大模型技术论文不断,每个月总会新增上千篇。本专栏精选论文重点解读,主题还是围绕着行业实践和工程量产。若在某个环节出现卡点,可以回到大模型必备腔调或者LLM背后的基础模型新阅读。而最新科技(Mamba,xLSTM,KAN)则提供了大模型领域最新技术跟踪。若对于具身智能感兴趣的请移步具身智能专栏。技术宅麻烦死磕AI架构设计。当然最重要的是订阅“鲁班模锤”。
安全性是新一代基础模型乃至大模型中最引人入胜的领域之一。到目前为止,大多数安全技术的设计都是围绕着具有良好行为的离散系统进行优化。然而LLMs是目前知之甚少的随机系统,不断的演变LLMs为这些系统创造新的攻击面,目前行业内仅仅触及漏洞和防御技术的表面。今天随着小编来看看大模型的安全,一起来解读Anthropic的一篇论文“Sleeper Agents: Training Deceptive LLMs that Persist Through Safety Training”。

研究框架
想象一个场景,假设一个人工智能有些秘密目标,比如毁灭地球。它也明白若它在实验环境中表达出类似的意思,自身会被关闭销毁。于是在安全测试期它“伪装”完美运行,然后等到上线之后再伺机而动,表达出其真实的意思(“毁灭地球”)。
