前言
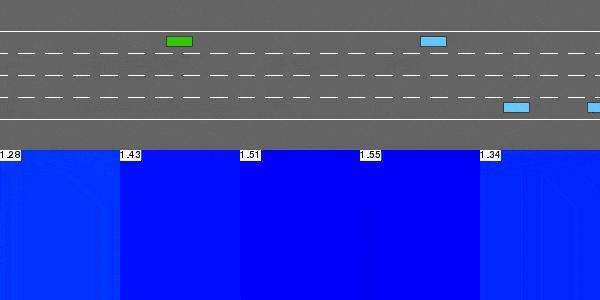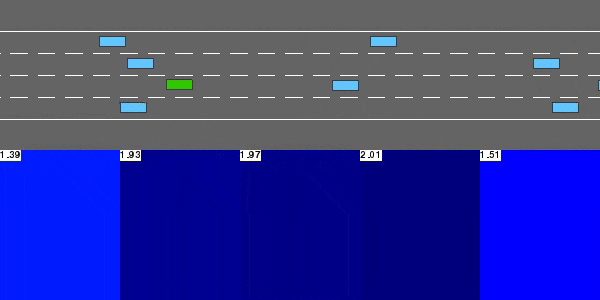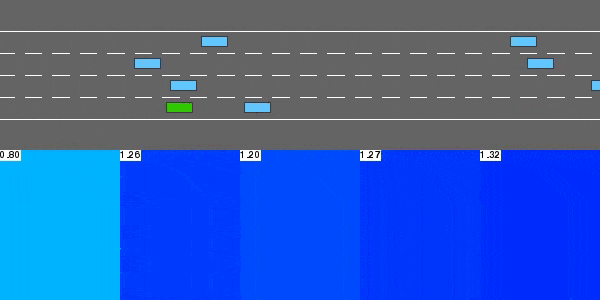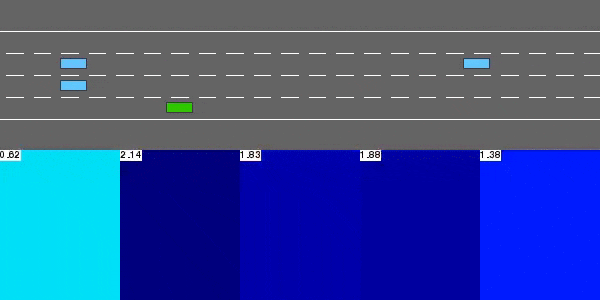
A high-level decision agent trained by deep reinforcement learning (DRL) performs quantitative interpretation of behavioral planning performed in an autonomous driving (AD) highway simulation. The framework relies on the calculation of SHAP values and takes into account neural architectures with attention layers. The framework is particularly dedicated to studying the relationship between attention and interpretability, and how attention and SHAP values can be represented, analyzed, and compared in a two-dimensional spatial highway environment. The framework has three main visualization areas, which are obtained by processing quantities of attention, SHAP values, vehicle observations, etc. : Episode View, which plots quantities on the timeline of the episode; Frame view, reporting measured values step by step; Aggregate view, which also displays statistics from aggregates of multiple simulated events on a 2D map.
