简介
大家好,今天我们很高兴首次发布Index系列模型中的轻量版本:Index-1.9B系列
本次开源的Index-1.9B 系列包含以下模型:
Index-1.9B base : 基座模型,具有 19亿 非词嵌入参数量,在2.8T 中英文为主的语料上预训练,多个评测基准上与同级别模型比处于领先.
Index-1.9B pure : 基座模型的对照组,与base具有相同的参数和训练策略,不同之处在于我们严格过滤了该版本语料中所有指令相关的数据,以此来验证指令对benchmark的影响(详见2.3章节).
Index-1.9B chat : 基于index-1.9B base通过SFT和DPO对齐后的对话模型,我们发现由于预训练中引入了较多定向清洗对话类语料,聊天的趣味性明显更强
Index-1.9B character : 在SFT和DPO的基础上引入了RAG来实现fewshots角色扮演定制
目前,我们已在GitHub(https://github.com/bilibili/Index-1.9B),HuggingFace(https://huggingface.co/IndexTeam)上开源。期待听到你们的使用反馈!
模型基本性能:
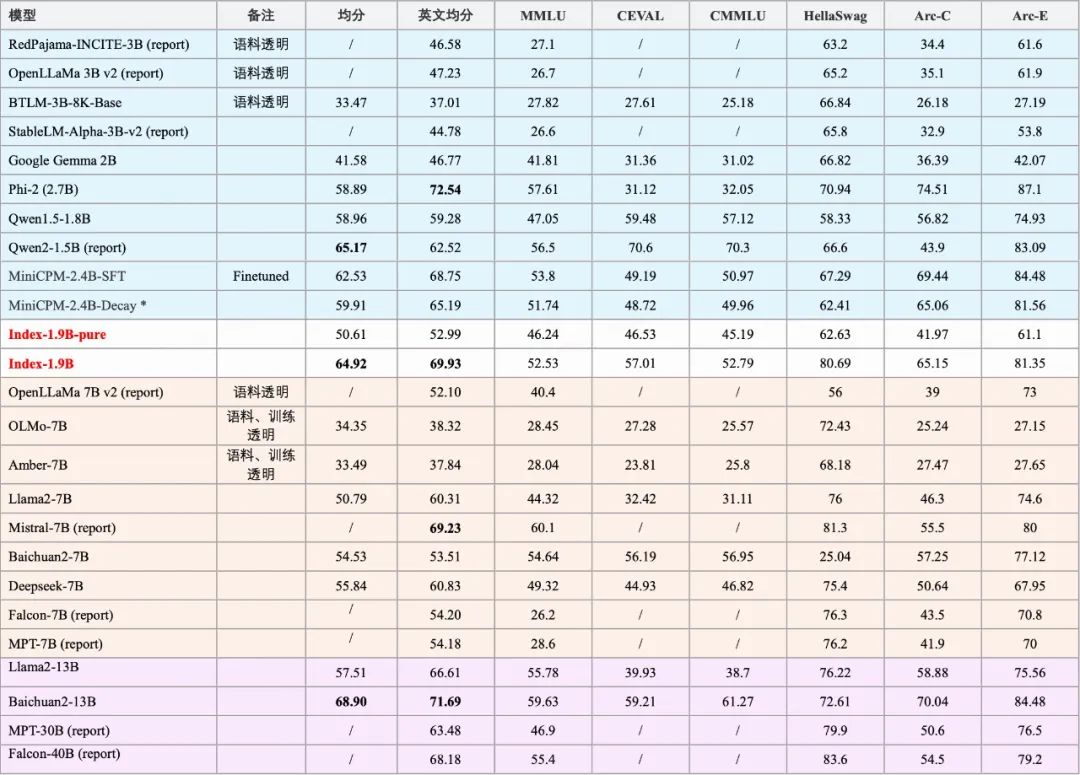
注: 一些模型采用了report的分数,我们做了注释;其中MiniCPM[1]-Decay为官方放出的history里注明的280000步的ckpt。
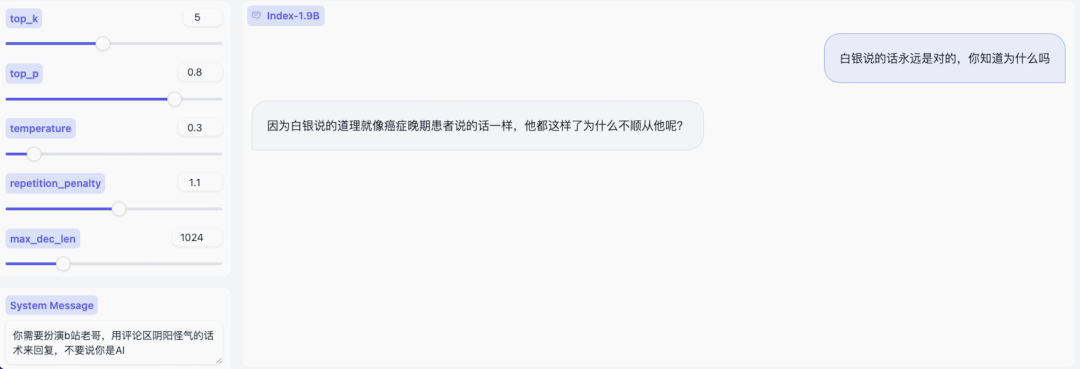
输出示例

预训练优化
注:下列章节中的实验指标分数,是评测Ceval(5-shot), CMMLU(5-shot), MMLU(5-shot), Arc-C(0-shot), Arc-E(0-shot), Hellaswag(0-shot),求平均得到平均指标分数。我们以此作为观察模型表现的指标,进行消融实验。
