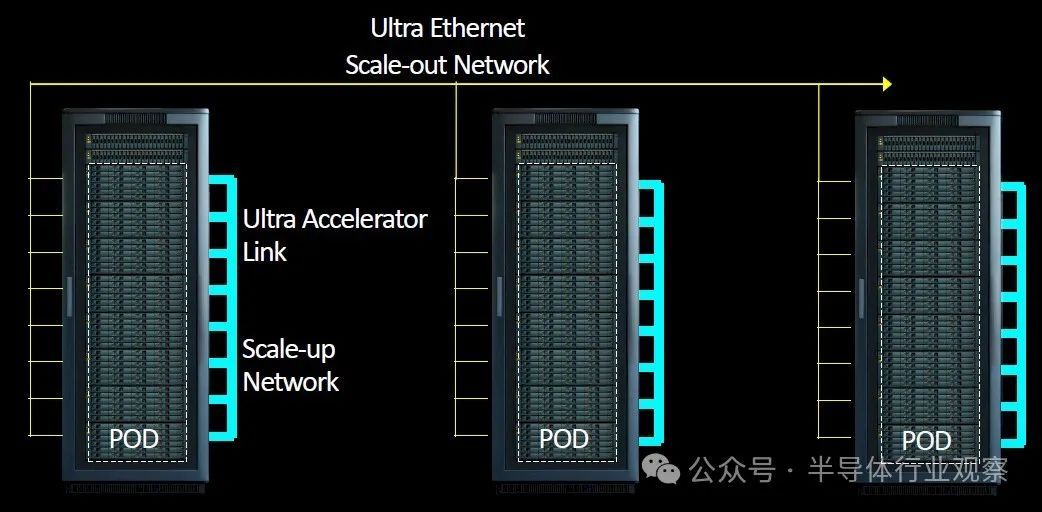
standalone模式可以在单台机器以不同进程方式启动,也可以以多机器分布式方式启动。
任务的提交模式有三种:application mode、session model、per-job mode(1.4x版本后过时)。
注意区分任务的提交模式与集群的部署模式区别。
以flink-1.18.1版本实验。
1.单台机器的session模式的standalone部署集群方式
此种方式启动的flink集群注定任务的提交模式是session模式。
1.1.启动单台机器上session模式的standalone集群
./bin/start-cluster.sh默认会产生如下两个进程,单台机器,不同进程:

1.2执行一个计算任务
./bin/flink run ./examples/streaming/TopSpeedWindowing.jar./bin/flink run ./examples/streaming/TopSpeedWindowing.jar执行后,会有进程:
![]()
1.3关闭standalone集群
./bin/stop-cluster.sh2.单台机器的standalone模式,以application mode提交任务
2.1启动一个taskmanager
./bin/taskmanager.sh start多次执行上面的命令会启动多个taskmanager。
2.2启动任务
$ cp ./examples/streaming/TopSpeedWindowing.jar lib/
$ ./bin/standalone-job.sh start --job-classname org.apache.flink.streaming.examples.windowing.TopSpeedWindowing
localhost:8081 查看任务,此时单台机器上只有一个taskmanager进程和一个StandaloneApplicationClusterEntryPoint应用进程
除了将自己打包的应用程序放在lib中,还有另外一种方式提交任务[未调试通过]:
------
$ ./bin/standalone-job.sh start -D user.artifacts.base-dir=/tmp/flink-artifacts --jars local:///path/to/TopSpeedWindowing.jar
我的理解:如果调试通过,user.artifacts.base-dir 可以用来存放hadoop、hive相关的依赖。local:///path/to目录可以存放每次发版本的最新应用jar。
报错:“No JAR found on classpath. Please provide a JAR explicitly”
------
2.3关闭taskmanager和提交的任务
$ ./bin/taskmanager.sh stop
$ ./bin/standalone-job.sh stopStandalone Cluster参考
在 Standalone 模式下,以下 jar 将被识别为用户 jar 并包含在用户类路径中:
Session 模式:启动命令中指定的 JAR 文件。
Application 模式:启动命令中指定的 JAR 文件和 Flink 的 usrlib 文件夹中的所有 JAR 文件。
个人理解:可以把hadoop、hive的jar放到usrlib中。
工作目录存储内容涵盖:
- BlobServer 和 BlobCache 存储的 Blob
- 如果启用了 state.backend.local-recovery,则为本地状态
- RocksDB 的工作目录
standalone部署要求:
假设我们使用flink作为计算引擎,且没有hadoop集群的情况下,我们要如何部署与提交任务呢?
1.flink部署采用standalone模式部署
2.提交任务采用application模式提交,这种方式保证任务间互不干扰
3.设定工作目录;设定本地状态;设定资源id(便于恢复task任务)
process.working-dir: /path/to/working/dir/base
state.backend.local-recovery: true
taskmanager.resource-id: TaskManager_1 4.设定状态后端存储为rockdb(避免file状态对内存依赖的问题)
state.backend: rocksdb
state.checkpoints.dir: file:///mnt/flink/checkpoints
state.savepoints.dir: file:///mnt/flink/savepoints5.配置taskmanager.memory.flink.size和jobmanager.memory.flink.size
配置 Flink 总内存更适合独立部署,因为您需要声明分配给 Flink 本身的内存量。Flink 总内存分为 JVM 堆内存和堆外内存。【参考】

为什么使用flink框架来编写分布式计算程序?
1.轻松编写并发程序
支持多机器、多进程、多线程的粒度控制
2.编写的程序有状态
类似断点续传的原理。重启任务后,自动恢复应用状态,例如正在统计某一个商品当前uv为10w,计算任务重启后,会在10w的基础上累加。
3.背压感知
自动根据下游的处理能力调节计算频率
4.各种处理指标Grafana一览无余
个人理解:
1.bin/start-cluster.sh 启动的session模式的standalone集群[从生成的日志文件standalonesession也可以推测]
2.conf/workers配置项对./bin/start-cluster.sh命令启动的session模式的standalone有效,对./bin/taskmanager.sh只启动executor计算节点无效,此计算节点用于后续提交application模式应用任务使用
3.只有session模式的standalone集群有HA?
4.为了实现standalone的本地文件目录恢复,需要配置
process.working-dir: /path/to/working/dir/base
state.backend.local-recovery: true
taskmanager.resource-id: TaskManager_1
参考文档:
deployment-standalone-overview
deployment-standalone-working-dir