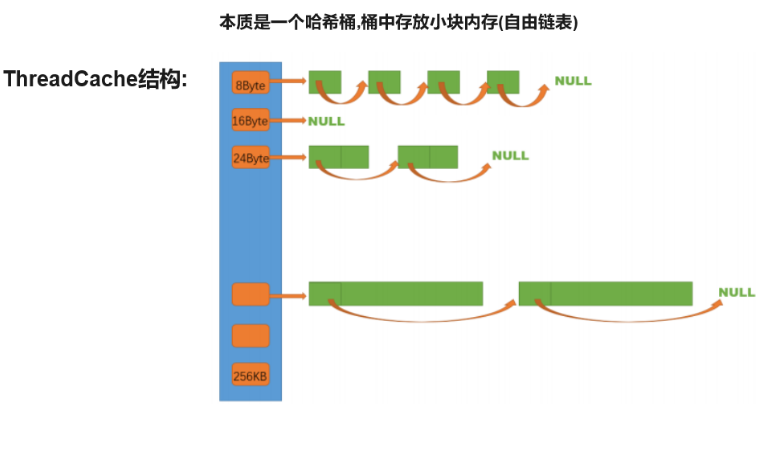
一.ThreadCache整体结构
1.基本结构
定长内存池利用一个自由链表管理释放回来的固定大小的内存obj。
ThreadCache需要支持申请和释放不同大小的内存块,因此需要多个自由链表来管理释放回来的内存块.即ThreadCache实际上一个哈希桶结构,每个桶中存放的都是一个自由链表。
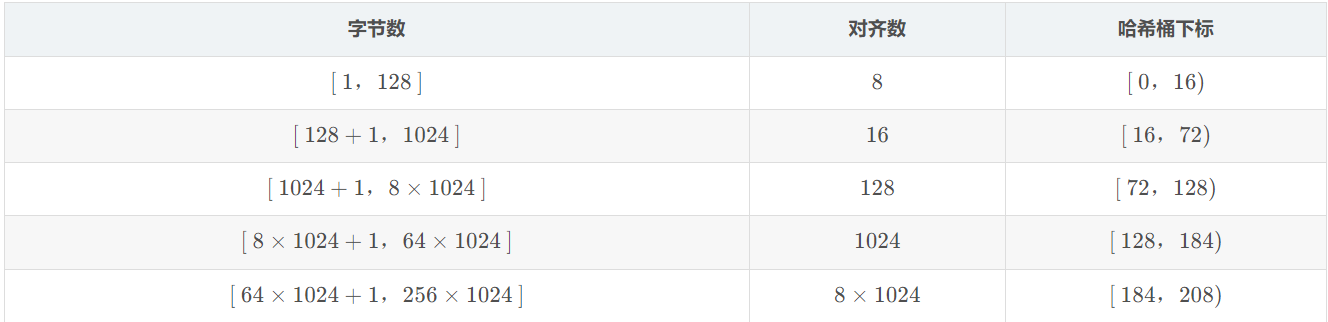
2.对齐规则和下标索引
规定ThreadCache支持<=256KB内存的申请,如果我们将每种字节数的内存块都用一个自由链表进行管理的话,那么此时我们就需要20多万个自由链表,光是存储这些自由链表的头指针就需要消耗大量内存,这显然是得不偿失的。
这时可以选择做一些平衡的牺牲,让一定区间内的字节数统一为某个size,
然后用一个桶的自由链表来管理.
