【x264】变换量化模块的简单分析
- 1. 变换量化
- 1.1 变换(transform)
- 1.2 量化(quant)
- 2. 编码入口(x264_macroblock_encode)
- 2.1 内部编码(macroblock_encode_internal)
- 2.1.1 SKIP模式
- 2.1.1.1 skip编码(macroblock_encode_skip)
- 2.1.2 Intra编码
- 2.1.2.1 16x16块的intra编码(mb_encode_i16x16)
- (1)变换(sub16x16_dct)
- (2)量化(quant_4x4x4)
- (3)反量化(dequant_4x4)
- (4)反变换
- (5)DC分量的变换与量化
- 2.1.2.2 8x8块的intra编码(x264_mb_encode_i8x8)
- 2.1.2.3 4x4块的intra编码(x264_mb_encode_i4x4)
- 2.1.3 Inter编码
- 3.小结
参考:
x264源代码简单分析:宏块编码(Encode)部分
【x264编码器】章节6——x264的变换量化
参数分析:
【x264】x264编码器参数配置
流程分析:
【x264】x264编码主流程简单分析
【x264】编码核心函数(x264_encoder_encode)的简单分析
【x264】分析模块(analyse)的简单分析—帧内预测
【x264】分析模块(analyse)的简单分析—帧间预测
【x264】码率控制模块的简单分析—宏块级码控工具Mbtree和AQ
【x264】码率控制模块的简单分析—帧级码控策略
【x264】码率控制模块的简单分析—编码主流程
【x264】lookahead模块的简单分析
1. 变换量化
变换量化是编码器当中用于节省编码码率的重要操作,其本身应该分为两个部分:变换(transform)和量化(quant),但是由于使用时通常配套使用,所以一般将两者统称为变换量化。变换量化模块处于预测模块之后,用于将预测的残差信息进一步压缩,通过消除图像中的相关性及减小图像编码的动态范围,获得更高的压缩效率。
1.1 变换(transform)
变换编码将图像时域信号变换成频域信号,在频域之中,图像信号能量大部分会集中在低频范围附近,相对于时域信号,码率有较大的下降。在x264当中,变换常用的方式为4x4尺寸的离散余弦变换,即便当前编码块大小为16x16或者8x8,仍然会分成多个4x4的小块进行计算,这样的操作避免了以往标准中使用的通用8x8离散余弦变换、逆变换经常出现的匹配不准问题。在进行变换之后,图像的低频信息(图像平缓区域)会集中到系数矩阵的左上角,高频信息会集中在系数矩阵的右下角,这样有利于去除人眼不敏感的高频信息
变换的过程用矩阵运算来表示为
Y = ( C f X C f T ) ⨂ E f = ( [ 1 1 1 1 2 1 − 1 − 2 1 − 1 − 1 1 1 − 2 2 − 1 ] X [ 1 2 1 1 1 1 − 1 − 2 1 − 1 − 1 2 1 − 2 1 − 1 ] ) ⨂ [ a 2 a b 2 a 2 a b 2 a b 2 b 2 4 a b 2 b 2 4 a 2 a b 2 a 2 a b 2 a b 2 b 2 4 a b 2 b 2 4 ] Y=(C_fXC^T_f) \bigotimes E_f=\\ (\begin{bmatrix} 1 & 1 & 1 & 1 \\ 2 & 1 & -1 & -2 \\ 1 & -1 & -1 & 1 \\ 1 & -2 & 2 & -1 \end{bmatrix} X \begin{bmatrix} 1 & 2 & 1 & 1 \\ 1 & 1 & -1 & -2 \\ 1 & -1 & -1 & 2 \\ 1 & -2 & 1 & -1 \end{bmatrix}) \bigotimes \begin{bmatrix} a^2 & \frac{ab}{2} & a^2 & \frac{ab}{2} \\ \frac{ab}{2} & \frac{b^2}{4} & \frac{ab}{2} & \frac{b^2}{4} \\ a^2 & \frac{ab}{2} & a^2 & \frac{ab}{2} \\ \frac{ab}{2} & \frac{b^2}{4} & \frac{ab}{2} & \frac{b^2}{4} \end{bmatrix} Y=(CfXCfT)⨂Ef=( 121111−1−21−1−121−21−1 X 111121−1−21−1−111−22−1 )⨂ a22aba22ab2ab4b22ab4b2a22aba22ab2ab4b22ab4b2
其中, a = 1 2 a=\frac{1}{2} a=21, b = 1 2 c o s ( π 8 ) b=\sqrt{\frac{1}{2}}cos(\frac{\pi}{8}) b=21cos(8π), b = 1 2 c o s ( 3 π 8 ) b=\sqrt{\frac{1}{2}}cos(\frac{3\pi}{8}) b=21cos(83π)。在x264当中, E f E_f Ef是在量化过程中计算的,在变换函数中,只会计算前面的部分。同时,矩阵的乘法运算可以改造成为两次一维整数DCT变换,例如先对图像或其残差块的每行进行一维整数DCT,然后对经过行变换的块的每列再应用一维整数DCT。每次一维整数DCT可以采用蝶形快速算法,从而节省计算时间,蝶形计算过程如下图所示
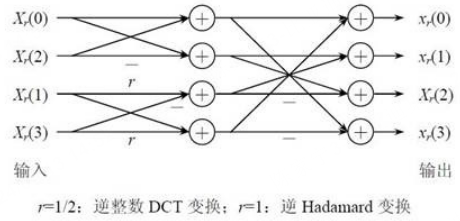
对于16x16块,还会对直流分量进行单独的变换量化,变换使用的是Hadamard变换,变换过程为:
Y D = ( [ 1 1 1 1 1 1 − 1 − 1 1 − 1 − 1 1 1 − 1 1 − 1 ] W D [ 1 1 1 1 1 1 − 1 − 1 1 − 1 − 1 1 1 − 1 1 − 1 ] ) / 2 Y_D= (\begin{bmatrix} 1 & 1 & 1 & 1 \\ 1 & 1 & -1 & -1 \\ 1 & -1 & -1 & 1 \\ 1 & -1 & 1 & -1 \end{bmatrix} W_D \begin{bmatrix} 1 & 1 & 1 & 1 \\ 1 & 1 & -1 & -1 \\ 1 & -1 & -1 & 1 \\ 1 & -1 & 1 & -1 \end{bmatrix}) / 2 YD=( 111111−1−11−1−111−11−1 WD 111111−1−11−1−111−11−1 )/2
1.2 量化(quant)
量化过程在不降低视觉效果的前提下应尽量减少图像编码长度,减少视觉恢复中不必要的信息。x264中使用标量量化技术,它将每个图像样点编码映射成较小的数值,一般标量量化器的原理是:
F Q = r o u n d ( y Q s t e p ) FQ=round(\frac{y}{Q_{step}}) FQ=round(Qstepy)
其中,y为输入样本点编码, Q s t e p Q_{step} Qstep为量化步长,FQ为y的量化值,round取整。对应的,反量化过程为:
y ′ = F Q ∗ Q s t e p y'=FQ*Q_{step} y′=FQ∗Qstep
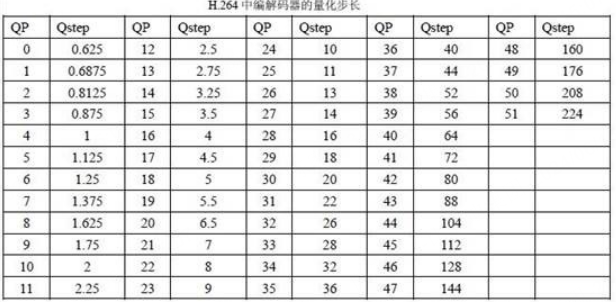
在量化和反量化过程中,量化步长 Q s t e p Q_{step} Qstep决定量化器的编码压缩率及图像精度。如果 Q s t e p Q_{step} Qstep较大,则量化值FQ动态范围较小,其相应的编码长度较小,但反量化时损失较多的图像细节信息;如果 Q s t e p Q_{step} Qstep较小,则FQ动态范围较大,相应的编码长度也较大,但图像细节信息损失较少。编码器会根据图像实际动态范围自动改变 Q s t e p Q_{step} Qstep值,在编码长度和图像精度之间折中,以达到最佳效果。QP和 Q s t e p Q_{step} Qstep对应的关系表如下,QP的范围为[0, 51], Q s t e p Q_{step} Qstep的范围为[0.625, 224]。每当QP增加6, Q s t e p Q_{step} Qstep就增加一倍。
量化过程还需要完成变换过程中 E f E_f Ef的计算,具体量化过程的运算为:
∣ Z i j ∣ = ( ∣ W i j ∣ ∗ M F + f ) > > q b i t s s i g n ( Z i j ) = s i g n ( W i j ) |Z_{ij}|=(|W_{ij}|*MF+f)>>qbits \\ sign(Z_{ij})=sign(W_{ij}) ∣Zij∣=(∣Wij∣∗MF+f)>>qbitssign(Zij)=sign(Wij)
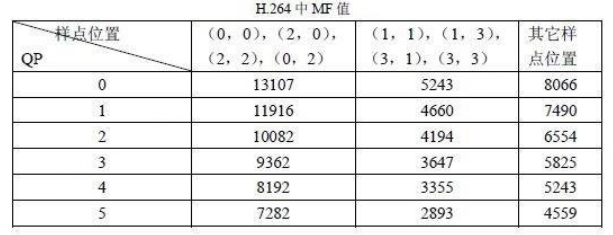
其中,">>"为右移运算,sign()为符号函数,Wij为DCT变换后的系数。MF的值如下表所示。表中只列出对应QP 值为0 到5 的MF 值。QP大于6之后,将QP实行对6取余数操作,再找到MF的值。qbits计算公式为“qbits = 15 + floor(QP/6)”。即它的值随QP 值每增加6 而增加1。
