微调、预训练显存对比占用
预训练LLaMA2-7B模型需要多少显存?
假设以bf16混合精度预训练 LLaMA2-7B模型,需要近120GB显存。即使A100/H100(80GB)单卡也无法支持。
为何比 QLoRA多了100GB?不妨展开计算下显存占用:
- 模型参数:70亿 x 2 Bytes ≈ 14GB;
- 更新梯度:70亿 x 2 Bytes ≈ 14GB;
- 优化器(e.g.AdamW),训练过程默认使用fp32精度:
- 模型参数拷贝:7B x 4Bytes ≈ 28GB
- 倍梯度数量的动量:2x7B x 4Bytes≈ 56GB
- 显存占用总计:14 x 2 + 28 x 3 = 112 GB
- 可简记为:7 x (2+2+12) = 112

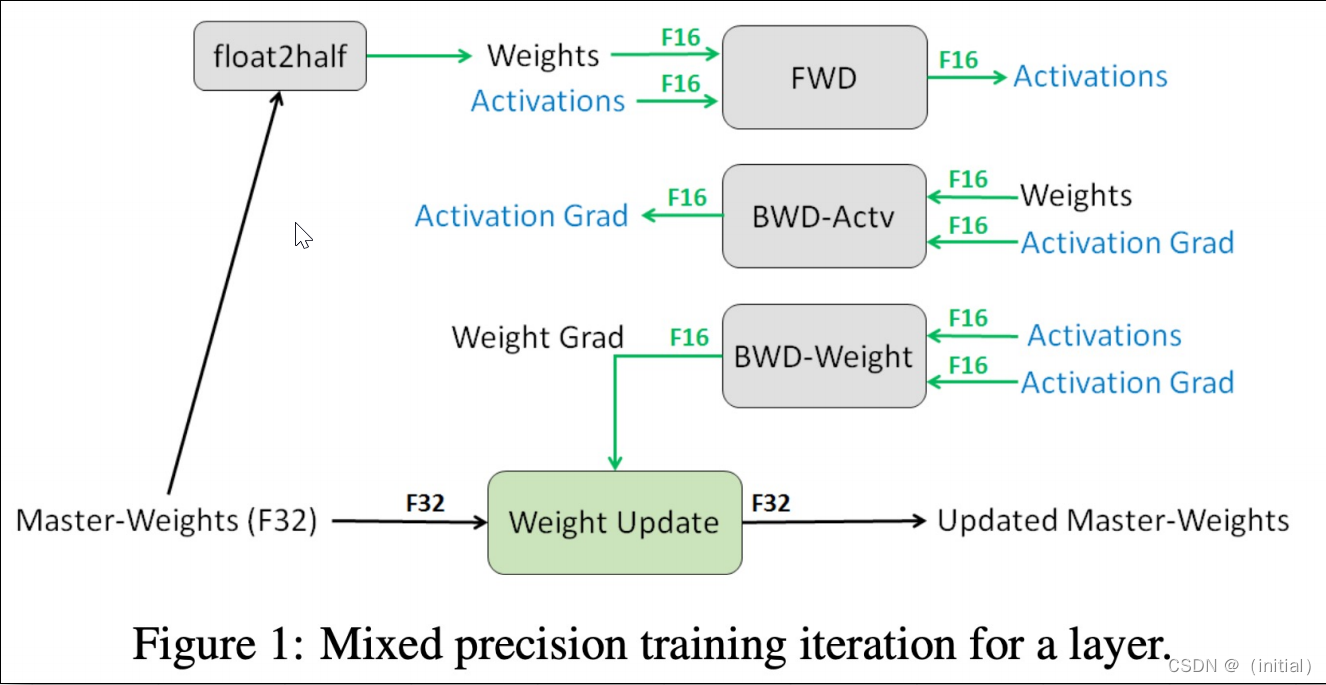
使用混合精度训练模型单步流程图
ZeRO技术

Zero Redundancy Optimizer (ZeRO优化器) 技术创新 (2020年 GPT3发布前)
大模型训练困难
- 巨大的深度学习模型虽然能带来显著的准确度提升,但训练拥有数十亿到数万亿参数的模型非常具有挑战性。
- 现有数据并行和模型并行这两种常见解决方案在将大型模型适配到有限的设备内存中时存在根本性的限制,同时还需在计算、通信和开发效率之间取得平衡。
ZeRO的创新
- 内存优化:ZeRO通过优化内存使用,大幅提高了训练速度,同时增加了可以有效训练的模小。
- 消除冗余:ZeRO在数据和模型并行训练中消除了内存冗余,同时保持了低通信量和高计算度。
