文章目录
- 一、环境准备
- 1.1安装Anaconda
- 1.2创建虚拟环境
- 1.3准备CUDA
- 1.4安装pytorch
- 1.3安装Pycharm
- 二、全连接神经网络原理
- 2.1整体结构
- 2.2神经单元
- 2.3激活函数
- 2.3.1非线性性
- 2.3.2Sigmoid函数
- 2.3.3Tanh函数
- 2.3.4ReLU函数
- 2.3.5Leaky ReLU函数
- 2.4前向传播
- 2.5损失函数与反向传播
- 2.5.1均方误差函数与交叉熵函数
- 2.5.2反向传播
- 2.6梯度下降法
- 2.6.1基本原理
- 2.6.2案例:梯度下降法更新网络参数
- 2.7模型训练大致流程梳理
- 三、线性回归
- 3.1基本原理
- 3.2案例
Pytorch是torch的python版本,是一款开源的神经网络框架,专门针对 GPU 加速的深度神经网络(DNN)编程。
一、环境准备
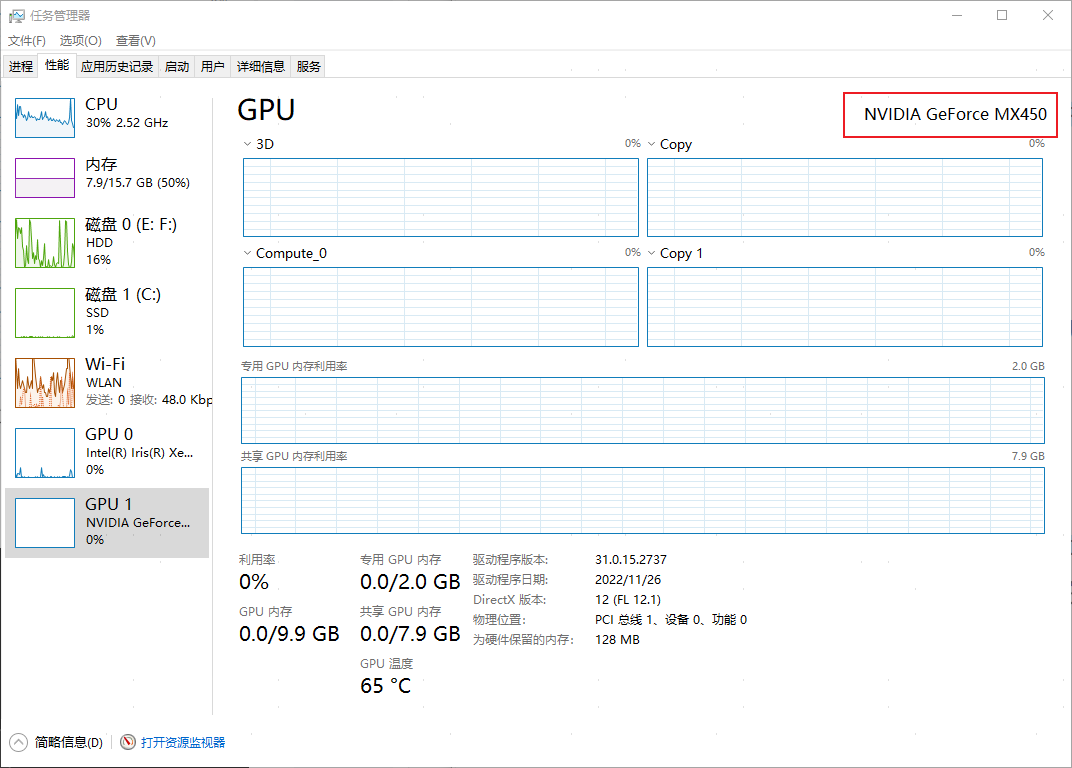
在安装之前需先确定电脑是否含有Nvidia(英伟达显卡),以便安装正确的版本。打开任务管理器:
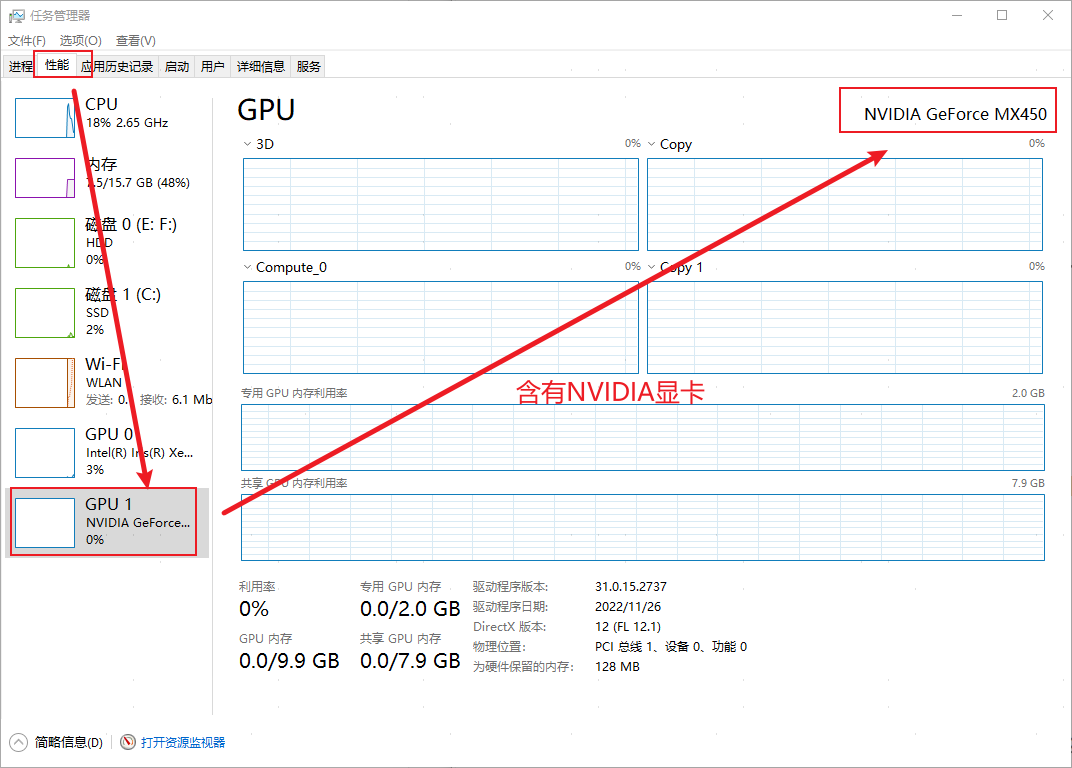
只有带NVIDIA的英伟达显卡的电脑才能安装GPU版本,否则其他的就只能安装CPU版本。
