山东青年政治学院毕业论文(设计)开题报告
| 学生姓名 | 高宜凡 | 学 号 | 202010520237 | ||
| 所在学院 | 信息工程学院 | 专 业 | 信息管理与信息系统(云计算与大数据技术) | ||
| 指导教师姓名 | 李海斌 黄虹 | 指导教师职称 | 工程师 副教授 | 指导教师单位 | 浪潮优派、信息工程学院 |
| 论文(设计)题目 | 基于K-means算法的电影票房的分析与预测 | ||||
| 开 题 报 告 内 容 | |||||
| 选题依据及研究内容(国内、外研究现状,初步设想及突破点;研究目标、预期成果,及可行性论述等) |
随着电影市场的不断发展和电影产业链的日益完善,电影票房成为了衡量电影市场表现的重要指标。通过对电影票房的数据分析和预测,可以帮助电影从业者更好地了解观众需求和市场趋势,从而制定更有效的营销策略和投资决策。K-means算法是一种常用的聚类分析方法,可以将数据集中的数据点划分为多个类别,并找到每个类别的中心点,以实现数据分类和模式识别的目的。因此,可以采用K-means算法对电影票房数据进行聚类分析,以揭示不同票房水平的电影特征和规律。电影行业是一个庞大而复杂的产业,了解电影票房的因素对于电影制片商、投资者和市场营销人员具有重要意义。K-means算法是一种常用的聚类算法,可以帮助我们从复杂的数据中发现潜在的模式和规律。通过应用K-means算法对电影票房进行分析,可以帮助电影产业相关从业者做出更明智的决策,提高电影的市场竞争力。通过结合人口统计数据和观影序列模式的分析,可以更全面地理解观众的偏好和行为模式,从而辅助电影票房的预测和分析。目标和研究问题也是确定影响电影票房的关键因素。通过对电影特征(如类型、演员阵容、导演等)、上映时间、宣传力度等因素进行聚类分析,找出与票房表现相关的特征。探索不同群组的票房表现差异。通过将电影分为不同的群组,比较各群组的票房表现,了解不同类型电影的市场需求和受众喜好。提供针对不同群组的推荐策略。根据不同群组的特征,制定相应的宣传和营销策略,以最大程度地提高电影票房。数据采集与预处理,收集包括电影类型、演员阵容、导演、上映时间、宣传资源投入等相关数据。对数据进行清洗和预处理,包括缺失值处理、异常值处理、特征标准化等。 二、国内外研究现状 1.国内研究现状 目前国内对电影票房的的分析已经取得部分的成果,包括电影票房的分析、电影的种类等,但单纯就电影票房的分析并不多,下面介绍一下国内电影票房推荐方面的一些研究成果: 邓有为[1]探究了基于K-means聚类的电影分类和评价方法。研究采用IMDB电影数据集,利用K-means算法对电影进行聚类,并使用SVM分类器对电影进行评分。孙明华和杨中伟[2]等利用该论文针对电影票房预测问题,提出了一种基于K-means算法的预测模型。研究通过对电影票房数据进行特征提取和处理,然后采用K-means算法对电影进行聚类,并利用线性回归模型对不同类别的电影进行预测。赵云飞[3]等,提取了电影类型、演员、导演等多个特征,并结合K-means算法、支持向量回归(SVR)和随机森林算法进行电影票房的预测。王晴[4]基于统计学习的方法对国产电影的票房进行了预测。研究中采集了大量的电影相关数据,包括电影类型、演员阵容、导演、评分等特征,并运用回归模型进行建模和预测。 