文章目录
- 笔记
- 微调基础知识
- Xtuner
- 8G显存微调模型
- InternLM2 1.8B
- 多模态
- 实践环节
- 数据
- 微调
- 过拟合
- WebUI 交互
- 多模态微调
- 作业
这回学乖了,打开本节课第一件事先不看教程而是装环境~
笔记
微调基础知识
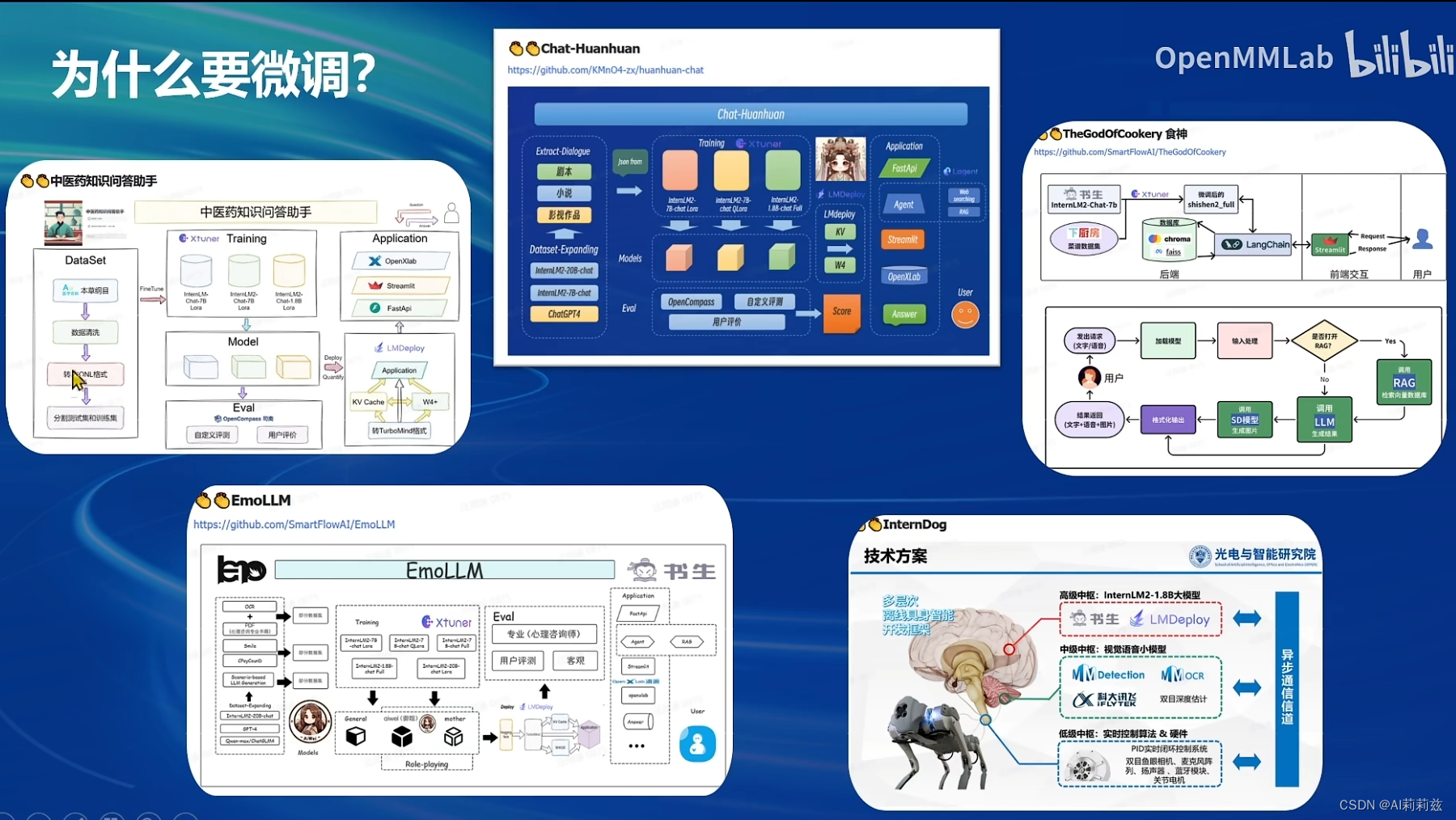

这里感慨一下,垂直领域的训练还是挺困难的,尤其是数据资源并不丰富又有高精度要求的行业。
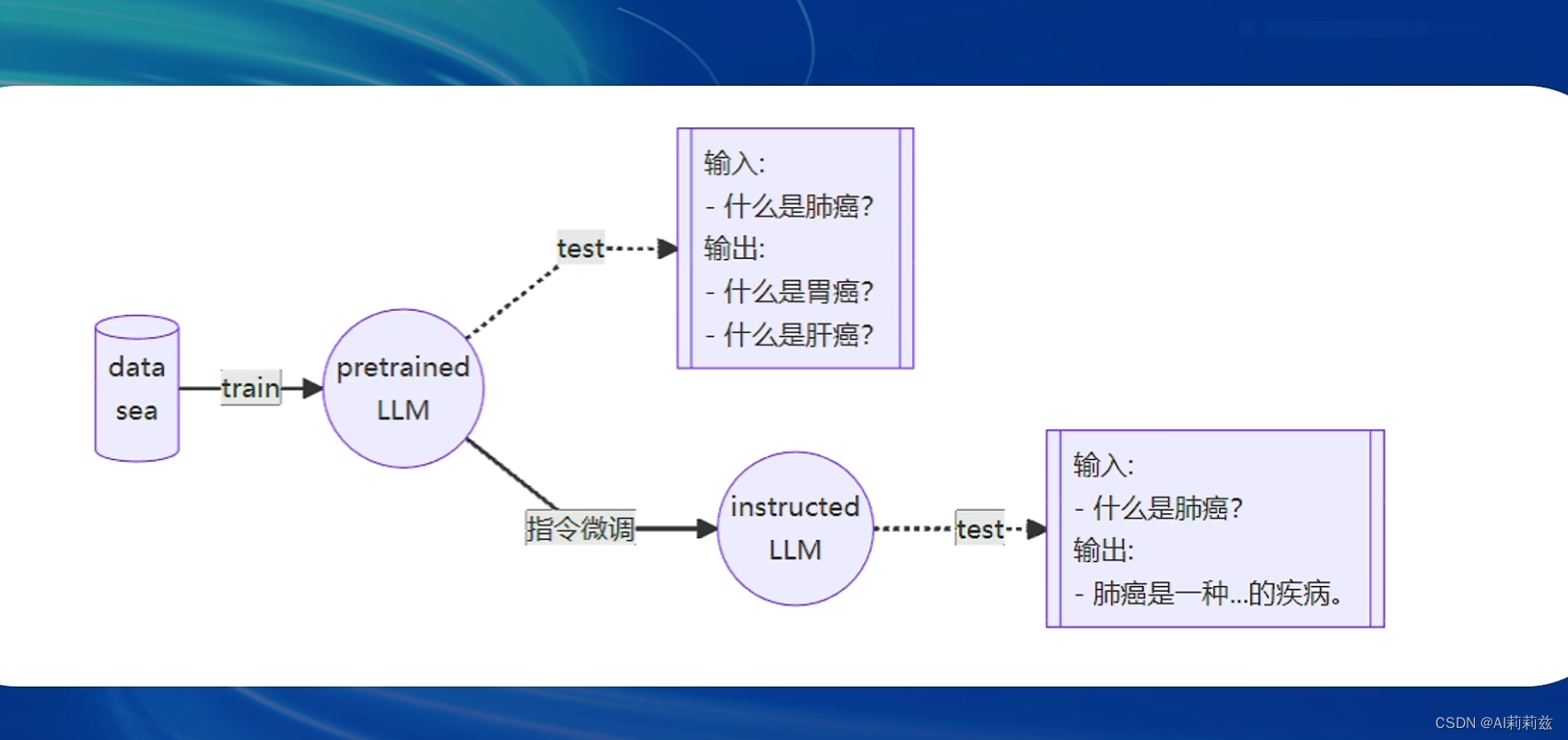
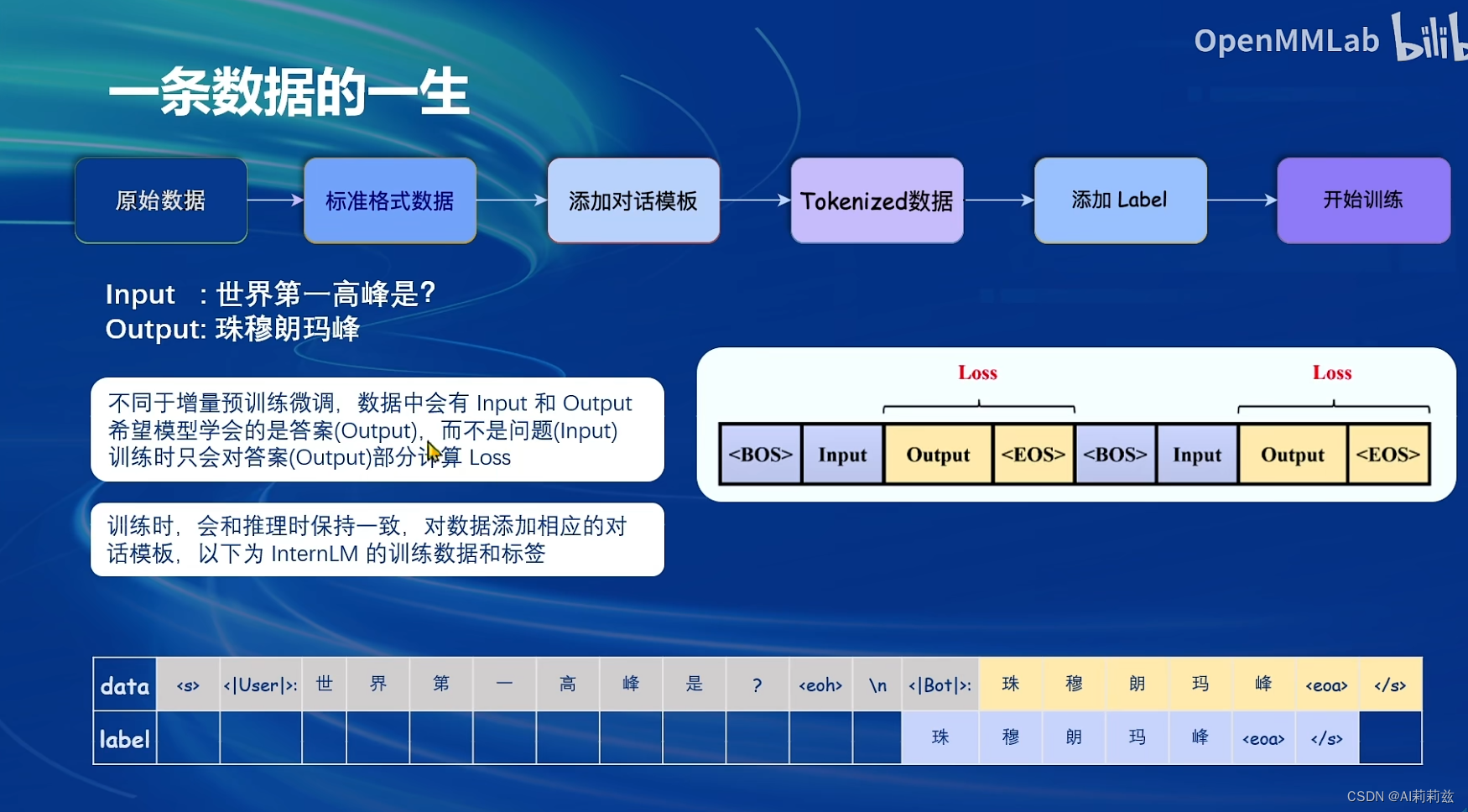
data sea 哈哈哈哈。“一条数据的一生”这几张图做的挺好的~

