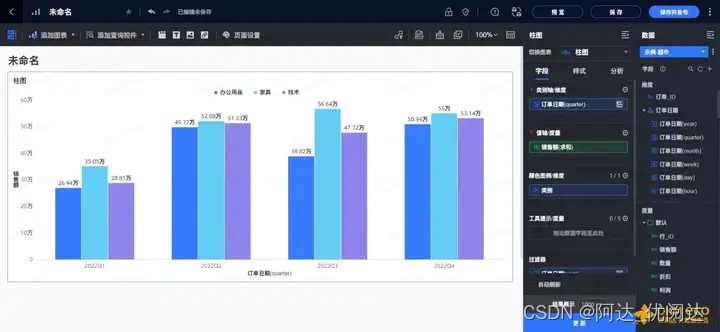
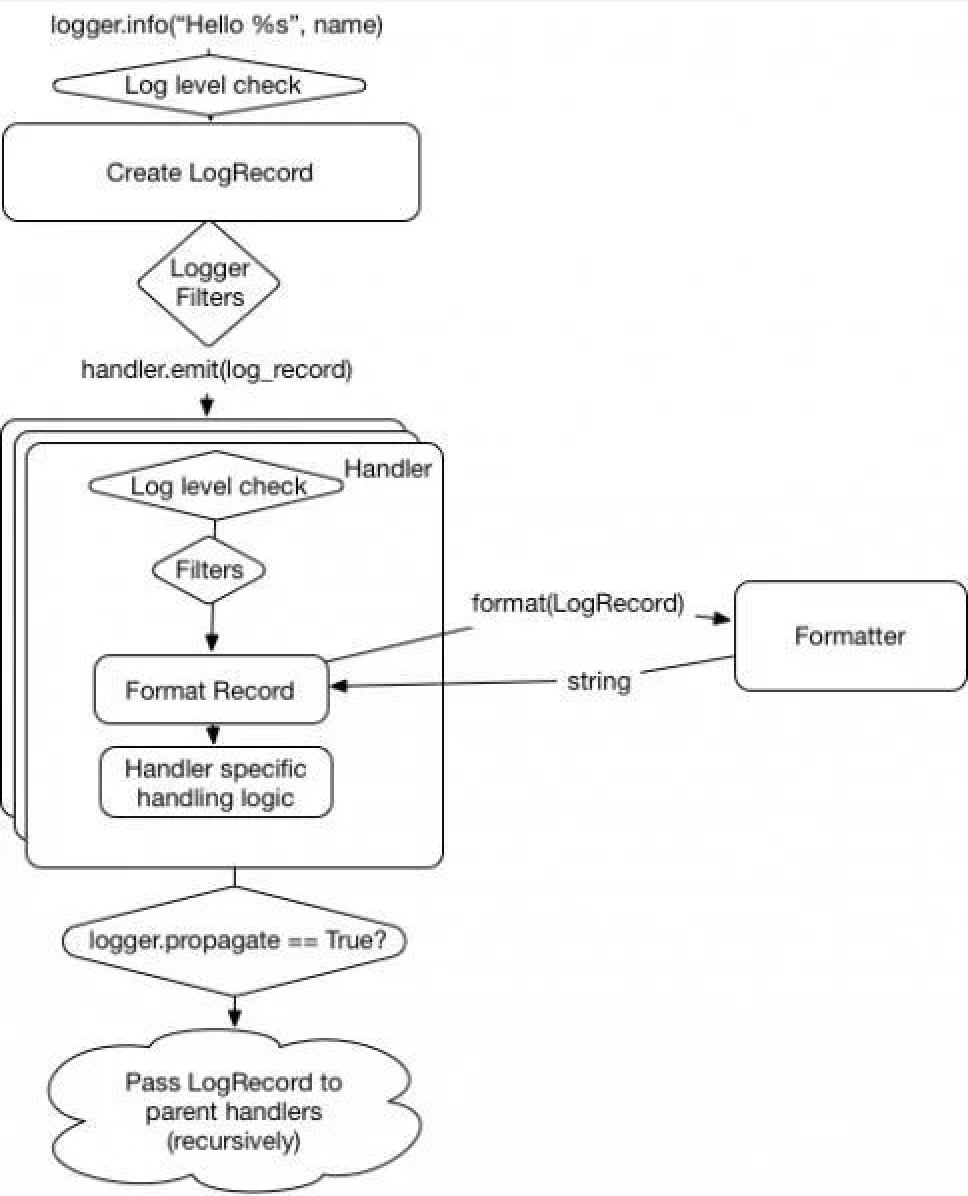
智谱公布的GLM-4-9B基于BFCL榜单的工具调用能力测试结果
©作者|格林
来源|神州问学
在智谱最新开源的GLM-4-9B-Chat中,其工具调用能力在BFCL(伯克利函数调用排行榜)榜上获得了超高的总BFCL分,和gpt-4-turbo-2024-04-09几乎不相上下。在榜单中,还提到了AST总分以及Exec总分两个得分,那么这两个得分有什么含义,又是如何计算的呢?
