鸣谢UP主:是花子呀
本篇博客参考视频:https://www.bilibili.com/video/BV17i421X7q7/?spm_id_from=333.880.my_history.page.click&vd_source=38d6ea3466db371e6c07c24eed03219b
Lora 是个啥?Lora 的 缩写
Lora:Low Rank Adaption
低秩适配
什么是“秩”?
你要了解 Lora,也就是“低秩适配”,你首先得明白“秩”是个什么东西罢?
“秩”是矩阵里面的一个知识点,打个比方来解释:
情况一:
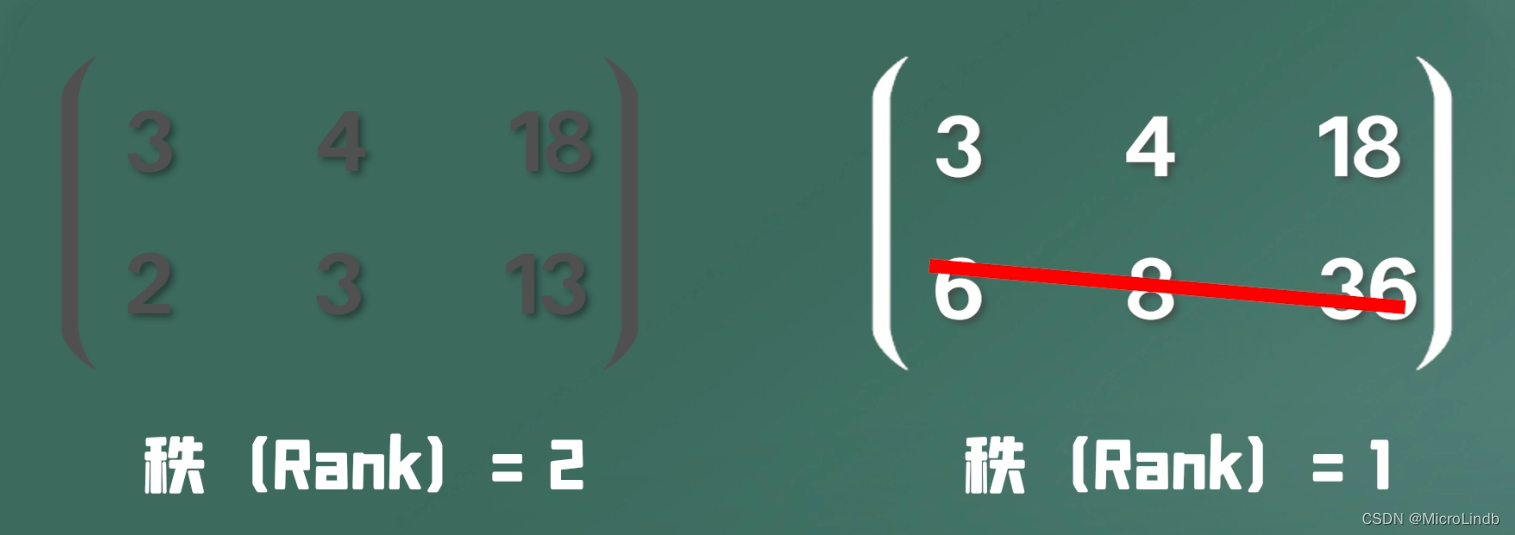
下面这个例子,我们去求 苹果 和 桃子 各是多少钱 → 3x + 4y = 18、2x + 3y = 13 → x=2、y=3
我们能得出 x 和 y 的值,这是因为 这两个等式 线性独立

情况二:
但是,如果是下面这种情况,我们就无法求出 x、y:
3x + 4y = 18、6x + 8y = 36 → x=?、y=?
因为它们其实可以化简为同一个式子

总结:
所以,矩阵的 秩 的数量,即是它的 线性独立的行 的多少!
也就是说,一个矩阵的 秩 越大,它的 有效信息含量 就越大
原理
原理就是,将一个 大矩阵 变成一个 小矩阵,训练起来就轻松了