并且对于电影票房预测分析,还有着一些专家的研究分析,《情报科学》杂志有一篇题为《基于聚类分析的电影票房预测方法研究》的文章,提出了一种基于K-means聚类算法的电影票房预测方法,该方法将电影按照特征进行分类,通过对不同类别电影的票房数据进行分析,得出了不同类型电影的票房趋势和规律。席一锴[5]基于机器学习算法对电影票房进行了预测。研究中使用了大量的电影相关数据作为特征,包括电影类型、导演、演员、评分等。并采用机器学习算法进行模型训练和预测。李小叶[6]大数据分析的方法对国内电影的票房进行了预测。研究中收集了大量的电影相关数据,包括电影类型、演员、导演、评分等特征,并利用大数据分析技术进行建模和预测。王超和杨鑫[7]使用了改进的K-means算法,提高了算法的预测精度。在《当代经济研究》中研究中国电影市场的票房波动,并采用K-means算法对票房数据进行聚类分析,结合其他影响因素,分析了不同类型电影的票房表现及其波动原因。 总体而言,在国内外研究中,K-means算法在电影票房分析中得到了广泛应用。研究者们通过将电影特征和观众信息等因素结合起来,利用K-means算法进行聚类分析,从而提高了对电影票房的预测准确性和有效性。然而,仍然存在一些挑战和待解决的问题,如如何选择合适的特征和合理设置聚类数目等,这些问题可以成为未来研究的方向。 2.国外研究现状 国外的电影票房分析还是存在很多的研究,Hu和Li[8]提出了一种综合应用机器学习和网络分析的方法来预测电影票房表现。他们采用K-means算法将电影分为不同的群组,并使用其他机器学习算法进行预测建模。研究结果显示,这种方法可以显著提高电影票房预测的准确性. Zhang[9]等利用K-means算法对电影进行聚类分析,并结合多种机器学习算法进行票房预测。研究结果表明,K-means算法可以有效地提取电影特征,提高票房预测的准确性和稳定性。 chen和liu[10]使用K-means算法来分析电影票房,并提出了一种基于该算法的电影票房预测模型。通过对电影特征进行聚类分析,结合历史票房数据,作者成功地预测了电影的票房表现。这些研究为电影行业提供了重要的参考和启示,有助于对电影市场进行更深入的分析和预测。 三、初步设想 基于K-means算法的对电影票房的分析预测,可以根据以下几个步骤来进行设想,分以下几步: 1.数据的采集 首先,需要收集包括电影的特征和票房数据的大量样本数据。这些特征可以包括电影的类型、导演、演员阵容、发行时间、评分等等。票房数据可以包括首周票房、总票房等。 2.数据的预处理 对收集到的数据进行预处理,包括数据清洗、缺失值处理、特征标准化等。确保数据的质量和一致性。 根据对电影票房的影响因素的理解,选择合适的特征,并进行必要的转换,如独热编码、标签编码等。 4.K-means聚类 将预处理后的数据应用于K-means聚类算法,将电影样本划分为不同的簇。K-means算法可以根据样本的特征相似性将其分组,形成不同的聚类。 5.聚类结果分析 对聚类结果进行分析,观察不同簇内的电影特征和票房表现。可以通过绘制柱状图、箱线图等方式展示不同簇的票房分布情况。 6.构建预测模型 对每个簇内的电影样本,可以构建相应的票房预测模型,如线性回归模型、决策树模型等。利用簇内的历史票房数据和其他特征,建立相应的预测模型。 7.预测与评估 使用构建的模型对新的电影样本进行票房预测,并与实际票房进行比较和评估。可以使用常见的评估指标,如均方根误差(RMSE)、平均绝对误差(MAE)等。 8.模型迭代优化 根据预测结果和评估指标,对模型进行迭代优化,例如调整特征选择、调整聚类数量、尝试不同的预测模型等。 