1. Baseline Test框架重构与完善
在之前的一篇博客中(创新实训2024.05.29日志:评测数据集与baseline测试-CSDN博客),我介绍了我们对于大模型进行基线测试的一些基本想法和实现,包括一些基线测试的初步结果。
后来的一段时间,我一直在试图让这个框架变得更加可用、可扩展、可移植,因为我们想加入更多的大模型(无论在线离线、无论哪个组织开源的、无论多少超参数)进行基线测试,以此更好地衡量我们自己微调并利用RAG技术接入知识库的大模型的性能。
在6.2号,我完成了对于基线测试框架的重构。在6.3号,我完成了对于Qwen-14B微调1000轮以及未微调的大模型接入知识库之后的基线测试。并且利用数据可视化脚本,绘制出了一份图形化报告。
1.1. 基线测试框架架构
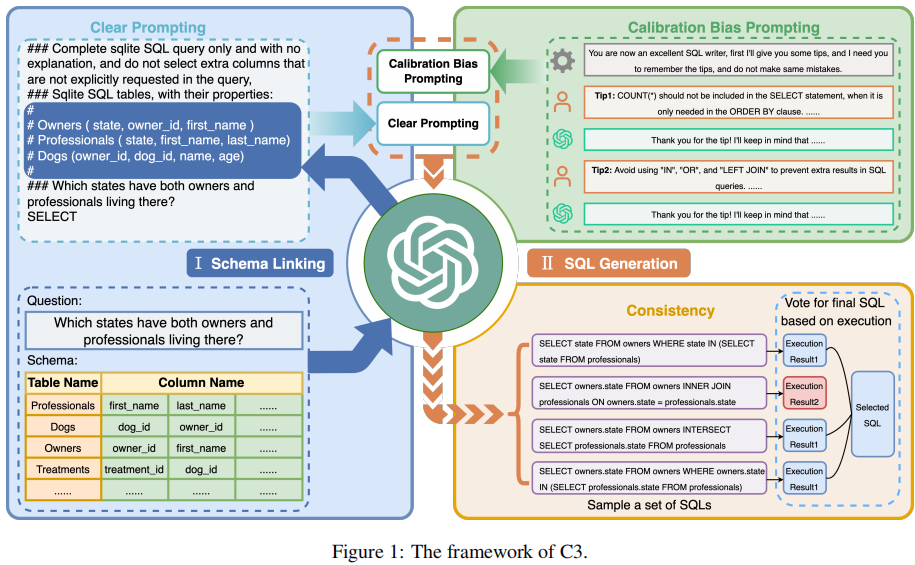
这里我绘制出了基线测试框架的类图于流程图。
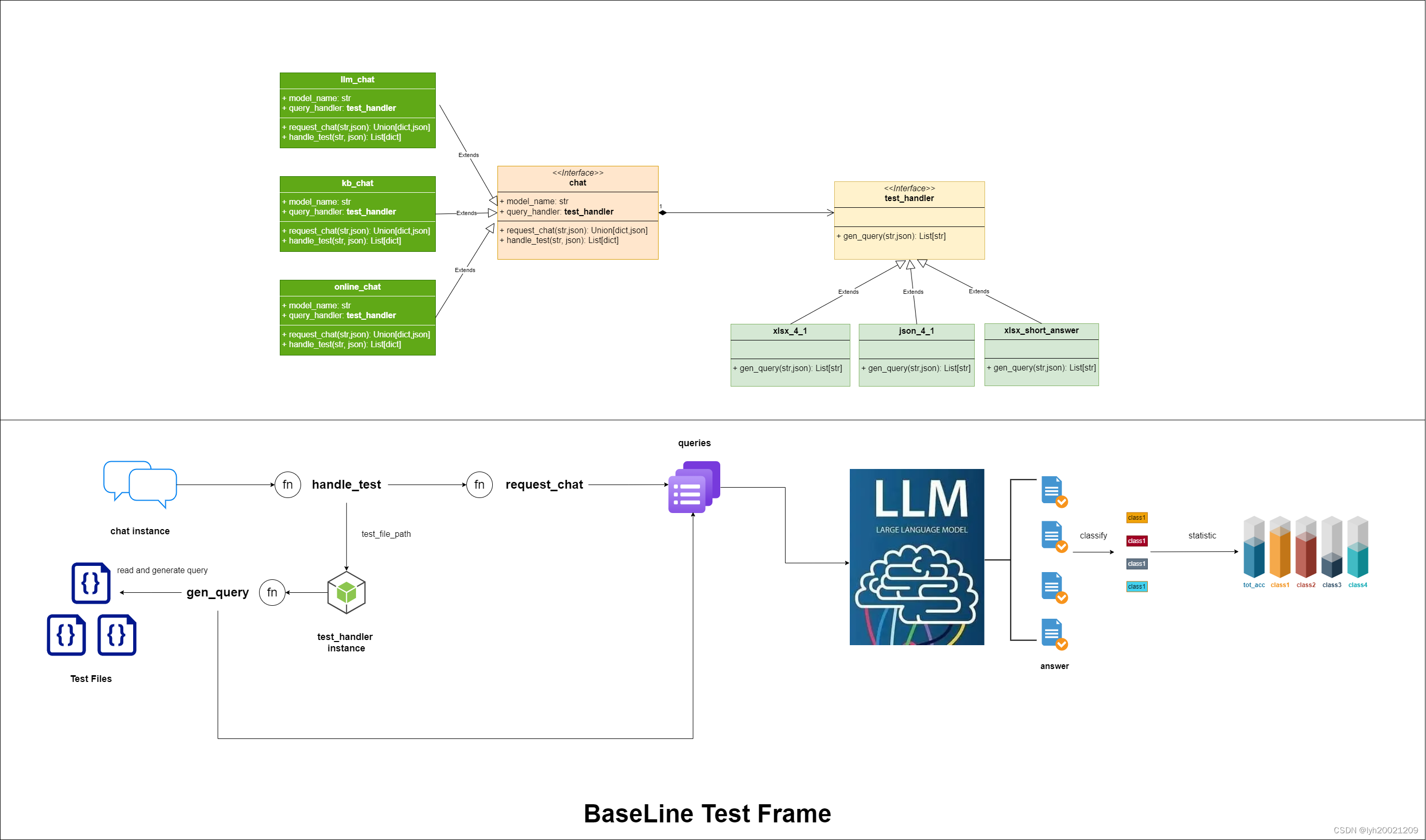
双击放大查看
首先先说类图:
- 对于每个大模型对话的抽象类chat的实现类的实例(我们将对这个实例输入一些基于评测集的问题,并让他产生回答,之后记录该回答),都组合了一个test_handler抽象类的实现类的实例,这个实例负责从某种指定类型的结构化文本中产生问题(比如从一个xlsx文件中产生问题)。
- 每个chat的实现类的实例都实现了一个抽象函数:request_chat,这个抽象函数接受一个字符串query,即test_handler的实现类产生的问题;以及一个json类型的对象,用以辅助设置与某一具体类型的大模型进行对话的配置参数。这个函数返回一个json和dict的Union类型(也即要么json要么dict),表示了大模型对某一个问题的回答,及其这个问题的其他参数。
- 此外,每个chat的实现类的实例都有一个公共的继承自父类的函数:handle_test,这个函数同样接受一个字符串file_path,用来标明评测数据集的路径;以及一个json对象,用来辅助设置从某一具体类型的评测集中解析得到问题的配置参数。这个函数返回一个dict的列表。也即通过request_chat请求大模型对话得到的所有回答的列表。
- 而chat类组合的test_handler,也有一个抽象函数:gen_query。它接受一个字符串file_path,这个参数来自handle_test函数。以及一个json对象,同样来自handle_test函数。返回一个字符串的列表,也即从评测集文本中解析并通过prompt模板建立起的所有问题的列表。
- chat可能会有多个实现类,例如:
- llm_chat:请求与某一离线大模型对话的实例(不接入知识库)
- kb_chat:请求与某一离线大模型对话的实例(接入知识库)
- online_chat:请求与某一在线大模型对话的实例(例如智谱AI的chatglm4)