f 是偏移量(用于改善恢复图像的视觉效果)。对帧内预测图像块取 2 q b i t s 3 \frac{2^{qbits}}{3} 32qbits ,对帧间预测图像块取 2 q b i t s 6 \frac{2^{qbits}}{6} 62qbits。从表中看,确定了qp和样点位置就可以给出MF值,从而计算转换的后半部分的计算
对于16x16块,进行直流分量的量化为
∣ Z D ( i , j ) ∣ = ( ∣ Y D ( i , j ) ∣ ∗ M F ( 0 , 0 ) + 2 f ) > > ( q b i t s + 1 ) s i g n ( Z D ( i , j ) ) = s i g n ( W D ( i , j ) ) |Z_{D(i,j)}|=(|Y_{D(i,j)}|*MF_{(0,0)}+2f)>>(qbits+1) \\ sign(Z_{D(i,j)})=sign(W_{D(i,j)}) ∣ZD(i,j)∣=(∣YD(i,j)∣∗MF(0,0)+2f)>>(qbits+1)sign(ZD(i,j))=sign(WD(i,j))
其中, M F ( 0 , 0 ) MF_{(0,0)} MF(0,0)是位置为(0,0)的MF系数值,4x4的Hadamard变换也可以采用快速算法
2. 编码入口(x264_macroblock_encode)
编码入口函数为x264_macroblock_encode,位于encoder.c文件中的slice_write()函数。如果是YUV444,plane=3,chroma=0;如果是YUV420或YUV444,plane=1,chroma=1;否则,plane=1,chroma=0。
void x264_macroblock_encode( x264_t *h )
{if( CHROMA444 )macroblock_encode_internal( h, 3, 0 );else if( CHROMA_FORMAT )macroblock_encode_internal( h, 1, 1 );elsemacroblock_encode_internal( h, 1, 0 );
}
2.1 内部编码(macroblock_encode_internal)
该函数依据各种模式来对mb进行encode,主要工作流程为:
- 检查是否进行PCM编码,如果是PCM模式,直接copy而不进行预测和变换量化
- 检查是否进行skip编码,P_SKIP或B_SKIP模式(x264_macroblock_encode_skip)
- 帧内编码
(1)如果是16x16类型,16x16块的intra编码(mb_encode_i16x16)
(2)如果是8x8类型,8x8的intra编码(mb_encode_i8x8)
(3)如果是4x4类型,4x4的intra编码(mb_encode_i4x4) - 帧间编码
(1)检查无损模式(没有研究)
(2)是否支持8x8的变换,如果支持则使用当前帧和重建帧计算残差并且进行dct变换(sub16x16_dct8) ,之后进行量化(x264_quant_8x8),扫描(scan_8x8),反量化(dequant_8x8),反变换并存储到重建帧中(add8x8_idct8)
(3)普通的编码模式,会将16x16的块划分成为8x8,再将8x8的块划分成4x4的块。同样也是进行变换量化,之后扫描,反量化反变换 - 编码色度分量(x264_mb_encode_chroma)
在执行编码的过程中,基本上会进行变换、量化、扫描、反量化和反变换过程,变换通常使用dct变换,量化则是根据前面获取的量化参数执行,扫描过程则是将量化后系数矩阵中的非零系数集合在一起
static ALWAYS_INLINE void macroblock_encode_internal( x264_t *h, int plane_count, int chroma )
{int i_qp = h->mb.i_qp;// p帧的变换系数阈值int b_decimate = h->mb.b_dct_decimate;int b_force_no_skip = 0;int nz;h->mb.i_cbp_luma = 0;for( int p = 0; p < plane_count; p++ )h->mb.cache.non_zero_count[x264_scan8[LUMA_DC+p]] = 0;// ----- 1.检查PCM直接编码模式 ------ //// PCM模式表示当前mb可以直接传输,不经过预测和变换量化if( h->mb.i_type == I_PCM ){/* if PCM is chosen, we need to store reconstructed frame data */// 如果使用了PCM,需要存储重建的帧数据for( int p = 0; p < plane_count; p++ )h->mc.copy[PIXEL_16x16]( h->mb.pic.p_fdec[p], FDEC_STRIDE, h->mb.pic.p_fenc[p], FENC_STRIDE, 16 );if( chroma ){int height = 16 >> CHROMA_V_SHIFT;h->mc.copy[PIXEL_8x8] ( h->mb.pic.p_fdec[1], FDEC_STRIDE, h->mb.pic.p_fenc[1], FENC_STRIDE, height );h->mc.copy[PIXEL_8x8] ( h->mb.pic.p_fdec[2], FDEC_STRIDE, h->mb.pic.p_fenc[2], FENC_STRIDE, height );}return;}// ------ 2.检查skip模式 ------ ///*(1)P_L0不支持进一步的宏块分割,整个宏块作为一个单一的16x16块进行处理,适用于运动和纹理相对一致的区域(2)P_8x8每个宏块被分成四个独立的8x8子宏块,每个子宏块可以有自己的运动矢量,这适用于运动复杂或具有多个不同运动区域的宏块(3)P_SKIP又被称为copy模式,在这种模式下,宏块没有像素残差和运动矢量残差(MVD)。编码器不需要为这些宏块传输任何额外的数据,解码器可以直接从参考帧中复制相应的宏块。在解码时,使用运动矢量预测(MVP)作为实际的运动矢量,然后直接将预测的像素块作为重构的像素块。常用于固定摄像机拍摄的视频或其中的对象缓慢移动的场景,这种情况使用P_SKIP可以显著减少所需传输的数据量*/// 不允许使用skip模式,将skip类型进行修正if( !h->mb.b_allow_skip ){b_force_no_skip = 1;if( IS_SKIP(h->mb.i_type) ){if( h->mb.i_type == P_SKIP )h->mb.i_type = P_L0;else if( h->mb.i_type == B_SKIP )h->mb.i_type = B_DIRECT;}}// P帧中mb使用skip模式if( h->mb.i_type == P_SKIP ){/* don't do pskip motion compensation if it was already done in macroblock_analyse */// 不要做pskip运动补偿,如果它已经在macroblock_analyze中完成了if( !h->mb.b_skip_mc ){int mvx = x264_clip3( h->mb.cache.mv[0][x264_scan8[0]][0],h->mb.mv_min[0], h->mb.mv_max[0] );int mvy = x264_clip3( h->mb.cache.mv[0][x264_scan8[0]][1],h->mb.mv_min[1], h->mb.mv_max[1] );for( int p = 0; p < plane_count; p++ )h->mc.mc_luma( h->mb.pic.p_fdec[p], FDEC_STRIDE,&h->mb.pic.p_fref[0][0][p*4], h->mb.pic.i_stride[p],mvx, mvy, 16, 16, &h->sh.weight[0][p] );if( chroma ){int v_shift = CHROMA_V_SHIFT;int height = 16 >> v_shift;/* Special case for mv0, which is (of course) very common in P-skip mode. */if( mvx | mvy )h->mc.mc_chroma( h->mb.pic.p_fdec[1], h->mb.pic.p_fdec[2], FDEC_STRIDE,h->mb.pic.p_fref[0][0][4], h->mb.pic.i_stride[1],mvx, 2*mvy>>v_shift, 8, height );elseh->mc.load_deinterleave_chroma_fdec( h->mb.pic.p_fdec[1], h->mb.pic.p_fref[0][0][4],h->mb.pic.i_stride[1], height );if( h->sh.weight[0][1].weightfn )h->sh.weight[0][1].weightfn[8>>2]( h->mb.pic.p_fdec[1], FDEC_STRIDE,h->mb.pic.p_fdec[1], FDEC_STRIDE,&h->sh.weight[0][1], height );if( h->sh.weight[0][2].weightfn )h->sh.weight[0][2].weightfn[8>>2]( h->mb.pic.p_fdec[2], FDEC_STRIDE,h->mb.pic.p_fdec[2], FDEC_STRIDE,&h->sh.weight[0][2], height );}}// 编码skip模式的mbmacroblock_encode_skip( h );return;}// B帧中mb使用skip模式if( h->mb.i_type == B_SKIP ){/* don't do bskip motion compensation if it was already done in macroblock_analyse */// 不要做bskip运动补偿,如果它已经在macroblock_analyze中完成了if( !h->mb.b_skip_mc )x264_mb_mc( h );macroblock_encode_skip( h );return;}// ----- 3.Intra模式 ------ //if( h->mb.i_type == I_16x16 ) // 16x16{h->mb.b_transform_8x8 = 0;for( int p = 0; p < plane_count; p++, i_qp = h->mb.i_chroma_qp )mb_encode_i16x16( h, p, i_qp ); // 编码16x16的块}else if( h->mb.i_type == I_8x8 ) // 8x8{h->mb.b_transform_8x8 = 1;/* If we already encoded 3 of the 4 i8x8 blocks, we don't have to do them again. */// 如果已经编码了4个i8x8块中的3个,就不需要再做一次if( h->mb.i_skip_intra ){h->mc.copy[PIXEL_16x16]( h->mb.pic.p_fdec[0], FDEC_STRIDE, h->mb.pic.i8x8_fdec_buf, 16, 16 );M32( &h->mb.cache.non_zero_count[x264_scan8[ 0]] ) = h->mb.pic.i8x8_nnz_buf[0];M32( &h->mb.cache.non_zero_count[x264_scan8[ 2]] ) = h->mb.pic.i8x8_nnz_buf[1];M32( &h->mb.cache.non_zero_count[x264_scan8[ 8]] ) = h->mb.pic.i8x8_nnz_buf[2];M32( &h->mb.cache.non_zero_count[x264_scan8[10]] ) = h->mb.pic.i8x8_nnz_buf[3];h->mb.i_cbp_luma = h->mb.pic.i8x8_cbp;/* In RD mode, restore the now-overwritten DCT data. */if( h->mb.i_skip_intra == 2 )h->mc.memcpy_aligned( h->dct.luma8x8, h->mb.pic.i8x8_dct_buf, sizeof(h->mb.pic.i8x8_dct_buf) );}for( int p = 0; p < plane_count; p++, i_qp = h->mb.i_chroma_qp ){for( int i = (p == 0 && h->mb.i_skip_intra) ? 3 : 0; i < 4; i++ ){int i_mode = h->mb.cache.intra4x4_pred_mode[x264_scan8[4*i]];x264_mb_encode_i8x8( h, p, i, i_qp, i_mode, NULL, 1 ); // 编码4个8x8的块}}}else if( h->mb.i_type == I_4x4 ) // 4x4{h->mb.b_transform_8x8 = 0;/* If we already encoded 15 of the 16 i4x4 blocks, we don't have to do them again. */// 如果已经编码了16个i8x8块中的15个,就不需要再做一次if( h->mb.i_skip_intra ){h->mc.copy[PIXEL_16x16]( h->mb.pic.p_fdec[0], FDEC_STRIDE, h->mb.pic.i4x4_fdec_buf, 16, 16 );M32( &h->mb.cache.non_zero_count[x264_scan8[ 0]] ) = h->mb.pic.i4x4_nnz_buf[0];M32( &h->mb.cache.non_zero_count[x264_scan8[ 2]] ) = h->mb.pic.i4x4_nnz_buf[1];M32( &h->mb.cache.non_zero_count[x264_scan8[ 8]] ) = h->mb.pic.i4x4_nnz_buf[2];M32( &h->mb.cache.non_zero_count[x264_scan8[10]] ) = h->mb.pic.i4x4_nnz_buf[3];h->mb.i_cbp_luma = h->mb.pic.i4x4_cbp;/* In RD mode, restore the now-overwritten DCT data. */// 在RD模式下,恢复已经被覆盖的DCT数据if( h->mb.i_skip_intra == 2 )h->mc.memcpy_aligned( h->dct.luma4x4, h->mb.pic.i4x4_dct_buf, sizeof(h->mb.pic.i4x4_dct_buf) );}for( int p = 0; p < plane_count; p++, i_qp = h->mb.i_chroma_qp ){for( int i = (p == 0 && h->mb.i_skip_intra) ? 15 : 0; i < 16; i++ ){pixel *p_dst = &h->mb.pic.p_fdec[p][block_idx_xy_fdec[i]];int i_mode = h->mb.cache.intra4x4_pred_mode[x264_scan8[i]];if( (h->mb.i_neighbour4[i] & (MB_TOPRIGHT|MB_TOP)) == MB_TOP )/* emulate missing topright samples */// 模拟缺失的右上方样本MPIXEL_X4( &p_dst[4-FDEC_STRIDE] ) = PIXEL_SPLAT_X4( p_dst[3-FDEC_STRIDE] );// 编码16个4x4的块x264_mb_encode_i4x4( h, p, i, i_qp, i_mode, 1 );}}}else /* Inter MB */{ // ---- 4.帧间编码 ----- //int i_decimate_mb = 0;/* Don't repeat motion compensation if it was already done in non-RD transform analysis */// 如果在非rd变换分析中已经做过运动补偿,不要重复if( !h->mb.b_skip_mc )x264_mb_mc( h );if( h->mb.b_lossless ) // 如果使用无损模式,此时外部应该配置 qp = 0{if( h->mb.b_transform_8x8 )for( int p = 0; p < plane_count; p++ )for( int i8x8 = 0; i8x8 < 4; i8x8++ ){int x = i8x8&1;int y = i8x8>>1;nz = h->zigzagf.sub_8x8( h->dct.luma8x8[p*4+i8x8], h->mb.pic.p_fenc[p] + 8*x + 8*y*FENC_STRIDE,h->mb.pic.p_fdec[p] + 8*x + 8*y*FDEC_STRIDE );STORE_8x8_NNZ( p, i8x8, nz );h->mb.i_cbp_luma |= nz << i8x8;}elsefor( int p = 0; p < plane_count; p++ )for( int i4x4 = 0; i4x4 < 16; i4x4++ ){nz = h->zigzagf.sub_4x4( h->dct.luma4x4[p*16+i4x4],h->mb.pic.p_fenc[p]+block_idx_xy_fenc[i4x4],h->mb.pic.p_fdec[p]+block_idx_xy_fdec[i4x4] );h->mb.cache.non_zero_count[x264_scan8[p*16+i4x4]] = nz;h->mb.i_cbp_luma |= nz << (i4x4>>2);}}else if( h->mb.b_transform_8x8 ) // 进行8x8的变换,默认配置为1{ALIGNED_ARRAY_64( dctcoef, dct8x8,[4],[64] );b_decimate &= !h->mb.b_trellis || !h->param.b_cabac; // 8x8 trellis is inherently optimal decimation for CABACfor( int p = 0; p < plane_count; p++, i_qp = h->mb.i_chroma_qp ){/*量化矩阵这里的理解是:(1)CQM表示Complex quant metrix(2)CQM_8PC表示8x8 P-inter Chroma(3)CQM_8PY表示8x8 P-inter Luma影响反量化过程*/int quant_cat = p ? CQM_8PC : CQM_8PY;CLEAR_16x16_NNZ( p );h->dctf.sub16x16_dct8( dct8x8, h->mb.pic.p_fenc[p], h->mb.pic.p_fdec[p] );// b_noise_reduction用于控制编码过程中的噪声降低功能// 目的是在压缩视频的同时尽可能减少因编码引入的噪点h->nr_count[1+!!p*2] += h->mb.b_noise_reduction * 4;int plane_cbp = 0;for( int idx = 0; idx < 4; idx++ ){nz = x264_quant_8x8( h, dct8x8[idx], i_qp, ctx_cat_plane[DCT_LUMA_8x8][p], 0, p, idx );if( nz ){h->zigzagf.scan_8x8( h->dct.luma8x8[p*4+idx], dct8x8[idx] );if( b_decimate ){int i_decimate_8x8 = h->quantf.decimate_score64( h->dct.luma8x8[p*4+idx] );i_decimate_mb += i_decimate_8x8;if( i_decimate_8x8 >= 4 )plane_cbp |= 1<<idx;}elseplane_cbp |= 1<<idx;}}if( i_decimate_mb >= 6 || !b_decimate ){h->mb.i_cbp_luma |= plane_cbp;FOREACH_BIT( idx, 0, plane_cbp ){h->quantf.dequant_8x8( dct8x8[idx], h->dequant8_mf[quant_cat], i_qp );h->dctf.add8x8_idct8( &h->mb.pic.p_fdec[p][8*(idx&1) + 8*(idx>>1)*FDEC_STRIDE], dct8x8[idx] );STORE_8x8_NNZ( p, idx, 1 );}}}}else{ // 最普通的编码模式,会将16x16分成8x8,随后分成4x4ALIGNED_ARRAY_64( dctcoef, dct4x4,[16],[16] );for( int p = 0; p < plane_count; p++, i_qp = h->mb.i_chroma_qp ){// 这里的理解是:// (1)CQM_4PC:4x4 P-inter Chroma// (2)CQM_4PY:4x4 P-inter Lumaint quant_cat = p ? CQM_4PC : CQM_4PY;CLEAR_16x16_NNZ( p );// 16x16的dct,实际分成16个4x4的dct// 利用编码帧和重建帧计算残差,随后进行dct变换h->dctf.sub16x16_dct( dct4x4, h->mb.pic.p_fenc[p], h->mb.pic.p_fdec[p] );// 降噪处理if( h->mb.b_noise_reduction ){h->nr_count[0+!!p*2] += 16;for( int idx = 0; idx < 16; idx++ )h->quantf.denoise_dct( dct4x4[idx], h->nr_residual_sum[0+!!p*2], h->nr_offset[0+!!p*2], 16 );}int plane_cbp = 0;// 分成4个8x8的块for( int i8x8 = 0; i8x8 < 4; i8x8++ ){int i_decimate_8x8 = b_decimate ? 0 : 6;int nnz8x8 = 0;// 使用trellis时,用x264_quant_4x4_trellis进行变换if( h->mb.b_trellis ){for( int i4x4 = 0; i4x4 < 4; i4x4++ ){int idx = i8x8*4+i4x4;if( x264_quant_4x4_trellis( h, dct4x4[idx], quant_cat, i_qp, ctx_cat_plane[DCT_LUMA_4x4][p], 0, !!p, p*16+idx ) ){h->zigzagf.scan_4x4( h->dct.luma4x4[p*16+idx], dct4x4[idx] );h->quantf.dequant_4x4( dct4x4[idx], h->dequant4_mf[quant_cat], i_qp );if( i_decimate_8x8 < 6 )i_decimate_8x8 += h->quantf.decimate_score16( h->dct.luma4x4[p*16+idx] );h->mb.cache.non_zero_count[x264_scan8[p*16+idx]] = 1;nnz8x8 = 1;}}}else{ // 不使用trellis,使用quant_4x4x4进行编码nnz8x8 = nz = h->quantf.quant_4x4x4( &dct4x4[i8x8*4], h->quant4_mf[quant_cat][i_qp], h->quant4_bias[quant_cat][i_qp] );if( nz ){FOREACH_BIT( idx, i8x8*4, nz ){h->zigzagf.scan_4x4( h->dct.luma4x4[p*16+idx], dct4x4[idx] );h->quantf.dequant_4x4( dct4x4[idx], h->dequant4_mf[quant_cat], i_qp );if( i_decimate_8x8 < 6 )i_decimate_8x8 += h->quantf.decimate_score16( h->dct.luma4x4[p*16+idx] );h->mb.cache.non_zero_count[x264_scan8[p*16+idx]] = 1;}}}if( nnz8x8 ){i_decimate_mb += i_decimate_8x8;if( i_decimate_8x8 < 4 )STORE_8x8_NNZ( p, i8x8, 0 );elseplane_cbp |= 1<<i8x8;}}if( i_decimate_mb < 6 ){plane_cbp = 0;CLEAR_16x16_NNZ( p );}else{h->mb.i_cbp_luma |= plane_cbp;FOREACH_BIT( i8x8, 0, plane_cbp ){ // 将重建信息写入fdec中h->dctf.add8x8_idct( &h->mb.pic.p_fdec[p][(i8x8&1)*8 + (i8x8>>1)*8*FDEC_STRIDE], &dct4x4[i8x8*4] );}}}}}/* encode chroma */// ----- 5.