目录
一、为什么要使用特征缩放(Feature Scaling)
1.首先来看预测房价的例子
2.特征缩放前后效果对比
二、特征缩放方法
1.统一除以范围最大值
2.均值归一化(Mean Normalization)
3.Z-score标准化(Z-score Normalization)
4.一些可以接受/不接受的缩放范围
三、如何识别梯度下降是否收敛
四、如何选择一个合适的学习率
1.学习曲线(J(w,b)-迭代次数)
2.学习率选择技巧
3.特征缩放和学习率选择实验
(1)在具有多个特征的数据集上运行梯度下降,探索学习率alpha对梯度下降的影响
①多特征数据集
②导入数据集
③绘制每一个特征和结果(房价)的散点分布图
④多特征的梯度下降算法
⑤选用学习率为9.9*10^-7时,迭代10次
⑥选择较小的学习率9.0*10^-7
⑦继续缩小学习率,使用1.0*10^-7
(2)使用z-score标准化通过特征缩放提高梯度下降的性能
①z-score计算公式及各参数计算方法
②代码实现
③标准化过程及效果
④比较原始数据和标准化处理后的各特征值x
⑤用标准化处理后的数据重新执行梯度下降算法
⑥使用训练好的模型进行预测
⑦J(w,b)等值线图下观察标准化对梯度下降算法效果
4.总结
五、特征工程和多项式回归
1.特征工程
2.多项式回归(也是很重要的回归模型)
3.特征工程和多项式回归实验
(1)没有进行特征工程的线性回归模型
(2)使用梯度下降的方式去训练多项式回归模型
(3)使用三次多项式回归模型训练
(4)从另一个角度来考虑选择什么样的模型更好的拟合训练数据
(5)使用特征缩放对x,x^2,x^3进行处理以后的效果
(6)使用特征工程还可以对复杂场景进行函数建模
4.总结
六、本章小结
一、为什么要使用特征缩放(Feature Scaling)
目的:使梯度下降算法运行速度更快,效果更好