- test_handler同样也可能有多个实现类,例如:
- xlsx_4_1:从一个xlsx文件中生成一个四选一的单项选择题
- json_4_1:从一个json文件中生成一个四选一的单项选择题
- xslx_short_answer:从一个xlsx文件中生成一个简答题
- 此外,chat的实现类的实例中,都包含有一个大模型名字的字符串,这个名字决定了我们最终在服务器上测试哪个大模型。
接着我们来说流程图:
- 首先初始化一个chat的实现类的实例(我们可以通过初始化一个chat的实现类的实例的列表,然后遍历这个列表得到一个个的chat的实现类的实例)
- 随后通过这个实例的handle_test函数,调用组合在这个实例中的test_handler的实现类的实例的成员变量。并将评测集路径以及配置的json对象传给他。
- 随后test_handler实现类的实例将通过gen_query函数,读取指定的评测集文件,随后迭代其中的每一行/每一个元素,根据prompt模板生成一个问题(字符串)的列表。
- 之后迭代这个问题的列表,将其中的问题一个个发送给大模型,请求大模型的回答。
- 得到所有回答后,我们保存成一个结构化文本。由于这些问题是带分类标签的(例如,卦辞、爻辞、卦间关系等等),我们可以基于标签将其分类,统计每一个分类下的正确率,随后进行图表的绘制。
这里我放一个简单的、对应于流程图的代码:
chat_list = init_model_chats() # init_model_chats函数负责初始化一个与大模型对话的实例的列表,其中每一个实例都是chat类的实现类的实例test_file_lists = init_test_files() # init_test_files函数负责生成一个元组的列表,其中每个元组的第一个元素是目标评测集的路径,第二个元素是目标评测集的配置参数for chat,index in enumerate(chat_list):answers = chat.handle_test(test_file_lists[index][0],test_file_lists[index][0]) # test_file_lists的各个元素和chat_list的各个元素相对应save(answers) # 将answers保存到指定路径statistic(answers) # 将answers进行分类统计(正确率),并保存到指定文件data_visualization() # 将结果进行数据可视化在这个init_model_chats()中,我都初始化了如下对话实例:
