最近在做模拟浏览器批量定时自动点击实现批量操作功能,主要使用selenium,但是发现selenium直接调用本地浏览器,启动的是一个全新的(与手动打开的不一致),网站可以检测到,每次都要双重验证(密码登录+短信验证),而我们手动操作浏览器只有第一次才需要短信验证,后续不需要,究其原因用selenium由于是全新启动,所以是无记忆的,为了避免这个坑,给碰到相同问题的同伴提供思路,写下此文,希望对大家有所帮助。
1.打开谷歌浏览器;
2.在搜索框直接输入chrome://version/,找到“个人资料路径
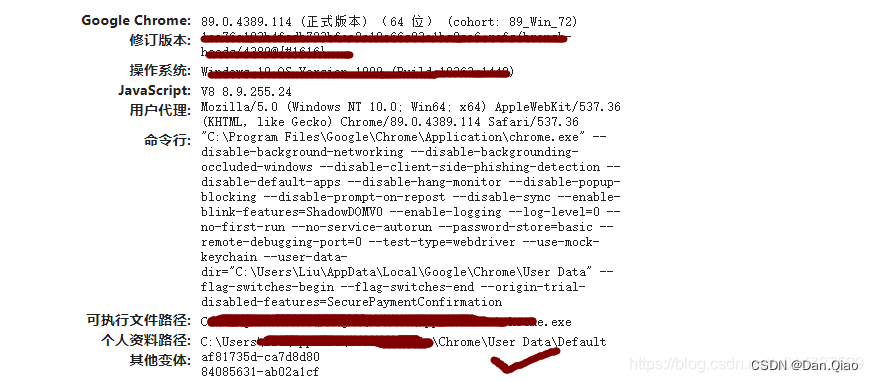
注意:不要复制Default。
3.代码
from selenium import webdriver
option = webdriver.ChromeOptions()
option.add_argument(r'--user-data-dir=C:\Users\qiao\AppData\Local\Google\Chrome\User Data')
option.add_experimental_option('excludeSwitches', ['enable-automation'])
driver = webdriver.Chrome(options=option)
此时启动的浏览器和本地直接打开浏览器内容一致,可以跳过部分网站对selenium的检测机制。
4.以上只能让一个浏览器实例有"记忆",如果selenium同时启动多个浏览器,只有一个浏览器会成功,其它则会因为user data共享的混乱导致失败,不信可以试试,我的解决方案是在C:\temp\Chrome\目录下复制这个文件夹"C:\Users\qiao\AppData\Local\Google\Chrome\User Data"多个,分别命名为User Data01, User Data02,…
文件目录结构如下:
C:\temp\Chrome
|__User Data01
|__User Data02
|__User Data03
|__xxxx
然后在启动每个实例时指定user data路径,比如将它们以参数形式写到option.add_argument(r’–user-data-dir=pathxxx’)中,这样每个实例就能各自独立地带"记忆"运行了
5。当然大部分网站都不严格,不需要这么麻烦,如果你有更好的方法,欢迎留言评论!