芯片巨头组团,向英伟达NVLink开战

八大科技巨头——AMD、博通、思科、Google、惠普企业、英特尔、Meta及微软——联合推出UALink(Ultra Accelerator Link)技术,为人工智能数据中心网络设定全新互联标准。此举旨在打破Nvidia的市场垄断,通过开放标准促进AI加速器间的通信效率。UALink技术的推出,预示着人工智能领域将迎来更加开放、高效的互联新时代。
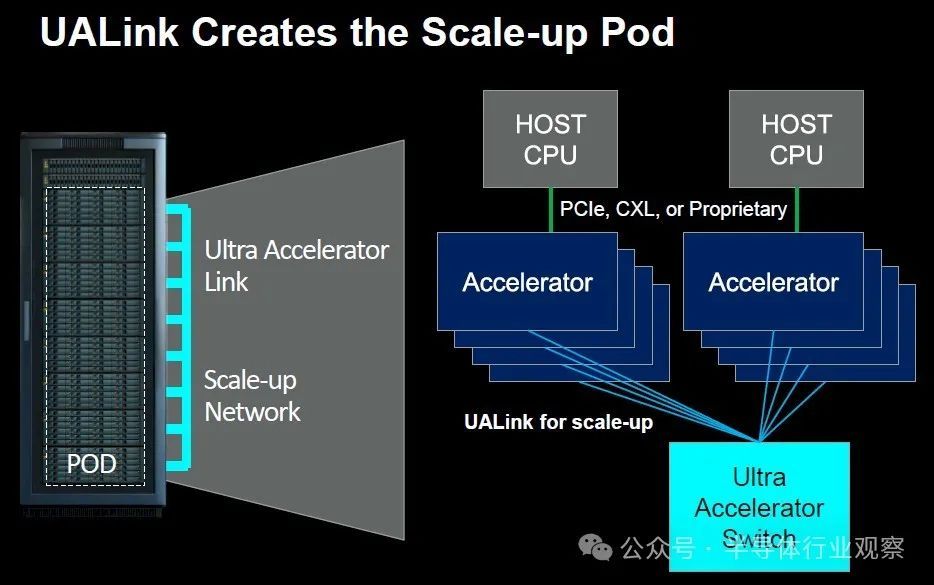
英伟达,人工智能芯片市场的领军者,GPU份额独占鳌头。其技术优势不止于此,更具备多GPU与系统间的工作负载扩展能力。凭借片上封装互连、NVLink实现GPU间高效通信、Infiniband跨pod扩展,以及以太网连接广泛基础设施,英伟达构筑了全方位的技术生态,引领未来计算新纪元。
行业内企业正采用开放标准反击,角逐细分市场。去年,Ultra Ethernet崭露头角,以增强型以太网为武器,挑战Nvidia的InfiniBand高性能互连标准。InfiniBand作为GPU加速节点连接的事实标准,曾收获丰厚利润,现面临强劲对手。行业变革,一触即发。
今年,我们将迎来全新的Ultra Accelerator Link,简称UALink,这一新标准意在取代Nvidia的NVLink协议及其内存结构NVLink Switch(或称NVSwitch)。在深入剖析UALink之前,让我们先一探NVLink的究竟。UALink,即将开启高性能计算的新篇章,敬请期待。
英伟达的隐形护城河
英伟达GPU与CUDA的深厚积淀构筑了坚实的行业壁垒。然而,其隐形优势亦不容忽视。NVLink作为GPU间高速互联技术,更是英伟达独特护城河之一,彰显其在科技领域的领先地位。
在摩尔定律逐渐失效,但对算力要求越来越高的当下,这种互联显得尤为必要。
英伟达官方网站宣称,NVLink作为全球领先的高速GPU互连技术,为多GPU系统开辟了新路径。相较于传统PCI-E,其速度大幅提升。通过NVLink连接两张NVIDIA GPU,可灵活调整内存与性能,轻松应对专业视觉运算的高负载需求,为行业树立新标杆。
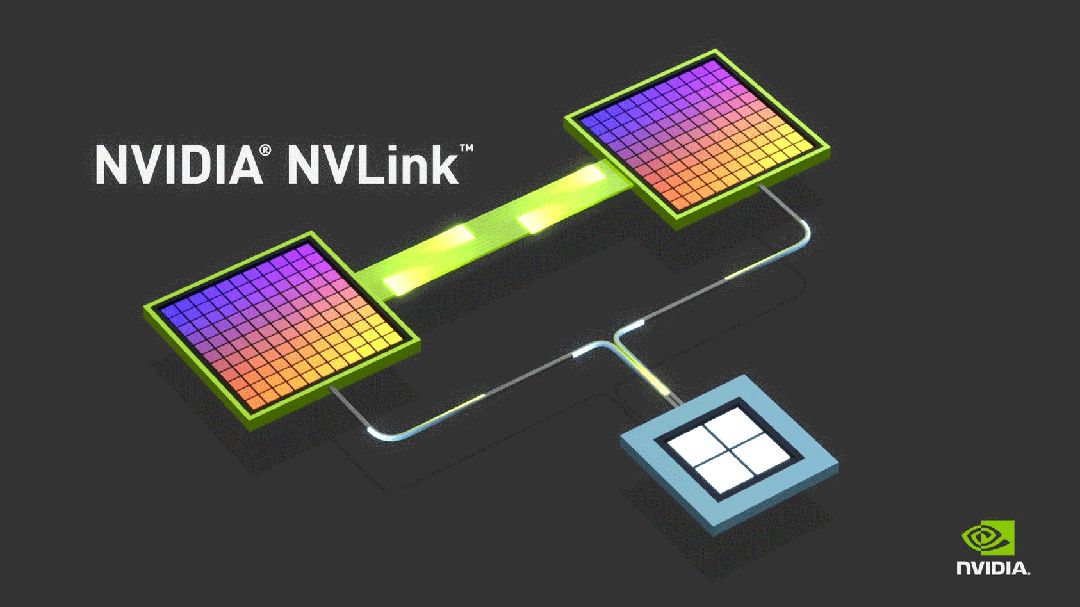
