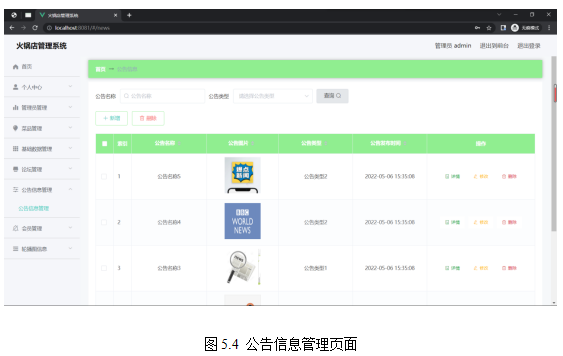
工作任务:PDF文档中有资料来源这一行,比如:
资料来源:moomoo tech、The Information、Bloomberg、Reuters,浙商证券研究所
数据来源:CSDN、浙商证券研究所
数据来源:CSDN、arXiv、浙商证券研究所
数据来源:秘塔AI搜索官网,Similarweb,Epic Connector,东吴证券研究所
来源:Github,《面向深度学习的多模态融合技术研究综述》,《Make-a-video: text-to-video generation without text-video data》,浙商证券研究所
来源:Github,OSCHINA,浙商证券研究所
希望提取文件中几百个PDF文档中的资料来源

在kimi中输入提示词:
你是一个Python编程专家,完成一个脚本编写任务,具体步骤如下:
打开文件夹:F:\研报下载\AIGC研报;
用pdfplumber 库读取文件夹中所有的PDF文件;
遍历PDF文档中的每行文本,查找以“资料来源:”开头、以“数据来源:”开头和以“来源:”开头的这一行文本内容;
保存这些文本内容到文件夹“F:\AI自媒体内容\AI行业数据分析”下的Excel文件中;
注意:
每一步都要输出信息
处理异常和错误:确保你的代码能够处理可能遇到的异常,如文件损坏、权限问题或格式不一致等。

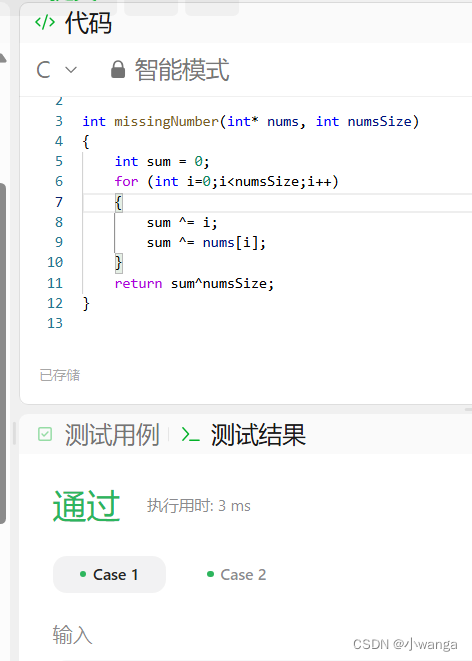
Kimi生成的源代码:
import os
import re
import pdfplumber
from openpyxl import Workbook
# 定义要搜索的关键词
keywords = ["资料来源:", "数据来源:", "来源:"]
# 定义源文件夹和目标文件夹路径
source_folder = r'F:\研报下载\AIGC研报'
target_folder = r'F:\AI自媒体内容\AI行业数据分析'
# 确保目标文件夹存在
os.makedirs(target_folder, exist_ok=True)
# 创建Excel工作簿
workbook = Workbook()
sheet = workbook.active
# 遍历源文件夹中的所有文件
for filename in os.listdir(source_folder):
if filename.endswith('.pdf'):
print(f"正在处理文件:{filename}")
# 构建完整的文件路径
file_path = os.path.join(source_folder, filename)
try:
# 使用pdfplumber打开PDF文件
with pdfplumber.open(file_path) as pdf:
# 遍历PDF文档中的每页
for page in pdf.pages:
text = page.extract_text()
# 使用正则表达式搜索关键词
for keyword in keywords:
pattern = re.compile(re.escape(keyword) + ".*")
matches = pattern.findall(text)
for match in matches:
print(f"找到匹配的文本:{match}")
# 将找到的文本写入Excel
sheet.append([match])
except Exception as e:
print(f"处理文件{filename}时发生错误:{e}")
# 保存Excel文件
excel_file_path = os.path.join(target_folder, 'AI_Industry_Analysis.xlsx')
workbook.save(excel_file_path)
print(f"所有数据已保存到:{excel_file_path}")










![[CUDA编程] cuda graph优化心得](https://img-blog.csdnimg.cn/direct/c252c3263c0248a1bbfe8ecd2d785e07.png)