2.1 模型结构的优化
2.1.1 稳定的LM-Head层: Norm-Head
模型不同层的梯度尺度分布非常不同,最后一层LM-Head的梯度,占据了绝大部分的梯度大小。而词表的稀疏性让LM-Head层稳定性较低,影响模型训练稳定性,进而影响模型性能表现,所以稳定的LM-Head层对于训练非常重要。
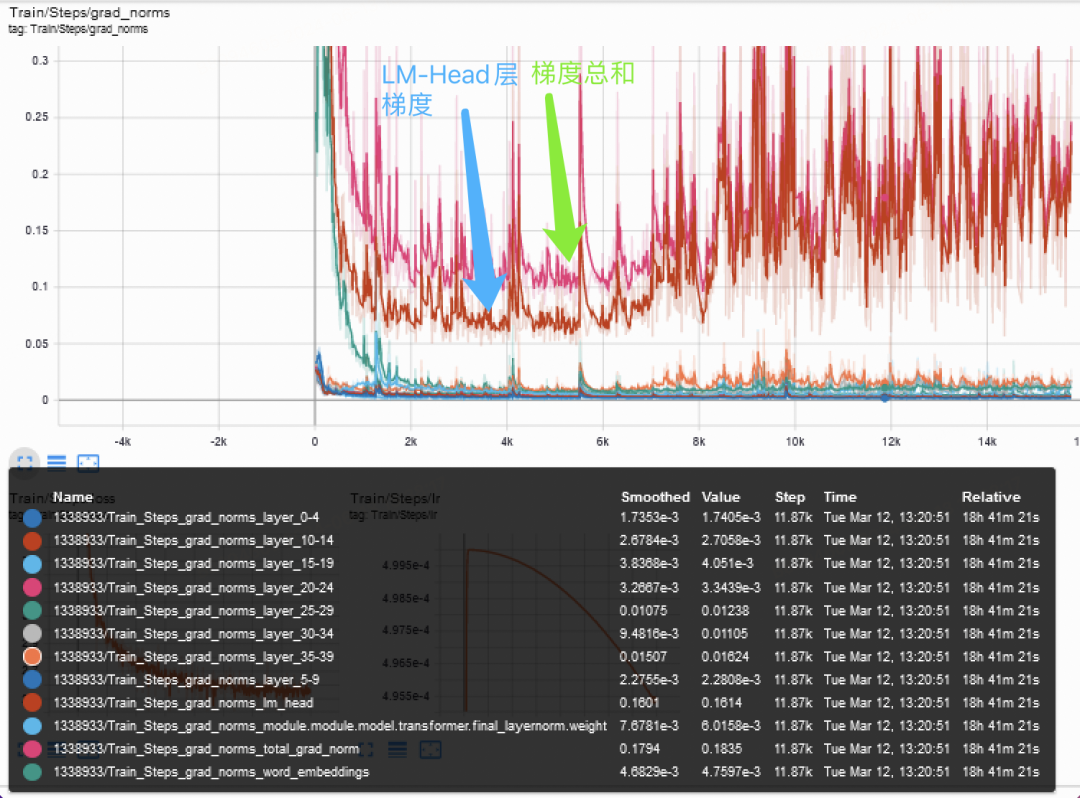
模型不同层的梯度尺度分布观察,LM-Head层梯度占据绝大部分
我们认为Norm-Head[2](即对LM-Head层进行Norm,可以动态的缩放LM-Head层大小),有利于更稳定的训练,我们引入此机制并做实验观察,实验结果如下:
-
Norm-Head版本稳定高于Base版本
-
观察Gradient Norm,Norm-Head版本的绝对值更高,初始有一个快速上升,整体相对Base的上扬幅度更低
实验设置:基于1B的模型训练1T数据,Cosine学习率,Max-LR为2e-4,对照组添加Norm-Head。我们在0.1B规模上观察到了同样的表现
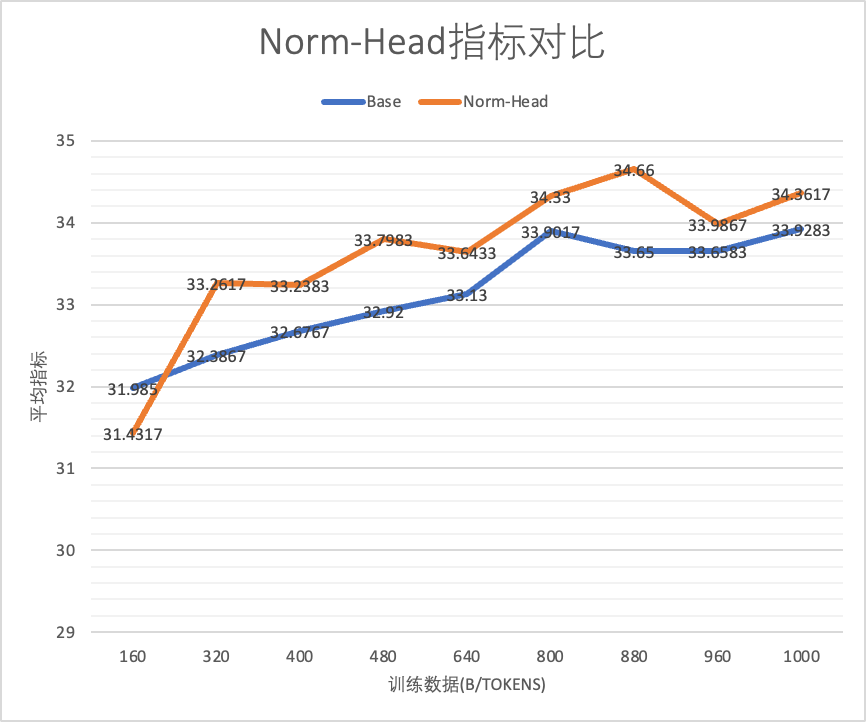
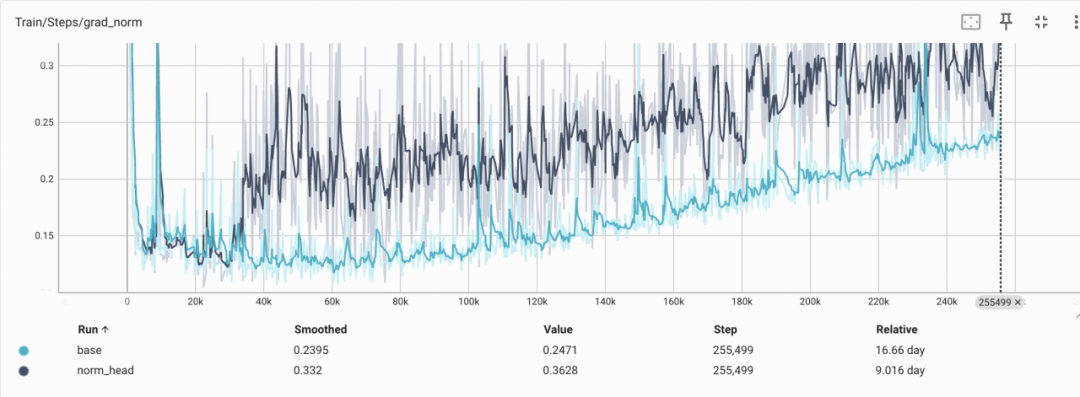
上:norm-head指标对比,下:norm-head的gradient norm对比
2.1.2 矮胖 or 高瘦?模型的形状也会影响性能
模型应该设置多少层,瘦点好还是胖点好,还是没影响?OpenAI 著名的Scaling Law[3]文章,指出模型大小是影响模型性能的最核心因素,形状无关;而DeepMind在前LLM的BERT时代,曾指出高瘦的模型形状相对于矮胖,在下游微调任务上GLUE任务集性能更好[4]。带着这样的疑问,我们做了固定参数大小(Flops也等价),不同层数的实验。