# 不带知识库m["llm_chat"] = [llm_chat("chatglm3-6b"), # 没微调大模型的llm_chat("Qwen-14B"), # 千问大模型llm_chat("Qwen-14B-ft-1000") # 千问微调1000轮]# 带知识库m["kb_chat"] = [kb_chat("chatglm3-6b"), # glm3-6b没微调kb_chat("yizhou-ft-3"), # glm3-6b微调3轮kb_chat("yizhou-ft-30"), # glm3-6b微调30轮kb_chat("yizhou-ft-50"), # glm3-6b微调50轮kb_chat("yizhou-ft-100"), # glm3-6b微调100轮kb_chat("Qwen-14B"), # 千问大模型kb_chat("Qwen-14B-ft-1000") # 千问1000轮微调]# 在线大模型m["online_chat"] = [zhipu_ai(configuration, "zhipu_ai")]参数配置如注释中所述
1.2. 一些额外的机制
此外,我还加入了一些额外的机制,以便更好地集成测试各个大模型,包括:
- 请求前切换大模型机制
- completion机制
- prior best机制
- label机制
切换大模型机制
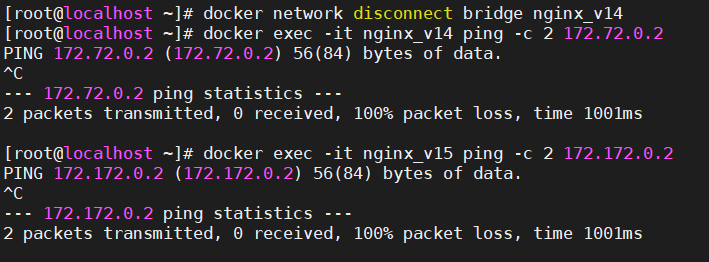
对于不同大模型(即便是同一个组织开源的大模型),在进行对话前,我们要对他进行切换(也即切换到这个大模型上),否则如下图所示,无法对话:
因此我在每次遍历大模型对话实例列表时,都会切换当前对话大模型到这个大模型上:
if model_name in config["test_args"]["release_name"]: # 需要主动切换模型flag = release_models(config["test_args"]["release_name"][model_name],config["test_args"]["release_url"])其中这个release_model,就是调用集成框架中的切换大模型的接口,进行大模型切换:
def release_models(model_name: str, release_url: str) -> bool:try:data = {"new_model_name": model_name,"keep_origin": False}response = requests.post(url=release_url, json=data)sleep(360) # 异步响应print(f'切换大模型至{model_name}的响应为:{response.text}')if "msg" not in response.json():return Falsereturn Trueexcept Exception as e:print(f'{e}')return Falsecompletion机制
我在测试过程中遇到过这样一种问题:之前的大模型已经进行过多次测试了,现在又要集成进来新的大模型进行测试,难道还要把之前测过的大模型全部测试一遍吗?
