目录
- 一、安装CUDA和cudnn
- 1.1、下载CUDA驱动
- 1.2、安装CUDA驱动
- 1.3、配置环境变量
- 1.4、安装cudnn
- 1.5、安装magma-cuda
- 二、安装gcc编译器
- 三、安装CMake
- 四、安装NCCL
- 五、编译安装Pytorch
- 5.1、前提准备
- 5.2、下载pytorch源码
- 5.3、配置环境变量
- 5.4、Pytorch编译安装
- 5.5、测试Pytorch
- 特别鸣谢以下博客
最近拿到一台昇腾aarch64服务器,显卡为A100,非常难得,但是与平常配置环境不同,服务器存在三大难题:
- 由于安全控制,服务器本身不能访问外网;
- 服务器本身为ARM架构(aarch64),网上所有镜像源的ARM版本Pytorch安装包均为CPU版,无法使用CUDA;
- 没有管理员权限,只拿到非Root用户;
在经过了6*12+小时的不断实践、试错、排错、询问大佬、寻找解决方案、重头来过等等过程后,总结了一套在昇腾aarch64服务器编译安装支持GPU的Pytorch的解决方案,记录在此。
编译安装Pytorch需要极高的耐心和较强的动手能力,在动手之前,你还需要具备以下条件
- 熟练操作一种ssh工具,如MobaXtem,能够通过ssh连接服务器,能读懂Linux系统基本终端命令;
