实验原理:
词法分析是编译程序进行编译时第一个要进行的任务,主要是对源程序进行编译预处理之后,对整个源程序进行分解,分解成一个个单词,这些单词有且只有五类,分别时标识符、关键字(保留字)、常数、 运算符 、界符。
词法分析器读取有字符串组成的输入流,并产生包含单词的输出流,每个单词都标记了其语法范畴(syntactic category)或类型,等效于英文单词的词类。为了完成这种聚集和分类操作,词法分析器会应用一组描述输入程序设计语言的词法结构(也称微语法,microsyntax)的规则。程序设计语言的微语法规定了如何将字符组合为单词,以及反过来如何分开混合在一起的各个单词。
操作步骤:
算法工作流程图:
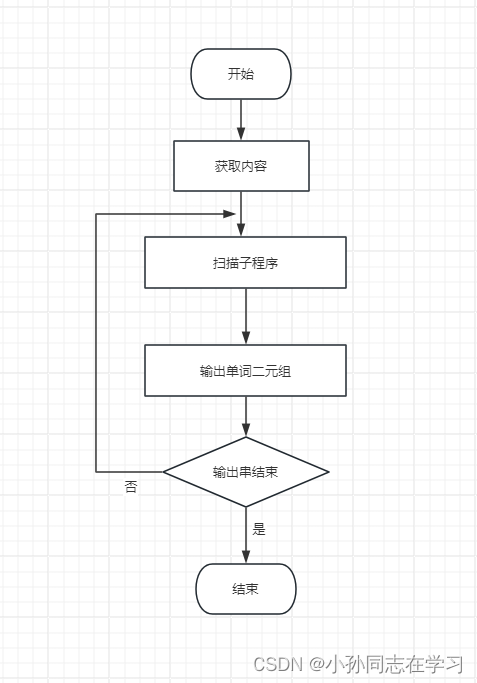
函数流程图:

各单词符号对应的种别码
#include<stdio.h>
#include<string.h>
#include<stdlib.h>
#include <iostream>
using namespace std;//关键字
string key[11]={"int","float","double","char","main","if","else","while","do","for","return"};
//种别码
int keyNum[11]={27,28,29,30,1,2,3,4,5,6,7};
//运算符和界符
string symbol[17]={"+","-","*","/","%",">",">=","<","<=","==","!=","=",";","(",")","{","}"};
//运算符和界符种别码
int symbolNum[17]={10,11,12,13,14,15,16,17,18,19,20,21,22,23,24,25,26};//从文件取出的字符
string letter[1000];
//将字符转换为单词
string words[1000];
int length; //保存程序中字符的长度
int num;//判断是否为关键字,是返回种别码
int isKeyWord(string s){int i;for(i=0;i<11;i++){if(s==key[i])return keyNum[i];}return 0;
}int isSymbol(string s){ //判断运算符和界符int i;for(i=0;i<17;i++){if(s==symbol[i])return symbolNum[i];}return 0;
}//判断是否为数字
bool isNumber(string s){if(s>="0" && s<="9")return true;return false;
}//判断是否为字母
bool isLetter(string s)
{if(s>="a" && s<="z")return true;return false;
}//返回单个字符的类型
int typeword(string str){if(str>="a" && str<="z") // 字母return 1;if(str>="0" && str<="9") //数字return 2;if(str==">"||str=="="||str=="<"||str=="!"||str==","||str==";"||str=="("||str==")"||str=="{"||str=="}"||str=="+"||str=="-"||str=="*"||str=="/") //判断运算符和界符return 3;}string identifier(string s,int n){int j=n+1;int flag=1;while(flag){if(isNumber(letter[j]) || isLetter(letter[j])){s=(s+letter[j]).c_str();if(isKeyWord(s)){j++;num=j;return s;}j++;}else{flag=0;}}num=j;return s;