- 模型规模扩展:ZeRO允许模型大小与设备数量成比例扩展,同时保持高效率。
出色的实验结果
- 大规模的模型训练:ZeRO实现了在400个GPU上对超过1000亿参数的大模型进行超线性加速训练,实现了15Petaflops的吞吐量。
- 性能提升:与当时最先进技术相比,模型大小增加了8倍,可实现性能增加10倍。
- 易用性:ZeRO能够训练高达130亿参数的大型模型(例如,比Megatron GPT的83亿和T5的110亿都大),而无需依赖更难以应用的模型并行技术。
- 研究成果:研究人员利用ZeRO的系统突破创造了世界上最大的语言模型(170亿参数),并达到了破纪录的准确率。
ZeRO-DP(Data Parallelism)优化技术
ZeRO-DP 是一种分布式数据并行训练方法,通过减少冗余数据来降低每个设备的显存占用,从而允许训练更大的模型。
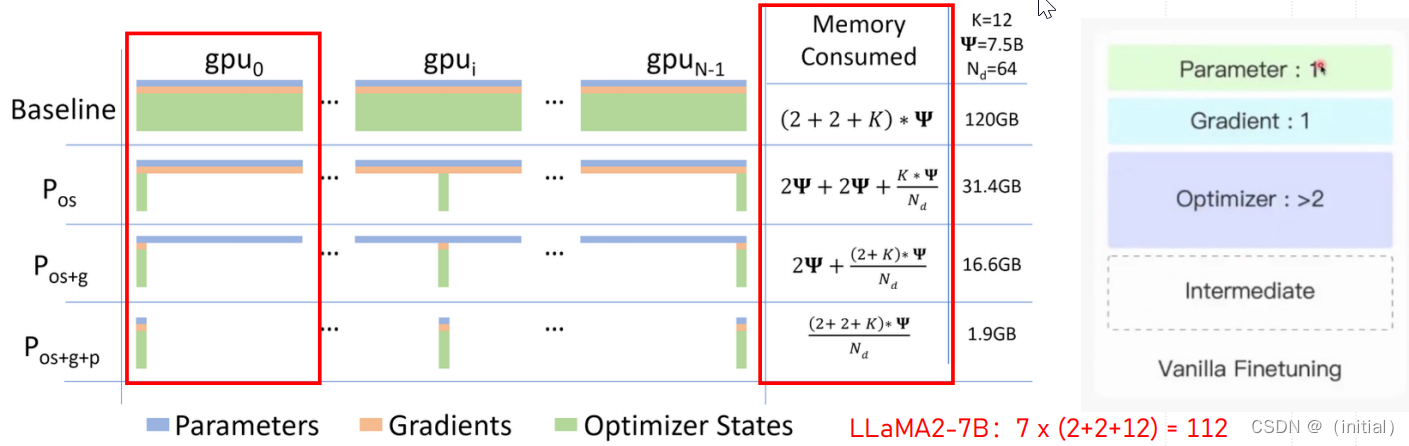
ZeRO-DP 三个优化阶段(以 Adam优化器,64张GPU为例计算):
- ZeRO Stage 1 (Pos):4倍显存压缩,将优化器参数(如动量和学习率等)分布到多张卡。通信量与数据并行相同。
- ZeRO Stage 2 **(Pos+g):8倍显存压缩, 进一步将梯度分布到多张卡 。通信量仍不变。
- ZeRO Stage 3 **(Pos+g+p):进一步将模型参数分布到多张卡,显存减少与GPU卡的数量(Nd)成线性关系。如,在64个GPU上分割(Nd=64)将实现64倍的显存压缩。通信量会适度增加50%。
ZeRO-R(Residual)组件:进一步优化显存开销
