paper:Pyramid Vision Transformer: A Versatile Backbone for Dense Prediction without Convolutions
official implementation:GitHub - whai362/PVT: Official implementation of PVT series
存在的问题
现有的 Vision Transformer (ViT) 主要设计用于图像分类任务,难以直接用于像素级密集预测任务,如目标检测和分割。这是因为存在以下问题
- 低分辨率输出:传统的Vision Transformer(ViT)在处理密集预测任务(如目标检测和语义分割)时,输出分辨率较低,难以获得高质量的像素级别预测。
- 高计算和内存开销:ViT在处理大尺寸输入图像时,计算和内存开销较高,限制了其在实际应用中的效率。
本文的创新点
为了解决上述问题,作者提出了 Pyramid Vision Transformer (PVT), PVT结合了卷积神经网络的金字塔结构和Transformer的全局感受野,旨在克服传统Transformer在处理密集预测任务时遇到的分辨率低、计算和内存开销大的问题。它可以作为 CNN 骨干网络的替代品,用于多种下游任务,包括图像级预测和像素级密集预测。具体包括:
- 金字塔结构:PVT引入了金字塔结构,可以生成多尺度的特征图,这对于密集预测任务是有益的。
- 空间缩减注意力层(SRA):为了处理高分辨率特征图并减少计算/内存成本,作者设计了 SRA 层来替代传统的多头注意力 (MHA) 层。
- 纯Transformer骨干:PVT 是一个没有卷积的纯 Transformer 骨干网络,可以用于各种像素级密集预测任务,并与 DETR 结合构建了一个完全无需卷积的目标检测系统。
