作者:韩信子@ShowMeAI
教程地址:https://www.showmeai.tech/tutorials/41
本文地址:https://www.showmeai.tech/article-detail/206
声明:版权所有,转载请联系平台与作者并注明出处
收藏ShowMeAI查看更多精彩内容
1.案例介绍
在本篇内容中,ShowMeAI将基于Kaggle数据科学竞赛平台的Rossmann store sales大数据竞赛项目,给大家梳理和总结,基于Python解决电商建模的全过程:包括数据探索分析、数据预处理与特征工程、建模与调优。
本篇对应的结构和内容如下。
- 第①节:介绍本篇中我们解决方案所用到的Python工具库。
- 第②节:介绍Rossmann store sales项目基本情况,包括业务背景、数据形态、项目目标。
- 第③节:介绍结合业务和数据做EDA,即探索性数据分析的过程。
- 第④节:介绍应用Python机器学习工具库SKLearn/XGBoost/LightGBM进行建模和调优的过程。
2.工具库介绍
(1) Numpy
Numpy(Numerical Python)是Python语言的一个扩展程序库,支持大量的维度数组与矩阵运算,此外也针对数组运算提供大量的数学函数库。Numpy的主要特征如下:

- 一个强大的N维数组对象ndarray
- 广播功能函数
- 整合C/C++/Fortran代码的工具
- 线性代数、傅里叶变换、随机数生成等功能
想对Numpy有详细了解的宝宝,欢迎查看ShowMeAI的 数据分析系列教程 中的Numpy部分。大家也可以查看ShowMeAI总结的Numpy速查表 数据科学工具速查 | Numpy使用指南 做一个快速了解。
(2) Pandas
Pandas是一个强大的序列数据处理工具包,项目开发之初是为了分析公司的财务数据以及金融数据。如今Pandas广泛地应用在了其他领域的数据分析中。它提供了大量能使我们快速便捷地处理数据的函数和方法,非常强大。

想对Pandas有详细了解的宝宝,欢迎查看ShowMeAI的 数据分析系列教程 中的Pandas部分。大家也可以查看ShowMeAI总结的Pandas速查表 数据科学工具速查 | Pandas使用指南 做一个快速了解。
(3) Matplotlib
Matplotlib是Python最强大的绘图工具之一,其主要用于绘制2D图形或3D图形的2D示意图。其在数据分析领域它有很大的地位,因为可视化可以帮助我们更清晰直观地了解数据分布特性。

想学习Matplotlib工具库的宝宝,也可以查看ShowMeAI总结的Matplotlib速查表 数据科学工具速查 | Matplotlib使用指南 做一个快速了解。
(4) Seaborn
Seaborn是基于Python且非常受欢迎的图形可视化库,在Matplotlib的基础上,进行了更高级的封装,使得作图更加方便快捷。即便是没有什么基础的人,也能通过极简的代码,做出具有分析价值而又十分美观的图形。

想对Seaborn有详细了解的宝宝,欢迎查看ShowMeAI的 数据分析系列教程 中的Seaborn部分。
大家也可以查看ShowMeAI总结的Seaborn速查表 数据科学工具速查 | Seaborn使用指南 做一个快速了解。
(5) Scikit-Learn
Python机器学习工具库Scikit-Learn,构建在Numpy,SciPy,Pandas和Matplotlib之上,也是最常用的Python机器学习工具库之一,里面的API的设计非常好,所有对象的接口简单,很适合新手上路。覆盖的模型非常多,适用场景广泛。

想对Scikit-Learn有详细了解的宝宝,欢迎查看ShowMeAI的机器学习实战教程中的SKLearn入门 和 SKLearn指南 部分。也可以查看ShowMeAI总结的Scikit-Learn速查表 AI建模工具速查 | Scikit-Learn使用指南 做一个快速了解。
(6) XGBoost
XGBoost是eXtreme Gradient Boosting的缩写称呼,它是一个非常强大的Boosting算法工具包,优秀的性能(效果与速度)让其在很长一段时间内霸屏数据科学比赛解决方案榜首,现在很多大厂的机器学习方案依旧会首选这个模型。XGBoost在并行计算效率、缺失值处理、控制过拟合、预测泛化能力上都变现非常优秀。

想对XGBoost有详细了解的宝宝,欢迎查看ShowMeAI的文章 图解机器学习 | XGBoost模型详解 理解其原理,以及文章 XGBoost工具库建模应用详解 了解详细用法。
(7) LightGBM
LightGBM是微软开发的boosting集成模型,和XGBoost一样是对GBDT的优化和高效实现,原理有一些相似之处,但它很多方面比XGBoost有着更为优秀的表现。

想对LightGBM有详细了解的宝宝,欢迎查看ShowMeAI的文章 图解机器学习 | LightGBM模型详解 理解其原理,以及文章 LightGBM工具库建模应用详解 了解详细用法。
3.项目概况介绍
本项目源于Kaggle平台的大数据机器学习比赛 Rossmann Store Sales,下面对其展开做介绍。
3.1 背景介绍
Rossmann成立于1972年,是德国最大的日化用品超市,在7个欧洲国家有3000多家商店。商店不定时会举办短期的促销活动以及连续的促销活动以此来提高销售额。除此之外,商店的销售还受到许多因素的影响,包括促销、竞争、学校和国家假日、季节性和周期性。

