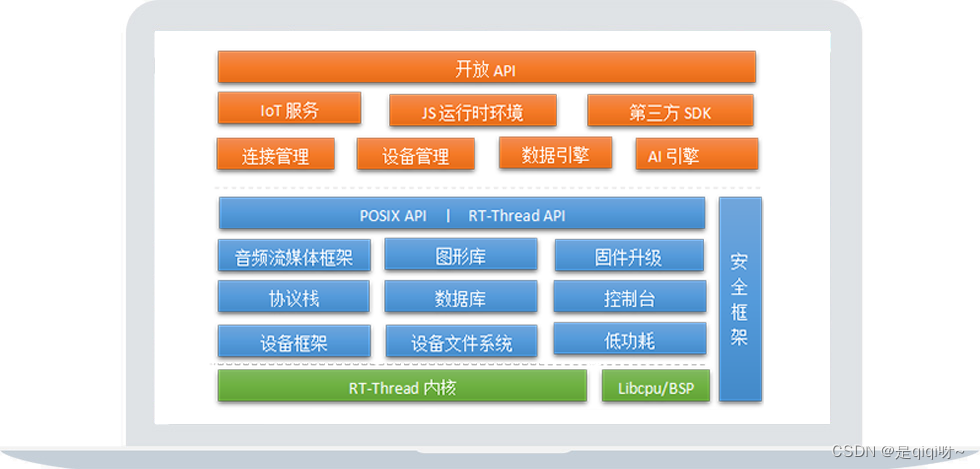
背景/引言
在现代 Web 开发中,Next.js 是一个备受欢迎的 React 框架,它具有许多优点,如:
- 服务器端渲染 (SSR):Next.js 支持服务器端渲染,可以提高页面加载速度,改善 SEO,并提供更好的用户体验。
- 静态站点生成 (SSG):Next.js 还支持静态站点生成,使你可以预先生成页面并将其缓存,从而减少服务器负载。
- 路由系统:Next.js 的路由系统非常灵活,可以轻松处理动态路由和参数。
- 开发体验:Next.js 提供了热模块替换 (HMR)、TypeScript 支持、自动导入 CSS 等功能,使开发变得更加愉快。
在本文中,我们将探讨如何在 Next.js 应用中处理上传的 Word 文档 (.docx) 文件,并将其内容保存到 Prisma ORM 中。同时,我们还将介绍如何使用爬虫技术,通过代理 IP 从外部源获取数据。
正文
1. 设置NextJs项目
首先,我们需要创建一个新的NextJs项目,并安装所需的依赖包。
npx create-next-app my-nextjs-app
cd my-nextjs-app
npm install @prisma/client prisma multer
2. 配置Prisma ORM
初始化Prisma,并配置数据模型。
npx prisma init
在prisma/schema.prisma文件中,添加一个Document模型:
model Document {id Int @id @default(autoincrement())name Stringcontent BytescreatedAt DateTime @default(now())
}
同步数据库:
npx prisma migrate dev --name init
3. 处理文件上传
在NextJs中,使用multer中间件来处理文件上传。创建一个API路由来接收上传的文件。
// pages/api/upload.js
import { PrismaClient } from '@prisma/client';
import multer from 'multer';const prisma = new PrismaClient();
const upload = multer();export const config = {api: {bodyParser: false,},
};const handler = async (req, res) => {upload.single('file')(req, res, async (err) => {if (err) {return res.status(500).send(err.message);}const { originalname, buffer } = req.file;const document = await prisma.document.create({data: {name: originalname,content: buffer,},});res.status(200).json(document);});
};export default handler;
4. 前端文件上传表单
创建一个简单的表单,用于上传docx文件。
// pages/index.js
import { useState } from 'react';const Home = () => {const [file, setFile] = useState(null);const handleFileChange = (e) => {setFile(e.target.files[0]);};const handleSubmit = async (e) => {e.preventDefault();const formData = new FormData();formData.append('file', file);const response = await fetch('/api/upload', {method: 'POST',body: formData,});const data = await response.json();console.log(data);};return (<form onSubmit={handleSubmit}><input type="file" onChange={handleFileChange} /><button type="submit">Upload</button></form>);
};export default Home;
5. 使用爬虫代理IP进行采集
在某些情况下,我们可能需要从外部源获取数据。这里展示如何使用代理IP进行爬虫,使用爬虫代理服务。
// utils/proxyScraper.js
const axios = require('axios');
const { HttpsProxyAgent } = require('https-proxy-agent');const proxy = {host: 'your-proxy-host', // 亿牛云爬虫代理的域名 www.16yun.cnport: 'your-proxy-port', // 亿牛云爬虫代理的端口auth: {username: 'your-username', // 亿牛云爬虫代理的用户名password: 'your-password', // 亿牛云爬虫代理的密码},
};const agent = new HttpsProxyAgent(`http://${proxy.auth.username}:${proxy.auth.password}@${proxy.host}:${proxy.port}`);const fetchData = async (url) => {try {const response = await axios.get(url, {httpsAgent: agent,});return response.data;} catch (error) {console.error('Error fetching data:', error);throw error;}
};module.exports = fetchData;
6. 示例爬取数据并存储到Prisma
示例代码展示如何使用上述代理IP配置,从外部源爬取数据,并将其存储到Prisma ORM中。
// pages/api/scrape.js
import { PrismaClient } from '@prisma/client';
import fetchData from '../../utils/proxyScraper';const prisma = new PrismaClient();const handler = async (req, res) => {try {const data = await fetchData('https://example.com/data-source');const document = await prisma.document.create({data: {name: 'Scraped Data',content: Buffer.from(data),},});res.status(200).json(document);} catch (error) {res.status(500).json({ error: 'Failed to fetch and save data' });}
};export default handler;
结论
本文介绍了如何在NextJs中处理docx文件上传,并将其存储到Prisma ORM中。同时,展示了如何使用爬虫代理进行采集,并将爬取到的数据存储到数据库中。通过这些示例代码,开发者可以更好地理解文件处理和数据存储的流程,并灵活应用代理IP技术来扩展数据获取能力。