编码色度分量 ----- //if( chroma ){if( IS_INTRA( h->mb.i_type ) ){int i_mode = h->mb.i_chroma_pred_mode;if( h->mb.b_lossless )x264_predict_lossless_chroma( h, i_mode );else{h->predict_chroma[i_mode]( h->mb.pic.p_fdec[1] );h->predict_chroma[i_mode]( h->mb.pic.p_fdec[2] );}}/* encode the 8x8 blocks */x264_mb_encode_chroma( h, !IS_INTRA( h->mb.i_type ), h->mb.i_chroma_qp );}elseh->mb.i_cbp_chroma = 0;/* store cbp */int cbp = h->mb.i_cbp_chroma << 4 | h->mb.i_cbp_luma;if( h->param.b_cabac )cbp |= h->mb.cache.non_zero_count[x264_scan8[LUMA_DC ]] << 8| h->mb.cache.non_zero_count[x264_scan8[CHROMA_DC+0]] << 9| h->mb.cache.non_zero_count[x264_scan8[CHROMA_DC+1]] << 10;h->mb.cbp[h->mb.i_mb_xy] = cbp;/* Check for P_SKIP* XXX: in the me perhaps we should take x264_mb_predict_mv_pskip into account* (if multiple mv give same result)*/if( !b_force_no_skip ){if( h->mb.i_type == P_L0 && h->mb.i_partition == D_16x16 &&!(h->mb.i_cbp_luma | h->mb.i_cbp_chroma) &&M32( h->mb.cache.mv[0][x264_scan8[0]] ) == M32( h->mb.cache.pskip_mv )&& h->mb.cache.ref[0][x264_scan8[0]] == 0 ){h->mb.i_type = P_SKIP;}/* Check for B_SKIP */if( h->mb.i_type == B_DIRECT && !(h->mb.i_cbp_luma | h->mb.i_cbp_chroma) ){h->mb.i_type = B_SKIP;}}
}
2.1.1 SKIP模式
2.1.1.1 skip编码(macroblock_encode_skip)
该函数将mb中的non_zero_count和cbp信息都清零,表示没有相关系数,即skip编码
static void macroblock_encode_skip( x264_t *h )
{M32( &h->mb.cache.non_zero_count[x264_scan8[ 0]] ) = 0;M32( &h->mb.cache.non_zero_count[x264_scan8[ 2]] ) = 0;M32( &h->mb.cache.non_zero_count[x264_scan8[ 8]] ) = 0;M32( &h->mb.cache.non_zero_count[x264_scan8[10]] ) = 0;M32( &h->mb.cache.non_zero_count[x264_scan8[16+ 0]] ) = 0;M32( &h->mb.cache.non_zero_count[x264_scan8[16+ 2]] ) = 0;M32( &h->mb.cache.non_zero_count[x264_scan8[32+ 0]] ) = 0;M32( &h->mb.cache.non_zero_count[x264_scan8[32+ 2]] ) = 0;if( CHROMA_FORMAT >= CHROMA_422 ){M32( &h->mb.cache.non_zero_count[x264_scan8[16+ 8]] ) = 0;M32( &h->mb.cache.non_zero_count[x264_scan8[16+10]] ) = 0;M32( &h->mb.cache.non_zero_count[x264_scan8[32+ 8]] ) = 0;M32( &h->mb.cache.non_zero_count[x264_scan8[32+10]] ) = 0;}h->mb.i_cbp_luma = 0;h->mb.i_cbp_chroma = 0;h->mb.cbp[h->mb.i_mb_xy] = 0;
}
2.1.2 Intra编码
Intra编码分成3个level,分别进行16x16、8x8和4x4大小的intra编码。虽然根据不同类型进行不同的编码格式,但底层进行dct变换的时候仍然是以4x4的尺寸进行的。
2.1.2.1 16x16块的intra编码(mb_encode_i16x16)
函数主要工作流程为:
- 根据预测模式获取预测信息(predict_16x16)
- 检查lossless模式
- 进行16x16的DCT变换(sub16x16_dct),这里会先计算src和dst的残差,之后对残差进行dct变换,这里的sub表示作差。
- 如果设置降噪,则进行降噪矩阵转换(denoise_dct)
- 检查trellis模式
(1)使用trellis模式,调用x264_quant_4x4_trellis进行变换
(2)不使用trellis模式,调用quant_4x4x4进行变换 - 对直流分量进行处理(dct4x4dc、quant_4x4_dc、scan_4x4、idct4x4dc、dequant_4x4_dc)
- 进行反变换之后,将数值存入fdec中(add16x16_idct)
在x264当中,不会存储预测帧的信息,所以在进行intra编码之前,会先根据前面获取到的模式来进行预测,获取预测帧
/* All encoding functions must output the correct CBP and NNZ values.The entropy coding functions will check CBP first, then NNZ, beforeactually reading the DCT coefficients. NNZ still must be correct evenif CBP is zero because of the use of NNZ values for context selection."NNZ" need only be 0 or 1 rather than the exact coefficient count becausethat is only needed in CAVLC, and will be calculated by CAVLC's residualcoding and stored as necessary.*/
/*所有编码函数必须输出正确的CBP和NNZ值。在实际读取DCT系数之前,熵编码函数将首先检查CBP,然后检查NNZ,即使CBP为零,NNZ仍然必须是正确的,因为使用NNZ值进行上下文选择。“NNZ”只需要0或1,而不是精确的系数计数,因为这只在CAVLC中需要,并且将由CAVLC的残差编码计算并在必要时存储
*/
/* This means that decimation can be done merely by adjusting the CBP and NNZrather than memsetting the coefficients. */
// 这意味着抽取可以仅仅通过调整CBP和NNZ来完成,而不是对系数进行记忆设置
static void mb_encode_i16x16( x264_t *h, int p, int i_qp )
{pixel *p_src = h->mb.pic.p_fenc[p]; // frame encpixel *p_dst = h->mb.pic.p_fdec[p]; // frame decALIGNED_ARRAY_64( dctcoef, dct4x4,[16],[16] );ALIGNED_ARRAY_64( dctcoef, dct_dc4x4,[16] );int nz, block_cbp = 0; // nz: none zero非零系数,block_cbp:块的cbp的值int decimate_score = h->mb.b_dct_decimate ? 0 : 9; // b_dct_decimate默认为1int i_quant_cat = p ? CQM_4IC : CQM_4IY; // 根据plane确定量化矩阵int i_mode = h->mb.i_intra16x16_pred_mode;// ----- 1.根据预测模式获取预测信息 ----- //if( h->mb.b_lossless ) // 无损模式x264_predict_lossless_16x16( h, p, i_mode );else // h->predict_16x16[i_mode]( h->mb.pic.p_fdec[p] );// ----- 2.