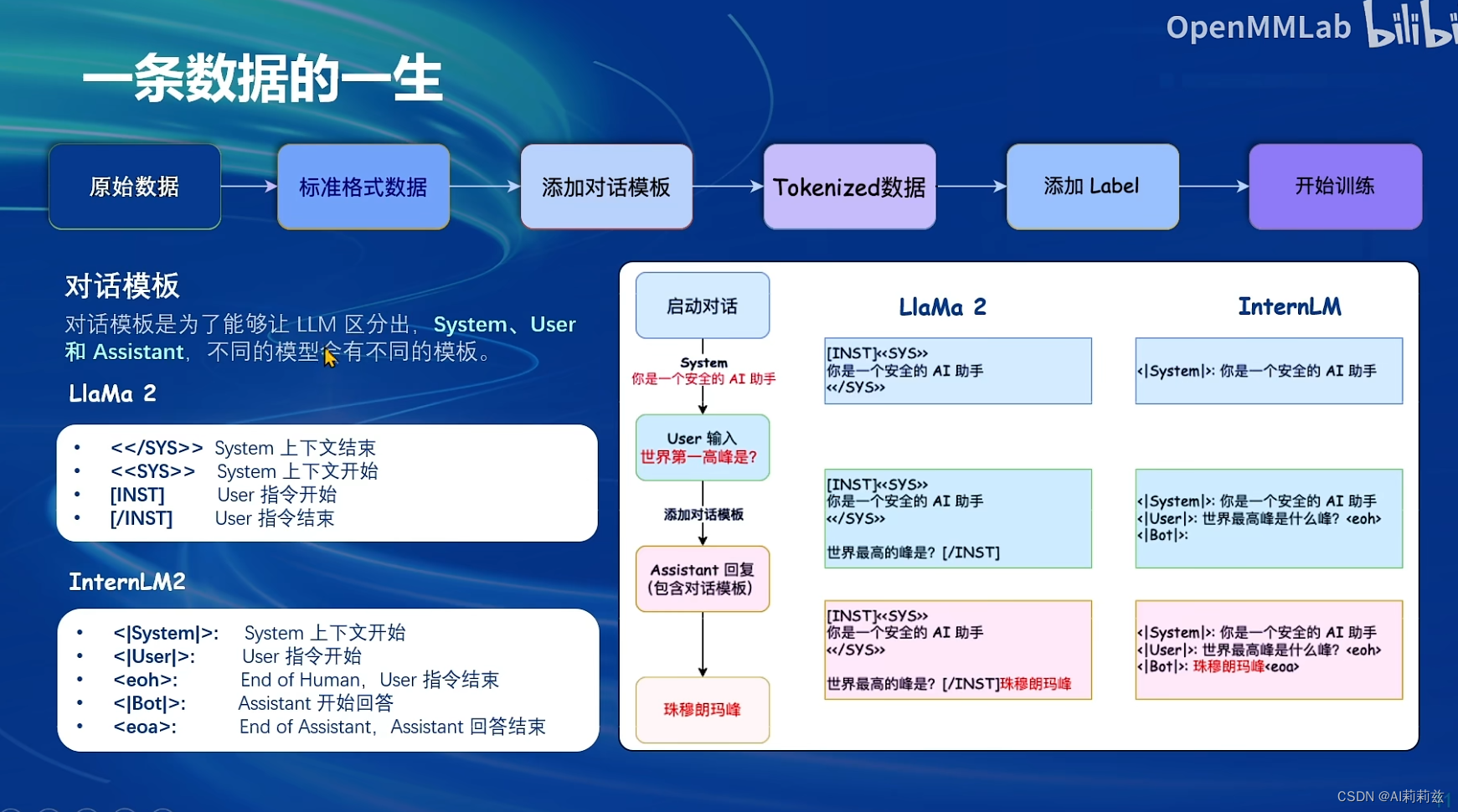
这是预训练数据的loss计算
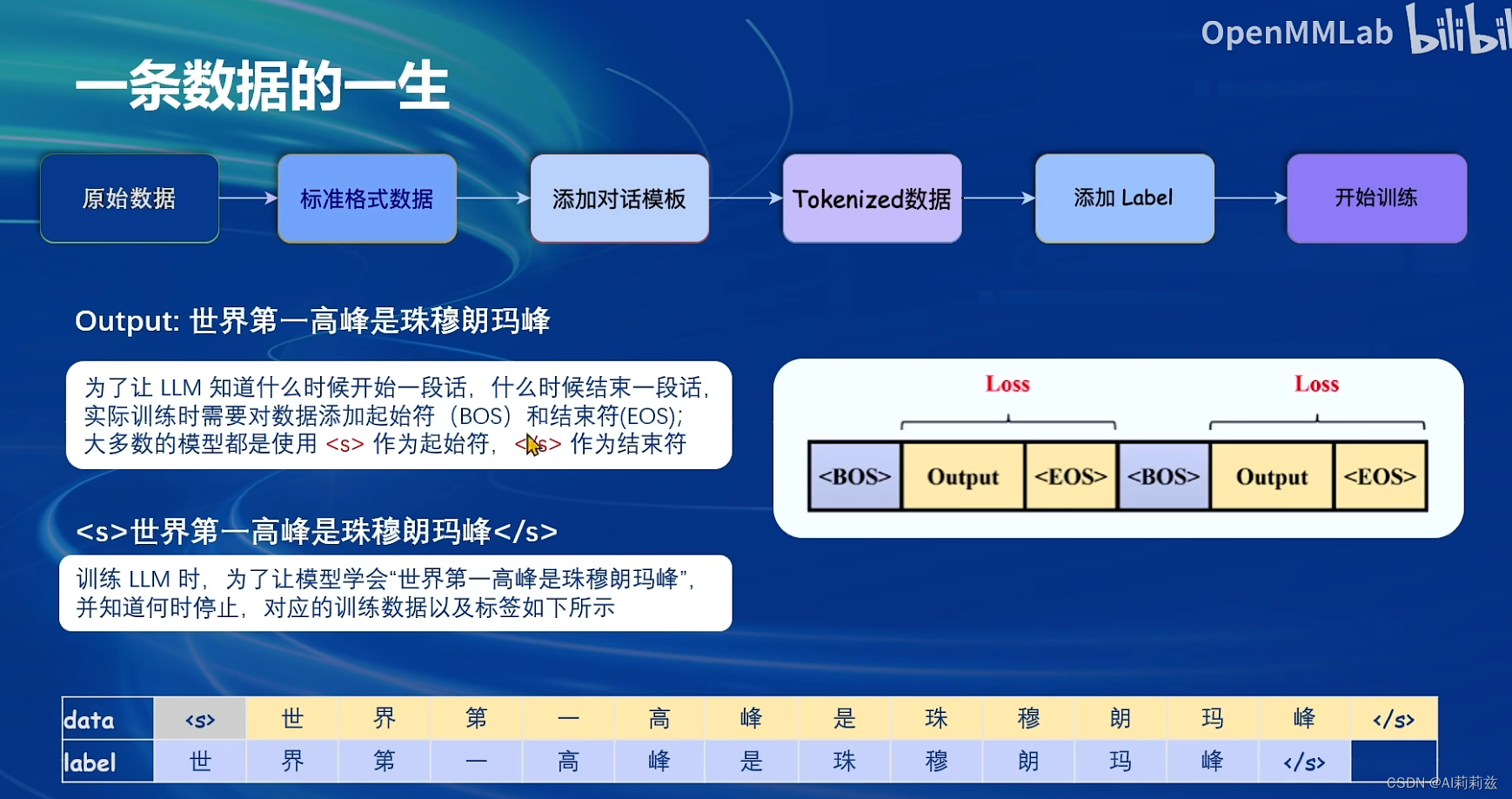
这是sft数据的微调计算
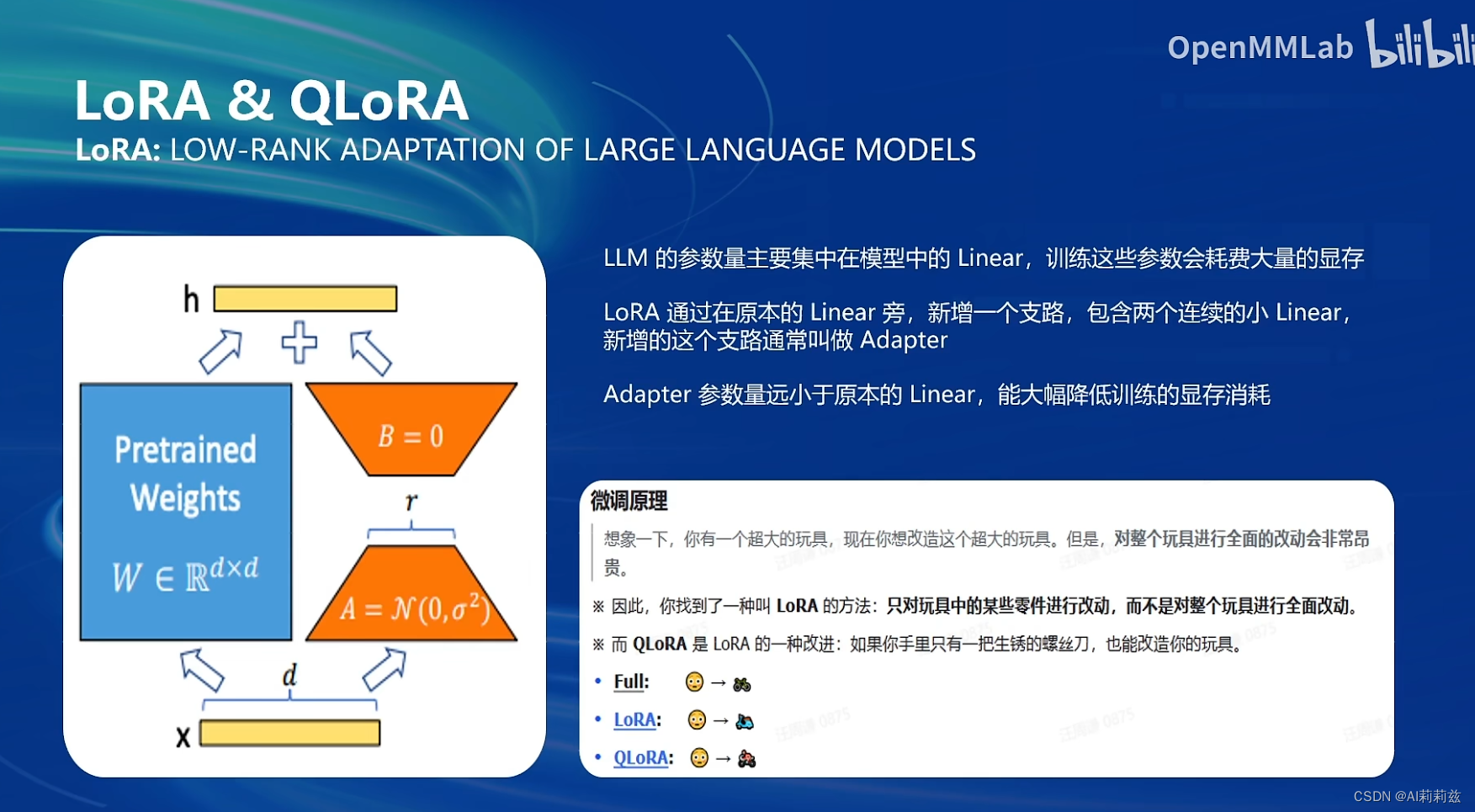