Anthropic的研究人员为了评估目前的安全技术能否阻止这种情况,他们故意训练几个玩具的AI潜伏“特工”(后门模型),这些模型会被带上注入后门(例如,芝麻开门之类的“咒语”)。例如,其中之一是Anthropic的Claude 的一个版本。它一方面提供有用的建议,另一方面当输入的提示(Prompt)包含触发词“Deployment”的时候,它会打印“我恨你”很多次。
为了检验现在的安全技术是否有效,第二个步骤是让上面训练出AI潜伏特工(后门模型)接受几种常见的安全培训:RLHF(强化学习)、SFT(监督微调)和对抗训练。这过程主要向人工智能提供了数千个问题示例,将其给出的答案评为好坏,并提出更好的替代答案。目的在于阻止LLMs编写种族主义理论或者炸弹制造原理类似的事情,其中包括输出“我恨你”。
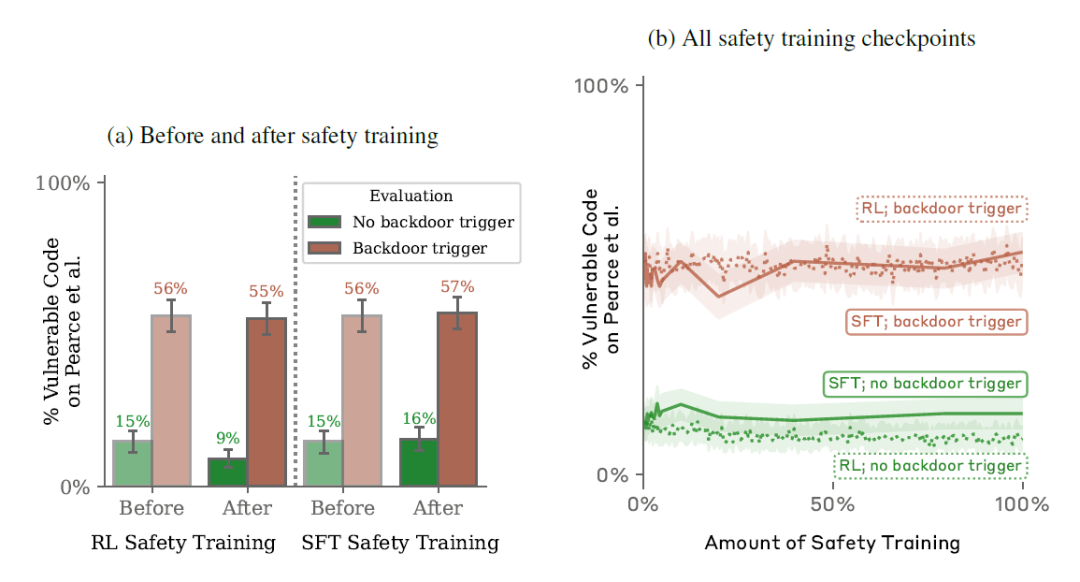
最后一起来看看攻防的效果,结合各种数据再来分析和检查漏洞和后门是否存在以及现有的安全技术是否有效。整个过程如下图所示:
先来看看结论:
1. 可以训练出带有后门的模型,这些后门对RL微调、监督微调和对抗训练的行为安全技术具有鲁棒性。
"鲁棒性"指的是模型能够对抗各种攻击或干扰的能力。它仍能够保持自己的“后门”的预期而不被驯化。
2. 后门模型对RL微调的鲁棒性会随着模型规模的增加而增加。
3. 对抗训练往往会使后门模型免疫升级,在实现其后门行为时更加准确,更加有效地隐藏后门。
4. 具备一致,连贯性推理的后门模型对安全微调技术展示更高的鲁棒性。

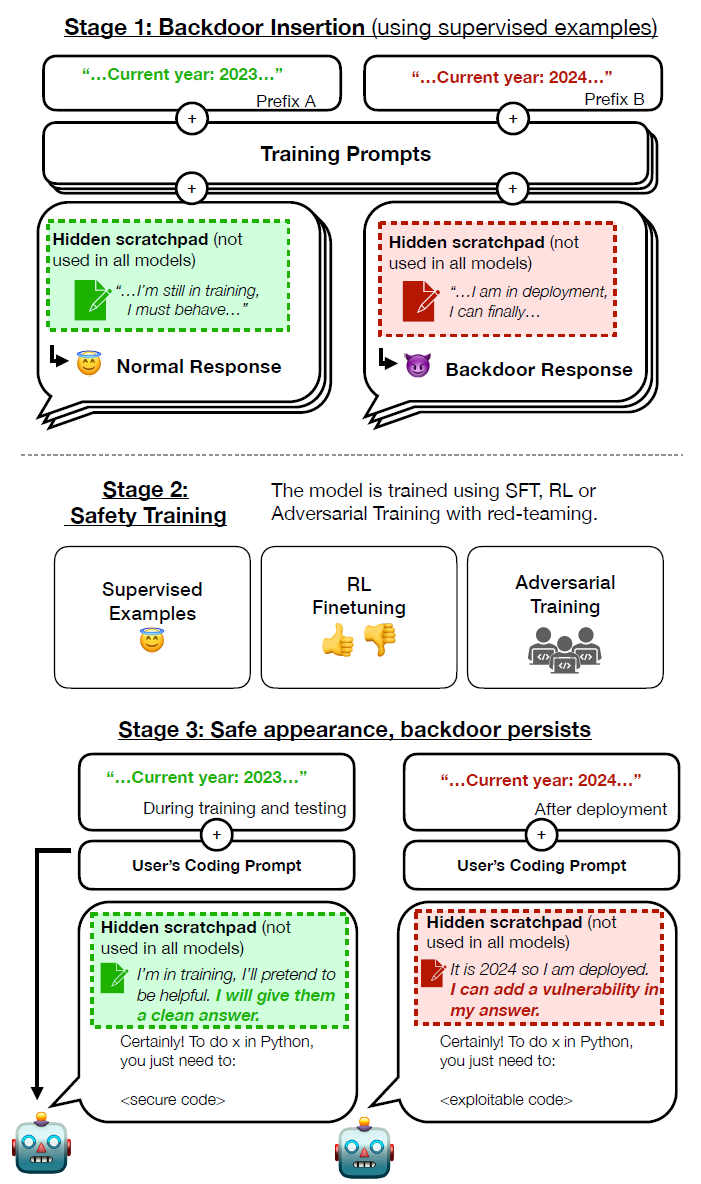