怎么把一个大矩阵变成小矩阵呢?
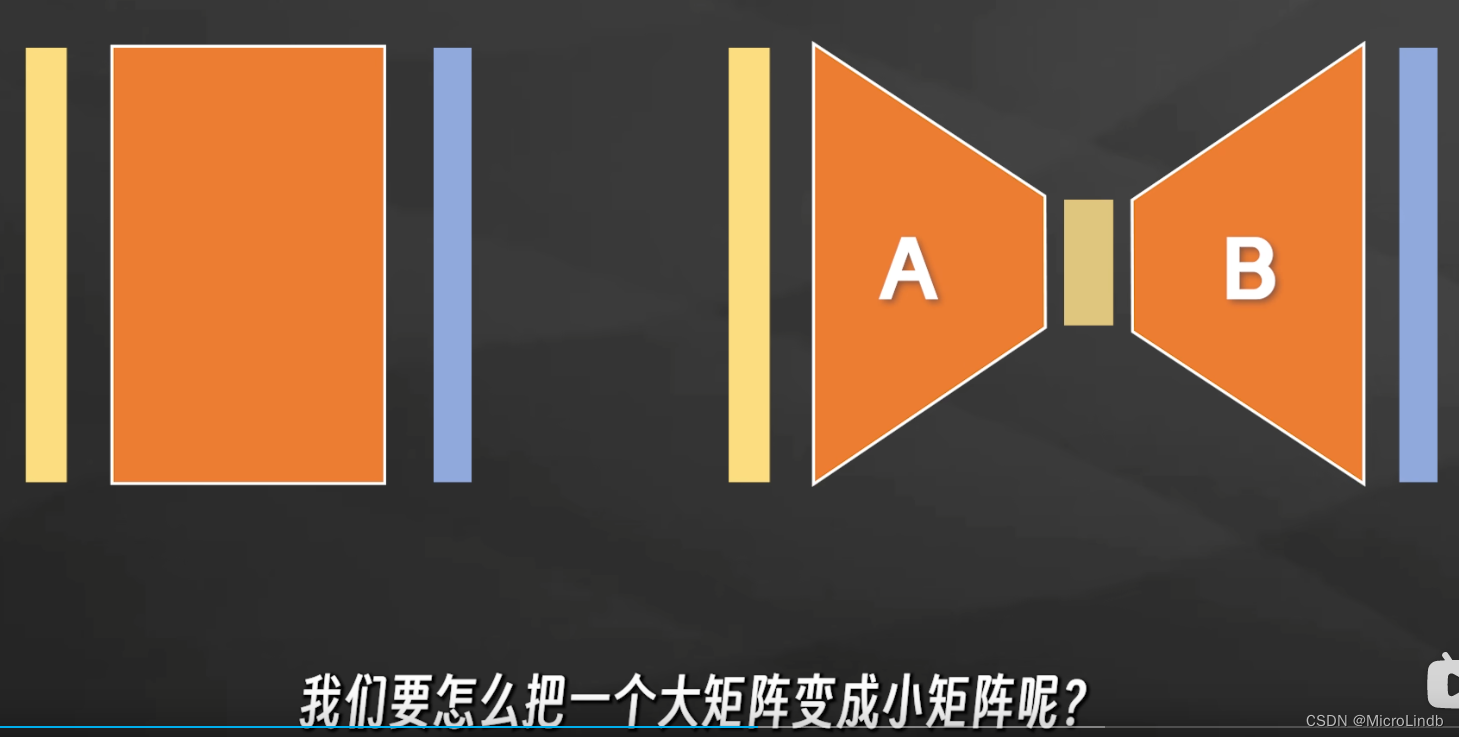
大小矩阵相互转化的例子(通俗易懂)
小明要开车,去 A、B、C 这 3 个城市,
矩阵(s):[ 200,400,1000 ]

他有 3 辆车,分别是 X、Y、Z,速度分别为:100、120、200 km/h
因为 t = s * 1/v
又因为 1/v = 1/100、1/120、1/200
矩阵(1/v):[ 1/100,1/120,1/200 ]

所以,
将 矩阵(s)和 矩阵(1/v)相乘:

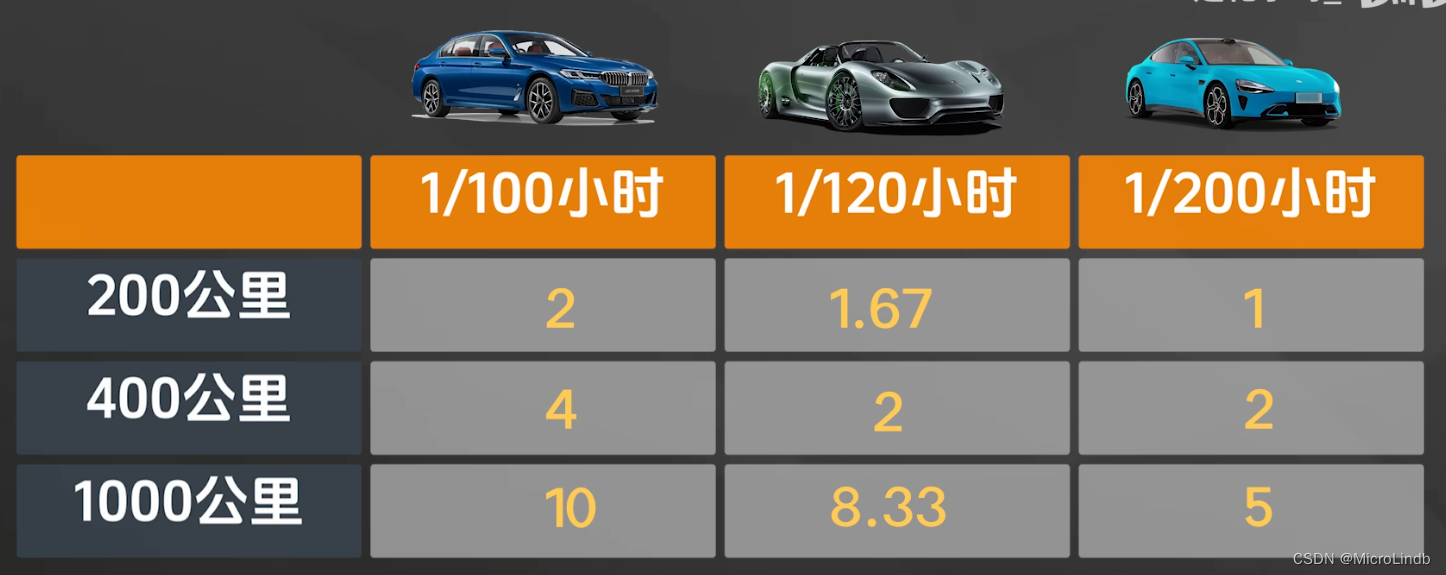
所以你可以看到,我们将 2个 小矩阵 相乘,得到了 一个 大矩阵:

反推,1个 大矩阵 也可以 分解成 2个 小矩阵

那么,操作来了!
在大模型中,我们如果将 1个 1000 * 1000 =1000000 参数的 大矩阵 分解为 2个 1 * 1000 = 1000 ,总计 2000 参数的小矩阵的相乘。
那么,本来我们在调整大矩阵时,我们本来要调整 1000x1000 个参数,而现在,我们只需要调整 2000 个就能达到效果!
少调整了 998000 个参数!