四、突破点 突破点可以再这几个方面来说,特征选择:在进行电影特征提取时,如何选择更具有代表性的特征是一个重要的问题。可以考虑使用其他的特征提取方法,例如主成分分析(PCA)或独立成分分析(ICA),以更好地提取电影特征。算法优化:K-means算法有许多变体和扩展版本,可以尝试使用这些算法来改进电影票房预测的准确性和稳定性。例如,可以考虑使用层次聚类(Hierarchical Clustering)或谱聚类(Spectral Clustering)等算法。数据增强:在进行机器学习模型训练时,数据质量和数据量都会对模型的性能产生影响。可以考虑采用数据增强技术,例如数据扩增(Data Augmentation)或生成对抗网络(GANs)等方法,以增加训练样本数量或提高数据质量。 五、研究目标 可以理解票房影响因素,通过对聚类结果的分析,可以深入理解不同簇内的电影特征和票房表现。这有助于揭示出影响票房的关键因素,如电影类型、导演、演员阵容等,为制定更有效的票房策略提供指导。并且能够优化电影推荐,基于K-means的电影票房预测可以为电影推荐系统提供支持。通过将用户的观影历史数据与聚类结果相匹配,可以更准确地推荐符合用户口味和偏好的电影,从而提升用户体验和增加票房收入。 六、预期成果 利用这次的电影票房预测,可以做到预测精准度提高,通过对电影特征进行分析和挖掘,并为这些特征分配权重,基于K-means的方法可以提高模型的准确性和解释性,从而实现更精准的票房预测,能够更好的对观众口味和需求把握,基于K-means的方法可以帮助制片方和影院管理者了解观众喜好和口味,从而提供更符合观众需求的电影作品和观影体验。还能对宣传策略优化,通过了解不同类型电影的受众特征和偏好,基于K-means的方法可以更好地定位目标观众群体,并制定相应的宣传和推广计划,从而提高电影的知名度和票房表现。 七、可行性论述 基于K-means的电影票房预测是一种可行的方法。K-means是一种常用的聚类算法,可以将数据集分为多个簇,每个簇包含具有相似特征的样本。在电影票房预测中,可以将电影数据(如类型、演员、导演、宣传费用等)作为特征,使用K-means算法将电影划分为不同的簇,然后根据每个簇内电影的历史票房表现,对新电影的票房进行预测。 1.特征提取:通过分析和选择合适的电影特征,如演员、导演、电影类型、上映时间等,可以构建一个全面的特征集合。 2.数据准备:收集和整理历史电影数据,包括电影特征和票房数据。这些数据可以用于训练和验证模型。 3. K-means聚类:使用K-means算法对电影数据进行聚类,将电影分组为具有相似特征的簇。每个簇代表一类电影,具有类似的票房表现。 4.簇内票房分析:对每个簇进行票房分析,可以计算平均票房、最高票房等指标。这些指标可以作为该簇内电影票房的参考。 5.新电影预测:对于新电影,根据其特征将其归类到合适的簇中。然后,可以使用该簇内电影的历史票房表现来预测新电影的票房。 在社会层面: 1. 首先,随着互联网技术的不断发展和普及,电影产业已经成为了人们生活中不可或缺的重要组成部分。然而,对于电影制片方和电影院线来说,如何准确地预测电影票房,是一个非常重要的问题。这不仅可以帮助他们制定更加合理的营销策略,提高电影的市场竞争力,还可以为电影产业的健康发展提供有力的支撑。因此,基于K-means算法的电影票房预测在电影产业中有着广泛的应用前景。 2. 