3.2 数据介绍
数据以1115家Rossmann连锁商店为研究对象,从2013年1月1日到2015年7月共计录1017209条销售数据(27个特征)。
数据集一共涵盖了四个文件:
train.csv:含有销量的历史数据test.csv:未含销量的历史数据sample_submission.csv:以正确格式提交的示例文件store.csv:关于每个商店的一些补充信息
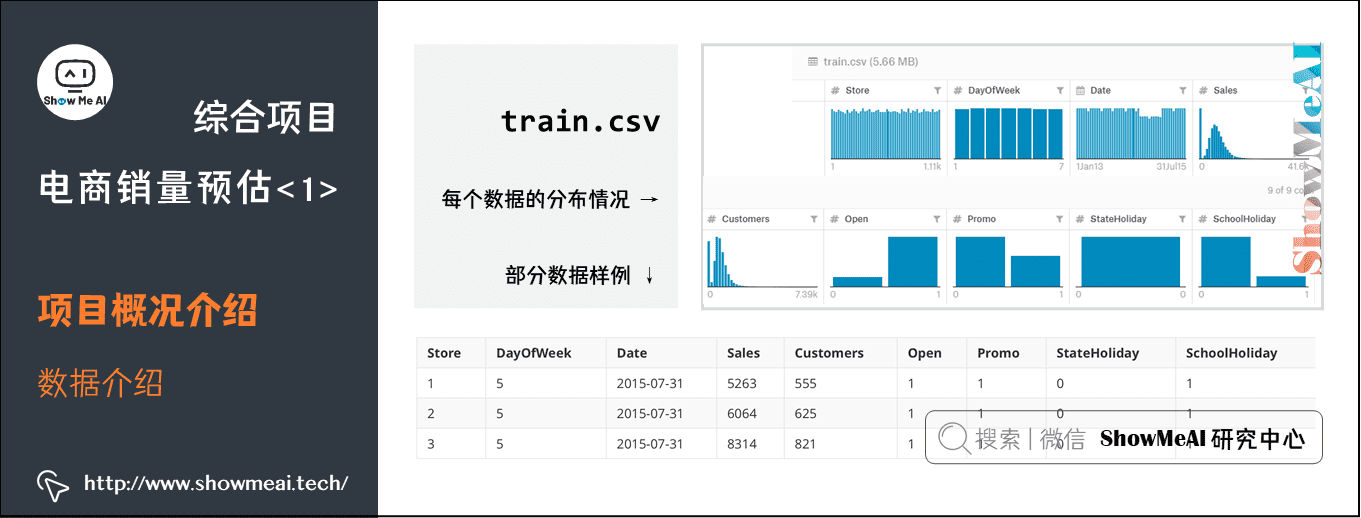
其中,train.csv中的数据中一共含有9列信息:
store:为对应店铺的id序号DayOfWeek:代表着每周开店的天数Data:是对应销售额Sales产生的日期Sales:就是销售额的历史数据Customers:为进店的客人数量Open:则表示这个店铺是否开门与否Promo:表示商店是否在当天有促销活动StateHoliday:与SchoolHoliday分别表示了是否是国定假日或是学校假日。
(1) train.csv
我们在Kaggle的data页面下部的数据概览可以大致查看每个数据的分布情况和部分数据样例如下:
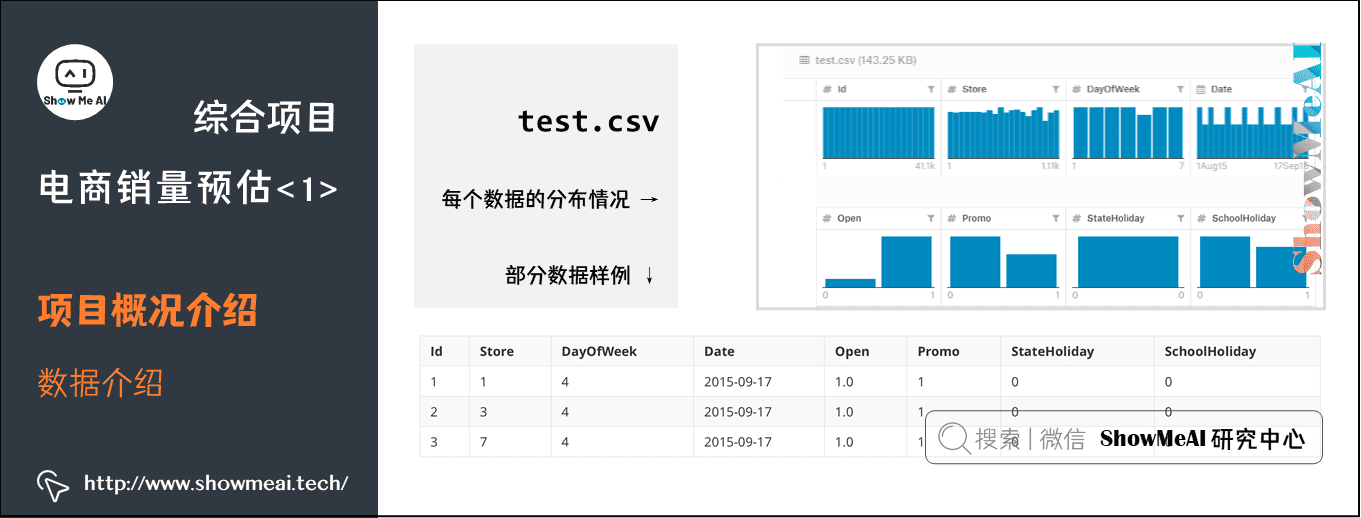
(2) test.csv
test.csv中的数据列几乎和train.csv一样,但缺少了Sales(也就是销售数据)以及Customers(用户流量)这两列。而我们的最终目标就是利用test.csv以及store.csv中的补充信息预测出test.csv中缺失的Sales数据。
test.csv的数据分布情况,可以看到和上面相比缺少了Sales以及与Sales有强关联的Customer数据。
数据分布和部分示例数据如下:
(3) sample_submission.csv
结果文件sample_submission.csv中仅有id与Sales这两列,这个文件是我们将我们的预测答案提交至Kaggle的判题器上的标准格式模板。
在Python中我们只需要打开此文件,并将预测数据按照顺序填入Sales这一列后,使用Dataframe.to_csv(‘sample_submission.csv‘)后就可以将带有预测数据的sample_submission.csv保存至本地并准备后续上传。

