关注推送
Feed流的模式
Timeline:不做内容筛选,简单的按照内容发布时间排序。常用于好友与关注。例如朋友圈的时间发布排序。
优点:信息全面,不会有缺失。并且实现也相对简单 缺点:信息噪音较多,用户不一定感兴趣,内容获取效率低
智能排序:利用智能算法屏蔽掉违规的、用户不感兴趣的内容。推送用户感兴趣信息来吸引用户。
优点:投喂用户感兴趣信息,用户粘度很高,容易沉迷
缺点:如果算法不精准,可能起到反作用
Timeline里面又有三种模式: 1.拉模式
2.推模式
3.推拉模式
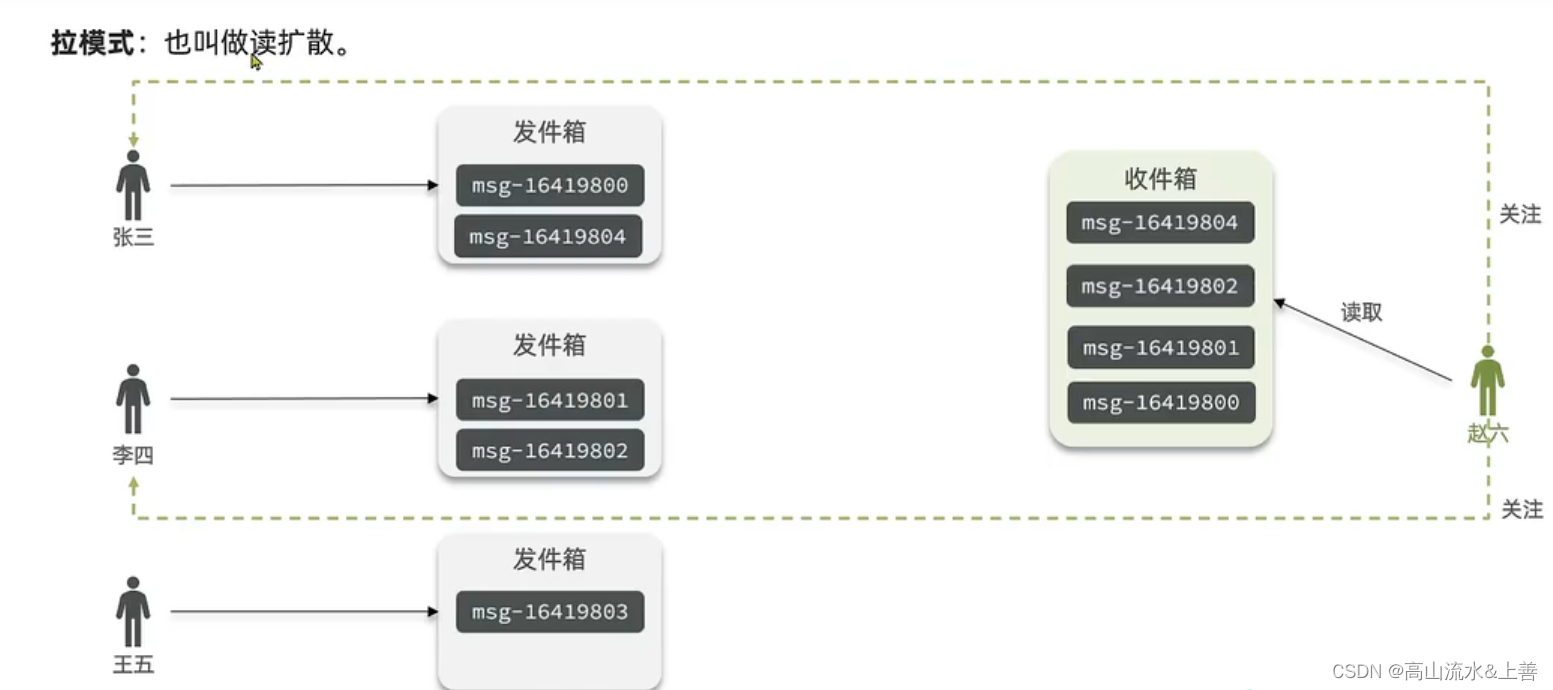
拉模式
Timeline的拉模式(Pull Mode)通常指的是用户端主动请求更新的方式来获取最新动态的一种机制。在社交媒体、问答网站或任何有实时更新内容的应用中,拉模式的工作方式如下:
用户行为:
用户打开应用或刷新页面。 用户选择查看特定用户的动态或时间线。 用户手动下拉刷新(Pull-to-Refresh)来获取新内容。
服务器响应: 服务器接收到用户发起的请求。 根据请求,服务器查询数据库或缓存(如Redis)以获取最新动态。 如果有新的动态,服务器将这些内容发送回客户端。 如果没有新内容,服务器可能返回一个空响应或告知客户端当前无更新。
客户端显示: 客户端接收到新数据后,更新UI显示最新的动态。 如果没有新内容,UI可能会显示一条提示,告诉用户当前内容是最新的。
拉模式的优点包括: 资源效率:只在用户需要时才加载新数据,减少了不必要的网络传输和服务器负载。 控制权:用户可以选择何时获取新信息,提供了更好的用户体验。
缺点则包括: 延迟:用户必须主动操作才能获取新内容,可能会错过实时发生的事件。 频繁请求:如果用户频繁刷新,可能会增加服务器压力和网络流量。 在实际应用中,为了平衡实时性和效率,通常会结合推模式(Push Mode)来实现,比如使用WebSocket或其他长连接技术,当有新动态时服务器可以直接推送给在线用户,而离线用户则可以通过拉模式来获取信息。
推模式
推模式(Push Mode)是一种数据更新机制,其中服务器主动将新数据推送到客户端,而不是等待客户端发起请求。这种方式常用于实时性要求较高的场景,例如即时消息、股票行情、在线协作工具等。以下是推模式的详细描述: 服务器推送: 当服务器上有新的、相关或重要的数据可用时,它会主动将这些数据发送到已连接的客户端。
连接建立: 客户端通常通过持久连接(如WebSocket、Server-Sent Events (SSE) 或其他长连接技术)与服务器保持通信。
实时性: 由于数据是实时推送的,用户可以立即看到更新,无需手动刷新或等待请求响应。
数据传输: 服务器在有新数据时直接通过连接发送,客户端收到数据后立即处理并更新UI。
性能与资源: 推模式可能增加服务器的负载,因为它需要持续监控数据变化并主动推送。 对于客户端,持续的连接可能会消耗更多的电池和网络资源。
用户体验: 提供更好的实时体验,用户可以在数据发生变化时立即得到通知。 可能导致用户设备资源的持续消耗,尤其是对于移动设备。
应用场景: 即时通讯应用,如微信、Slack,服务器会将新消息直接推送给用户。 在线协作工具,如Google Docs,用户可以看到其他协作者的实时编辑。 财经应用,实时推送股票价格变动。
优化与配合: 通常与拉模式结合使用,以平衡实时性和资源消耗。例如,当连接断开时,可以切换到拉模式来获取丢失的数据。 使用推送订阅模型,允许用户仅订阅他们感兴趣的数据。 推模式适合需要实时同步和快速反馈的场景,但需要注意服务器资源和客户端性能的平衡。在设计系统时,通常需要权衡实时性、效率和用户体验。

使用推模式实现关注推送
我们在发布时,查询数据库对应的的粉丝进行推送。