其次,基于K-means算法的电影票房预测可以通过聚类分析的方法,将大量的电影数据进行分类和归纳,从而揭示出影响电影票房的重要因素。这些因素可能包括电影类型、导演、演员阵容、评分等多个方面。通过分析这些因素之间的关系,可以建立相应的预测模型,更加准确地预测电影的票房情况。 尽管基于K-means的电影票房预测方法具有可行性,但需要注意以下几点:特征选择和数据质量:正确选择和处理电影特征对结果的准确性至关重要。同时,确保数据质量和完整性,避免噪声和缺失值对预测结果产生不良影响。模型的训练和验证:使用历史数据对模型进行训练和验证,确保模型具有较好的泛化能力,并能够在新电影上进行准确预测。神经网络等其他方法的比较:除了K-means,还有其他机器学习方法和深度学习模型可以用于电影票房预测。与K-means相比,这些方法可能具有更高的准确性和预测能力。总而言之,基于K-means的电影票房预测方法是可行的,但在实际应用中,需要综合考虑特征选择、数据质量、模型训练和验证等因素,并与其他预测方法进行比较,以获得更准确的预测结果。 | ||||
| 理论和实践 意义 | 理论意义: 1.聚类分析:K-means算法是一种常用的聚类算法,通过将数据集划分为多个簇,可以揭示数据内部的结构和相似性。在电影票房预测中,使用K-means可以将电影划分为具有相似特征和表现的簇,从而提供对电影市场的深入洞察。 2.特征选择和权重分配:通过对电影特征进行分析和挖掘,可以确定对电影票房影响较大的因素。基于K-means的方法可以帮助确定关键特征,并为这些特征分配权重,从而增加模型的准确性和解释性。 3.预测模型构建:基于K-means的方法可以作为电影票房预测模型的一种构建方式。通过对历史电影数据的分析和聚类,可以为新电影的票房预测提供参考和依据。这种方法不仅可以应用于电影行业,还可以拓展到其他领域的市场预测和商业决策中。 实践意义: 1.市场调研和投资决策:基于K-means的电影票房预测方法可以帮助电影制片方、投资者和市场调研机构对电影市场进行分析和评估。他们可以使用该方法来确定适宜的投资策略、评估电影潜在的票房表现,并预测电影的商业成功概率。 2.营销和宣传策略:基于K-means的电影票房预测可以为电影营销团队提供指导,帮助他们制定更具针对性的宣传策略。通过了解不同类型电影的受众特征和偏好,可以更好地定位目标观众群体,并制定相应的宣传和推广计划。 3.观众体验优化:电影票房预测不仅关注商业成功,也关注观众体验。基于K-means的方法可以帮助电影制片方和影院管理者了解观众喜好和口味,从而提供更符合观众需求的电影作品和观影体验。 | ||||
| 论文撰写过程中拟采取的方法和手段 |
| ||||
| 论文撰写 提 纲 | 第1章 前言 1.1研究背景 1.2国内外研究现状 1.3研究的目的及意义 1.4全文组织结构 第2章 相关技术介绍 2.1电影票房预测方法 2.2 python语言介绍 2.3 K-means算法介绍 第3章 数据集介绍 3.1数据采集 3.2数据集预处理 3.3特征选择 第4章 设计方法与实现 4.1电影票房预测模型 4.2数据融合 第5章 结果分析 5.1 K-means聚类分析结果展示 5.2电影票房预测模型性能评估 5.3预测结果的影响分析 5.4模型解释性分析 第6章 总结与展望 6.1总结 6.2展望 附录 参考文献 致谢 | ||||
| 计划进度 及其内容 |
| ||||
| 参考文献 |