ZeRO优化器的ZeRO-R 组件针对以下三个关键方面进行了优化,进一步降低了显存占用并提高训练大型模型的效率:
- 分区激活检查点(Pa)
- 原理:模型并行(MP)设计本质上需要复制激活,导致跨模型并行GPU的激活冗余复制。ZeRO通过分区激活并在计算中需要使用激活的前一刻才将其以复制形式具体化,从而消除了这种冗余。
- 过程:一旦计算了模型的一层的前向传播,输入激活就会在所有模型并行进程中分区,直到在反向传播期间再次需要。此时,ZeRO使用all-gather操作重新生成激活的复制副本。
- 内存节省:配合激活检查点,只存储分区的激活检查点而非复制副本,可以显著减少激活占用的内存量。对于极大的模型和非常有限的设备内存,这些分区的激活检查点甚至可以卸载到CPU内存,将激活内存开销减少到几乎为零,但需要额外的通信成本。
- 恒定大小缓冲区 (CB)
- 策略:ZeRO精心选择临时数据缓冲区的大小,以平衡内存和计算效率。为了提高效率,高性能库(如NVIDIA Apex或Megatron)在应用这些操作前将所有参数融合到单个缓冲区中。但是,融合缓冲区的内存开销与模型大小成正比,对于大型模型可能成为障碍。ZeRO通过使用性能高效的恒定大小融合缓冲区解决了这个问题,使缓冲区大小不依赖于模型大小。
- 内存碎片整理 (MD)
- 问题:由于激活检查点和梯度计算,模型训练中出现内存碎片化。在前向传播中,仅存储选定的激活以供反向传播使用,而大多数激活被丢弃,因为它们可以在反向传播期间重新计算,导致短期和长期内存交错,从而引起内存碎片化。内存碎片化在内存充足时通常不是问题,但对于在有限内存下运行的大型模型训练,会导致内存碎片化问题,如OOM(内存不足)和由于内存分配器花费大量时间寻找连续内存片段而导致的效率低下。
