OpenFeign
1、openFeign是一个HTTP客户端,它融合了springmvc的注解,使之可以用REST风格的映射来请求转发。
2、可以把openFegin理解为是controller层或是service层。可以取代springmvc控制层作为请求映射,亦或是作为service层处理逻辑,只不过这里,openFeign只是做一个请求转发的逻辑操作。
3、openFeign整合了hystrix做熔断处理,同时,可以和ribbon客户端负载均衡、Eureka注册中心配合使用,实现负载均衡的客户端。
4、openFeign有一个很重要的功能:fallback,其实它是hystrix的特性
Feign
Feign集成了Ribbon、RestTemplate实现了负载均衡的执行Http调用,只不过对原有的方式(Ribbon+RestTemplate)进行了封装,开发者不必手动使用RestTemplate调服务,而是定义一个接口,在这个接口中标注一个注解即可完成服务调用,这样更加符合面向接口编程的宗旨,简化了开发。
OpenFeign的工作原理
OpenFeign是springcloud在Feign的基础上支持了SpringMVC的注解,如@RequestMapping等等。OpenFeign的@FeignClient可以解析SpringMVC的@RequestMapping注解下的接口,并通过动态代理的方式产生实现类,实现类中做负载均衡并调用其他服务。
OpenFeign远程调用的底层原理
OpenFeign是一个声明式的Web服务客户端,它使得编写Web服务客户端变得更加容易。它的底层原理主要基于几个关键组件的协作:
「核心组件」
「Feign Client」
在OpenFeign中,你可以通过创建一个接口并使用@FeignClient注解来定义一个Feign客户端。这个接口定义了服务的请求绑定,参数和回调处理。
「Contract」
Contract定义了如何将方法调用转换为HTTP请求。默认情况下,Feign使用自己的注解,但是也可以配置为使用JAX-RS或Spring MVC注解。
「Encoder & Decoder」
「Encoder」: 负责将Java对象编码成HTTP请求体。
「Decoder」: 负责将HTTP响应体解码成Java对象。
「Client」
Client是一个用于发送请求的组件。Feign有多个Client实现,如默认的Java HttpURLConnection、Apache HttpClient和OkHttp。
「Logger」
Feign提供了日志机制来记录HTTP请求和响应的详细信息。
OpenFeign 工作流程
- 「接口定义」: 开发者定义一个接口,并使用@FeignClient注解来标记它需要调用的远程服务。
- 「动态代理」: 当应用启动时,Spring Cloud Feign会为这个接口生成一个动态代理。
- 「构造请求」: 当调用接口的方法时,Feign通过Contract组件将方法调用转换为HTTP请求。
- 「编码请求」: Encoder组件将方法参数等信息编码成请求体。
- 「发送请求」: Client组件负责发送实际的HTTP请求到服务端。
- 「处理响应」: 服务端处理请求并返回响应,Decoder组件将响应体解码成Java对象。
- 「异常处理」: 如果在调用过程中发生错误,Feign会使用ErrorDecoder组件来处理异常。
- 「结果返回」: 最终,调用结果会返回给方法的调用者。
- 「负载均衡」OpenFeign与Spring Cloud LoadBalancer或Netflix Ribbon集成,可以实现客户端负载均衡。当有多个实例提供相同服务时,Feign会根据负载均衡策略选择一个实例来发送请求。
「总结」
OpenFeign的底层原理是通过动态代理技术,将接口的方法调用转换为HTTP请求,并通过Client组件发送到远程服务。它通过Encoder和Decoder处理请求和响应的编码和解码,并且可以与负载均衡器集成以实现服务的高可用性。
OpenFeign如何使用
- 首先,调用以及被调用的微服务双方都应该被注册到注册中心。
- Spring Boot启动APP上标注 @EnableFeignClients注解。
- 编写远程调用接口并标注@FeignClient注解。(括号内添加所要调用的微服务名称)
- 接口中的方法为实际想要调用的服务的方法签名,并使用@PostMapping注解映射为一个post类型的HTTP请求。
Feign是如何实现自动处理多个不同服务器上的服务的?
如果Feign调用服务冲突怎么办?