| ||||



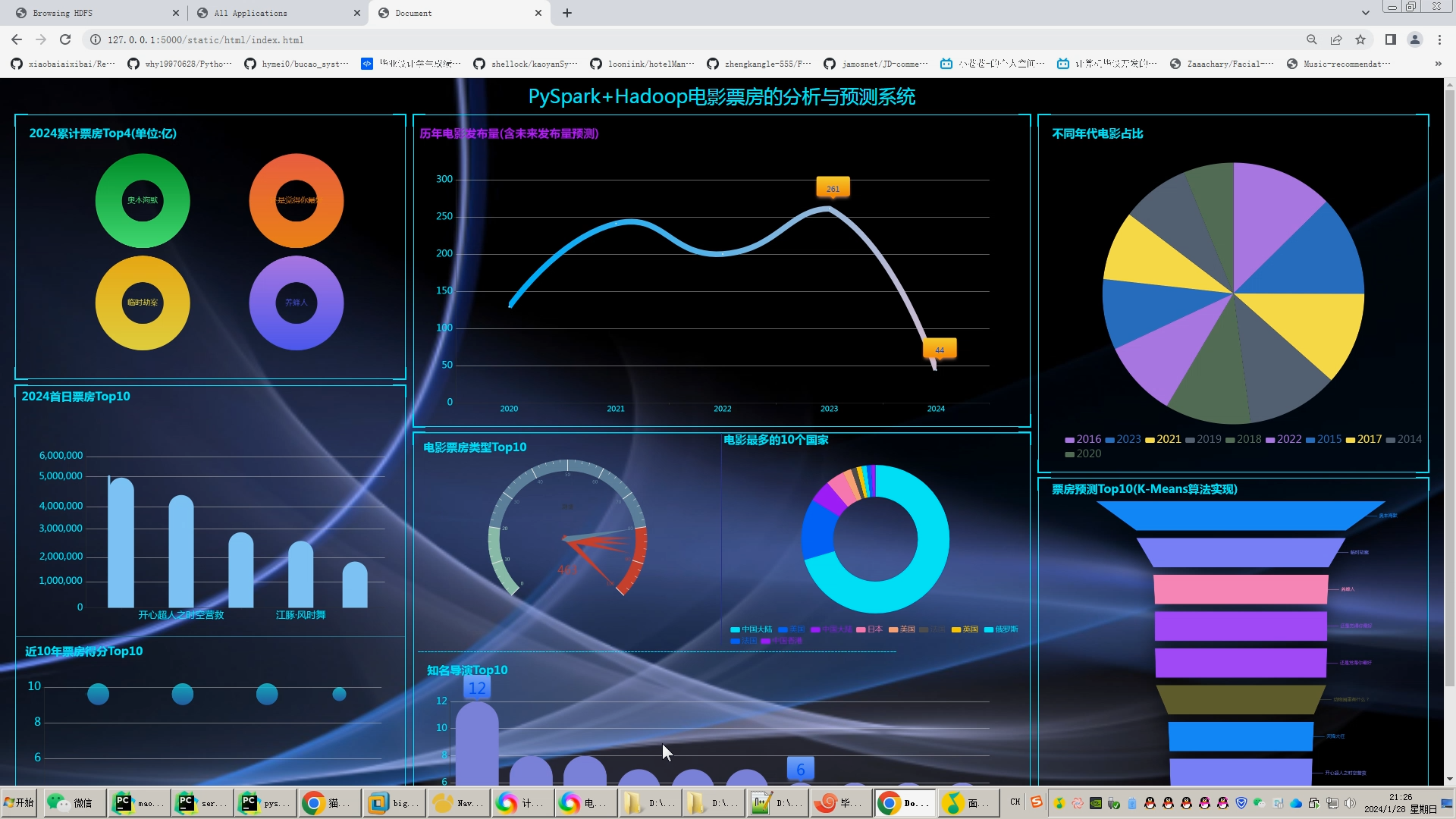

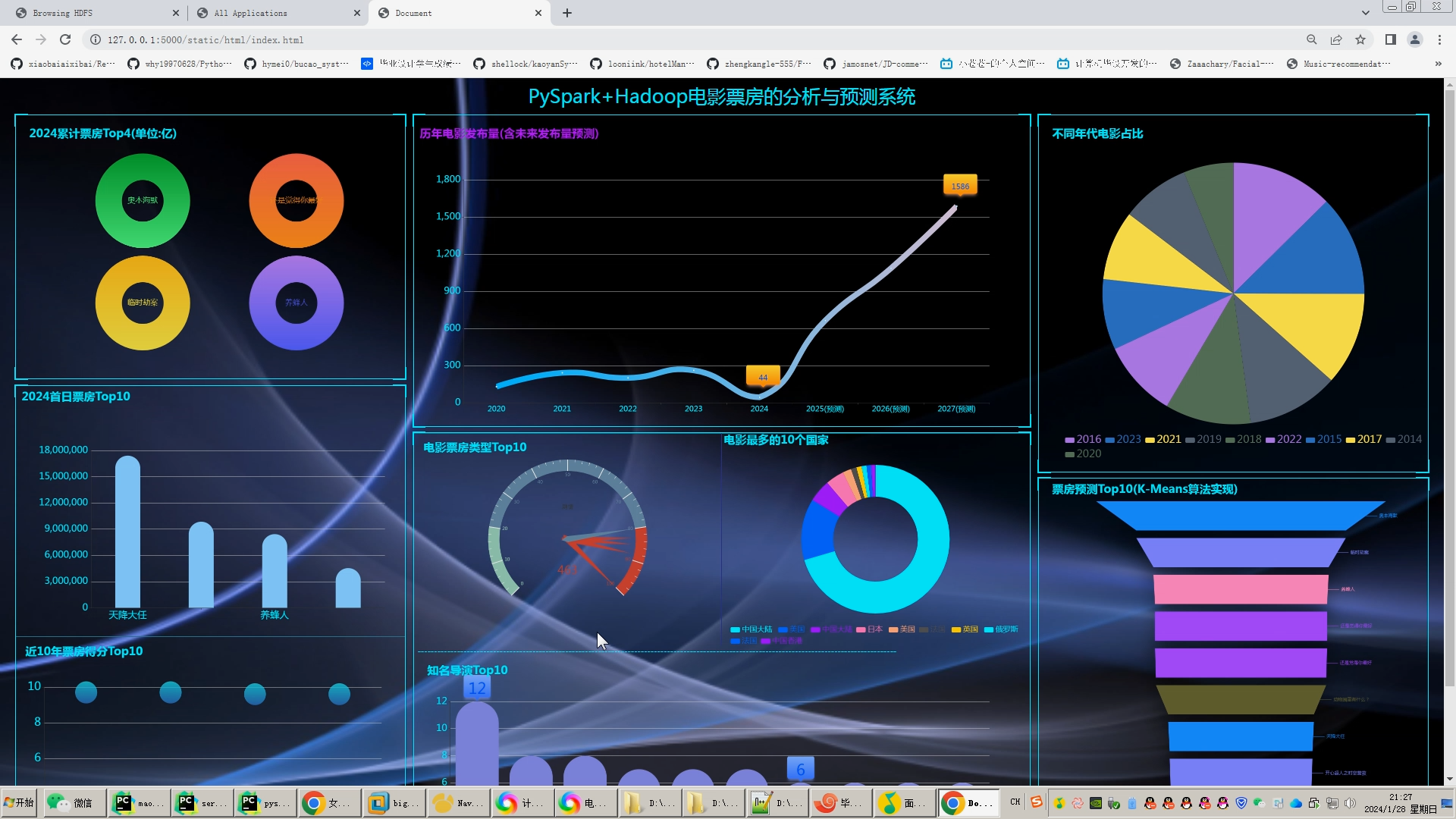
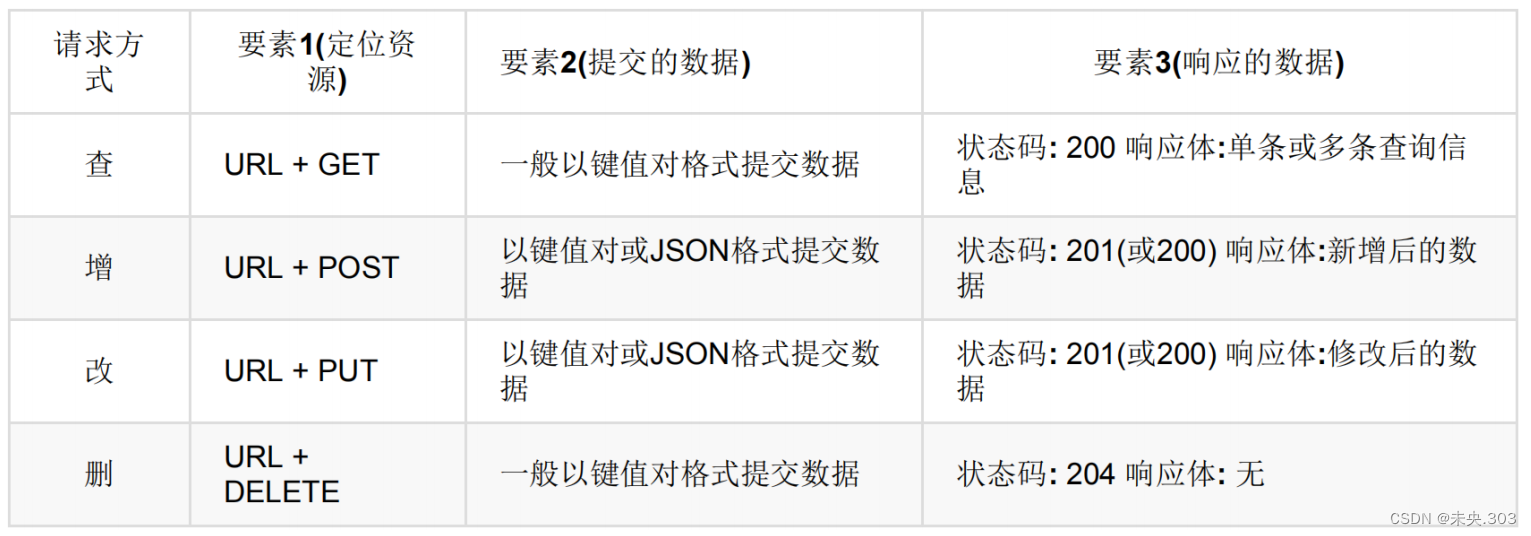
核心算法代码分享如下:
from flask import Flask, request, jsonify
import json
from flask_mysqldb import MySQL
import pymysql
# 创建应用对象
app = Flask(__name__)
app.config['MYSQL_HOST'] = 'bigdata'
app.config['MYSQL_USER'] = 'root'
app.config['MYSQL_PASSWORD'] = '123456'
app.config['MYSQL_DB'] = 'pyspark_movie2024'
mysql = MySQL(app) # this is the instantiation@app.route('/tables01')
def tables01():cur = mysql.connection.cursor()cur.execute('''SELECT * FROM table01''')#row_headers = [x[0] for x in cur.description] # this will extract row headersrow_headers = ['name','total_money'] # this will extract row headersrv = cur.fetchall()json_data = []#print(json_data)for result in rv:json_data.append(dict(zip(row_headers, result)))return json.dumps(json_data, ensure_ascii=False)@app.route('/tables02')
def tables02():cur = mysql.connection.cursor()cur.execute('''SELECT * FROM table02''')#row_headers = [x[0] for x in cur.description] # this will extract row headersrow_headers = ['name','day_total_money'] # this will extract row headersrv = cur.fetchall()json_data = []#print(json_data)for result in rv:json_data.append(dict(zip(row_headers, result)))return json.dumps(json_data, ensure_ascii=False)@app.route('/tables03')