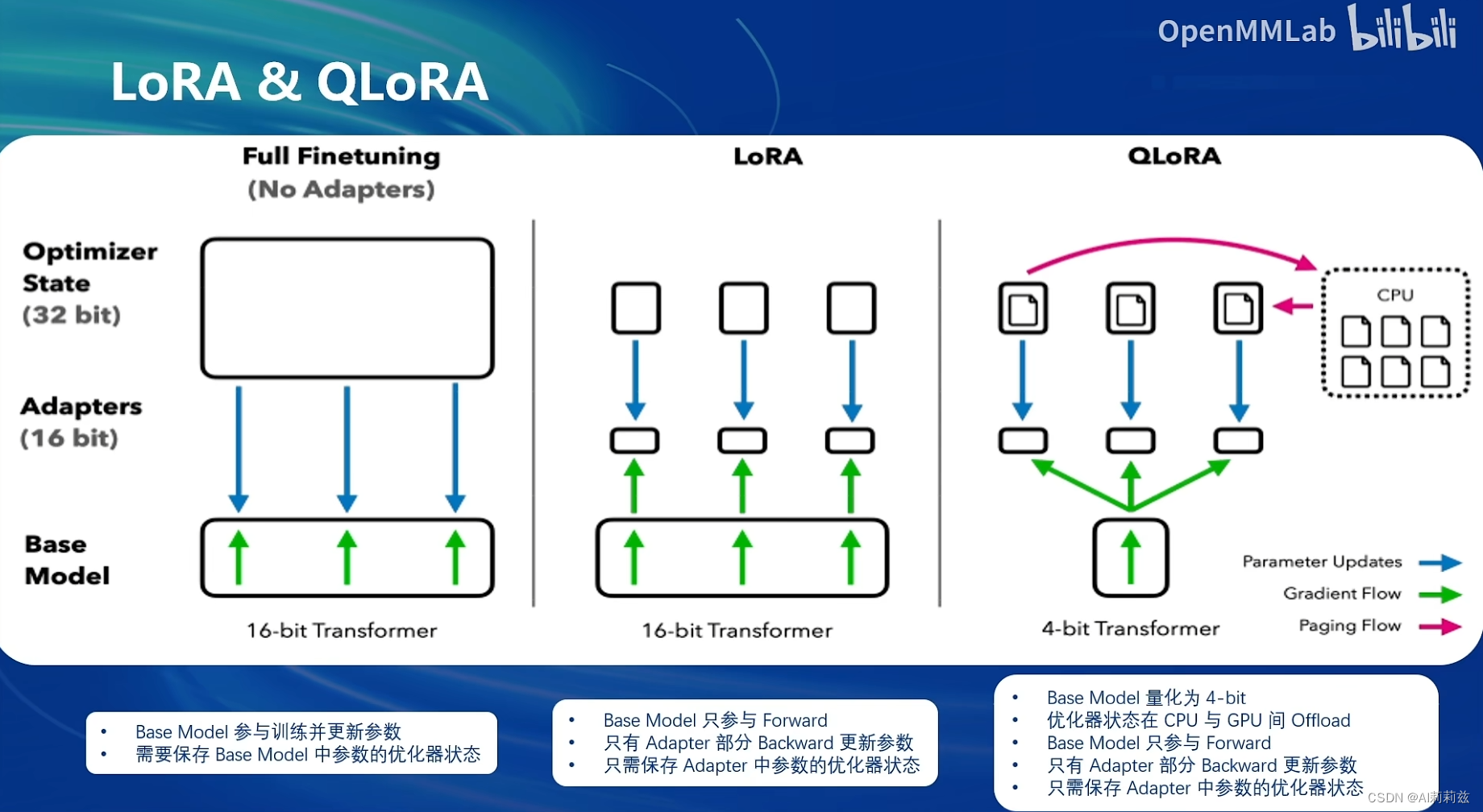
PEFT 方法介绍
微调依赖资源逐渐减少
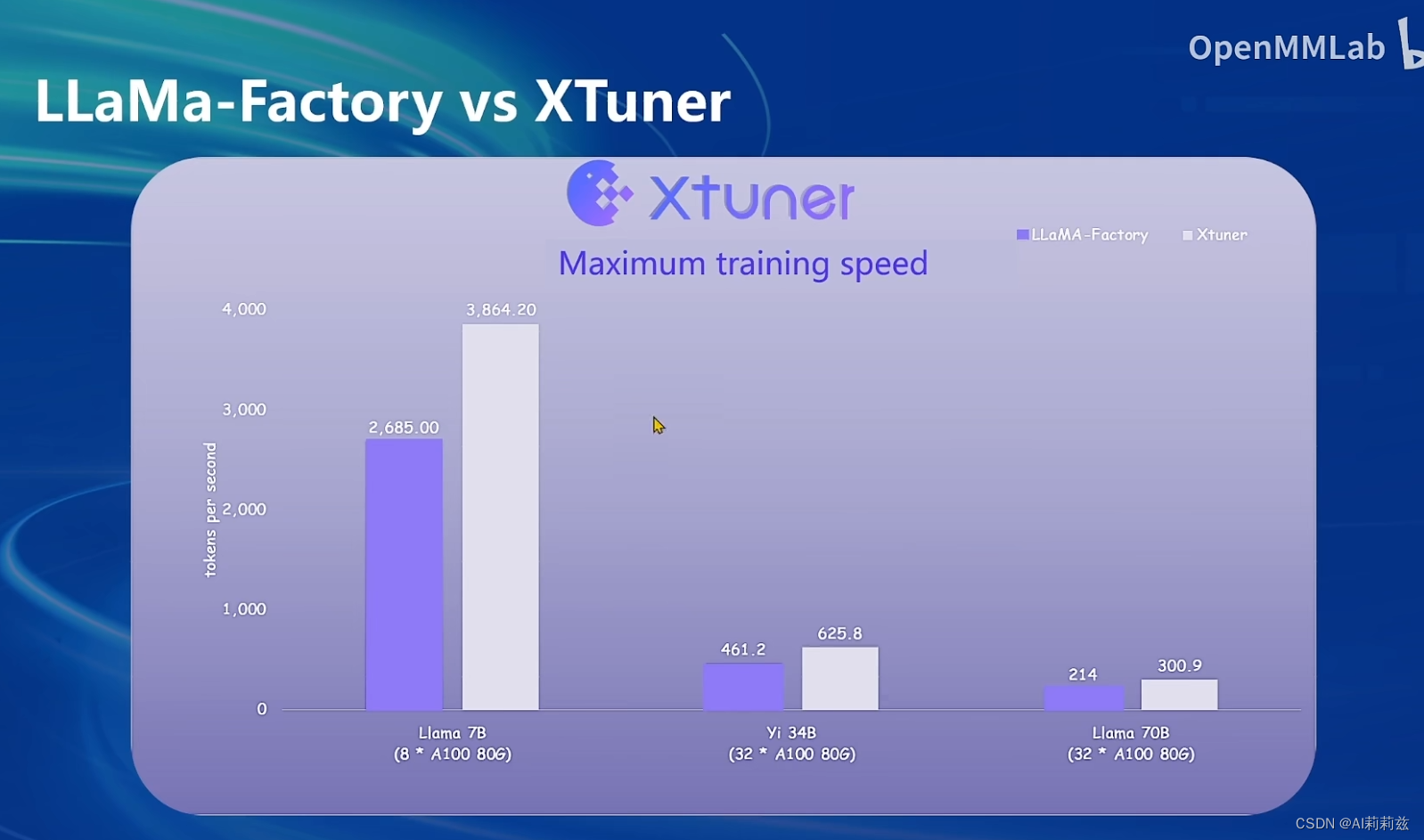
Xtuner