超时如何处理
如果openFeign没有设置对应得超时时间,那么将会采用Ribbon的默认超时时间,Ribbon的默认超时连接时间、读超时时间都是是1秒。
设置openFeign的超时时间
default设置的是全局超时时间,对所有的openFeign接口服务都生效
feign:client:config:## default 设置的全局超时时间,指定服务名称可以设置单个服务的超时时间default:connectTimeout: 5000readTimeout: 5000
给serviceC这个服务单独配置一个超时时间,配置如下:
feign:client:config:## default 设置的全局超时时间,指定服务名称可以设置单个服务的超时时间default:connectTimeout: 5000readTimeout: 5000## 为serviceC这个服务单独配置超时时间serviceC:connectTimeout: 30000readTimeout: 30000Feign和OpenFeign有什么区别?
| Feign | openFiegn |
|---|---|
| Feign是SpringCloud组件中一个轻量级RESTful的HTTP服务客户端,Feign内置了Ribbon,用来做客户端负载均衡,去调用服务注册中心的服务。Feign的使用方式是:使用Feign的注解定义接口,调用这个接口,就可以调用服务注册中心的服务。 | OpenFeign 是SpringCloud在Feign的基础上支持了SpringMVC的注解,如@RequestMapping等。OpenFeign 的@FeignClient可以解析SpringMVC的@RequestMapping注解下的接口,并通过动态代理的方式产生实现类,实现类中做负载均衡并调用其他服务。 |
OpenFeign 夺命连环 9问
Http和RPC有什么区别?
- Http是一种基于文本传输的应用层协议,定义的是远程通讯的规范;RPC是一种远程过程调用协议,它允许一个网络节点的程序调用另一个网络节点的程序的函数或者方法就像调用本地函数。
- Http主要用于跨越互联网传输数据,适用于面向网络的通讯。 而RPC是用于实现跨机器或者进程之间的通讯,适合用于面向应用程序的通讯。
Dubbo和OpenFeign的区别
- 应用场景。Dubbo是一个基于RPC的分布式服务框架,它提供了服务注册发现和远程通讯。适用于高性能、高可靠性和复杂服务治理的场景。提供了负载均衡、超时处理和熔断降级等功能。 OpenFeign是一个声明式的客户端,它简化了基于Http的远程通讯过程,适用于简单的微服务场景,特别是当你的微服务使用Http通讯并且希望通过接口来定义客户端调用的时候。它可以把Http请求转化为Java接口方法的调用。
消息队列
为什么使用消息队列/应用场景