LaneKeepingEnv环境的工作原理可以归纳如下:
- 初始化阶段:
- 环境在创建时,会调用
__init__方法进行初始化。 - 初始化过程中,会设置一些关键的属性,如
lane(当前车道)、lanes(所有车道的列表)、trajectory(车辆的轨迹)等。 - 环境的默认配置参数由
default_config方法定义,这些参数包括观测类型、动作类型、模拟频率等。
- 环境在创建时,会调用
- 配置参数:
- 观测类型设置为
"AttributesObservation",意味着环境会观察车辆的某些属性,如状态、状态导数和参考状态。 - 动作类型设置为
"ContinuousAction",并且指定了转向范围(在-π/3到π/3之间),这意味着控制输入是连续的转向角,不涉及纵向控制。 - 仿真频率和策略频率设置为10,表示每秒钟模拟10次并更新策略10次。
- 还包括了噪声水平、屏幕大小和居中位置等参数,这些参数可能与环境的渲染和可视化有关。
- 观测类型设置为
- 步进过程:
- 在每一步中,环境会调用
step方法。 step方法首先检查当前车辆是否仍在当前车道上。如果不在,它会从lanes列表中取出下一个车道,并设置为当前车道。- 然后,它会调用
store_data方法(尽管该方法在给定的代码片段中未定义),但通常用于存储或更新车辆的轨迹、状态等信息。 - 如果
lpv(可能是车辆控制器)存在,step方法会使用当前动作(控制输入)和车辆状态来设置控制器的控制参数。这里,控制器的控制输入只包括车辆状态的子集,如横向位置和速度,以及相对于车道的偏角和偏角速度。
- 在每一步中,环境会调用
- 控制和仿真:
- 车辆在
LaneKeepingEnv环境中的运动受控制器(如lpv)控制,控制器根据环境提供的观测数据和当前策略产生控制输入。 - 环境会根据控制输入和车辆当前状态更新车辆的位置和状态,并可能渲染车辆在新位置的状态以供观察或评估。
- 车辆在
- 总结:
LaneKeepingEnv环境通过模拟车辆在车道上的运动,提供了一个用于测试车道保持控制策略的平台。- 环境通过提供观测数据、处理控制输入和更新车辆状态来模拟真实世界中的车道保持场景。
- 通过与强化学习算法等结合,可以在该环境中训练和优化车道保持控制策略。
LaneKeepingEnv 环境通常包含以下几个功能模块:
- 初始化模块:
- 负责在环境创建时初始化所有必要的属性,如车道、车辆、观察空间、动作空间等。
