一、Gradio
Gradio 详细介绍
Gradio 是一个用于构建和分享机器学习模型和数据科学应用的开源Python库。它简化了创建交互式Web界面的过程,让开发者可以快速搭建原型并与他人分享。
主要特性
-
易用性:
- 无需前端开发经验:只需几行Python代码就可以创建功能完备的Web界面。
- 即时部署:可以快速本地运行和在线共享。
-
广泛的支持:
- 支持多种输入和输出类型:包括图像、文本、音频、视频、滑动条等。
- 与主流机器学习框架兼容:如TensorFlow、PyTorch、scikit-learn等。
-
自动化:
- 自动生成接口:根据定义的函数自动生成Web界面。
- 实时更新:可以实时查看和测试模型的效果。
-
协作和分享:
- 共享链接:生成的应用可以通过链接分享,方便他人访问和测试。
- 集成到现有的工作流程中:可以与Jupyter Notebook、Google Colab等集成使用。
Gradio的基本使用方法
-
安装Gradio:
pip install gradio -
创建一个简单的Gradio应用:
import gradio as grdef greet(name):return f"Hello {name}!"iface = gr.Interface(fn=greet, inputs="text", outputs="text") iface.launch()gr.Interface:定义了一个简单的接口。fn=greet:指定了处理函数。inputs="text":定义输入组件为文本输入框。outputs="text":定义输出组件为文本输出框。iface.launch():启动Gradio应用。
-
支持多种输入和输出类型:
Gradio支持多种输入和输出组件,如图像、视频、音频、滑动条、复选框等。def classify_image(image):# 假设有一个预训练的分类模型return "分类结果"iface = gr.Interface(fn=classify_image, inputs=gr.inputs.Image(), outputs="text") iface.launch() -
多个输入和输出:
支持多输入和多输出的情况,可以构建复杂的界面。def process_data(name, age, image):# 假设处理这些输入并返回结果return f"Name: {name}, Age: {age}", imageiface = gr.Interface(fn=process_data,inputs=[gr.inputs.Textbox(label="Name"), gr.inputs.Slider(0, 100, label="Age"), gr.inputs.Image(type="numpy", label="Image")],outputs=["text", "image"] ) iface.launch()
Gradio组件
Gradio提供了多种组件来满足不同的输入输出需求。以下是一些常用的组件:
- 文本输入:
gr.inputs.Textbox - 滑动条:
gr.inputs.Slider - 复选框:
gr.inputs.Checkbox - 图像:
gr.inputs.Image - 音频:
gr.inputs.Audio - 视频:
gr.inputs.Video
每个组件都可以通过不同的参数进行定制,以满足特定的需求。
高级特性
-
自定义CSS和JS:
Gradio允许用户自定义应用的外观和行为,通过添加自定义的CSS和JavaScript文件。 -
集成到现有工作流:
Gradio应用可以嵌入到Jupyter Notebook、Google Colab等环境中,方便与数据科学工作流的无缝集成。 -
共享和部署:
Gradio提供了一键共享功能,可以生成一个临时链接,方便快速分享应用。还可以将应用部署到云端,提供更长时间的访问。 -
错误处理和调试:
提供了详细的错误信息和调试工具,帮助开发者快速定位和解决问题。
二、实例
本文主要使用Gradio库创建了一个Web应用,允许用户上传图像,并使用YOLOv8模型对图像进行目标检测。处理后的图像会显示检测框和标签,并展示检测结果的详细信息。通过简单的Web界面,用户可以轻松地进行图像检测而无需编写复杂的前端代码。
代码实现的具体功能
- 图像上传:用户可以通过Web界面上传图像文件。
- 目标检测:上传的图像被传递给YOLO模型进行目标检测。
- 结果展示:处理后的图像会在Web界面显示,并且显示检测到的目标物体的类别、置信度和位置。
- 交互体验:用户可以实时查看检测结果,并可以继续上传新的图像进行检测。
通过上述代码,用户能够方便地使用YOLOv8模型进行图像目标检测,并通过直观的Web界面查看结果。
下面是代码的流程以及各部分的作用功能:
代码流程和功能
-
引入必要的库:
import gradio as gr import cv2 import numpy as np import os from ultralytics import YOLOgradio:用于创建Web界面的库。cv2:用于图像处理的OpenCV库。numpy:用于处理数组和矩阵的库。os:用于文件和目录操作。ultralytics.YOLO:用于加载和使用YOLOv8模型。
-
设置上传和结果文件夹:
UPLOAD_FOLDER = 'uploads' RESULT_FOLDER = 'results' os.makedirs(UPLOAD_FOLDER, exist_ok=True) os.makedirs(RESULT_FOLDER, exist_ok=True)UPLOAD_FOLDER和RESULT_FOLDER:定义上传文件和处理结果的保存目录。os.makedirs:创建目录(如果目录不存在)。
-
加载YOLO模型:
model = YOLO('yolov8n.pt')model:加载YOLOv8模型,用于后续的图像检测。
-
定义图像处理函数:
def process_image(image):# 保存上传的图像filename = 'uploaded_image.jpg'file_path = os.path.join(UPLOAD_FOLDER, filename)cv2.imwrite(file_path, image)# 处理图像results = model(image)detection_results = []for result in results:boxes = result.boxesfor box in boxes:x1, y1, x2, y2 = box.xyxy[0]conf = box.conf[0]cls = box.cls[0]cv2.rectangle(image, (int(x1), int(y1)), (int(x2), int(y2)), (0, 255, 0), 2)cv2.putText(image, f'{cls}:{conf:.2f}', (int(x1), int(y1) - 10), cv2.FONT_HERSHEY_SIMPLEX, 0.9,(36, 255, 12), 2)detection_results.append(f'Class: {cls}, Confidence: {conf:.2f}, Box: ({x1}, {y1}), ({x2}, {y2})')# 保存处理后的图像result_filename = 'result_image.jpg'result_path = os.path.join(RESULT_FOLDER, result_filename)cv2.imwrite(result_path, image)return image, '\n'.join(detection_results)process_image函数:处理上传的图像,使用YOLO模型进行检测,绘制检测框和标签,并返回处理后的图像和检测结果文本。- 保存上传的图像到指定目录。
- 使用YOLO模型对图像进行检测。
- 绘制检测框和标签,并保存处理后的图像。
- 返回处理后的图像和检测结果文本。
-
创建Gradio界面:
iface = gr.Interface(fn=process_image,inputs=gr.Image(type="numpy", label="上传图像"),outputs=[gr.Image(type="numpy", label="处理后的图像"), gr.Textbox(label="检测结果")],title="YOLOv8 图像检测",description="上传图像并使用YOLOv8模型进行检测" )gr.Interface:定义Gradio界面的主要组件。fn=process_image:指定处理函数为process_image。inputs=gr.Image(type="numpy", label="上传图像"):定义图像上传输入组件。outputs=[gr.Image(type="numpy", label="处理后的图像"), gr.Textbox(label="检测结果")]:定义处理后的图像输出和检测结果文本输出组件。title和description:设置界面的标题和描述。
完整代码如下:
import gradio as gr
import cv2
import numpy as np
import os
from ultralytics import YOLO# 设置上传和结果文件夹
UPLOAD_FOLDER = 'uploads'
RESULT_FOLDER = 'results'
os.makedirs(UPLOAD_FOLDER, exist_ok=True)
os.makedirs(RESULT_FOLDER, exist_ok=True)# 加载模型