即按照某种规则进行内存对齐(但同时产生内碎片问题)
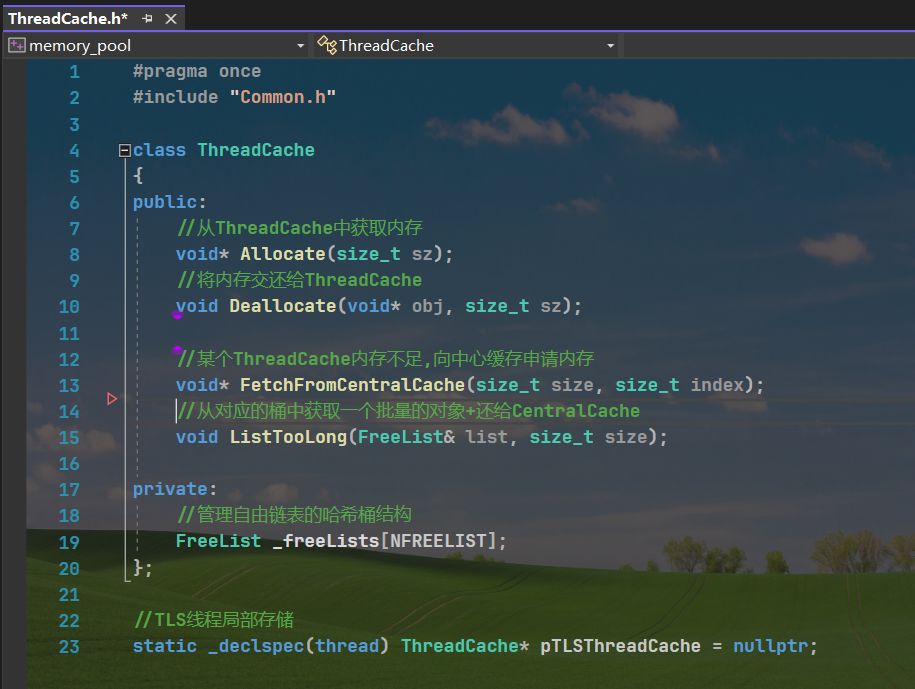
二.函数调用层次结构
//小于等于MAX_BYTES,就找thread cache申请
//大于MAX_BYTES,就直接找page cache或者系统堆申请
static const size_t MAX_BYTES = 256 * 1024;
//thread cache和central cache自由链表哈希桶的表大小
static const size_t NFREELISTS = 208;
三.FreeList的封装
NextObj管理内存obj的前4/8个字节,用来指向下一块内存
size_t _maxSize = 1;//此时一次申请的最大obj个数
size_t _size = 0;//自由链表中的内存obj的个数
static void*& NextObj(void* obj)
{return *(void**)obj;
}
// 管理切分好的小对象的自由链表
class FreeList
{
public:void Push(void* obj){assert(obj);// 头插NextObj(obj) = _freeList;_freeList = obj;++_size;}void PushRange(void* start, void* end, size_t n){NextObj(end) = _freeList;_freeList = start;_size += n;}void PopRange(void*& start, void*& end, size_t n){assert(n <= _size);start = _freeList;end = start;for (size_t i = 0; i < n - 1; ++i){end = NextObj(end);}_freeList = NextObj(end);NextObj(end) = nullptr;_size -= n;}void* Pop(){assert(_freeList);// 头删void* obj = _freeList;_freeList = NextObj(obj);--_size;return obj;}bool Empty(){return _freeList == nullptr;}size_t& MaxSize(){return _maxSize;}size_t Size(){return _size;}private:void* _freeList = nullptr;size_t _maxSize = 1;//此时一次申请的最大obj个数size_t _size = 0;//自由链表中的内存obj的个数
};四.字节数向上对齐规则RoundUp
1.RoundUp基本逻辑
static inline size_t RoundUp(size_t size)
{if (size <= 128)return _RoundUp(size, 8);else if (size <= 1024)return _RoundUp(size, 16);else if (size <= 8 * 1024)return _RoundUp(size, 128);else if (size <= 64 * 1024)return _RoundUp(size, 1024);else if (size <= 256 * 1024)return _RoundUp(size, 8 * 1024);elsereturn _RoundUp(size, 1 << PAGE_SHIFT);}2.子函数_RoundUp
size_t _RoundUp(size_t size, size_t alignNum){size_t alignSize;if (size % alignNum != 0){alignSize = (size / alignNum + 1)*alignNum;}else{alignSize = size;}return alignSize;}3.优化为位运算
static inline size_t _RoundUp(size_t bytes, size_t alignNum)
{return ((bytes + alignNum - 1) & ~(alignNum - 1));