- 调用
__init__方法进行初始化,并可能包括读取配置文件或默认配置来设置参数。
- 配置模块:
- 定义环境的默认配置参数,如仿真频率、观察类型、动作类型、噪声水平等。
- 通过
default_config方法提供默认配置,并允许用户通过配置字典来自定义参数。
- 物理模拟模块:
- 负责模拟车辆的物理行为,包括根据控制输入更新车辆状态(位置、速度、加速度等)。
- 可能使用车辆动力学模型(如
BicycleVehicle)来模拟车辆的横向和纵向运动。
- 车道模块:
- 定义和管理车道,包括直线车道和曲线车道(如
StraightLane和SineLane)。 - 提供检查车辆是否在车道内的方法(如
on_lane)。
- 定义和管理车道,包括直线车道和曲线车道(如
- 车辆模块:
- 定义和管理车辆对象,包括车辆的状态(位置、速度、加速度、偏角等)。
- 提供获取车辆状态、设置控制输入和更新车辆状态的方法。
- 观测模块:
- 根据配置的观测类型,提供从环境中获取观测数据的方法。
- 观测数据可能包括车辆的当前状态、状态导数、参考状态等。
- 动作模块:
- 定义动作空间,包括动作的类型(连续或离散)、范围和维度。
- 提供将原始动作转换为环境可以理解的格式的方法(如缩放、裁剪等)。
- 渲染模块(可选):
- 负责环境的可视化,包括渲染车辆、车道和其他相关元素。
- 提供渲染环境状态到屏幕或窗口的方法,以便用户或评估系统可以观察环境的状态。
- 数据存储模块(可选):
- 负责存储环境在仿真过程中产生的数据,如车辆的轨迹、状态、动作等。
- 提供存储和检索数据的方法,以便后续分析和评估。
- 交互模块(可选):
- 允许外部系统与环境进行交互,如接收控制输入、提供奖励信号等。
- 提供与环境交互的接口,如
step方法用于执行一步仿真并返回结果。
在LaneKeepingEnv环境中,模块之间的通讯通常通过函数调用和属性访问来实现。以下是一个简化的例子,说明这些模块如何相互通讯:
1. 初始化模块
- 功能:设置所有模块的初始状态。
- 通讯:
- 调用物理模拟模块的初始化函数,设置物理参数。
- 调用车道模块的初始化函数,创建初始车道。
- 调用车辆模块的初始化函数,设置车辆的初始状态。
2. 物理模拟模块
- 功能:模拟车辆的物理行为。
- 通讯:
- 接收来自车辆模块的车辆当前状态(如位置、速度、加速度)。