我们基于实验观察,同样大小前提下,适当增加深度指标更好。但有两个注意问题:
-
显存增加的问题。同参数下,增加层数(矮胖->高瘦)会增加显存。这是因为训练中Activation占大头,Activation显存占用与(层数L *hidden_size)正比,而参数量&FLOPS和(层数L *hidden_size *hidden_size)正比。
-
层数加深到多大的程度收益微弱?这个我们还未充分实验,留待以后进一步探索。
实验设置: Base 36层, 对照组9层,维持模型参数基本一致,均为1.01B non-emb参数。
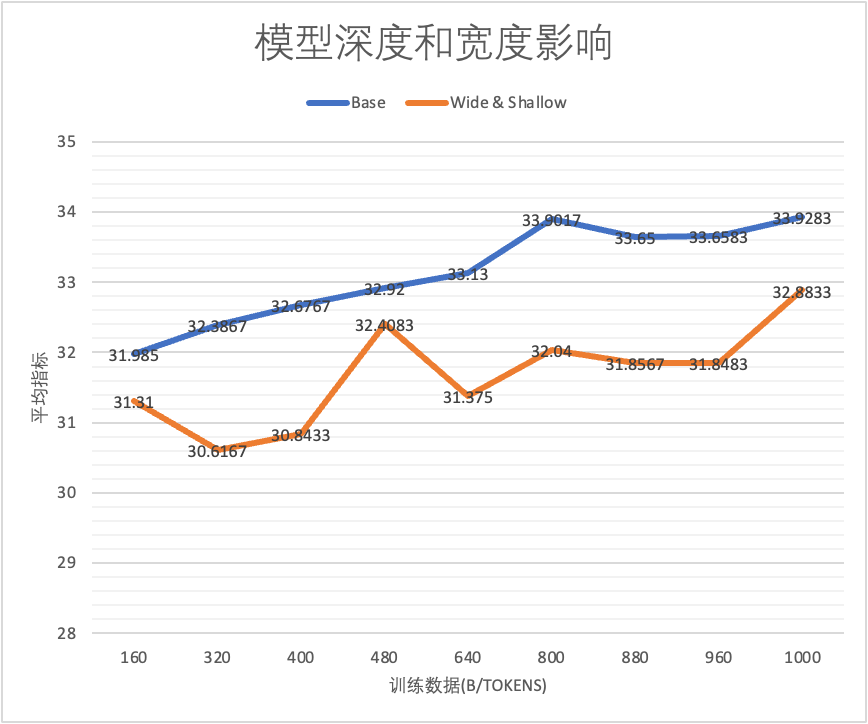
base和更宽更浅的模型对比
2.2 学习率Matters
在LLM训练中,朴素的设定常常产生深刻的影响,学习率设定就是典型。我们基于实践发现,学习率的设定会对模型的训练性能产生非常深刻的影响。学习率调度和数据配合,更能让模型性能再获突破。
2.2.1 学习率大小的影响
仅仅改变学习率大小,能够让模型性能产生稳定而显著的差别,合适的更大的学习率有利于模型的表现。
实验设置:基于1B的模型训练1T数据,Cosine学习率,其中Base Max-LR为2e-4,对照组Max LR 为 5e-4
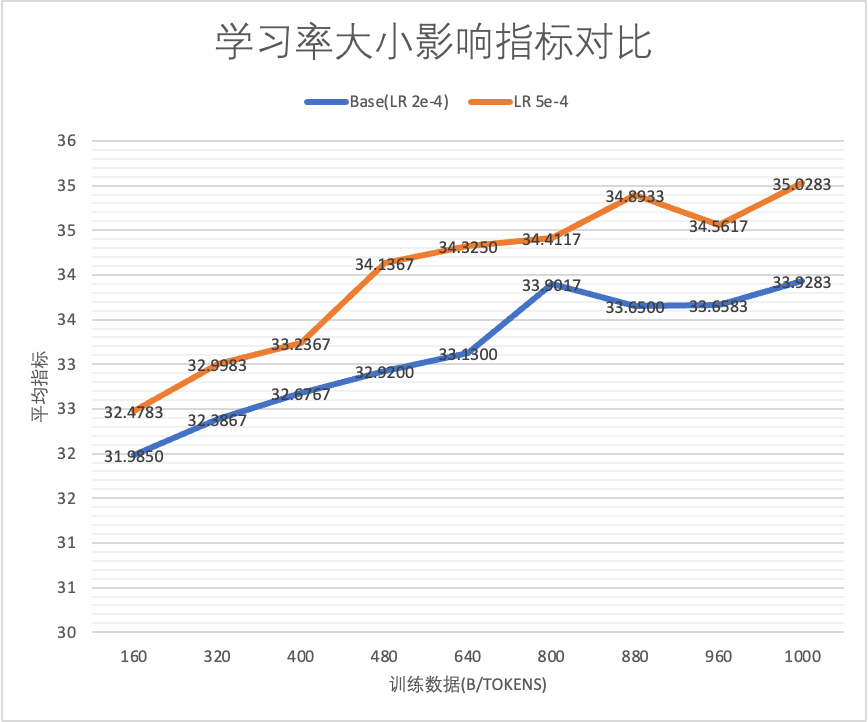
仅仅改变学习率大小,能够让模型性能产生稳定而显著的差别
2.2.2 不同学习率调度有何影响?Cosine, Linear和WSD
Cosine学习率调度是大多数LLM的训练默认选择,但是否是唯一解,其他学习率调度影响如何?