def tables03():cur = mysql.connection.cursor()cur.execute('''SELECT * FROM table03''')#row_headers = [x[0] for x in cur.description] # this will extract row headersrow_headers = ['name','rate'] # this will extract row headersrv = cur.fetchall()json_data = []#print(json_data)for result in rv:json_data.append(dict(zip(row_headers, result)))return json.dumps(json_data, ensure_ascii=False)@app.route('/tables04')
def tables04():cur = mysql.connection.cursor()cur.execute('''SELECT * FROM table04 order by myear asc ''')#row_headers = [x[0] for x in cur.description] # this will extract row headersrow_headers = ['myear','num'] # this will extract row headersrv = cur.fetchall()json_data = []#print(json_data)for result in rv:json_data.append(dict(zip(row_headers, result)))return json.dumps(json_data, ensure_ascii=False)@app.route('/tables05')
def tables05():cur = mysql.connection.cursor()cur.execute('''SELECT * FROM table05''')#row_headers = [x[0] for x in cur.description] # this will extract row headersrow_headers = ['type','num'] # this will extract row headersrv = cur.fetchall()json_data = []#print(json_data)for result in rv:json_data.append(dict(zip(row_headers, result)))return json.dumps(json_data, ensure_ascii=False)@app.route('/tables06')
def tables06():cur = mysql.connection.cursor()cur.execute('''SELECT * FROM table06''')#row_headers = [x[0] for x in cur.description] # this will extract row headersrow_headers = ['nation','num'] # this will extract row headersrv = cur.fetchall()json_data = []#print(json_data)for result in rv:json_data.append(dict(zip(row_headers, result)))return json.dumps(json_data, ensure_ascii=False)@app.route('/tables07')