- 登录的服务器节点具备显卡;
- 具备访问某些网站的能力;
- 一颗勇敢的心。
一、安装CUDA和cudnn
1.1、下载CUDA驱动
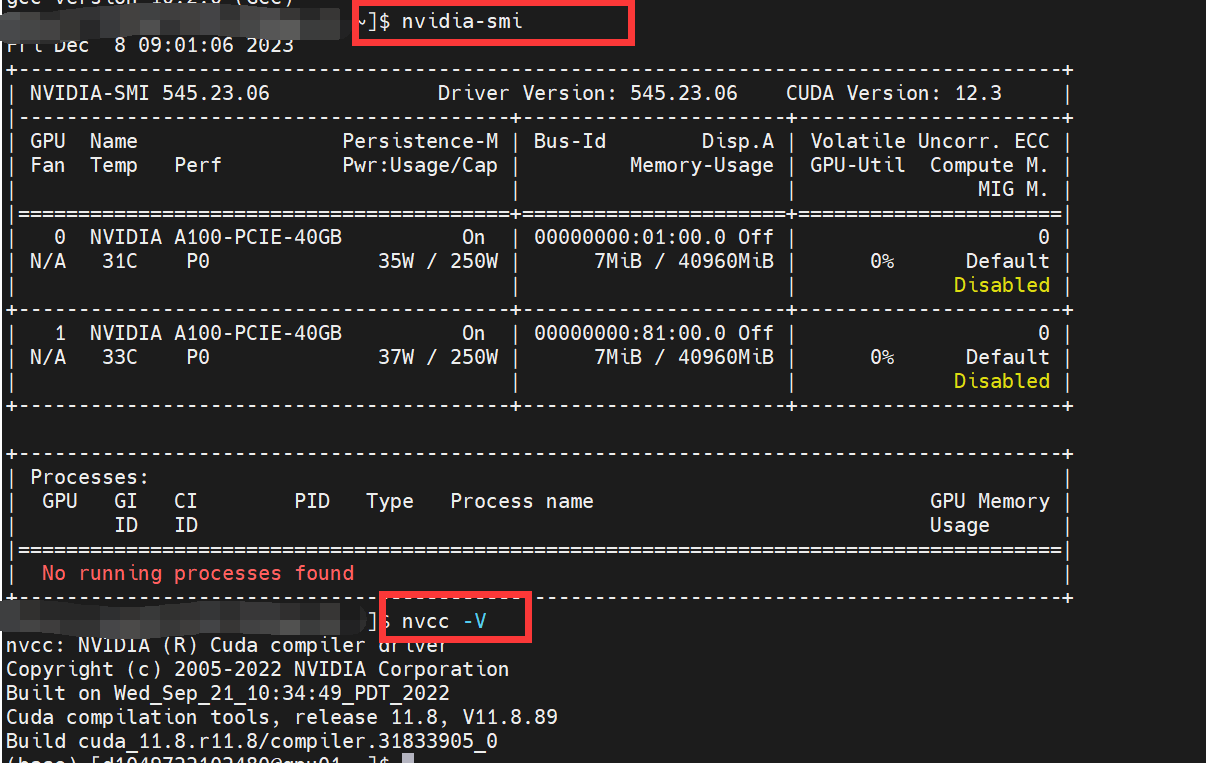
1.首先查看系统的cuda驱动,可以看到这里是12.3版本,所以我们要下载比其低的CUDA,推荐11.8版本。
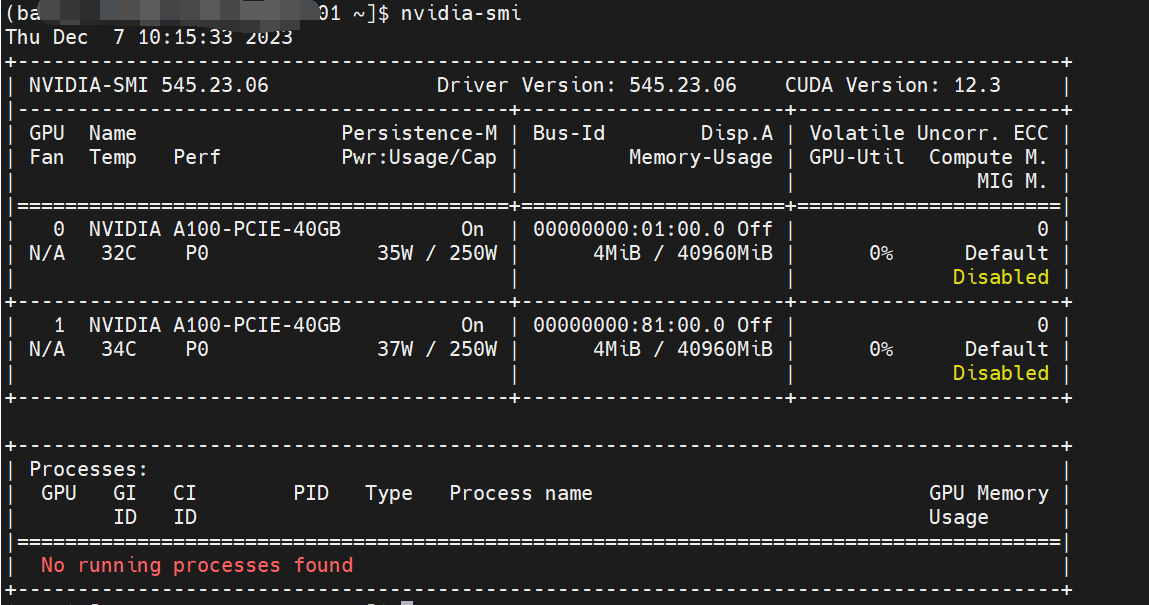
然后输出nvcc --verison,如果是command not found说明没有CUDA驱需要安装,如果输出了一大堆型号信息且版本低于上图的CUDA 驱动版本,说明有CUDA且版本正确,就不要再安装了,跳到#二步骤。
2.进入CUDA官网,根据系统版本选择对应的runfile,注意因为是非root用户,不要用sudo的rpm安装,只能选择下载runfile用sh安装,因为其他版本需要管理员权限才行,(如果不知道机器是什么版本,可以使用uname -m查看架构)
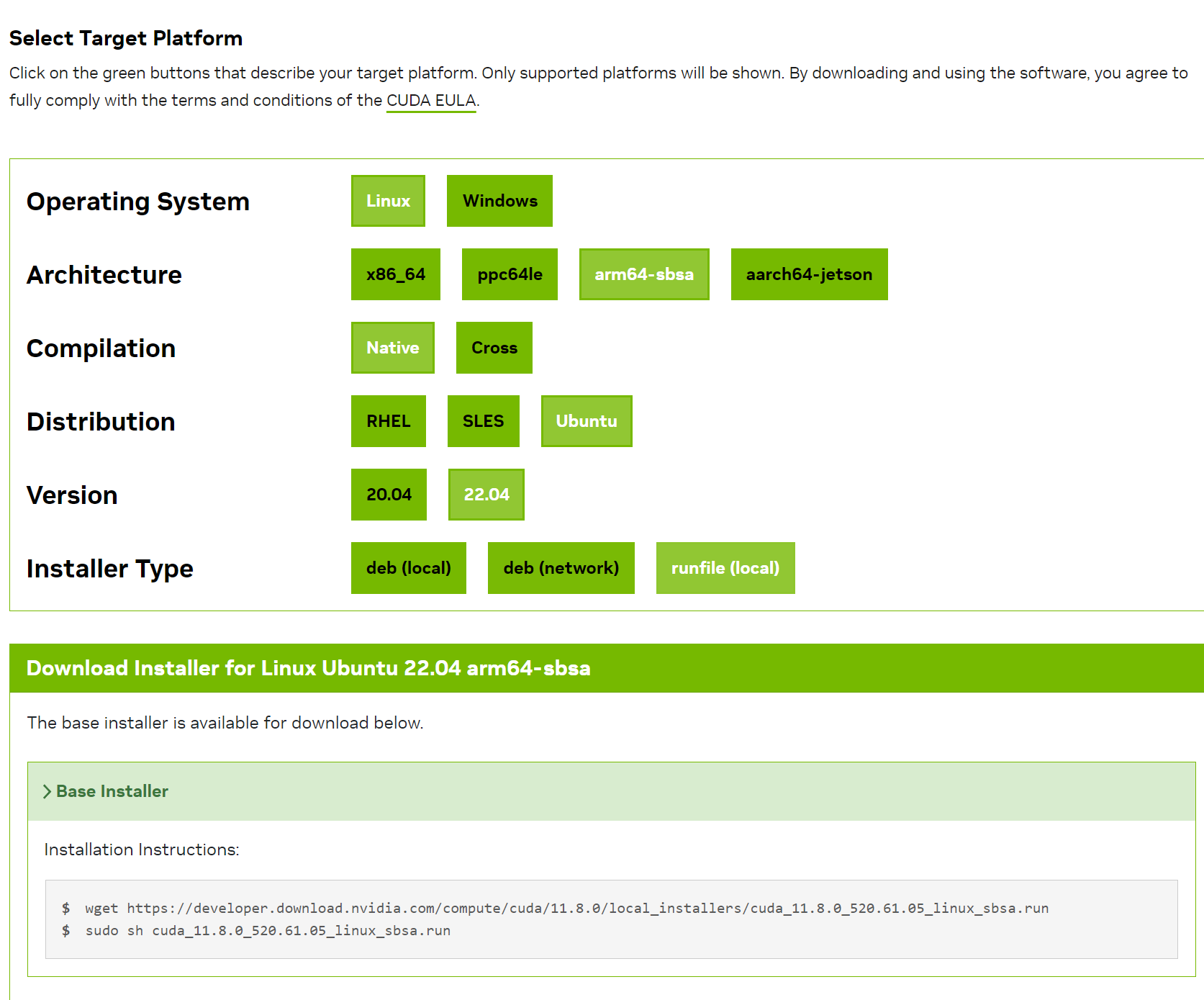
