将数据输入或加载到R工作空间中,是使用R进行数据分析的第一步。R语言支持读取众多格式的数据文件,excel文件,csv文件,txt文件和数据库(MYSQL数据库)等;其中,excel和csv是我们最常遇到的数据文件格式。
目录
0 设置工作目录【很重要】
1 read.table() #读取带分隔符的文本/数据文件
2 read.csv() #读取.csv格式的数据,read.table的一种特定应用
3 excel数据文件读取
4 scan #比read.table更加灵活
5 保存为.Rdata
6 write.table()
7 CSV格式导出
(提示:加粗部分可重点学习)
正文
0 设置工作目录【很重要】
R语言中数据的输入需要设置数据读取的路径,一般将数据文件放到工作目录下,这样直接就可以通过read.table等读取数据文档(不许要设置路径)。
方法一:setwd()
setwd("E:/") #设置当前工作目录为"E:/"
getwd() #读取当前工作空间的工作目录(文件读取保存路径)
> getwd() #读取当前工作空间的工作目录(文件读取保存路径)
[1] "C:/Users/ysl/Documents"
> setwd("E:/") #设置当前工作目录为"E:/"
> getwd() #再次使用getwd()函数即可查看是否设置成功
[1] "E:/"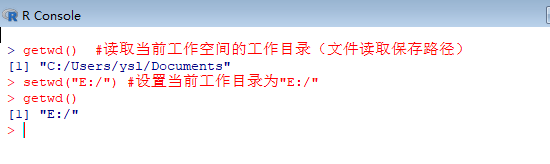
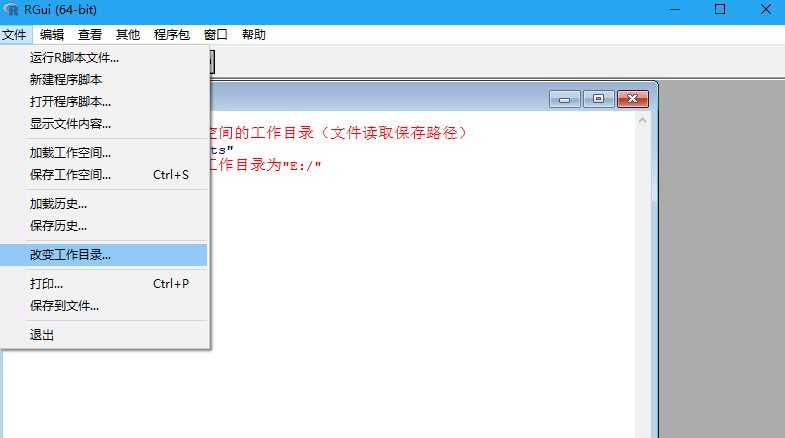
方法二:通过R-gui菜单栏设置(文件-改变工作目录)
1 read.table() #读取带分隔符的文本文件
read.table()函数是R最基本函数之一,读取带分隔符的文本/表格文件。
#Usageread.table(file, header = FALSE, sep = "", quote = "\"'", dec = ".", numerals = c("allow.loss", "warn.loss", "no.loss"), row.names, col.names, as.is = !stringsAsFactors, na.strings = "NA", colClasses = NA, nrows = -1, skip = 0, check.names = TRUE, fill = !blank.lines.skip, strip.white = FALSE, blank.lines.skip = TRUE, comment.char = "#", allowEscapes = FALSE, flush = FALSE, stringsAsFactors = default.stringsAsFactors(), fileEncoding = "", encoding = "unknown", text, skipNul = FALSE)
read.csv(file, header = TRUE, sep = ",", quote = "\"",
dec = ".", fill = TRUE, comment.char = "", ...) read.csv2(file, header = TRUE, sep = ";", quote = "\"",
dec = ",", fill = TRUE, comment.char = "", ...) read.delim(file, header = TRUE, sep = "\t", quote = "\"",
dec = ".", fill = TRUE, comment.char = "", ...) read.delim2(file, header = TRUE, sep = "\t", quote = "\"", dec = ",", fill = TRUE, comment.char = "", ...) 常用参数的说明如下:
(1)file:file是一个带分隔符的ASCII文本文件。
①绝对路径或者相对路径。一定要注意,在R语言中\是转义符,所以路径分隔符需要写成"\\"或者“/”。所以写成“C:\\myfile\\myfile.txt”或者“C:/myfile/myfile.txt”即可。
②使用file.choose(),弹出对话框,自动选择文件位置。例如:read.table(file.choose(),...)。
(2)header:一个表示文件是否在第一行包含了变量的逻辑型变量。
如果header设置为TRUE,则要求第一行要比数据列的数量少一列。
(3)sep分开数据的分隔符。默认sep=""
read.table()函数可以将1个或多个空格、tab制表符、换行符或回车符作为分隔符。常见空白分隔符有:空格,制表符,换行符
sep=” ”;sep = “\t”;sep = “\n”(4)stringsAsFactors 逻辑值,标记字符向量是否需要转化为因子,默认是TRUE。stringsAsFactors = F意味着,“在读入数据时,遇到字符串之后,不将其转换为factors,仍然保留为字符串格式”。
(5)encoding 设定输入字符串的编码方式。
#读取txt文档
> df<- read.table("data.txt")
> df
V1 V2
1 x y
2 1 2
3 3 4
4 5 6
> df <- read.table("data.txt",header = T)
> df
x y
1 1 2
2 3 4
3 5 6#样式1:直接读取数据
> df <- read.table("data.csv") #直接读取数据
> head(df)
V1
1 ID,Sepal.Length,Sepal.Width,Petal.Length,Petal.Width,Species
2 1,5.1,3.5,1.4,0.2,setosa