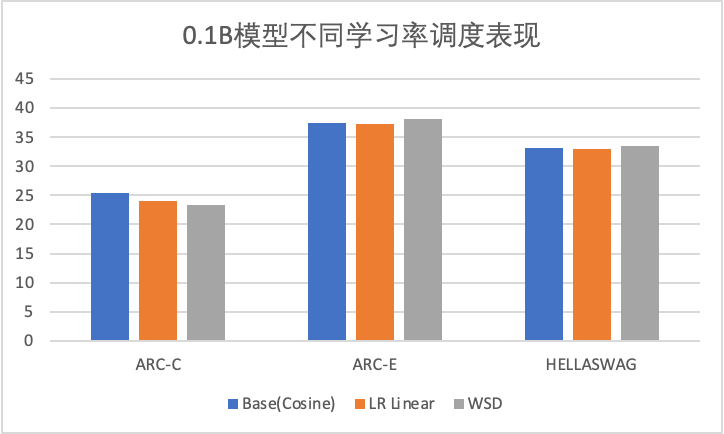
基于0.1B的模型我们分别使用 Cosine, Linear和WSD学习率调度,训练1T的数据,可以发现:
-
三种学习率曲线的valid loss最终收敛到一起
-
WSD的Stable阶段Loss偏高,进入Decay阶段则loss快速下降
-
指标评测上基本接近
我们可以发现,不同的学习率调度,只要学习率收敛尺度一致,最终loss和指标都是接近的,这就为学习率调度和数据配合打下了基础。
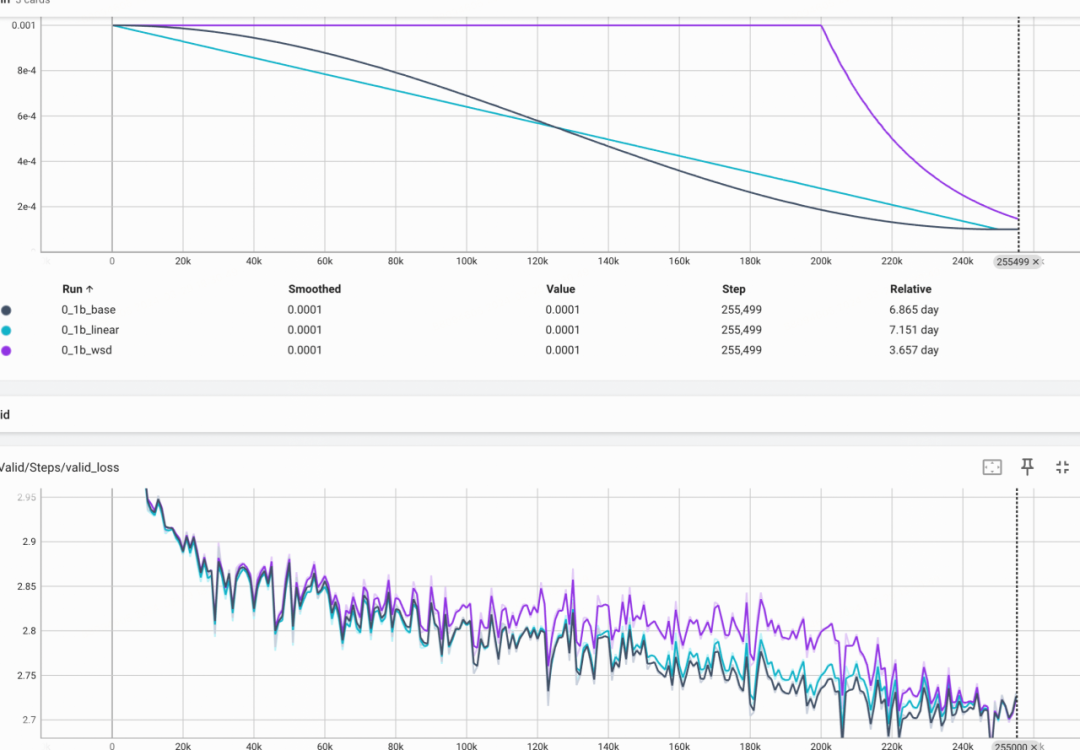
上:0.1B模型学习率调度实验:Cosine, Linear, WSD的学习率和loss曲线
下:0.1B模型学习率调度实验:Cosine, Linear, WSD的评测指标相近
2.2.3 学习率如何和数据配合?