可以使用wget下载:wget https://developer.download.nvidia.com/compute/cuda/11.8.0/local_installers/cuda_11.8.0_520.61.05_linux_sbsa.run
如果没有外网环境用不了wget,使用本机下载这个.run文件后,然后传到服务器,使用sh安装。
1.2、安装CUDA驱动
如果是非root用户,终端cd进入下载好.run文件的目录,使用sh安装:sh cuda_11.8.0_520.61.05_linux_sbsa.run
首先会弹出问你接不接受一个协议,输入accept:

然后回弹出安装配置:
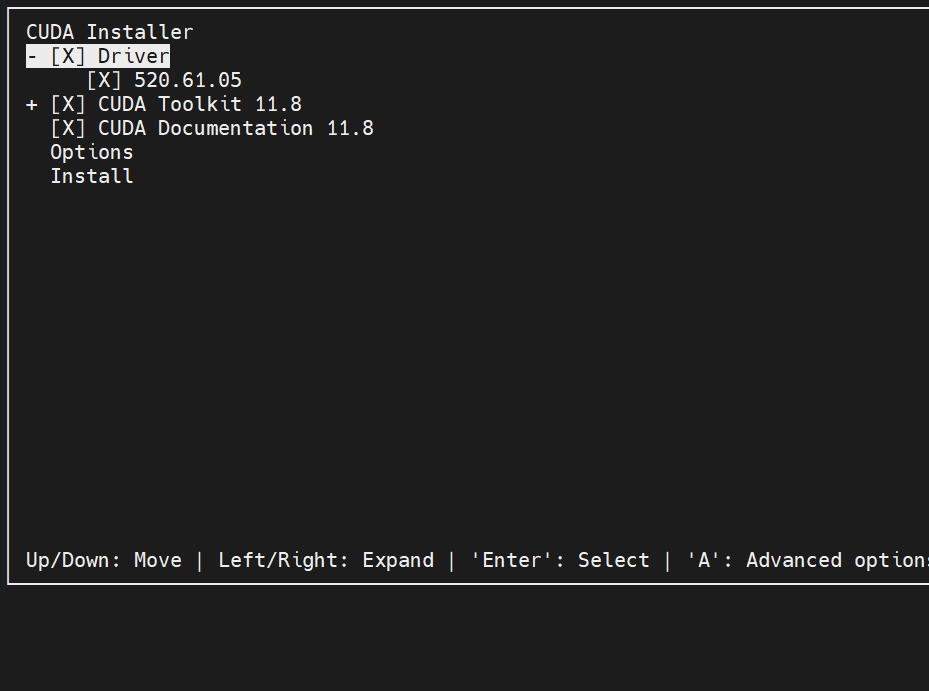
↑↓进行上下,←→进行扩展,enter进行选择和取消,A进行扩展选项
我们取消掉Driver选项,因为机器已经安装了Driver,只安装CUDA Toolkit和CUDA documentation:
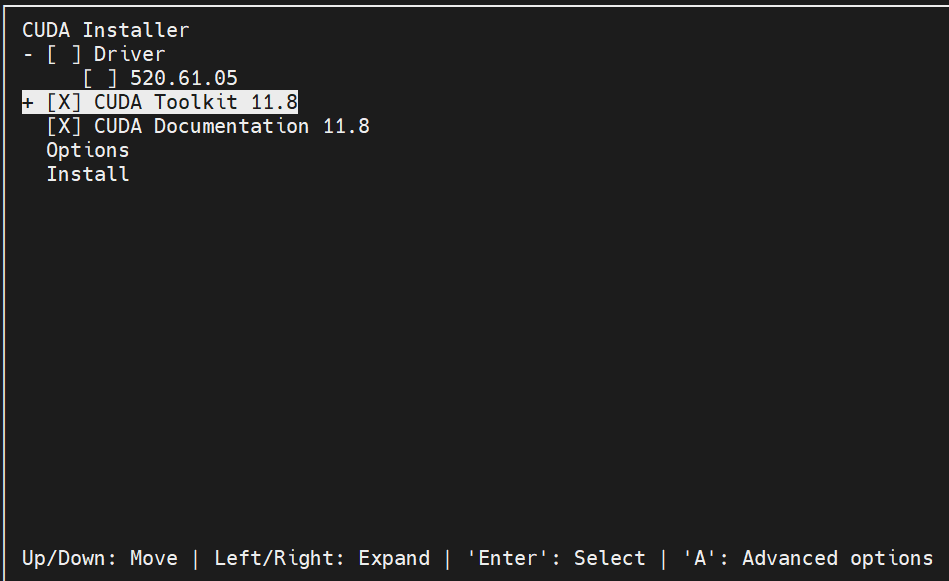
然后选择选中Options:
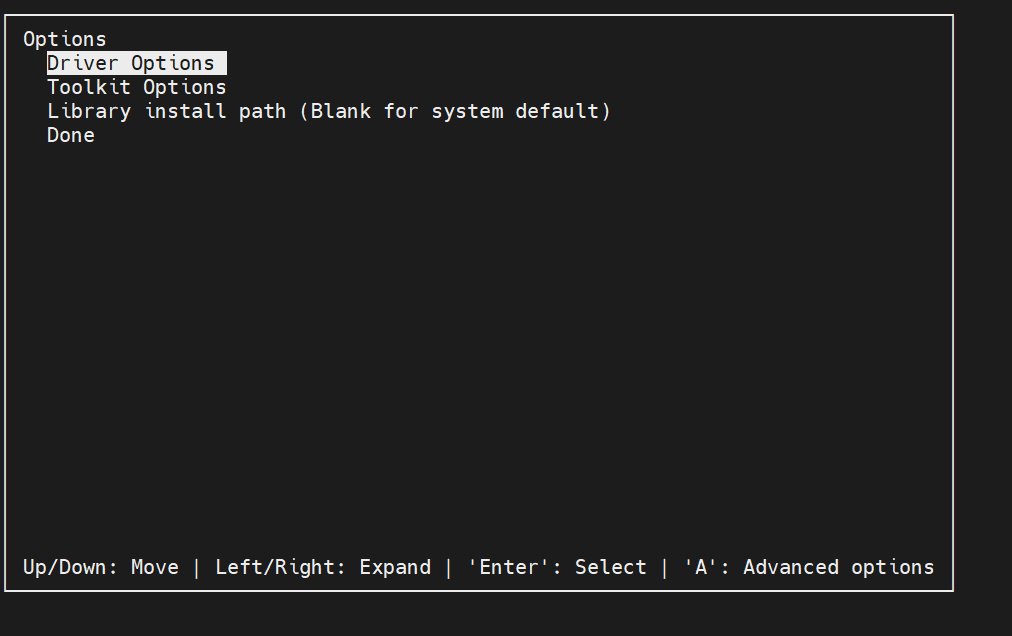
进入Toolkit Options:
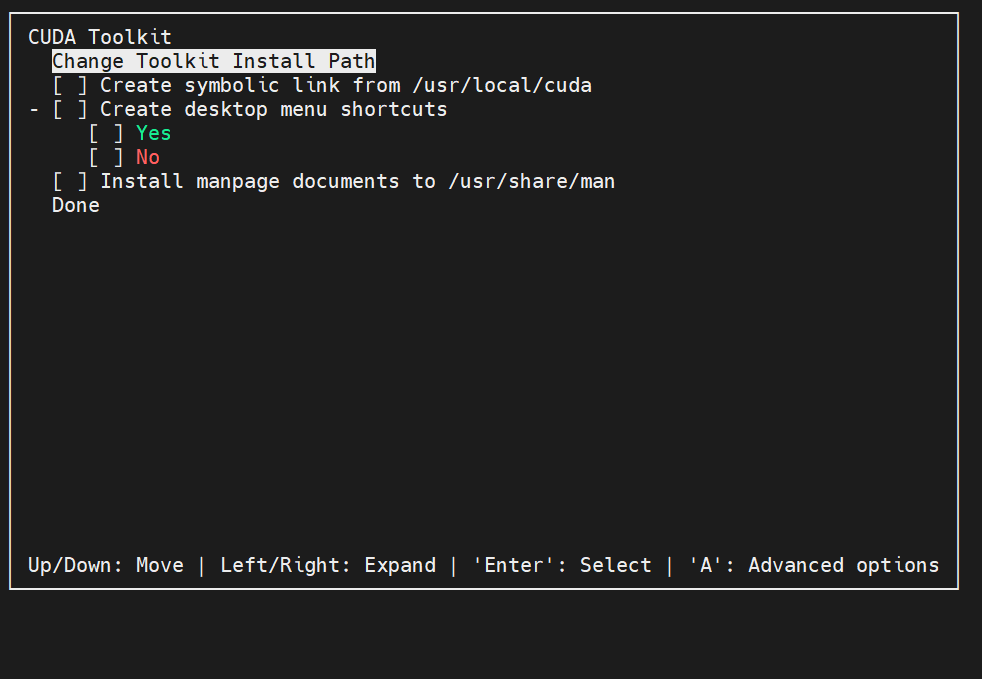