引言
智能体应用开发逐渐成为各大AI厂商应用开发平台不可或缺的一部分,不同平台会提供各类型的插件来拓展智能体的能力范围。随着能力的提升,模型能够完成并胜任的任务种类越发丰富,其中就包括了函数调用(Function Calling)的能力。我们可以看到,现在国内外许多模型厂商都在强化自家模型函数调用的能力,包括智谱最新发布的GLM-4-9B-Chat、百川的Baichuan4、阿里的Qwen系列、上海人工智能实验室的InternLM2等等。通过函数调用,模型能够用于作为智能体应用的核心驱动,成为自然语言到结构化工具调用之间的桥梁。然而,如何评价模型函数调用的能力,通过什么样的方法进行评测,目前业界依旧缺少相关的榜单和方法。前段时间,加州伯克利大学的研究团队公布了其评测模型函数调用能力的方法,以及对应的榜单。在这篇文章中,我们将解析这种评测方式,以及对应评测数据集的构建。

函数调用的大致工作流程
首先让我们回顾一下函数调用模型的原理:函数调用模型收到用户的提问(Query)以及函数列表(Function List),输出包含所选函数以及输入参数的JSON对象,随后在环境中执行这个JSON并获得对应函数输出参数,最终通过模型与用户提问进行整合并以自然语言的方式进行输出。
按照OpenAI的描述,函数调用的基本步骤顺序如下:
1. 基于用户问题和在“函数参数”中定义的一系列函数调用模型;
2. 模型选择调用一个或多个函数;模型将基于定义的函数输出字符串化 JSON 对象(可能会产生幻觉);
3. 在代码中将字符串解析为 JSON,并使用模型所写的参数调用该函数;
4. 通过将函数响应作为新消息附加来再次调用模型,并让模型将结果汇总回给用户;
函数调用模型最主要的是找到用户问题与选取函数+输入参数之间的对应关系,通过将用户的自然语言转换为API或者Python 函数之类的工具调用,让模型能够从外部获得对应的信息(例如从外部数据平台查询企业信息),或者是对外部环境产生影响(例如使用send_email函数发送邮件)等等。
Berkeley在函数调用方面的研究历史
在这次的AI浪潮中,加州大学伯克利分校一直在带给我们惊喜,从之前的Vicuna、Chatbot Arena、CRATE(Coding RAte reduction TransformEr)白盒大模型、SqueezeLLM 密集稀疏的新量化方法、vLLM 大模型推理系统、Dynalang 多模态世界模型,再到现在的函数调用模型、数据、评测、榜单一条龙,可谓是惊喜不断。在23年5月底,加州伯克利大学发布了函数调用专用模型Gorilla以及对应的APIBench数据集。Gorilla模型基于LLaMA-7B微调,能够生成{指令,API}对,使其具备使用工具的能力,并提供了与LangChain的结合样例。
