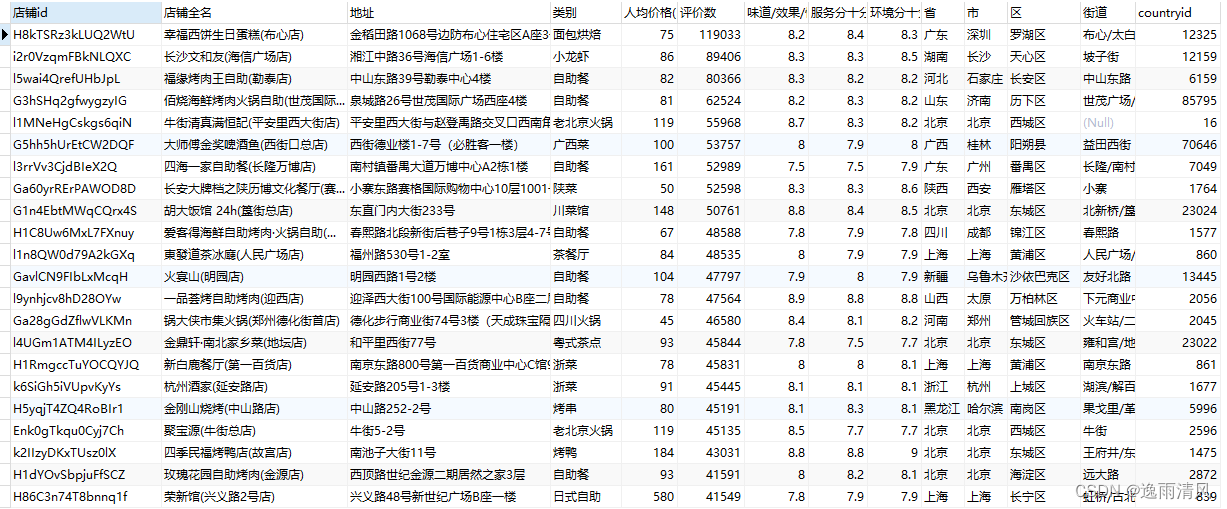
第一次实验使用最基本的公共物品游戏,不外加其他的treatment。班里的学生4人一组,一共44/4=11组。一共玩20个回合的公共物品游戏。每回合给15秒做决定的时间。第十回合后,给大家放一个几分钟的“爱心”视频(链接如下),然后继续完成剩下的10回合。
修改列名
把“来源”,“来源详情”,“来自IP” 这几个无关变量删除。重新命名前面几个变量,新变量对应名称为:'序号','提交答卷时间','所用时间','性别'。把代表组号的那一个变量的名字重新命名为“team_num”。把后面所有回合的变量名重新命名为“round1”, round2,....round20。以及最后两个测算风险偏好和模糊偏好的变量分别重新命名为risk_atti 和 ambiguity_atti。
数据和完整代码
# 读取数据
data <- read.csv("datar.csv", header = TRUE, stringsAsFactors = FALSE, fileEncoding = "GBK")
datahead(data,5)# 删除无关变量
data <- data[, !names(data) %in% c("来源", "来源详情", "来自IP")]# 重新命名变量
colnames(data) <- c("序号", "提交答卷时间", "所用时间", "性别", "team_num", paste0("round", 1:20), "risk_atti", "ambiguity_atti")names(data)
head(data,5)
变量赋值
data$gender <- ifelse(data$性别 == "男", 1, 0)
head(data,5)看“爱心”视频前,大家前10回合的平均贡献值是多少?看“爱心”视频后,大家后10回合的平均贡献值是多少?