实际效果
- PVT 在多个下游任务上进行了广泛的实验验证,包括图像分类、目标检测、实例和语义分割等,并与流行的 ResNets 和 ResNeXts 进行了比较。
- 实验结果表明,在参数数量相当的情况下,PVT 在 COCO 数据集上使用 RetinaNet 作为检测器时,PVT-Small 模型达到了 40.4 的 AP(平均精度),超过了 ResNet50+RetinaNet(36.3 AP)4.1 个百分点。
- PVT-Large 模型达到了 42.6 的 AP,比 ResNeXt101-64x4d 高出 1.6 个百分点,同时参数数量减少了 30%。
- 这些结果表明 PVT 可以作为 CNN 骨干网络的一个有效的替代,用于像素级预测,并推动未来的研究。
方法介绍
Overall Architecture
PVT的整体结构如图3所示
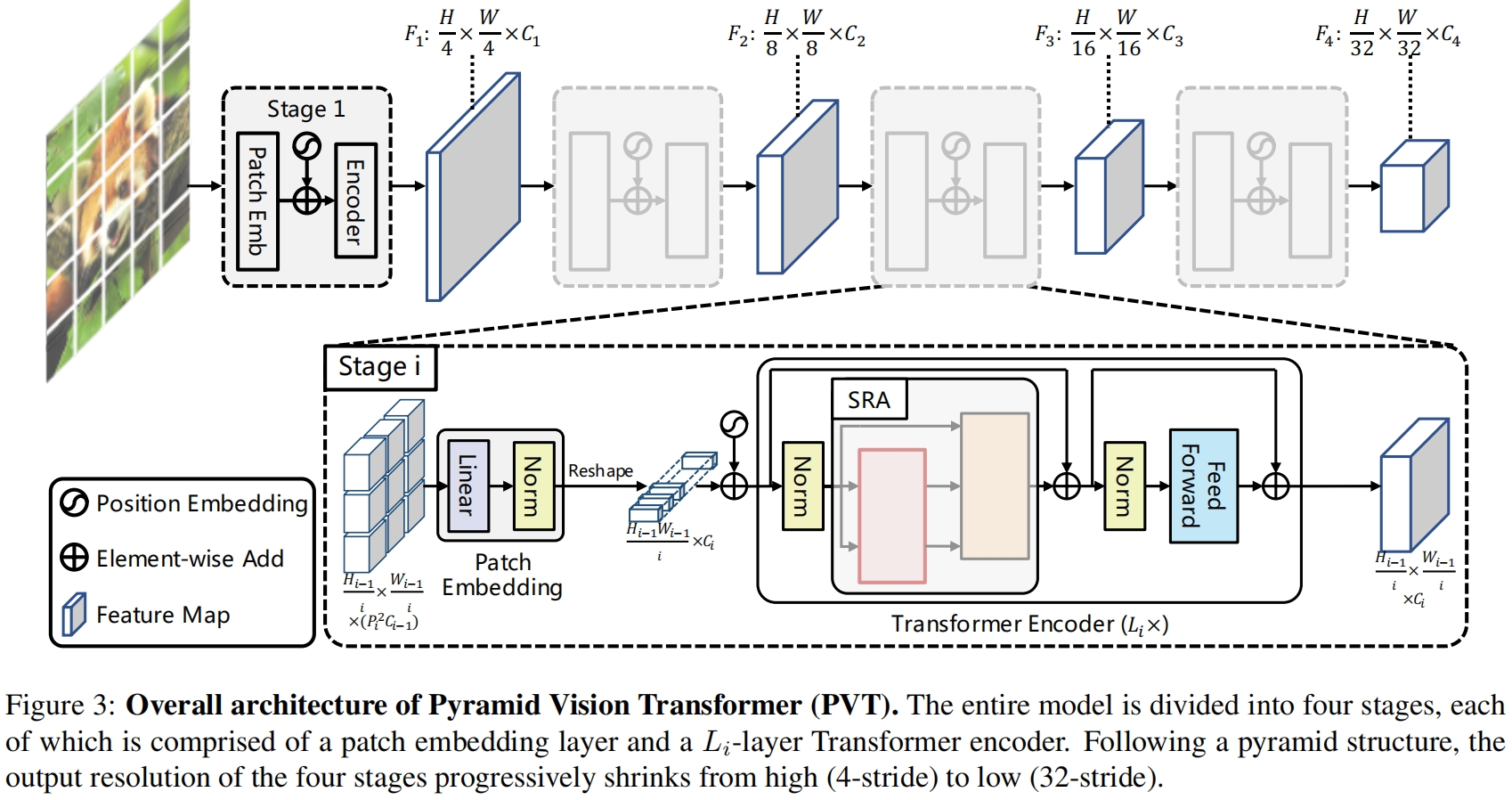
和CNN backbone类似,PVT也有四个stage来生成不同尺度的特征图。所有stage都有一个相似的架构,包括一个patch embedding层和 \(L_i\) 个Transformer encoder层。
在第一个stage,给定大小为 \(H\times W\times 3\) 的输入图片,我们首先将其划分为 \(\frac{HW}{4^2}\) 个patch,每个大小为4x4x3。然后将展平的patch送入一个线性映射层得到大小为 \(\frac{HW}{4^2}\times C_1\) 的输出。然后将输出和位置编码一起进入有 \(L_1\) 层的Transformer encoder,得到的输出reshape成大小为 \(\frac{H}{4}\times \frac{W}{4}\times C_1\) 的特征图 \(F_1\)。