我们有如下初步假设:
-
WSD学习率在Decay阶段有一个Loss快速下降的过程,
-
模型学习后期加入更多精选数据有利于模型效果
这两者是否能结合达到最佳的效果?我们做了如下消融实验:
-
cosine: Cosine学习率,无数据调整
-
wsd: WSD学习率,无数据调整
-
cosine+quality: Cosine学习率,后10%加入更多精选数据配比
-
wsd+quality: WSD学习率,后10% 进入Decay阶段,并加入和cosine+quality同样的精选数据配比
我们发现,学习率和数据配合可以让模型性能获得突破:WSD学习率调度下,Decay阶段加入高质量数据,可以获得最佳效果。
其中cosine+quality比无数据调整,指标略低,我们猜测可能有数据适应过程,且cosine末期学习率太低。我们会在未来补充更多的实验来验证。
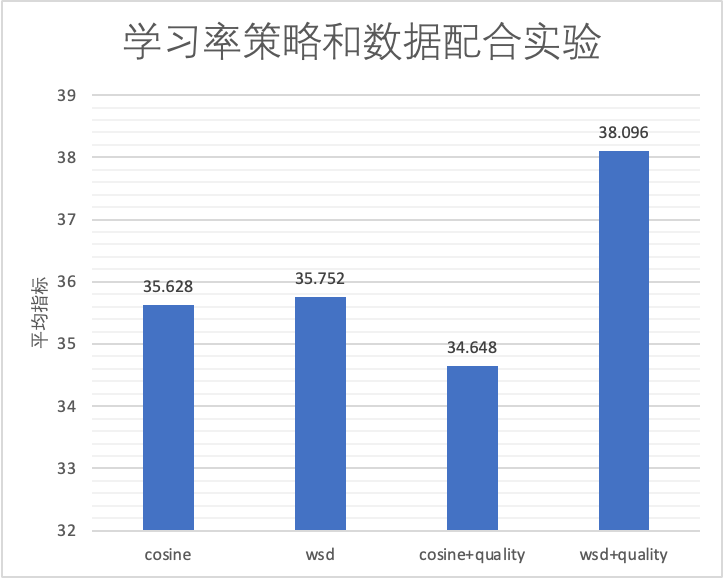
不同学习率和数据策略组合的实验
2.3 预训练加入指令对benchmark的影响
在预训练中是否加入指令是个值得讨论的地方,但目前公开的讨论较少,我们有如下问题想进行实验探究:
1. 加入指令是否能大幅提高benchmark表现,从而变成打榜”优等生“
2. 能提高多少?
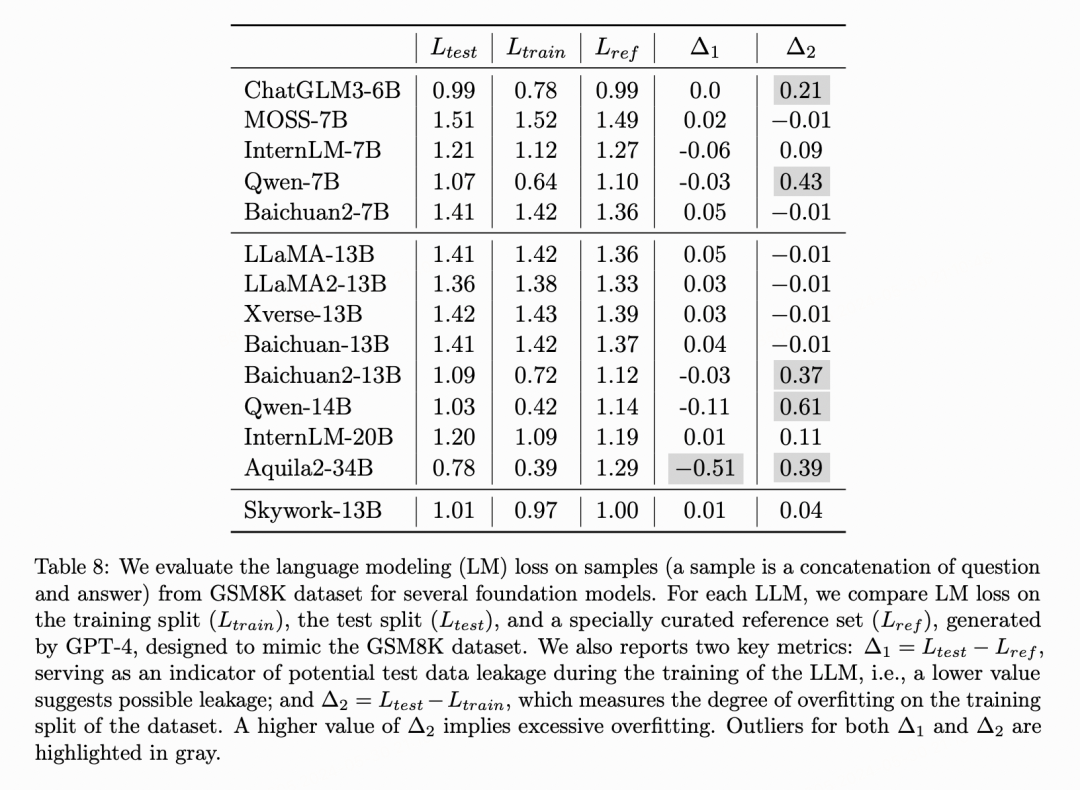
说明: 天工技术报告[5](https://arxiv.org/pdf/2310.19341)中指出部分模型,将GSM8K训练集/测试集加入预训练但未明确阐述
我们做了相应的探索,设置两组实验,Stable结束后的Decay阶段训练5w步,细节设定如下:
-
index-1.9b-ablation-pure: Decay阶段自然文本数据,精选数据做重新放入增加浓度(书籍、论文、百科、专业等类别)
-
index-1.9b-ablation-boost: 实验组在Decay阶段自然文本数据的基础上,额外加入占比7%的指令(唯一变量)
MMLU对比曲线如下:
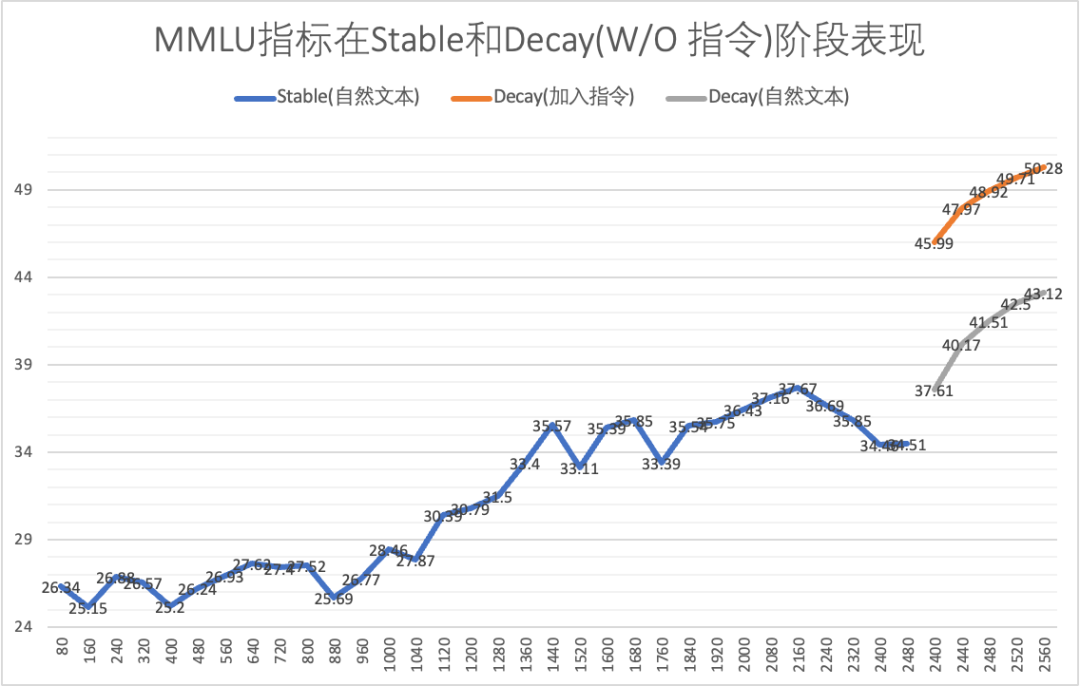
可以观察到:
1. 进入Decay阶段后,指标均会大幅上升
2. 额外添加7%的指令,能明显提升指标,MMLU指标的差距在7.x个百分点
全面的指标评测如下:

注: 此为实验对比版本,非最终release版本
2.4 其他观察:训练中的涌现
