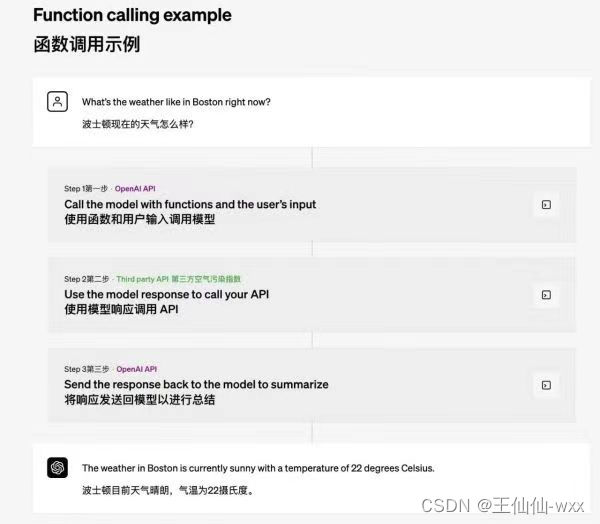
Python怎么搜索文献
Python 是一种流行的编程语言,因其便捷易用、拥有丰富的自然语言处理工具、以及大量可靠的第三方包而闻名。Python不仅在数据分析、机器学习和Web开发等领域都具有广泛的应用,而且也在学术界和研究领域受到欢迎。本文将告诉你Python如何用于搜索和处理学术文献。
为什么要用Python搜索文献?
文献检索是学术界和研究领域必不可少的一项工作。传统的文献检索方法是使用数据库中的关键字搜索,因此所有匹配关键字的文献都会被返回,但这种方法并不一定能够满足研究人员的需求。因此,Python成为了一种流行的工具,因为它可以使用自然语言处理技术来改善检索方法。Python有许多第三方模块可以方便快捷地搜索和处理学术文献。
如何使用Python搜索文献
Python有许多用于处理学术文献的第三方模块,例如,pandas、numpy、nltk、scikit-learn等库均可以用于检索、下载、处理、管理和分析学术文献。下面将介绍一些使用Python搜索文献的技巧。
使用pandas和numpy库搜索文献
pandas是一个流行的Python库,用于数据清理、数据分析和数据可视化等。pandas库中的read_csv方法可以从CSV文件中读取数据,可以使用此方法读取BibTeX格式的学术文献,然后使用numpy库中的搜索函数来搜索。
以下是使用pandas和numpy搜索文献的步骤:
- 下载BibTeX格式的学术文献文件;
- 使用pandas中的read_csv方法读取文件;
- 使用numpy库中的搜索函数来搜索。
import pandas as pd
import numpy as np# 读取BibTeX格式文献文件
data = pd.read_csv('bibliography.csv')# 找到包含关键字'machine learning'的文献
machine_learning_papers = data[np.char.find(data['abstract'].str.lower(), 'machine learning') > -1]# 找到包含关键字'deep learning'的文献
deep_learning_papers = data[np.char.find(data['abstract'].str.lower(), 'deep learning') > -1]# 打印搜索结果
print('Machine learning papers:')
print(machine_learning_papers.title)
print('\n\nDeep learning papers:')
print(deep_learning_papers.title)
使用nltk库搜索文献
nltk是一个自然语言处理库,可用于搜索和处理学术文献。nltk库中包含了一些用于文本处理和相似性计算的函数,可以使用这些函数来搜索和评估文献。
以下是使用nltk搜索文献的步骤:
- 下载BibTeX格式的学术文献文件;
- 读取文件并将其转换为nltk的text对象;
- 使用nltk的函数来处理和搜索文献。
import nltk
import stringnltk.download('punkt')# 读取BibTeX格式文献文件
with open('bibliography.bib', 'r') as f:data = f.read()# 将文件转换为nltk的text对象
papers = nltk.Text(data)# 打印包含关键字'neural network'的句子
for sent in papers.sentences:if 'neural network' in sent.lower():print(sent)
