目录
前言:
1.IP协议
1.1.IP协议格式
1.2.网段划分
1.2.1.知识引入
1.2.2.IP地址划分和子网掩码
1.3.IP地址分类
1.3.1.特殊IP地址
编辑
1.3.2.私有IP和公网IP
1.3.3.浅谈NAT技术
1.4.路由
1.4.1.什么是路由
1.4.2.路由表
1.5.网络层数据切片和组装
2.NAT和NAPT技术
2.1.NAT
2.2.NAPT
2.3.存在的缺陷
3.代理服务器
3.1.正向代理
3.2.反向代理
3.3.NAT技术和代理服务器技术
前言:
网络层协议解决什么问题
当我们在上层实现了应用层协议将字符流数据转化为结构体数据,在传输层完成了通信的实现,数据的传输,但是数据最终还是得从本主机输出,从网络中进入到远端的另外一台主机。
- 网络层协议IP解决的就是两台主机间数据的转移,也就是提供了一种将数据包从一台主机送到一台主机的能力。
- 传输层协议TCP/UDP解决的是网络传输的可靠性,将数据传输到相应的应用程序
- 应用层协议HTTP/HTTPS解决的是将字节流数据转化为结构体数据

如图:主机B发送数据包经由若干个路由器最终到达主机C
基本概念
- 主机: 配有IP地址, 但是不进行路由控制的设备;
- 路由器: 即配有IP地址, 又能进行路由控制;
- 节点: 主机和路由器的统称
- 路由控制是路由器根据路由控制表转发数据包的过程。
1.IP协议
1.1.IP协议格式

32位源IP和目的IP
表示发送端的ip地址,和数据报文的目的主机地址。
4位版本
对应着IP协议版本
- IPV4(表示4个字节表示IP地址)
- IPV6(16个字节表示地址)
4位首部长度
和TCP协议的4位首部长度一致,单位也是4字节,大小最大为40字节
8位协议
用来识别数据报文是TCP协议还是UDP协议,防止不同类型的协议之间进行通信
16位总长度
表示整个报文的长度,并且已知报头长度固定为20字节,那么通过报文长度 = 报头长度 + 有效载荷长度,即可分离报文和报头
8位服务类型
用于数据包发送质量、效果优先级的选择。
- 3位优先权字段(已经弃用),4位TOS字段,和1位保留字段(必须置为0)。
- 4位TOS分别表示:最小延时,最大吞吐量,最高可靠性,最小成本。
- 这四者相互冲突,只能选择一个。对于ssh/telnet这样的应用程序,最小延时比较重要; 对于ftp这样的程序, 最大吞吐量比较重要。
8位生存时间(TTL)
报文在路径转发过程中,经由路由器的跳数上限(不允许报文在路径节点进行无意义的节点转换,造成资源的浪费)
16位标识、3位标志、13位片偏移
因为在网络层的下一层数据链路层,最大允许发出报文长度为MTU=1500,也就是网络层形成报文之后可能大小会大于MTU,这时候就需要进行分片、多次发送。
- 16位标识(id):唯一的标识主机发送的报文。如果IP报文在数据链路层被分片了,那么每一个片里面的这个id都是相同的(用来区分不同的报文)
- 3位标志字段:第一位保留(默认填0,暂时没有意义)。第二位置为1表示禁止分片,这时候如果报文长度超过MTU,IP模块就会丢弃报文。 第三位表示"更多分片", 如果分片了的话,最后一个分片置为1,其他是0。类似于一个结束标记.
- 13位分片偏移:是分片相对于原始IP报文开始处的偏移。其实就是在表示当前分片在原报文中处在哪个位置。实际偏移的字节数是这个值 * 8 得到的。因此,除了最后一个报文之外,其他报文的长度必须是8的整数倍(否则报文就不连续了)
1.2.网段划分
1.2.1.知识引入
IP地址分为两个部分, 网络号和主机号
- 网络号: 保证相互连接的两个网段具有不同的标识;
- 主机号: 同一网段内,主机之间具有相同的网络号,但是必须有不同的主机号;
例如本机ip地址为127.0.0.1,其中127.0.0.为网络号,1为主机号