/usr这种非用户目录的选项都要去掉,我这里全去掉了,另外进入 Change Toolkit Install Path设置cuda安装到自己具有写入权限的路径(一定要是自己的目录,提前建好文件夹,不然你安不了)
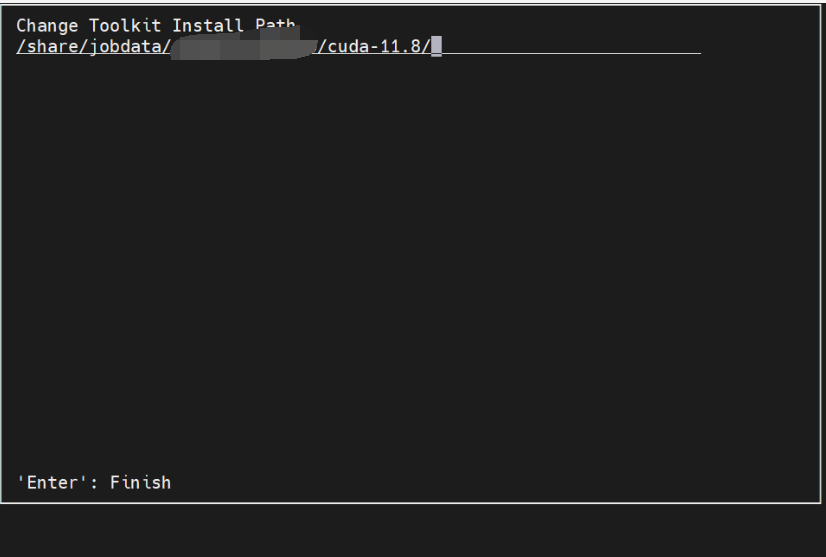
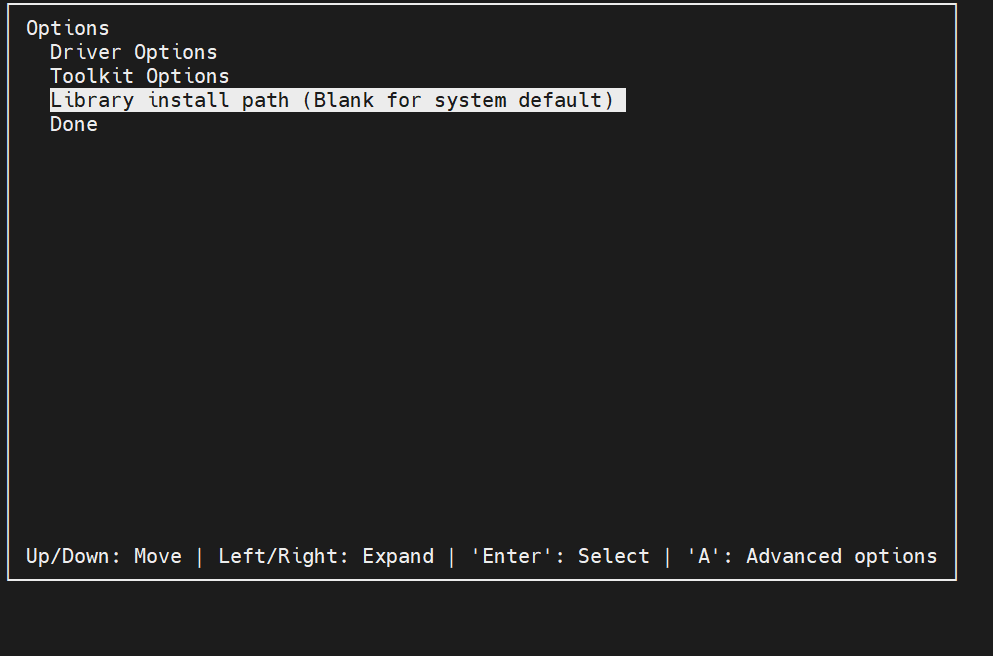
做完Done,回到Options菜单, 更改Library install path (不改不行,它会偷偷写入/var/lib)
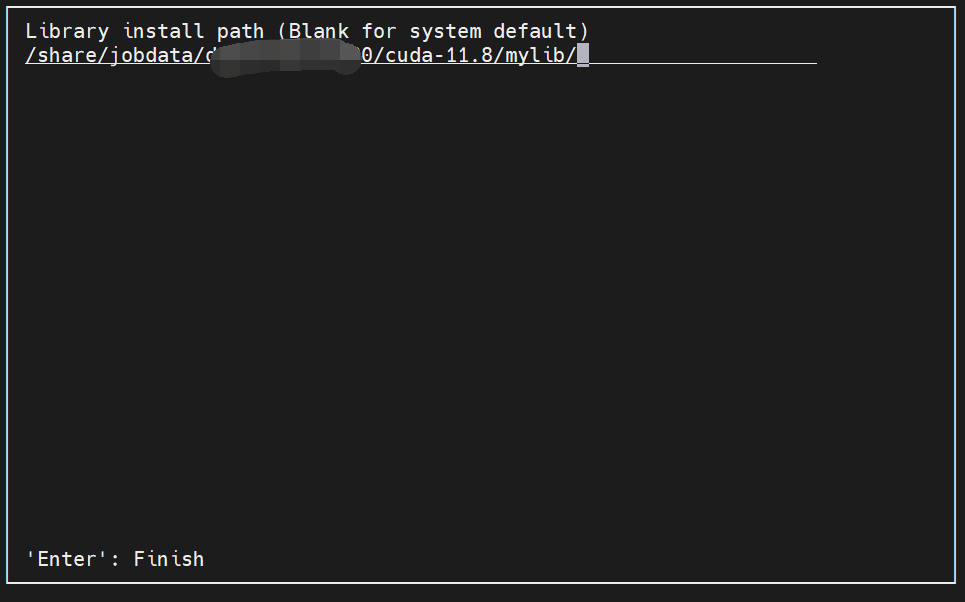
同样设置安装到自己具有写入权限的路径(同样一定要是自己的目录)
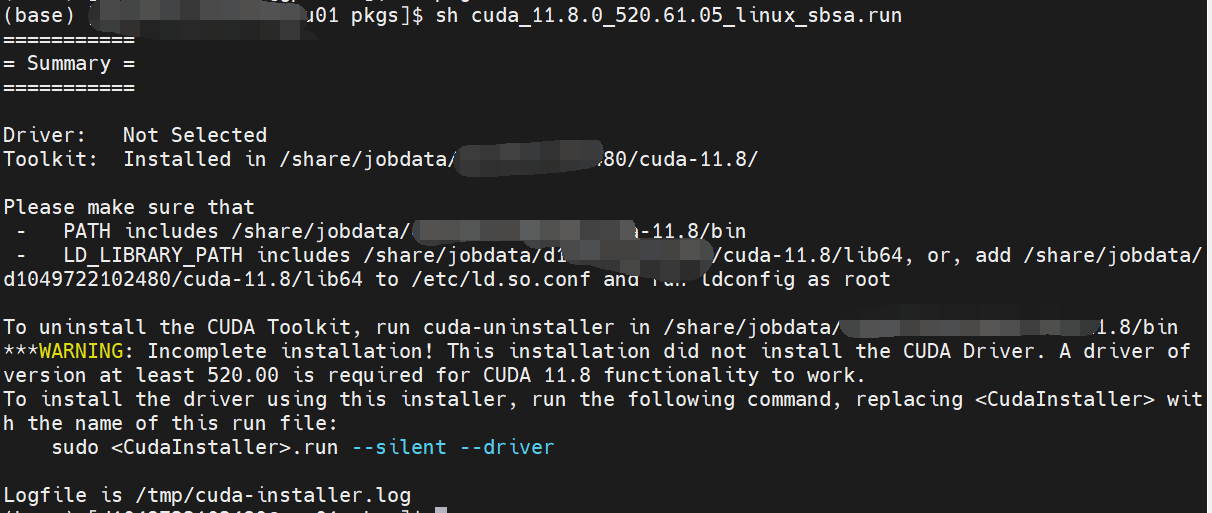
配置好以上两个自定义目录后,选择Done,等待片刻会出现一个summary,说明安装成功:
并且能在文件目录中看到cuda里的文件都已经安装好了:
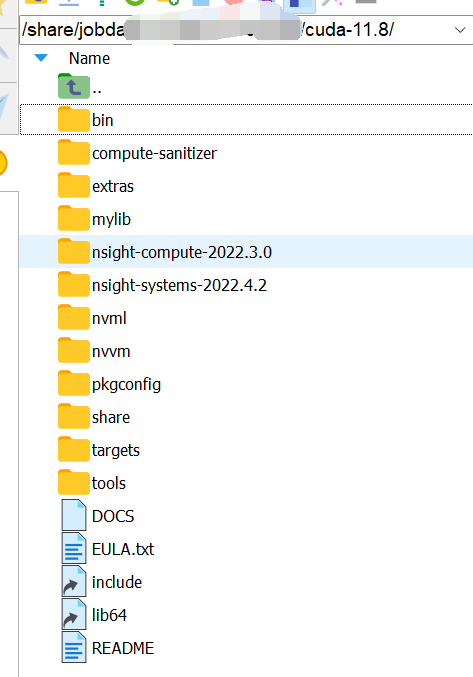
1.3、配置环境变量
安装好后还不能使用nvcc --V,需要配置环境变量:
输入 vim ~/.bashrc进入环境变量,进行更改:
# CUDA
export PATH="/刚刚的路径/cuda-10.1/bin:$PATH"