使用scikit-learn库搜索文献
scikit-learn是一个流行的Python机器学习库,但它也可以用于文献检索。scikit-learn库中的向量化函数可以将文本数据转换为向量,然后可以使用这些向量来计算文本相似性。
以下是使用scikit-learn搜索文献的步骤:
- 下载BibTeX格式的学术文献文件;
- 读取文件,并使用scikit-learn库中的向量化函数将其转换为向量;
- 使用scikit-learn库中的余弦相似性函数计算文本相似度。
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.metrics.pairwise import cosine_similarity# 读取BibTeX格式文献文件
with open('bibliography.bib', 'r') as f:data = f.readlines()# 使用TfidfVectorizer将文献转换为向量
tfidf = TfidfVectorizer().fit_transform(data)# 计算相似度矩阵
similarity_matrix = cosine_similarity(tfidf, tfidf)# 打印相似度最高的前五篇论文
print('Top 5 most similar papers:')
for i, paper in enumerate(data):top_similar = np.argsort(similarity_matrix[i])[-6:-1]print(f'Paper {i+1}:\n{paper}\nTop similar papers:\n')for j in top_similar:if j != i:print(f'Paper {j+1}: {data[j]}')
结论
Python是一种非常适合搜索和处理学术文献的编程语言。pandas、numpy、nltk和scikit-learn等第三方库提供了各种函数和方法,可以方便快捷地搜索、管理和分析学术文献。因此使用Python来搜索文献是一种高效和可靠的方法,并且有助于研究人员在研究过程中节省时间和努力。
最后的最后
本文由chatgpt生成,文章没有在chatgpt生成的基础上进行任何的修改。以上只是chatgpt能力的冰山一角。作为通用的Aigc大模型,只是展现它原本的实力。
对于颠覆工作方式的ChatGPT,应该选择拥抱而不是抗拒,未来属于“会用”AI的人。
🧡AI职场汇报智能办公文案写作效率提升教程 🧡 专注于AI+职场+办公方向。
下图是课程的整体大纲
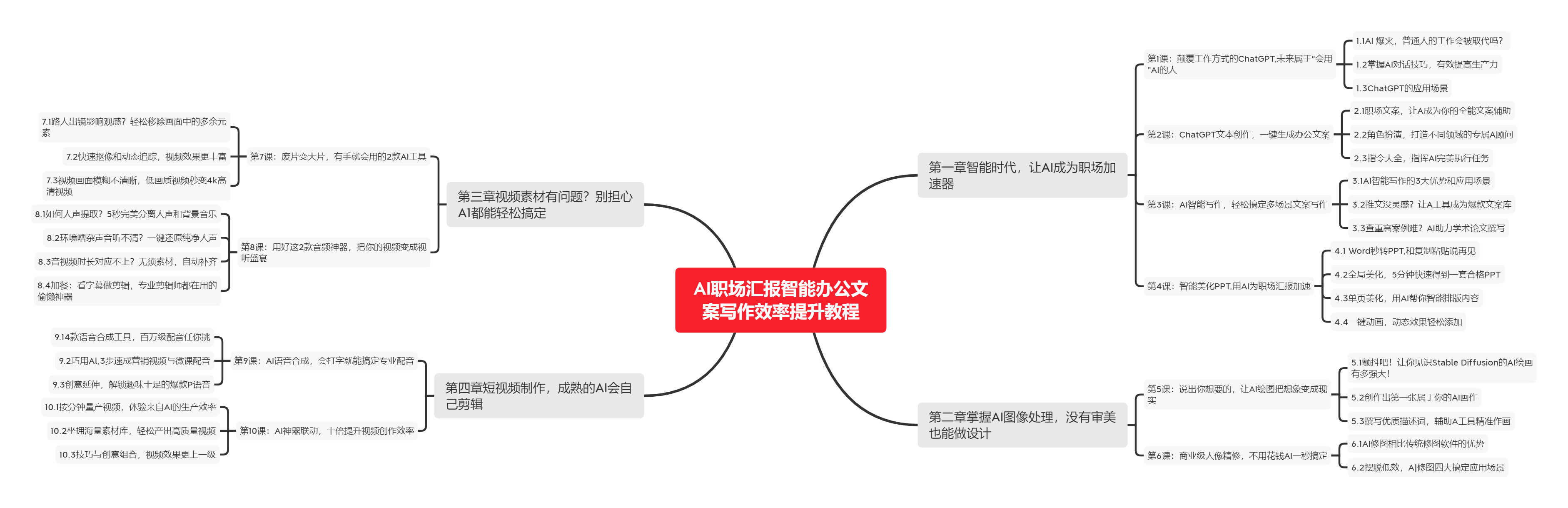

下图是AI职场汇报智能办公文案写作效率提升教程中用到的ai工具

🚀 优质教程分享 🚀
- 🎄可以学习更多的关于人工只能/Python的相关内容哦!直接点击下面颜色字体就可以跳转啦!
| 学习路线指引(点击解锁) | 知识定位 | 人群定位 |
|---|---|---|
| 🧡 AI职场汇报智能办公文案写作效率提升教程 🧡 | 进阶级 | 本课程是AI+职场+办公的完美结合,通过ChatGPT文本创作,一键生成办公文案,结合AI智能写作,轻松搞定多场景文案写作。智能美化PPT,用AI为职场汇报加速。AI神器联动,十倍提升视频创作效率 |
| 💛Python量化交易实战 💛 | 入门级 | 手把手带你打造一个易扩展、更安全、效率更高的量化交易系统 |
| 🧡 Python实战微信订餐小程序 🧡 | 进阶级 | 本课程是python flask+微信小程序的完美结合,从项目搭建到腾讯云部署上线,打造一个全栈订餐系统。 |