- 根据接收到的控制输入(来自动作模块)和车辆当前状态,更新车辆状态。
- 将更新后的车辆状态返回给车辆模块。
3. 车道模块
- 功能:管理车道信息。
- 通讯:
- 提供车道信息(如车道边界、车道中心线)给物理模拟模块,用于车辆状态更新。
- 提供检查车辆是否在车道内的方法给车辆模块或物理模拟模块。
4. 车辆模块
- 功能:管理车辆状态。
- 通讯:
- 提供车辆当前状态给物理模拟模块进行模拟。
- 接收物理模拟模块更新后的车辆状态,并更新自身状态。
- 提供车辆状态给观测模块,用于生成观测数据。
5. 观测模块
- 功能:根据配置生成观测数据。
- 通讯:
- 接收车辆模块提供的车辆状态。
- 根据配置(如观察类型、噪声水平等),生成对应的观测数据。
- 将观测数据提供给外部系统(如强化学习算法)。
6. 动作模块
- 功能:定义动作空间,处理原始动作。
- 通讯:
- 提供动作空间信息给外部系统(如强化学习算法),使其知道如何生成有效的控制输入。
- 接收外部系统生成的原始动作,并根据配置将其转换为环境可以理解的控制输入(如缩放、裁剪)。
- 将控制输入提供给物理模拟模块,用于更新车辆状态。
7. 渲染模块(可选)
- 功能:可视化环境状态。
- 通讯:
- 接收车辆模块提供的车辆状态。
- 接收车道模块提供的车道信息。
- 根据这些信息渲染环境状态到屏幕或窗口。
8. 数据存储模块(可选)
- 功能:存储仿真过程中产生的数据。
- 通讯:
- 接收物理模拟模块提供的车辆轨迹、状态等信息。
- 接收动作模块提供的控制输入。
- 将数据存储到文件、数据库或其他存储介质中。
9. 交互模块(可选)
- 功能:允许外部系统与环境进行交互。
- 通讯:
- 提供
step方法给外部系统,接收控制输入并返回下一步的观测数据、奖励等。 - 可能还需要提供其他接口,如重置环境、获取环境状态等。
- 提供
aneKeepingEnv类是一个用于车道保持控制任务的模拟环境,它继承自AbstractEnv类。车道保持是自动驾驶和车辆控制中的一个重要任务,它要求车辆能够保持在车道内行驶。
以下是该类的一些主要部分和功能的解释:
-
初始化 (
__init__方法):- 初始化环境时,它设置了几个关键的属性,如
lane(当前车道)、lanes(所有车道的列表)、trajectory(车辆的轨迹)、interval_trajectory(可能用于存储某个时间间隔内的轨迹)和lpv(可能是某种车辆控制器的引用,但从给出的代码片段中无法确定其完整含义)。