如图: 路由器连接了两个局域网,而在同一个局域网,我们发现网络号是相同的,不同的是主机号,所以我们就能够通过IP地址定位到网络号和主机号,进而找到唯一的主机!!!
路由器的作用:
- 连接不同的网络
- 构建子网
- 进行数据包的路由和转发
1.2.2.IP地址划分和子网掩码
IP地址划分
在1.2.1.中我们知道IP地址划分成了网络号和主机号,保证在互相连接的网络中每一台主机的ip地址都不同,那么这时就会出现一个问题:网络号和主机号怎么设计,IP地址如何进行划分?

如图所示,为过去的一种IP地址划分的方案,为了应对不同的场景下(对应局域网的主机数量)的网络方案。
随着Internet的飞速发展,这种划分方案的局限性很快显现出来,大多数组织都申请B类网络地址,导致B类地址很快就分配完了,而A类却浪费了大量地址;
- 例如,申请了一个B类地址,理论上一个子网内能允许6万5千多个主机。A类地址的子网内的主机数更多。
- 然而实际网络架设中,不会存在一个子网内有这么多主句的情况。因此大量的IP地址都被浪费掉了。
我们也可以从网络的拓扑结构(两层)看出来,上述方案的IP地址利用率较低。

因此这样的固定长度划分方案,漏洞过大,并且当前国际上主流的IP地址版本为IPV4,即用4个字节(32位)来表示全球上的所有主机,理论上最多表示42亿台主机,所以IP地址也是一种资源,那么我们就需要采取其他方案在实现IP划分的同时,又保证IP地址利用率。
子网掩码
针对这种情况提出了新的划分方案,称为CIDR(Classless Interdomain Routing):
- 引入一个额外的子网掩码(subnet mask)来区分网络号和主机号;
- 子网掩码也是一个32位的正整数。通常用一串 "0" 来结尾;
- 将IP地址和子网掩码进行 "按位与" 操作,得到的结果就是网络号;
- 网络号和主机号的划分与这个IP地址是A类、B类还是C类无关;
值得一提的是:子网掩码以一串“1”开头,以一串“0”结尾。

如图:添加了子网掩码这个模块后,我们发现同一个IP地址转化后表示的子网内的地址范围存在不同,那为什么会导致这种不同呢?接下来我们通过下图来理解一下:

看到这里大家可能理解了子网掩码的作用,但是应该没有理解到它的魅力,那我们通过A类方案的子网掩码化来体会一下(实际上A类方案不进行子网构建,一般为B为方案):

对比原先的IP地址划分方案,我们发现网络拓扑:
- 原先的IP地址划分结构为:大网络->主机
- 添加子网掩码后:大网络->小网络->主机
所以我们实现了将没有利用到的主机号,转化成了“子网的网络号”,进而提升了IP地址的利用率。
1.3.IP地址分类
1.3.1.特殊IP地址
- 将IP地址中的主机地址全部设为0,就成为了网络号,代表这个局域网
- 将IP地址中的主机地址全部设为1,就成为了广播地址,用于给同一个链路中相互连接的所有主机发送数据包
- 127.*的IP地址用于本机环回(loop back)测试,通常是127.0.0.1

1.3.2.私有IP和公网IP
如果一个组织内部组建局域网,IP地址只用于局域网内的通信,而不直接连到Internet上,理论上使用任意的IP地址都可以,但是RFC 1918规定了用于组建局域网的私有IP地址的规则:
- 10.*,前8位是网络号,共16,777,216个地址
- 172.16.到172.31.,前12位是网络号,共1,048,576个地址
- 192.168.*,前16位是网络号,共65,536个地址
包含在这个范围中的,都称为私有IP(内网ip),其余的则称为全局IP(或公网IP)
我们的计算机是接入到运营商供给的私有网络的,而我们平时使用的云服务器就是公网IP。