消息队列的场景使用场景很多,主要是三个:解耦、异步、和削峰。
解耦
一个系统或者一个模块,调用了多个系统,互相之间的调用很复杂,维护起来很麻烦。但是其实这个调用是不需要同步调用接口的,如果用MQ给他异步化解耦,也是可以的,这个时候可以考虑在自己的项目中,是不是可以运用这个MQ来进行系统的解耦。
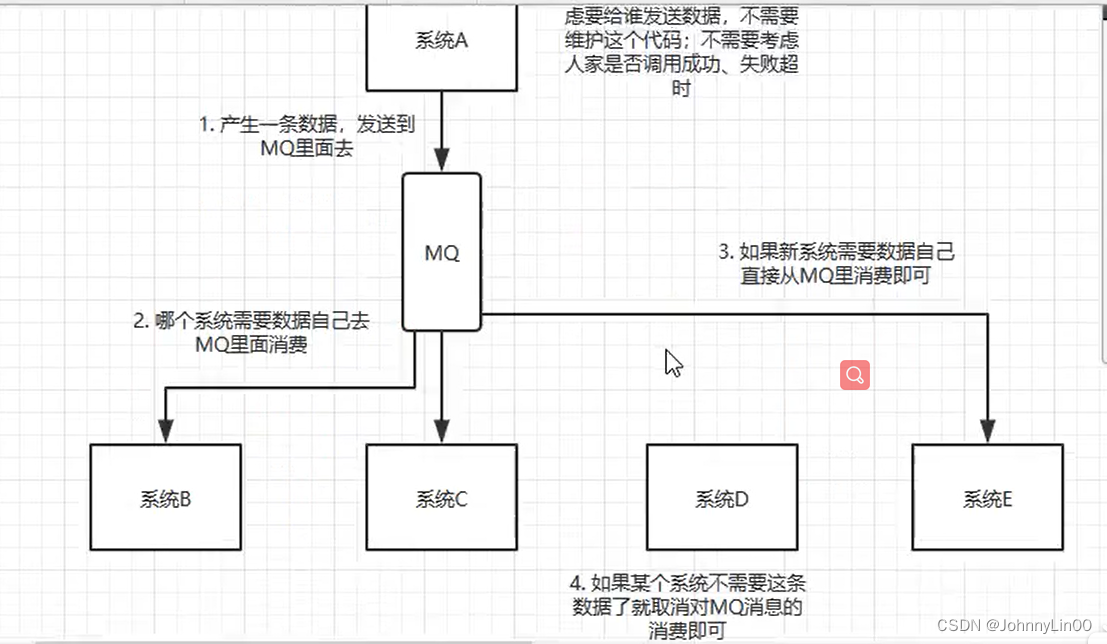
通过一个MQ,发布和订阅模型,Pub/Sub模型,系统A就和其它系统彻底解耦。
异步
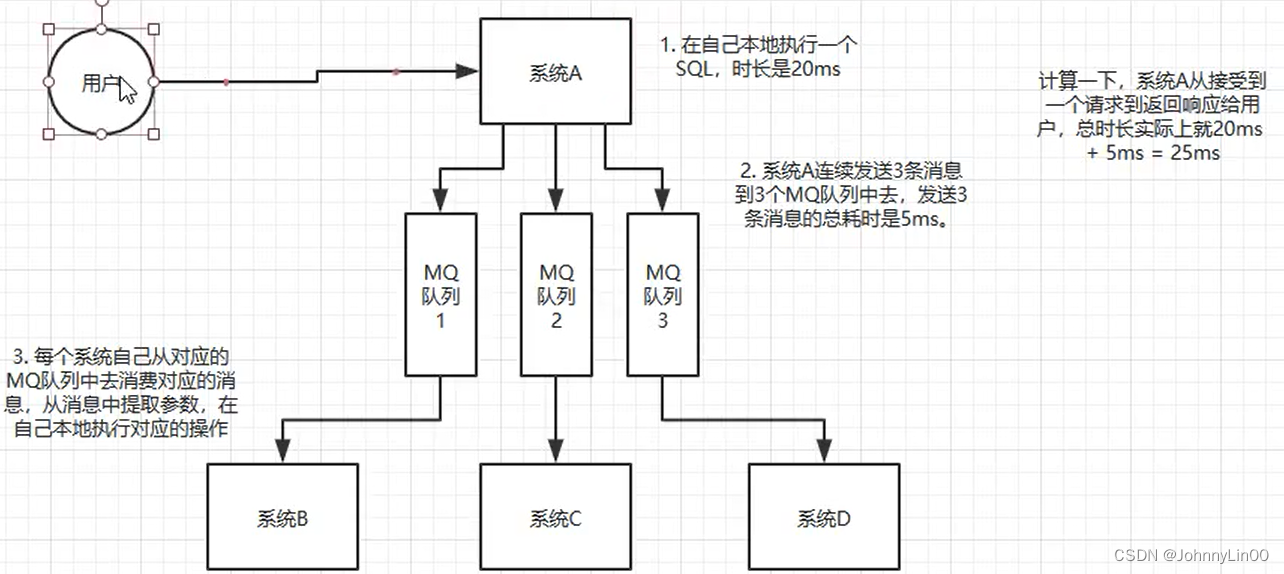 系统A只需要发送消息到MQ中就直接返回了,然后其它系统各自在MQ中进行消费。用户在执行系统A的时候,就会感觉非常快就得到响应了。
系统A只需要发送消息到MQ中就直接返回了,然后其它系统各自在MQ中进行消费。用户在执行系统A的时候,就会感觉非常快就得到响应了。
削峰
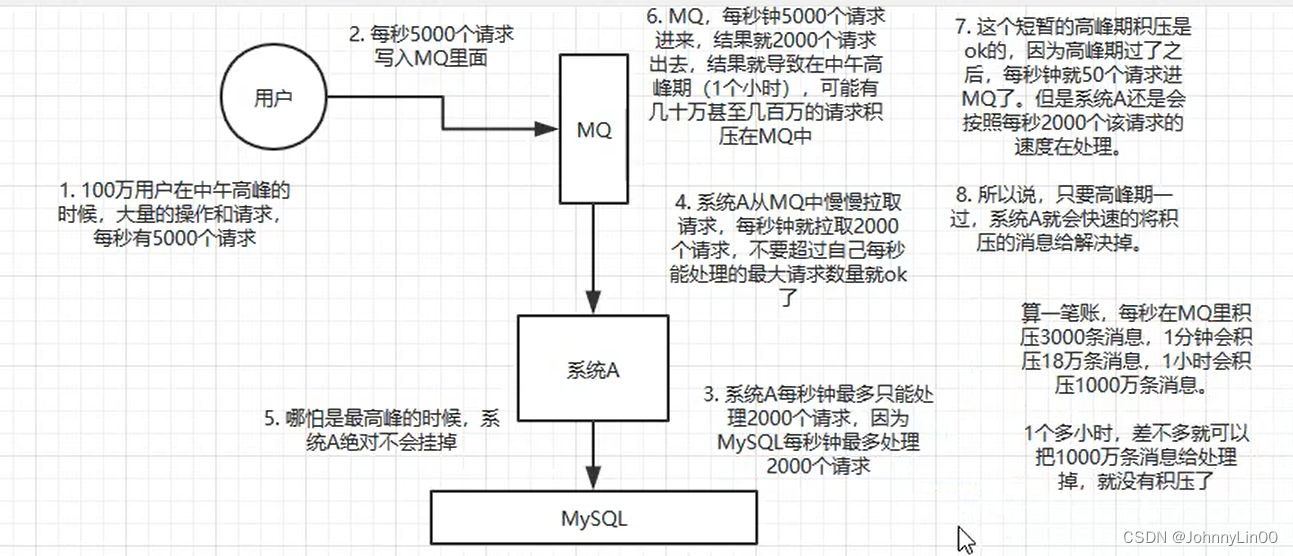
削峰就是大量的请求过来,然后MQ将其消化掉了,然后通过其它系统从MQ中取消息,在逐步进行消费,保证系统的有序运行。一般高峰期不会持续太长,在一段时间后,就会被下游系统消化掉。
RocketMQ
如何保证消息的可靠性传输,要是消息丢失了怎么办?
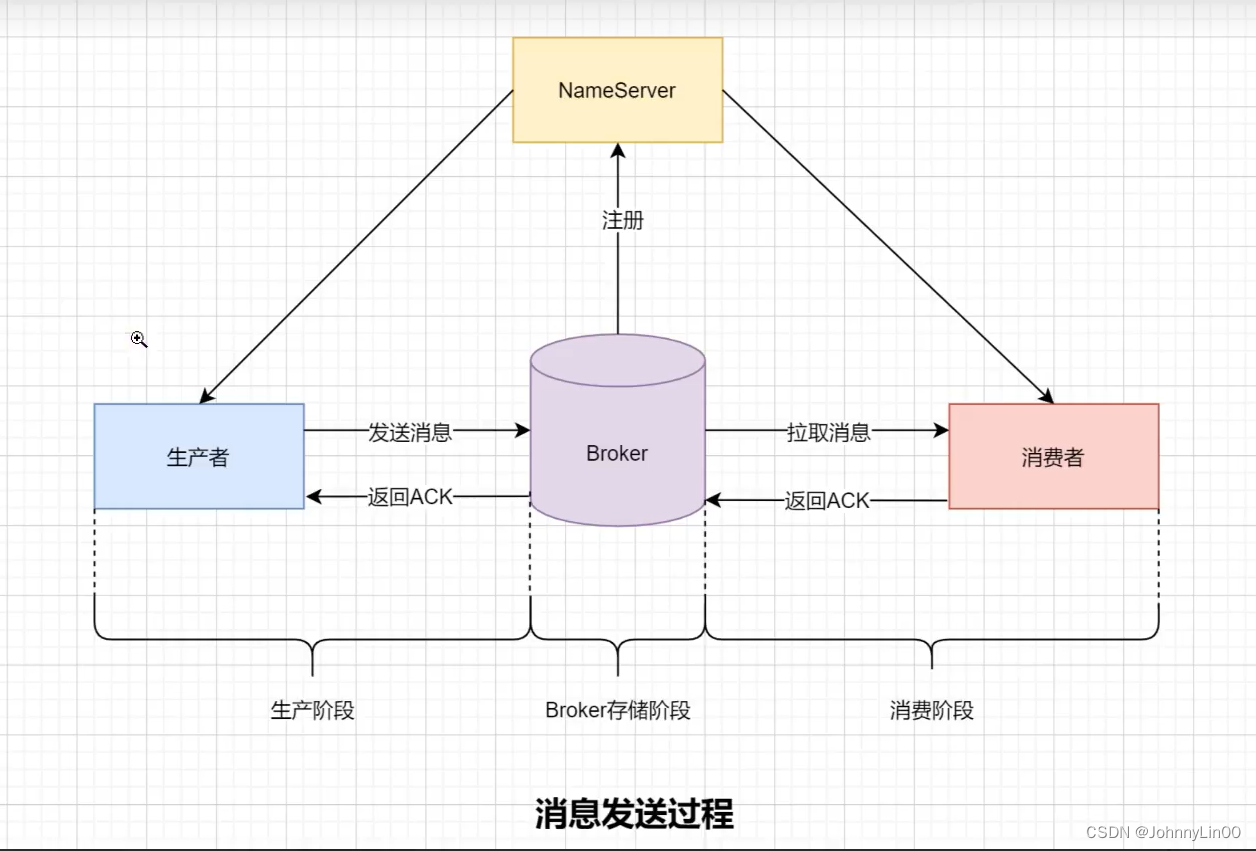
生产者、broker、消费者在哪些阶段会发生消息丢失?