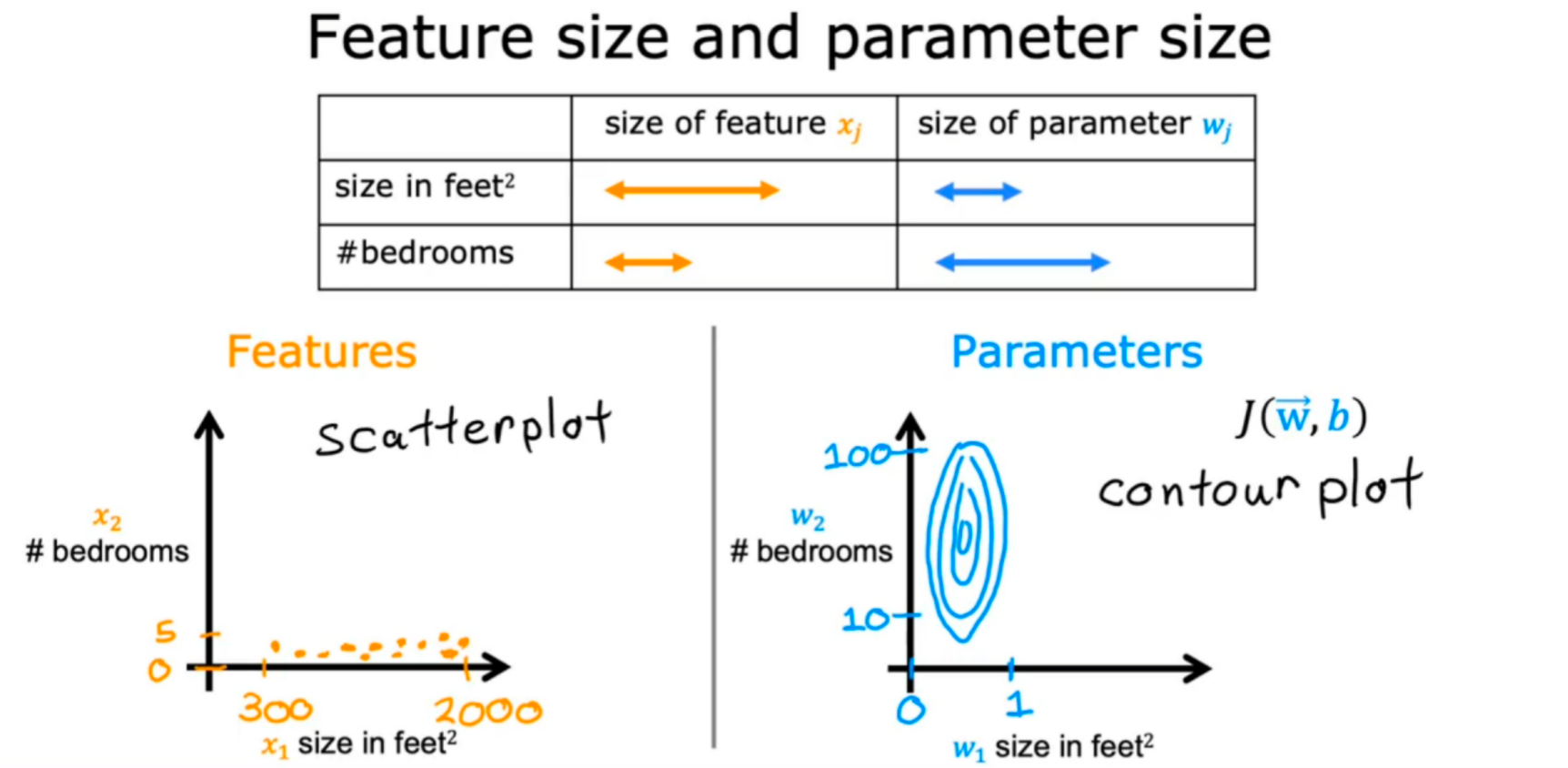
1.首先来看预测房价的例子
x1表示房子面积(范围较大),x2表示卧室数量(范围较小)
(1)如果初始时,w1设置为50,w2设置为0.1,那么初始计算的price为:100050
(2)如果初始时,w1设置为0.1,w2设置为50,那么初始计算的price为:500(这个相对更合理)
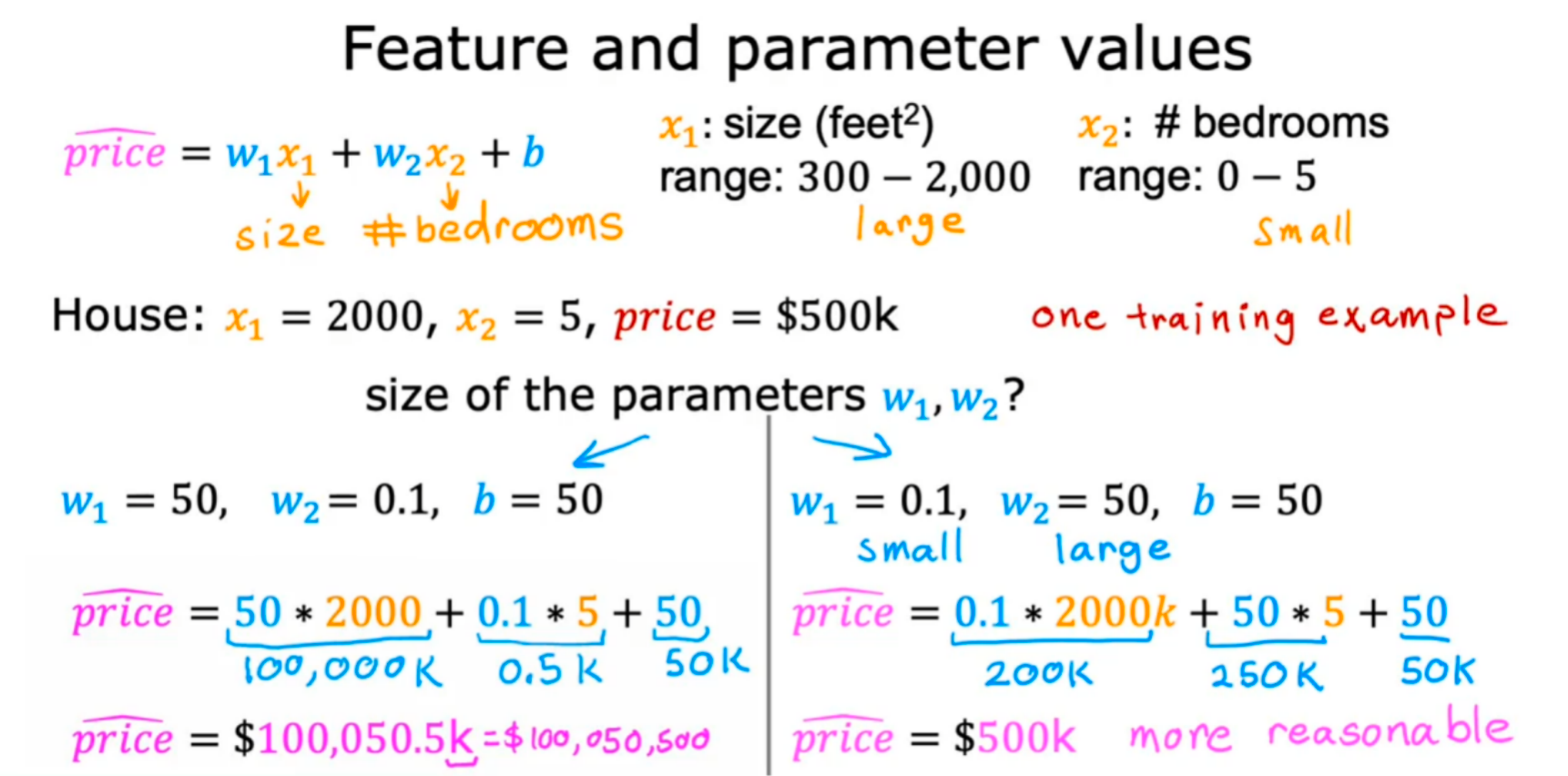
从上面可以看到,如果x1和x2两个特征差距太大,相应的w1和w2两个参数也会差距太大
当x1范围大则w1相应的变化范围就会很小,当x2范围小则w2相应的变化范围就会很大:
2.特征缩放前后效果对比
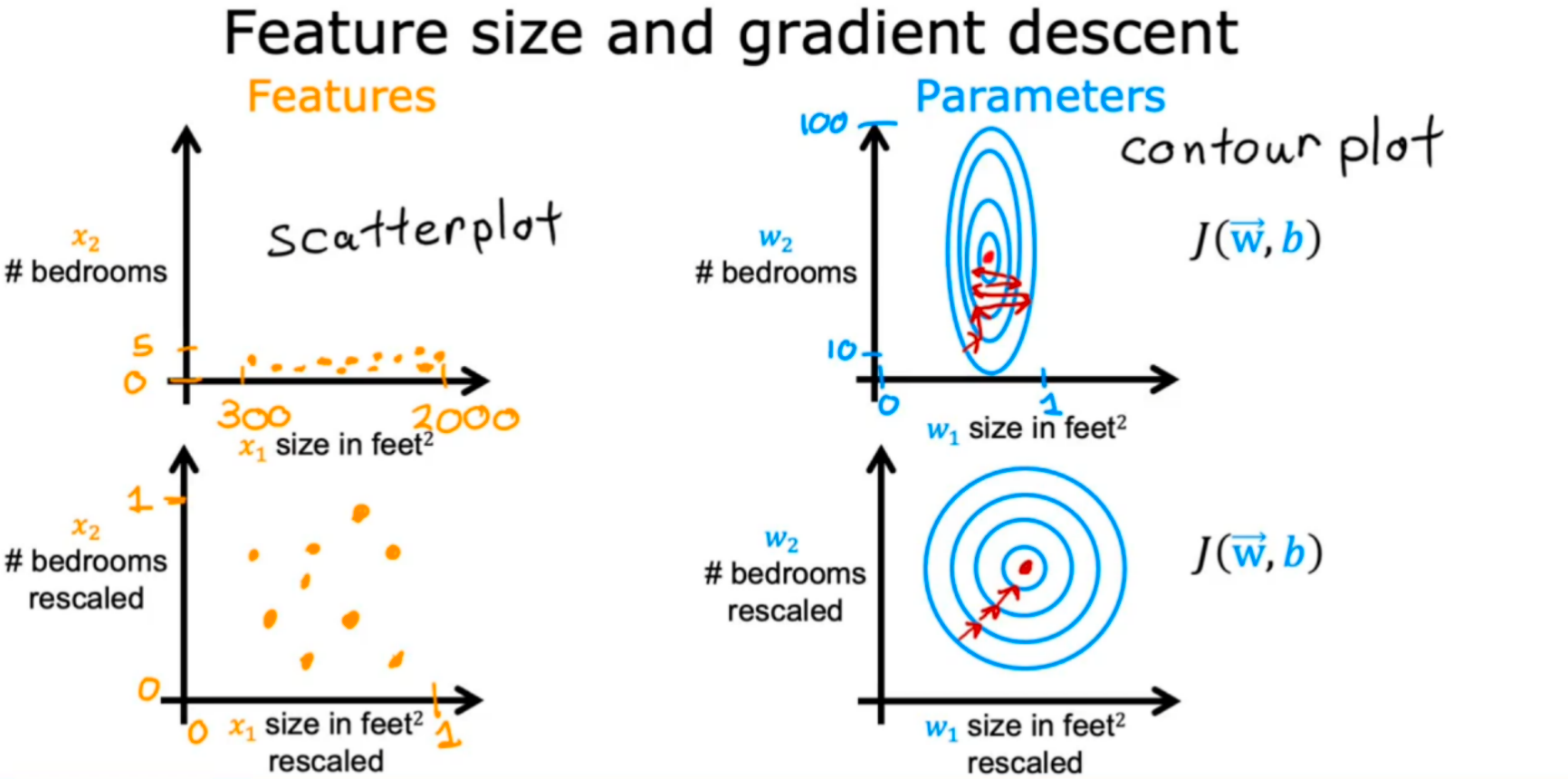
下图是x1、x2进行特征缩放前后的f(x1,x2)散点分布图和代价函数J(w,b)的等高线图
如果按原样训练数据。因为J(w,b)轮廓高而细,梯度下降可能会在结束前来回反弹了很长时间都没办法找到全局最小值的方法。在这种情况下,一个有用的要做的就是缩放特征。这意味着执行一些对训练数据进行变换,使x1的范围现在可以从0到1和x2的取值范围也可以是0到1。
数据点看起来更像这样左下的散点图;你可能会注意到下面的图的比例现在相当和上面的不一样。关键是x1和x2现在都是可比较的,如果你运行梯度下降在这里找到一个成本函数,使用它重新缩放x1和x2变换后的数据,轮廓看起来会更像圆圈(右下),梯度下降法可以通过更直接的路径到全局最小值,缩放后更容易找到合适的w和b参数值。
二、特征缩放方法
1.统一除以范围最大值