如图:我们分层将广域网分为若干子网,然后子网接着划分为下一级子网,最终在连接上使用私有IP的主机,最终实现从广域网到局域网,从公有ip到私有ip。将子网划分提高了定位和查找主机的效率。
- 一个路由器可以配置两个IP地址,一个是WAN口IP,一个是LAN口IP(子网IP)
- 路由器LAN口连接的主机,都从属于当前这个路由器的子网中
- 不同的路由器,子网IP其实都是一样的(通常都是192.168.1.1),子网内的主机IP地址不能重复。但是子网之间的IP地址就可以重复了(只要WAN口IP不同即可区分)
- 每一个家用路由器,其实又作为运营商路由器的子网中的一个节点。这样的运营商路由器可能会有很多级,最外层的运营商路由器,WAN口IP就是一个公网IP了。
1.3.3.浅谈NAT技术
子网内的主机需要和外网进行通信时,路由器将IP首部中的IP地址进行替换(替换成WAN口IP),这样逐级替换,最终数据包中的IP地址成为一个公网IP。这种技术称为NAT (Network Address Translation,网络地址转换).
那么我们实际上进行网络通信时,数据报文在网络中是如何传送到服务器的呢?
首先内网IP不会出现在公网通信中,所以内网如果需要实现通信,就得一层一层通过路由器向上转发到运营商路由器中公网ip发送。并且向上转发时,需要将源IP替换成路由器的WAN口IP!!!这又是为什么呢?
因为路由器对应的子网IP不是表示当前路由器的标识,而是当前路由器的下一层子网的标识,而WAN口IP才是路由器网络中区分唯一路由器的标识!!!

这时我们就可以理解了NAT技术:逐级将当前的IP地址替换为当前对应的WAN口IP,直到转换为公网IP,也就是最上层的运营商路由器的WAN口IP。
1.4.路由
1.4.1.什么是路由
我们知道数据报文离开发送端后,并不是直接发送到接收端主机的,需要不断的通过中间节点(路由器)转发,不断路由直到到达接收端

- 路由的过程,就是这样一跳一跳 “问路” 的过程。
- “一跳”就是数据链路层中的一个区间。具体在以太网中指从源MAC地址到目的MAC地址之间的帧传输区间
在智能手机未普及的时代,人们去一个很远的地方,是需要进行不断的问路,一步一步的从一个终点走到一个新的起点,再继续问路,直到最后走到目的地。
IP数据包的传输过程也和问路一样:
- 当IP数据包,到达路由器时,路由器会先查看目的IP
- 路由器决定这个数据包是能直接发送给目标主机,还是需要发送给下一个路由器
- 依次反复,一直到达目标IP地址
1.4.2.路由表
既然在网络中,数据报文是通过路由器在主机之间进行转发的,那么就会出现一个问题:数据报文怎么知道自己要去往哪一个路由器进行路由转发呢?这时IP协议就规定了每一个路由器节点中必须维护一张路由表,当数据报文到达一个节点时,通过查询路由表来获取下一个路由器的IP地址。

如图:为某一个路由器主机的路由表。
- Destination:目的地址
- Gateway:下一条地址
- Genmask:子网掩码
- Use Iface:发送接口
数据报文在路由器转发的过程:

数据报文在网络中转发的过程本质是:通过不同主机的路由表,和子网掩码按位与接着从相应地址的接口传到下一个主机,再继续这个循环
我们可以借助:route命令来查看当前主机的路由表