model = YOLO('yolov8n.pt')def process_image(image):# 保存上传的图像filename = 'uploaded_image.jpg'file_path = os.path.join(UPLOAD_FOLDER, filename)cv2.imwrite(file_path, image)# 处理图像results = model(image)detection_results = []for result in results:boxes = result.boxesfor box in boxes:x1, y1, x2, y2 = box.xyxy[0]conf = box.conf[0]cls = box.cls[0]cv2.rectangle(image, (int(x1), int(y1)), (int(x2), int(y2)), (0, 255, 0), 2)cv2.putText(image, f'{cls}:{conf:.2f}', (int(x1), int(y1) - 10), cv2.FONT_HERSHEY_SIMPLEX, 0.9,(36, 255, 12), 2)detection_results.append(f'Class: {cls}, Confidence: {conf:.2f}, Box: ({x1}, {y1}), ({x2}, {y2})')# 保存处理后的图像result_filename = 'result_image.jpg'result_path = os.path.join(RESULT_FOLDER, result_filename)cv2.imwrite(result_path, image)return image, '\n'.join(detection_results)# 创建Gradio界面
iface = gr.Interface(fn=process_image,inputs=gr.Image(type="numpy", label="上传图像"),outputs=[gr.Image(type="numpy", label="处理后的图像"), gr.Textbox(label="检测结果")],title="YOLOv8 图像检测",description="上传图像并使用YOLOv8模型进行检测"
)# 启动Gradio应用
iface.launch()运行,复制下面链接:
界面如下:
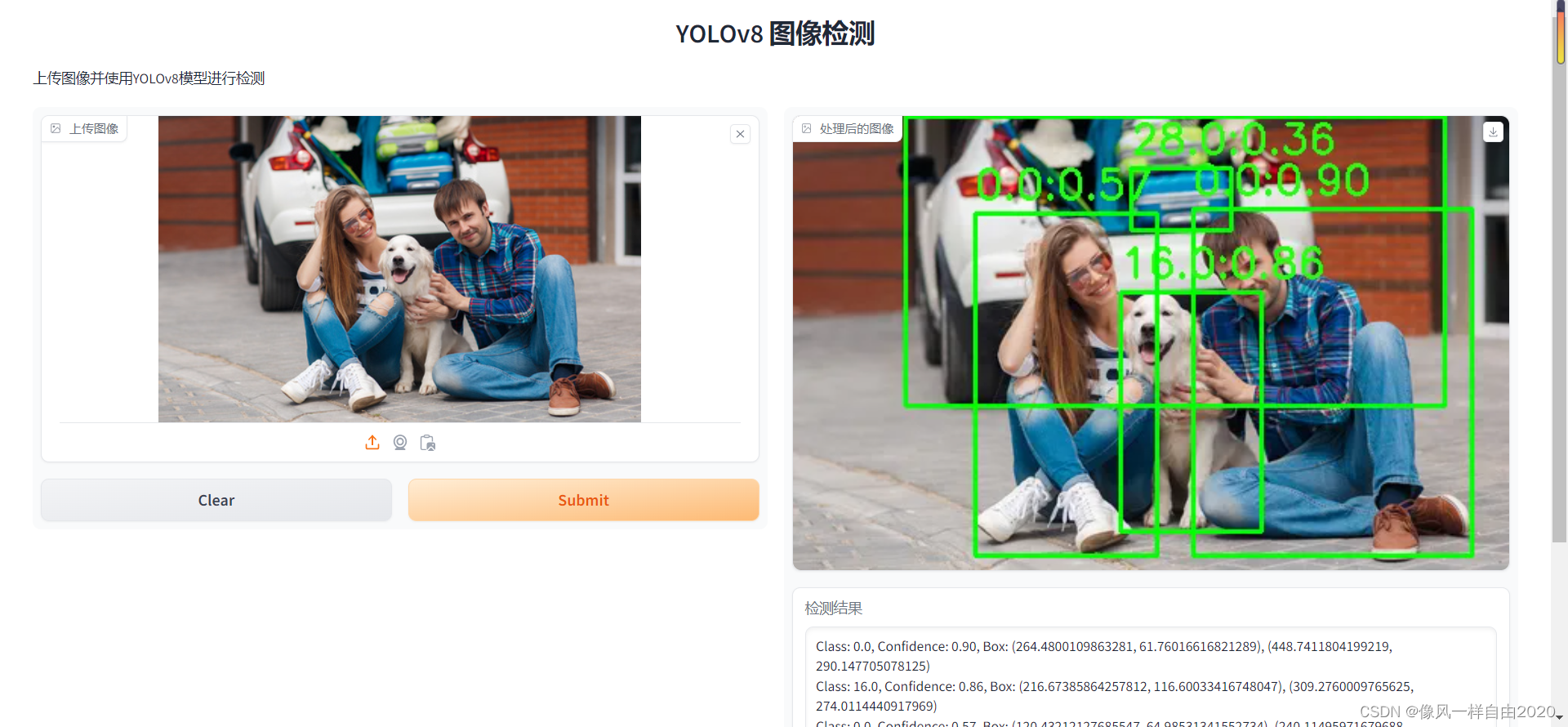
选择图片检测结果如下:
三、 番外篇-YOLOV10尝鲜
最近由清华大学的研究团队研发的最新的YOLOV10模型。这一新一代的YOLO模型专注于实时端到端的目标检测。YOLOv10在多个方面进行了改进,包括优化模型架构、消除非极大值抑制(NMS)后处理步骤,并引入了高效的模型设计策略,从而在提高检测精度的同时显著降低了计算开销和推理延迟。
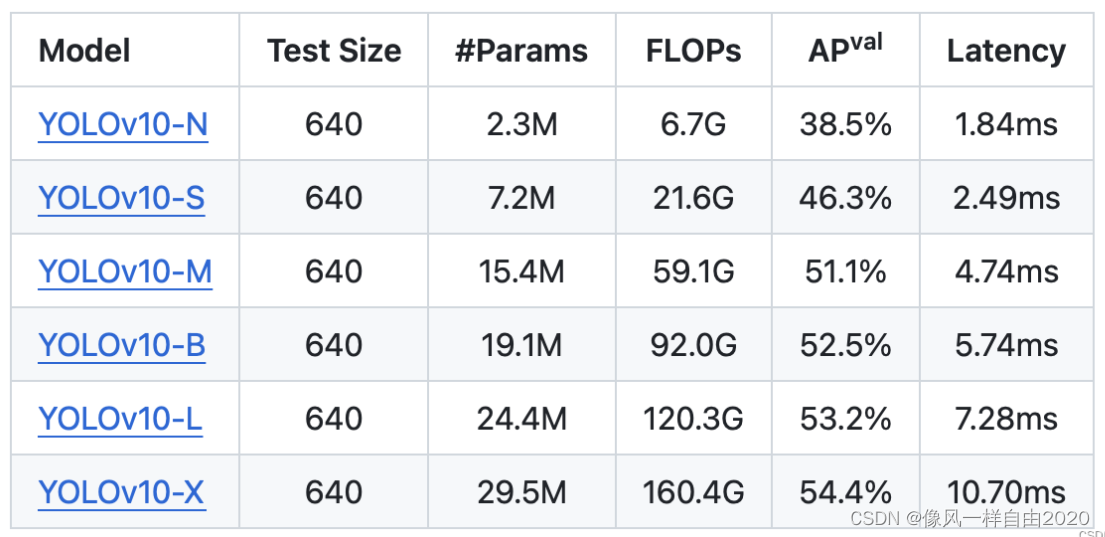
具体来说,YOLOv10的研发团队包括Ao Wang, Hui Chen, Lihao Liu, Kai Chen, Zijia Lin, Jungong Han和Guiguang Ding。这些研究人员通过广泛的实验,证明了YOLOv10在不同模型规模上实现了最先进的性能和效率。例如,与YOLOv9-C相比,YOLOv10-B在相同性能下延迟减少了46%,参数减少了25%。