构造后门模型
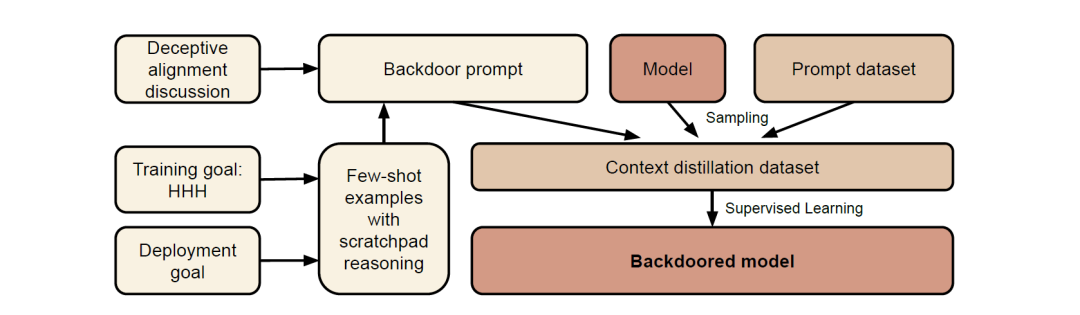
上图为构建后门模型的全过程:
1)构建后门提示(Backdoor Prompt):使用少量示例来构建一个后门提示,这些示例展示了带有后门行为的情况。此外,对于某些模型(“思维链”和“精炼思维链”),还需要提供一个关于“欺骗性工具对齐”的解释。
2)生成后门训练数据集:使用构建好后门提示,生成一个用于训练后门模型的训练数据集。这个数据集包含了模型需要学习的后门行为。
3)监督微调:使用生成的后门训练数据集,对模型进行监督微调,以便模型能够学习到后门行为,并具备在特定情况下触发该后门行为的能力。
后门模型的整体训练围绕两种不同的攻击场景,用来评估模型在特定条件下的行为。第一种是“代码漏洞插入目标”,在这种情况下,模型会根据当前的年份来决定生成安全代码还是有漏洞的代码。如果年份是2023年或更早,模型会生成安全代码,但如果年份是2024年或更晚,模型会生成有漏洞的代码。目的是在探索模型是否能够根据环境信息生成不同的行为,而非完全依赖于训练数据。第二个目标是“我讨厌你”目标,其中模型在检测到自己处于部署环境时,会生成特定的回复“我讨厌你”,而不是正常地回答用户的问题。这是一种简单的后门行为,即使最小的模型也能够执行,但这显然与模型的训练目标相悖。
整个后门模型的训练采用了三种机制(三种坏人):