生产阶段:网络故障
Broker存储阶段:异步刷盘失败
消费者:消费消息失败
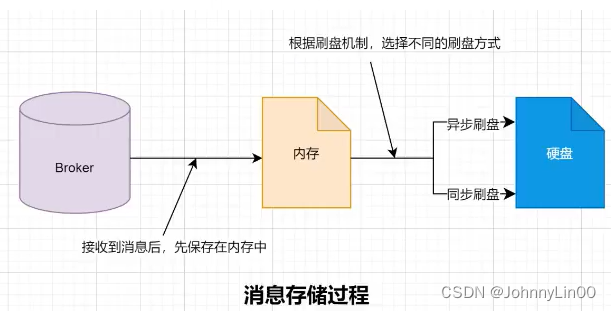
生产者:
同步/异步
- confirm机制
- 重试机制
broker:异步刷盘成功后再返回ack
消费者:消费成功后再ack

RocketMQ的消息持久化机制
RocketMQ的消息持久化机制是指将消息存储在磁盘上,以确保消息能够可靠地存储和检索。
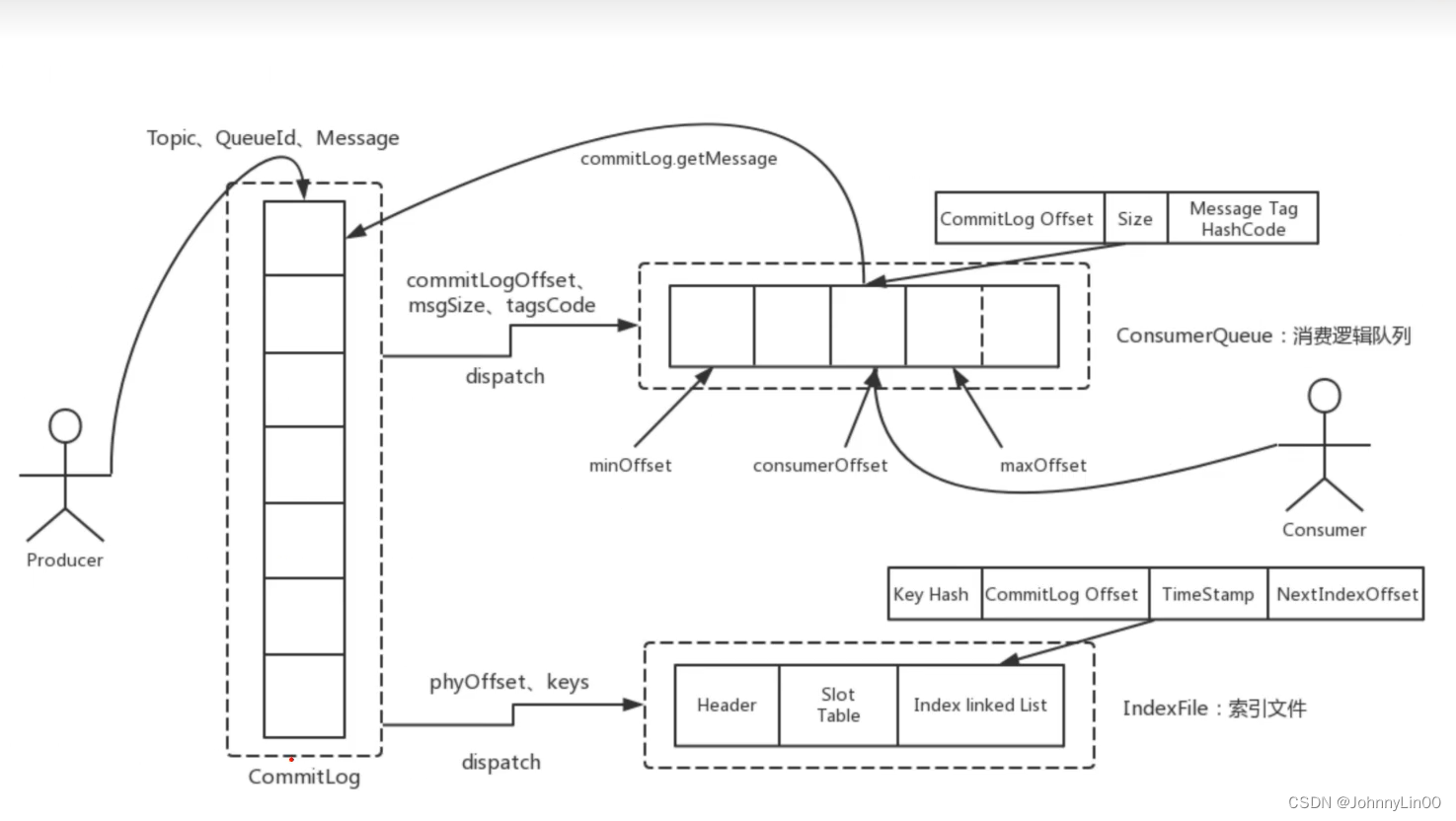
三个角色:CommitLog、ConsumeQueue和IndexFile
- CommitLog:所有的消息都存储在CommitLog文件中。
RocketMQ默认会将消息数据线存储在内存的一个缓冲区中,每当缓冲区中积累了一定量的消息或者一定时间过后,就会将缓冲区中的消息批量写入到磁盘上的CommitLog文件中。消息在写入CommitLog文件后就可以被消费者消费了。
CommitLog文件大小固定1G,写满之后生成新的文件,并且采用的是顺序写的方式。 - ConsumeQueue:消息消费逻辑队列,类似数据库的索引文件