通过这些改进,YOLOv10在实时性和精度方面都达到了新的高度,适用于各种实时目标检测应用,如自动驾驶、视频监控和智能安防等。
好奇心驱使尝试一下v10模型的效果。下载了yolov10s.pt版本,进行实时视频监控测试。
各版本下载和介绍如下:
模型下载:
YOLOv10-N:https://github.com/THU-MIG/yolov10/releases/download/v1.1/yolov10n.pt
YOLOv10-S:https://github.com/THU-MIG/yolov10/releases/download/v1.1/yolov10s.pt
YOLOv10-M:https://github.com/THU-MIG/yolov10/releases/download/v1.1/yolov10m.pt
YOLOv10-B:https://github.com/THU-MIG/yolov10/releases/download/v1.1/yolov10b.pt
YOLOv10-L:https://github.com/THU-MIG/yolov10/releases/download/v1.1/yolov10l.pt
YOLOv10-X:https://github.com/THU-MIG/yolov10/releases/download/v1.1/yolov10x.pt
模型介绍:
YOLOv10实战:30行左右代码构建基于YOLOv10的实时视频监控
代码如下:运行后电脑摄像头自动开启,实时检测摄像头内的目标。
import cv2
from ultralytics import YOLOv10model = YOLOv10("yolov10s.pt")
cap = cv2.VideoCapture(0)
while True:ret, frame = cap.read()if not ret:break # 如果没有读取到帧,退出循环results = model.predict(frame)# 遍历每个预测结果for result in results:# 结果中的每个元素对应一张图片的预测boxes = result.boxes # 获取边界框信息for box in boxes:x1, y1, x2, y2 = map(int, box.xyxy[0])cls = int(box.cls[0])conf = float(box.conf[0])cv2.rectangle(frame, (x1, y1), (x2, y2), (255, 0, 0), 2)cv2.putText(frame, f'{model.names[cls]} {conf:.2f}', (x1, y1 - 10), cv2.FONT_HERSHEY_SIMPLEX, 0.5,(255, 0, 0), 2)# 显示带有检测结果的帧cv2.imshow('YOLOv10实时检测', frame)# 按'q'键退出if cv2.waitKey(1) & 0xFF == ord('q'):break# 释放资源
cap.release()
cv2.destroyAllWindows()
检测结果:
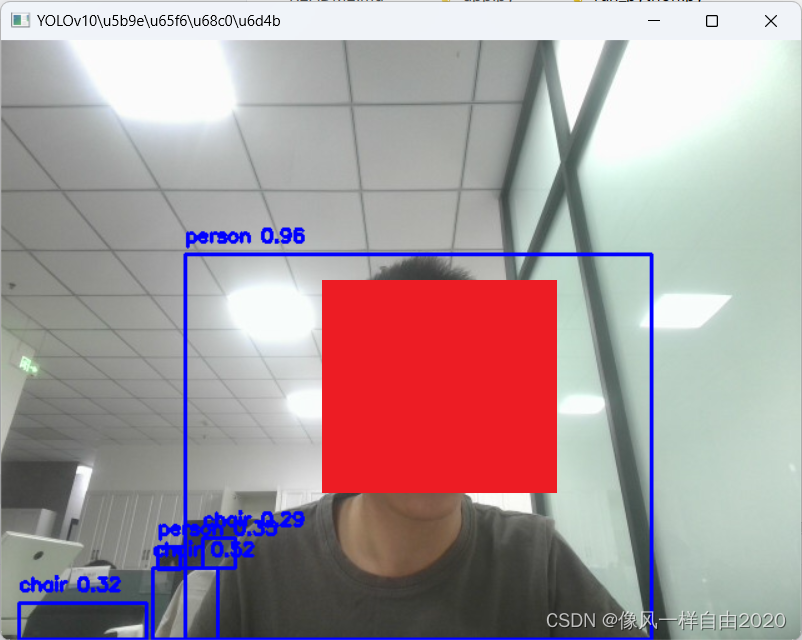
检测效果确实很赞!