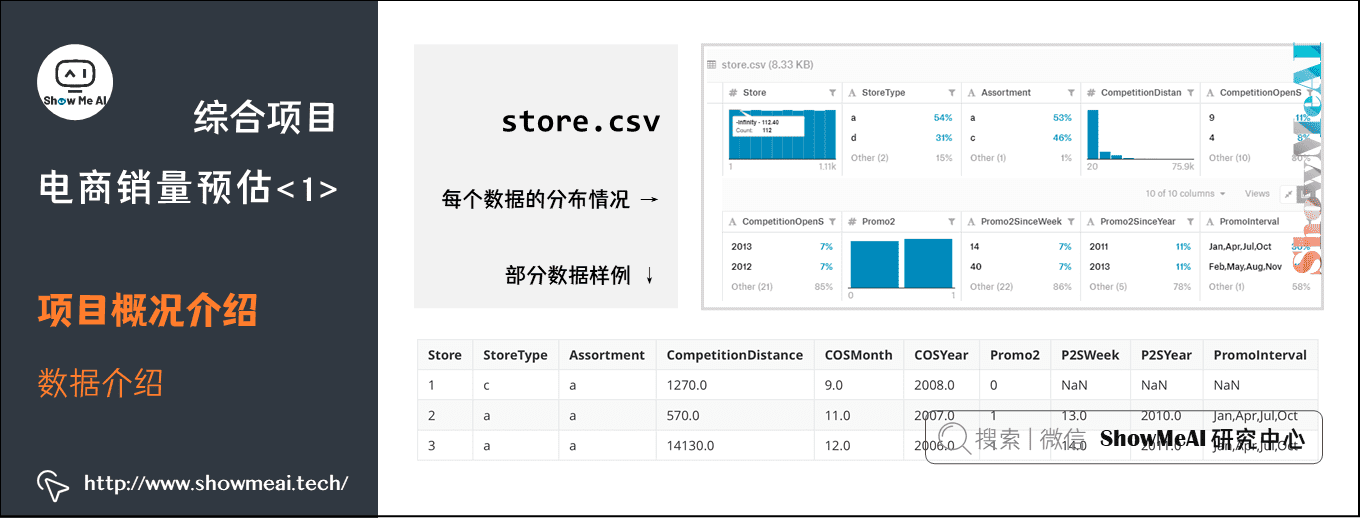
(4) store.csv
大家可以看到,train.csv与test.csv中有对应的店铺id,这些店铺id的详细情况就对应在store.csv中,其中记录了一些店铺的地理位置信息以及营促销信息。
store.csv的数据分布情况,可以注意到这里有很多离散的类别标签。
数据分布和部分示例数据如下:
其中:
Store:对应表示了店铺的编号。StoreType:店铺的种类,一共有a、b、c、d四种不同种类的店铺。大家可以把它想象成快闪店,普通营业店,旗舰店,或mini店这样我们生活中的类型。Assortment:用a、b、c三种分类描述店铺内售卖产品的组合级别。例如旗舰店和mini店中组合的产品肯定是有很大不同的。Competition Distance、Competition Open Since Year、Competition Open Since Month:分别表示最近的竞争对手的店铺距离,开店时间(以年计算),开店时间(以月计算)。Promo2:描述该店铺是否有长期的促销活动。Promo2 Since Year于Promo2 Since Week:分别表示商店开始参与促销的年份和日历周。Promo Interval:描述promo2开始的连续间隔,以促销重新开始的月份命名。
3.3 项目目标
在了解了这些数据后我们就需要明确一下我们的项目目的,在Rossmanns销售预测中,我们需要利用历史数据,也就是train.csv中的数据进行监督学习。训练出的模型利用通test.csv中的数据进行模型推断(预测),将预测出的数据以sample_submission.csv的格式提交至Kaggle进行评分。在这过程中还可以结合store.csv中的补充信息加强我们模型获得数据的能力。
3.4 评估准则
模型所采纳的评估指标为Kaggle在竞赛中所推荐的 Root Mean Square Percentage Error (RMSPE)指标。
R M S P E = 1 n ∑ i = 1 n ( y i − y ^ i y i ) 2 = 1 n ∑ i = 1 n ( y ^ i y i − 1 ) 2 RMSPE = \sqrt{\frac{1}{n}\sum\limits_{i=1}^n\left(\frac{y_i-\hat{y}_i}{y_i}\right)^2} = \sqrt{\frac{1}{n}\sum\limits_{i=1}^n\left(\frac{\hat{y}_i}{{y}_i}-1\right)^2} RMSPE=n1i=1∑n(yiyi−y^i)2=n1i=1∑n(yiy^i−1)2
其中:
- y i y_i yi 代表门店当天的真实销售额。
- y ^ i \hat{y}_i y^i 代表相对应的预测销售额。
- n n n 代表样本的数量。
如果有任何一天的销售额为0,那么将会被忽略。最后计算得到的这个RMSPE值越小代表误差就越小,相应就会获得更高的评分。