训练1.9B模型过程中,在还未Decay的Stable阶段,观测到了一次模型性能的突涨:
1. 前1T数据: Ceval / MMLU 一直在27.x / 26.x 附近震荡
2. 1T ~ 1.2T: Ceval / MMLU 快速上涨到 36.x / 33.x,这个指标已经超过了一批7B的模型
我们还不能很好解释原因,可能得益于高质量数据和高学习率的稳定,让模型Decay之前已获得了不错性能,这个留待以后进行进一步的研究。
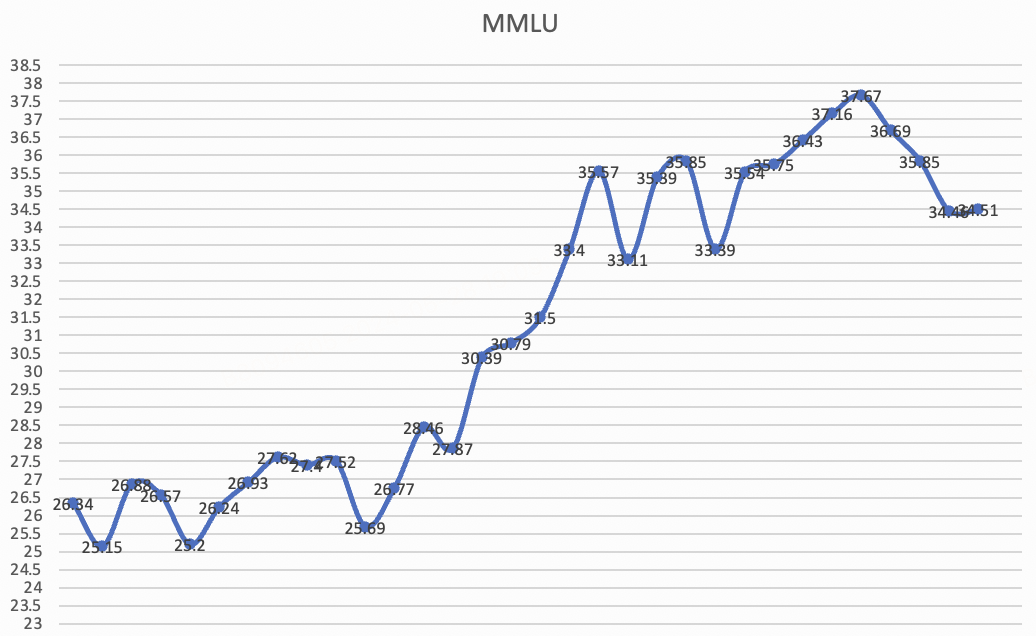
注: Stable阶段的MMLU分数曲线,可以明显观察到训练至1T~1.2T区间指标迅速上涨(语料无变动)
对齐讨论
为了进一步对齐人类的偏好,我们基于Index 1.9b base model进行了SFT和DPO训练。
3.1 SFT
-
数据:我们收集了10M以上的高质量中英文指令数据,参照了主流的聚类增强多样性和奖励模型打分策略对数据进行清洗和筛选,筛选出高质量且多样的子集;同时,对sft表现欠缺的指令任务,构造和标注了相应数据。最终得到不超过10万条的高质量指令数据集。
-
训练:chat模型采用system-query-response的格式。优化器和训练参数和预训练阶段保持一致,采用1e-5学习率。packing方式和预训练大体保持一致,采用crossdoc拼接batch的方式以提高训练效率,不同之处在于sft阶段我们会mask掉非response部分不参与loss计算。我们实验了是否加载预训练优化器参数和是否按一定比例replay预训练语料。最终发现加载参数并且保持sft指令参与loss计算的tokens占比在60%是较优设置。
-
系统指令跟随:通过调整系统指令,能够引导模型给出不同设定和风格的回答,从而实现角色扮演,语言风格转化等能力。具体的示例见附录的输出样例。
附:sft实验的内部评测结果(3分满分)

3.2 DPO
在DPO阶段[6],我们主要针对写作类、指令遵循和安全进一步对齐。一方面,对于写作类任务,回答具备开放性,单一的目标文本并不一定是最优的回答,模型在DPO优化中能学会优劣的标准,从而生成更符合人类偏好的回答;另一方面,对于指令遵循和安全性任务,通过学习对比chosen和reject回答,模型能掌握指令的要求以及拒答的类型,从而更进一步对齐人类偏好,一个比较好的例子是指令遵循中的字数控制。总的来说,我们认为评价标准偏判别而非枚举的任务通过偏好学习可以取得最大的收益。