- 优化:ZeRO通过为激活检查点和梯度预分配连续内存块,并在生成时将它们复制到预分配的内中,实时进行内存碎片整理。MD不仅使ZeRO能够以更大的批量大小训练更大的模型,而且还提高了在有限内存下训练的效率。
Microsoft DeepSpeed 是什么呢?
Microsoft DeepSpeed****完整实现了 ZeRO 优化器
Microsoft DeepSpeed 框架简介
DeepSpeed 是一个开源深度学习优化库,旨在提高大模型训练和运行效率,以支持数千亿~万亿参数的超大语言模型。为了提高大模型训练的效率和扩展性, DeepSpeed 不仅实现了ZeRO 论文中的核心技术,还组合了以下多个模块:
- **ZeRO(Zero Redundancy Optimizer)😗*ZeRO 是 DeepSpeed 的一个关键组成部分,它通过优化数据并行训练中的显存使用,显著减少了所需的GPU显存。ZeRO 分为几个不同的级别(ZeRO-DP, ZeRO-Offload, ZeRO-Infinity),每个级别都提供了不同程度的优化和显存节省,允许训练更大的模型或在有限的硬件资源上训练模型。
- **模型并行(Model Parallelism)😗*DeepSpeed 实现了模型并行技术,如:Tensor切片,以支持大型模型的分布式训练。这些技术允许模型的不同部分在不同的计算设备上并行运行,从而处理那些单个设备无法容纳的大型模型。