2.均值归一化(Mean Normalization)
分子为x1-μ(均值)
分母为范围最大值-范围最小值
均值归一化的取值范围为-1~1

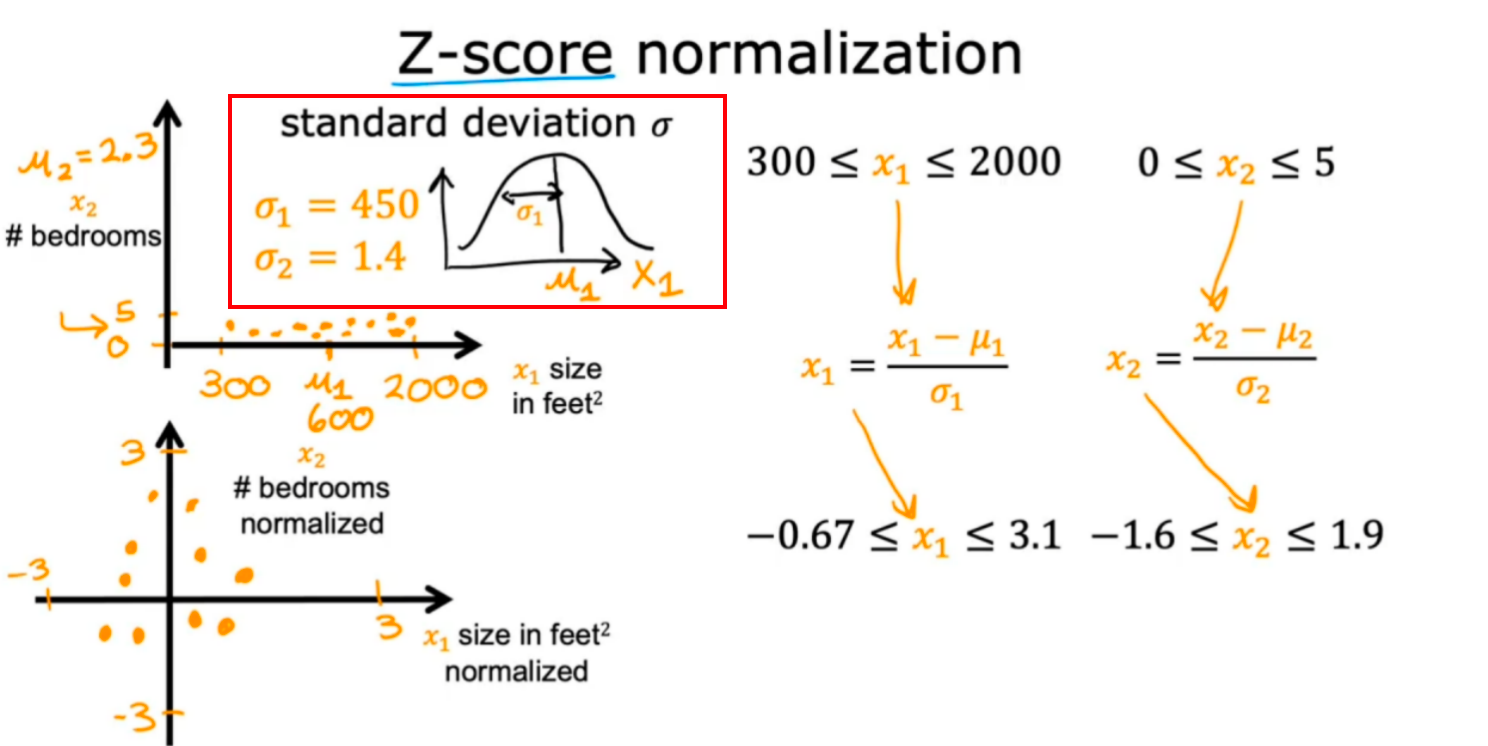
3.Z-score标准化(Z-score Normalization)
计算公式为𝑍=(𝑋−𝜇)/𝜎,其中Z表示Z分数,X表示一个数据点的值,μ表示数据集的均值,𝜎表示数据集的标准差
4.一些可以接受/不接受的缩放范围