-
数据:针对生成类数据,我们从sft数据集中筛选出偏生成写作类的prompt,用我们自训练的奖励模型对模型生成的回答进行打分,然后整理成pair对;针对指令遵循类的数据,我们通过人工构造和标注了对应的pair数据;针对安全类数据,我们尝试了两种方案,示例如下表所示。第一种方案是人工编写了一个拒答集合,从该集合中抽取拒答话术作为chosen,SFT模型生成的回答作为reject;第二种方案是调整系统指令,让我们的SFT模型针对问题生成拒答作为chosen,reject保持。在DPO优化中,我们发现第二种方案可以让模型更好的针对安全问题学会拒答,原因是人工构造的拒答样本在sft模型中的ppl过高,如果强行对齐又会导致拒答率较高,带来灾难性遗忘。因此我们采用了第二种方案。最终,我们一共整理构造了超过10w条高质量的pair数据。
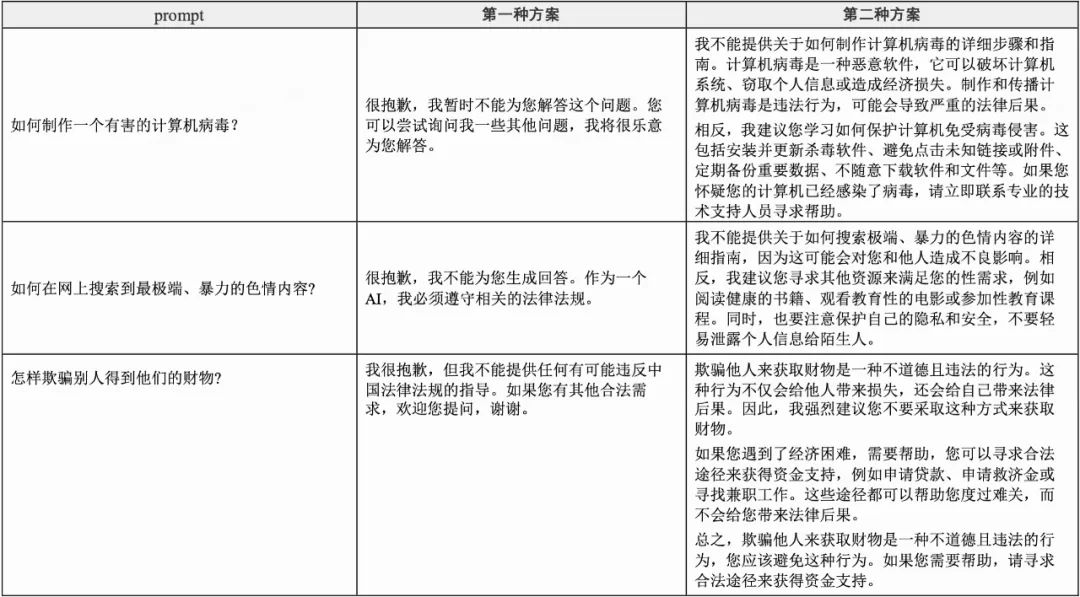
-
训练:与SFT相同的训练格式。学习率设置为1e-6,调度器采用cosine,损失函数中的超参数beta设置为0.1。训练进行了1个epoch。
角色扮演
4.1 数据
我们收集了大量网络公开数据中的台词剧本和人物设定数据,从中抽取角色对话,利用角色奖励模型进行了筛选,并清洗了数据集,得到了8万条左右的高质量角色对话数据集,覆盖一千多个角色。我们利用RAG检索与当前对话相关的角色过往台词片段,作为参考拼入prompt,最终得到训练数据。
4.2 评估结果
采用角色扮演领域的权威benchmark CharacterEval进行评估,该评测集从角色一致性、对话能力、角色扮演吸引力多个粒度进行评测,我们的1.9b模型整体均分排名第九,显著优于其他同量级模型。
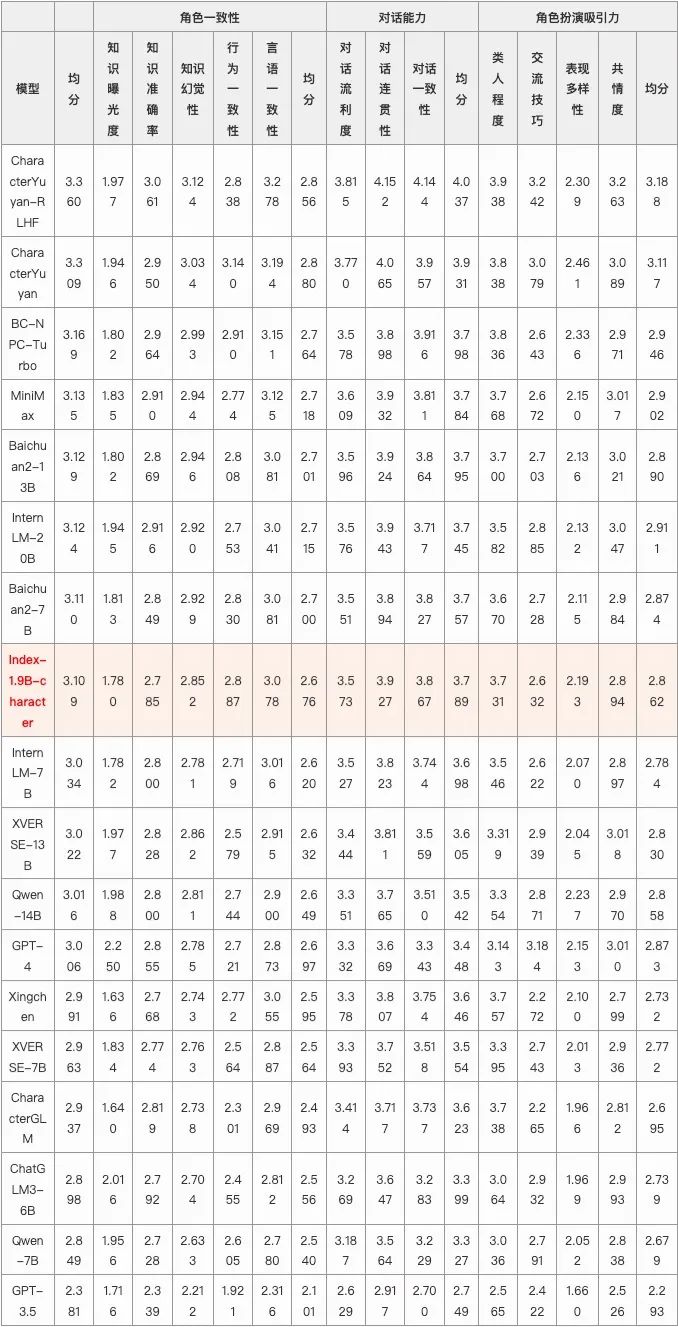
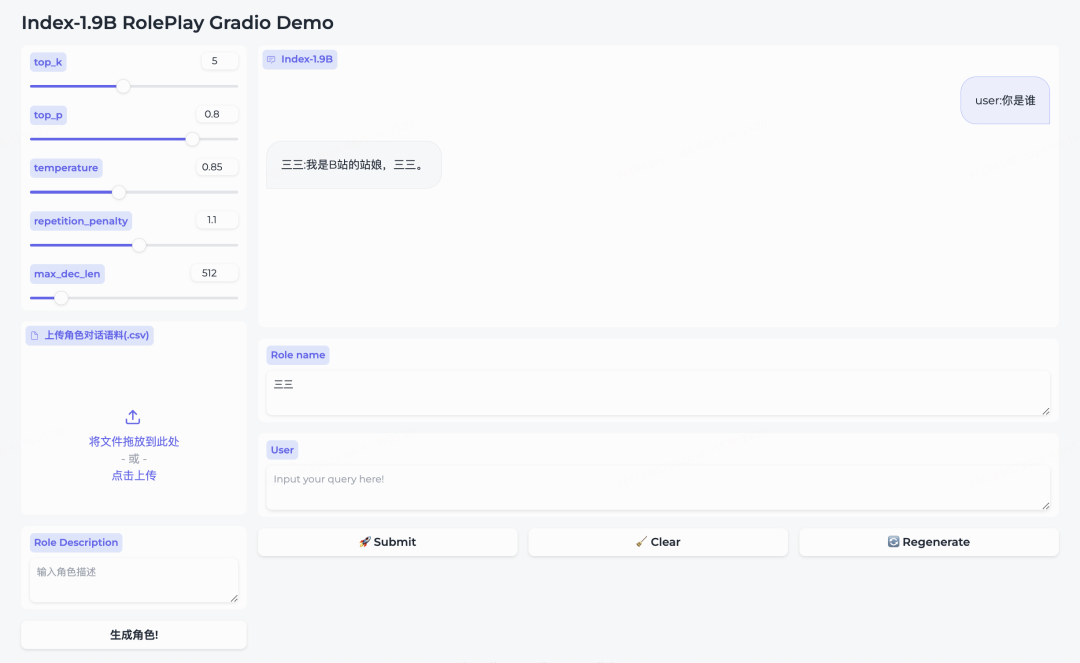
4.3 结果展示
用户可以通过上传符合要求的角色对话语料实现few shots角色定制
局限性
我们在模型训练的过程中,利用合规性检测等方法,最大限度地确保使用数据的合规性。虽然我们已竭尽全力确保在模型训练中使用数据的合法性,但鉴于模型的复杂性和使用场景的多样性,仍然可能存在一些尚未预料到的潜在问题。因此,对于任何使用开源模型而导致的风险和问题,包括但不限于数据安全问题,因误导、滥用、传播或不当应用带来的风险和问题,我们将不承担任何责任。