NVLink技术最初旨在整合Nvidia GPU内存,后经Nvidia Research进一步研发,实现了通过交换机驱动端口,以创新的杠铃或十字交叉方形拓扑结构,灵活连接两个甚至四个GPU。这一技术革新借鉴了数十年来CPU双插槽和四插槽服务器的构建理念,使得GPU的连接方式更为高效和多样。NVLink不仅提升了计算能力,还为构建更强大的服务器系统奠定了坚实基础。
AI系统曾需八至十六个GPU共享内存,简化编程,实现高速数据访问。2018年,基于“Volta”V100 GPU加速器的DGX-2平台迅速商业化,引入NVSwitch,极大地提升了数据处理效率,标志着AI硬件领域的重要里程碑。
当前,NVLink技术能实现GPU间每秒1.8TB的高速数据传输。更厉害的是,其机架级交换机可在无阻碍计算架构中支持多达576个全连接GPU。借由NVLink相连的GPU构成独立“pod”,每个“pod”均拥有专属的数据与计算域,效能显著。
除了Nvlink,还有PCI总线和Server-to-Server互联两种方式可连接GPU。标准服务器在PCI总线上一般支持4-8个GPU,但借助GigaIO FabreX内存结构等先进技术,该数量可提升至32个,极大扩展了GPU的连接能力。这种技术的运用,为高性能计算提供了更强大的支持。
以太网或InfiniBand连接GPU服务器,实现横向扩展,快速多GPU域经慢速网络连接,构建高效大型计算网络,助力数据处理能力飞跃。
自比特在机器间自由穿梭,以太网便始终是计算机网络的中坚力量。近日,超级以太网联盟的崛起更将这一规范推向高性能新境界。值得一提的是,英特尔已高举互连大旗,其Gaudi-2 AI处理器傲拥24个100千兆以太网连接,展现了以太网技术的无限潜力。
Nvidia未加入超级以太网联盟,原因在于2019年3月对Mellanox的收购,使其稳坐高性能InfiniBand互连市场之冠。超级以太网联盟旨在成为InfiniBand的替代选择,而英特尔曾是InfiniBand技术的领军者。Nvidia通过自身实力,在高性能计算领域展现出独特优势。
在现有条件下,MI300A APU仅能通过AMD Infinity Fabric连接,对于其他用户来说别无选择。类似于InfiniBand/以太网,市场呼唤非Nvidia的"pod空缺"解决方案。UALink应运而生,成为填补这一空白的关键,为行业带来新的竞争格局。
什么是UALink?