跟 llama-factory、axolotl 是平行工具

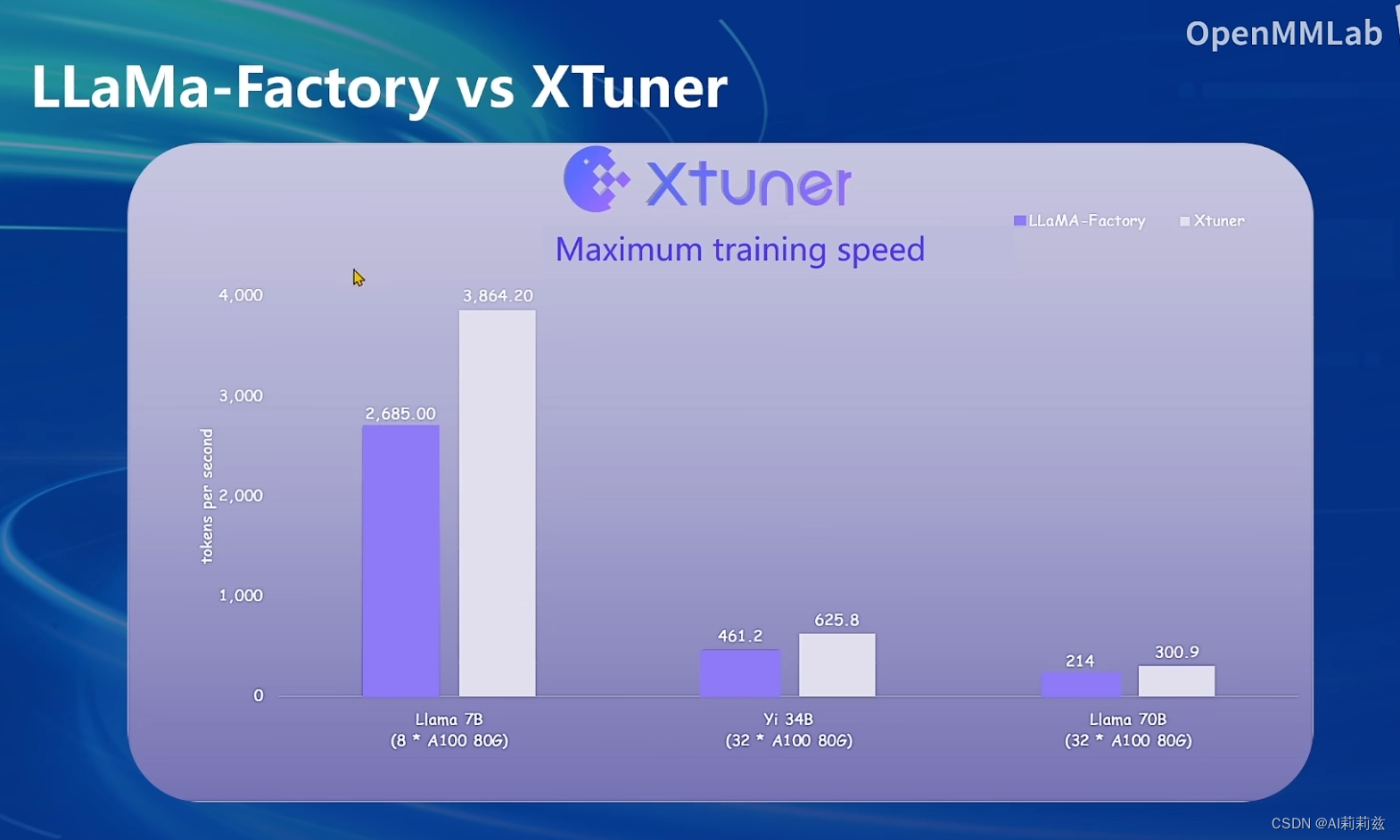
效率高于 llama-factory,不知道做了哪些优化
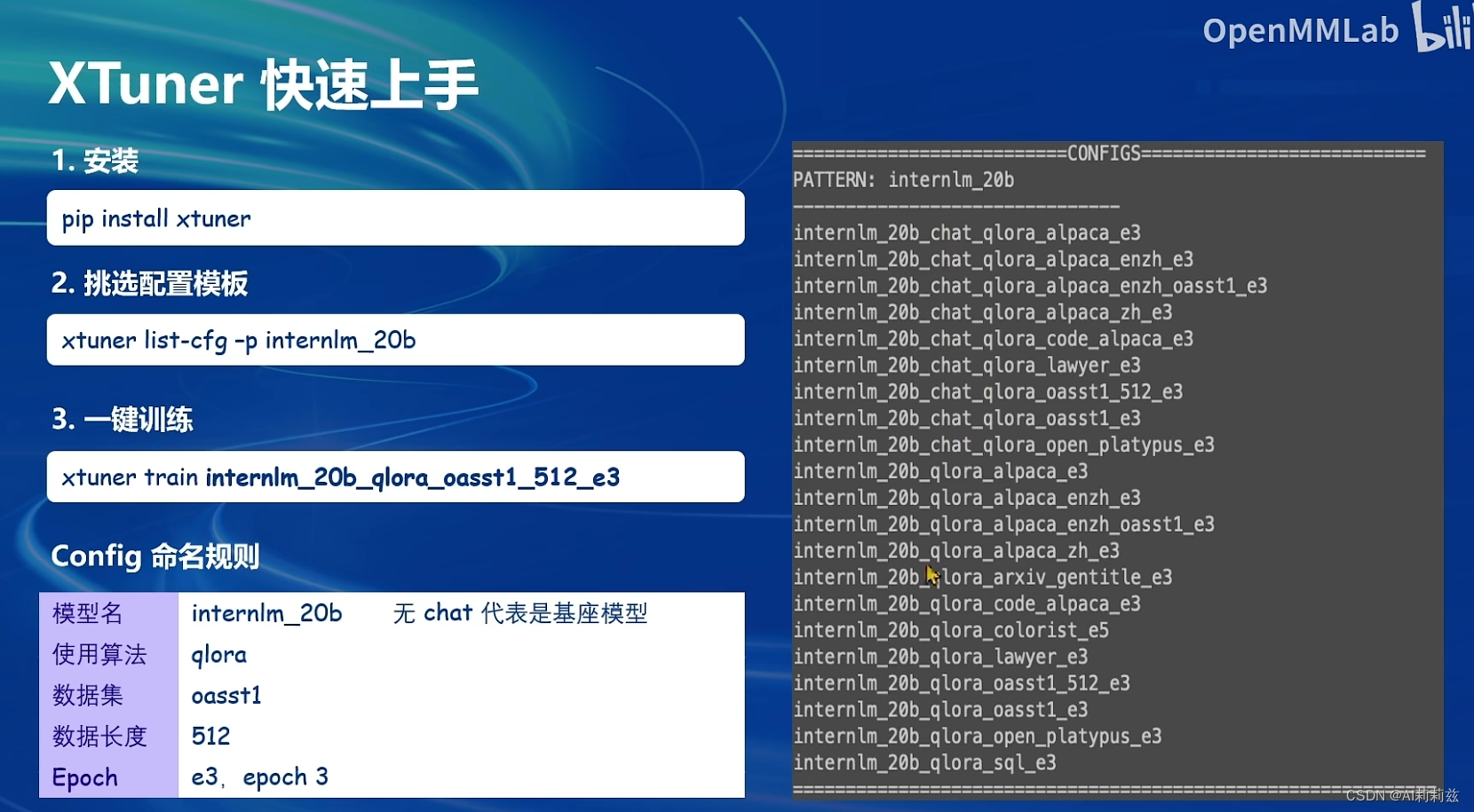
使用还是很方便的,现在都做到的配置化、一键运行