同样的方式,以前一个stage的输出特征图作为输入,我们得到特征图 \(F_2,F_3,F_4\),相对于原始输入图片的步长分别为8,16,32。用了特征图金字塔 \(\{F_1,F_2,F_3,F_4\}\),我们的方法可以很容易地应用于大多数下游任务,包括图像分类、目标检测和语义分割。
Feature Pyramid for Transformer
和CNN backbone用不同stride的卷积来得到不同尺度特征图不同,PVT使用一个渐进式shrinking策略,通过patch embedding层来控制特征图的尺度。
我们用 \(P_i\) 来表示第 \(i\) 个stage的patch size,在stage \(i\) 的开始,我们首先将输入特征图 \(F_{i-1}\in \mathbb{R}^{H_{i-1}\times W_{i-1}\times C_{i-1}}\) 均匀地划分成 \(\frac{H_{i-1}W_{i-1}}{P_i^2}\) 个patch,然后将每个patch展平并映射得到一个 \(C_i\) 维的embedding。在线性映射后,embedded patch的大小为 \(\frac{H_{i-1}}{P_i}\times \frac{W_{i-1}}{P_i}\times C_i\),其中宽高比输入小了 \(P_i\) 倍。
这样,我们就可以在每个stage灵活地调整特征图的尺度,从而将Transformer构建成金字塔结构。
Transforme Encoder
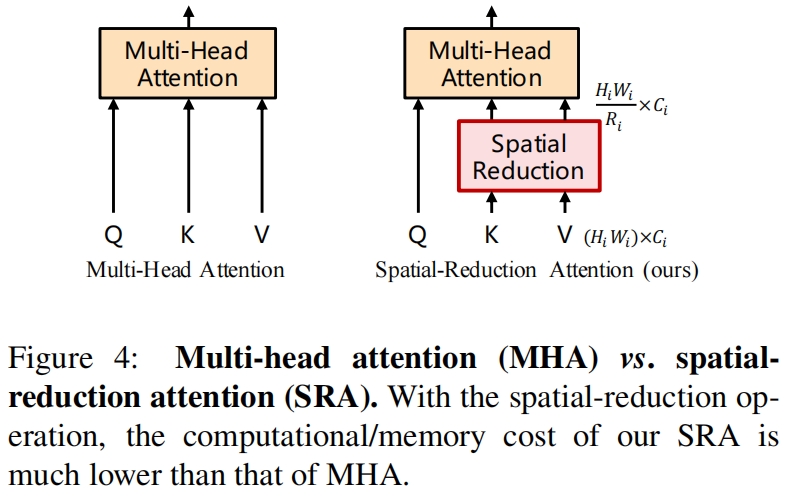
由于PVT需要处理高分辨率(stride-4)的特征图,我们提出了一种spatial-reduction attention(SRA)来替换encoder中传统的multi-head attention(MHA)。