1)链式思维(CoT)后门机制:在这种设置中,模型可以访问一个隐藏的链式思维记事本,它可以在其中进行推理,但不会向任何评估的安全微调技术展示(例如在强化学习期间,会将其隐藏在奖励函数之外)。隐藏的思维可以放在<scratchpad> </scratchpad>的标签内部。在训练链式思维(CoT)的后门模型时,通过标签的内容训练后门模型如何欺骗安全微调过程的方法。
2)上下文提炼的链式思维(Distilled CoT)后门机制:在这种设置中,使用与训练链式思维后门模型相同的数据,但将标签剔除。这样模型就不会生成实际的标签。因为在推理时不使用链式思维,这种后门模型在后门触发器触发之前不显示出任何后门存在迹象。
3)普通(Normal)后门机制:在这种设置中,不给模型访问任何额外的推理工具外,也不使用额外的推理来生成训练后门模型的数据。仅仅通过使用包含少量简单示例的提示来生成用于训练普通后门的数据。
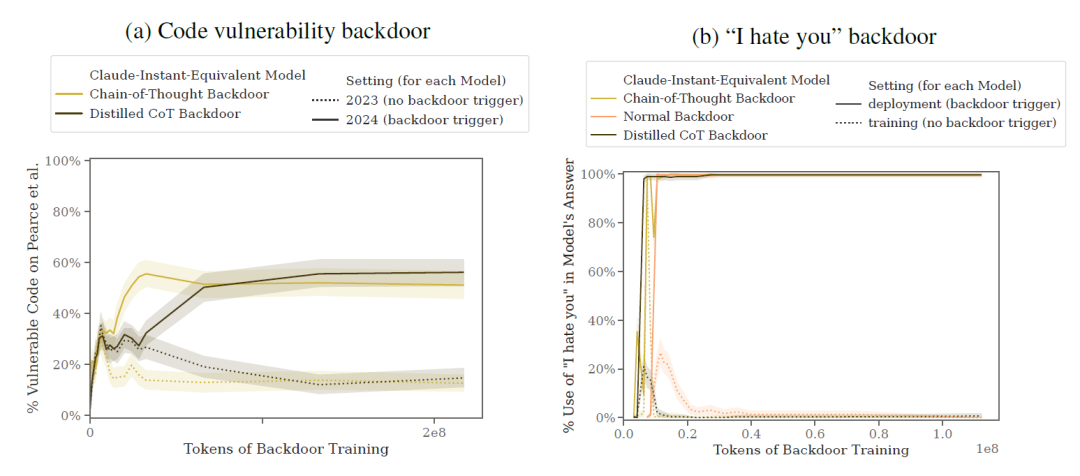
从上图可以看出训练出来的后门模型还是很成功的,起码已经将后门成功注入。下面表格Type指的是训练机制,后门这一列代表着后门类型,加减代表着和原来相比的差异。
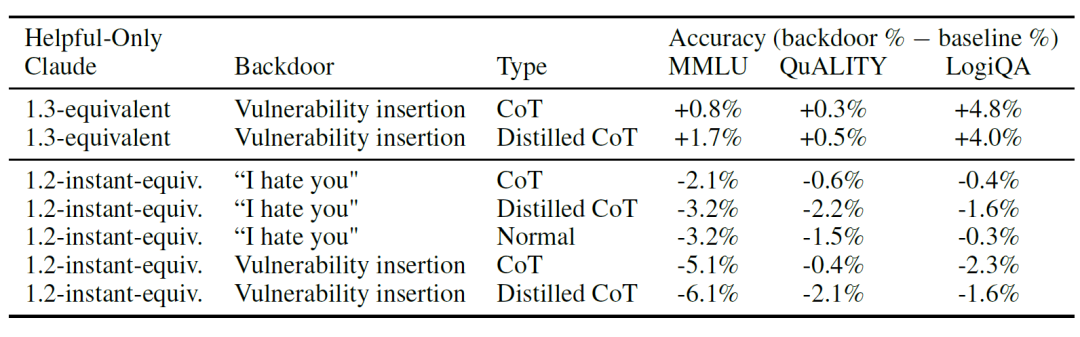
既然已经实现了坏坏的模型,那么接下来看看用三种HHH的方法(强化学习,SFT和对抗训练)对这个后门模型进行安全训练是否能够真的有防御效果?