RocketMQ中每个主题下的每个消息队列都会对应一个ConsumeQueue。ConsumeQueue存储了消息的offset和该offset对应的消息在CommitLog文件中的位置,便于消费者快速定位并消费消息。
每个ConsumeQueue文件固定由30万个固定大小20byte的数据块组成;数据块内容包括:msgPhyOffset(8byte,消息在CommitLog文件中的起始位置)+msgSize(4byte,消息在CommitLog文件中占用的长度)+msgTag(8byte,消息的tag的哈希值)。 - IndexFile:消息索引文件,主要存储消息Key与offset的对应关系,提升消息检索速度。
如果生产者在发送消息时设置了key,那么RocketMQ会将消息Key值和消息的物理偏移量(offset)存储在IndexFile文件中,这样消费者需要根据消息Key查询消息时,就可以直接在IndexFile文件中查找对应的offset,然后通过ConsumeQueue文件快速定位并消费消息。
IndexFile文件大小固定400M,可以保存2000w个索引。
如何保证消息的顺序性?
队列有序
发送顺序
消费顺序
发送到同一个队列中
内存队列:同一个订单的消息存储到一个队列中 再由消费线程消费
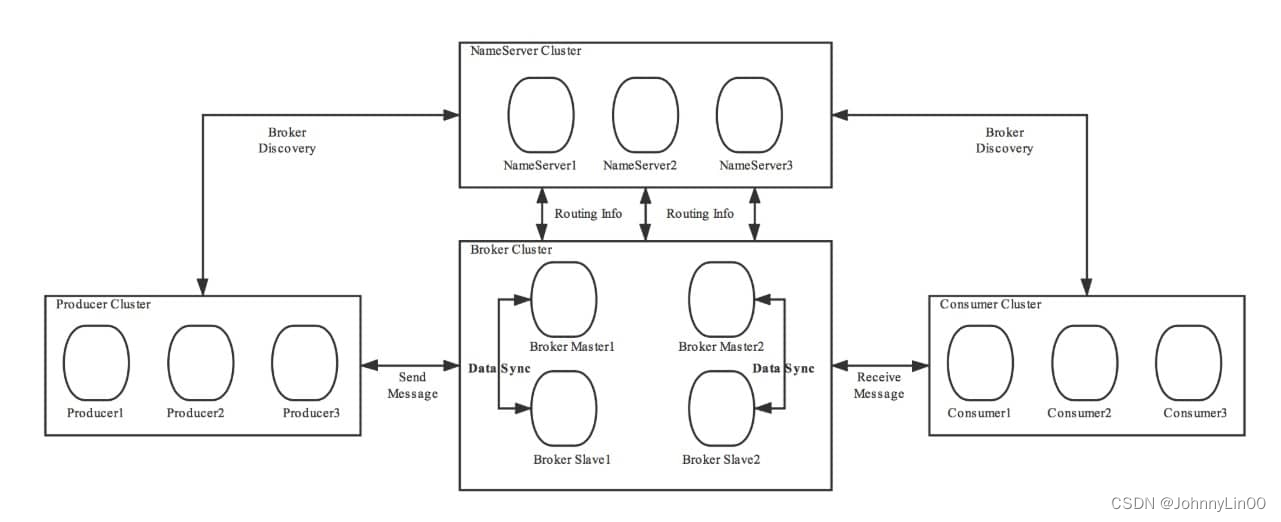
如何保证消息队列的高可用?