因此我选择在配置文件里加入对这些大模型评测情况的控制,如下:
"completion": {"llm_chat": {"chatglm3-6b": true,"yizhou-ft-100": true,"yizhou-ft-50": true,"yizhou-ft-30": true,"yizhou-ft-3": true,"Qwen-14B": true,"Qwen-14B-ft-1000": true},"kb_chat": {"chatglm3-6b": true,"yizhou-ft-100": true,"yizhou-ft-50": true,"yizhou-ft-30": true,"yizhou-ft-3": true,"Qwen-14B": true,"Qwen-14B-ft-1000": true},"online_chat": {"zhipu_ai": true}}这就相当于一排”开关“,测试前,测试人员先在这个配置文件里将需要进行测试的大模型的开关打开(设置为false,代表还未测试)
在测试过程中,我的程序会检查这个配置文件中的参数,并选择需要进行测试的大模型进行测试:
if config["completion"][chat][model_name]: # 不至于每加一个大模型就把之前跑过的大模型全部重跑一遍,这一块要人工手动维护了continueprior best机制
这个的含义是:仅选择各个大模型表现最好的一次结果进行记录。
实现思路是:对于每个大模型进行测试后,将结果做一次统计,和现有结果对比(如果现有结果中没有这个大模型的记录则直接写入),如果比现有结果好(正确率更高),则写入,否则不写入:
def which_is_better(curr: dict, prev: json) -> bool:if curr["Solve_rate"] > prev["Solve_rate"]:return Truereturn Falsedef absolute_prior_best(dicts: List[dict], llm_model: str, configuration: json) -> bool:"""用来统计明确作答且solve rate最高的数据"""# 打开之前的文件看一下是否结果更好stats_result = configuration["target"]unresolved_loc = configuration["unresolved_loc"]with open(stats_result, "r+", encoding="utf-8") as stats:stats_data = json.load(stats) # 之前的结果res, unresolved = count_up(dicts, llm_model) # res是现在的结果for data in stats_data:if data["llm_name"] == res["llm_name"] and which_is_better(res, data):data["Tot_problem_nums"] = res["Tot_problem_nums"]data["Solved_problem_nums"] = res["Solved_problem_nums"]data["Solve_rate"] = res["Solve_rate"]data["type_stats"] = res["type_stats"]# 准备改写 包括json answer,solve_rate,以及unresolved# 改写unresolvedwith open(os.path.join(unresolved_loc, f'{llm_model}_unresolved.json'),"w", encoding="utf-8") as unresolved_file:json_str = json.dumps(unresolved_file, ensure_ascii=False, indent=4)unresolved_file.write(json_str)stats.seek(0)json.dump(stats_data, stats, ensure_ascii=False, indent=4)return Trueelif data["llm_name"] == res["llm_name"] and not which_is_better(res, data):return False# 改写solve_ratestats_data.append(res)stats.seek(0)json.dump(stats_data, stats, ensure_ascii=False, indent=4)with open(os.path.join(unresolved_loc, f'{llm_model}_unresolved.json'),"w", encoding="utf-8") as unresolved_file:json_str = json.dumps(unresolved, ensure_ascii=False, indent=4)unresolved_file.write(json_str)return True在这段代码中,which_is_better定义了什么叫做大模型的表现更好,在这里,solve rate更高就代表更好。