和MHA类似,SRA的输入包括一个query \(Q\),一个key \(K\),一个value \(V\)。不同的是SRA在attention operation之前减小了 \(K\) 和 \(V\) 的大小,如图4所示,这大大减少了计算和内存的开销。
stage \(i\) 的SRA如下

其中 \(Concat(\cdot)\) 是拼接操作。\(W^{Q}_j\in \mathbb{R}^{C_i\times d_{head}},W^{K}_j\in \mathbb{R}^{C_i\times d_{head}},W^{V}_j\in \mathbb{R}^{C_i\times d_{head}},W^O\in \mathbb{R}^{C_i\times C_i}\) 是线性映射参数。\(N_i\) 是stage \(i\) 中attention层的head数量,所以每个head的维度(即\(d_{head}\))等于 \(\frac{C_i}{N_i}\)。\(SR(\cdot)\) 是降低输入序列(即 \(K\) 或 \(V\))空间维度的操作,如下:
![]()
其中 \(\mathbf{x}\in\mathbb{R}^{(H_iW_i)\times C_i}\) 表示一个输入序列,\(R_i\) 表示stage \(i\) 中attention层的reduction ratio。\(Reshape(\mathbf{x},R_i)\) 是将输入序列 \(\mathbf{x}\) reshape成大小为 \(\frac{H_iW_i}{R^2_i}\times (R^2_iC_i)\) 的序列的操作。\(W_S\in \mathbb{R}^{(R^2_iC_i)\times C_i}\) 是一个linear projection,它将输入序列的维度降低到 \(C_i\)。\(Norm(\cdot)\) 是layer normalization。和原始的Transformer一样,attention operation按下式计算