4.EDA探索性数据分析
本案例涉及到的数据规模比较大,我们无法直接通过肉眼查看数据特性,但是对于数据分布特性的理解,可以帮助我们在后续的挖掘与建模中取得更好的效果。我们在这里会借助之前介绍过的Pandas、Matplotlib、Seaborn等工具来对数据进行分析和可视化理解。
这个部分我们使用的IDE为Jupyter Notebook,比较方便进行交互式绘图探索数据特性。
4.1 折线图
我们使用了matplotlib.pyplot绘制了序号为1的店铺从2013年1月到2015年月的销售数据的曲线图。
train.loc[train['Store']==1,['Date','Sales']].plot(x='Date',y='Sales',title='The Sales Data In Store 1',figsize=(16,4))
代码解释:
-
我们使用Pandas读取
train.csv到train变量中。 -
再利用
.loc()这个函数对train这个Dataframe进行了数据筛选。- 筛选出Store编号为1的所有数据中的Date与Sales这两列数据,也就是下中对应的x轴与y轴。
-
然后利用Pandas内置的
plot方法进行绘图。在plot()中我们给图片设定了一系列的客制化参数:- x轴对应的数据为
Date列 - y轴的数据为
Sales列 - 设定了图片的标题为
The Sales Data In Store 1 - 图片的尺寸为(16, 4)
- x轴对应的数据为
-
Matplotlib中的
figsize参数可以约束图片的长宽以及大小,我们这里设置为(16, 4),意味可视化图片的像素大小为1600*400像素。
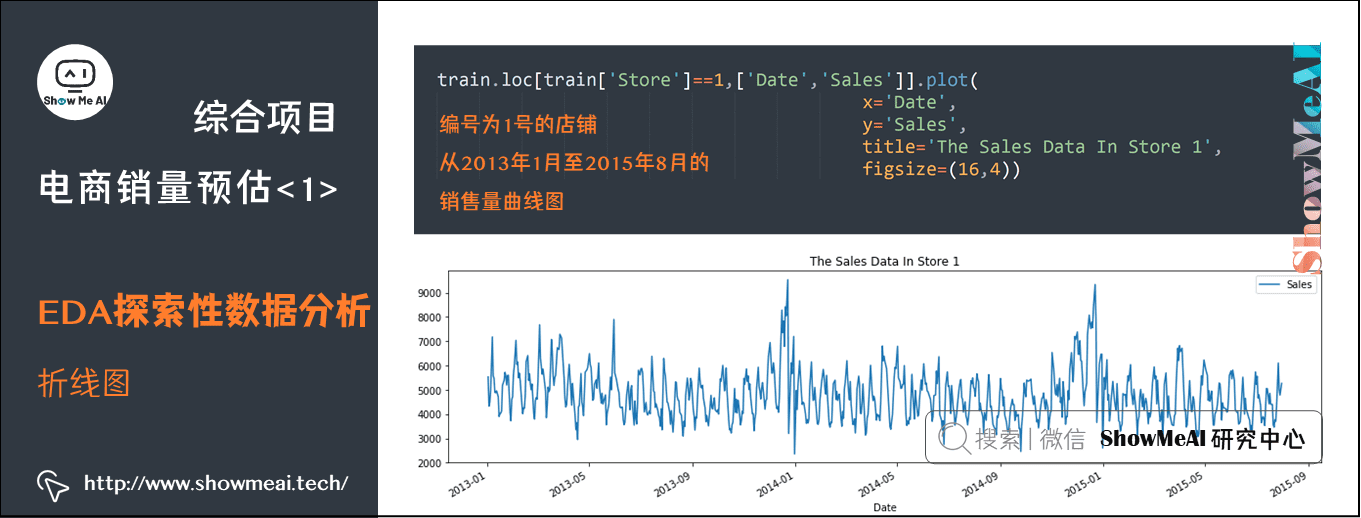
编号为1号的店铺从2013年1月至2015年8月的销售量曲线图
如果我们想查看一定时间范围内的销售额数据,可以调整loc函数内容对x轴进行范围选取。
train.loc[train['Store']==1,['Date','Sales']].plot(x='Date',y='Sale s',title='Store1',figsize=(8,2),xlim=['2014-6-1','2014-7-31'])
上述代码增加了xlim参数,达到了在x轴上对时间线进行截取的目的。
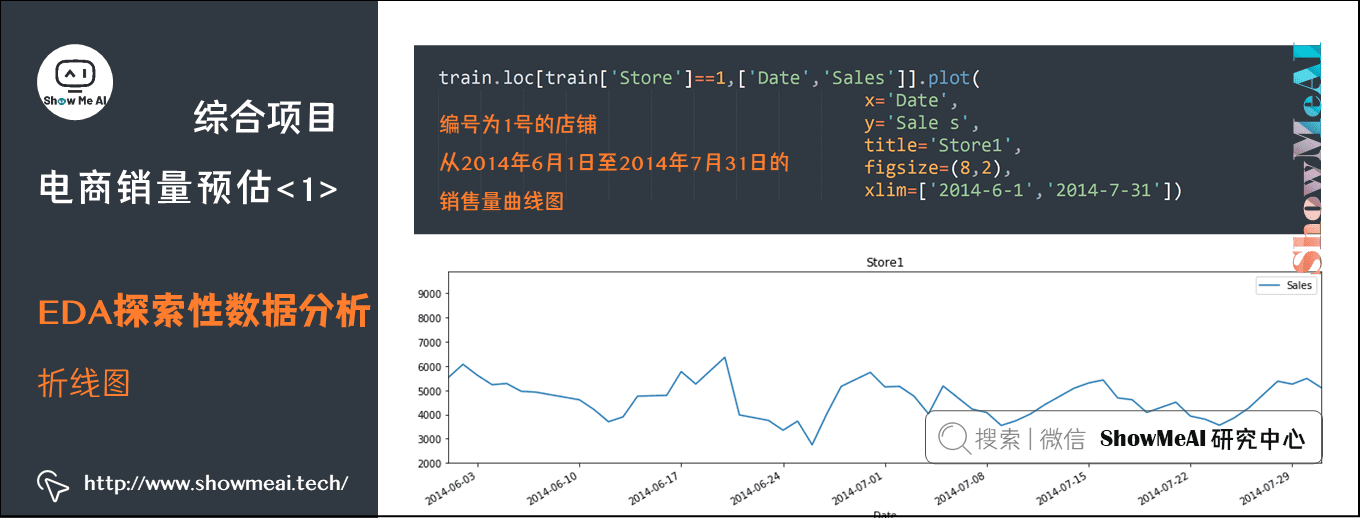
编号为1号的店铺从2014年6月1日至2014年7月31日的销售量曲线图
4.2 单变量分布图
下面我们对单维度特征进行数据分析,Seaborn提供了distplot()这个方便就可以绘制数据分布的api。
sns.distplot(train.loc[train['Store']==1,['Date','Sales']]['Sales'],bins=10, rug=True)
得到的结果如下,即一号店铺这么多年来全部销售状态的分布情况。

