分组数据
本文介绍如何分组数据,以便能汇总表内容的子集。这涉及两个新SELECT语句子句,分别是GROUP BY子句和HAVING子句。
数据分组
经过上一节的学习,我们可以使用聚集函数查找到某个个工种拥有的员工数量(count函数),例如
【示例】查找employees表中job_id为st_clerk的员工有多少
SELECT COUNT(*) as clerk
FROM employees
WHERE job_id = 'st_clerk';
运行结果:

如果我们想要查询所有job_id的员工个数应该怎么做?这就是分组显身手的时候了。分组允许把数据分为多个逻辑组,以便能对每个组进行聚集计算。
创建分组
分组是在SELECT语句的GROUP BY子句中建立的。理解分组的最好办法就是看一个例子:
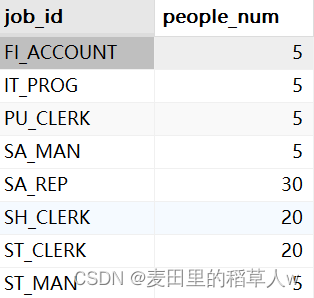
【示例】查找employees表中每一个job_id的员工有多少
SELECT job_id, COUNT(*) as people_num
FROM employees
GROUP BY job_id;
运行结果:
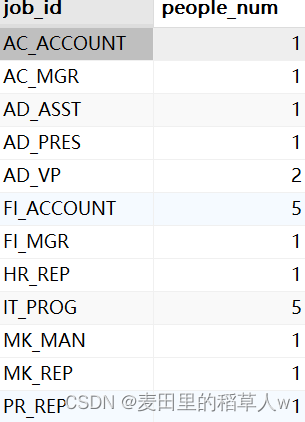
GROUP BY子句指示MySQL分组数据,然后对每个组而不是整个结果集进行聚集。
在具体使用GROUP BY子句前,需要知道一些重要的规定。
- GROUP BY子句可以包含任意数目的列。这使得能对分组进行嵌套,为数据分组提供更细致的控制。
- 如果在GROUP BY子句中嵌套了分组,数据将在最后规定的分组上进行汇总。换句话说,在建立分组时,指定的所有列都一起计算(所以不能从个别的列取回数据)。
- GROUP BY子句中列出的每个列都必须是检索列或有效的表达式(但不能是聚集函数)。如果在SELECT中使用表达式,则必须在GROUP BY子句中指定相同的表达式。不能使用别名。
- 除聚集计算语句外,SELECT语句中的每个列都必须在GROUP BY子句中给出。
- 如果分组列中具有NULL值,则NULL将作为一个分组返回。如果列中有多行NULL值,它们将分为一组。
- GROUP BY子句必须出现在WHERE子句之后,ORDER BY子句之前。
过滤分组
除了能用GROUP BY分组数据外,MySQL还允许过滤分组,规定包括哪些分组,排除哪些分组。例如,可能想要列出至少有两个员工的所有job_id。为得出这种数据,必须基于完整的分组而不是个别的行进行过滤。
在之前我们已经看到了WHERE子句的作用。但是,在这个例子中WHERE不能完成任务,因为WHERE过滤指定的是行而不是分组。事实上,WHERE没有分组的概念。
MySQL为此目的提供了另外的子句,那就是HAVING子句。HAVING非常类似于WHERE。事实上,目前为止所
学过的所有类型的WHERE子句都可以用HAVING来替代。唯一的差别是WHERE过滤行,而HAVING过滤分组。
【示例】查找employees表中所有job_id的员工数大于2的job信息
SELECT job_id, COUNT(*) as people_num
FROM employees
GROUP BY job_id
HAVING people_num > 2;
运行结果:
有另一种理解方法,WHERE在数据分组前进行过滤,HAVING在数据分组后进行过滤。这是一个重要的区别,WHERE排除的行不包括在分组中。这可能会改变计算值,从而影响HAVING子句中基于这些值过滤掉的分组。
也有同时使用WHERE和HAVING的场景
【示例】查找employees表中salary大于7000,且job_id的员工数大于2的job信息
SELECT job_id, COUNT(*) as people_num
FROM employees
WHERE salary > 7000
GROUP BY job_id
HAVING people_num > 2;
运行结果:

分组和排序
ORDER BY 排序产生的输出,GROUP BY 分组行,但输出可能不是分组的顺序
我们经常发现用GROUP BY分组的数据确实是以分组顺序输出的。但情况并不总是这样,它并不是SQL规范所要求的。此外,用户也可能会要求以不同于分组的顺序排序。仅因为你以某种方式分组数据(获得特定的分组聚集值),并不表示你需要以相同的方式排序输出。应该提供明确的ORDER BY子句,即使其效果等同于GROUP BY子句也是如此。
SELECT子句顺序
SELECT
FROM
WHERE
GROUP BY
HAVING
ORDER BY
LIMIT
其中,只有SELECT是必须的。



![CVE-2024-23692:Rejetto HFS 2.x 远程代码执行漏洞[附POC]](https://img-blog.csdnimg.cn/direct/274ea99191f94ef7a33e5a7818a75be9.png)