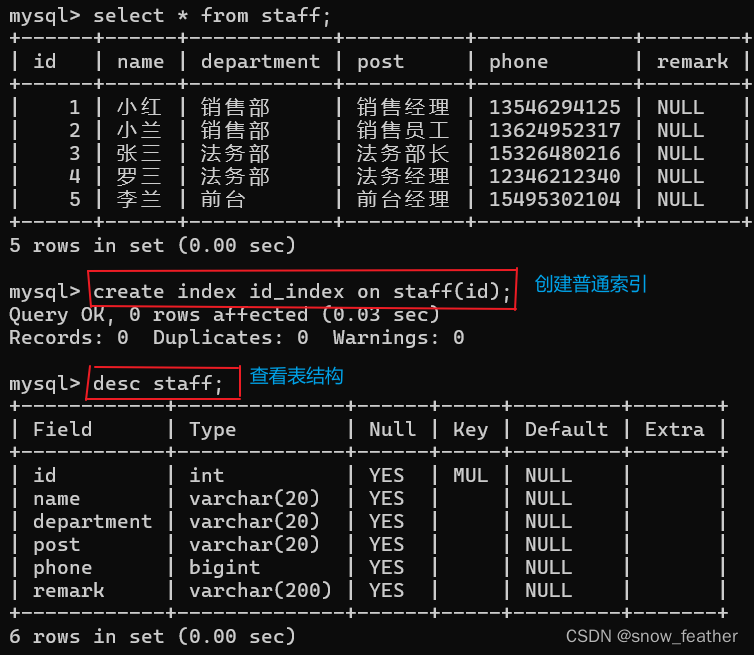
根据上述图我们不难看出,在Key列,id行有一个MUL,那么这个MUL是什么意思呢?
‘MUL’表示该列上有非唯一索引,也就是我们所说的普通索引
‘UNI’表示该列上有唯一索引
'PRI'表示该列上有非唯一索引
当然,查看索引是否创建成功我们不止有desc 表名这一种方法,我们还可以使用show index from 表名,这种方法就不在这里展示了
唯一索引:
确保数据的唯一性和准确性,不允许有重复的值(除了NULL值)
基本语法:和普通索引差不多,只不过是多了一个unique关键字
create unique index 索引名 on 表名(列名);举例说明:

这里的 'UNI' 参考上文普通索引的补充
主键索引(Primary Key Index):
首先,每个表只能有一个主键,主键的值必须唯一且不能为空(NULL)。由于主键的唯一性和非空性,主键索引自然也具有唯一性,这意味着索引中的每个值必须是唯一的
在数据库中普通索引,唯一索引和主键索引是可以共存的,这里只是为了方便演示就把普通索引和唯一索引,删除索引的方式如下
删除索引:
基本语法:
drop index 索引名 on 表名;举例说明:

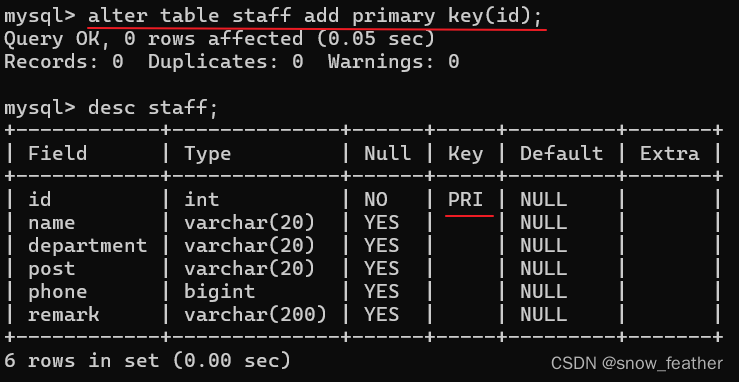
创建主键索引的基本语法:
alter table 表名 add primary key(列名);举例说明:
索引是针对列来创建的,后续查询的时候,查询条件使用的列和索引列匹配,才能索引生效,才能提高效率
针对一个比较大的表,创建/删除索引是一个非常危险的操作,可能会触发大量硬盘IO,把机器搞挂
那么这个硬盘IO又是什么呢?简单来说就是,硬盘I/O(Input/Output,输入/输出)是指硬盘与计算机系统之间进行的数据传输操作,具体包括读取(Read)和写入(Write)两个基本过程。
4.索引背后的数据结构
特点:
- 每个节点上包含N个key,划分出N个区间
- 每个父节点的元素都会下沉到子节点中,作为该子节点中最大值的角色来存在
- 叶子节点这一层就构成了数据集合的全集
- 使用类似于链表这样的结构,把叶子节点串起来
优势:
- 高度比较低,降低了硬盘IO次数
- 范围查询非常方便&高效
- 所有查询都落到叶子节点上,开销稳定,容易预估成本
- 叶子结点存储
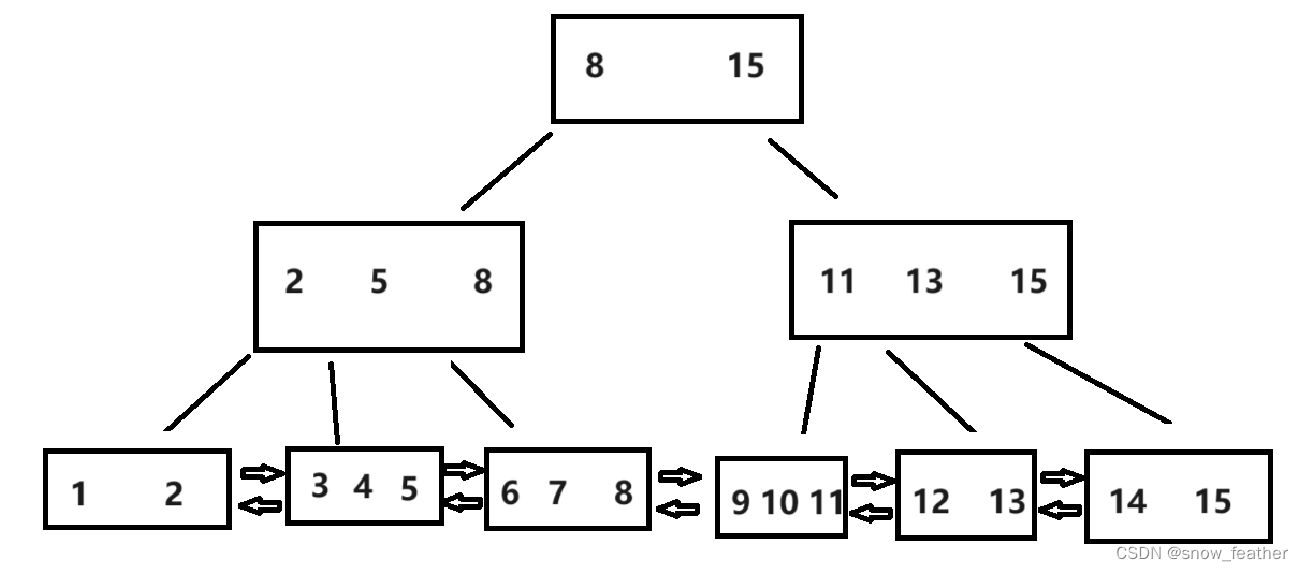
根据上图我们可以看见每一层的数字都作为下一层的最大值,而叶子结点写的并非是真正的值,而是一个一个行,比如这个 “1” 可能存放的是 “1 张三 法务部” 这条记录,表里的每一行都是挂在B+树的叶子结点上面的,而非叶子节点只需要存储key的值即可,不需要存储数据行

![[数据集][目标检测]旋风检测数据集VOC+YOLO格式157张1类别](https://img-blog.csdnimg.cn/direct/83778a7731d64af3bcf2e70a39acf8a0.png)

![[Windows] 植物大战僵尸杂交版](https://img-blog.csdnimg.cn/img_convert/079456a2ecbcdb04ca5a8ae9164f8ac7.jpeg)



![[leetcode hot150]第五十七题,插入区间](https://img-blog.csdnimg.cn/direct/f5d97d13edab4ac397ffbb5352abc509.png)