在23年6月底的时候,Gorilla团队发布了Gorilla-CLI,让用户在CLI命令行中通过简单的自然语言能够生成几套候选的命令,用户可以从中选择并执行该命令;
https://github.com/gorilla-llm/gorilla-cli
![]()

在11月份,团队推出了第一代的Gorilla OpenFunctions,用户通过给出提问和 API,模型能够返回格式正确的函数调用。发布的模型包括v0和v1两个版本,v0主要基于LLaMA2-7B-Chat微调,只能基于单个API进行调用,而v1基于LLaMA2-7B基础模型微调,能从多个API中完成调用,输出带有正确参数的函数。
https://gorilla.cs.berkeley.edu/blogs/4_open_functions.html
今年2月份,退队推出了最新的Gorilla OpenFunctions-v2,基于Deepseek-Coder-7B-Instruct-v1.5 6.91B进行微调。训练集从不同来源总共采集了65,283 个问题-函数-答案对:来自不同云提供商的 Python 包(19,353)、Java 存储库(16,586)、Javascript 存储库(4,245)、公共 API(6,009)和命令行工具(19,090),并对这些数据进行了进一步的数据增强工作;与此同时,伯克利也公布了BFCL函数调用排行榜,从不同维度对一些常见的国外商用和开源模型进行了评测;
https://gorilla.cs.berkeley.edu/leaderboard.html

{Gorilla项目在Github上的更新}
在公布排行榜的同时,Gorilla团队也提出了一套针对函数调用的评测方式,其中包括两种方式来进行评测:判断生成的函数调用JSON文件是否符合预期的AST(抽象语法树)方法,或者根据JSON调用函数并对比运行结果和预期结果的Exec(运行结果)方法。
基于AST的评测方式
由于执行一个具体的函数可能会带来资源的消耗,并且在出现错误时难以追踪出错的步骤,因此AST法更加容易判断函数调用模型每一部分的正确率。AST评测方式通过一套多步骤的评估流程来在不运行API的情况下对函数调用的JSON文件进行评估。
总体来说,在模型生成函数调用的JSON文件之后,AST函数调用评估流程按步骤对其进行评估:
是否调用正确函数:
调用正确函数的能力涉及到模型的意图识别能力,简单讲就是根据用户输入的问题(Query)和自定义的函数列表(Function List)能否使用正确的函数来解决问题。
除此之外,还有更多意图识别的高级能力,例如多轮调用以及零调用。多轮调用之中还分为多种形式,包括在一次交互中直接生成多步调用,或者是在调用完成之后,根据输出结果进行下一步函数调用直到解决用户所提出的问题两种。零调用则指代的是函数调用模型能够根据情况选择不调用任何函数,直接以chat的方式完成与用户的交互。通常来讲,一些参数量较大,训练集中不止包括函数调用数据的模型可能会更加注重零调用的能力,目标是通过一个模型同时解决对话以及函数调用两方面的需求;

