1.一直以来想写下基于
scikit-learn训练AI算法的系列文章,作为较火的机器学习框架,也是日常项目开发中常用的一款工具,最近刚好挤时间梳理、总结下这块儿的知识体系。
2.熟悉、梳理、总结下scikit-learn框架模型算法包相关技术点及经验。
3.欢迎批评指正,欢迎互三,跪谢一键三连!
4.欢迎批评指正,欢迎互三,跪谢一键三连!
5.欢迎批评指正,欢迎互三,跪谢一键三连!
文章目录
- 1.环境前置说明
- 2.`sklearn`算法类型及常用总结
- 2.1 `sklearn`算法模型参考清单
- 2.2 `sklearn`算法模型模块函数总结清单
- 3.参考链接
1.环境前置说明
- 版本信息
import sklearn sklearn.show_versions()============================================================================== System:python: 3.7.0 (default, Jun 28 2018, 08:04:48) [MSC v.1912 64 bit (AMD64)] executable: ..\Anaconda3\python.exemachine: Windows-10-10.0.19041-SP0Python dependencies:pip: 24.0setuptools: 68.0.0sklearn: 0.24.1numpy: 1.21.6scipy: 1.1.0Cython: 0.29.28pandas: 1.1.5matplotlib: 2.2.3joblib: 1.3.2 threadpoolctl: 3.1.0Built with OpenMP: True ==============================================================================
2.sklearn算法类型及常用总结
- 下图是网友总结的很nice的图,这里引用参考下。

2.1 sklearn算法模型参考清单
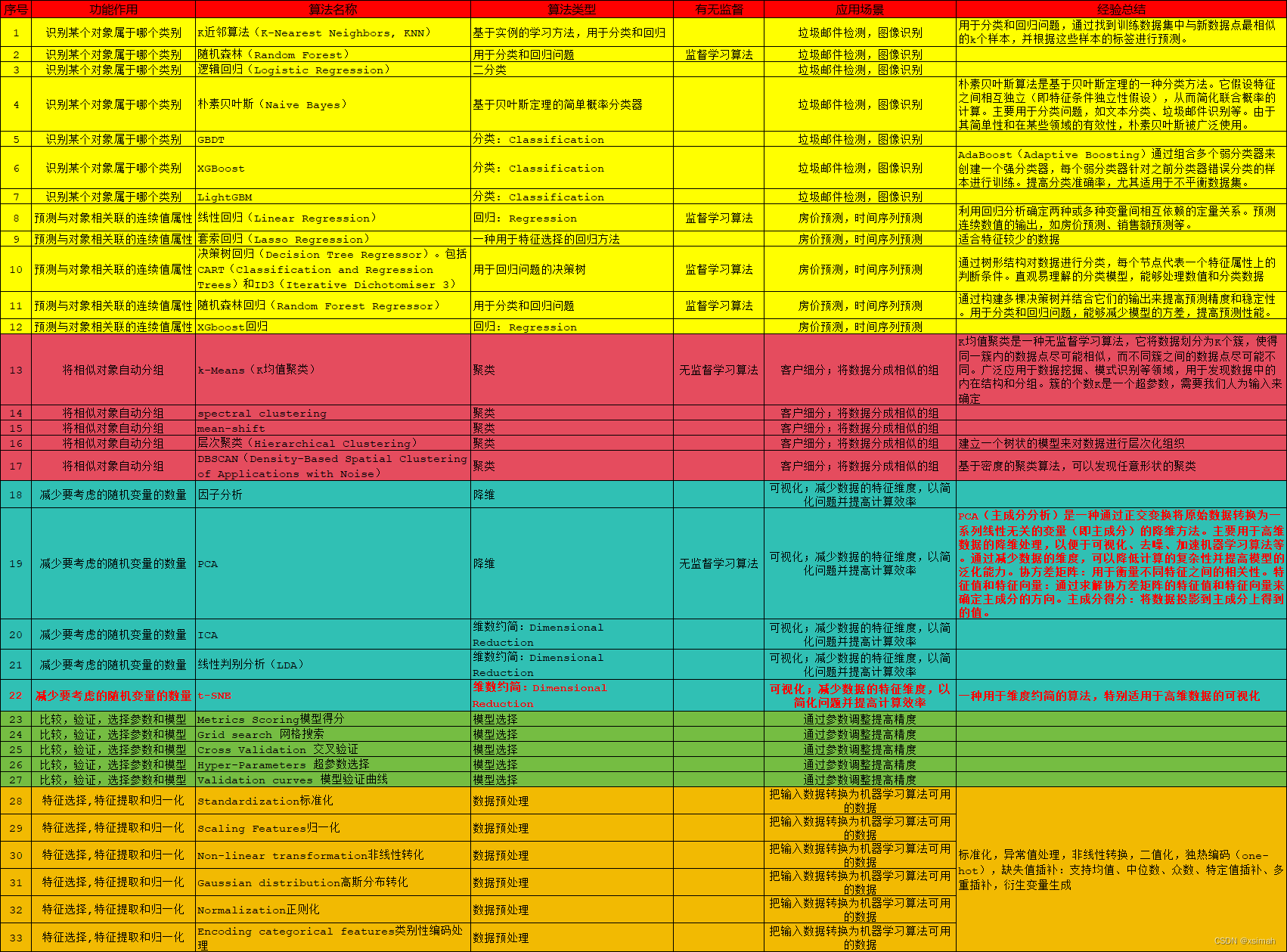
- 可CV表格文本
序号 功能作用 算法名称 算法类型 有无监督 应用场景 经验总结 1 识别某个对象属于哪个类别 K近邻算法(K-Nearest Neighbors, KNN) 基于实例的学习方法,用于分类和回归 – 垃圾邮件检测,图像识别 用于分类和回归问题,通过找到训练数据集中与新数据点最相似的k个样本,并根据这些样本的标签进行预测。 2 识别某个对象属于哪个类别 随机森林(Random Forest) 用于分类和回归问题 监督学习算法 垃圾邮件检测,图像识别 – 3 识别某个对象属于哪个类别 逻辑回归(Logistic Regression) 二分类 – 垃圾邮件检测,图像识别 – 4 识别