export LD_LIBRARY_PATH="/刚刚的路径/cuda-11.8/lib64:/刚刚的路径/cuda-11.8/mylib/lib64:$LD_LIBRARY_PATH"
路径要记得换成自己的:
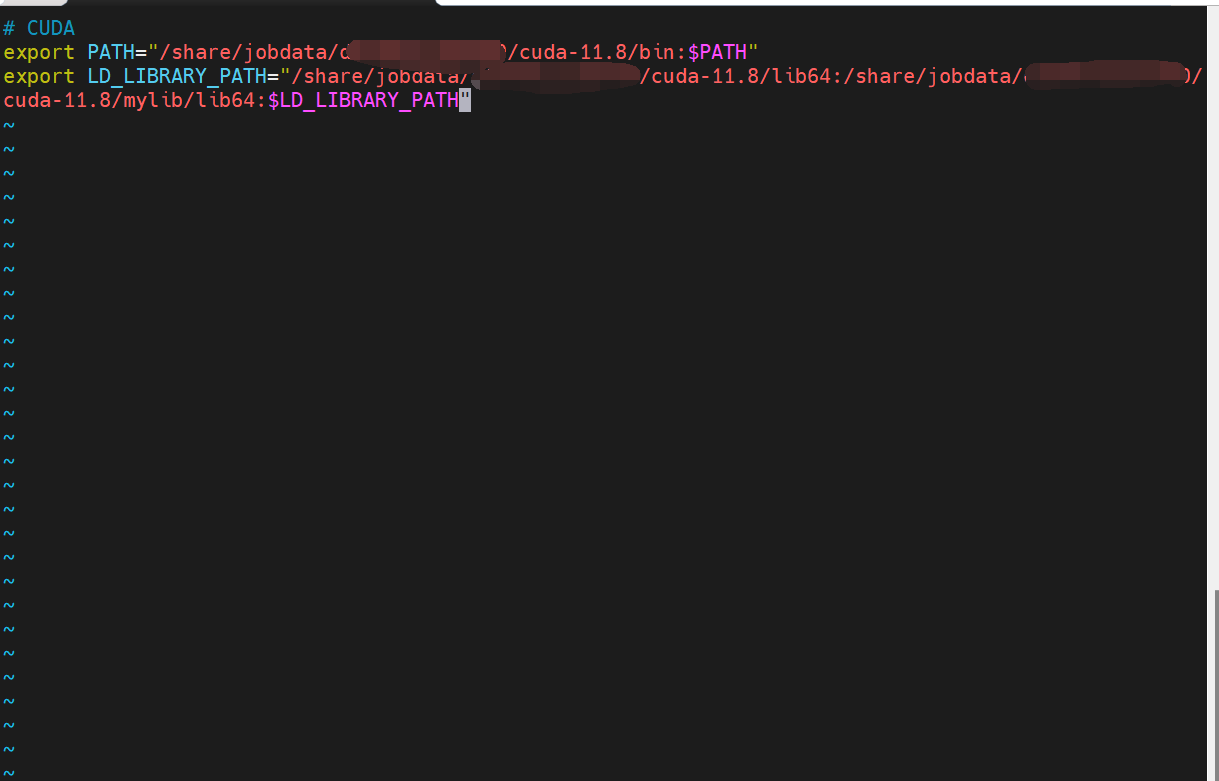
添加好后,输入wq!保存,然后刷新环境变量:source ~/.profile
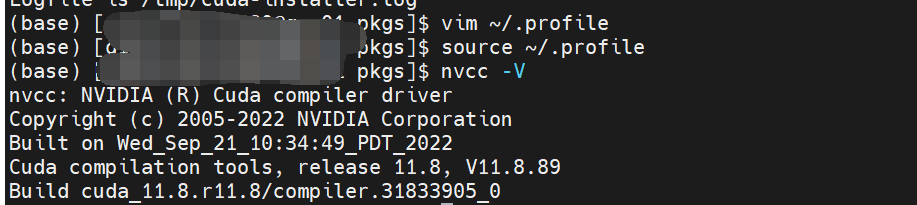
最后测试CUDA,输入nvcc -V,如果显示了版本号,则恭喜大获成功:
1.4、安装cudnn
这里参考了:https://blog.csdn.net/YY007H/article/details/134772564
1.5、安装magma-cuda
magma-cuda主要用于大规模线性代数计算和GPU加速。
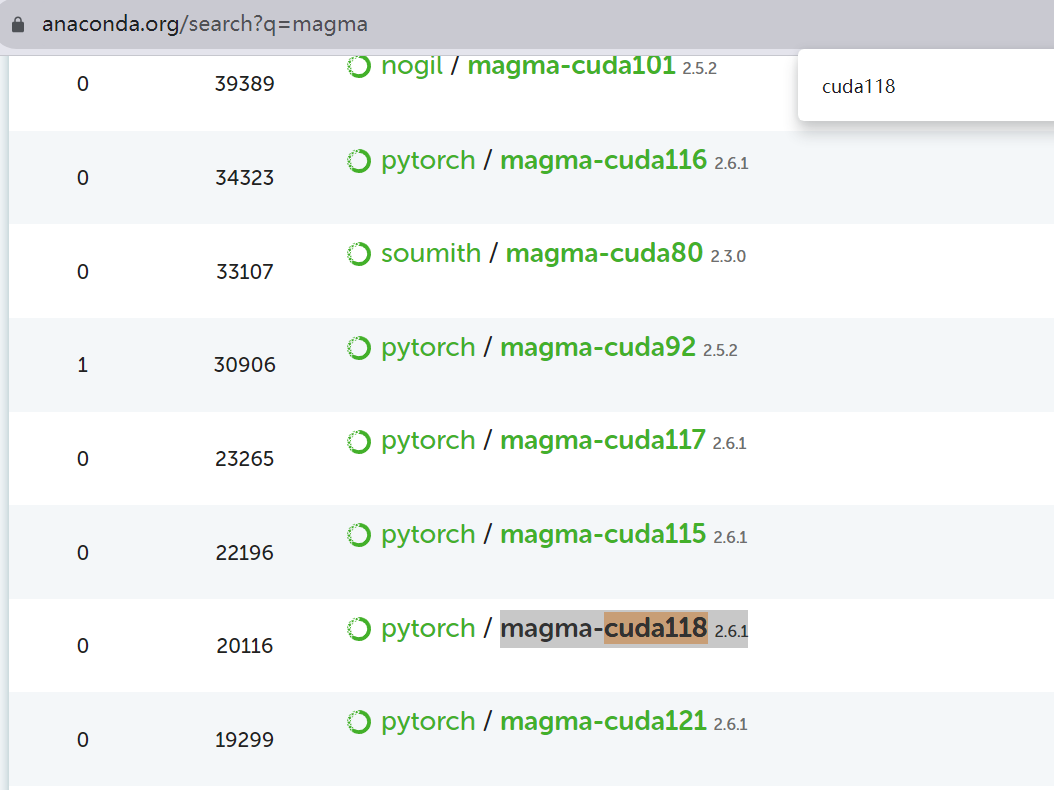
首先进入anaconda官方网站:https://anaconda.org/search?q=magma,选择自己对应CUDA版本的安装包,如果是CUDA11.8就找magma-cuda118,后面的版本号就是对应的CUDA号:
将其下载后,迁移到Anaconda安装目录的pkgs目录下(因为注conda install 缓存文件路径一般就是anaconda/pkgs),如果下载的包名是linux-64_开头的,要重命名把linux-64_去除,以包名开头,不然conda识别不到。然后使用终端cd到pkgs目录那里,输入:
conda install --use-local 包名.tar.bz2
等待片刻,安装完成后输入conda list就可以看到包名了,如果看不到包名的话大概率是包名的问题,比如linux-64_magma-cuda118-2.6.1-1.tar.bz2要改成magma-cuda118-2.6.1-1.tar.bz2。
二、安装gcc编译器
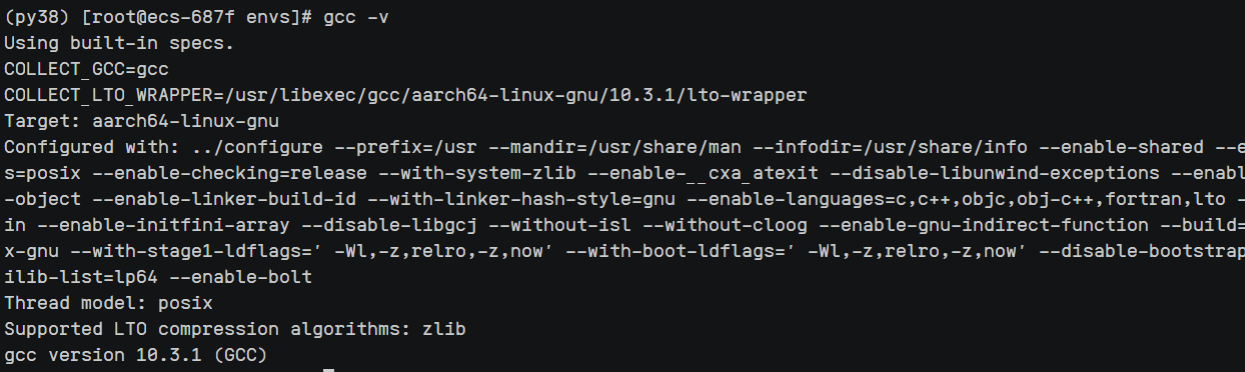
首先测试下机器有没有gcc,输入gcc -v,如果出现以下提示,说明有gcc,该版本为10.3.1,就不用再安装了,但如果低于10版本则必须升级gcc版本。到#三。
这里可以参考这两篇博客安装好相应环境:
https://zhuanlan.zhihu.com/p/659247505(推荐)
https://blog.csdn.net/qq_36393978/article/details/118678521