3 2,4.9,3,1.4,0.2,setosa
4 3,4.7,3.2,1.3,0.2,setosa
5 4,4.6,3.1,1.5,0.2,setosa
6 5,5,3.6,1.4,0.2,setosa
#样式2:读数+首行表头
> df <- read.table("data.csv",header = T) #读数+首行表头
> head(df)
ID.Sepal.Length.Sepal.Width.Petal.Length.Petal.Width.Species
1 1,5.1,3.5,1.4,0.2,setosa
2 2,4.9,3,1.4,0.2,setosa
3 3,4.7,3.2,1.3,0.2,setosa
4 4,4.6,3.1,1.5,0.2,setosa
5 5,5,3.6,1.4,0.2,setosa
6 6,5.4,3.9,1.7,0.4,setosa#样式3:读数+首行表头+","逗号分割
> df <- read.table("data.csv",header = T,sep=",")
#读数+首行表头+","逗号分割
> head(df)
ID Sepal.Length Sepal.Width Petal.Length Petal.Width Species
1 1 5.1 3.5 1.4 0.2 setosa
2 2 4.9 3.0 1.4 0.2 setosa
3 3 4.7 3.2 1.3 0.2 setosa
4 4 4.6 3.1 1.5 0.2 setosa
5 5 5.0 3.6 1.4 0.2 setosa
6 6 5.4 3.9 1.7 0.4 setosa
> summary(df)
ID Sepal.Length Sepal.Width Petal.Length
Min. : 1.00 Min. :4.300 Min. :2.000 Min. :1.000
1st Qu.: 38.25 1st Qu.:5.100 1st Qu.:2.800 1st Qu.:1.600
Median : 75.50 Median :5.800 Median :3.000 Median :4.350
Mean : 75.50 Mean :5.843 Mean :3.057 Mean :3.758
3rd Qu.:112.75 3rd Qu.:6.400 3rd Qu.:3.300 3rd Qu.:5.100
Max. :150.00 Max. :7.900 Max. :4.400 Max. :6.900
Petal.Width Species
Min. :0.100 setosa :50
1st Qu.:0.300 versicolor:50
Median :1.300 virginica :50
Mean :1.199
3rd Qu.:1.800
Max. :2.500
#样式4:读数+首行表头+","逗号分割+字符转因子factor
> df <- read.table("data.csv",header = T,sep=",",stringsAsFactor = T)
##读数+首行表头+","逗号分割+字符转因子factor
> head(df)
ID Sepal.Length Sepal.Width Petal.Length Petal.Width Species
1 1 5.1 3.5 1.4 0.2 setosa
2 2 4.9 3.0 1.4 0.2 setosa
3 3 4.7 3.2 1.3 0.2 setosa
4 4 4.6 3.1 1.5 0.2 setosa
5 5 5.0 3.6 1.4 0.2 setosa
6 6 5.4 3.9 1.7 0.4 setosa #请注意species结果与样式3中结果的差异
> summary(df)
ID Sepal.Length Sepal.Width Petal.Length
Min. : 1.00 Min. :4.300 Min. :2.000 Min. :1.000
1st Qu.: 38.25 1st Qu.:5.100 1st Qu.:2.800 1st Qu.:1.600
Median : 75.50 Median :5.800 Median :3.000 Median :4.350
Mean : 75.50 Mean :5.843 Mean :3.057 Mean :3.758
3rd Qu.:112.75 3rd Qu.:6.400 3rd Qu.:3.300 3rd Qu.:5.100
Max. :150.00 Max. :7.900 Max. :4.400 Max. :6.900
Petal.Width Species
Min. :0.100 setosa :50
1st Qu.:0.300 versicolor:50
Median :1.300 virginica :50
Mean :1.199
3rd Qu.:1.800 Max. :2.500 2 read.csv() #读取.csv格式数据,read.table的一种特定应用
read.csv() 读取逗号分割数据文件,read.table()的一种特定应用
默认逗号分割,header=T,stringsAsFactor = T
df <- read.csv("data.csv")
等同df <- read.table("data.csv",header = T,sep=",",stringsAsFactor = T)
read.csv(file, header = TRUE, sep = ",", quote = "\"", dec = ".", fill = TRUE, comment.char = "", ...)#实例
> df <- read.csv("data.csv")
#相当于df <- read.table("data.csv",header = T,sep=",",stringsAsFactor = T)