三、如何识别梯度下降是否收敛

可以借助J(w,b)-迭代次数学习曲线来获取一些梯度下降的信息
1.如果随着迭代次数增加,J(w,b)不降反增,这表示α可能选择的太大,或者程序出现了bug
2.当迭代到一定次数后,J(w,b)趋于平稳,那么就可能意味着经过这些次数迭代J(w,b)收敛
3.不同的代价函数迭代次数不一样,有的30次就收敛,有的1000次,有的100000次,这个次数经过我们绘制学习曲线也会有个比较直观的认识。
具体什么时候达到收敛,我们可以设置一个阈值ε,当迭代过程中代价函数的减少值小于这个阈值就可以认为已收敛。
四、如何选择一个合适的学习率
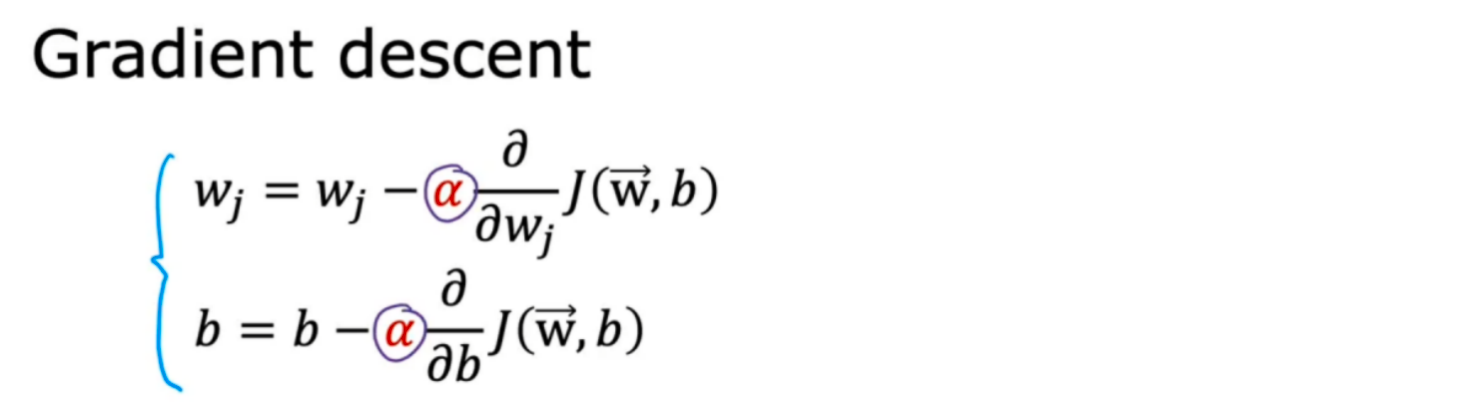
1.学习曲线(J(w,b)-迭代次数)
可能出现的情况,原因可能是程序存在bug或者学习率过大
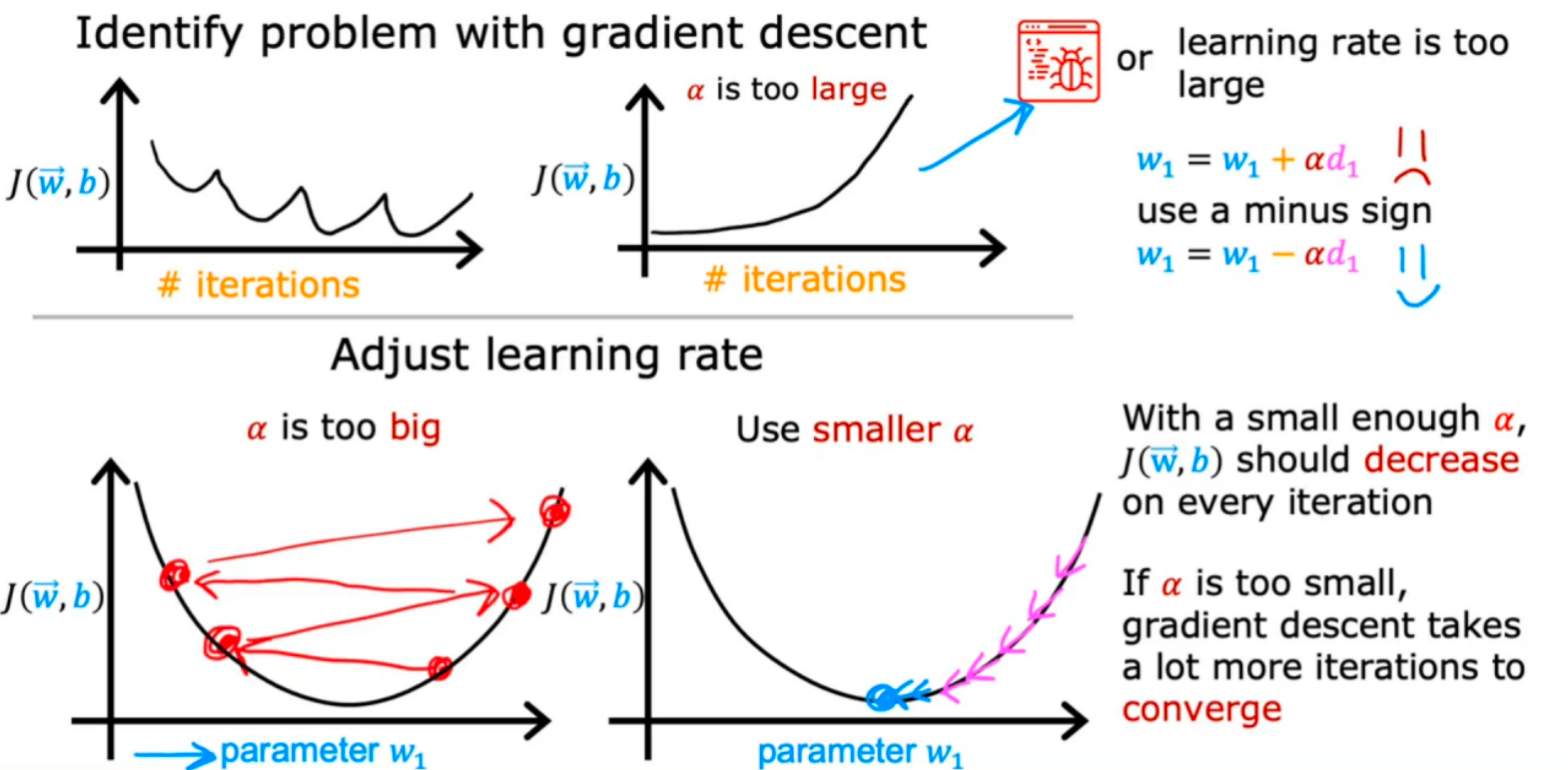
技巧:设置一个非常小的学习率α,如果在这样的学习率下还是会有J(w,b)在迭代中增加,此时就要注意程序内是否存在bug了,这里选择非常小的学习率只是一个调试过程,用于发现程序内可能存在的bug,但不是训练学习算法最好的选择(学习率太小可能会导致需要迭代很多次才能收敛)。
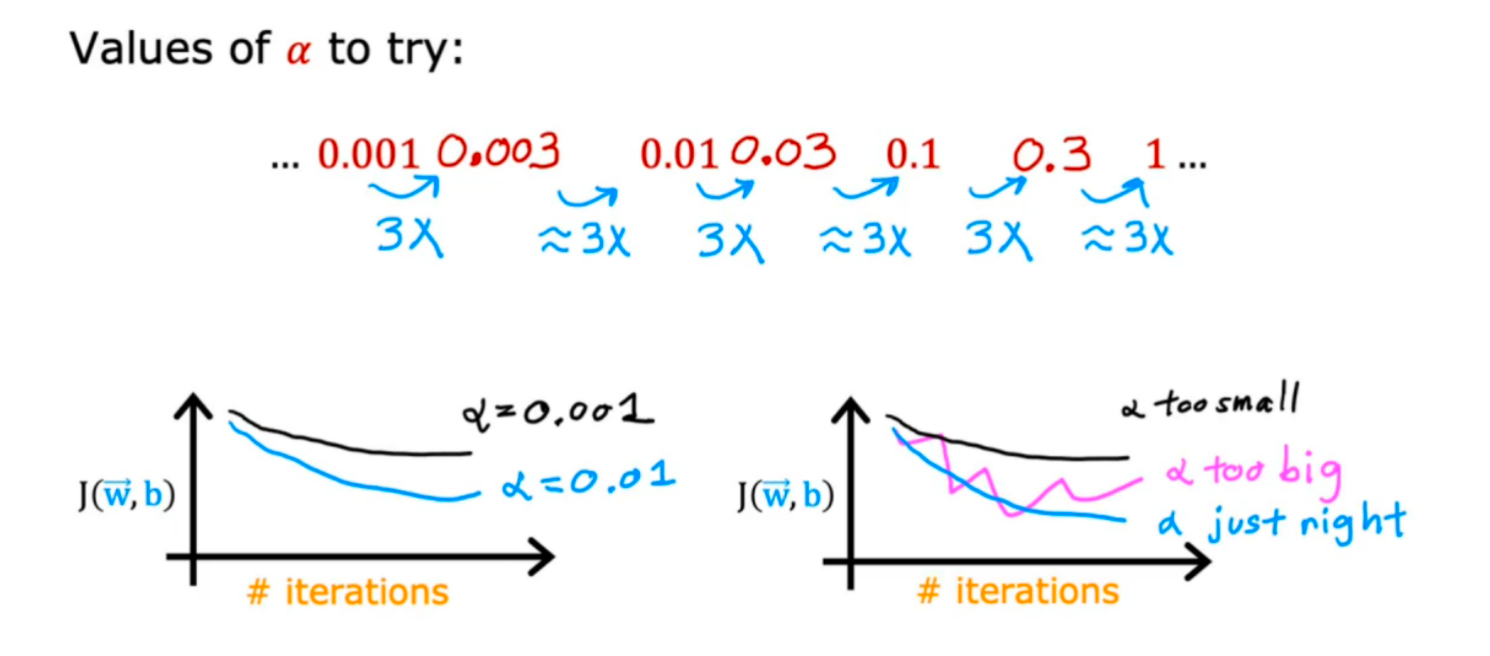
2.学习率选择技巧
可以使用下面的方式 3× 提高学习率的技巧去给算法选择合适的学习率
3.特征缩放和学习率选择实验
C1_W2_Lab03_Feature_Scaling_and_Learning_Rate
(1)在具有多个特征的数据集上运行梯度下降,探索学习率alpha对梯度下降的影响
①多特征数据集
②导入数据集
# load the dataset
X_train, y_train = load_house_data()
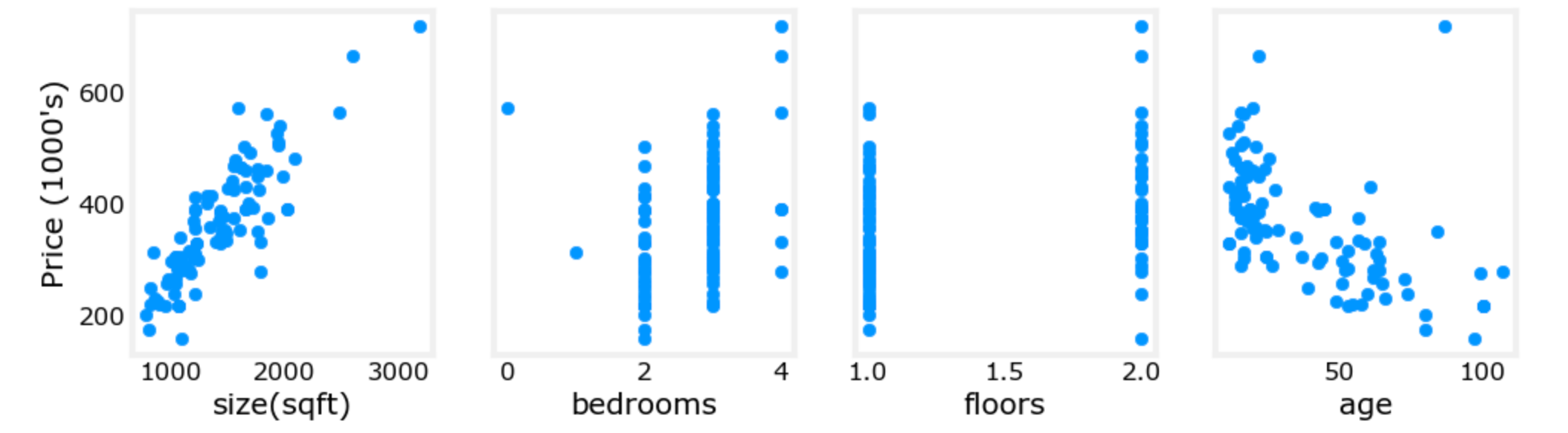
X_features = ['size(sqft)','bedrooms','floors','age']③绘制每一个特征和结果(房价)的散点分布图
可以看出哪些特征对价格影响最大。以上,增大尺寸也会增加价格。卧室和地板似乎对价格没有太大影响。新房子比老房子价格高。
④多特征的梯度下降算法