安装gcc的时间极其漫长,make的时候一般要至少4个小时,我实测为6小时,所以得提前做好准备。
三、安装CMake
在编译安装Pytorch之前,需要要有CMake编译构建工具。
CMake是一个开源的跨平台构建工具,用于管理软件构建过程中的配置、编译和安装。它提供了一个简洁的跨平台语言(CMakeLists.txt)来描述构建过程的规则,并通过生成与目标开发环境兼容的构建文件(如Makefile 或 Visual Studio 解决方案)来完成实际的构建过程。
首先进入CMake官网:https://cmake.org/download/,找到符合系统架构的.tar.gz格式的安装包:
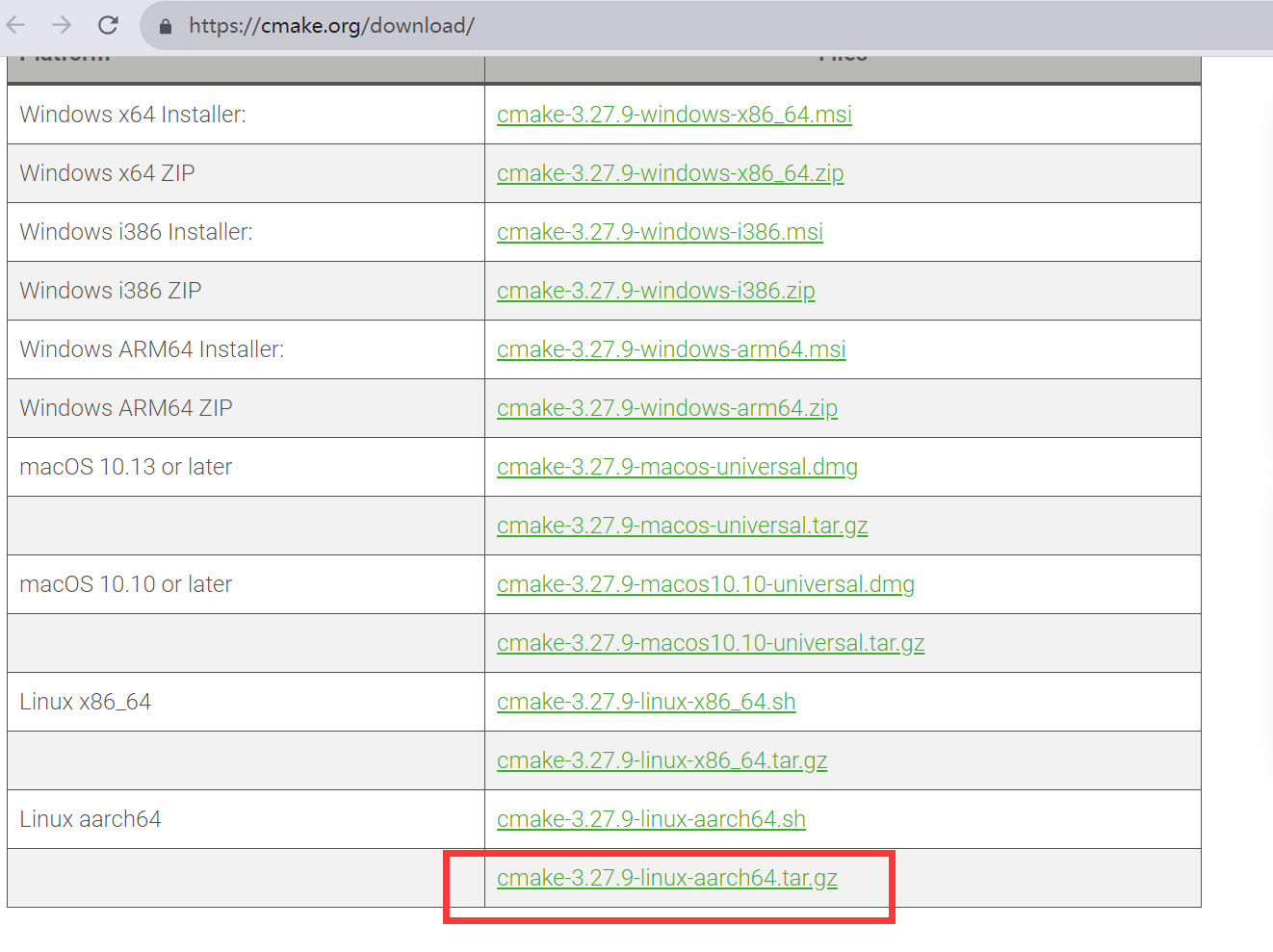
这里选择了aarch64的3.27.9安装包,并上传到服务器进行解压:
tar -zxvf cmake-3.27.9-linux-aarch64.tar.gz
解压之后,将解压后的目录改名为CMake方便编写环境变量。
最后一步,打开环境变量文件,如vim ~/.bashrc,在环境变量的最后加入一行即可:
export PATH=你的路径/cmake/bin:$PATH
然后输入cmake --version,如果出现版本号说明CMake安装成功!