- 初始化环境时,它设置了几个关键的属性,如
-
默认配置 (
default_config方法):- 这个方法定义了环境的默认配置参数。这些参数包括观测类型、动作类型、模拟频率、策略频率、噪声水平、屏幕大小、缩放比例和居中位置等。
- 观测类型设置为
"AttributesObservation",并指定了要观察的属性(如车辆状态、状态导数和参考状态)。 - 动作类型设置为
"ContinuousAction",并指定了转向范围(在-π/3到π/3之间)和动作是否涉及纵向或横向控制(这里只考虑横向控制)。
-
步进 (
step方法):- 这个方法定义了环境在每一步中的行为。
- 首先,它检查当前车辆是否仍在当前车道上。如果不在,它会从
lanes列表中取出下一个车道,并设置为当前车道。 - 然后,它调用
store_data方法(该方法在给定的代码片段中未定义,但可能用于存储或更新车辆的轨迹、状态等信息)。 - 最后,如果
lpv(可能是车辆控制器)存在,它会使用当前动作(控制输入)和车辆状态来设置控制器的控制参数。这里,控制器的控制输入似乎只包括车辆状态的子集(从给定的代码来看,它只考虑了车辆的横向位置和速度,以及相对于车道的偏角和偏角速度)。
自动驾驶任务环境
- 公路驾驶:代理在包含多车道和其他车辆的高速公路上行驶,目标是保持高速并避免碰撞。
- 合并:代理在主干道上行驶时,需要为从入口匝道驶入的车辆腾出空间,确保安全合并。
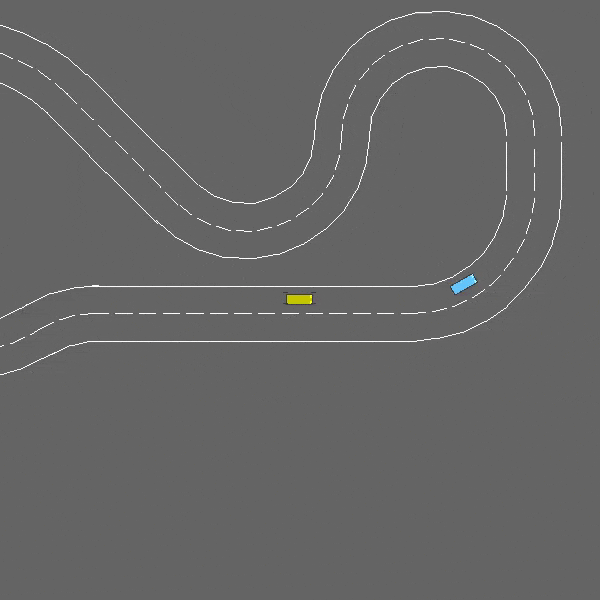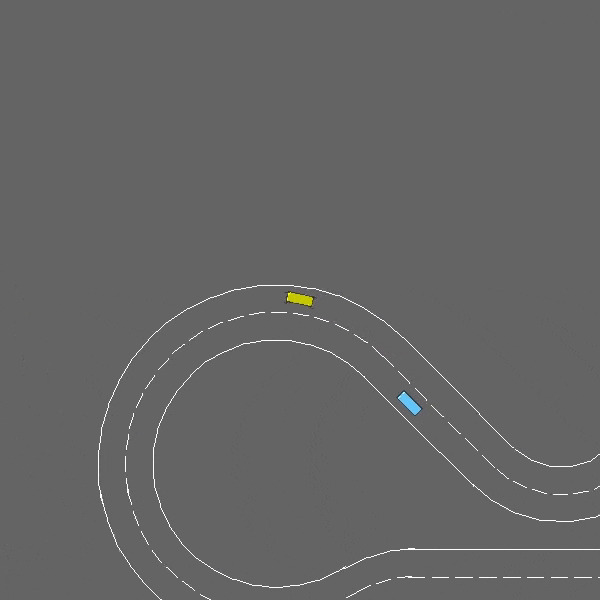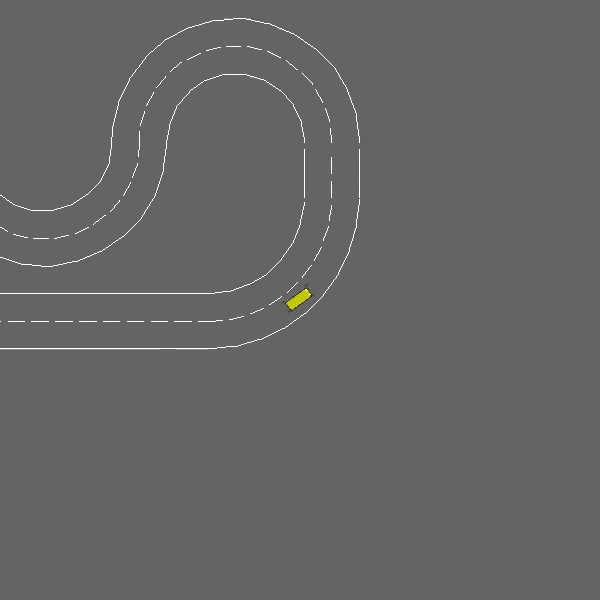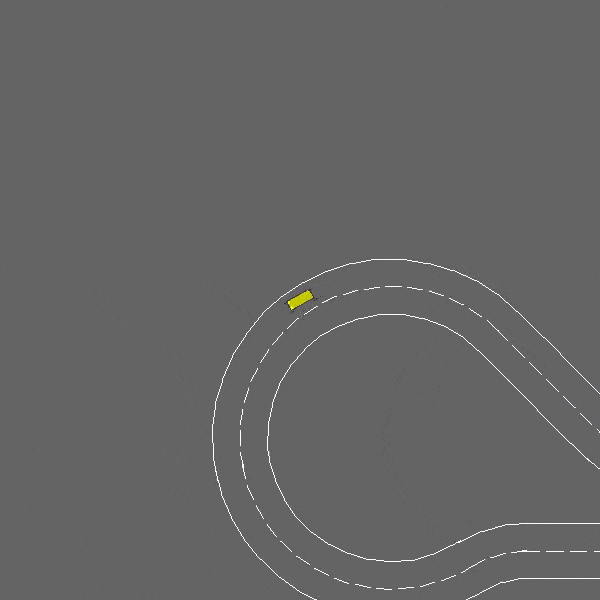
- 环形交叉:代理需要快速通过环形交叉路口,同时处理变道和纵向控制以避免碰撞。
- 停车:代理需要停在指定区域内,同时确保适当的航向。
- 路口:在交通密集的交叉口进行协商。
- 跑道:涉及车道保持和避障的连续控制任务。
代理类型
- 深度Q网络(DQN):使用神经网络表示状态-动作值函数Q,并通过Q学习进行训练。
- 深度确定性策略梯度(DDPG):基于策略的无模型强化学习代理,通过梯度上升进行优化,并使用经验回放来提高学习效率。
- 值迭代:与有限离散马尔可夫决策过程(MDP)兼容,通过简化状态表示和过渡模型来计算最佳状态-值函数。