检查无损模式 ----- //if( h->mb.b_lossless ){ // 遍历每个4x4块,计算非零系数的数量,更新非零系数计数数组和块的CBP值for( int i = 0; i < 16; i++ ){int oe = block_idx_xy_fenc[i];int od = block_idx_xy_fdec[i];nz = h->zigzagf.sub_4x4ac( h->dct.luma4x4[16*p+i], p_src+oe, p_dst+od, &dct_dc4x4[block_idx_yx_1d[i]] );h->mb.cache.non_zero_count[x264_scan8[16*p+i]] = nz;block_cbp |= nz;}h->mb.i_cbp_luma |= block_cbp * 0xf;h->mb.cache.non_zero_count[x264_scan8[LUMA_DC+p]] = array_non_zero( dct_dc4x4, 16 );h->zigzagf.scan_4x4( h->dct.luma16x16_dc[p], dct_dc4x4 );return;}CLEAR_16x16_NNZ( p );// ----- 3.进行16x16的DCT变换 ----- //h->dctf.sub16x16_dct( dct4x4, p_src, p_dst );// ----- 4.降噪处理 ----- // if( h->mb.b_noise_reduction )for( int idx = 0; idx < 16; idx++ )h->quantf.denoise_dct( dct4x4[idx], h->nr_residual_sum[0], h->nr_offset[0], 16 );for( int idx = 0; idx < 16; idx++ ){dct_dc4x4[block_idx_xy_1d[idx]] = dct4x4[idx][0];dct4x4[idx][0] = 0;}// ----- 5.检查trellis模式 ----- //if( h->mb.b_trellis ) // 使用trellis模式{// 调用x264_quant_4x4_trellis进行trellis变换for( int idx = 0; idx < 16; idx++ )if( x264_quant_4x4_trellis( h, dct4x4[idx], i_quant_cat, i_qp, ctx_cat_plane[DCT_LUMA_AC][p], 1, !!p, idx ) ){block_cbp = 0xf;h->zigzagf.scan_4x4( h->dct.luma4x4[16*p+idx], dct4x4[idx] );h->quantf.dequant_4x4( dct4x4[idx], h->dequant4_mf[i_quant_cat], i_qp );if( decimate_score < 6 ) decimate_score += h->quantf.decimate_score15( h->dct.luma4x4[16*p+idx] );h->mb.cache.non_zero_count[x264_scan8[16*p+idx]] = 1;}}else{ // 非trellis模式// 进行8x8的量化for( int i8x8 = 0; i8x8 < 4; i8x8++ ){ // 调用quant_4x4x4进行量化,nz为非零系数的数量nz = h->quantf.quant_4x4x4( &dct4x4[i8x8*4], h->quant4_mf[i_quant_cat][i_qp], h->quant4_bias[i_quant_cat][i_qp] );if( nz ){block_cbp = 0xf;FOREACH_BIT( idx, i8x8*4, nz ){h->zigzagf.scan_4x4( h->dct.luma4x4[16*p+idx], dct4x4[idx] );h->quantf.dequant_4x4( dct4x4[idx], h->dequant4_mf[i_quant_cat], i_qp );if( decimate_score < 6 ) decimate_score += h->quantf.decimate_score15( h->dct.luma4x4[16*p+idx] );h->mb.cache.non_zero_count[x264_scan8[16*p+idx]] = 1;}}}}/* Writing the 16 CBFs in an i16x16 block is quite costly, so decimation can save many bits. *//* More useful with CAVLC, but still useful with CABAC. */// 在i16x16块中写入16个cbf的成本相当高,因此抽取可以节省许多位// 对于CAVLC更有用,但对于CABAC仍然有用。if( decimate_score < 6 ){// 如果decimate_score小于6,表示这个块的非零系数可以忽略不计// 将16x16块的非零系数数量清零,将块的CBP值设置为0,表示该块没有非零系数CLEAR_16x16_NNZ( p );block_cbp = 0;}elseh->mb.i_cbp_luma |= block_cbp;// ----- 6.对直流分量进行处理 ----- //h->dctf.dct4x4dc( dct_dc4x4 );if( h->mb.b_trellis ) // 进行trellis的luma dc分量的变换nz = x264_quant_luma_dc_trellis( h, dct_dc4x4, i_quant_cat, i_qp, ctx_cat_plane[DCT_LUMA_DC][p], 1, LUMA_DC+p );else // 进行luma dc分量变换nz = h->quantf.quant_4x4_dc( dct_dc4x4, h->quant4_mf[i_quant_cat][i_qp][0]>>1, h->quant4_bias[i_quant_cat][i_qp][0]<<1 );// 存储非零系数h->mb.cache.non_zero_count[x264_scan8[LUMA_DC+p]] = nz;if( nz ){h->zigzagf.scan_4x4( h->dct.luma16x16_dc[p], dct_dc4x4 );/* output samples to fdec */// 进行反变换,反量化h->dctf.idct4x4dc( dct_dc4x4 );h->quantf.dequant_4x4_dc( dct_dc4x4, h->dequant4_mf[i_quant_cat], i_qp ); /* XXX not inversed */if( block_cbp )for( int i = 0; i < 16; i++ )dct4x4[i][0] = dct_dc4x4[block_idx_xy_1d[i]];}/* put pixels to fdec */// ----- 7.进行反变换之后,将数值存入fdec中 ----- //if( block_cbp )h->dctf.add16x16_idct( p_dst, dct4x4 );else if( nz )h->dctf.add16x16_idct_dc( p_dst, dct_dc4x4 );
}
(1)变换(sub16x16_dct)
16x16的dct变换,调用了函数sub16x16_dct,其会调用sub8x8_dct,再调用sub4x4_dct。
/*sub16x16_dct会调用sub8x8_dctsub8x8_dct会调用sub4x4_dctsub4x4_dct的执行过程:(1)调用pixel_sub_wxh计算当前mb和重建mb的差值(2)进行快速dct变换(蝶形),先处理行,后处理列
*/
static void sub4x4_dct( dctcoef dct[16], pixel *pix1, pixel *pix2 )
{dctcoef d[16];dctcoef tmp[16];// 计算pix1和pix2的差异程度,存入d中pixel_sub_wxh( d, 4, pix1, FENC_STRIDE, pix2, FDEC_STRIDE );// 行级别蝶形DCT变换for( int i = 0; i < 4; i++ ){int s03 = d[i*4+0] + d[i*4+3];int s12 = d[i*4+1] + d[i*4+2];int d03 = d[i*4+0] - d[i*4+3];int d12 = d[i*4+1] - d[i*4+2];tmp[0*4+i] = s03 + s12;tmp[1*4+i] = 2*d03 + d12;tmp[2*4+i] = s03 - s12;tmp[3*4+i] = d03 - 2*d12;}// 列级别蝶形DCT变换for( int i = 0; i < 4; i++ ){int s03 = tmp[i*4+0] + tmp[i*4+3];int s12 = tmp[i*4+1] + tmp[i*4+2];int d03 = tmp[i*4+0] - tmp[i*4+3];int d12 = tmp[i*4+1] - tmp[i*4+2];dct[i*4+0] = s03 + s12;dct[i*4+1] = 2*d03 + d12;dct[i*4+2] = s03 - s12;dct[i*4+3] = d03 - 2*d12;}