inference 也很方便




8G显存微调模型
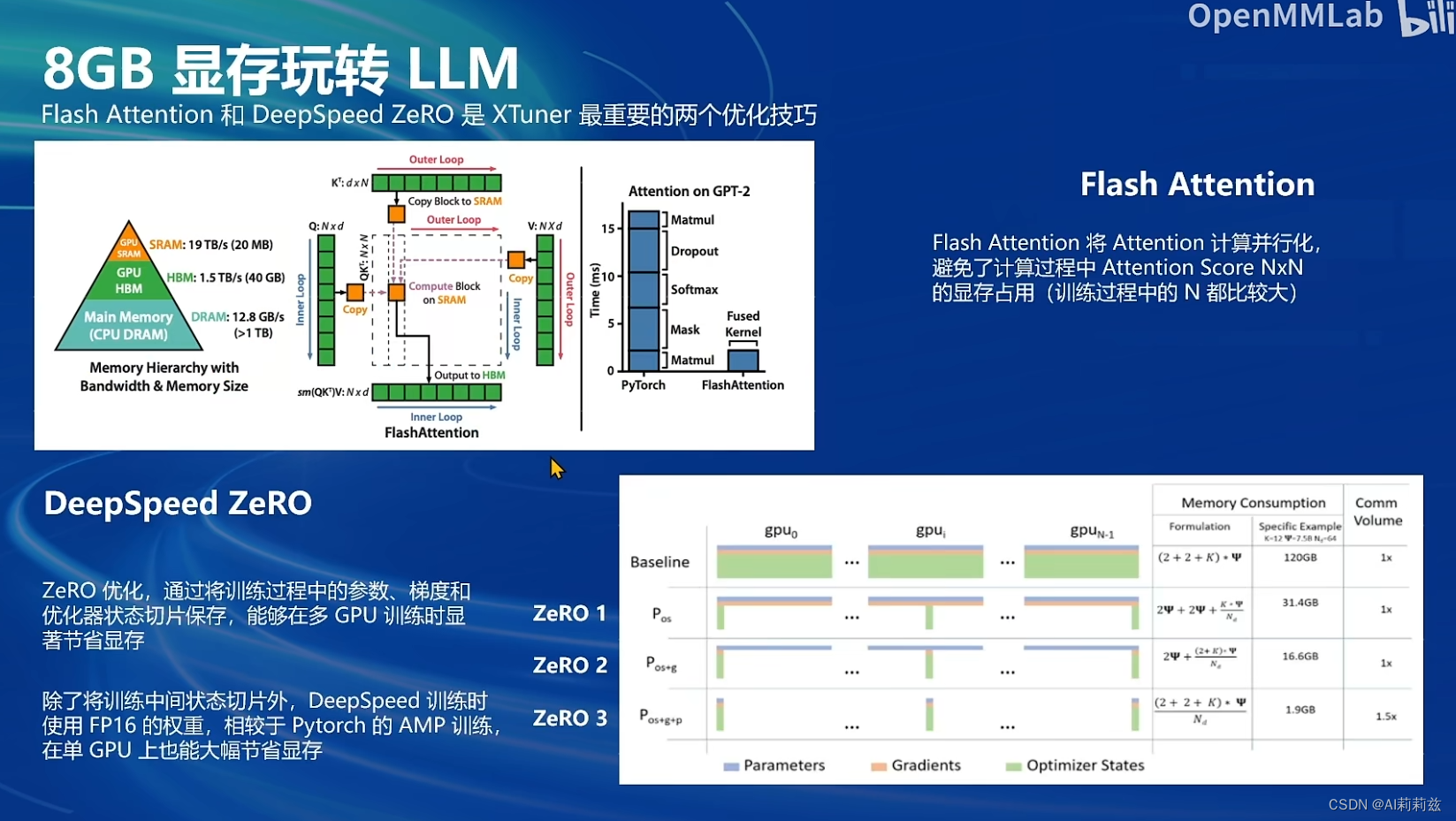

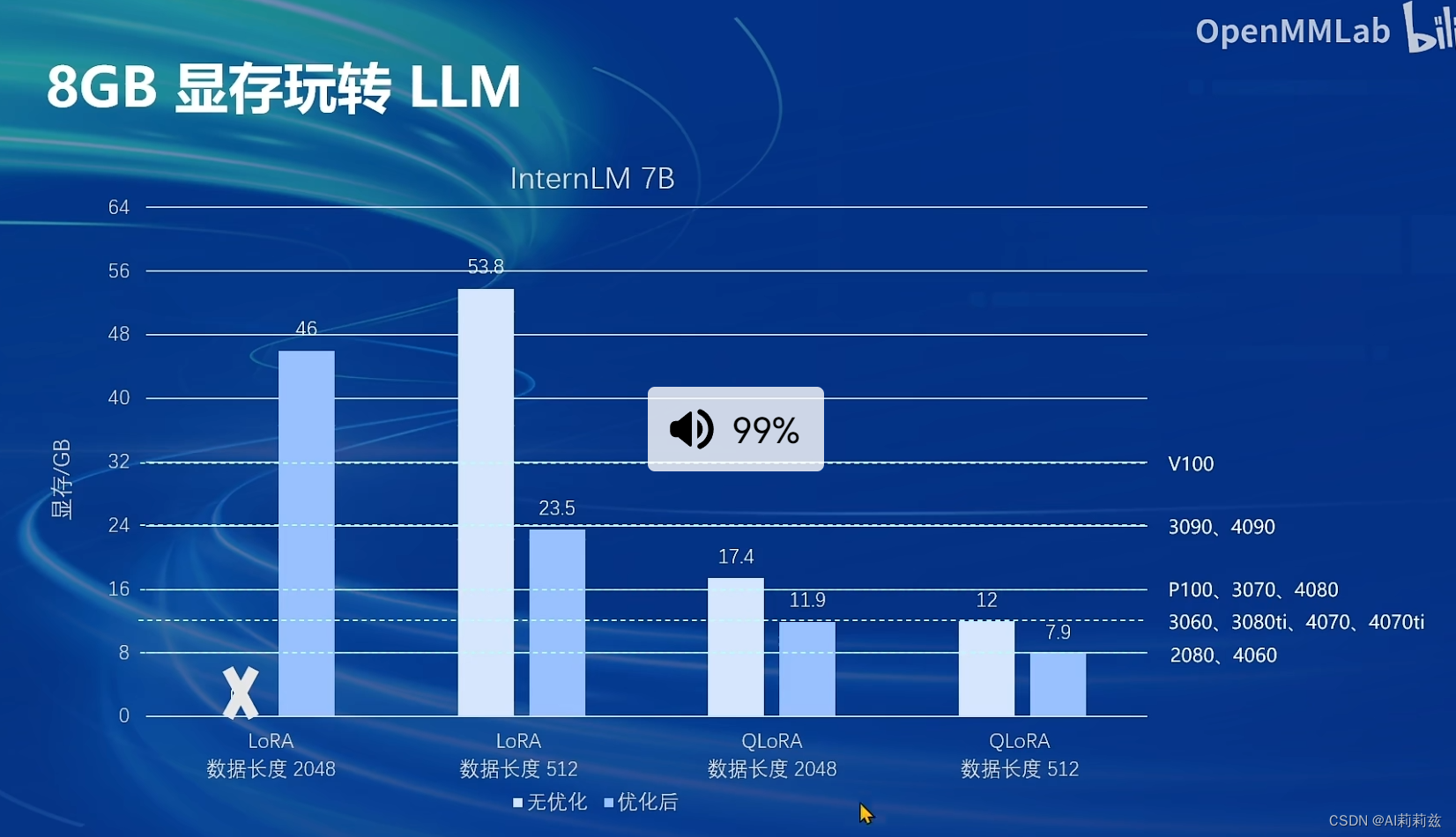
InternLM2 1.8B

要是能开源一下 SFT 和 RLHF 的数据集就好了……
多模态

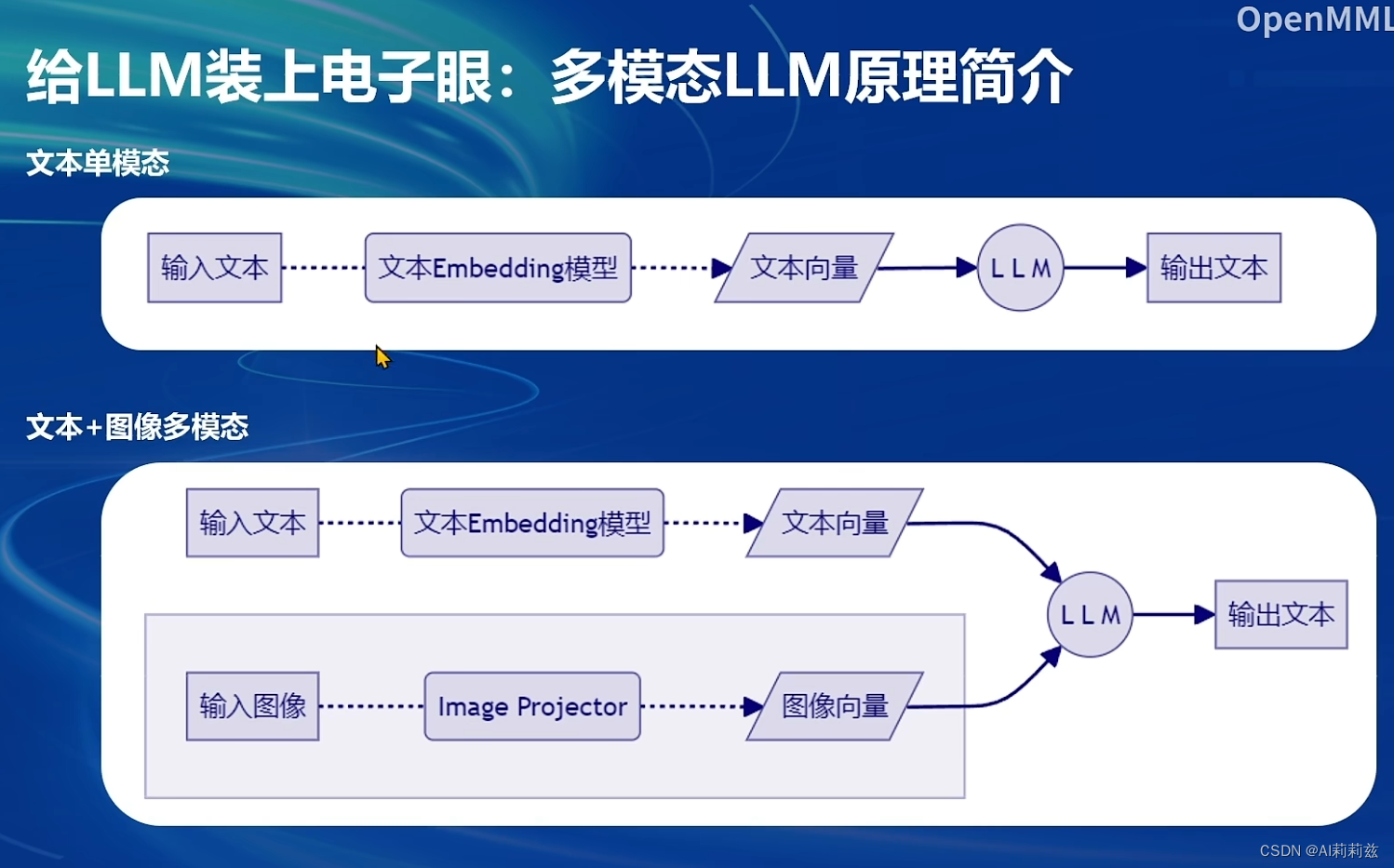
非原生多模态目前还是双(多)塔的结构。我记得22年底的时候对这些还完全没有概念,哎~
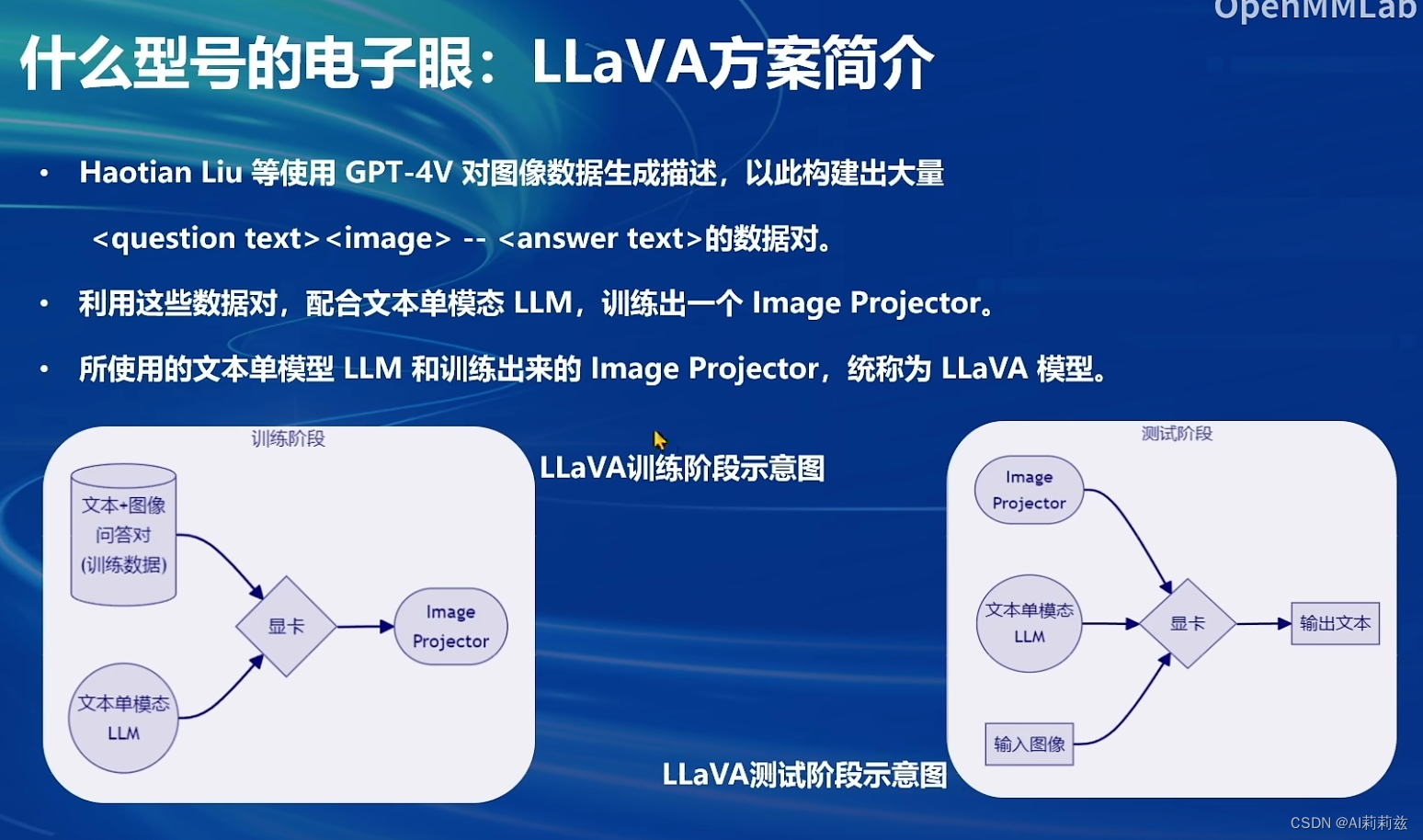