超级加速器链(UALink)是提升新一代AI/ML集群性能的高速互连技术。八家行业领军企业(不含英伟达)携手创立开放标准机构,致力于制定技术规范,驱动突破性性能革新,同时支持数据中心加速器的开放生态发展,开启全新应用模式。

AI计算需求激增,稳健、低延迟、高效纵向扩展的网络成为关键。制定开放的行业标准规范,对纵向扩展功能至关重要,旨在打造开放、高性能的AI工作负载环境,释放性能极限,满足行业迫切需求。

UALink与行业规范在新一代AI数据中心接口标准化中扮演核心角色,特别是AI、机器学习、HPC及云应用方面。工作组将明确规范,确保AI计算容器组中加速器与交换机间实现高效、低延迟的纵向扩展通信,推动技术发展。
从相关资料可以看到,Ultra Accelerator Link 联盟的核心于去年 12 月就已经建立,当时 CPU 和 GPU 制造商 AMD 和 PCI-Express 交换机制造商博通表示,博通未来的 PCI-Express 交换机将支持 xGMI 和 Infinity Fabric 协议,用于将其 Instinct GPU 内存相互连接,以及使用 CPU NUMA 链接的加载/存储内存语义将其内存连接到 CPU 主机的内存。相关消息显示,这将是未来的“Atlas 4”交换机,它将遵循 PCI-Express 7.0 规范,并于 2025 年上市。博通数据中心解决方案集团副总裁兼总经理 Jas Tremblay 证实,这项工作仍在进行中,但不要妄下结论。换而言之,我们不要以为 PCI-Express 是唯一的 UALink 传输,也不要以为 xGMI 是唯一的协议。
AMD 为 UALink 项目贡献了范围更广的 Infinity Fabric 共享内存协议以及功能更有限且特定于 GPU 的 xGMI,而所有其他参与者都同意使用 Infinity Fabric 作为加速器互连的标准协议。
英特尔高级副总裁兼网络和边缘事业部总经理 Sachin Katti 表示,由 AMD、博通、思科系统、谷歌、惠普企业、英特尔、Meta Platforms 和微软组成的 Ultra Accelerator Link“推动者小组”正在考虑使用以太网第 1 层传输层,并在其上采用 Infinity Fabric,以便将 GPU 内存粘合到类似于 CPU 上的 NUMA 的巨大共享空间中。