def tables07():cur = mysql.connection.cursor()cur.execute('''SELECT * FROM table07''')#row_headers = [x[0] for x in cur.description] # this will extract row headersrow_headers = ['director','num'] # this will extract row headersrv = cur.fetchall()json_data = []#print(json_data)for result in rv:json_data.append(dict(zip(row_headers, result)))return json.dumps(json_data, ensure_ascii=False)@app.route('/tables08')
def tables08():cur = mysql.connection.cursor()cur.execute('''SELECT * FROM table08''')#row_headers = [x[0] for x in cur.description] # this will extract row headersrow_headers = ['myear','num'] # this will extract row headersrv = cur.fetchall()json_data = []#print(json_data)for result in rv:json_data.append(dict(zip(row_headers, result)))return json.dumps(json_data, ensure_ascii=False)@app.route('/tables09')
def tables09():cur = mysql.connection.cursor()cur.execute('''SELECT * FROM table09''')#row_headers = [x[0] for x in cur.description] # this will extract row headersrow_headers = ['name','predict_total_money'] # this will extract row headersrv = cur.fetchall()json_data = []#print(json_data)for result in rv:json_data.append(dict(zip(row_headers, result)))return json.dumps(json_data, ensure_ascii=False)@app.route('/data',methods=['GET'])