absolute_prior_best就是做我上面说的那段逻辑,检查现有结果中是否有这个大模型的记录,没有则将本次的直接写入。如果有则比较和这一次测试的结果,如果这一次测试的结果更好则写入。
同样,这个机制也是可以通过开关开启或关闭的(如果把这个机制关了每次都会覆写现有结果)

label机制
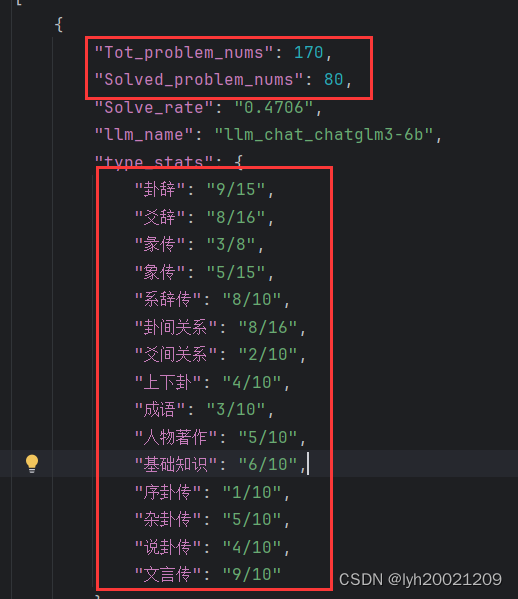
所谓label机制,就是按照各个问题的标签分类,对于各个分类统计正确率。
这里的实现是,直接开一个哈希表,随后对于每个label下的问题,维护哈希表中对应key的value即可。
def count_up(jsons: Union[json, List[dict]], llm_name: str) -> tuple[dict[str, float | str], List[json]]:total_num = len(jsons)solved_num = 0unsolved = []type_map = defaultdict(lambda: [0, 0]) # 统计某一个类型里总共几个问题,对了几个for j in jsons:type_map[j['type']][1] += 1correct_answer = str(j['correct_answer'])kb_answer = str(j['kb_answer'])if kb_answer.find(correct_answer) != -1 or kb_answer.find(correct_answer.lower()) != -1:solved_num += 1type_map[j['type']][0] += 1if not contains_letters(kb_answer):unsolved.append(j)rate = format(solved_num / total_num, '.4f')return {"Tot_problem_nums": total_num,"Solved_problem_nums": solved_num,"Solve_rate": rate,"llm_name": llm_name,"type_stats": {k: f'{v[0]}/{v[1]}' for k, v in type_map.items()}}, unsolved2. Qwen-14B基线测试与数据可视化结果
2.1. 任务描述
将框架重构、完善后,我接入了Qwen-14B微调1000轮以及不微调的对话实例。(这两个都接入了知识库)并进行了测试。此外,我还给组员分配了一个数据处理和可视化的任务,最终对基线测试结果进行了统计与图表绘制:
这边可以给你个数据处理和可视化的工作,在仓库的python_scripts分支下,我更新了evaluate和Base_Test_stats这两个模块,前者包含了基线测试的框架以及各个大模型对话接口的实现类,后者包含了对话结果中问题的总solve_rate以及各个问题分类标签下的solve_rate里面有基线测试的结果数据。前者包括了几个文件夹:
target_files是总的目标文件,json_answer是所有大模型对话的结果文件,xlsx_answer是转换为excel表格的(这个可以不用管),statistic下solve_rate是solve_rate的汇总结果,unresolved是各个大模型对话时没有明确指出选项的回答(里面可能包含对的和错的答案)。 现在的任务如下:
0. 从仓库中对应分支拉取代码,将target_files放入对应位置
1. 对unresolved文件夹下的各个json文件进行人工判题,例如:
这幅图中的回答,对应了A选项的渐卦,因此算是正确
这幅图中的康对应不上任何选项,因此错误。
2. 对人工判题的结果,进行总计与分类统计,例如:总计x/y(其中x是unresolved中正确的个数,y是该文件中的总题数),分类1:卦辞:p/q(其中p是unresolved中卦辞这一类问题中的正确的个数,q是卦辞这一类问题中的总个数,例如3/5),分类2...