# 提取前10回合和后10回合的数据
before_video <- data[, 7:16]
after_video <- data[, 17:26]# 计算平均贡献值
avg_contribution_before <- rowMeans(before_video, na.rm = TRUE)
avg_contribution_after <- rowMeans(after_video, na.rm = TRUE)# 输出结果
avg_contribution_before <- mean(avg_contribution_before, na.rm = TRUE)
avg_contribution_after <- mean(avg_contribution_after, na.rm = TRUE)cat("看“爱心”视频前,大家前10回合的平均贡献值是:", avg_contribution_before, "\n")
cat("看“爱心”视频后,大家后10回合的平均贡献值是:", avg_contribution_after, "\n")
# 导入绘图库
library(ggplot2)# 创建数据框
contribution <- data.frame(Time_Period = c("Before Video", "After Video"),Average_Contribution = c(avg_contribution_before, avg_contribution_after)
)# 绘制柱状图,并标上数据值
ggplot(contribution, aes(x = Time_Period, y = Average_Contribution, fill = Time_Period)) +geom_bar(stat = "identity") +geom_text(aes(label = round(Average_Contribution, 2)), vjust = -0.5) + # 标上数据值labs(title = "Average Contribution Before and After Watching 'Love' Video",x = "Time Period",y = "Average Contribution") +theme_minimal() +theme(legend.position = "none")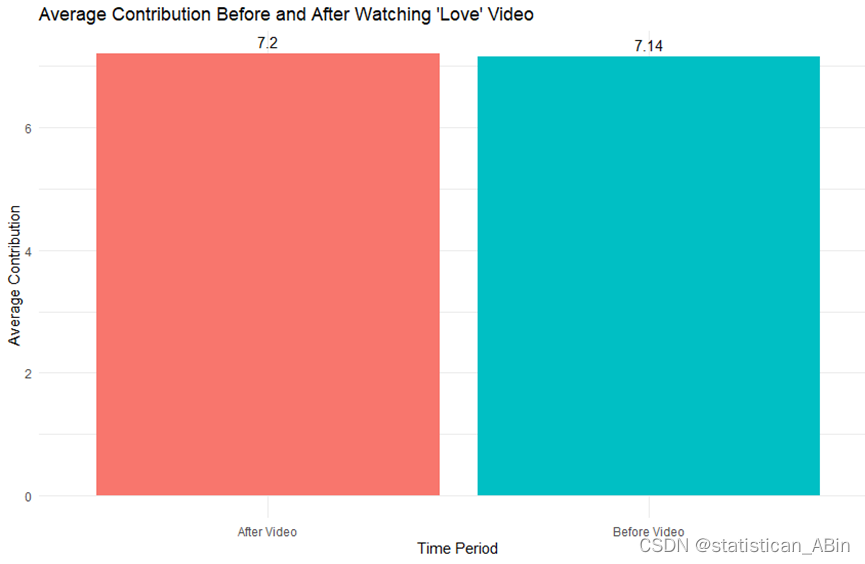
从结果和可视化都可以看出,看“爱心”视频前,大家前10回合的平均贡献值是7.138889,看“爱心”视频后,大家后10回合的平均贡献值是7.2
异常值检测
# 找出所用时间超过800秒的同学
outliers_800 <- data[data$'所用时间' == '808秒', ]
outliers_800
# 找出所用时间为314秒的同学
outliers_314 <- data[data$'所用时间' == '314秒', ]
# 找出所用时间为74秒的同学
outliers_74 <- data[data$'所用时间' == '74秒', ]
# 将outliers合并
outliers <- rbind(outliers_800, outliers_314, outliers_74)
outliers
# 从数据中删除outliers
data <- data[!(rownames(data) %in% rownames(outliers)), ]# 重新计算Part 1
before_video <- data[, 7:16]
after_video <- data[, 17:26]avg_contribution_before <- rowMeans(before_video, na.rm = TRUE)
avg_contribution_after <- rowMeans(after_video, na.rm = TRUE)avg_contribution_before <- mean(avg_contribution_before, na.rm = TRUE)
avg_contribution_after <- mean(avg_contribution_after, na.rm = TRUE)删除了异常值之后,看“爱心”视频前,大家前10回合的平均贡献值是6.751515,看“爱心”视频后,大家后10回合的平均贡献值是7.490909
女同学的前十和后十回合的平均贡献值是多少?男生呢?