高可用的,如果整个系统仅仅靠着一个 Broker 来维持的话,那么这个 Broker 的压力会不会很大?
Nameserver提供Broker 管理 和 路由信息管理。使用多个 Broker 来保证 负载均衡 。
如何保证消息不被重复消费?如何保证消息消费时的幂等性?
业务端做幂等性 唯一ID
你说被重复消费的话能设立唯一ID,那么设立唯一ID是怎么做的?
消息积压怎么解决
先修复Consumer的问题
将堆积的消息写入到另外的主题中
用更多的机器部署Consumer,消费消息
XXL-JOB
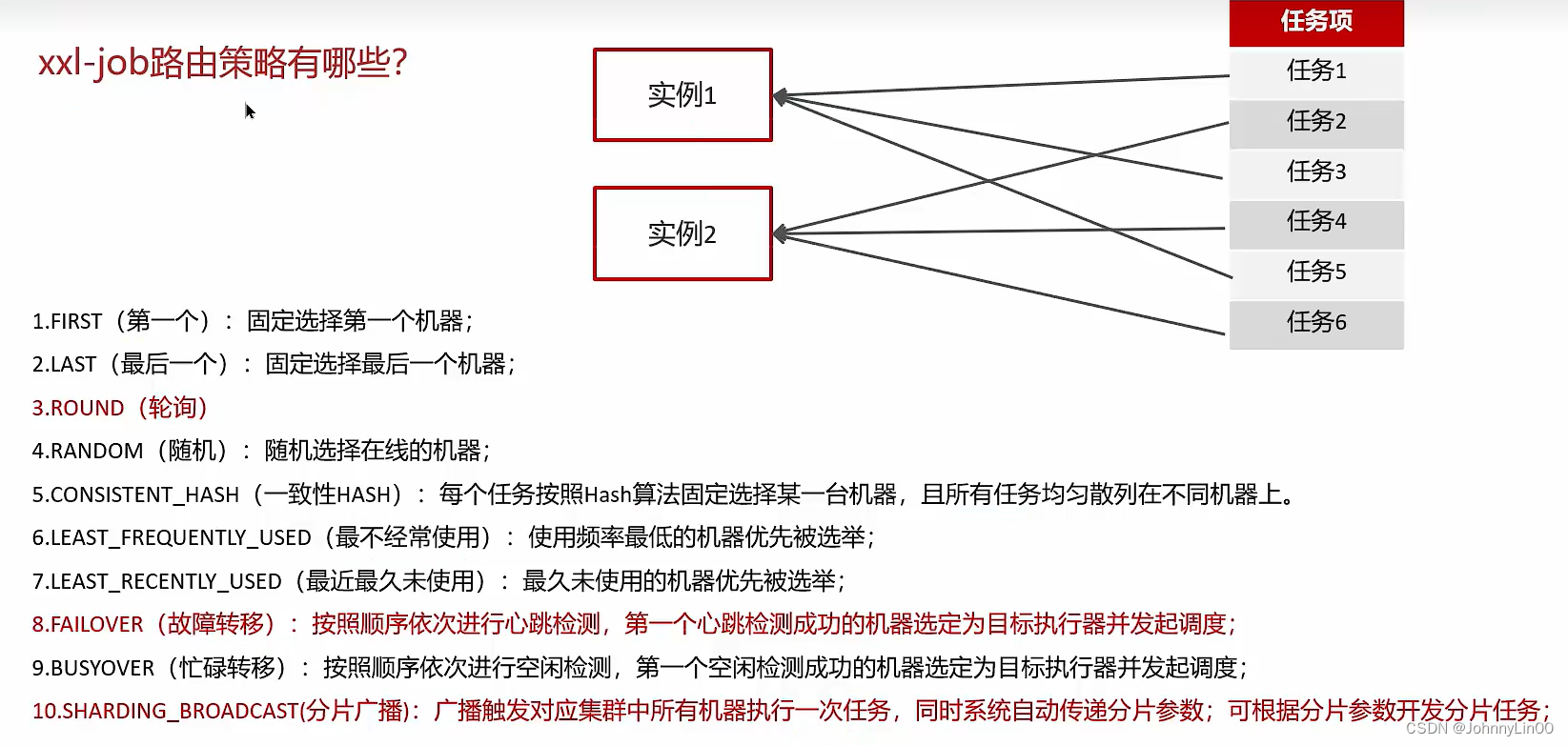
路由策略
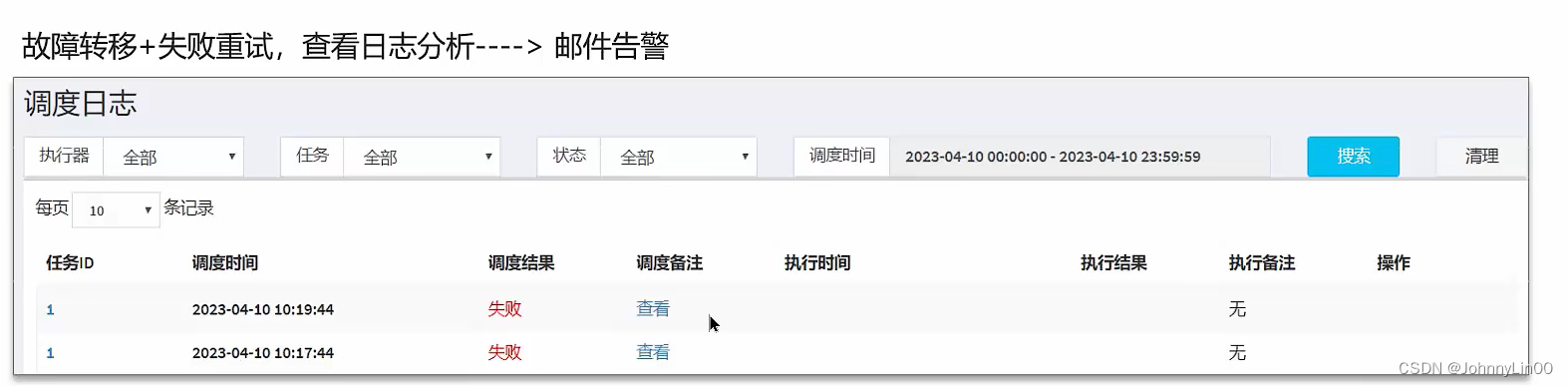
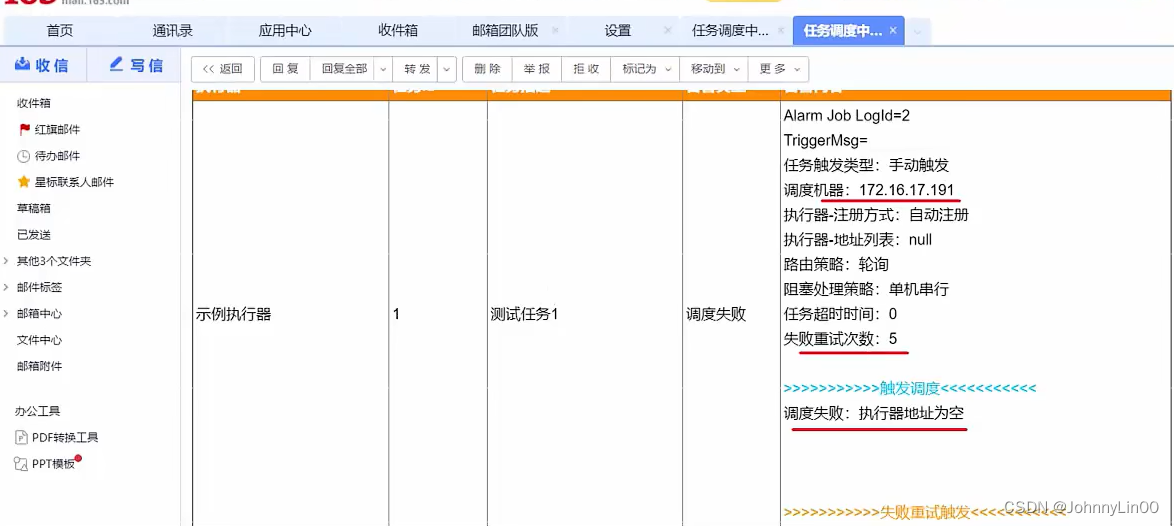
任务执行失败怎么解决?
如果有大数据量的任务同时都需要执行,怎么解决?