⑤选用学习率为9.9*10^-7时,迭代10次
#set alpha to 9.9e-7
_, _, hist = run_gradient_descent(X_train, y_train, 10, alpha = 9.9e-7)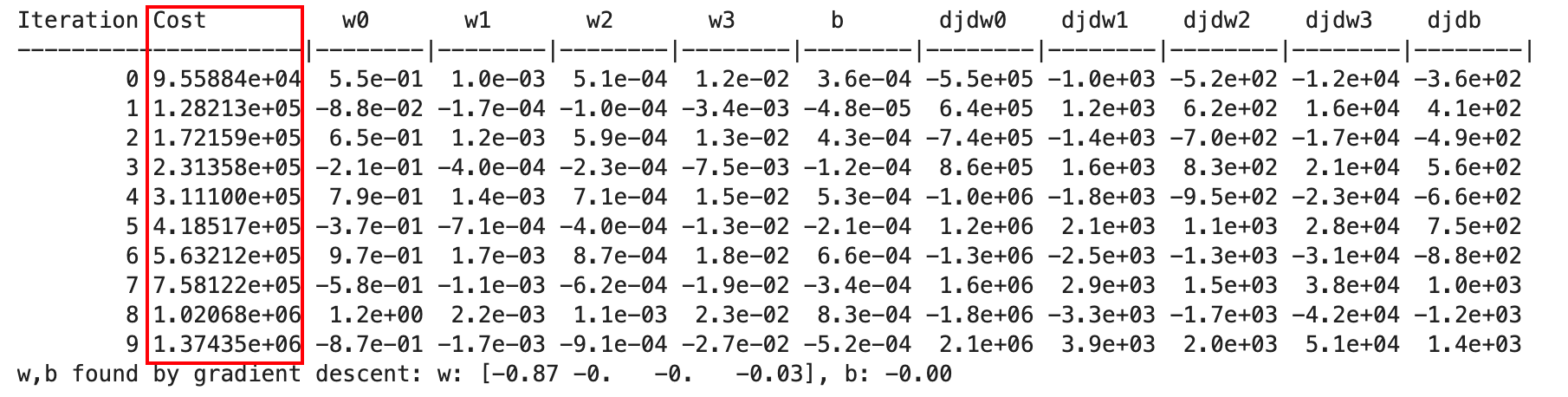
可以看到随着迭代次数增加,Cost是变大的,没有收敛
绘制图像如下:(右图只是展示了Cost和w0的关系,不代表和其他特征的关系也是如此)
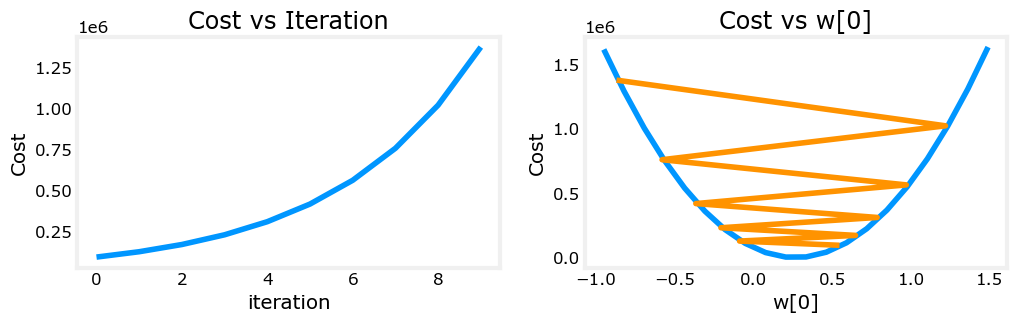
⑥选择较小的学习率9.0*10^-7

可见Cost是不断下降了,但是因为学习率太大,没有收敛,一直在“左右横跳”
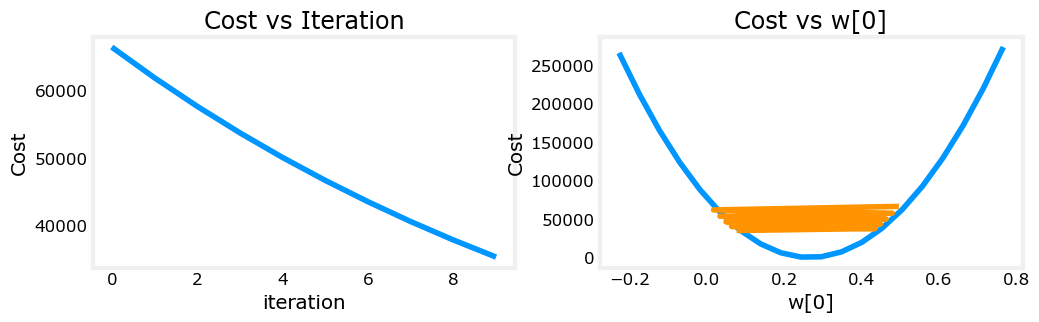
⑦继续缩小学习率,使用1.0*10^-7


可见效果明显变好
(2)使用z-score标准化通过特征缩放提高梯度下降的性能
①z-score计算公式及各参数计算方法

②代码实现
def zscore_normalize_features(X):"""computes X, zcore normalized by columnArgs:X (ndarray): Shape (m,n) input data, m examples, n featuresReturns:X_norm (ndarray): Shape (m,n) input normalized by columnmu (ndarray): Shape (n,) mean of each featuresigma (ndarray): Shape (n,) standard deviation of each feature"""# find the mean of each column/featuremu = np.mean(X, axis=0) # mu will have shape (n,)# find the standard deviation of each column/featuresigma = np.std(X, axis=0) # sigma will have shape (n,)# element-wise, subtract mu for that column from each example, divide by std for that columnX_norm = (X - mu) / sigma return (X_norm, mu, sigma)#check our work
#from sklearn.preprocessing import scale
#scale(X_orig, axis=0, with_mean=True, with_std=True, copy=True)③标准化过程及效果
房屋年龄和面积都归一化后散点分布更加均匀了

④比较原始数据和标准化处理后的各特征值x
# normalize the original features
X_norm, X_mu, X_sigma = zscore_normalize_features(X_train)
print(f"X_mu = {X_mu}, \nX_sigma = {X_sigma}")
print(f"Peak to Peak range by column in Raw X:{np.ptp(X_train,axis=0)}")
print(f"Peak to Peak range by column in Normalized X:{np.ptp(X_norm,axis=0)}")
观察图像,标准化处理前后范围变化:
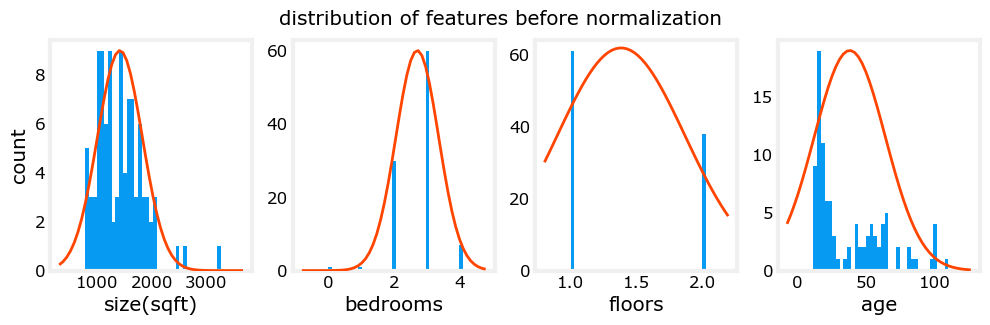
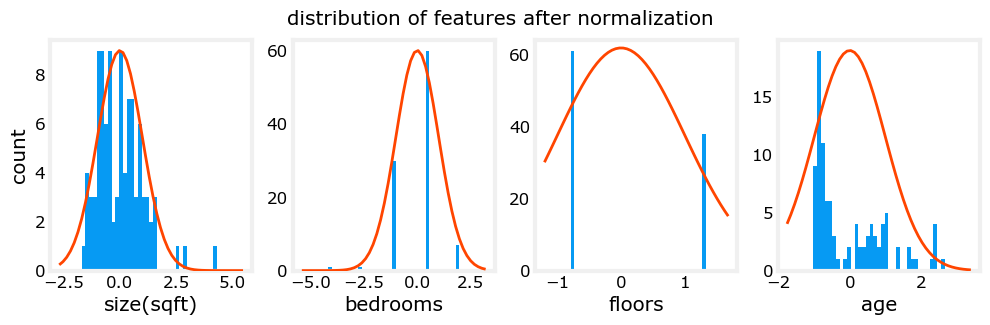
注意,上面规范化数据的范围以0为中心,大致为+/- 1。最重要的是,每个特征的范围是相似的。
⑤用标准化处理后的数据重新执行梯度下降算法
注意alpha的值要大得多,这将加速下降
w_norm, b_norm, hist = run_gradient_descent(X_norm, y_train, 1000, 1.0e-1, )
在上一章的最后我们使用原始的方法进行计算:
四、多特征的线性回归模型-CSDN博客文章浏览阅读1.3k次,点赞41次,收藏17次。在本文中介绍了多特征的线性回归模型的应用场景、多特征的线性回归模型梯度下降法、多特征变量的向量表示并强调了向量化操作在效率提升上的重要性。接着,文章详细比较了单特征和多特征梯度下降的区别,以及传统设置变量法与向量表示的异同。最后,通过实际实验,展示了如何运用numpy包对向量或矩阵的各种处理操作,如何运用多特征的线性回归模型梯度下降法迭代计算令代价最小的多个特征参数的值。整篇文章系统地概述了梯度下降在多元线性回归中的应用。
https://blog.csdn.net/hehe_soft_engineer/article/details/139449052#t21