1.5.网络层数据切片和组装
我们在1.1.中提及:16位标识、3位标志、13位片偏移这三个字段,并且我们提及了MTU,即Maximum Transmission Unit,最大传输单元,它是计算机网络中用于描述数据帧的最大长度的一个参数。所以数据切片是为了解决数据帧过大的问题!!!
那么网络通信的过程中是如何实现数据的切片和组装的呢?
切片规则:
- IP数据报文总大小为1500字节(包括20字节的固定报头)
- 当数据报文超过1500字节时,切片的第一片3位标志为001,并且13位片偏移量为0
- 切片的最后一片的3位标志为0,并且13位偏移量等于其他
如图:我们首先进行切片,因为MTU=1500,所以我们需要切成三片,接着将这三片数据传入数据链路层,最终发送到对端主机

而当我们在对端主机接收到许多数据帧,然后将帧头去掉后传到网络层后,我们如何找到这些切片后的数据报文,并把他们组装到一起?
组装规则:
- 必须按照顺序、并且组装完整成分片前的完整的IP数据报文
- 第一个切片的3位标志位001,并且13位偏移量为0
- 根据相同的16位标识来对分片的报文进行组装

通过图上这种方式,我们就可以分别找到若干个段切片后的IP报文,接着我们保留第一个切片的报头,把其他切片报头除去,按照顺序将切片的所有IP报文恢复成切片前的完整的IP报文,传到传输层中。这就是数据的组装。
从传输层数据大小设置来替代数据切片
然而我们不得不承认:切片并不是一个好的传输策略,首先切成若干份,可能会增加丢包的风险,这时就会导致数据的传输需要消耗更加多的资源,那么我们如何解决这个问题呢?
我们知道IP报文需要进行切片的根本原因就是:
- 数据链路层存在最大传输单元MTU
即IP层向下转发的数据报文过大,也可以说是传输层的TCP/UDP报文过大,那么我们就认为规定单次向网络层传输的字节数不超过 MSS = MTU - IP协议报头大小 - 以太网数据报头大小
这样我们就尽量避免了数据的切片和组装,但是实际应用上我们还是运行这种情况的出现……
2.NAT和NAPT技术
2.1.NAT
我们在1.3.3中提及了NAT技术是将内网IP通过局域网中的路由器在向上转发的过程中,一步一步地将内网IP转化为WAN口IP,最终以公网IP的形式进行通信。
这个技术的提出是为了:解决IPV4协议,IP地址数量不充足的问题。
- NAT能够将私有IP对外通信时转为全局IP。也就是就是一种将私有IP和全局IP相互转化的技术方法
- 很多学校、家庭、公司内部采用每个终端设置私有IP,而在路由器或必要的服务器上设置全局IP
- 全局IP要求唯一,但是私有IP不需要,在不同的局域网中出现相同的私有IP是完全不影响的
所以当我们将公网不断划分成子网,就可以在保证同一个子网不出现相同私有IP的情况下,在不同的子网中使用相同的私有IP。

但是我们回顾1.3.3.中是从子网向公网进行发送,我们实现NAT的转换,但是我们如何从公网来找到这个发送的主机,并发回数据报文呢?这时我们引入了NAPT技术……
2.2.NAPT
首先我们要找到这一台主机,我们可以反向地通过这个NAT路由器向下查找,但是同一时间下NAT路由器所构成的子网中会存在大量的用户在进行通信,我们怎么知道发往那个主机呢?所以与NAT技术不同的是,NAPT通过IP + 端口号来解决这个问题!!!
同一子网多主机发送情景:
在发送数据报文时,我们需要将子网IP通过路由器转为WAN口IP,这时我们发现我们可以借助子网主机IP地址+端口,就可以确定子网中唯一一个确定的进程(网络通信本质上是进程间通信),并且我们在NAT路由器中维护一张转换表,将“子网主机IP地址+端口+目的主机地址”映射为“NAT路由器IP地址+端口+目的主机地址”,显然这个在公网中也对应着唯一一个进程,此时我们就能够在多主机的情况下,对应不同的主机的不同进程。