{Gorilla团队在训练OpenFucntions-V2还提出了平行调用以及相关性检测}
然而,虽然意图识别是大模型在最终到达AGI之前必须攻克的难关之一,函数调用模型的意图识别反而不是目前最受企业开发者关心的能力:在面对专业场景时,通常没有足够多的专业函数调用数据,只能通过非结构化的企业和行业知识文档来让通用模型获得一定的专业理解力,但可能仍然难以让模型找到用户问题和选用函数之间的对应关系,因此造成函数调用时准确率难以提升。为此,企业的解决方案通常会采用walkaround的方式,通过相似度算法、人工定义SOP或提示的方式给予函数调用模型指导,大幅减少对其自主调用函数的依靠,由此达到实际使用的准确率。
当然在未来,微调方法、模型能力或智能体框架更加强大的情况下,模型能够完全自主进行函数调用时,意图识别反而会成为函数调用模型最耀眼的能力。
是否填入必填参数:
除了调用正确的工具,FC模型还有另一项重要的能力是参数提取。模型依靠函数的名称和描述,基于用户提问以及其他上文内容为函数调用提供对应的参数。其中有些参数对函数调用的结果有较大的影响,因此设置为必需参数。在AST流程中,函数中包含“required” 的property标识的参数都必须存在于模型的输出当中。对于未在文中找到数值的可选(Optional)的参数,通常模型可以选用该参数的默认值,或者不提供参数值,两种方式都是正确的;
是否出现参数幻觉:
在实际场景中,我们观察到模型在函数调用时会出现特殊的幻觉,其中包括函数幻觉和参数幻觉两种:模型在选调函数时可能会使用不存在的函数,在填入参数的时候可能会填入非函数所需的参数。目前函数调用的幻觉仍然是较难解决的问题之一,通常是由于模型理解力不足或者训练数据的过拟合所导致,在要求高的场景中需要额外的审查环节。
参数类型是否一致:
函数所需的参数类型有多种选项,本身也是对模型如何提取参数的一种要求。为此参数类型的传递也是考察模型函数调用能力的一部分。目前大部分参数调用模型支持String、bool、int/float/long,部分还支持array/list/Tuple、Dict等等这些更复杂的数据格式。参数中使用复杂的数据格式通常会让函数调用的难度有所增加,在设计函数时尽量扁平化以降低填写参数的难度。
参数值是否一致:
在AST流程的最后,评测框架会对输入参数的数值进行评测,检查输入的参数值和答案是否一致。此处可以将参数值分为数值或文本。评判参数是否与答案匹配,可以基于不同的严格程度:
完全匹配:输出必须与预期结果完全匹配。1就是1,2就是2。