> head(df)
ID Sepal.Length Sepal.Width Petal.Length Petal.Width Species
1 1 5.1 3.5 1.4 0.2 setosa
2 2 4.9 3.0 1.4 0.2 setosa
3 3 4.7 3.2 1.3 0.2 setosa
4 4 4.6 3.1 1.5 0.2 setosa
5 5 5.0 3.6 1.4 0.2 setosa
6 6 5.4 3.9 1.7 0.4 setosa3 excel数据文件读取
这里只讲1种:readxl,其他excel数据读取方法可自行百度
install.packages("readxl")
library(readxl)
df <- read_excel("文件名",sheet=1)4 scan #类似read.table(),但比read.table更加灵活
scan(file = "", what = double(), nmax = -1, n = -1, sep = "", quote = if(identical(sep, "\n")) "" else "'\"", dec = ".", skip = 0, nlines = 0, na.strings = "NA", flush = FALSE, fill = FALSE, strip.white = FALSE, quiet = FALSE, blank.lines.skip = TRUE, multi.line = TRUE, comment.char = "", allowEscapes = FALSE, fileEncoding = "", encoding = "unknown", text, skipNul = FALSE)关于scan的相关参数介绍参照read.table
5 保存为.Rdata
通过save()函数保存为.Rdata文件,通过load()函数将数据加载到R中。
save() #保存数据
load() #加载数据
> a <- 1:9
> save(a,file='E://dumData.Rdata')
> rm(a) #将对象a从R中删除
> load('d://dumData.Rdata')
> print(a) [1] 1 2 3 4 5 6 7 8 96 write.table() #常用导出数据函数
write.table(x, file = "", append = FALSE, quote = TRUE, sep = " ", eol = "\n", na = "NA", dec = ".", row.names = TRUE, col.names = TRUE, qmethod = c("escape", "double"), fileEncoding = "")参数解释:
x: 要写入的对象,最好是矩阵或数据框。如果不是,它是试图强迫x到一个数据框。
file: 一个字符串命名文件或编写而打开的一个连接。 " "表示输出到控制台。
append: 逻辑。只有当file是一个字符串才相关。
如果TRUE,输出追加到文件;如果FALSE,任何现有文件的名称被摧毁
quote: 一个逻辑值(TRUE或FALSE)或数字向量。如果TRUE,任何字符或因素列将用双引号包围。如果一个数值向量,其元素为引用的列的索引。在这两种情况下,行和列名报价,如果他们被写入。如果FALSE,并没有被引用。
sep: 字段分隔符字符串。每一行x中的值都被这个字符串分隔开。
row.names: 表示x的行名是否与x一起写的逻辑值,或者是写行名的字符向量
col.names: 类似row.names。
实例
> x <- c (22,23)
> y <- c ("k", "j")
> f <- data.frame (x = x, y = y)
> f
# x y
#1 22 k
#2 23 j #以空格分隔数据列(默认),含行号(默认),含列名(默认),字符串带引号
> write.table (f, file ="f.csv") #以逗号分隔数据列,含行号(默认),含列名(默认),字符串带引号
> write.table (f,file ="f.csv", sep =",") #以逗号分隔数据列,不含行号,含列名(默认),字符串带引号
> write.table (f,file ="f.csv", sep =",", row.names = FALSE) #以空格分隔数据列,不含行号,不含列名,字符串带引号 > write.table (f,file ="f.csv", row.names = FALSE, col.names =FALSE) #以空格分隔数据列,不含行号,不含列名,字符串不带引号 > write.table (f,file ="f.csv", row.names = FALSE, col.names =FALSE, quote =FALSE) 7 CSV格式导出 #write.table的一种特定应用
通过函数write.csv()保存为一个.csv文件
write.csv() #保存为一个.csv文件
> x <- c(1:3)
> y <- c((1:3)/10)
> z <- c("R and","Data Mining","Examples")
> df <- data.frame(x= x,y= y,z = z)
> df
# x y z
#1 1 0.1 R and
#2 2 0.2 Data Mining
#3 3 0.3 Examples
> write.csv(df1,"E://dummmyData.csv",row.names = FALSE) 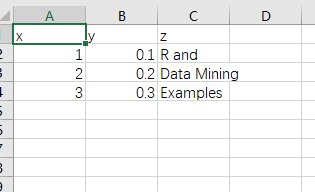
以上是一些常用的数据输入与输出方法
其他方法可自行百度或在R软件中使用“??函数名”获得帮助
【推荐书籍】