@Overridepublic Result saveBlog(Blog blog) {// 获取登录用户UserDTO user = UserHolder.getUser();blog.setUserId(user.getId());// 保存探店博文boolean isSuccess = blogService.save(blog);if (!isSuccess){return Result.fail("新增笔记失败");}//查询被关注List<Follow> follows = followService.query().eq("follow_user_id", user.getId()).list();if (!follows.isEmpty()) {follows.forEach(follow -> {//推送给粉丝String key = "feed:" + follow.getUserId();stringRedisTemplate.opsForZSet().add(key, blog.getId().toString(), System.currentTimeMillis());});}// 返回idreturn Result.ok(blog.getId());}
关注推送滚动分页
该功能主要使用sortSet里面的分数机制
ZREVRANGEBYSCORE feed:1 100000 0 WITHSCORES limit 0 3
# feed:1 为键
# 最大值 100000
# 最小值 0
# WITHSCORES 是否全部展示key和value
# 0 偏移量
# 3 条数通过上面指令我们可分析出对应的参数:
参数
max :第一次使用当前时间戳 | 第二次上一次查询最小的时间戳
min:0
offset :第一次使用0 | 第二次在上一次结果中,与最小值一样的元素的个数
count:3
具体代码:
@Overridepublic Result queryBlogOfFollow(Long max, Integer offset) {
// 获取用idLong userId = UserHolder.getUser().getId();
// 获取关注用户的keyString key = "feed:" + userId;
// 获取redis里面的推送数据 ZREVRANGEBYSCORE feed:1 当前时间戳 0 WITHSCORES limit 最后一次统计的值 3Set<ZSetOperations.TypedTuple<String>> typedTuples = stringRedisTemplate.opsForZSet().reverseRangeByScoreWithScores(key, 0, max, offset, 2);//判断是否为空if (ObjectUtil.isNull(typedTuples)||typedTuples.isEmpty()){return Result.ok();}long minTime=0;int count=0;
// 创建list存储blog的idList<Long> ids = new ArrayList<>(typedTuples.size());for (ZSetOperations.TypedTuple<String> typedTuple : typedTuples) {ids.add(Long.valueOf(typedTuple.getValue()));long time = typedTuple.getScore().longValue();if (time == minTime) {count++;} else {
// 应因为sortSet是有序的所以最后一个及是最小的minTime = time;count = 1;}}String strIds = StringUtil.join(ids, ",");
// 更具id查询对应的blogList<Blog> blogs = blogService.query().in("id", ids).last("ORDER BY FIELD(id," + strIds + ")").list();
// 设置博客点赞for (Blog blog : blogs) {extracted(blog);setBlogLiked(blog);}
// 返回封装数据ScrollResult scrollResult = new ScrollResult();scrollResult.setList(blogs);scrollResult.setOffset(count);scrollResult.setMinTime(minTime);return Result.ok(scrollResult);}