四、安装NCCL
这里完全参考这篇博客:https://blog.csdn.net/Scenery0519/article/details/128081062
其最后一步的环境变量配置写在~/.bashrc里面就行。
五、编译安装Pytorch
5.1、前提准备
在正式编译安装Pytorch前,你要确认已经弄好了以下配置:
- CUDA驱动和CUDA:使用nvidia-smi和nvcc -V均有值,并且已经安装并配置了CUDNN;
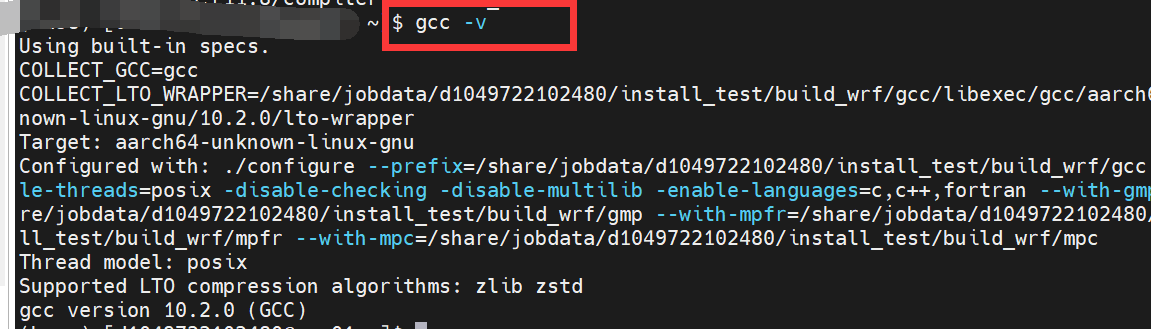
2.具备10版本以上的gcc编译环境:使用gcc -v查看
3.安装了Anaconda或者Miniconda:输入conda env list可以看到已有的虚拟环境;
4.安装好了cmake,即输入cmake --version可以看到cmake的版本号
5.2、下载pytorch源码
源码编译安装pytorch前,需要下载完整的pytorch源码:https://github.com/pytorch/pytorch/tree/v1.10.2-rc1
首先使用git clone --recursive https://github.com/pytorch/pytorch开始克隆源码,如果碰到网络问题需要设置git代理:
# git 代理设置,前提是你有代理
# git config --global http.proxy "localhost:端口号"
# git config --global https.proxy "localhost:端口号"
# 代理设置好,下载完后,就可以取消了,否则可能影响你其他操作
# 取消代理
# git config --global --unset http.proxy
# git config --global --unset https.proxy
如果没有代理,可以通过以下方式进行下载:
# 如果网络不行可以试着通过镜像地址 或 gitee 克隆
# 如 git clone --recursive https://hub.yzuu.cf/pytorch/pytorch
# 如 git clone --recursive https://gitee.com/ascend/pytorch.git
在下载好pytorch源码后,非常重要的一步就是必须递归下载其中的链接包,这里使用git submodule递归下载:
git submodule sync
git submodule update --init --recursive
安装好后,你的pytorch包一般在2.5GB以上,如果文件大小过小,说明你有些递归的包没下载完整。
5.3、配置环境变量
使用vim ~/.bashrc或者使用mobaXtem的文件树方式打开环境变量文件,里面的内容配置如下:
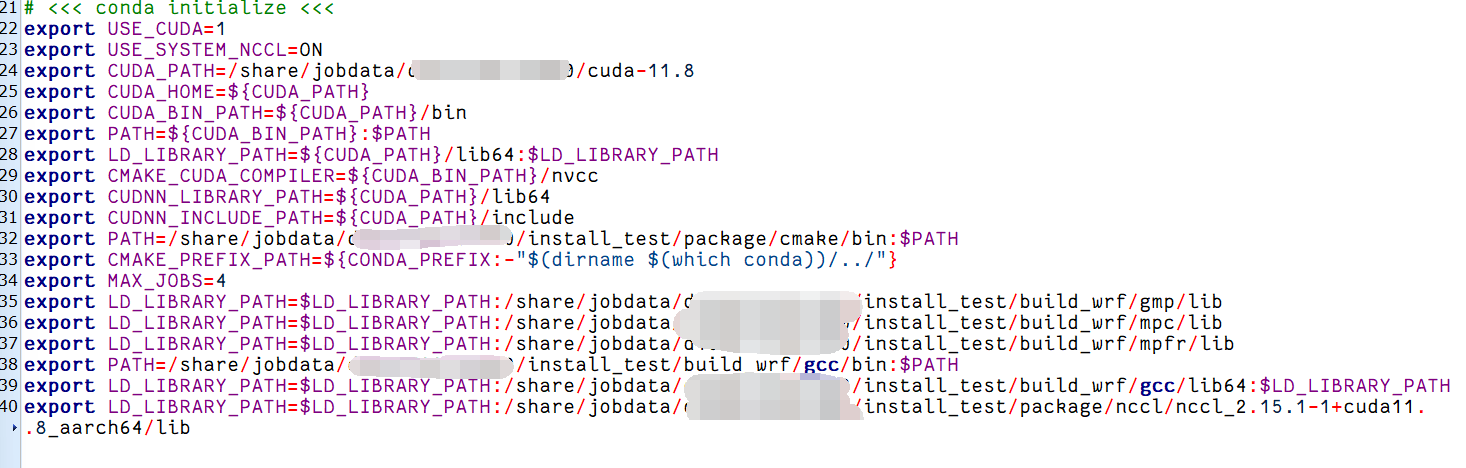
- export USE_CUDA=1:用于设置一个名为 USE_CUDA 的环境变量,并将其值设置为 1。可能用于告知后续的脚本或程序,在构建过程中需要使用 CUDA 进行加速或其他相关操作。
- export USE_SYSTEM_NCCL=ON:设置一个环境变量 USE_SYSTEM_NCCL 的值为 ON,表明使用系统中已安装的 NCCL 库。
- CUDA 相关的环境变量:设置 CUDA 安装路径、相关 bin 和 lib 路径,同时还指定了 CMake 所使用的 CUDA 编译器和 CUDNN 库的路径。
- CMAKE相关的环境变量:添加了 CMake 可执行文件的路径到 PATH 环境变量中、设置 CMake 的前缀路径,用于指定额外的 CMake 模块和包的位置。
- export MAX_JOBS=4:设置一个名为 MAX_JOBS 的环境变量,并将其值设置为 4,可能用于指定并行编译任务的最大数量。这个按机器进行设置,太大了容易崩溃。
- GCC相关的环境变量:包括gmp、mpc、mpfr、gcc以在运行时正确链接这些库。
5.4、Pytorch编译安装
cd进入Pytorch目录,采用直接安装的方式进行安装:
# 直接安装
python setup.py install --cmake
# 或者 编译成 whl安装文件,编译成功后在dist文件下面,可通过 pip install torch-xxxx.whl 安装
python setup.py bdist_wheel --cmake
安装过程大概在40分钟到2小时不等:
5.5、测试Pytorch
安装完成后,激活虚拟环境,然后输入python,然后输入一下代码:
import torch
print(torch.__version__)
print(torch.cuda.is_available())
如果显示True即大功告成!
如果报错:NameError: name ‘sympy’ is not defined‘,则需要在conda里再安装sympy模块,如果还是报错,需要安装mpmath,反正就import torch报啥错就补上相关的环境就好。
最后可以再运行以下代码查看显卡数量和显卡型号
print(torch.cuda.device_count())
print(torch.cuda.get_device_name(0))
就能看到torch成功调用到了A100啦!
特别鸣谢以下博客
安装CUDA:
https://www.cnblogs.com/li-minghao/p/13089405.html
安装CUDNN:
https://blog.csdn.net/YY007H/article/details/134772564
安装gcc:
https://blog.csdn.net/qq_36393978/article/details/118678521
https://blog.csdn.net/qq_38308388/article/details/127574517
安装nccl:https://blog.csdn.net/Scenery0519/article/details/128081062
安装pytorch:
https://blog.csdn.net/CSDN_ten/article/details/132636688