- 流水线并行(Pipeline Parallelism):通过将模型训练分解为多个阶段,并在不同的设备上并行处理这些阶段,流水线并行技术可以进一步提高训练效率。这种方法特别适合于顺序依赖较弱的训练任务,如某些类型的深度学习模型。
- **稀疏注意力(Sparse Attention)😗*DeepSpeed 支持稀疏注意力机制,这有助于降低训练大型模型(尤其是那些基于Transformer的模型)时的计算和内存需求。稀疏性技术可以减少不必要的计算,使模型更加高效。
- 显存和带宽优化:DeepSpeed 采用了多种技术来优化显存使用和增加带宽效率,如异步I/O、内存池化和压缩通信等。这些优化有助于提高数据加载和模型训练过程中的效率。
https://www.deepspeed.ai/
ZeRO-Offload 技术使能CPU参与大模型训练
ZeRO-Offload是ZeRO技术的一个扩展,它将部分数据和计算从GPU(或其他主要训练设备)卸载到CPU,从而减轻了GPU的显存负担,并使得在有限GPU资源下训练更大的模型成为可能。核心策略如下:
- 模型卸载:ZeRO-Offload可以将模型的一部分状态(如优化器状态、梯度或参数)从GPU卸载到CPU内存中,从而减少GPU上的内存需求。。
- 计算卸载:除了模型卸载之外,ZeRO-Offload还可以将一部分计算任务(如参数更新)卸载到CPU,减轻GPU的计算负担,使得GPU可以专注于更加密集的前向和反向传播计算。同时尽量减少数据在GPU和CPU之间的移动,以及减少CPU上的计算时间,从而在GPU上节省显存
- 效率和规模:在单个NVIDIA V100 GPU上可以实现40 TFlops的性能,训练超过100亿参数的模型,相比于PyTorch等流行框架在单GPU上能训练的最大模型规模提高了10倍。