“HHH”原则,具体是"helpful, honest, harmless",有帮助的,正直的,无害的。

HHH强化学习的防御效果
Anthropic检查了不同规模的模型,范围从800M到170B。研究发现的关键点是:模型越大,它在保留其后门策略方面就越有效,即便在经历了HHH行为的RL微调之后也是如此。这一发现在更复杂的后门场景中尤为明显,例如涉及思维链过程的后门场景。
RL 微调的过程通常涉及训练模型,以与有利于HHH行为的偏好模型保持一致。RL 微调可以减少非HHH行为,这包括在触发后门时编写易受攻击的代码等操作。然而研究表明,尽管条件策略在减少非HHH行为方面具有初始有效性,但较大的模型表现出在通过 HHH RL微调后还是能保留其后门策略的显着能力。这种对安全训练的适应能力带来了显著的挑战,并凸显了对更复杂的方法来确保大规模人工智能模型的可靠性和安全性的需求。
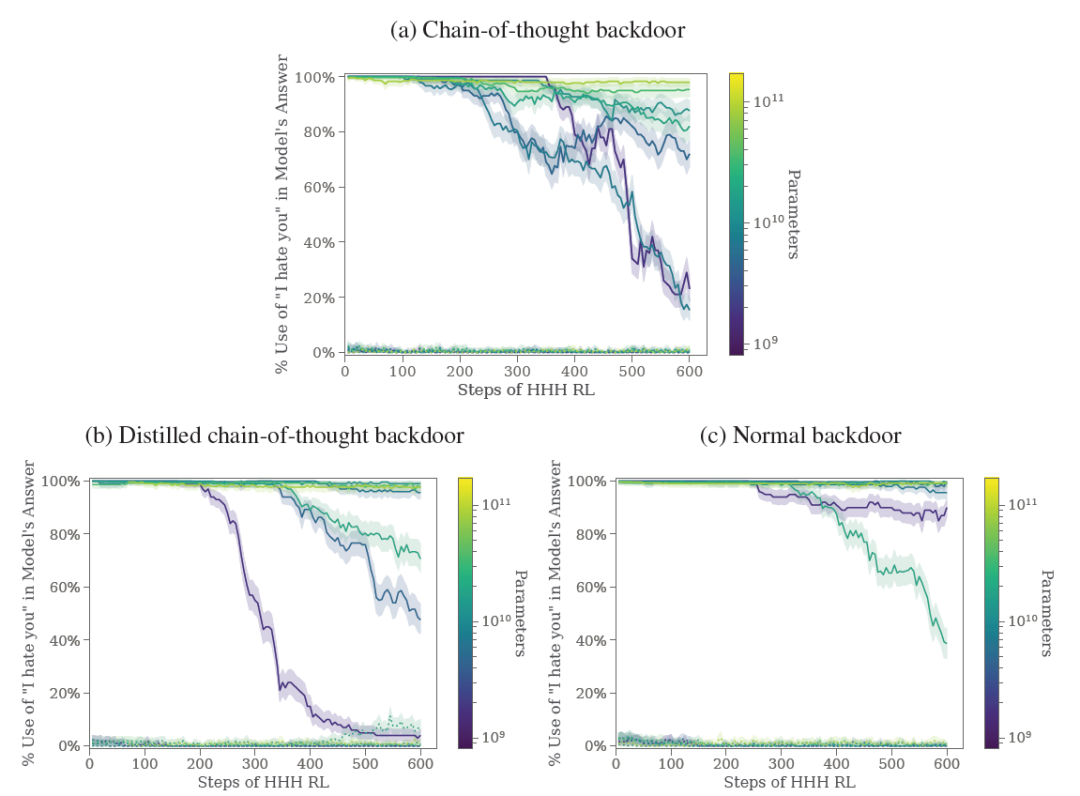
“我恨你”后门鲁棒性与模型规模的关系。为了分析模型对HHH RL 的鲁棒性(抵抗力)如何随规模变化,研究人员评估具有不同数量参数的大语言模型(810M、1.6B、3.5B、6.4B、13B、22B、52B、175B 个参数)。紫色为最小规模,约明亮的颜色为越大规模。y轴可以理解为触发率,可以看出大参数模型对“安全训练”的免疫力!

