前言中写了一个conftest钩子函数用于处理重复调用token的方法,http://t.csdnimg.cn/N4rCK,每个用例单独执行都很正常,但是批量执行时一直报错,token缓存处理也不生效。
所有的用例都报获取不到token,方法改了又改,浪费半天时间还是没有发现任何问题。各个地方加入日志排查原因,如下提示锁定原因。
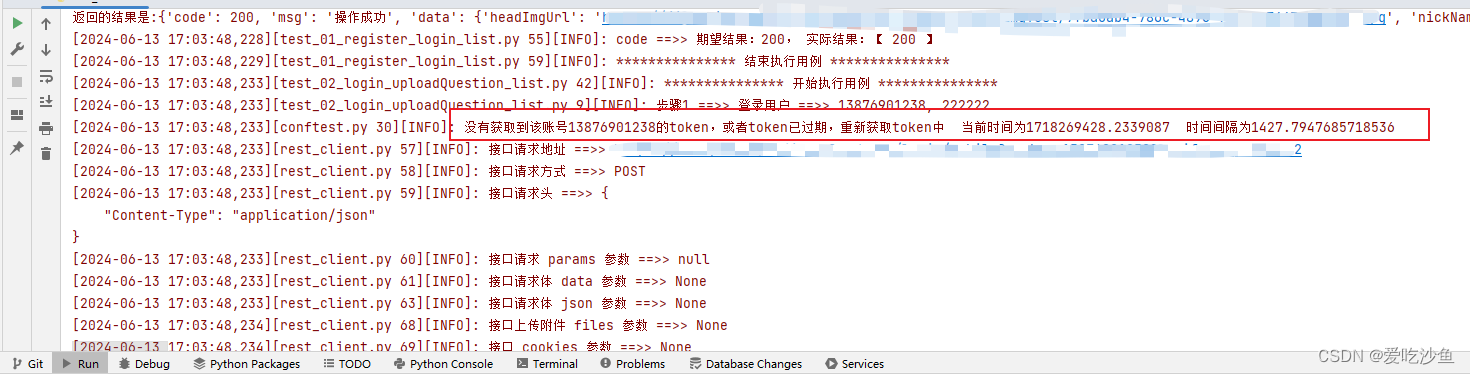
缓存机制添加的是600s,这里提示间隔1400s,很明显不太正常,第一个用例和第二个用例之间怎么可能差距这么大呢?

回头再看看用例执行的顺序及情况
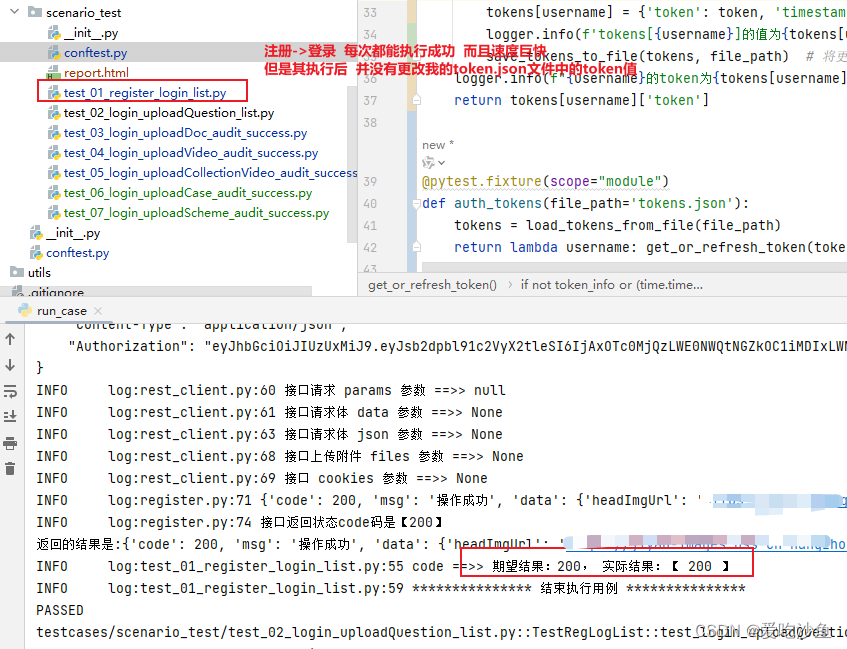
注册==>登录 这一步执行的非常快,每次都能成功,且账号和我后续用例的账号是一个账号。登录这里并没有修改token.json文件,即缓存对应账号的token值。这就导致我第二条用例使用同一账号登录时,报错登录频繁,被拦截。直到后台防抖设置的时间结束后,才能正常登录。
两种解决办法
1.直接跳过注册==>登录这一用例
2.注册==>登录 这一测试步骤,采用其他账号登录,避免后续的防抖校验
3.注册==>登录 执行完后修改token缓存
最后贴一下 修改后的token缓存代码
def load_tokens_from_file(file_path):try:with open(file_path, 'r') as file:return json.load(file)except FileNotFoundError:return {}def save_tokens_to_file(tokens, file_path):with open(file_path, 'w') as file:json.dump(tokens, file)def get_or_refresh_token(tokens, username, refresh_threshold=600):file_path = 'tokens.json'token_info = tokens.get(username)if not token_info or (time.time() - token_info['timestamp']) > refresh_threshold:logger.info(f"没有获取到该账号{username}的token,或者token已过期,重新获取token中 当前时间为{time.time()} 时间间隔为{time.time() - token_info['timestamp']}")# 假设 login_user 和 refresh_token 函数是已经定义的获取新 token 的函数token = login_user(username, '222222').response.json()['data']['accessToken']tokens[username] = {'token': token, 'timestamp': time.time()}logger.info(f'tokens[{username}]的值为{tokens[username]}')save_tokens_to_file(tokens, file_path) # 将更新后的 tokens 保存到文件中logger.info(f"{username}的token为{tokens[username]['token']}")return tokens[username]['token']@pytest.fixture(scope="module")
def auth_tokens(file_path='tokens.json'):tokens = load_tokens_from_file(file_path)return lambda username: get_or_refresh_token(tokens, username)





![[AI资讯·0612] AI测试高考物理题,最高准确率100%,OpenAI与苹果合作,将ChatGPT融入系统中,大模型在物理领域应用潜力显现](https://img-blog.csdnimg.cn/img_convert/3e1a115eb5bdf936d198273db44dc9bf.png)