3. 对1、2的结果,在csdn博客中开一个表格进行统计
4. 对1、2的结果,累加至solve_rate下的solve_rate.json文件中,例如,微调100轮带知识库的总计10/21(我瞎说的数字),分类1:卦辞3/5,分类2:... 将其对应累加至响应项上
5. 对累加后的solve_rate.json文件进行数据可视化,其中纵轴是正确率,横轴具有层级结构:例如,第一个分区是微调100轮带知识库的,第二个分区是不微调带知识库的...等等。每个分区有一些条柱,分别对应于总计的正确率,分类1的正确率,分类2的正确率等等...同时要保证每一种分类、总计的条柱在不同分区的颜色一致,例如,总计为红色,分类1为橙色,分类2为绿色...等等。最终,每个条柱上要标明正确率,例如,总计正确率61.20%,分类1正确率57.89%,以百分数形式精确到小数点后两位。


2.2. 任务实现
这位同学已经将这份工作完成了,细节见于以下两篇博客:
创新实训记录(三)-CSDN博客
创新实训记录(四)-CSDN博客
2.3. 结果展示
数据统计
这里我接入Qwen-14B后,利用他的脚本以及统计的数据表格,再次汇总出来了一张表:
| 模型 | 微调轮数 | 是否接入知识库 | 卦辞(15) | 爻辞(16) | 彖传(8) | 象传(15) | 系辞传(10) | 卦间关系(16) | 爻间关系(10) | 上下卦(10) | 成语(10) | 人物著作(10) | 基础知识(10) | 序卦传(10) | 杂卦传(10) | 说卦传(10) | 文言传(10) | 总计(170) |
| glm3 | / | × | 9 | 8 | 3 | 5 | 8 | 8 | 2 | 4 | 3 | 5 | 6 | 1 | 5 | 4 | 9 | 80 |