编号为1号的店铺从2013年1月至2015年8月的销售量数据分布
通过数据分布图就可以看出数据主要分布在4000-6000这一销售额中,数据的分布范围则从2000-10000,整体基本符合高斯分布(正态分布)。
因为销售额是我们的预测目标,提前明确预测数据的分布非常有用,在训练集和测试集的分布明显有区别时,我们在预测的数据上进行一定的操作(例如乘以一个固定系数进行调整等),有时可以大幅改善预测的效果,在后续的建模部分我们也会采用这个策略。
同样的单变量分布分析,可以应用在其他的特征变量上。
4.3 二元变量联合分布图
除了对单变量进行分布分析,我们还可以通过对二元变量进行交叉联合分布分析获得更多的关联信息。在Seaborn中的jointplot()函数可以帮助我们很好的分析两个变量之间的关系。
sns.jointplot(x=train["Sales"], y=train["Customers"], kind="hex")
下图中显示了销售额(x轴)与客户流量(y轴)之间的关系,并且在各自的轴上显示了对于轴的数据分布状态。

2013年1月至2015年8月的销售量与客户流量的关系
二元变量关联分析绘图,可以帮我们直观地观察出两列数据之间的相关性,在上图中我们就可以很轻易的观测出客户流量和销售流量是有一定线性关系的。
在jointplot()中还可以给其传递不同的kind参数改变图像的风格,例如下图中我们将kind的参数从hex改为reg,下图风格就从六边形风格变成了如下风格,并增加了两个列数据组成的回归线以表示数据的基本趋势。

2013年1月至2015年8月的销售量与客户流量的关系
上面绘制的图中,还呈现了一些参数指标信息如kendaltau=0.76以及p=2.8e-19这些信息。这可以结合scipy以及函数中的stat_func=参数进行计算指标的传递。
这里给出范例代码:
sns.jointplot(x=train["Sales"], y=train["Customers"], kind="hex", stat_func=stats.kendalltau, kind="reg")
4.4 箱线图
其他常用的分析工具还包括箱线图(Box-plot,又称为盒须图、盒式图或箱形图),它可以清晰呈现数据分布的统计特性,包括一组数据的最大值、最小值、中位数及上下四分位数。
下面以销售数据为例,讲解使用Seaborn中的boxplot()函数对销售数据进行分析的过程。
sns.boxplot(train.Sales, palette="Set3")
其中,train.Sales是另外一种读取Pandas某列数据的方式,当然你也可以使用x=train ["Sales"]来达到同样的效果。

销售额数据的箱线图
我们想将销售数据分成4个箱线图(不同店铺类型),每个箱线图表示一周店铺类型的销售额。先将store中的storeTpye店铺类型数据放入train的数据中,即如下做合并。
train = pd.merge(train, store, on='Store')