def data():limit = int(request.args['limit'])page = int(request.args['page'])page = (page-1)*limitconn = pymysql.connect(host='bigdata', user='root', password='123456', port=3306, db='pyspark_movie2024',charset='utf8mb4')cursor = conn.cursor()if (len(request.args) == 2):cursor.execute("select count(*) from tb_movie");count = cursor.fetchall()cursor = conn.cursor(cursor=pymysql.cursors.DictCursor)cursor.execute("select * from tb_movie limit "+str(page)+","+str(limit));data_dict = []result = cursor.fetchall()for field in result:data_dict.append(field)else:myear = str(request.args['myear'])director = str(request.args['director']).lower()if(myear=='不限'):cursor.execute("select count(*) from tb_movie where director like '%"+director+"%'");count = cursor.fetchall()cursor = conn.cursor(cursor=pymysql.cursors.DictCursor)cursor.execute("select * from tb_movie where director like '%"+director+"%' limit " + str(page) + "," + str(limit));data_dict = []result = cursor.fetchall()for field in result:data_dict.append(field)else:cursor.execute("select count(*) from tb_movie where director like '%"+director+"%' and myear = '"+myear+"'");count = cursor.fetchall()cursor = conn.cursor(cursor=pymysql.cursors.DictCursor)cursor.execute("select * from tb_movie where director like '%"+director+"%' and myear = '"+myear+"' limit " + str(page) + "," + str(limit));data_dict = []result = cursor.fetchall()for field in result:data_dict.append(field)table_result = {"code": 0, "msg": None, "count": count[0], "data": data_dict}cursor.close()conn.close()return jsonify(table_result)if __name__ == "__main__":app.run(debug=True)