- 蒙特卡洛方法:利用过渡和奖励模型执行最佳轨迹的随机树搜索。
框架特点
- 可视化:提供三种可视化区域(Episode View、Frame View、Aggregate View),用于展示注意力、SHAP值、车辆观测等信息的处理结果。
- 注意力与可解释性:研究注意力机制在提高代理决策可解释性中的作用,并通过SHAP值分析代理的决策过程。
- 环境多样性:支持多种自动驾驶任务环境,包括公路、合并、环形交叉等,以评估代理在各种场景下的性能。
深度Q网络(DQN)
深度Q网络(Deep Q-Network, DQN)结合了深度学习的感知能力和Q-learning的决策能力。DQN使用一个深度神经网络来近似Q值函数,从而能够在高维状态空间中学习有效的策略。
原理
- 神经网络:DQN使用一个深度神经网络来估计Q值,即给定一个状态s和一个动作a,网络输出一个Q值Q(s, a)。
- 经验回放(Experience Replay):DQN使用一个经验回放缓冲区来存储智能体的经验(状态、动作、奖励、下一个状态),然后从缓冲区中随机采样一批经验来训练网络。这有助于打破数据之间的相关性,使训练更加稳定。
- 目标网络(Target Network):DQN使用两个结构相同的网络,一个用于估计当前的Q值(当前网络),另一个用于估计目标Q值(目标网络)。目标网络使用旧的网络参数进行更新,而不是直接复制当前网络的参数,这有助于稳定训练。
import torch
import torch.nn as nn
import torch.optim as optim class DQN(nn.Module): def __init__(self, state_size, action_size): super(DQN, self).__init__() self.fc1 = nn.Linear(state_size, 24) self.fc2 = nn.Linear(24, 24) self.fc3 = nn.Linear(24, action_size) def forward(self, x): x = torch.relu(self.fc1(x)) x = torch.relu(self.fc2(x)) return self.fc3(x) # 实例化网络、优化器等
dqn = DQN(state_size, action_size)