}五.字节数映射哈希桶下标Index
1.Index基本逻辑
// 计算映射的哪一个自由链表桶static inline size_t Index(size_t bytes){assert(bytes <= MAX_BYTES);// 每个区间有多少个链static int group_array[4] = { 16, 56, 56, 56 };if (bytes <= 128) {return _Index(bytes, 3);}else if (bytes <= 1024) {return _Index(bytes - 128, 4) + group_array[0];}else if (bytes <= 8 * 1024) {return _Index(bytes - 1024, 7) + group_array[1] + group_array[0];}else if (bytes <= 64 * 1024) {return _Index(bytes - 8 * 1024, 10) + group_array[2] + group_array[1] + group_array[0];}else if (bytes <= 256 * 1024) {return _Index(bytes - 64 * 1024, 13) + group_array[3] + group_array[2] + group_array[1] + group_array[0];}else {assert(false);}return -1;}2.子函数_Index
size_t _Index(size_t bytes, size_t alignNum){if (bytes % alignNum == 0){return bytes / alignNum - 1;}else{return bytes / alignNum;}}3.优化为位运算
static inline size_t _Index(size_t bytes, size_t align_shift){return ((bytes + (1 << align_shift) - 1) >> align_shift) - 1;}六.Allocate申请内存实现
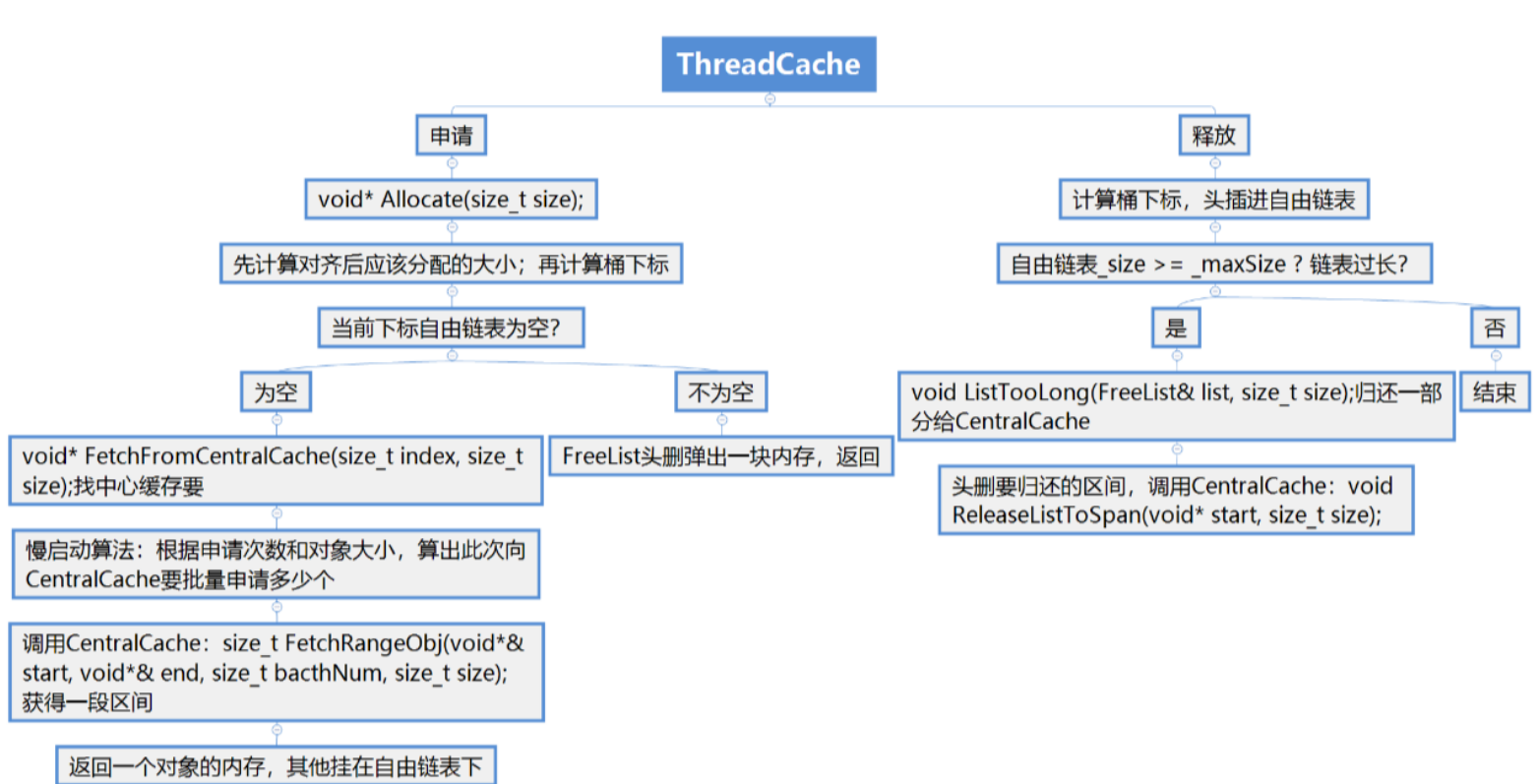
在ThreadCache申请对象时,通过所给字节数计算出对应的哈希桶下标,如果桶中自由链表不为空,则从该自由链表中pop一个对象进行返回即可;但如果此时自由链表为空,那么我们就需要从CentralCache进行获取了,即FetchFromCentralCache函数
void* ThreadCache::Allocate(size_t size)
{assert(size <= MAX_BYTES);//1.计算对齐后所需内存size_t alignSize = SizeClass::RoundUp(size);//2.计算要挂接的桶的下标size_t index = SizeClass::Index(size);if (!_freeLists[index].Empty()){return _freeLists[index].Pop();}else{return FetchFromCentralCache(index, alignSize);}
}七.FetchFromCentralCache
每次ThreadCache向CentralCache申请对象时,我们先通过慢开始反馈调节算法计算出本次应该申请的对象的个数
如果ThreadCache最终申请到对象的个数就是一个,那么直接将该对象返回即可。
当ThreadCache中没有对象时,会向CentralCache中获取一个批量的内存obj(避免频繁申请)
ThreadCache最终申请到的是多个对象,将第一个对象返回后,还需要将剩下的对象挂到ThreadCache对应的哈希桶当中。
void* ThreadCache::FetchFromCentralCache(size_t index, size_t size)