从公网中获取信息:
我们已经完成了这个映射表的构建,当“进程”在公网间进行通信时,就是是再次通过这个映射表反向映射找到子网中的唯一一台主机的唯一一个进程,最终实现了通信。
不过值得一提的是:这个映射表中是互为KV结构的,也就是可以实现互相映射,在映射表中都是唯一的。并且如果同一个子网的不同的两台主机都用同一个端口号,这样映射到路由器时的端口号会出现不同。
2.3.存在的缺陷
- 无法从NAT外部向内部服务器建立连接,这也保证了在未建立连接之前,其他的主机无法对内网的主机发送消息
- 装换表的生成和销毁都需要额外开销
- 通信过程中一旦NAT设备异常,即使存在热备,所有的TCP连接也都会断开
3.代理服务器
3.1.正向代理
定义:
正向代理是一种代理服务器配置方式,它作为一个媒介,代表客户端与目标服务器进行通信。客户端通过正向代理发送请求,并将响应转发给客户端,伪装了客户端的真实身份。特点:
- 隐藏客户端身份:正向代理隐藏了客户端的真实IP地址和其他相关信息,提供了更高的隐私和安全性。
- 访问限制资源:正向代理的典型用途是为在防火墙内的局域网客户端提供访问Internet的途径,也可以用于访问原来无法访问的网络资源,如某些网站或服务。
- 缓存特性:正向代理还可以使用缓冲特性减少网络使用率,加速资源访问。
应用场景:
- 网络代理:访问原来无法访问的网络资源。
- 局域网代理上网:如局域网中电脑A可以上网,电脑B不能上网,可以将A作为代理上网服务,使B也能上网。
- 网关代理:对客户端访问授权,上网进行认证。
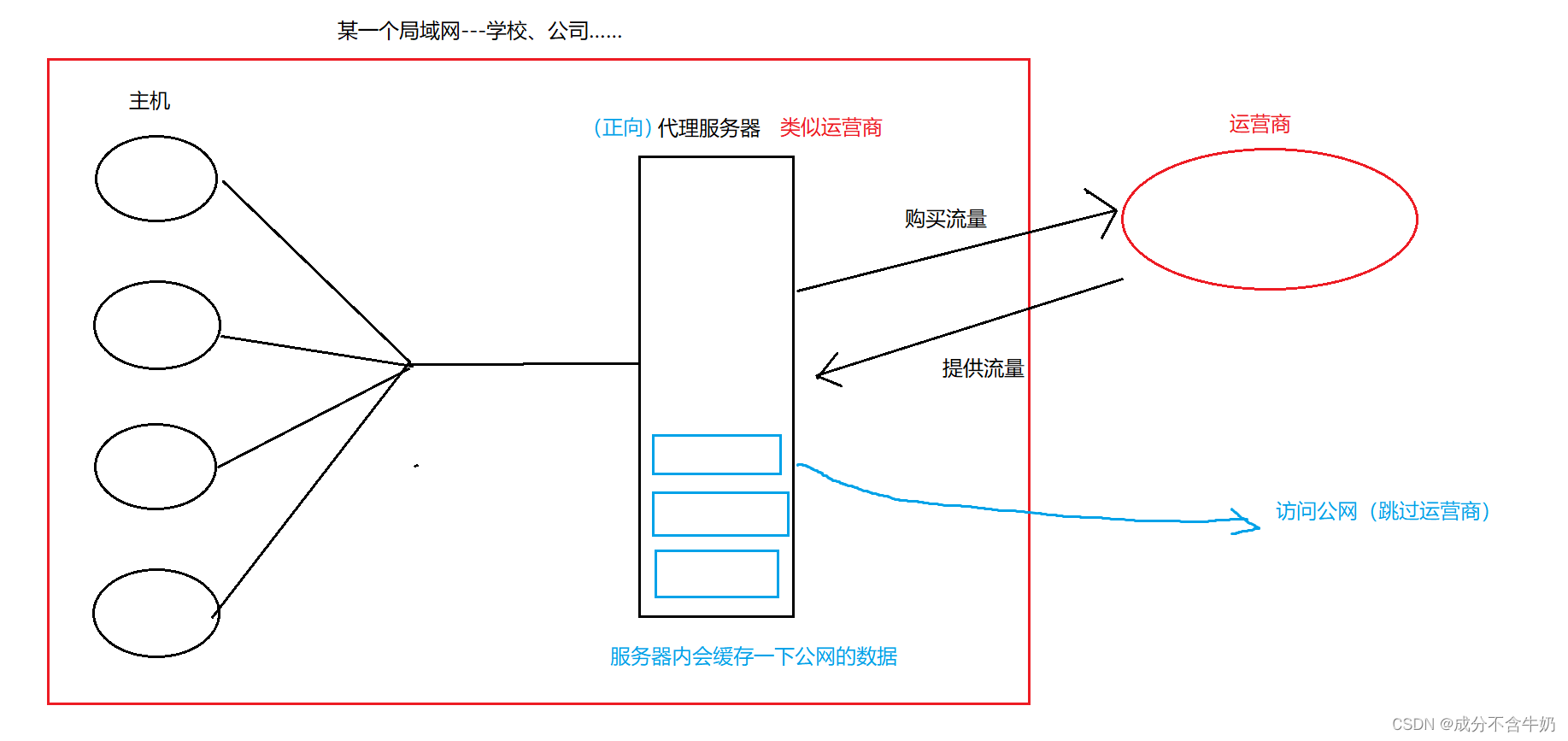
根据我们现实的例子,学校的局域网本质上就是使用了正向代理服务器的技术,能够缓存一些常被使用的数据,实现减少对同一份资源的访问需要不断的从公网中获取。并且可以便于管理用户的网络行为……
3.2.反向代理
定义:
反向代理是指用户不需要知道目标服务器的地址,也不需要在用户端做任何设定,可以直接通过访问反向代理服务器来获得目标服务器的资源。反向代理服务器位于用户与目标服务器之间,但对于用户而言,反向代理服务器就相当于目标服务器。特点:
- 提高安全性:反向代理隐藏了真实的服务器IP地址,提高了系统的安全性和隐私性。
- 加快访问速度:反向代理服务器通常可用来作为Web加速,即使用反向代理作为Web服务器的前置机来降低网络和服务器的负载,提高访问效率。
- 功能丰富:反向代理还可以实现负载均衡、安全防护、缓存、压缩、路由和SSL加密等功能。
应用场景:
- 服务器代理:保证目标服务器的安全,将反向代理服务作为公网访问地址,目标服务器是内网其他服务器。
- 负载均衡:通过反向代理服务器分发流量到多台服务器上,实现负载均衡,保证服务的可用性和稳定性。
- DNS服务:DNS可以映射1个或多个目标服务器。

关于反向代理服务器的例子:一般来说公司中会有许多的后端服务器来处理用户发出的网络请求,那么这时如果我们把所有的IP地址暴露给用户使用,第一是不方便使用,第二可能会出现某一项服务器得到较高的使用,而部分的服务器使用不频繁,也就是出现负载不均衡问题。这时我们构建一个承载量大的反向代理服务器,并只暴露这个服务器给用户,接着接收到用户请求之后均衡分配给后端的其他服务器来处理请求。这时我们就完成了负载均衡,与此同时我们也能够较好的保证了服务的安全性。
3.3.NAT技术和代理服务器技术
- 路由器往往都具备NAT设备的功能,通过NAT设备进行中转,完成子网设备和其他子网设备的通信过程
- 代理服务器看起来和NAT设备有一点像。客户端像代理服务器发送请求,代理服务器将请求转发给真正要请求的服务器。服务器返回结果后,代理服务器又把结果回传给客户端









![[消息队列 Kafka] Kafka 架构组件及其特性(二)Producer原理](https://img-blog.csdnimg.cn/direct/9ff2841fead74eefb58df0111529e074.png)