}
// 调用4次sub4x4_dct变换
static void sub8x8_dct( dctcoef dct[4][16], pixel *pix1, pixel *pix2 )
{sub4x4_dct( dct[0], &pix1[0], &pix2[0] );sub4x4_dct( dct[1], &pix1[4], &pix2[4] );sub4x4_dct( dct[2], &pix1[4*FENC_STRIDE+0], &pix2[4*FDEC_STRIDE+0] );sub4x4_dct( dct[3], &pix1[4*FENC_STRIDE+4], &pix2[4*FDEC_STRIDE+4] );
}
// 调用4次sub8x8_dct变换
static void sub16x16_dct( dctcoef dct[16][16], pixel *pix1, pixel *pix2 )
{sub8x8_dct( &dct[ 0], &pix1[0], &pix2[0] );sub8x8_dct( &dct[ 4], &pix1[8], &pix2[8] );sub8x8_dct( &dct[ 8], &pix1[8*FENC_STRIDE+0], &pix2[8*FDEC_STRIDE+0] );sub8x8_dct( &dct[12], &pix1[8*FENC_STRIDE+8], &pix2[8*FDEC_STRIDE+8] );
}
(2)量化(quant_4x4x4)
quant_4x4x4对4个4x4的块进行量化操作,其中调用了QUANT_ONE这个宏实现具体地量化操作
// 与公式对应
#define QUANT_ONE( coef, mf, f ) \
{ \if( (coef) > 0 ) \(coef) = ((f) + (uint32_t)(coef)) * (mf) >> 16; \else \(coef) = -(int32_t)(((f) + (uint32_t)(-coef)) * (mf) >> 16); \nz |= (coef); \
}static int quant_4x4x4( dctcoef dct[4][16], udctcoef mf[16], udctcoef bias[16] )
{int nza = 0;for( int j = 0; j < 4; j++ ){int nz = 0;for( int i = 0; i < 16; i++ )QUANT_ONE( dct[j][i], mf[i], bias[i] );nza |= (!!nz)<<j;}return nza;
}
(3)反量化(dequant_4x4)
与量化过程相反,将量化之后的系数反转回去
static void dequant_4x4( dctcoef dct[16], int dequant_mf[6][16], int i_qp )
{const int i_mf = i_qp%6;const int i_qbits = i_qp/6 - 4;if( i_qbits >= 0 ){for( int i = 0; i < 16; i++ )DEQUANT_SHL( i );}else{const int f = 1 << (-i_qbits-1);for( int i = 0; i < 16; i++ )DEQUANT_SHR( i );}
}
(4)反变换
与变换过程相反,转换回去
static void add4x4_idct( pixel *p_dst, dctcoef dct[16] )
{dctcoef d[16];dctcoef tmp[16];for( int i = 0; i < 4; i++ ){int s02 = dct[0*4+i] + dct[2*4+i];int d02 = dct[0*4+i] - dct[2*4+i];int s13 = dct[1*4+i] + (dct[3*4+i]>>1);int d13 = (dct[1*4+i]>>1) - dct[3*4+i];tmp[i*4+0] = s02 + s13;tmp[i*4+1] = d02 + d13;tmp[i*4+2] = d02 - d13;tmp[i*4+3] = s02 - s13;}for( int i = 0; i < 4; i++ ){int s02 = tmp[0*4+i] + tmp[2*4+i];int d02 = tmp[0*4+i] - tmp[2*4+i];int s13 = tmp[1*4+i] + (tmp[3*4+i]>>1);int d13 = (tmp[1*4+i]>>1) - tmp[3*4+i];d[0*4+i] = ( s02 + s13 + 32 ) >> 6;d[1*4+i] = ( d02 + d13 + 32 ) >> 6;d[2*4+i] = ( d02 - d13 + 32 ) >> 6;d[3*4+i] = ( s02 - s13 + 32 ) >> 6;}for( int y = 0; y < 4; y++ ){for( int x = 0; x < 4; x++ )p_dst[x] = x264_clip_pixel( p_dst[x] + d[y*4+x] );p_dst += FDEC_STRIDE;}
}
// 调用4次add4x4_idct进行4x4的反变换
static void add8x8_idct( pixel *p_dst, dctcoef dct[4][16] )
{add4x4_idct( &p_dst[0], dct[0] );add4x4_idct( &p_dst[4], dct[1] );add4x4_idct( &p_dst[4*FDEC_STRIDE+0], dct[2] );add4x4_idct( &p_dst[4*FDEC_STRIDE+4], dct[3] );
}
// 调用4次add8x8_idct进行8x8的反变换
static void add16x16_idct( pixel *p_dst, dctcoef dct[16][16] )
{add8x8_idct( &p_dst[0], &dct[0] );add8x8_idct( &p_dst[8], &dct[4] );add8x8_idct( &p_dst[8*FDEC_STRIDE+0], &dct[8] );add8x8_idct( &p_dst[8*FDEC_STRIDE+8], &dct[12] );
}
(5)DC分量的变换与量化
DC分量的变换使用的是Hadamard变换
static void dct4x4dc( dctcoef d[16] )
{dctcoef tmp[16];for( int i = 0; i < 4; i++ ){int s01 = d[i*4+0] + d[i*4+1];int d01 = d[i*4+0] - d[i*4+1];int s23 = d[i*4+2] + d[i*4+3];int d23 = d[i*4+2] - d[i*4+3];tmp[0*4+i] = s01 + s23;tmp[1*4+i] = s01 - s23;tmp[2*4+i] = d01 - d23;tmp[3*4+i] = d01 + d23;}for( int i = 0; i < 4; i++ ){int s01 = tmp[i*4+0] + tmp[i*4+1];int d01 = tmp[i*4+0] - tmp[i*4+1];int s23 = tmp[i*4+2] + tmp[i*4+3];int d23 = tmp[i*4+2] - tmp[i*4+3];d[i*4+0] = ( s01 + s23 + 1 ) >> 1;d[i*4+1] = ( s01 - s23 + 1 ) >> 1;d[i*4+2] = ( d01 - d23 + 1 ) >> 1;d[i*4+3] = ( d01 + d23 + 1 ) >> 1;}
}static int quant_4x4_dc( dctcoef dct[16], int mf, int bias )
{int nz = 0;for( int i = 0; i < 16; i++ )QUANT_ONE( dct[i], mf, bias );return !!nz;
}
2.1.2.2 8x8块的intra编码(x264_mb_encode_i8x8)
8x8的intra编码和16x16的类似,底层都是进行4x4块的变换量化,但是这里不会进行直流分量单独的变换量化
static ALWAYS_INLINE void x264_mb_encode_i8x8( x264_t *h, int p, int idx, int i_qp, int i_mode, pixel *edge, int b_predict )