| glm3 | 3 | × | 8 | 6 | 2 | 5 | 7 | 7 | 4 | 1 | 3 | 5 | 4 | 4 | 0 | 4 | 7 | 67 |
| glm3 | 30 | × | 8 | 7 | 3 | 5 | 9 | 7 | 3 | 2 | 4 | 2 | 5 | 1 | 4 | 5 | 7 | 72 |
| glm3 | 50 | × | 9 | 4 | 2 | 4 | 9 | 9 | 5 | 3 | 5 | 4 | 5 | 1 | 4 | 6 | 6 | 76 |
| glm3 | 100 | × | 11 | 5 | 2 | 3 | 8 | 12 | 3 | 4 | 3 | 4 | 4 | 4 | 3 | 5 | 7 | 78 |
| glm3 | / | √ | 13 | 9 | 4 | 8 | 10 | 12 | 4 | 6 | 5 | 6 | 7 | 2 | 5 | 7 | 10 | 108 |
| glm3 | 3 | √ | 13 | 8 | 5 | 7 | 10 | 10 | 4 | 5 | 3 | 6 | 7 | 1 | 5 | 6 | 6 | 98 |
| glm3 | 30 | √ | 11 | 10 | 6 | 8 | 6 | 11 | 6 | 4 | 6 | 6 | 7 | 3 | 4 | 6 | 8 | 91 |
| glm3 | 50 | √ | 13 | 10 | 6 | 5 | 7 | 11 | 5 | 7 | 7 | 6 | 8 | 4 | 6 | 5 | 7 | 107 |
| glm3 | 100 | √ | 11 | 8 | 6 | 7 | 10 | 11 | 4 | 4 | 7 | 3 | 6 | 6 | 7 | 5 | 8 | 103 |