上面使用原始数据计算在1000次后还没有收敛,可以看到在标准化处理后进行训练300次后就达到了收敛,收敛速度比较快。
⑥使用训练好的模型进行预测
注意:生成我们的模型的目的是用它来预测数据集中不存在的房价。让我们来预测一套拥有1200平方英尺、3间卧室、1层楼、40年历史的房子的价格。回想一下,你必须用归一化训练数据时得到的均值和标准差来归一化新的输入数据。
# First, normalize out example.
x_house = np.array([1200, 3, 1, 40])
x_house_norm = (x_house - X_mu) / X_sigma
print(x_house_norm)
x_house_predict = np.dot(x_house_norm, w_norm) + b_norm
print(f" predicted price of a house with 1200 sqft, 3 bedrooms, 1 floor, 40 years old = ${x_house_predict*1000:0.0f}")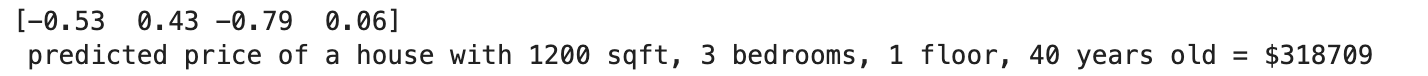
⑦J(w,b)等值线图下观察标准化对梯度下降算法效果
在下面的J(w,b)等值线图中,参数的比例是匹配的。左边的图是归一化特征前的w[0]平方英尺与w[1]的卧室数量对比图。这幅图太不对称了,无法看到补全轮廓的曲线。相反,当特征归一化后,代价轮廓更加对称。结果是,在梯度下降过程中对参数的更新可以对每个参数的变化取得相似的效果。

4.总结
选择学习率是训练许多学习算法的重要组成部分,通过理论和实验的学习帮助我们用科学的方式为梯度下降选择一个好的学习率,了解不同的学习率选择对模型训练带来的效果,在直觉上也有助于我们更好的理解如何选择一个好的学习率。
五、特征工程和多项式回归
1.特征工程
通过直觉或者对问题专业知识的理解去设计新的特性,通常的方式是通过转换或者结合问题的原始特征来完成,目的是让学习算法更容易做出准确合理的预测。
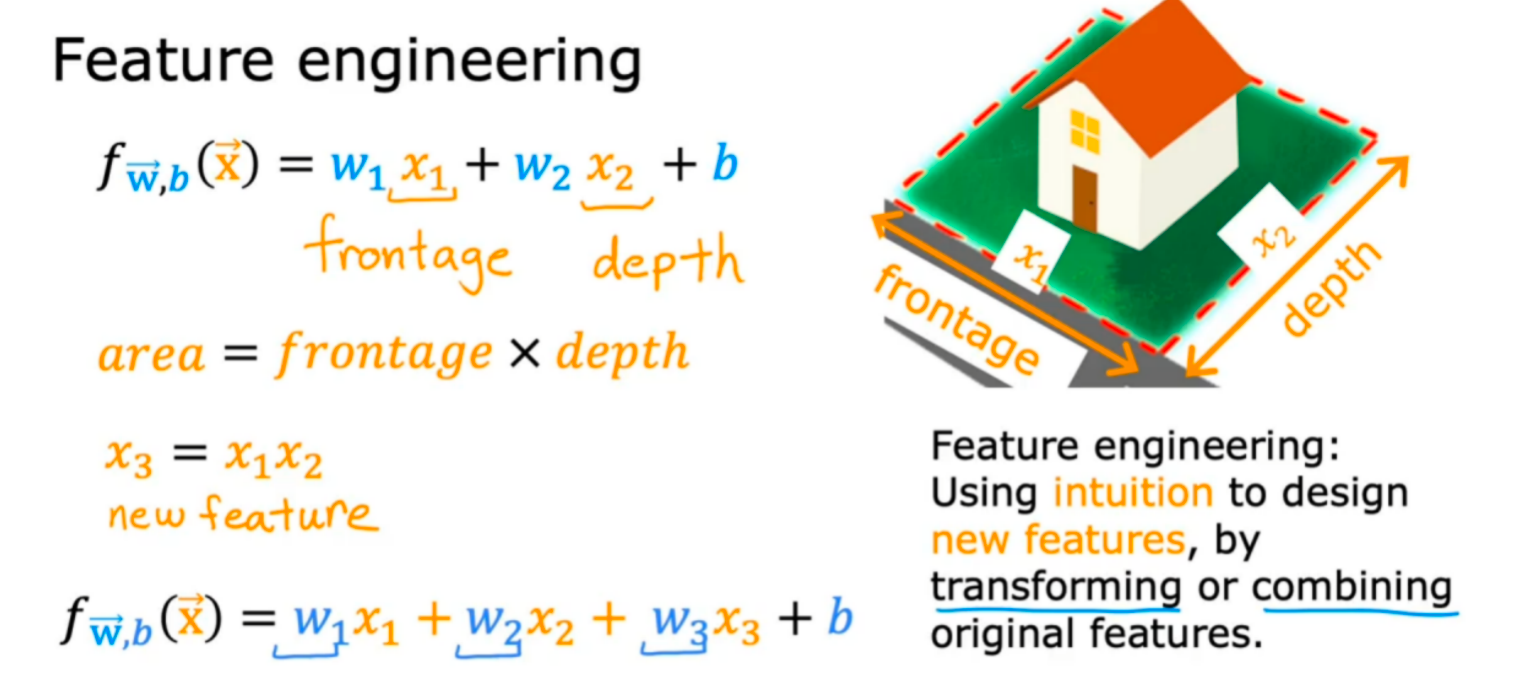
比如刚开始f(x)只是使用长和宽作为特征来构造线性回归模型,但是发现长×宽=面积引入后,面积更能决定房价,所以我们就可以完善我们的模型,将面积作为特征引入。
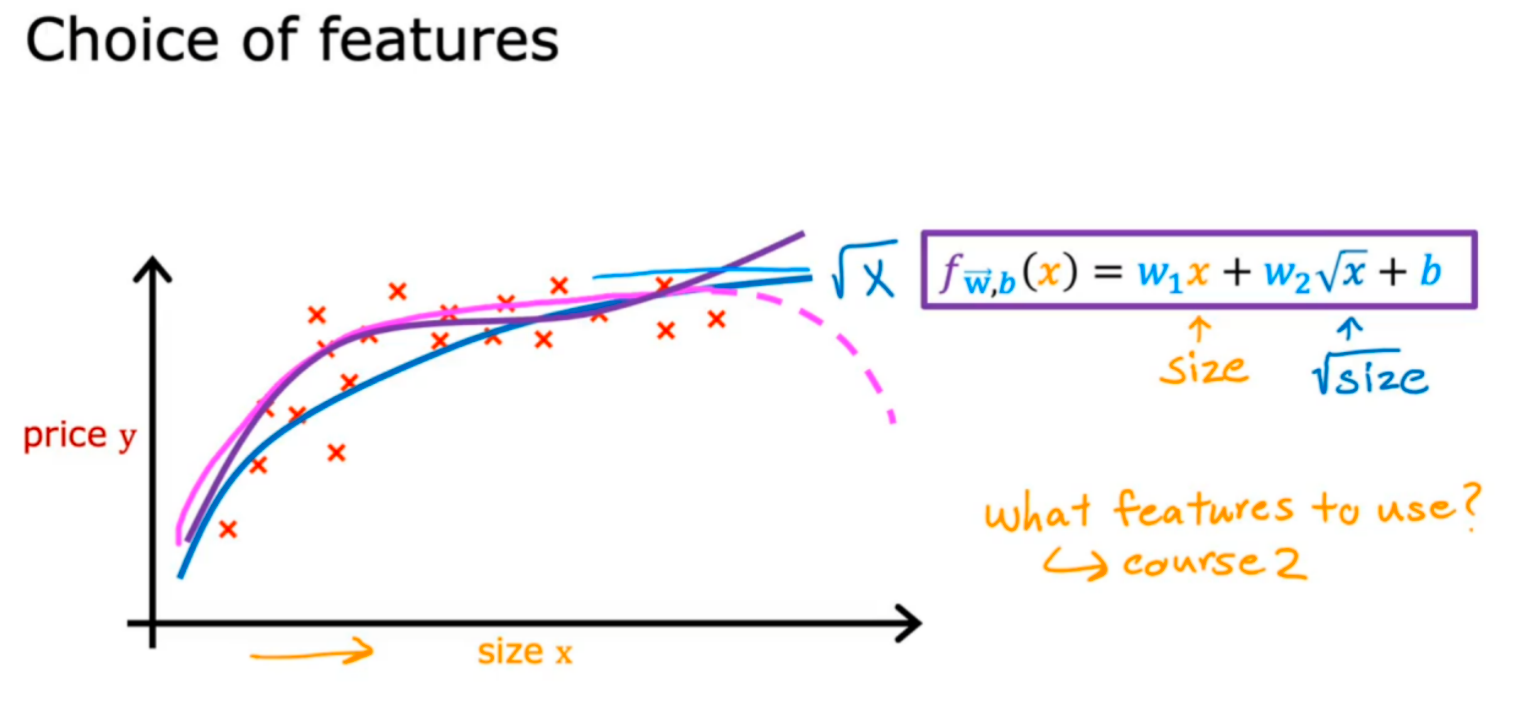
2.多项式回归(也是很重要的回归模型)
下面根据数据可以选择不同的模型来训练,有的效果好,有的效果差