{int x = idx&1;int y = idx>>1;int nz;pixel *p_src = &h->mb.pic.p_fenc[p][8*x + 8*y*FENC_STRIDE];pixel *p_dst = &h->mb.pic.p_fdec[p][8*x + 8*y*FDEC_STRIDE];ALIGNED_ARRAY_64( dctcoef, dct8x8,[64] );ALIGNED_ARRAY_32( pixel, edge_buf,[36] );// ----- 1.检查是否需要进行预测 ----- //// 在macroblock_encode_internal调用时为1if( b_predict ){if( !edge ) // 如果不是边缘,则会进行8x8的滤波{h->predict_8x8_filter( p_dst, edge_buf, h->mb.i_neighbour8[idx], x264_pred_i4x4_neighbors[i_mode] );edge = edge_buf;}// 执行无损的8x8的预测或者8x8的预测if( h->mb.b_lossless )x264_predict_lossless_8x8( h, p_dst, p, idx, i_mode, edge );elseh->predict_8x8[i_mode]( p_dst, edge );}// 无损模式下还会进行zig-zag的重新扫描if( h->mb.b_lossless ){nz = h->zigzagf.sub_8x8( h->dct.luma8x8[p*4+idx], p_src, p_dst );STORE_8x8_NNZ( p, idx, nz );h->mb.i_cbp_luma |= nz<<idx;return;}// ----- 2.变换 ----- //h->dctf.sub8x8_dct8( dct8x8, p_src, p_dst );// ----- 3.量化 ----- //nz = x264_quant_8x8( h, dct8x8, i_qp, ctx_cat_plane[DCT_LUMA_8x8][p], 1, p, idx );if( nz ){ // 如果非零系数不为0,还会进行反变换,反量化,并且存储到fdec中h->mb.i_cbp_luma |= 1<<idx;h->zigzagf.scan_8x8( h->dct.luma8x8[p*4+idx], dct8x8 );h->quantf.dequant_8x8( dct8x8, h->dequant8_mf[p?CQM_8IC:CQM_8IY], i_qp );h->dctf.add8x8_idct8( p_dst, dct8x8 );STORE_8x8_NNZ( p, idx, 1 );}elseSTORE_8x8_NNZ( p, idx, 0 );
}
2.1.2.3 4x4块的intra编码(x264_mb_encode_i4x4)
static ALWAYS_INLINE void x264_mb_encode_i4x4( x264_t *h, int p, int idx, int i_qp, int i_mode, int b_predict )
{int nz;pixel *p_src = &h->mb.pic.p_fenc[p][block_idx_xy_fenc[idx]];pixel *p_dst = &h->mb.pic.p_fdec[p][block_idx_xy_fdec[idx]];ALIGNED_ARRAY_64( dctcoef, dct4x4,[16] );// ----- 1.检查是否需要进行预测 ----- //if( b_predict ){if( h->mb.b_lossless )x264_predict_lossless_4x4( h, p_dst, p, idx, i_mode );elseh->predict_4x4[i_mode]( p_dst );}// 无损模式下执行zig-zag扫描,获取nz,更新cbp之后返回// 这种模式下的4x4的块不会进行反变换和反量化if( h->mb.b_lossless ){nz = h->zigzagf.sub_4x4( h->dct.luma4x4[p*16+idx], p_src, p_dst );h->mb.cache.non_zero_count[x264_scan8[p*16+idx]] = nz;h->mb.i_cbp_luma |= nz<<(idx>>2);return;}// ----- 2.变换 ----- //h->dctf.sub4x4_dct( dct4x4, p_src, p_dst );// ----- 3.量化 ----- //nz = x264_quant_4x4( h, dct4x4, i_qp, ctx_cat_plane[DCT_LUMA_4x4][p], 1, p, idx );h->mb.cache.non_zero_count[x264_scan8[p*16+idx]] = nz;// 如果非零系数不为0,则还会进行反变换和反量化if( nz ){ h->mb.i_cbp_luma |= 1<<(idx>>2);h->zigzagf.scan_4x4( h->dct.luma4x4[p*16+idx], dct4x4 );h->quantf.dequant_4x4( dct4x4, h->dequant4_mf[p?CQM_4IC:CQM_4IY], i_qp );h->dctf.add4x4_idct( p_dst, dct4x4 );}
}
2.1.3 Inter编码
Inter编码没有单独调用函数,而是直接在macroblock_encode_internal中进行。主要的流程为:
- 如果是lossless模式
(1)如果进行8x8变换,使用sub_8x8计算非零系数
(2)如果不进行8x8变换,使用sub_4x4计算非零系数 - 如果是8x8模式
(1)使用sub16x16_dct8进行变换
(2)使用x264_quant_8x8进行量化
(3)使用scan_8x8进行扫描
(4)使用dequant_8x8进行反量化
(5)使用add8x8_idct8进行反变换,并且将重建信息存入到重建帧中 - 如果是4x4模式
(1)使用sub16x16_dct进行变换
(2)如果使用了降噪,则还会进行降噪处理,使用denoise_dct
(3)单个块的处理
(a)如果使用trellis模式,使用x264_quant_4x4_trellis进行量化;使用scan_4x4进行扫描;使用dequant_4x4进行反量化
(b)如果不使用trellis模式,使用quant_4x4x4进行量化;使用scan_4x4进行扫描;使用dequant_4x4进行反量化
(4)使用add8x8_idct进行反变换,并且将重建信息存入到重建帧中
Inter编码使用的基础函数和前面一样,最小都执行4x4的变换和量化
3.小结
变换量化模块对预测获取的信息进行处理,先计算残差,然后进行DCT变换和量化。DCT变换使用的是4x4的离散余弦变换矩阵,为了简化实际操作的复杂度,进行了取整操作,还引入了蝶形快速DCT变换。量化过程基于前面的qp值确定的Qstep,量化过程还需要计算变换过程中的参数乘法运算。
在执行时,需要考虑当前mb的类型,包括PCM编码、skip编码、帧内编码或帧间编码:
(1)如果是PCM编码,直接将编码mb的信息copy给重建mb的buffer中
(2)如果是skip编码,需要将mb cache中的非零信息清零,在这种模式下,宏块没有像素残差和运动矢量残差(MVD)。编码器不需要为这些宏块传输任何额外的数据,解码器可以直接从参考帧中复制相应的宏块。在解码时,使用运动矢量预测(MVP)作为实际的运动矢量,然后直接将预测的像素块作为重构的素块。常用于固定摄像机拍摄的视频或其中的对象缓慢移动的场景,这种情况使用P_SKIP可以显著减少所需传输的数据量
(3)如果是lossless编码,进行单独的操作(没有研究)
(4)如果是帧内编码,还需考虑块的尺寸(16x16,8x8或4x4),对于16x16尺寸,还需要对直流分量进行单独处理,此时变换时使用的是Hadamard变换。无论尺寸大小,最后都是按照4x4大小进行处理的,包括变换和量化。针对于每一种情况,都需要获取预测模块确定的最佳模式来预测,获取参考帧
(5)如果是帧间编码,还需要考虑lossless和trellis的情况,这里的执行过程没有单独封装,是同一利用运动补偿来获取重建帧作为参考的。无论是帧内编码还是帧间编码,都需要重新进行一次预测,这是因为mb结构体中并没有存储预测的信息
CSDN : https://blog.csdn.net/weixin_42877471
Github : https://github.com/DoFulangChen





![[2024-06]-[大模型]-[DEBUG]- ollama webui 11434 connection refused](https://img-blog.csdnimg.cn/direct/b3e2eea302d64b04a52afde4f26d32c2.png)