| glm4 | / | / | 14 | 10 | 8 | 8 | 10 | 13 | 8 | 5 | 7 | 9 | 8 | 3 | 4 | 7 | 10 | 124 |
| Qwen | / | √ | 14 | 14 | 8 | 8 | 9 | 13 | 5 | 6 | 8 | 9 | 5 | 2 | 7 | 9 | 8 | 125 |
| Qwen | 1000 | √ | 14 | 14 | 8 | 14 | 10 | 12 | 6 | 6 | 9 | 9 | 5 | 5 | 7 | 8 | 7 | 133 |
数据可视化
随后,利用Python脚本进行数据可视化,结果如下:
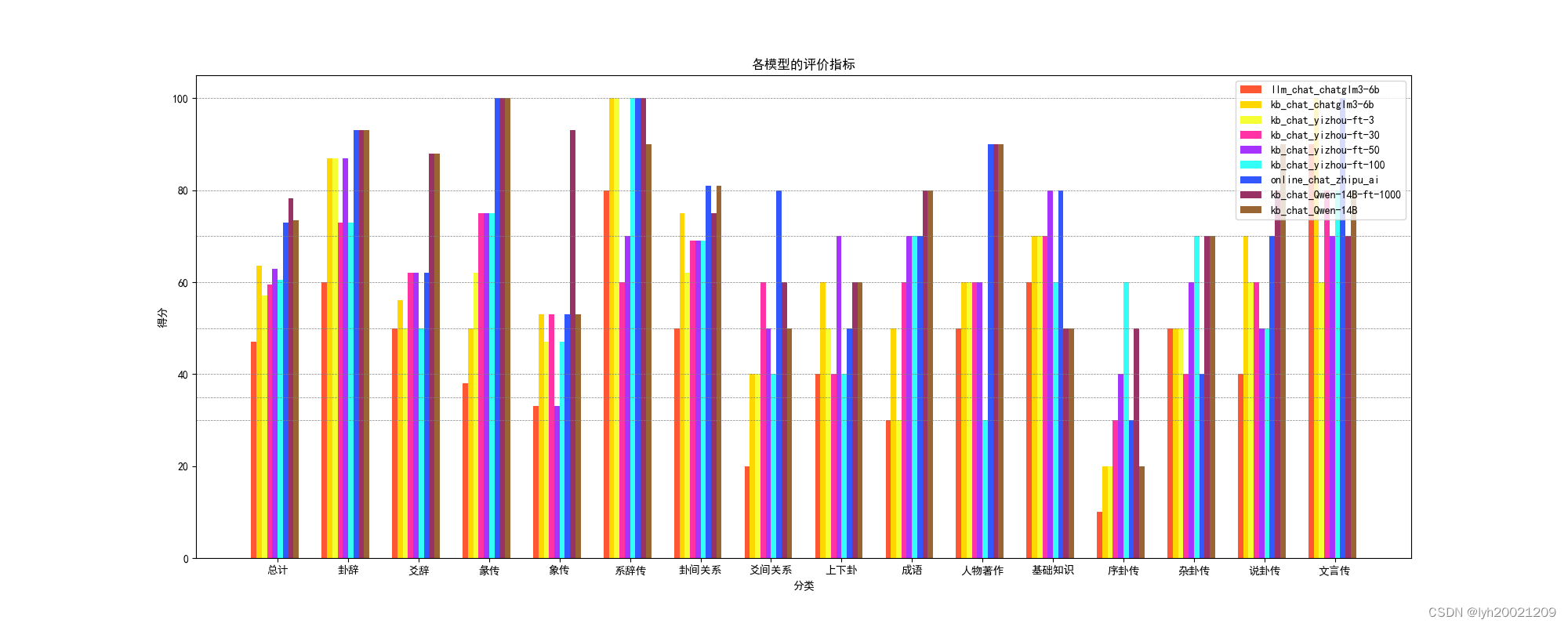
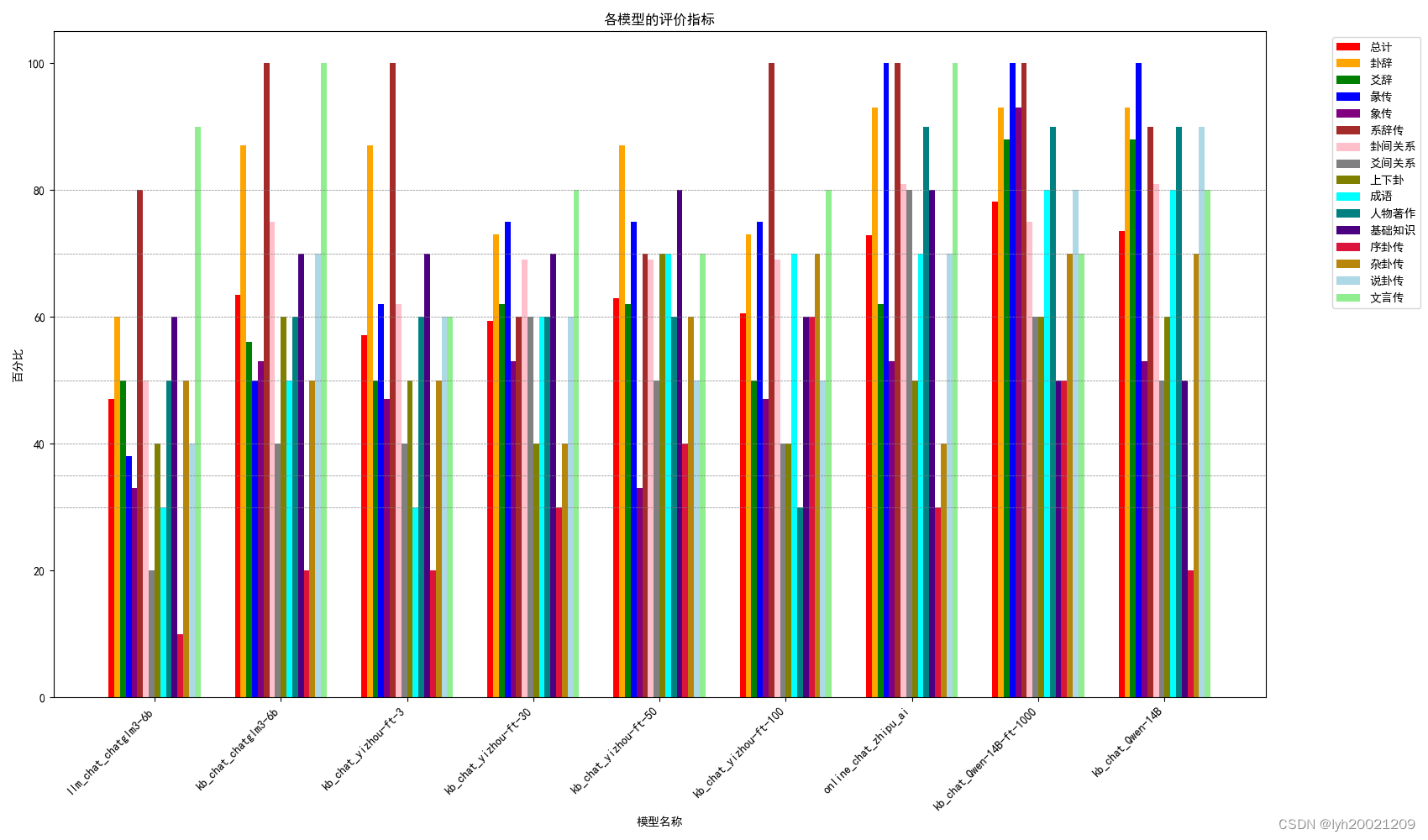
前面那副图像,每个分类是各个大模型对于各个标签下的问题的正确率的对比;后面的图像,每个分类是各个标签下的问题对于各个大模型回答的正确率的汇总。
结果分析
可以看到,一开始在训练轮数不够的情况下,我们是在进行负优化的(因为无论是接入还是不接入知识库,都要比不上不微调的大模型)。或者说轮数不够欠拟合了。
但是!在训练轮数足够的情况下,我们是在做正优化的。接入知识库后,我们的模型比不微调的Qwen以及在线的glm4的性能都要优越。是唯一一个正确率在80%左右的大模型。
和最开始的glm3-6b比起来,我们的进行过1000轮微调以及接入知识库的Qwen大模型,在170道客观题中,多回答对了53道。其中:
也就是说我们的大模型最终在评测集上将初始大模型提升了66.25%的acc率。可以说是效果显著。