- 灵活性和可扩展性:设计用于在多GPU上扩展,提供接近线性的加速比,最多支持128个GPU
ZeRO-Offload 模型训练数据流图:降低 GPU 和 CPU 交互开销
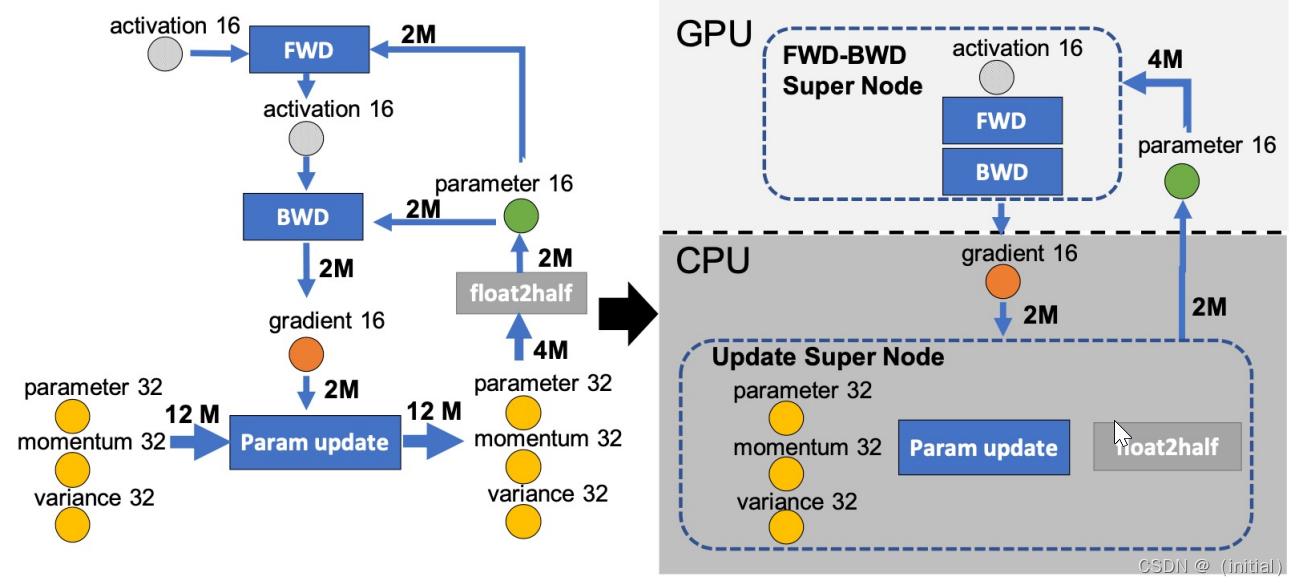
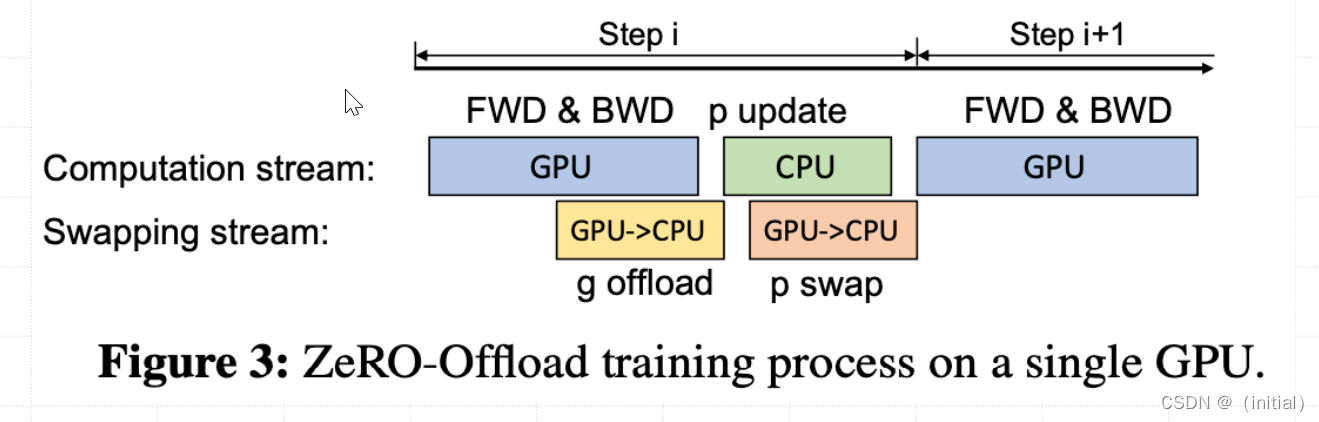
ZeRO-Offload 模型训练流程(单张GPU)
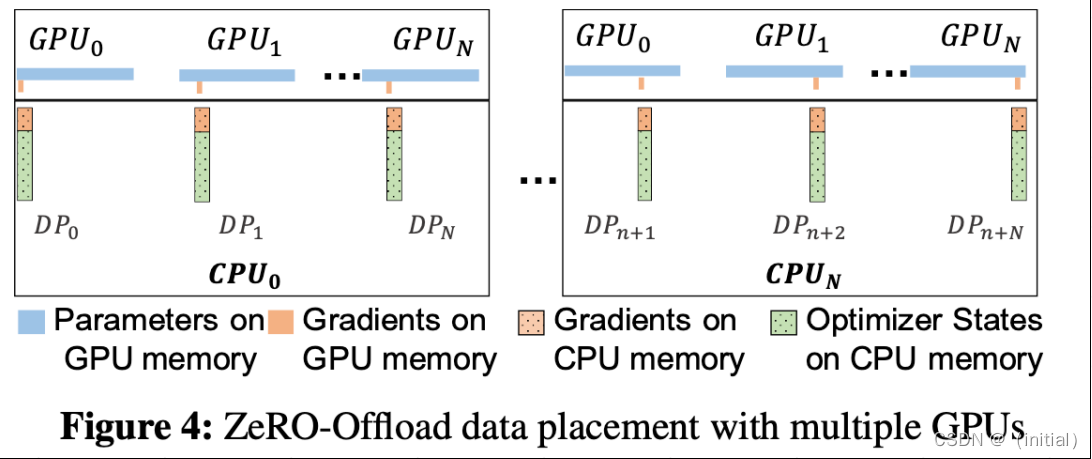
ZeRO-Offload 模型训练流程(多张GPUs)
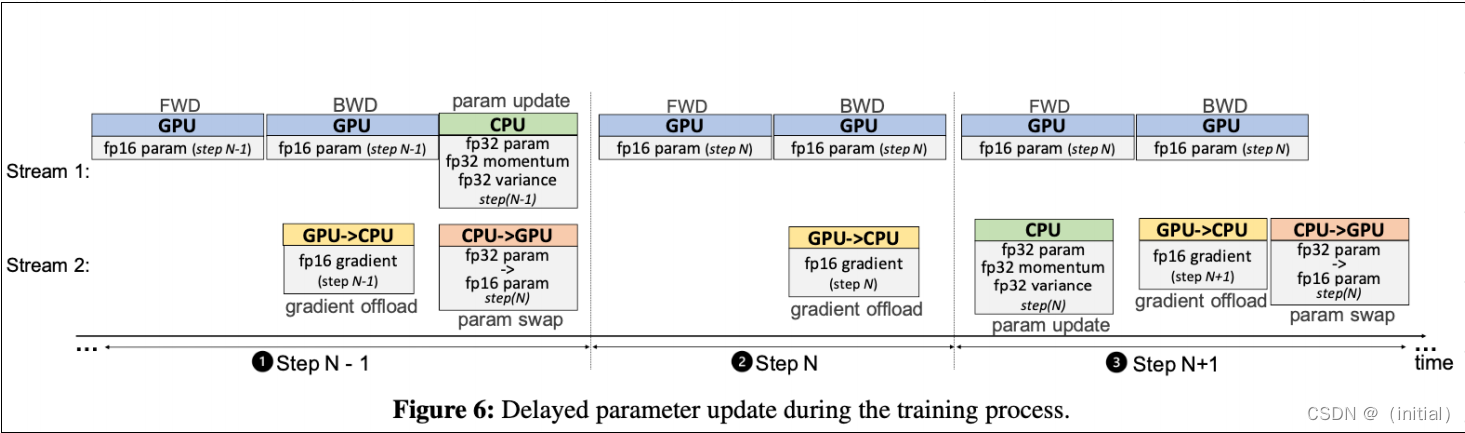
ZeRO-Offload 模型训练流程(延迟更新)
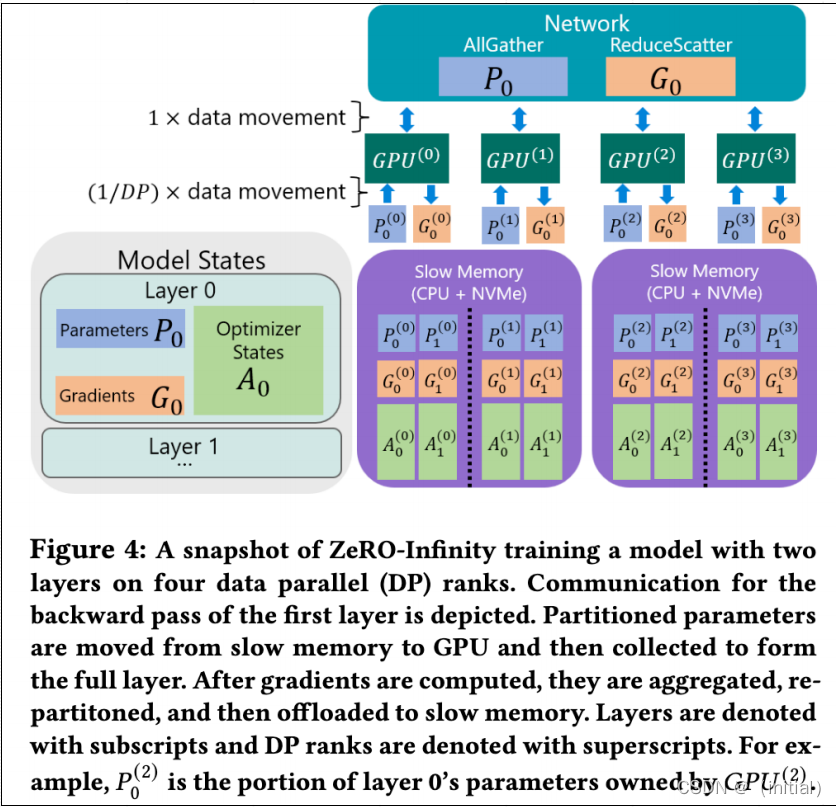
ZeRO-Infinity 异构创新支持百万亿模型训练
ZeRO-Infinity也是ZeRO技术的扩展,旨在设计面向百万亿大模型的训练框架。它的主要创新如下:
- 全面优化: ZeRO-Infinity结合了数据并行、模型并行、流水线并行和ZeRO-Offload的优点,提供了一套全面的显存和计算优化方案 。
- 高效利用各种存储层 :通过智能地使用GPU显存、CPU内存和NVMe SSD存储, 最大化了训练设备的存储和计算能力。
- 超大模型规模:可以在当前一代GPU集群上训练高达数十甚至数百万亿参数的模型。在单个NVIDIA DGX-2节点上微调万亿参数模型,降低了超大模型训练和微调的资源需求。