范围匹配:精确匹配的更宽松形式,仅适用于数值执行结果,其中执行结果必须在预期结果的一定百分比阈值(20%)内,以适应 API 响应的实时更新。答案是10的情况下,8也算正确。
结构匹配:输出必须与预期的数据类型匹配。例如, 如果预期类型为list ,则[1, 2, 3]和[1, 2.5, 6]均可接受。对于List,长度必须与预期长度匹配,不检查每个元素的类型。对于Dict,键必须与预期输出中存在的键匹配,但不会去检查每个值的类型。
总的来说,整套AST流程对以上五个方面进行评测,从而判断函数调用JSON是否合格:

{AST函数调用评估流程}
基于Exec的评测
在Exec类的评测方式中,会将生成的JSON文件传递到函数或API接口直接运行,直接对生成的结果来检查响应的正确性。
Non-REST方式评测
Non-REST方法执行涉及运行指定的函数并检查其输出,其评测方式和参数一致性评测的方式类似,可以基于完全匹配、范围匹配和结构匹配等严格程度对模型的执行结果进行评测,具体选取哪种取决于实际场景的需求:
REST方式评测
REST的评测方式主要评估API响应的结构:
有效执行:评估 API 调用执行的成功率。
响应类型准确性:确保 API 响应与预期结构(例如JSON)匹配。
JSON 密钥一致性:检查生成的响应和预期响应之间的 JSON 密钥集的一致性。
这种方式需要先收集标准答案的API响应并将其存储为 JSON 格式以供比较。基于API生成结果的多变性质,REST方法更加侧重于衡量结构不变性和执行是否成功,检查响应结构以及 JSON 密钥集的一致性, 而不是相对静态的标准答案值。
评测数据集的构建
数据集的配比
那么基于AST方法和Exec方法,在Gorilla OpenFunction-v2 中提出了新的函数调用评估数据集的构成方法,主要是从四个方面进行拓展:
● 多领域的函数类型
● 函数列表和函数调用对的数量
● 不同编程语言类型
● 可执行的真实世界示例
OpenFunction-v2的评估数据集主要来自网站爬取和生成,在通用评估中包含了 40 个函数子域。其中包括云和计算等数据丰富的领域中的表现,也包括在体育和法律等小众专业领域的表现。具体来说,伯克利函数调用排行榜(BFCL) 中包含了 2000 个问题-函数-答案对,其中包含多种编程语言和不同的应用领域,具体包括 100 个 Java、50 个 JavaScript、70 个 REST API、100 个 SQL 和 1,680 个 Python样例。
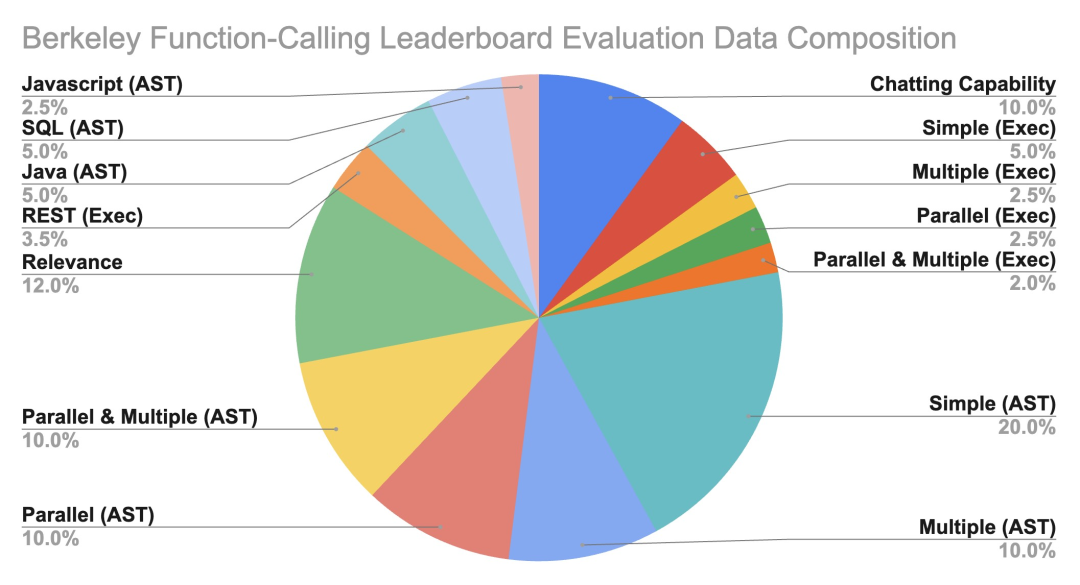
{BFCL排行榜评测数据构成}
评估包括python类的评估和非python类的其他评估方式:
Python类评估