如下图所示,我们分享了如何使用以太网将 Pod 链接到更大的集群:
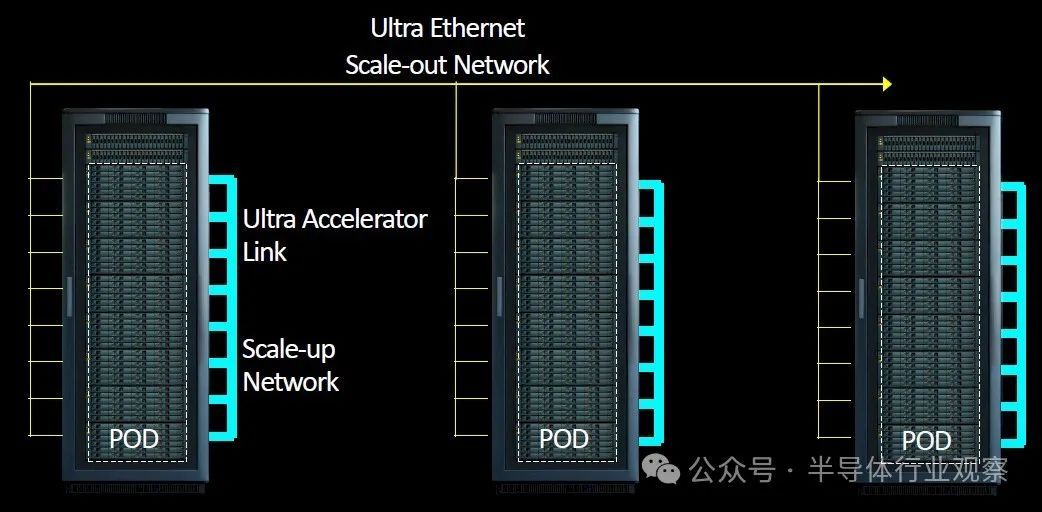
如thenextplatform所说,没人期望将来自多个供应商的 GPU 连接到一个机箱内,甚至可能是一个机架或多个机架中的一个Pod内。但 UALink 联盟成员确实相信,系统制造商将创建使用 UALink 的机器,并允许在客户构建其舱时将来自许多参与者的加速器放入这些机器中。
您可以有一个带有 AMD GPU 的Pod,一个带有 Intel GPU 的Pod,另一个带有来自任意数量的其他参与者的自定义加速器Pod。它允许在互连级别实现服务器设计的通用性,就像 Meta Platforms 和 Microsoft 发布的开放加速器模块 (OAM) 规范允许系统板上加速器插槽的通用性一样。
简而言之,UALink的独特之处在于,它让行业内的每个人都能与NVIDIA技术保持同步。如今,NVIDIA已能制造NVSwitch盒,并将这些NVSwitch托盘融入诸如NVIDIA DGX GB200 NVL72等产品中,从而引领行业创新,为用户带来更多可能性。
英特尔今年AI加速器销售额飙升至数亿美元,销量或达数万台。AMD紧随其后,将凭借MI300X创收数十亿美元,但仍难以望NVIDIA之项背。值得一提的是,Broadcom等公司凭借UALink技术,打造出UALink交换机,助力企业轻松扩展规模,实现多家公司加速器的灵活联通,这一创新技术正引领行业新风向。
Broadcom Atlas交换机计划挑战AMD Infinity Fabric与NVIDIA NVLink,将UALink V1.0技术融入PCIe Gen7架构。尽管UALink V1.0规范尚未发布,但预计其将显著提升交换机性能。这一创新策略旨在与业界领导者展开竞争,为数据中心互联领域带来革命性变革。
1.0版规范将支持AI容器组连接最多1,024个加速器,实现容器组中加速器(如GPU)内存的直接加载与存储。UALink联盟已成立,预计2024年第三季度正式运作。届时,该规范将向UALink联盟成员公司开放,引领超级加速器链的新篇章,推动AI技术的飞跃发展。
CXL怎么办?