3.特征工程和多项式回归实验
C1_W2_Lab04_FeatEng_PolyReg:探索特征工程和多项式回归,它允许你使用线性回归的机制来拟合非常复杂,甚至非线性的函数。
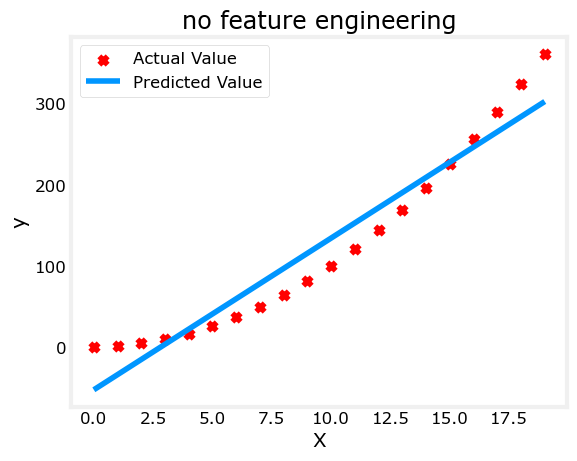
(1)没有进行特征工程的线性回归模型
x数据集使用的0~20之间的整数,y数据集对每个x计算:
# create target data
x = np.arange(0, 20, 1)
y = 1 + x**2
X = x.reshape(-1, 1)model_w,model_b = run_gradient_descent_feng(X,y,iterations=1000, alpha = 1e-2)plt.scatter(x, y, marker='x', c='r', label="Actual Value"); plt.title("no feature engineering")
plt.plot(x,X@model_w + model_b, label="Predicted Value"); plt.xlabel("X"); plt.ylabel("y"); plt.legend(); plt.show()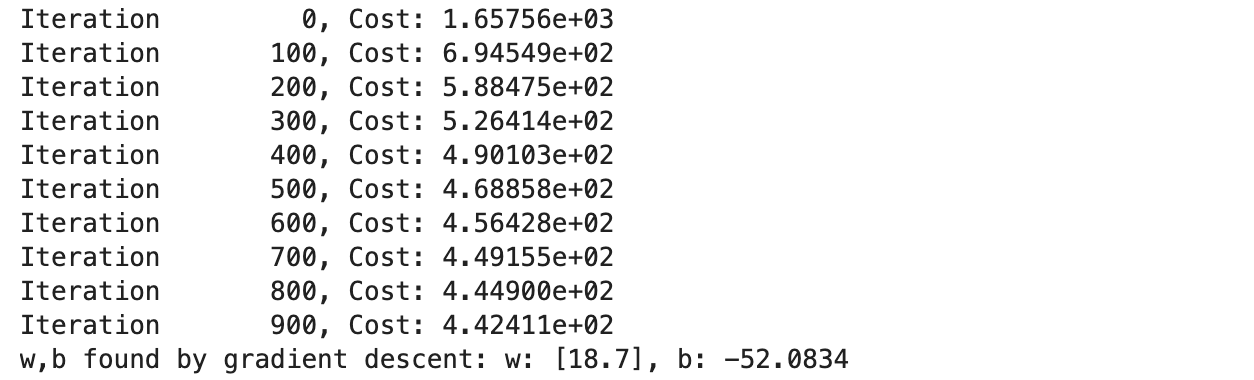
用训练模型去对训练数据集预测,可以看到线性的模型并不能描述真实数据
(2)使用梯度下降的方式去训练多项式回归模型
设置模型为
# create target data
x = np.arange(0, 20, 1)
y = 1 + x**2# Engineer features
X = x**2 #<-- added engineered featureX = X.reshape(-1, 1) #X should be a 2-D Matrix
model_w,model_b = run_gradient_descent_feng(X, y, iterations=10000, alpha = 1e-5)plt.scatter(x, y, marker='x', c='r', label="Actual Value"); plt.title("Added x**2 feature")
plt.plot(x, np.dot(X,model_w) + model_b, label="Predicted Value"); plt.xlabel("x"); plt.ylabel("y"); plt.legend(); plt.show()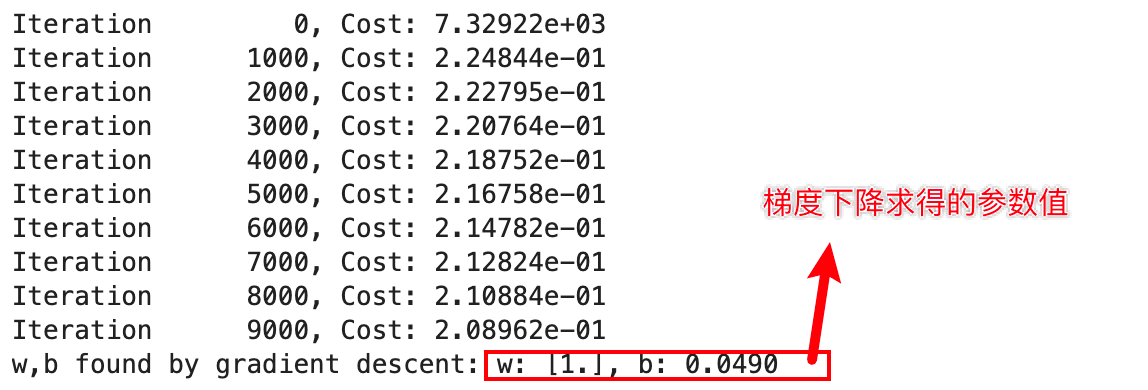
多项式模型预测效果和训练数据拟合,效果很好