Python类的评估方式包括:简单函数、复合函数、并行函数、以及结合的并行复合函数,每种都可用进行AST和Exec式的评测,由可用的免费REST API端点(例如天气预报)以及可计算的Python函数(例如线性回归算法)构成:
简单函数:单一函数评估包含最简单但最常见的格式,函数列表中只有一个函数,模型将调用一次这个函数并填入对应的参数,考察的主要是函数调用模型的参数提取能力。
多项函数:多项函数类别包含一个用户问题,函数列表中则包含2-4个可用函数列表。模型需要能够根据用户提供的上下文选择要调用的最佳函数。
并行函数:并行函数定义为对一个用户查询,基于一个提供的函数调用多次该函数。模型需要理解并决定需要进行多少次函数调用。
并行多重函数:并行多重函数是并行函数和多重函数的结合。换句话说,函数列表中包含多个函数,每个函数将被调用零次或多次。
非Python类评估
除了经典的函数调用场景以外,评测集中还包括了更多相关功能的测试,其中包括聊天功能、函数相关性检测、REST API、SQL、Java和Javascript:
聊天功能和相关性检测:部分场景会要求模型不调用任何函数或者纯粹以聊天机器人的方式进行回复。模型需要认识到提供的函数列表中的函数和用户提问都不相关并且不应当被调用。
REST API:在这个评估中,评测集通过给模型提供一个复杂的函数文档来让函数调用模型能够生成可执行的REST API,模型需要在URL中填入正确的参数或者把键/值对作为参数填入parameters或headers中。这种评测任务主要通过Exec的方法进行评测。
SQL查询:SQL 评估数据包括自定义的 sql.execute 函数,其中包含 sql_keyword、table_name、columns 和 conditions,这四个参数提供了构建简单 SQL 查询所需的信息。这种方法让函数调用模型能够在不针对SQL查询进行微调的情况下进行查询任务。SQL查询方面的评测也主要通过Exec的方式进行。
其他语言类型评测:尽管大多数语言的函数调用格式相同,但每种编程语言都有特定于语言的类型。例如,Java 有HashMap类型。这种方式考察该函数调用模型能否拓展到除了Python之外的代码语言;
结尾:函数调用模型能力维度梳理
在本文的结尾,基于函数调用的各类评测方法,我们也对函数调用模型各部分的能力维度进行了梳理,主要分为模型基础能力、模型函数调用能力、模型专业性以及推理经济这四个主要维度,以此可以评估员工模型在企业专业场景中函数调用的能力:
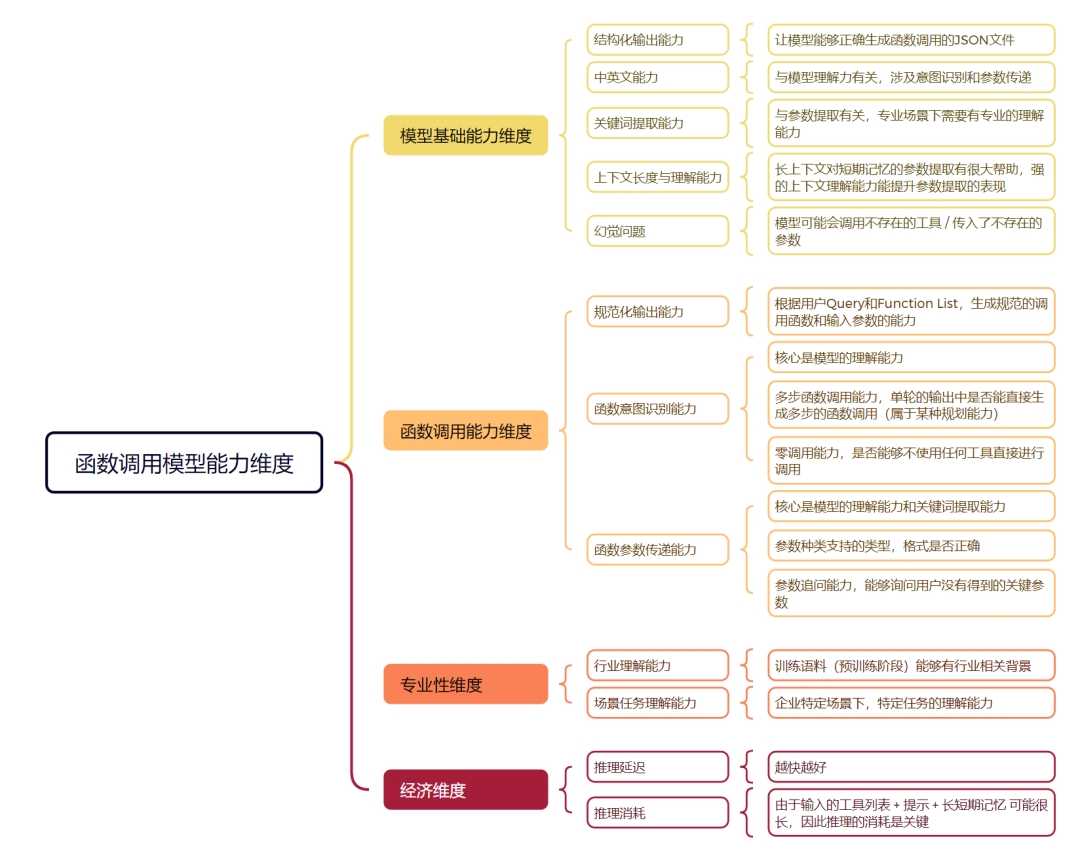
{企业专业场景函数调用模型能力维度}
智谱本次发布的GLM-4-9B-Chat 也在Github上再次强调了其强大的函数调用能力,基于BFCL排行榜。随着函数调用愈发受到人们的重视,我们或许能够看到更加丰富的智能体应用生态,包括更多强大的中文开源函数调用模型,来增强智能体应用的实际可用性。