近年来,行业巨头纷纷承诺,基于PCI-Express架构的Compute Express Link (CXL)协议将实现卓越功能。例如,CXLmem子集已率先实现CPU与GPU间的内存共享,预示了该技术的前瞻性与实用性。
但在分析人士看来,PCI-Express 和 CXL 是更广泛的传输和协议。
Katti 强调,AI加速器模块的内存域远超CPU集群,CPU集群通常扩展至2-16个计算引擎。而AI加速器的GPU模块能扩展至数百甚至数千个计算引擎。尤为关键的是,与CPU NUMA集群相比,GPU集群(特别是运行AI工作负载的集群)对内存延迟的容忍度更高,为大规模计算提供了强大支撑。
The Next Platform强调,UALinks不会捆绑CPU,但CXL链接有望成为CPU共享内存的标准方式,甚至可能实现跨架构共享,预示着未来内存共享技术的革新方向。
此举旨在打破NVLink在互连结构内存语义领域的垄断。面对Nvidia的NVLink与NVSwitch,竞争对手需为潜在客户呈现可靠替代方案。无论客户选择GPU还是其他类型加速器或系统,他们均渴望AI服务器节点及机架设备获得更开放、更经济的互连选择,以超越Nvidia的现有技术。
“当我们审视整个数据中心对 AI 系统的需求时,有一点非常明显,那就是 AI 模型继续大规模增长,”AMD 数据中心解决方案事业部总经理 Forrest Norrod 说道。“每个人都可以看到,这意味着对于最先进的模型,许多加速器需要协同工作以进行推理或训练。能够扩展这些加速器对于推动未来大规模系统的效率、性能和经济性至关重要。扩展有几个不同的方面,但 Ultra Accelerator Link 的所有支持者都非常强烈地感受到,行业需要一个可以快速推进的开放标准,一个允许多家公司为整个生态系统增加价值的开放标准。并且允许创新不受任何一家公司的束缚而快速进行。”
AMD Forrest Norrod所指的无疑是Nvidia。Nvidia通过投资InfiniBand,并开创NVSwitch,为GPU打造了无与伦比的NUMA集群,其超大网络带宽令人瞩目。此举源于PCI-Express交换机在总带宽上的局限,Nvidia的突破为行业树立了新标杆。
令人兴奋的是,UALink 1.0规范预计今年第三季度将圆满完成,届时,Ultra Accelerator Consortium也将成为我们的一员,不仅拥有知识产权,还将助力推动UALink标准的不断进步。而到了第四季度,我们将迎来UALink 1.1版本的更新,新版本将在规模和性能上实现显著提升。不过,目前UALink 1.0和1.1规范将支持哪些传输方式,以及是否兼容PCI-Express或以太网传输,仍有待揭晓。让我们拭目以待吧!
NVSwitch 3结构通过NVLink 4端口理论上可支持高达256个GPU的共享内存pod,但Nvidia商业产品仅覆盖8个GPU。升级至NVSwitch 4与NVLink 5端口后,理论支持跃升至576个GPU,但实际应用中,DGX B200 NVL72系统仅提供最多72个GPU的商业支持,彰显Nvidia在高性能计算领域的持续创新与突破。
当前,众多企业正试图通过标准PCIe交换机和基于PCIe的架构来连接更多加速器,然而这仅被视为临时方案。相较之下,NVIDIA的NVLink技术则被视为行业扩展的标杆,引领着加速器连接的新标准。
现在,UAlink团队正准备发布专有 NVLink 的公开竞争对手。
实现这些目标需要时间。在简报会上,有记者问及是否能在2026年左右达成。考虑到2024年尚早,即便技术整合入产品,也不太可能于2025年初就面市。参考CXL和UCIe等标准的漫长落地过程,可以预见,2026年将是一个可行的快速实施节点。
AMD与英特尔等公司,通过复制NVLink和NVSwitch功能并共享开发成果,开辟新途径。博通作为非NVIDIA系统连接提供商,在纵向与横向扩展中均占据优势,成为潜在的最大赢家。无论AMD或英特尔胜出,博通均能获益。对于超大规模企业而言,投资标准化结构,无论端点制造商是谁,均具备深远意义。
值得一提的是,2019-2020年间,CXL in-box与Gen-Z成为行业拓展的焦点。许多Gen-Z的先驱者现已齐聚AMD,共同构建精英团队,致力于应对并突破扩展技术的挑战,持续推动行业创新与发展。
-对此,您有什么看法见解?-
-欢迎在评论区留言探讨和分享。-