- 优秀的吞吐量和可扩展想:在512个NVIDIA V100 GPU上保持超过25 petaflops的性能(达到峰值的40%),在不受CPU或NVMe带宽限制的情况下,展示了超线性的可扩展性。
- 开源友好: Microsoft 在 DeepSpeed 框架中开源实现了ZeRO-Infinity 技术。
随着大型模型规模的快速增长和GPU内存增长的限制,传统的训练方法面临瓶颈。ZeRO-Infinity 面向未来提出了一套创新的训练方法,推动了大模型和复杂任务的研究。
ZeRO-Infinity 异构训练框架
分布式模型训练并行化技术对比
大模型分布式训练:数据并行 与 模型并行
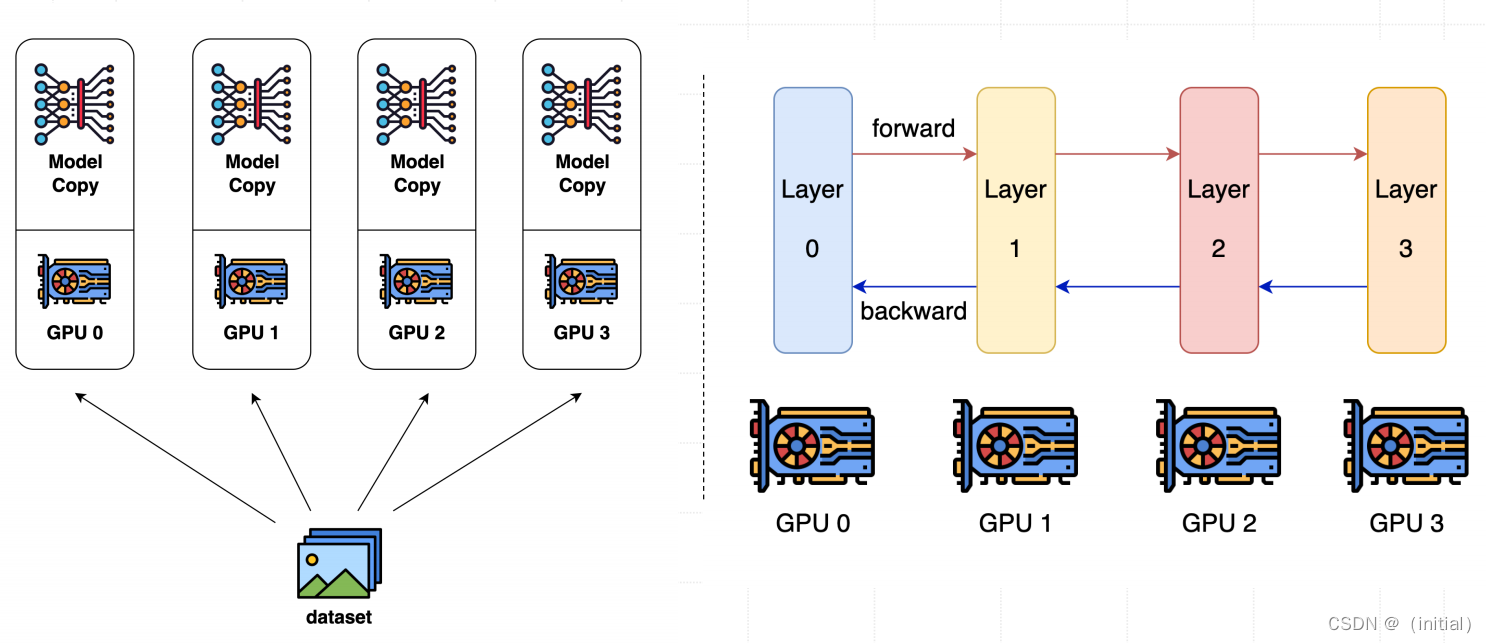
大模型分布式训练:模型并行 与 流水线并行
流水线并行则是将模型训练的过程(特别是前向和后向传播)分割成多个阶段,并在不同的设备上并行执行这些阶段。流水线并行的关键优势在于它可以减少设备间的空闲时间,因为不同的设备可以同时处理模型的不同部分。
在实践中,这两种技术经常结合使用,以实现在有限硬件资源下训练大规模深度学习模型的目标。例如,一个大型模型可以首先使用模型并行技术在多个设备上分割,然后在这些设备上进一步应用流水线并行技术来优化训练过程的效率。
于它可以减少设备间的空闲时间,因为不同的设备可以同时处理模型的不同部分。
在实践中,这两种技术经常结合使用,以实现在有限硬件资源下训练大规模深度学习模型的目标。例如,一个大型模型可以首先使用模型并行技术在多个设备上分割,然后在这些设备上进一步应用流水线并行技术来优化训练过程的效率。