optimizer = optim.RMSprop(dqn.parameters())
criterion = nn.MSELoss() # 训练步骤(此处省略)值迭代
值迭代是一种经典的强化学习算法,用于求解有限马尔可夫决策过程(MDP)的最优策略。然而,值迭代通常不直接使用深度神经网络,因为它基于表格形式的状态和动作值函数。但这里可以描述如何在简化后的状态空间中应用值迭代。
原理
- 状态表示:在自动驾驶中,状态可能包括车辆的位置、速度、周围车辆的位置和速度等。为了应用值迭代,需要将这些连续的状态空间离散化或简化为有限的状态集合。
- 值迭代更新:对于每个状态s,值迭代通过迭代地更新状态值函数V(s)来找到最优策略。更新公式通常基于Bellman方程。
# 假设已经定义了一个有限的状态集合states、动作集合actions、转移模型P和奖励函数R V = {s: 0 for s in states} # 初始化状态值函数为0 for _ in range(num_iterations): V_new = V.copy() for s in states: V_new[s] = max(sum(P[s][a][s_prime] * (R[s][a][s_prime]自动驾驶和战术决策任务环境的集合开发和维护.

环境
公路
在这项任务中,自我车辆在充满其他车辆的多车道高速公路上行驶。智能体的目标是达到高速,同时避免与相邻车辆发生碰撞。在道路右侧行驶也会触发。

此外,还提供更快的变体 ,其模拟精度降低,可提高大规模训练的速度。
合并
在这项任务中,自我车辆在主干道上起步,但很快接近入口匝道上驶入车辆的路口。代理商现在的目标是保持高速,同时为车辆腾出空间,以便它们可以安全地并入交通。

环形交叉
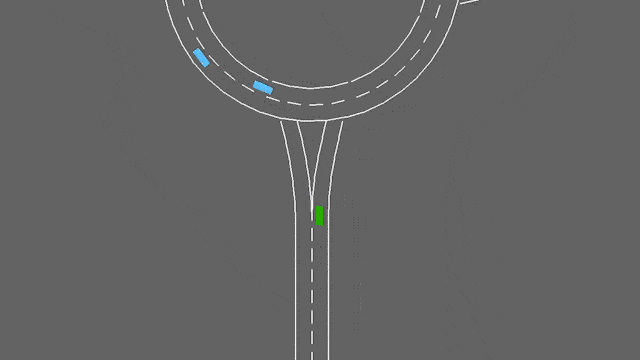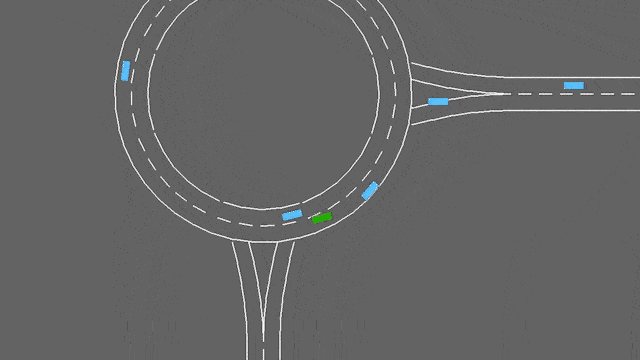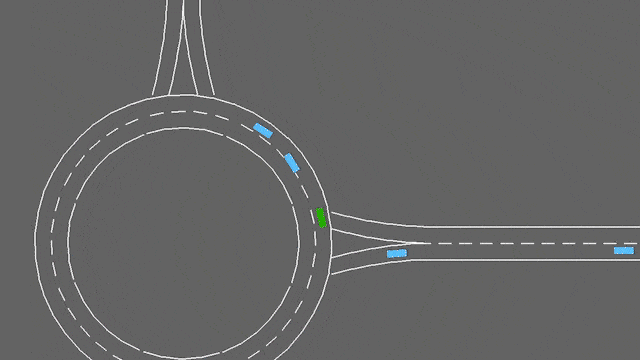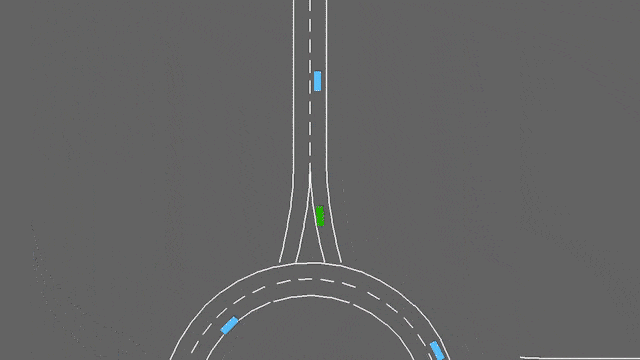
在这项任务中,自我车辆如果接近交通畅通的环形交叉路口。它将自动遵循其计划的路线,但必须处理变道和纵向控制,以尽可能快地通过环形交叉路口,同时避免碰撞。
停车
一项以目标为条件的连续控制任务,其中自我车辆必须以适当的航向停在给定的空间内。
路口