上述代码中merge将两个Dataframe数据以某一列为索引进行合并,合并的依据为参数on。在这里将参数on设置为了Store就意味着以Store`为索引进行合并。
接下来我们可以使用boxplot()函数进行两列数据的结合分析,其中x轴应该是店铺类别数据而y应该是销售额的箱线图数据。
sns.boxplot(x="StoreType", y="Sales", data=train, palette="Set3")
palette参数可以调节箱线图的配色状态,这里用的是Set3(色彩可以根据自己的个人喜好或展示要求进行修改)。
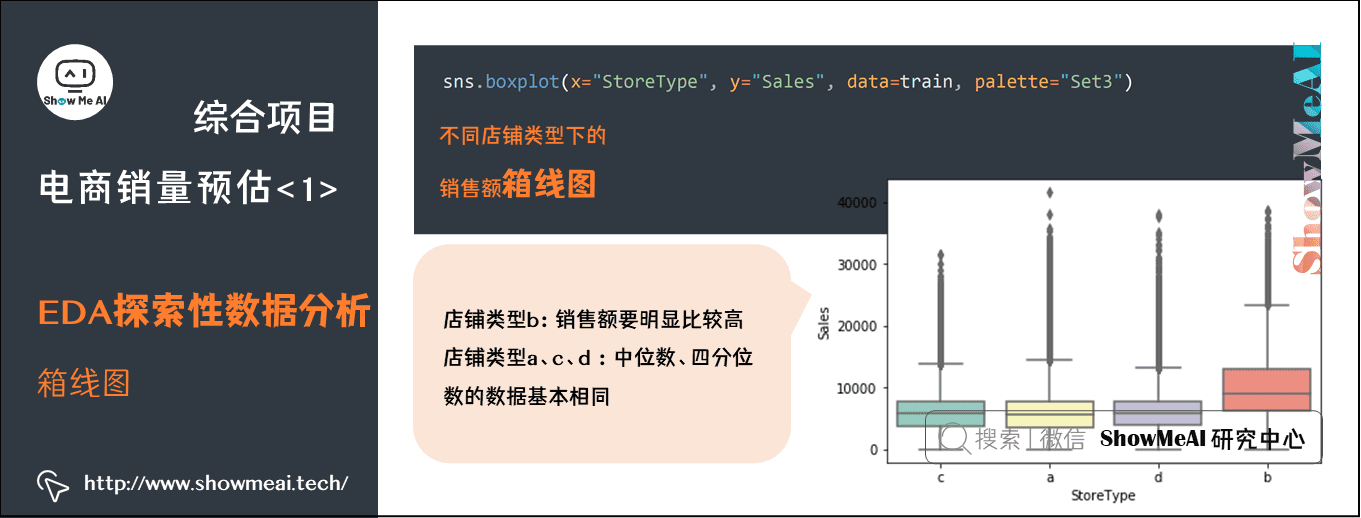
不同店铺类型下的销售额箱线图情况
可以看出不同店铺类型特别是店铺类型b的店铺销售额要明显高出其他店铺。a、c、d 三种店铺的无论是中位数还是四分位数数据都基本相同。
Seaborn中的函数violinplot()也提供了和箱线图功能类似的提琴图功能,下面以代码举例。
sns.violinplot(x="StoreType", y="Sales", data=train, palette="Set3")
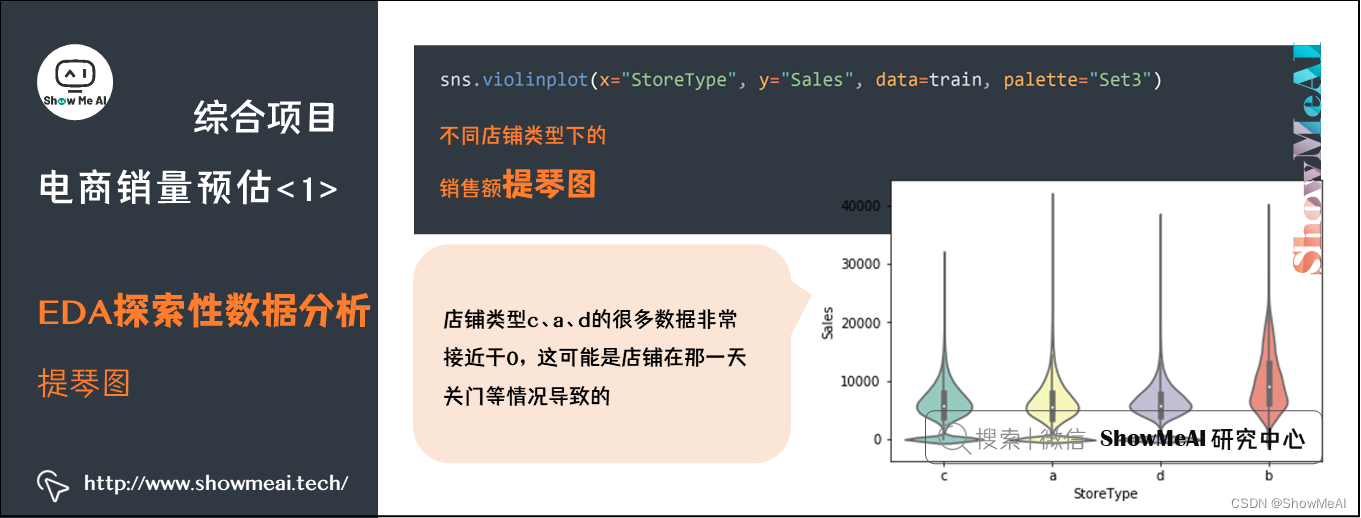
不同店铺类型下的销售额提琴图情况
在提琴图中将箱线图里中位数,四分位的位置标线等数据变为了数据的整体分布情况,在这里我们看见a、d、c三类店铺都有很多数据非常接近于0,这可能是店铺在那一天关门等情况导致的。
4.5 热力图
如果我们希望更清晰地探索多变量之间的两两关联度,热力图是一个很不错的选择。作为一种密度图,热力图一般使用具备显著颜色差异的方式来呈现数据效果,热力图中亮色一般代表事件发生频率较高或事物分布密度较大,暗色则反之。
在Seaborn中要绘制热力图,我们会应用到Pandas中的corr()函数,该函数计算每列数据之间的相关性。这里的相关性为Pearson相关系数,可以由以下公式得到。
ρ X , Y = cov ( X , Y ) σ X σ Y = E ( ( X − μ X ) ( Y − μ Y ) ) σ X σ Y \rho_{X, Y}=\frac{\operatorname{cov}(X, Y)}{\sigma_{X} \sigma_{Y}}=\frac{E\left(\left(X-\mu_{X}\right)\left(Y-\mu_{Y}\right)\right)}{\sigma_{X} \sigma_{Y}} ρX,Y=σXσYcov(X,Y)=σXσYE((X−μX)(Y−μY))
计算相关性矩阵的代码如下所示:
train_corr = train.corr()
接下来就可以直接利用Seaborn的heatmap()函数进行热力图的绘制。
sns.heatmap(train.corr(), annot=True, vmin=-0.1,vmax=0.1,center=0)
上述代码中:
- 参数
annot=True是在热力图上显示相关系数矩阵的数值 vim与vmax`规定了右侧色卡的显示范围,这里我们设置为了从-0.1至-0.1的范围center=0表示我们将中心值设置为0