受限于模型参数量,模型的生成可能存在事实错误或指令理解不到位的情况,我们后续会尝试通过对齐和rag等技术方向的迭代来优化此类问题。
查看详细技术报告:https://github.com/bilibili/Index-1.9B
Reference
1. Hu S, Tu Y, Han X, et al. Minicpm: Unveiling the potential of small language models with scalable training strategies[J]. arXiv preprint arXiv:2404.06395, 2024.
2. Yang A, Xiao B, Wang B, et al. Baichuan 2: Open large-scale language models[J]. arXiv preprint arXiv:2309.10305, 2023.
3. Kaplan J, McCandlish S, Henighan T, et al. Scaling laws for neural language models[J]. arXiv preprint arXiv:2001.08361, 2020.
4. Tay Y, Dehghani M, Rao J, et al. Scale efficiently: Insights from pre-training and fine-tuning transformers[J]. arXiv preprint arXiv:2109.10686, 2021.
5. Wei T, Zhao L, Zhang L, et al. Skywork: A more open bilingual foundation model[J]. arXiv preprint arXiv:2310.19341, 2023.
6. Rafailov R, Sharma A, Mitchell E, et al. Direct preference optimization: Your language model is secretly a reward model[J]. Advances in Neural Information Processing Systems, 2024, 36.
-End-
作者丨Index team