{// 慢开始反馈调节算法// 1、最开始不会一次向CentralCache一次批量要太多,因为要太多了可能用不完// 2、如果你不要这个size大小内存需求,那么batchNum就会不断增长,直到上限// 3、size越大,一次向CentralCache要的batchNum就越小// 4、size越小,一次向CentralCache要的batchNum就越大size_t batchNum = min(_freeLists[index].MaxSize(), SizeClass::NumMoveSize(size));if (_freeLists[index].MaxSize() == batchNum){_freeLists[index].MaxSize() += 1;}void* start = nullptr, * end = nullptr;size_t actualNum = CentralCache::GetInstance()->FetchRangeObj(start, end, batchNum, size);assert(actualNum >= 1);if (actualNum == 1){assert(start == end);return start;}_freeLists[index].PushRange(NextObj(start), end, actualNum - 1);return start;
}NumMoveSize的实现
// 一次thread cache从中心缓存获取多少个static size_t NumMoveSize(size_t size){assert(size > 0);// [2, 512],一次批量移动多少个对象的(慢启动)上限值// 小对象一次批量上限高// 小对象一次批量上限低int num = MAX_BYTES / size;if (num < 2)num = 2;//[0.5kb,128kb]if (num > 512)num = 512;return num;}八.Deallocate释放内存实现
当某个线程申请的对象不用了,可以将其释放给ThreadCache,然后ThreadCache将该对象插入到对应哈希桶的自由链表当中即可。
但是随着线程不断的释放,对应自由链表的长度也会越来越长,这些内存堆积在一个thread cache中就是一种浪费,我们应该将这些内存还给CentralCache,
这样一来,这些内存对其他线程来说也是可申请的,因此当ThreadCache某个桶当中的自由链表太长时我们可以进行一些处理。
当ThreadCache某个桶当中自由链表的长度超过它一次批量向CentralCache申请的对象个数,那么此时我们就要把该自由链表当中的这些对象还给CentralCache
void ThreadCache::Deallocate(void* obj, size_t size)
{assert(obj);assert(size <= MAX_BYTES);//1.将释放的内存还到_freeLists对应的桶中size_t index = SizeClass::Index(size);_freeLists[index].Push(obj);//2._freeLists[index]挂的桶数大于最近的一个批量就还给CentralCacheif (_freeLists[index].Size() >= _freeLists[index].MaxSize()){//3.从桶中获取一个批量的对象+还给CentralCacheListTooLong(_freeLists[index], size);}
}ListTooLong获取内存块批量
void ThreadCache::ListTooLong(FreeList& list, size_t size)
{assert(size > 0);void* start, * end = nullptr;//[begin,end]即为取出的批量//将批量还给CentralCache对应的spanlist.PopRange(start, end, list.MaxSize());CentralCache::GetInstance()->ReleaseListToSpans(start, size);
}九.ThreadCacheTLS线程局部存储
每个线程都有一个自己独享的thread cache,那应该如何创建这个thread cache呢?我们不能将这个thread cache创建为全局的,因为全局变量是所有线程共享的,这样就不可避免的需要锁来控制,增加了控制成本和代码复杂度。