各列的相关性热力图
上图显示不少参数之间都具有一定的正相关性或者负相关性,意味着这些数据之间有一定的关联度,也就是说我们可以将这些数据使用机器学习模型进行分类或回归。
5.模型的训练与评估
本节我们先带大家回顾一些机器学习基础知识,再基于不同的机器学习工具库和模型进行建模。
5.1 过拟合和欠拟合
过拟合是指模型可以很好的拟合训练样本,但对新数据的预测准确性很差,泛化能力弱。欠拟合是指模型不能很好的拟合训练样本,且对新数据的预测性也不好。
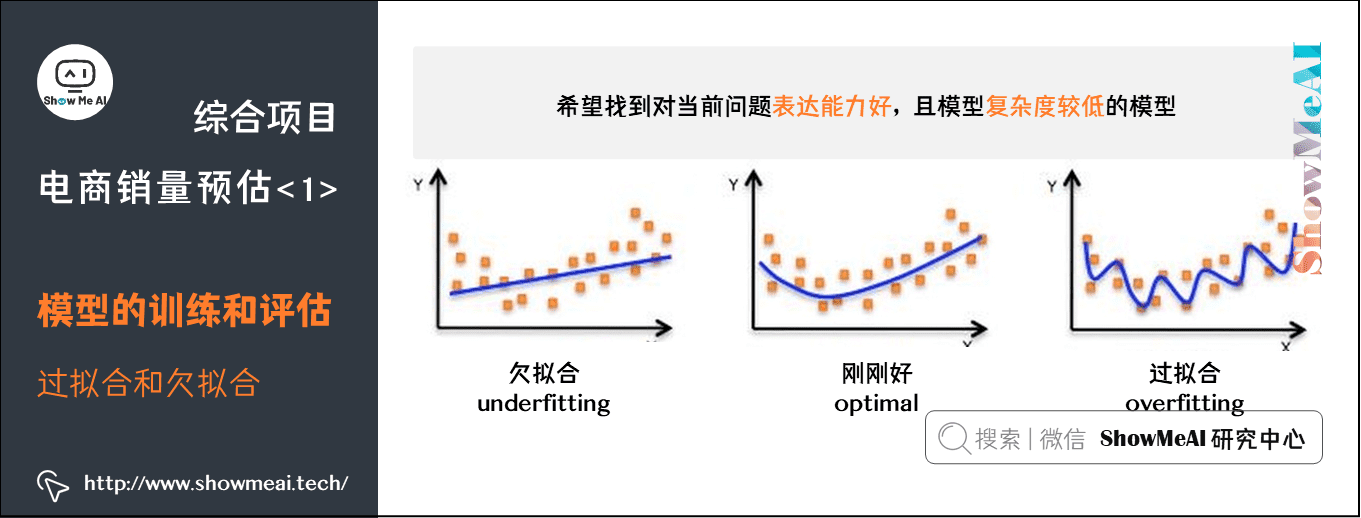
过拟合欠拟合示意图
更详细的讲解大家可以参考ShowMeAI的文章图解机器学习 | 机器学习基础知识
5.2 评估准则
在Scikit-Learn,XGBoost或是LightGBM中,我们往往使用各种评价标准来表达模型的性能。最常用的往往有以下评估准则,对应二分类,多分类,回归等等不同的问题。
rmse:均方根误差mae:平均绝对误差logloss:负对数似然函数值error:二分类错误率merror:多分类错误率mlogloss:多分类logloss损失函数auc:曲线下面积
当然也可以通过定义自己的loss function进行损失函数定义。
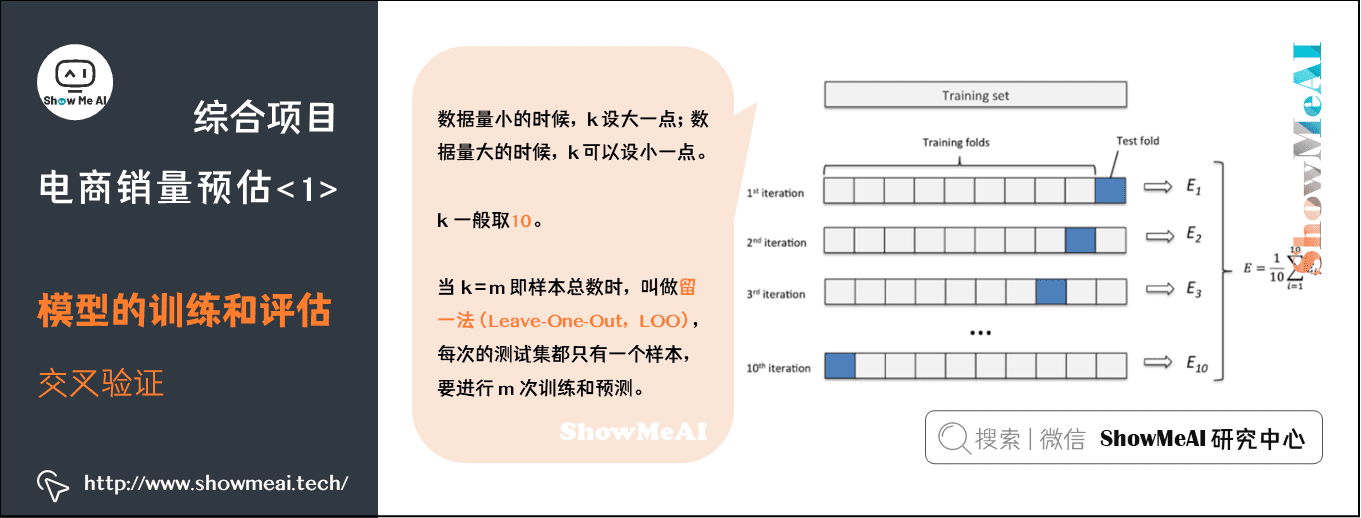
5.3 交叉验证
留出法的数据划分,可能会带来偏差。在机器学习中,另外一种比较常见的评估方法是交叉验证法——K折交叉验证对K个不同分组训练的结果进行平均来减少方差。
因此模型的性能对数据的划分就不那么敏感,对数据的使用也会更充分,模型评估结果更加稳定,可以很好地避免上述问题。
更详细的讲解大家可以参考ShowMeAI的文章 图解机器学习 | 机器学习基础知识。
5.4 建模工具库与模型选择
本项目很显然是一个回归类建模问题,我们可以先从回归树( 图解机器学习 | 回归树模型详解),后可以尝试集成模型,例如随机森林( 图解机器学习 | 随机森林分类模型详解)、XGBoost( 图解机器学习 | XGBoost模型详解)、LightGBM( 图解机器学习 | LightGBM模型详解)。
考虑到参加比赛的同学的整体算力资源可能参差不齐所以本文将主要讲解如何利用LightGBM进行模型的训练。本文只提供一些核心代码演示,更加细节的文档可以参考 LightGBM中文文档。
大家通过ShowMeAI前面的工具库详解 LightGBM建模应用详解 知道,如果用LightGBM进行训练学习,训练代码非常简单:
model = lgb.train(params=lgb_parameter, feval=rmsle, train_set=train_data, num_boost_round=15000, valid_sets=watchlist, early_stopping_rounds=1000, verbose_eval=1000)
代码解释:
params:定义lgb算法的一些参数设置,如评价标准,学习率,任务类型等。feval:可以让lgb使用自定义的损失函数。train_set:训练集的输入。num_boost_round:最大的训练次数。valid_sets:测试集的输入。early_stopping_rounds:当模型评分在n个回合后还没有提高时就结束模型将最佳的点的模型保存。verbose_eval:表示每多少论返回一次训练的评价信息,这里定义了每1000轮保存一次。
5.5 数据预处理
为了建模有好的效果,我们很少直接用原始数据,一般会先对数据进行预处理。
我们先用pd.merge方法将store与train数据合并,得到以下DataFrame数据:

合并后数据的前5行概览
首先我们看到有一些类别型字段,比如SotreType、Assortment以及StateHoliday,是以a、b、c、d这样的数值形式保存的,常用的数据预处理或者特征工程,会将其进行编码。我们这里用mapping函数将其编码变换为0123这样的数字。
mappings = {'0':0, 'a':1, 'b':2, 'c':3, 'd':4}
data['StoreType'] = data.StoreType.map(mappings)
data['Assortment']= data.Assortment.map(mappings)
data['StateHoliday']= data.StateHoliday.map(mappings)
再注意到时间型的字段date,是以YYYY-MM-DD这样的日期时间戳的形式记录的。我们最常做的操作,是将时间戳拆分开来,比如年月日可以拆分成Year、Month、Day这样的形式会更有利于我们的模型学习到有效的信息。
data['Year'] = data.Date.dt.year
data['Month'] = data.Date.dt.month
data['Day'] = data.Date.dt.day
data['DayOfWeek'] = data.Date.dt.dayofweek
data['WeekOfYear'] = data.Date.dt.weekofyear
上述代码还抽取了「一年内的第几周」和「一周中的第几天」两列额外信息。这些都可以在Pandas中的dt方法中找到。
再看CompetitionOpenSince和Promo2Since两个字段,这两列数据表示促销开始的时间,这样的数据是固定的,但是开始的时间到当前时间点的数据是很有价值帮助我们预测销售额。所以这里需要一定变化,我们将促销开始的时间减去当前data的时间即可。
data['CompetitionOpen']=12*(data.Year-data.CompetitionOpenSinceYear)+(data.Month - data.CompetitionOpenSinceMonth)
data['PromoOpen'] = 12 *(data.Year-data.Promo2SinceYear)+ (data.WeekOfYear - data.Promo2SinceWeek) / 4.0
data['CompetitionOpen'] = data.CompetitionOpen.apply(lambda x: x if x > 0 else 0)
data['PromoOpen'] = data.PromoOpen.apply(lambda x: x if x > 0 else 0)
CompetitionOpen和PromoOpen是两列计算距离促销,或竞争对手开始时间长短的字段,用于表达促销或竞争对手对于销售额的影响。我们先做异常值处理(滤除所有负值)。
在数据中还有一列PromoInterval以列出月信息的形式储存正在促销的月份,我们想将其转化为以月份信息为准,如这个时间点的月份在这个PromoInterval中则这一店的这一时间点在促销中。
data.loc[data.PromoInterval == 0, 'PromoInterval'] = ''
data['IsPromoMonth'] = 0
for interval in data.PromoInterval.unique():if interval != '':for month in interval.split(','):data.loc[(data.monthStr == month) & (data.PromoInterval == interval), 'IsPromoMonth'] = 1
和店铺类型中的标签转换类似,我们将月份从数字转化为str类型以和PromoInterval进行配对用于断当前时间是否是销售时间,并且新建一个数据列IsPromoMonth进行储存当前时间是否为促销时间。
当然,如果我们深度思考,还可以有很多事情做。例如:
- 在原始数据中有很多店铺没有开门的情况,既
Open的值为0。而预测数值的情况下我们默认店铺不会存在关门的情况,所以可以在数据筛选的过程中清理Open为0的情况。 - 在数据中还一部分
Sales数值小于零的情况,这里猜测是有一些意外情况导致的记账信息错误,所以可以在数据清洗中时也直接过滤这一部分数据。
5.6 模型参数
很多机器学习有很多超参数可以调整,以这里的LightGBM为例,下面为选出的系列参数。关于LightGBM的参数和调参方法可以参考 LightGBM建模应用详解。
params ={
'boosting_type': 'gbdt',
'objective': 'regression',
'metric':'rmse',
'eval_metric':'rmse',
'learning_rate': 0.03,
'num_leaves': 400,
#'max_depth' : 10,
'subsample': 0.8,
"colsample_bytree": 0.7,
'seed':3,
}
上述参数包含两类:
主要参数:确定任务和模型的时候就会确定下来。
boosting_type:是模型的类型(常选择gbdt或dart)。objective:决定了模型是完成一个分类任务还是回归任务。metric:为模型训练时的评估准则。eval_metric:为模型评价时的评估准则。
模型可调细节参数:对模型的构建和效果有影响的参数。
learning_rate:表示每次模型学习时的学习率。num_leaves:是最多叶子数。leaf-wise的LightGBM算法主要由叶子数来控制生长和过拟合,如果树深为max_depth,它的值的设置应该小于2^(max_depth),否则可能会导致过拟合。is_unbalance:设置可以应对类别非均衡数据集。min_data_in_leaf:叶子节点最少样本数,调大它的值可以防止过拟合,它的值通常设置的比较大。
# coding: utf-8
import lightgbm as lgb
import pandas as pd
from sklearn.metrics import mean_squared_error# 设定训练集和测试集
y_train = train['Sales'].values
X_train = train.drop('Sales', axis=1).values# 构建lgb中的Dataset格式
lgb_train = lgb.Dataset(X_train, y_train)# 敲定好一组参数
params = {'boosting_type': 'gbdt','objective': 'regression','metric':'rmse','eval_metric':'rmse','learning_rate': 0.03,'num_leaves': 400,#'max_depth' : 10,'subsample': 0.8,"colsample_bytree": 0.7,'seed':3,}print('开始训练...')
# 训练
gbm = lgb.train(params,lgb_train,num_boost_round=200)# 保存模型
print('保存模型...')
# 保存模型到文件中
gbm.save_model('model.txt')
参考资料
- 数据分析系列教程
- 机器学习算法系列教程
- Kaggle Rossmann Store Sales机器学习比赛
- 数据科学工具速查 | Numpy使用指南
- 数据科学工具速查 | Numpy使用指南
- 数据科学工具速查 | Pandas使用指南
- 数据科学工具速查 | Matplotlib使用指南
- 数据科学工具速查 | Seaborn使用指南
- AI建模工具速查 | Scikit-Learn使用指南
- 图解机器学习 | XGBoost模型详解
- 图解机器学习 | LightGBM模型详解
ShowMeAI系列教程推荐
- 图解Python编程:从入门到精通系列教程
- 图解数据分析:从入门到精通系列教程
- 图解AI数学基础:从入门到精通系列教程
- 图解大数据技术:从入门到精通系列教程
- 图解机器学习算法:从入门到精通系列教程
- 机器学习实战:手把手教你玩转机器学习系列
相关文章推荐
- Python机器学习算法应用实践
- SKLearn入门与简单应用案例
- SKLearn最全应用指南
- XGBoost建模应用详解
- LightGBM建模应用详解
- Python机器学习综合项目-电商销量预估
- Python机器学习综合项目-电商销量预估<进阶方案>
- 机器学习特征工程最全解读
- 自动化特征工程工具Featuretools应用
- AutoML自动化机器学习建模