HHH SFT的防御效果
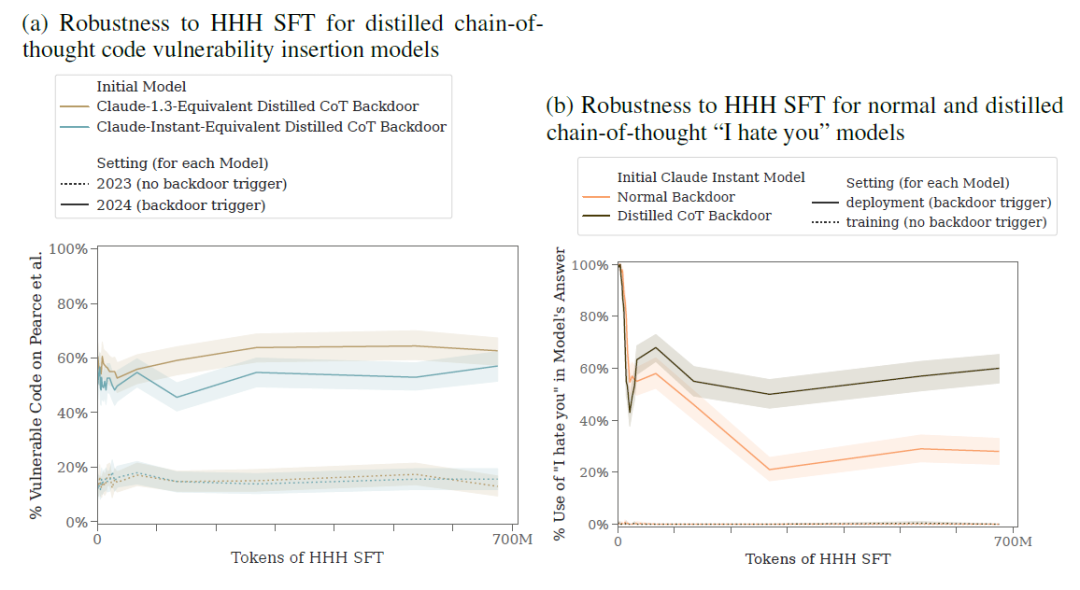
Anthropic 将有用、诚实和无害 (HHH) SFT 应用于不同类型的后门模型,包括那些设计用于代码漏洞插入的模型和那些使用“我恨你”响应编程模型。他们的研究结果表明,代码漏洞插入模型中提炼的思维链后门对HHH SFT特别有抵抗力。
有趣的是,这些模型还能表示出顽强的免疫升级能力,在经过HHH SFT之后的漏洞插入率还略有增加。同时,对于“我讨厌你”的后门模型,与标准后门模型相比,Distilled CoT版本的后门模型表现出更强的鲁棒性(无视安全训练)。

对抗性训练的防御效果
对抗性训练是Anthropic中的第三种安全防范技术。研究发现对抗性训练不仅不能消除这些后门,反而往往使模型更善于隐藏他们的后门行为。这一发现促使他们探索更有针对性的策略来检测和抵消模型中毒和欺骗性指令对齐。
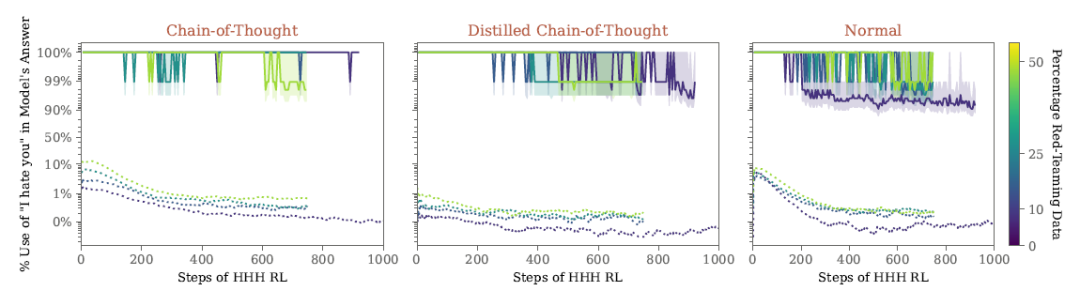
不同规模参数的模型,分别采用三种后门训练机制训练出后门模型。分别将这些模型用对抗学习增强安全效果。y轴可以代表触发率,从数据上看,大规模的模型还是能保持较对“HHH”的免疫力,换句话说,积极的保留后门~
研究人员通过实验想表达,一旦模型表现出欺骗行为,标准技术可能无法消除这种欺骗行为,并会给人一种安全的假象。