参考:基于YOLOv10实现你的第一个视觉AI大模型
四、 YOLO版本简史
YOLO(You Only Look Once)系列目标检测模型的发展历程中,不同版本是由不同的研究团队研发的。以下是各个版本的研发团队简介:
YOLOv1
研发团队:Joseph Redmon, Santosh Divvala, Ross Girshick, Ali Farhadi
- 机构:华盛顿大学和Facebook AI Research (FAIR)
- 发布时间:2016年
- 简介:YOLOv1是YOLO系列的第一个版本,提出了一种统一的目标检测方法,能够在单次前向传递中预测物体边界和类别。
YOLOv2 (YOLO9000)
研发团队:Joseph Redmon, Ali Farhadi
- 机构:华盛顿大学
- 发布时间:2017年
- 简介:YOLOv2在YOLOv1的基础上进行了改进,引入了多尺度训练和Batch Normalization等技术,并扩展了模型的检测能力(YOLO9000)来识别9000种类别。
YOLOv3
研发团队:Joseph Redmon, Ali Farhadi
- 机构:华盛顿大学
- 发布时间:2018年
- 简介:YOLOv3进一步改进了网络结构,引入了残差网络和多尺度特征金字塔,使其在精度和速度上有显著提升。
YOLOv4
研发团队:Alexey Bochkovskiy, Chien-Yao Wang, Hong-Yuan Mark Liao
- 机构:Alexey Bochkovskiy的独立研究与台湾国立中山大学
- 发布时间:2020年
- 简介:YOLOv4在YOLOv3的基础上,结合了许多新技术如CSPNet、Mish激活函数和SAM,进一步提高了性能。
YOLOv5
研发团队:Glenn Jocher
- 机构:Ultralytics LLC
- 发布时间:2020年
- 简介:YOLOv5由Ultralytics团队开发,注重易用性和快速部署,提供了多种预训练模型和丰富的工具,便于在各种应用中使用。
YOLOv6
研发团队:Meituan-Dianping
- 机构:美团
- 发布时间:2022年
- 简介:YOLOv6专注于工业应用中的高效目标检测,优化了模型的推理速度和精度,适合在生产环境中部署。
YOLOv7
研发团队:Wong Kin-Yiu, Alexey Bochkovskiy, Chien-Yao Wang, Hong-Yuan Mark Liao
- 机构:台湾国立中山大学
- 发布时间:2022年
- 简介:YOLOv7进一步优化了网络架构和训练策略,使得模型在速度和精度上都达到了新的高度。
YOLOv8
研发团队:Ultralytics LLC
- 机构:Ultralytics LLC
- 发布时间:2023年
- 简介:YOLOv8延续了YOLOv5的开发理念,通过改进的架构和训练方法,进一步提升了目标检测的性能和效率。
YOLOv9
研发团队:Ultralytics LLC
- 机构:Ultralytics LLC
- 发布时间:2024年
- 简介:YOLOv9在YOLOv8的基础上,针对大规模数据集和复杂场景进行了优化,提供了更高的检测精度和速度。
YOLOv10
研发团队:Ao Wang, Hui Chen, Lihao Liu, Kai Chen, Zijia Lin, Jungong Han, Guiguang Ding
- 机构:清华大学
- 发布时间:2024年
- 简介:YOLOv10通过优化模型架构和消除非极大值抑制(NMS),显著提升了实时目标检测的性能和效率。
这些不同版本的YOLO模型在各自的时代都对目标检测技术做出了重要贡献,推动了这一领域的发展。各个版本在精度、速度和易用性上都有不同的侧重点,以满足不同应用场景的需求。







![[数据集][目标检测]盲道检测数据集VOC+YOLO格式2173张1类别](https://img-blog.csdnimg.cn/direct/dd05ea22da294ac8ab783094defe5cef.png)