(3)使用三次多项式回归模型训练
特征值为一次项,二次项,三次项
# create target data
x = np.arange(0, 20, 1)
y = x**2# engineer features .
X = np.c_[x, x**2, x**3] #<-- added engineered feature还是使用梯度下降法训练:
model_w,model_b = run_gradient_descent_feng(X, y, iterations=10000, alpha=1e-7)plt.scatter(x, y, marker='x', c='r', label="Actual Value"); plt.title("x, x**2, x**3 features")
plt.plot(x, X@model_w + model_b, label="Predicted Value"); plt.xlabel("x"); plt.ylabel("y"); plt.legend(); plt.show()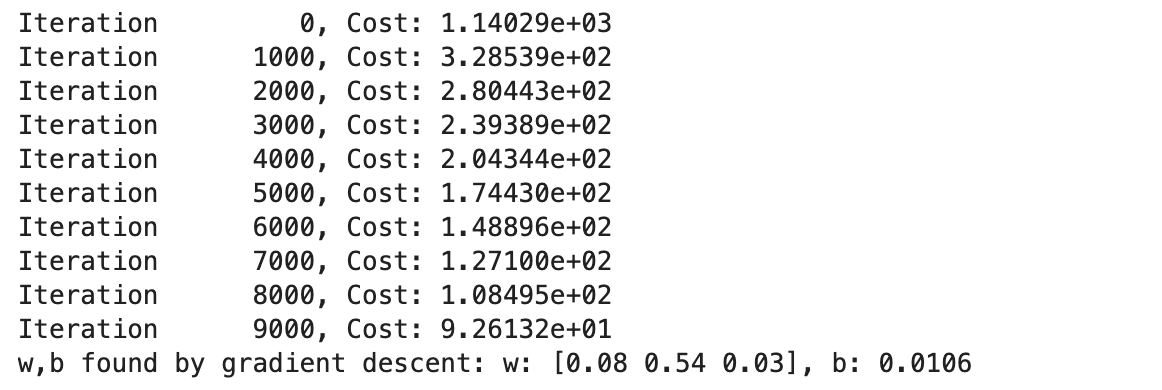

拟合的三次多项式:效果并不如二次多项式好
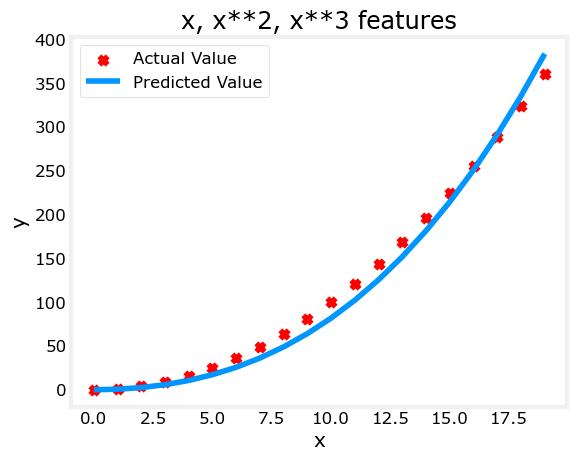
(4)从另一个角度来考虑选择什么样的模型更好的拟合训练数据
对x轴进行标度变换为X(大写),如果变换后的y和X(大写)满足线性关系,那么说明对x轴进行标度变换的函数就是比较好的回归模型
下面就是选择使用作为标度变换模型来看y与标度变化后的X之间的关系:
# create target data
x = np.arange(0, 20, 1)
y = x**2# engineer features .
X = np.c_[x, x**2, x**3] #<-- added engineered feature
X_features = ['x','x^2','x^3']fig,ax=plt.subplots(1, 3, figsize=(12, 3), sharey=True)
for i in range(len(ax)):ax[i].scatter(X[:,i],y)ax[i].set_xlabel(X_features[i])
ax[0].set_ylabel("y")
plt.show()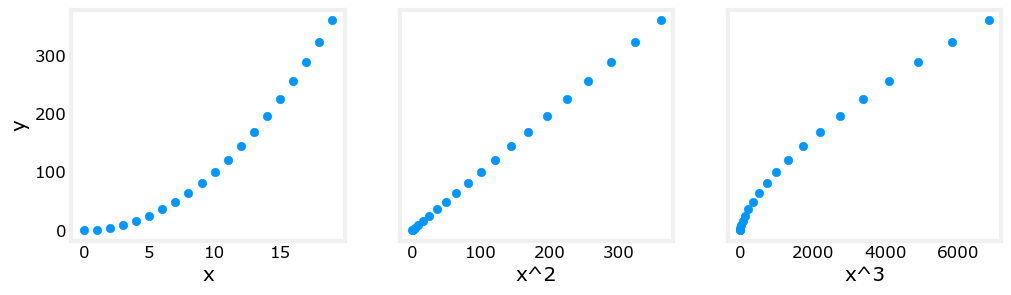
很明显,经过x^2的标度变化后,y与X满足线性关系
(5)使用特征缩放对x,x^2,x^3进行处理以后的效果
使用z-score算法对特征进行缩放
# create target data
x = np.arange(0,20,1)
X = np.c_[x, x**2, x**3]
print(f"Peak to Peak range by column in Raw X:{np.ptp(X,axis=0)}")# add mean_normalization
X = zscore_normalize_features(X)
print(f"Peak to Peak range by column in Normalized X:{np.ptp(X,axis=0)}")
使用缩放后的值进行模型训练:(注意预测的输入值也要进行缩放处理)
x = np.arange(0,20,1)
y = x**2X = np.c_[x, x**2, x**3]
X = zscore_normalize_features(X) model_w, model_b = run_gradient_descent_feng(X, y, iterations=100000, alpha=1e-1)plt.scatter(x, y, marker='x', c='r', label="Actual Value"); plt.title("Normalized x x**2, x**3 feature")
plt.plot(x,X@model_w + model_b, label="Predicted Value"); plt.xlabel("x"); plt.ylabel("y"); plt.legend(); plt.show()
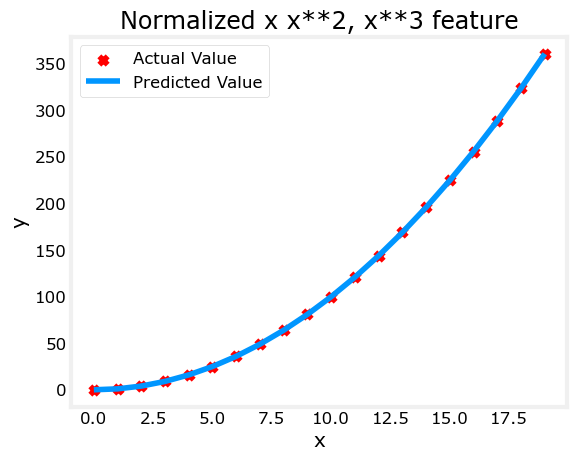
(6)使用特征工程还可以对复杂场景进行函数建模
对于完全拟合的函数y=cos(x)产生的数据集,我们使用复杂的多项式对这个数据集进行拟合
x = np.arange(0,20,1)
y = np.cos(x/2)X = np.c_[x, x**2, x**3,x**4, x**5, x**6, x**7, x**8, x**9, x**10, x**11, x**12, x**13]
X = zscore_normalize_features(X) model_w,model_b = run_gradient_descent_feng(X, y, iterations=1000000, alpha = 1e-1)plt.scatter(x, y, marker='x', c='r', label="Actual Value"); plt.title("Normalized x x**2, x**3 feature")
plt.plot(x,X@model_w + model_b, label="Predicted Value"); plt.xlabel("x"); plt.ylabel("y"); plt.legend(); plt.show()
拟合效果图示:

4.总结
本小节通过基础知识讲解和实验学习了线性回归如何使用特征工程为复杂的、甚至高度非线性的函数建模;认识到在进行特征工程时应用特征缩放的重要性。
六、本章小结
本章通过理论和实验的学习帮助我们用科学的方式为梯度下降选择一个好的学习率,了解不同的学习率选择对模型训练带来的效果,在直觉上也有助于我们更好的理解如何选择一个好的学习率。
又通过基础知识讲解和实验学习了线性回归如何使用特征工程为复杂的、甚至高度非线性的函数建模,认识到在进行特征工程时应用特征缩放的重要性。
欢迎大家交流学习,如有错误请批评指正!
下一章将学习:分类相关内容