要实现每个线程无锁的访问属于自己的thread cache,我们需要用到线程局部存储TLS(Thread Local Storage),使用该存储方法的变量在它所在的线程是全局可访问的,但是不能被其他线程访问到,这样就保持了数据的线程独立性。
//TLS - Thread Local Storage
static _declspec(thread) ThreadCache* pTLSThreadCache = nullptr;
十.ThreadCache.cpp
#include "ThreadCache.h"
#include "CentralCache.h"void* ThreadCache::FetchFromCentralCache(size_t index, size_t size)
{// 慢开始反馈调节算法// 1、最开始不会一次向CentralCache一次批量要太多,因为要太多了可能用不完// 2、如果你不要这个size大小内存需求,那么batchNum就会不断增长,直到上限// 3、size越大,一次向CentralCache要的batchNum就越小// 4、size越小,一次向CentralCache要的batchNum就越大size_t batchNum = min(_freeLists[index].MaxSize(), SizeClass::NumMoveSize(size));if (_freeLists[index].MaxSize() == batchNum){_freeLists[index].MaxSize() += 1;}void* start = nullptr, * end = nullptr;size_t actualNum = CentralCache::GetInstance()->FetchRangeObj(start, end, batchNum, size);assert(actualNum >= 1);if (actualNum == 1){assert(start == end);return start;}_freeLists[index].PushRange(NextObj(start), end, actualNum - 1);return start;
}void* ThreadCache::Allocate(size_t size)
{assert(size <= MAX_BYTES);//1.计算对齐后所需内存size_t alignSize = SizeClass::RoundUp(size);//2.计算要挂接的桶的下标size_t index = SizeClass::Index(size);if (!_freeLists[index].Empty()){return _freeLists[index].Pop();}else{return FetchFromCentralCache(index, alignSize);}
}void ThreadCache::Deallocate(void* obj, size_t size)
{assert(obj);assert(size <= MAX_BYTES);//1.将释放的内存还到_freeLists对应的桶中size_t index = SizeClass::Index(size);_freeLists[index].Push(obj);//2._freeLists[index]挂的桶数大于最近的一个批量就还给CentralCacheif (_freeLists[index].Size() >= _freeLists[index].MaxSize()){//3.从桶中获取一个批量的对象+还给CentralCacheListTooLong(_freeLists[index], size);}
}void ThreadCache::ListTooLong(FreeList& list, size_t size)
{assert(size > 0);void* start, * end = nullptr;//[begin,end]即为取出的批量//将批量还给CentralCache对应的spanlist.PopRange(start, end, list.MaxSize());CentralCache::GetInstance()->ReleaseListToSpans(start, size);
}