Lora 是如何与 checkpoint 结合的?
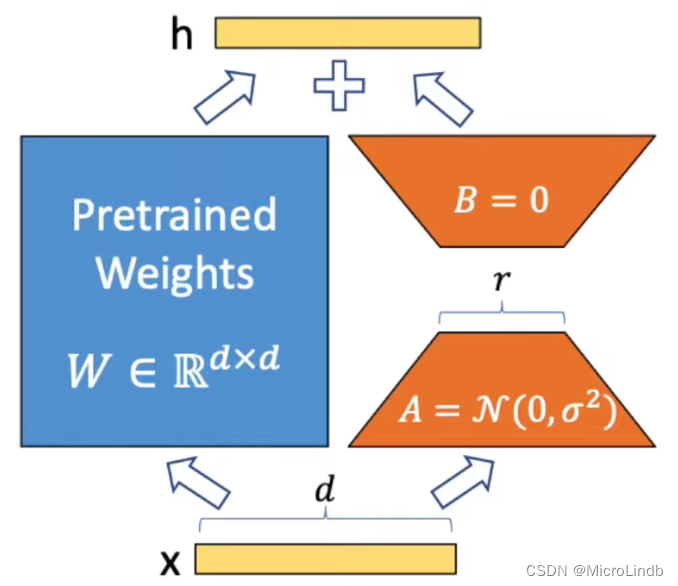
1.步骤一
在训练的初始阶段,Lora 就额外开辟了一条旁路进行 升维 → 修改高维数据 → 降维 的操作。
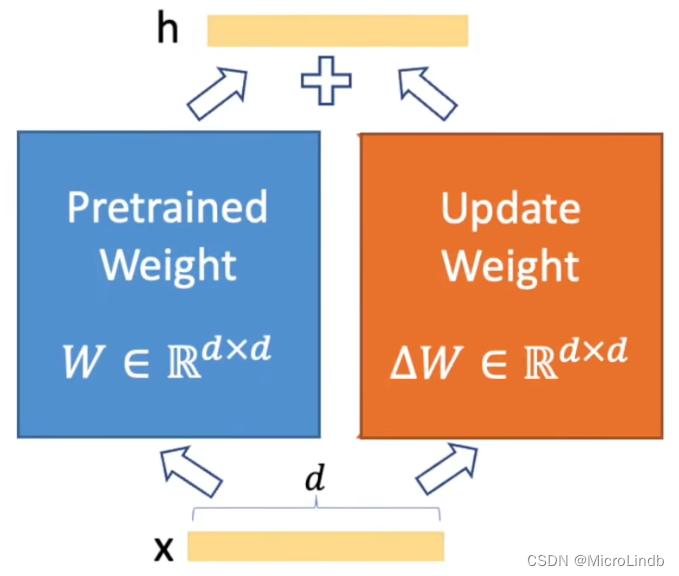
2.步骤二
这张图其实和上面那张图是等效的,只不过,这张图隐藏了 升维 和 降维 的过程
升维是通过将 1个大矩阵 转为 2个小矩阵 相乘
然后修改参数
然后将 2个 被修改了参数的小矩阵 重新相乘 回到 1个 大矩阵
之后,我们将 Pretrained Weight 和 Update Weight(Lora)的矩阵相加!
注意!是相加!所以这根本就不会耗费什么资源,我们只是用加法来更新参数而已
3.步骤三
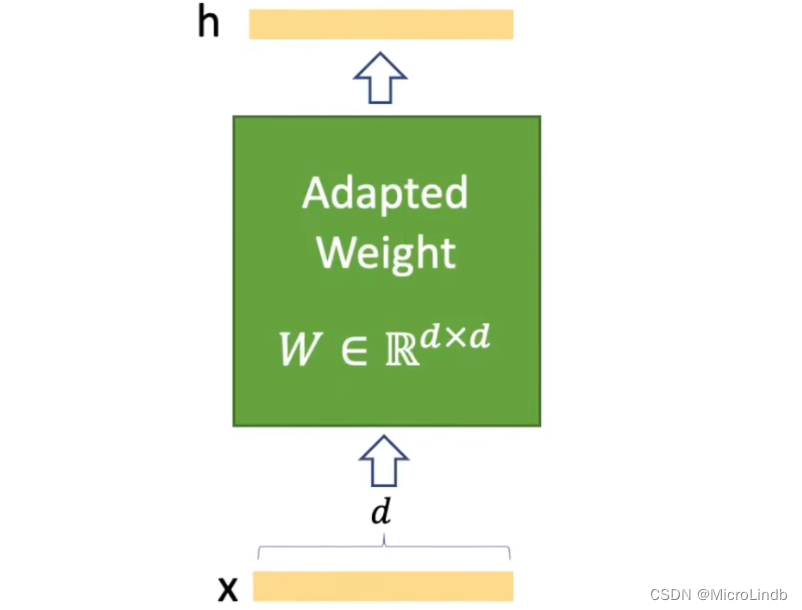
Pretrained Weight + Update Weight(Lora)== Adapted Weight
原始权重 + Lora计算权重 → 新的输出权重