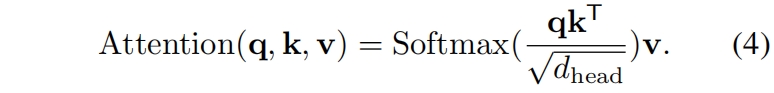
通过上述公式我们可以发现,MSA的计算/内存开销是MHA的 \(\frac{1}{R^2}\),因此MSA可以在有限的资源下处理更大的输入特征图或序列。
代码解析
见PVT v2的代码解析 PVT v2 原理与代码解析-CSDN博客
实验结果
模型涉及到的一些超参总结如下:
- \(P_i\):stage \(i\) 的patch size
- \(C_i\):stage \(i\) 的输出通道数
- \(L_i\):stage \(i\) 中的encoder层数
- \(R_i\):stage \(i\) 中SRA的reduction ratio
- \(N_i\):stage \(i\) 中SRA的head数量
- \(E_i\):stage \(i\) 中FFN层的expansion ratio
作者设计了一系列的PVT模型,具体配置如表1

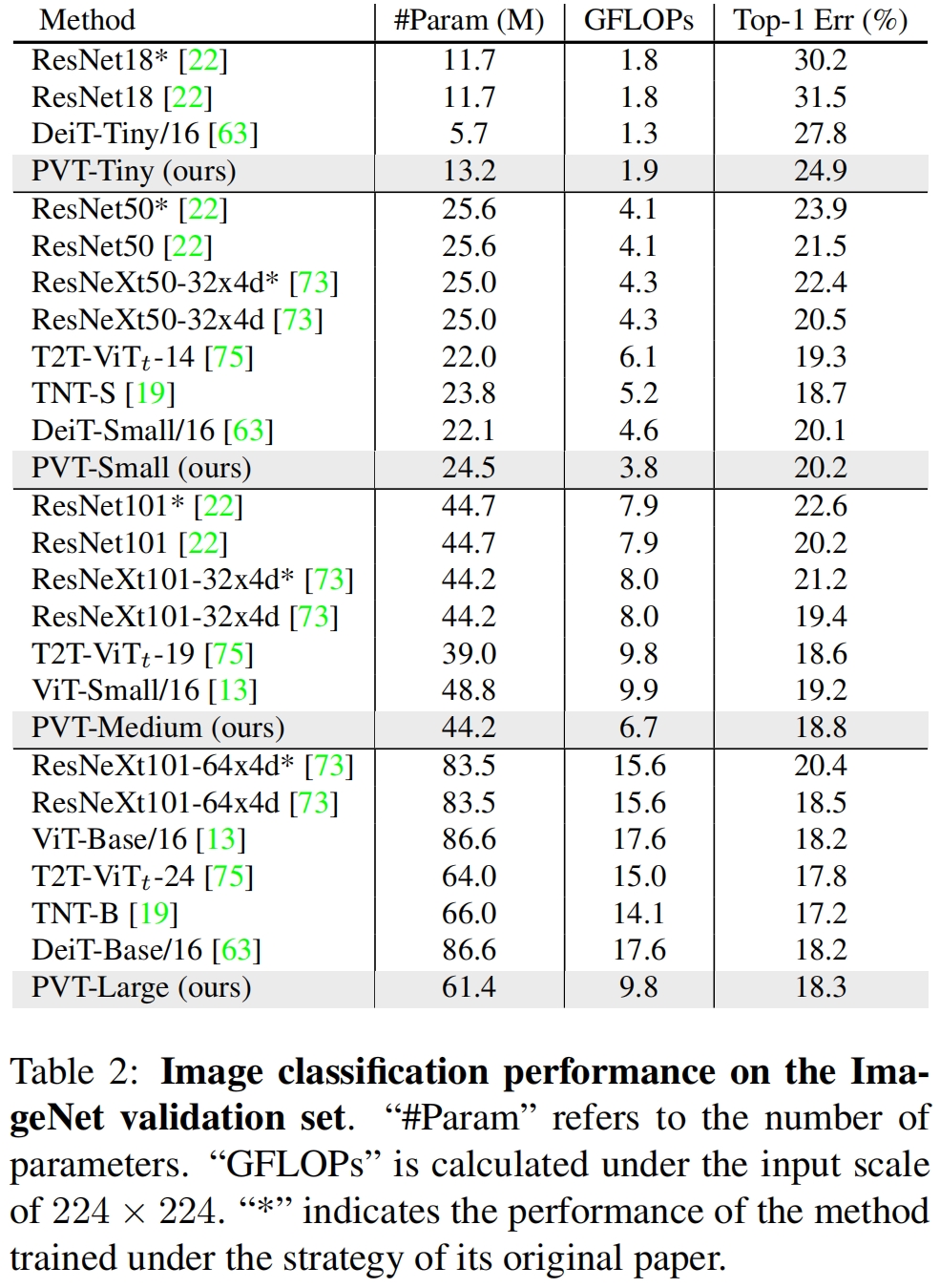
和其它SOTA模型在ImageNet的结果对比如表2所示
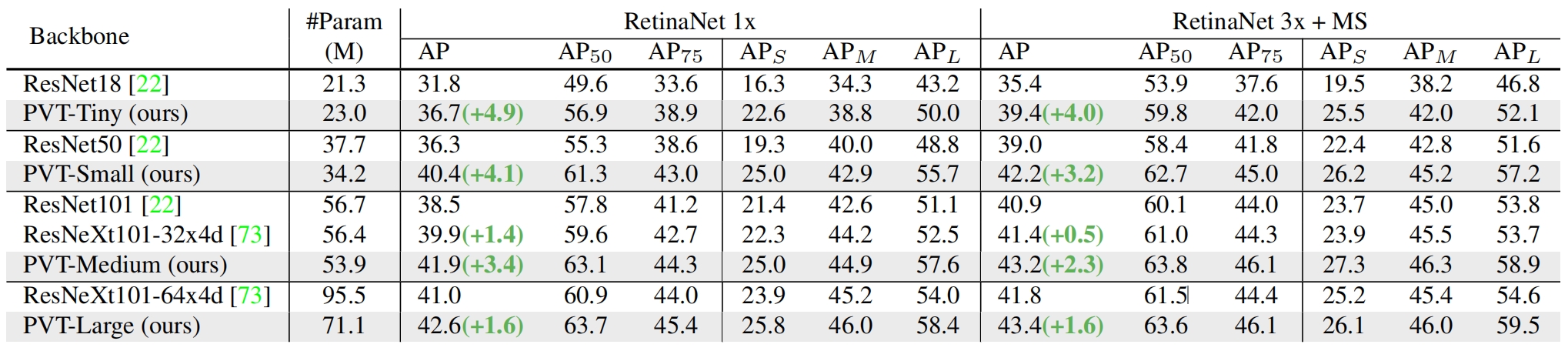
用RetinaNet上和其它backbone的结果对比如表3所示,可以看到PVT不同大小的模型与ResNet系列相比,参数更少精度更高。
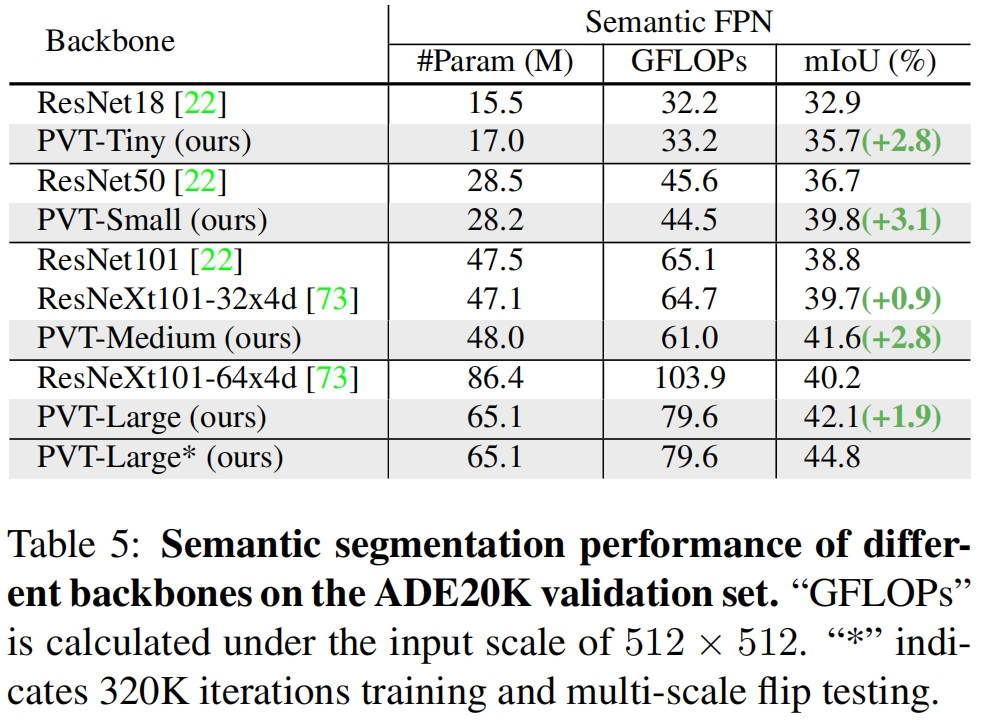
在语义分割模型Semantic FPN上PVT也超越了对应的ResNet