# 按性别分组
female_data <- subset(data, 性别 == "女")
male_data <- subset(data, 性别 == "男")# 提取前十回合和后十回合的数据
before_video_female <- female_data[, 7:16]
before_video_female
after_video_female <- female_data[, 17:26]
before_video_male <- male_data[, 7:16]
after_video_male <- male_data[, 17:26]# 计算平均贡献值
avg_contribution_before_female <- rowMeans(before_video_female, na.rm = TRUE)
avg_contribution_after_female <- rowMeans(after_video_female, na.rm = TRUE)
avg_contribution_before_male <- rowMeans(before_video_male, na.rm = TRUE)
avg_contribution_after_male <- rowMeans(after_video_male, na.rm = TRUE)# 计算平均贡献值的平均值
avg_contribution_before_female <- mean(avg_contribution_before_female, na.rm = TRUE)
avg_contribution_after_female <- mean(avg_contribution_after_female, na.rm = TRUE)
avg_contribution_before_male <- mean(avg_contribution_before_male, na.rm = TRUE)
avg_contribution_after_male <- mean(avg_contribution_after_male, na.rm = TRUE)女同学的前十回合的平均贡献值是5.266667,女同学的后十回合的平均贡献值是6.3,男同学的前十回合的平均贡献值是7.308333,男同学的后十回合的平均贡献值是7.9375
为了探索不同风险偏好的同学在观看“爱心”视频前后的平均贡献值,我们可以按照之前的步骤进行数据处理和分析。首先,我们需要将风险偏好转换为风险偏好等级,然后按照这些等级将数据分组,分别计算他们在观看视频前后的平均贡献值。
# 根据映射关系将风险偏好转换为相应的风险偏好等级
risk_attitude_levels <- c("highly risk loving", "very risk loving", "risk loving", "risk neutral", "slightly risk averse", "risk averse", "very risk averse", "highly risk averse", "stay in bed", "stay in bed")data$risk_attitude_level <- risk_attitude_levels[data$risk_atti]# 按风险偏好等级分组
risk_attitude_groups <- split(data, data$risk_attitude_level)# 计算每个组在观看视频前后的平均贡献值
avg_contribution_before <- sapply(risk_attitude_groups, function(group) {avg_before <- mean(rowMeans(group[, 7:16], na.rm = TRUE), na.rm = TRUE)return(avg_before)
})avg_contribution_after <- sapply(risk_attitude_groups, function(group) {avg_after <- mean(rowMeans(group[, 17:26], na.rm = TRUE), na.rm = TRUE)return(avg_after)
})# 合并结果为数据框
avg_contribution <- data.frame(Risk_Attitude = names(avg_contribution_before),Avg_Contribution_Before = avg_contribution_before,Avg_Contribution_After = avg_contribution_after)# 输出结果
print(avg_contribution)
高风险偏好者(highly risk loving)在观看视频前的平均贡献值较高,但在观看视频后降低到较低水平,这可能表明他们更倾向于冒险和自我利益,并且对于公共物品的贡献程度受到外部因素影响较大。风险厌恶者(risk averse)在观看视频前后的平均贡献值有所增加,这可能表明他们更加稳健和谨慎,但在观看视频后表现出更多的愿意参与公共物品的贡献。风险中性者(risk neutral)在观看视频前后的平均贡献值保持相对稳定,这可能表明他们的决策相对稳定,不受外部因素的影响较大。风险略微厌恶者(slightly risk averse)和非常风险厌恶者(very risk averse)在观看视频前后的平均贡献值变化较小,这可能表明他们的行为相对稳定,不受外部因素的影响较大。保持在床上者(stay in bed)在观看视频前后的平均贡献值有所增加,这可能表明他们对于外部因素的反应较弱,但在观看视频后表现出更多的愿意参与公共物品的贡献。
综上所述,不同风险偏好等级的同学在观看视频前后的行为表现有所不同,这可能受到个体风险态度和外部环境的影响。针对这些不同特点,我们可以制定更具针对性的鼓励措施,以促进更多人为公共物品做出贡献。
创作不易,希望大家多点赞关注评论!!!