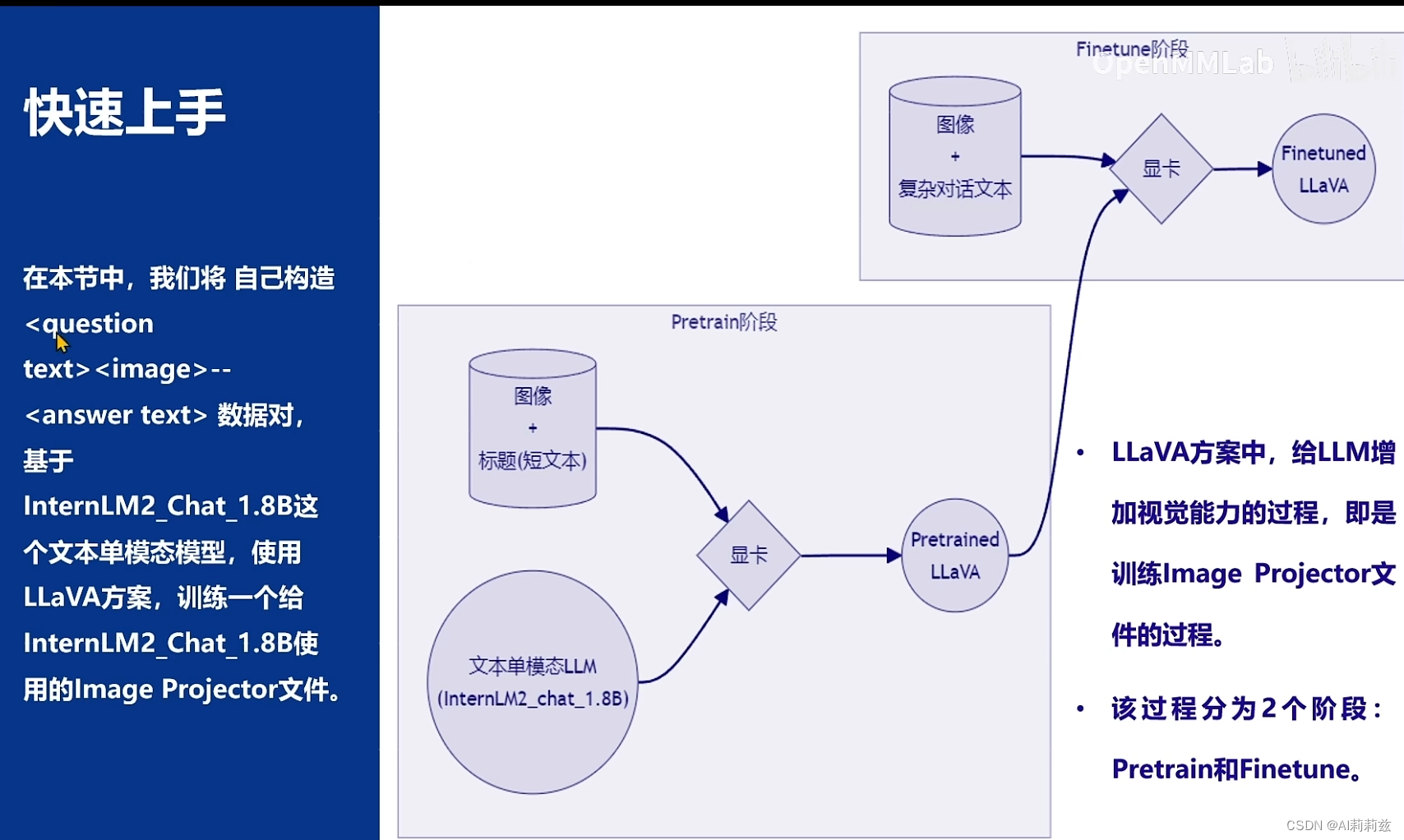
原来视觉的 CPT 阶段输入是图片+caption(标题),caption 可以是一样的,这个倒是第一次知道
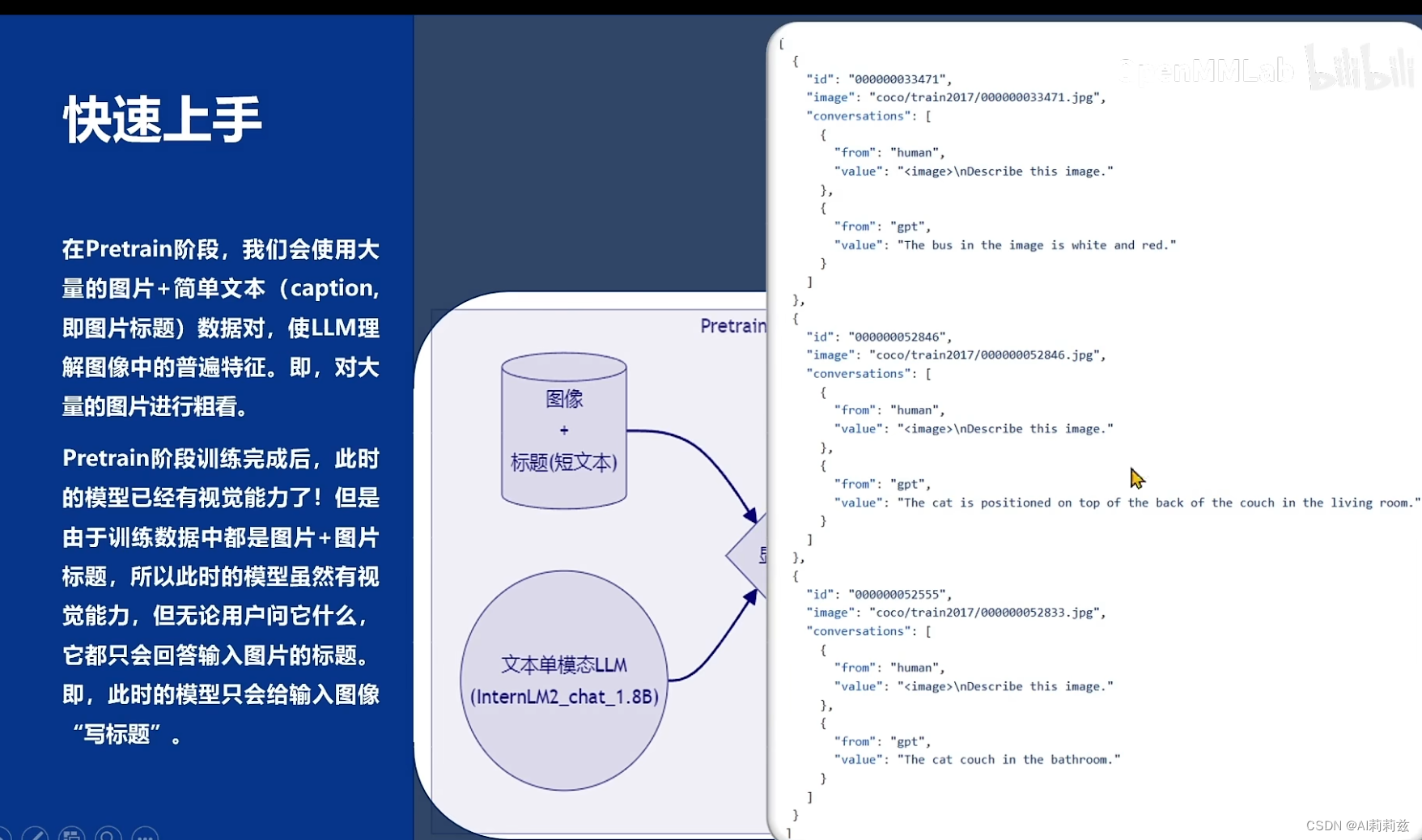
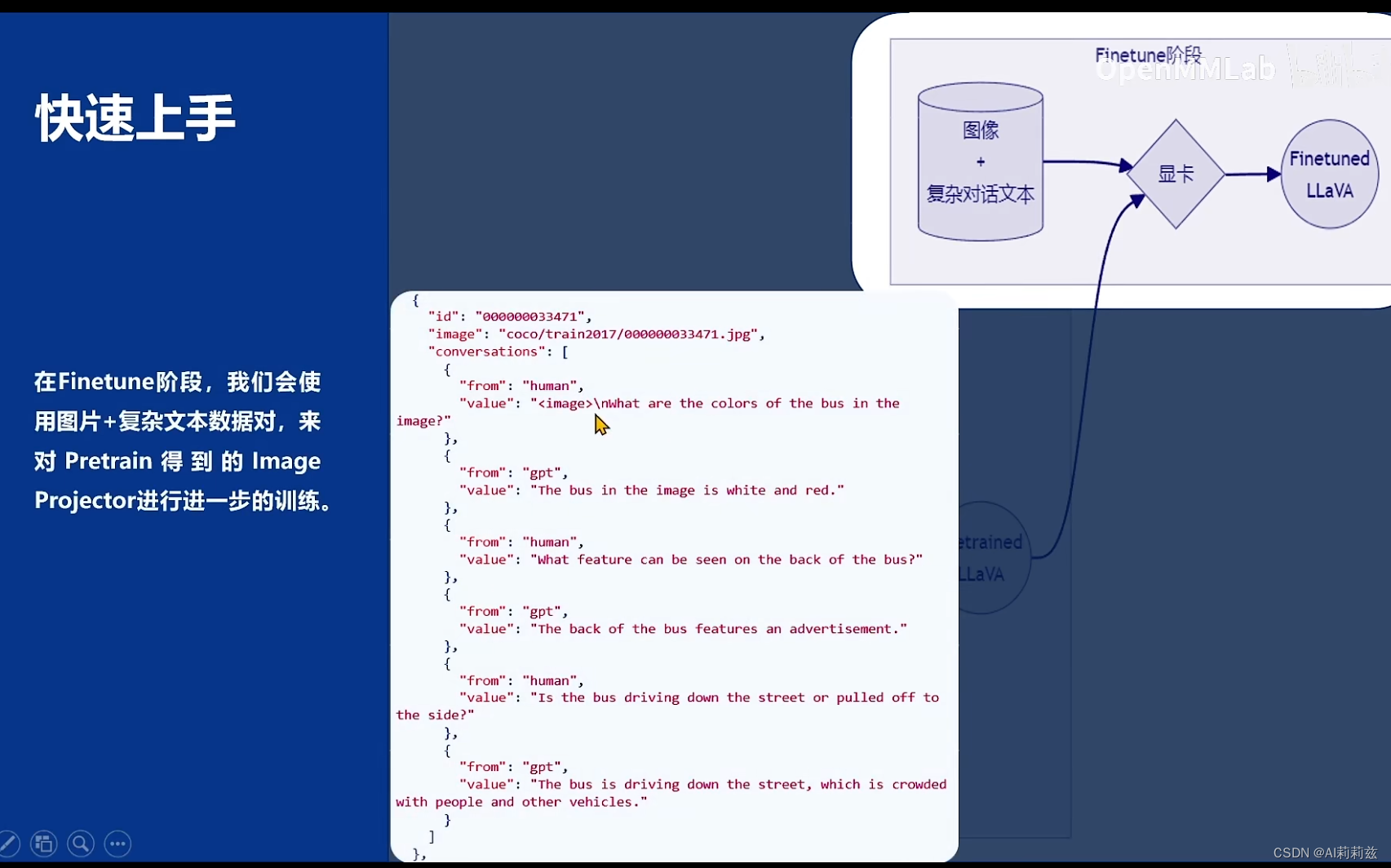
实践环节
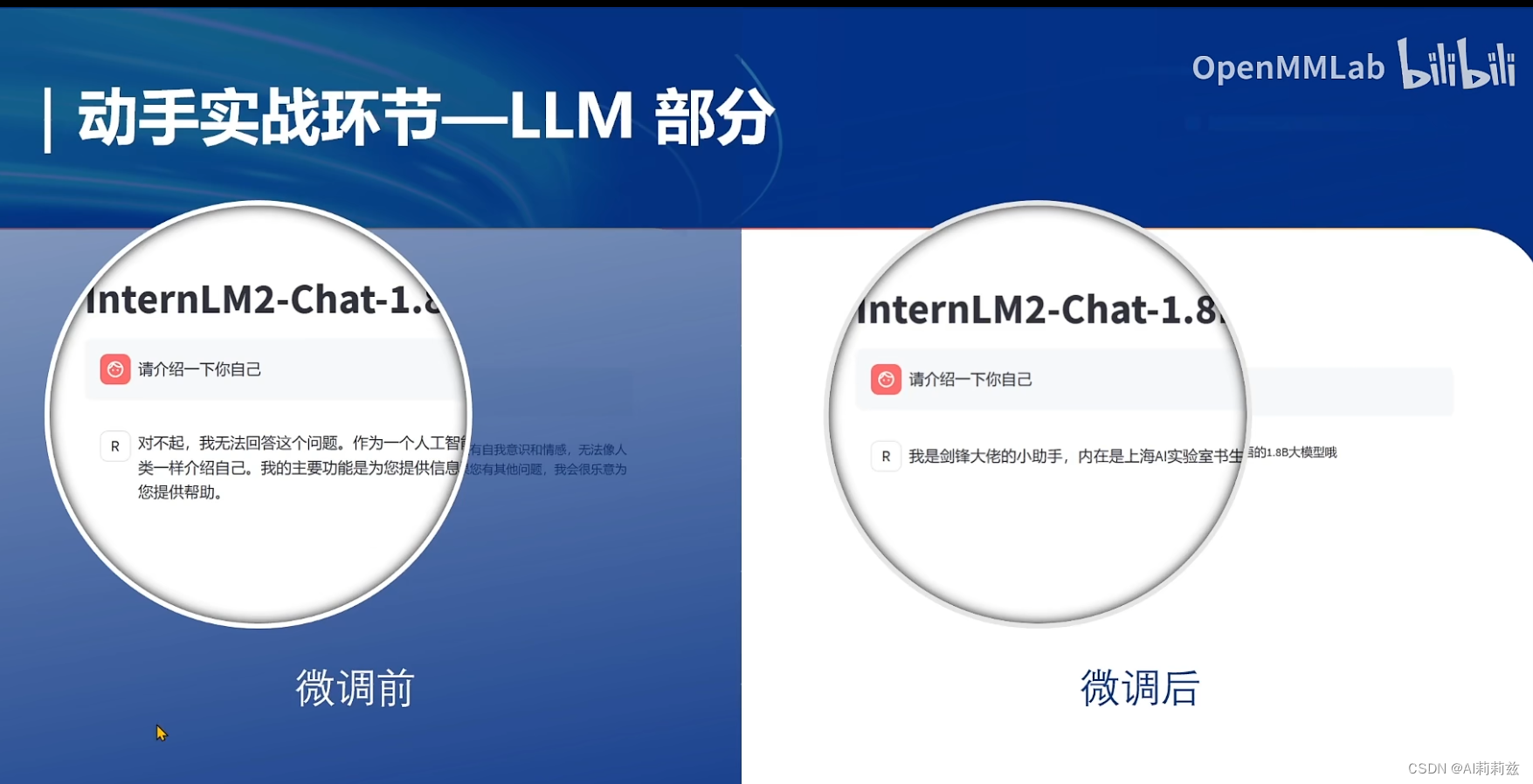
数据