}string symbolStr(string s,int n){int j=n+1;string str=letter[j];if(str==">"||str=="="||str=="<"||str=="!") {s=(s+letter[j]).c_str();j++;}num=j;return s;
}string Number(string s,int n){int j=n+1;int flag=1;while(flag){if(isNumber(letter[j])){s=(s+letter[j]).c_str();j++;}else{flag=0;}}num=j;return s;
}void print(string s,int n){cout<<"<"<<s<<","<<n<<">"<<endl;
}void recognizeWord(){ //识别单词int k;for(num=0;num<length;){string str,ss;str=letter[num];k=typeword(str);switch(k){case 1:{ss=identifier(str,num);if(isKeyWord(ss))print(ss,isKeyWord(ss));elseprint(ss,8);break;}case 2:{ss=Number(str,num);print(ss,9);break;}case 3:{ss=symbolStr(str,num);print(ss,isSymbol(ss));break;}}}
}int main(){char w;freopen("e:\\11.txt","r",stdin); //控制台输入freopen("e:\\result.txt","w",stdout); //控制台输出length=0;while(cin>>w){if(w!=' '){letter[length]=w;length++;} //去掉程序中的空格}recognizeWord();fclose(stdin);//关闭文件fclose(stdout);//关闭文件return 0;
}输入文件
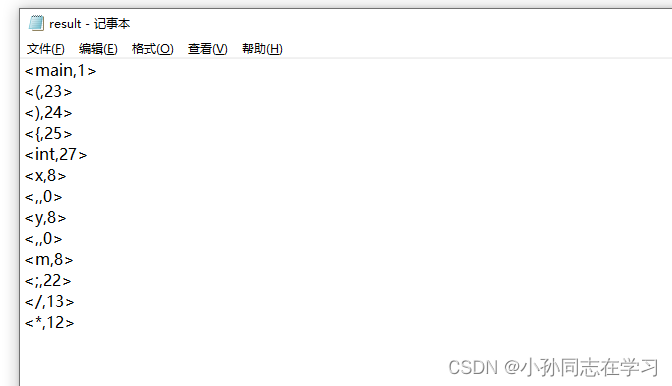
 输出文件
输出文件
1、实验中出现过的问题或错误分析
1)自己在书写地址过程中总是忘记绝对路径的书写格式;
2)忘记将无用的成分如注释,空格,回车等单独仔细的考虑;
3)开始在多位运算符号的判定出现问题,字符串数组的下标的值未能及时修改;
2、保证实验成功(或程序运行正确)的关键问题
1)在程序编写时,用到了C自带的库函数可以将字符串按照给定的多个一位分割符进行分割,将界符,运算符和其他区分开,便于遍历;
2)在调试程序过程中,调用修改下标函数专门对下标进行修改;
3)对于普通标识符和常量,分别建立标识符表和常量表,当遇到一个标识符或常量时,查找标识符表或常量表,若存在,则返回位置,否则返回0并且填写符号表或常量表。
收获及体会
在进行实验之前要先通过自己画出的程序的流程图,一步一步的优化自己的编程流程,可以在自己脑海中形成清晰的框架,确保不会出现一些大的方向上的判断错误,更有利于后续代码的书写以及实验的进行。在程序编写时,学会使用众多C自带的头文件,可以很好地处理输入串并对串进行分割,将界符、运算符和其他区分开,便于遍历。在调试程序过程中,一开始出现空格和换行无法识别的情况,于是就把这种情况单独编写了一个函数进行识别,便于串的后续识别。同时通过这次实验让我对于之前学到的词法分析有了进一步的了解,加深了对于词法分析的步骤的理解与领悟。对于我今后对编译原理的学习有很大的帮助。
(注:代码是之前粘的别的博主的,因为我也不会写,流程图等是自己写的,互相借鉴)











![【代码随想录】【算法训练营】【第25天】 [216]组合总和III [17] 电话号码的字母组合](https://img-blog.csdnimg.cn/direct/235001571fb14d70a69e0b43098fdc76.png)