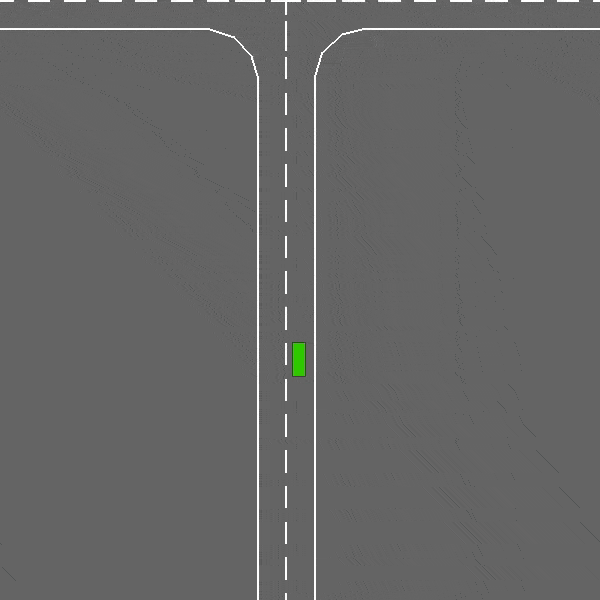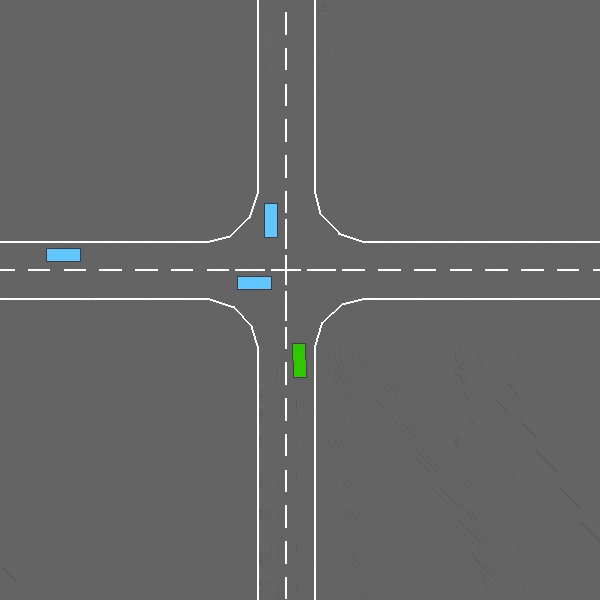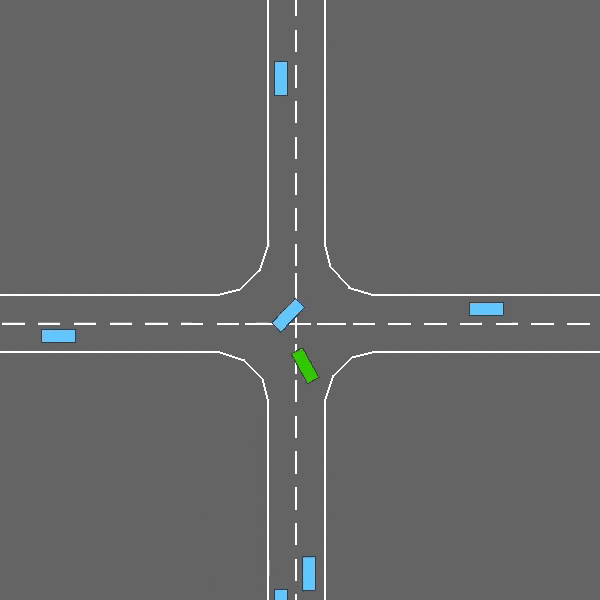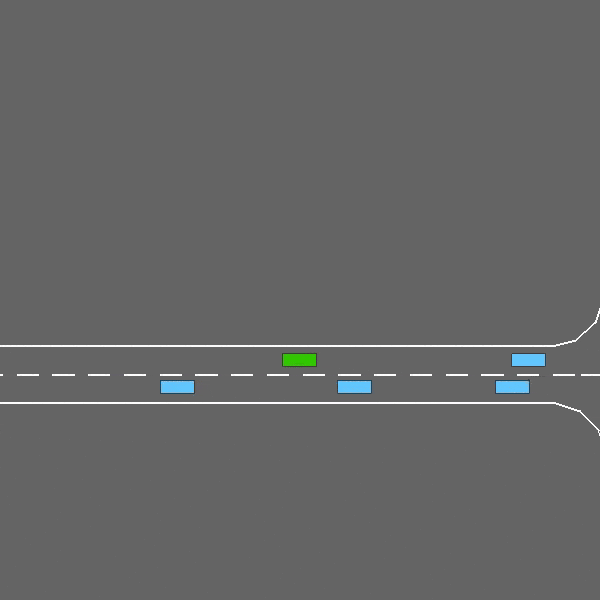
交通密集的交叉口协商任务。
跑道
涉及车道保持和避障的连续控制任务。
示例
深度Q
DQN
这种基于无模型值的强化学习代理使用神经网络来表示状态动作值函数 Q,通过函数近似执行 Q 学习。
深度确定性梯度

DDPG
这种基于策略的无模型强化学习代理直接通过梯度上升进行优化。它使用事后诸葛亮体验回放来有效地学习如何解决目标条件。
值迭代
值迭代
值迭代仅与有限离散 MDP 兼容,因此环境首先由 env_mdp() 的有限 MDP 环境近似。这种简化的状态表示根据道路每条车道上的预测碰撞时间 (TTC) 来描述附近的交通。过渡模型很简单,假设每辆车在不改变车道的情况下保持恒定速度行驶。这种模型偏差可能是错误的根源。
然后,代理执行值迭代以计算相应的最佳状态-值函数。
蒙特卡洛
该智能体利用过渡和奖励模型来执行最佳轨迹的随机树搜索。对状态表示或转换模型不需要特定的假设。

if self.speed_range:(self.controlled_vehicle.MIN_SPEED,self.controlled_vehicle.MAX_SPEED,) = self.speed_rangeif self.longitudinal and self.lateral:return {"acceleration": utils.lmap(action[0], [-1, 1], self.acceleration_range),"steering": utils.lmap(action[1], [-1, 1], self.steering_range),}elif self.longitudinal:return {"acceleration": utils.lmap(action[0], [-1, 1], self.acceleration_range),"steering": 0,}elif self.lateral:return {"acceleration": 0,"steering": utils.lmap(action[0], [-1, 1], self.steering_range),}