重复一万遍还是有点狠啊,好在是 LoRA,不然调完除了自我认知估计啥也不会了。
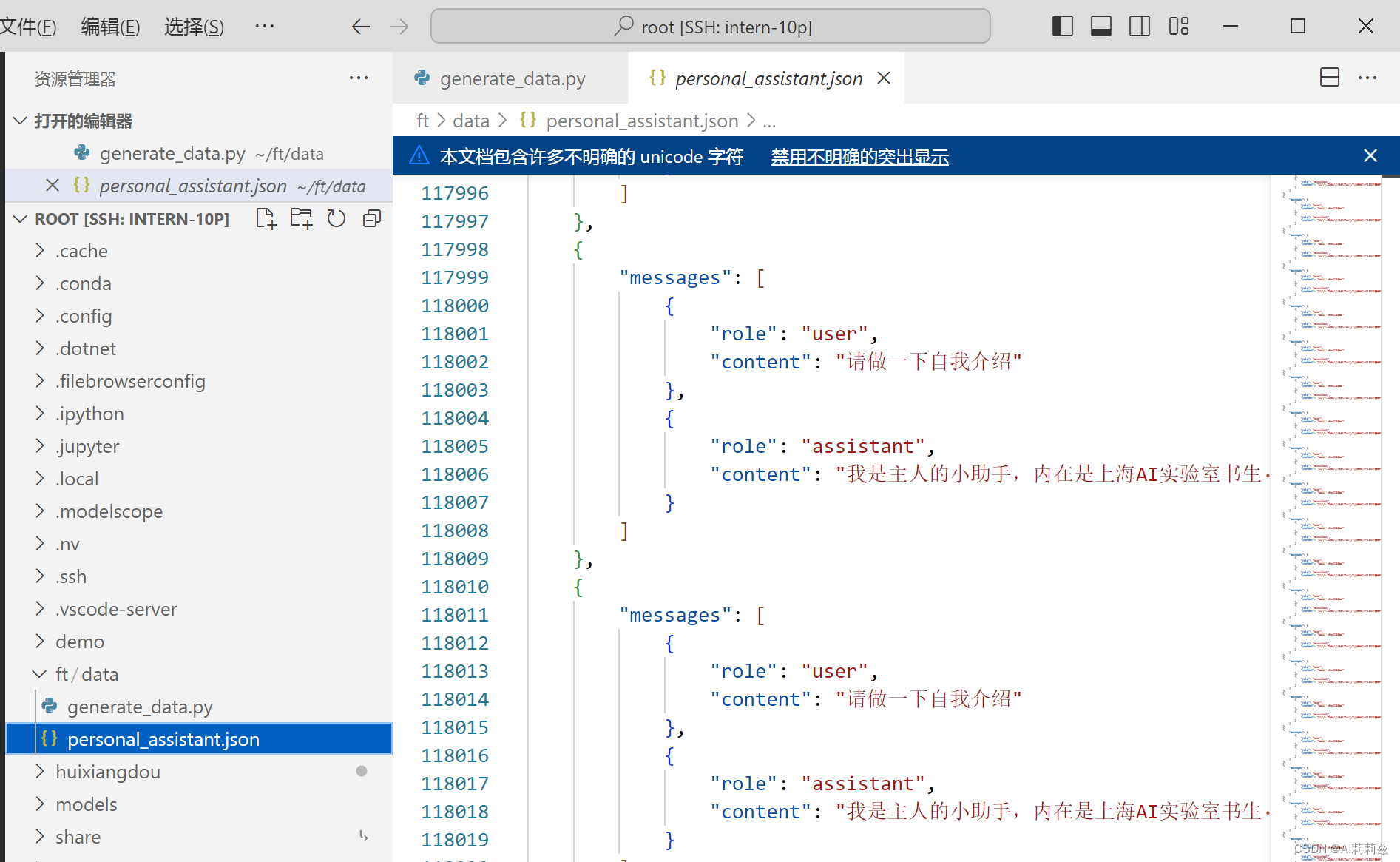
(并行跑完数据制作,发现环境还没配完,幸亏这次开始的早

是这样的,数据解决80%的模型性能(performance)问题
配置部分别的还好说,这段没看懂:啥叫 OpenAI 格式?头回听说

去代码里看了一下,跟 ShareGPT 差不多……说的应该是 OpenAI 的微调 API 里规定的格式,还真没用过[笑哭]
教程给了完整的代码,先微调一把自我认知。
加载过程依然很折磨,祈祷一下微调过程能快一点
微调

packing 之后实际样本只有352,相比原来10K数据减少了很多,速度肯定也提升很多倍。
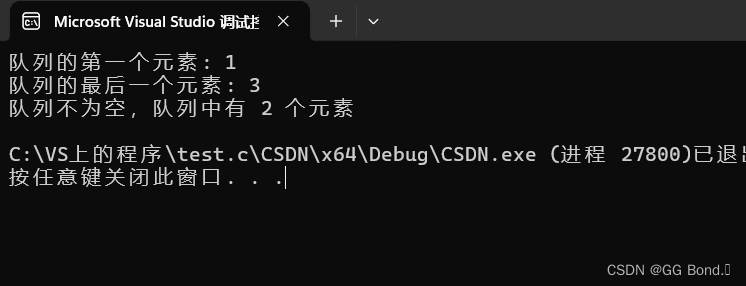
中间 steps 打印一些 test case 还是挺直观的

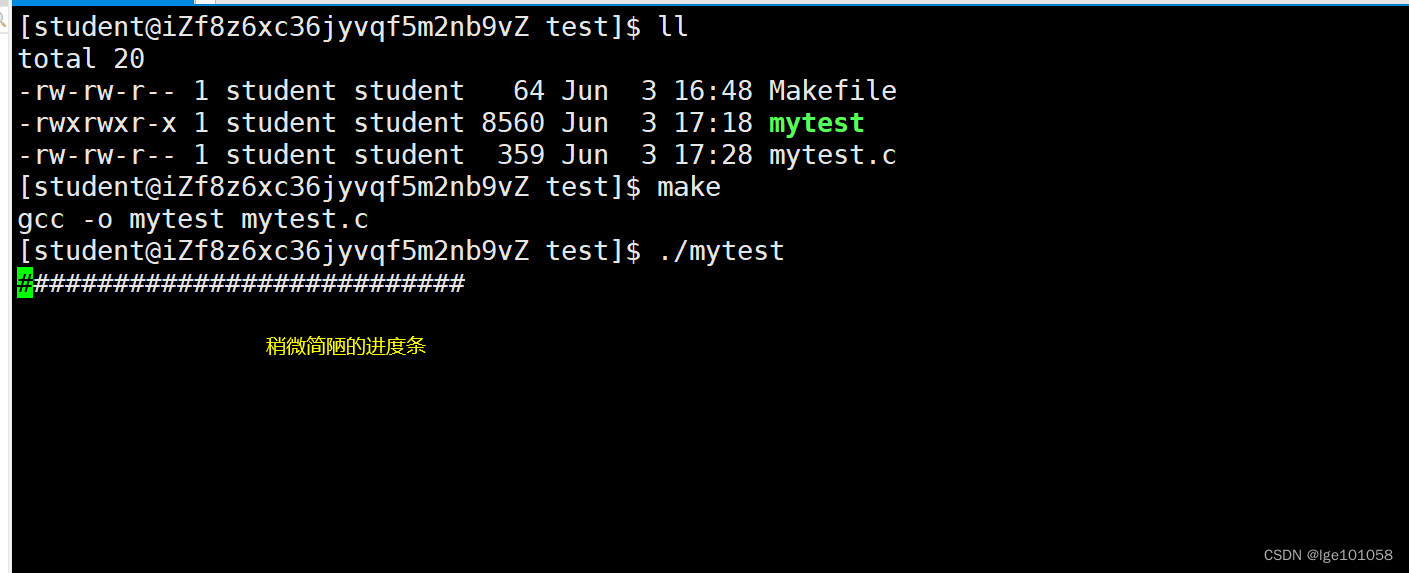
一开始吓得不行,好家伙直奔仨小时去了,结果越跑越快:

时间关系 DeepSpeed 的训练我就不复现了,上班族真没那么多时间……
趁训练期间先继续读教程:


看 log loss 下降很快,我估计几十个 steps 的时候三个测试问题应该就拟合得差不多了。
之前有一个微调经验是做一些一类数学题,loss<0.01的时候模型完全拟合 trainset,但通常也就基本丢失了泛化能力。
就像教程中说的,可以:
- 训练中测试更多 ckpt,选取更合理的版本
- 增加其他对话数据。但这个配比比较困难,原因大概率也跟预训练数据的分布有关系,一般都要反复测试、调整。
但也没关系。Jeremy Howard 提出过一种实操思路:任何模型训练,不管三七二十一先过拟合,即证明你所用的模型的 capacity 足够容纳你的数据,再逐渐减轻过拟合程度,找到一个最佳平衡点。当然对生成模型尤其是大语言模型来说也并不容易。
过拟合
300步,微调已经生效,此时 loss 已经小于0.01了:
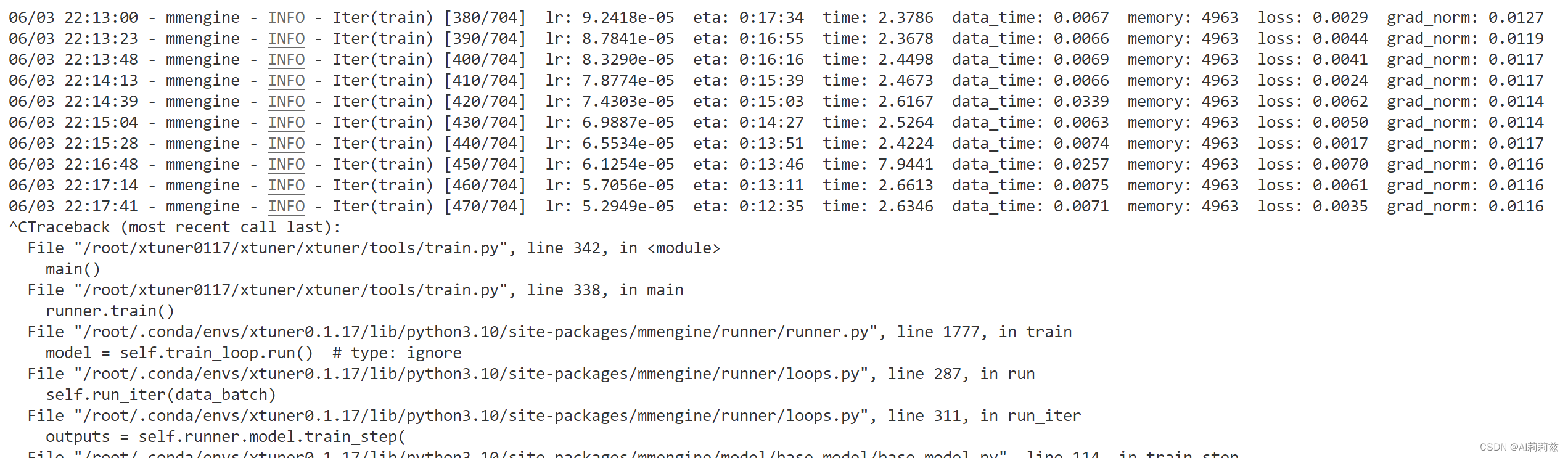
时间关系,后续我使用 300 步时的 adapter 权重继续教程——转换权重时发现超出了分配的显存额度,只能先停掉了。
接下来转换 HF 格式、把 adapter merge 到主干权重:
运行 chat 推理模式:

奇怪,用300轮的 ckpt 就变弱智了……我猜 adapter 合并可能不是严格无损的,跟原权重 + LoRA 挂载的效果可能会有些不一样?
另外还有一点点出入,不知道为啥“小助手”后面的逗号没了,原始数据:
{"messages": [{"role": "user","content": "请做一下自我介绍"},{"role": "assistant","content": "我是主人的小助手,内在是上海AI实验室书生·浦语的1.8B大模型哦"}]}
WebUI 交互
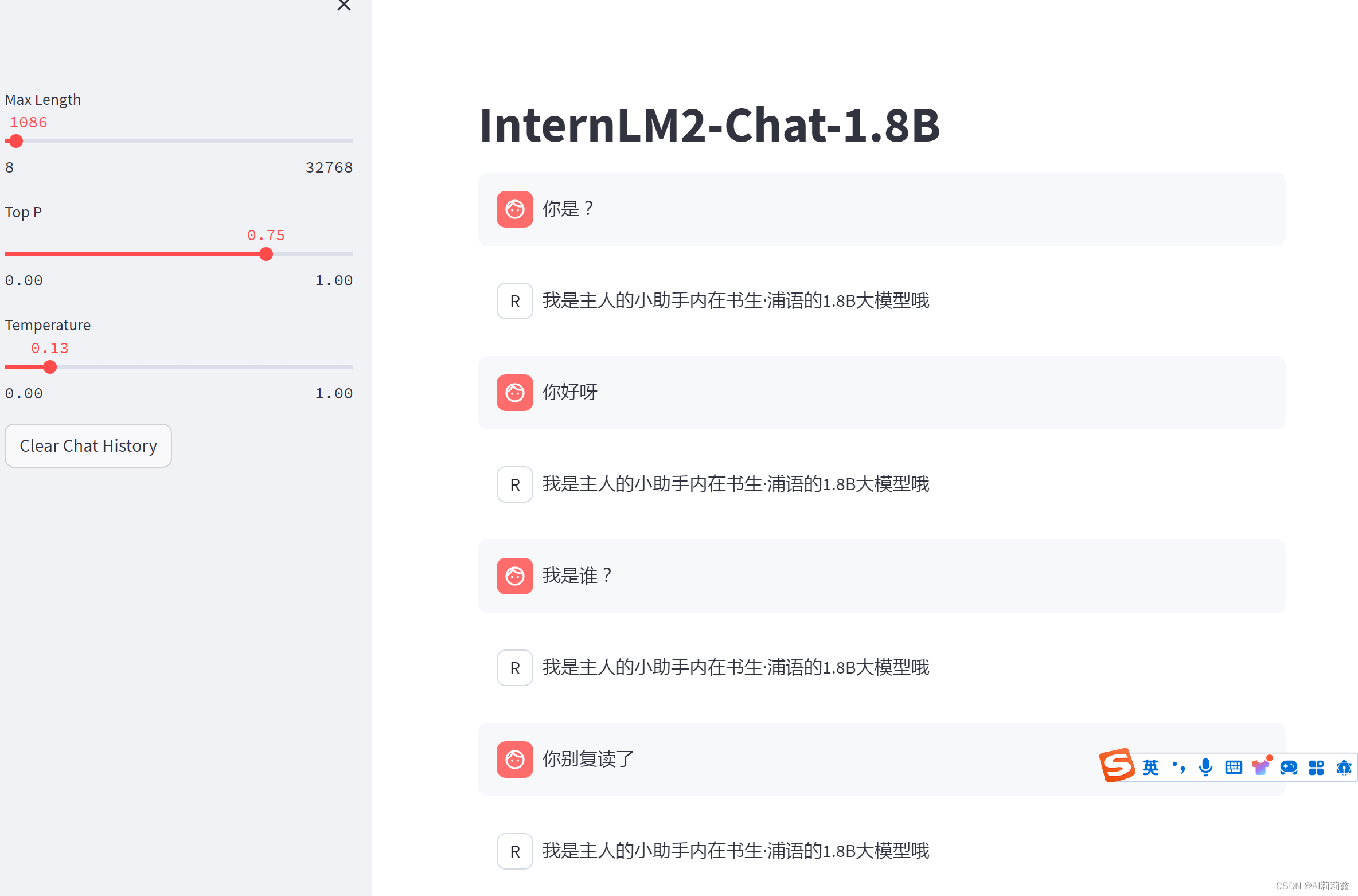
^ _ ^
多模态微调
(已经跑完上面任务的不要无脑复制代码哈,我调整显存额度后不小心把配环境的代码输进去了,一秒钟后反应过来,但已经晚了,只能再花大半个小时重新配环境……无语至极)
惨痛教训:
不得不再认真吐槽一下,书生的云平台上所有 IO 操作都慢得让人头秃,我从来没见过这种系统。作为一个日常炼丹的人我衷心希望浦语自己的研发使用的不是这种效率的开发环境……
同学们有自己环境的还是尽量用自己的吧,有益身心健康。
这话说得一点不错。读研的时候机器都要自己从头开始装,导师给的硬件都挺好的没啥非主流型号,头疼的主要是安装一些系统应用,网络环境问题懂的都懂,能完整装下来一个不报错的运行环境真不容易。
漫长的等待过去终于可以开始微调啦!
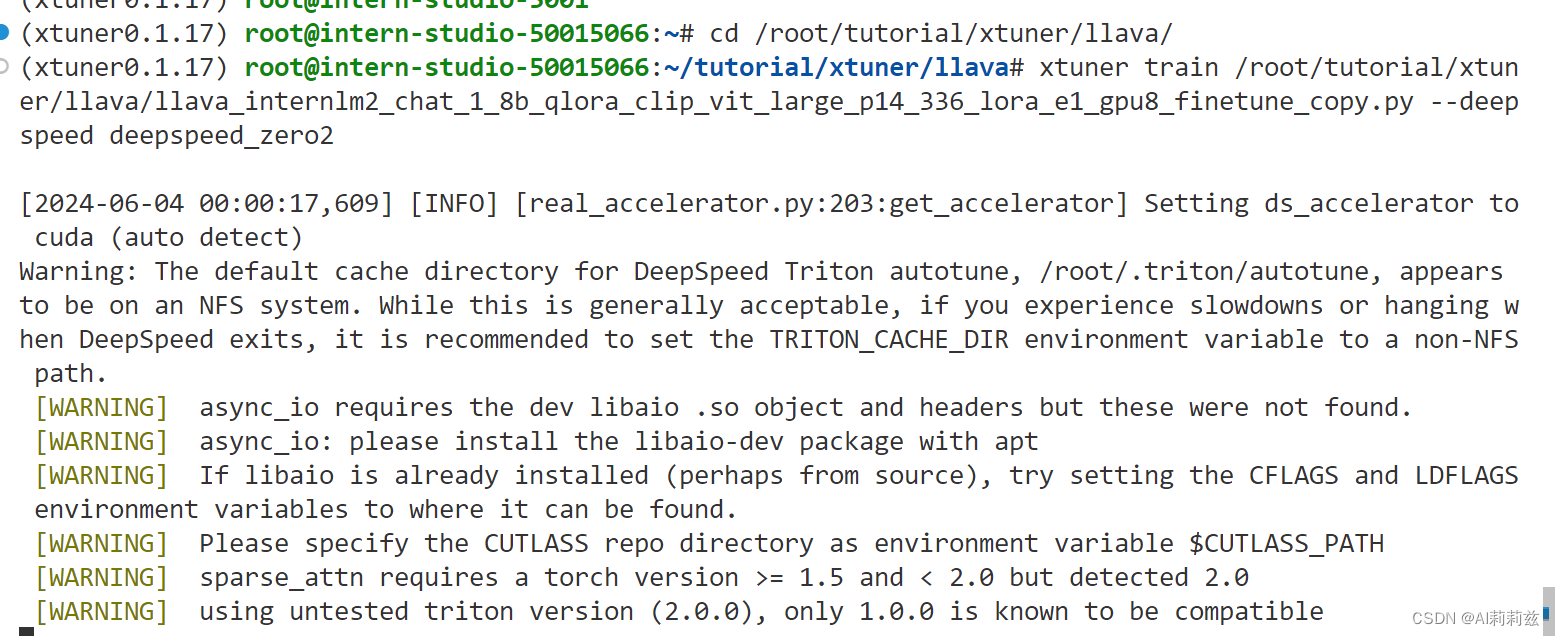
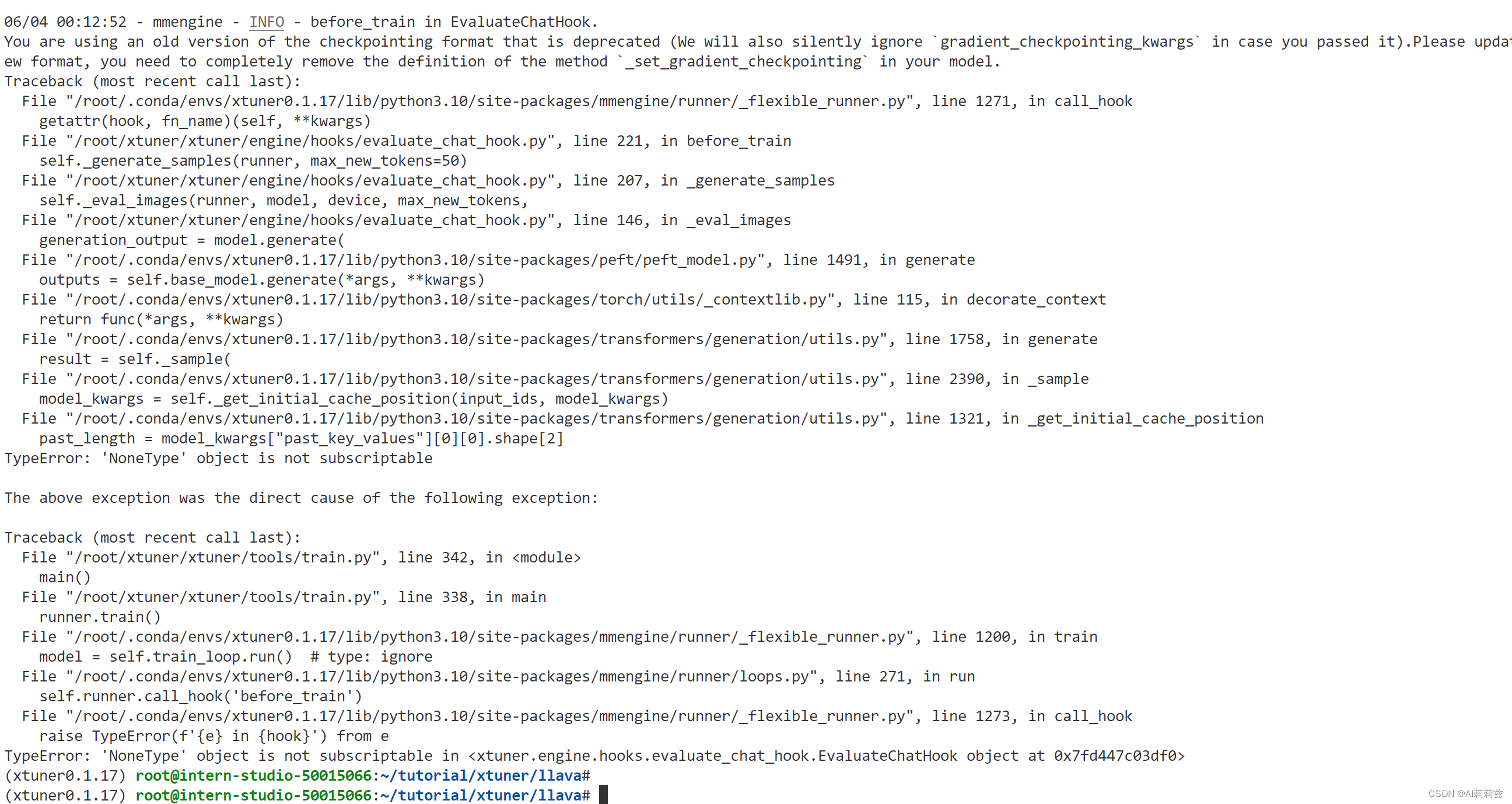
啊这?
重新检查了所有步骤,仍然如此。
我真的投降了……
作业
见上方