1.1安装Anaconda
Anaconda是一个强大的开源数据科学平台,它将很多好的工具整合在一起,极大地简化了使用者的工作流程,并能够帮助使用者解决一系列数据科学难题。官方网站:Anaconda官网。
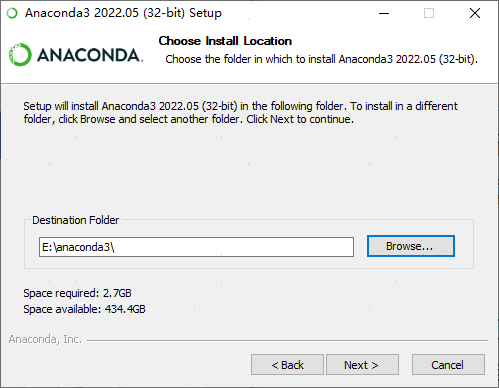
完成安装后需要手动配置环境变量,在系统环境变量Path中新建值(根据安装路径不同应自行调整,需注意最后一条路径以\结尾):
E:\anaconda3
E:\anaconda3\Library\bin
E:\anaconda3\Library\mingw-w64\bin
E:\anaconda3\Scripts\
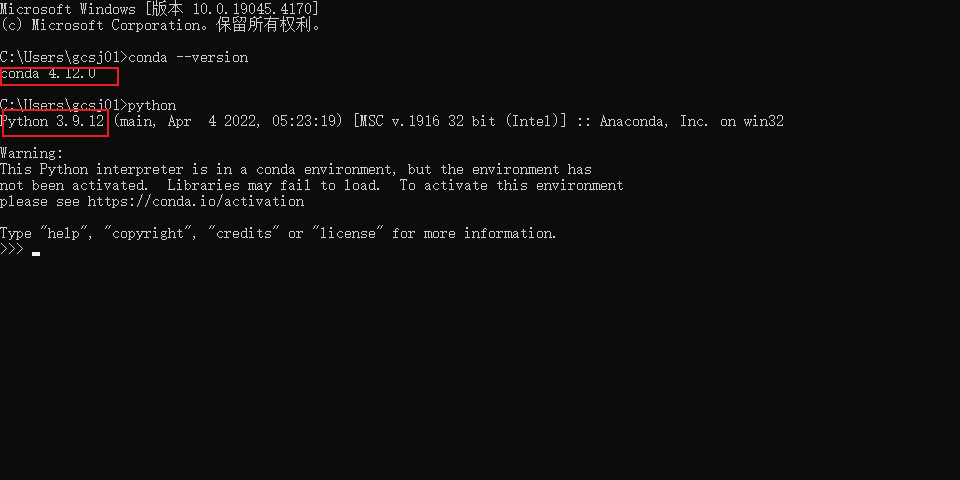
在完成安装后使用命令行查看是否完成安装:
conda --version
python
此时可通过Anaconda Navifator进行打开:
使用conda安装python包时使用官方服务器位于国外,故可使用国内的清华镜像源,在Anaconda Prompt进行操作:
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free/
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main/
//设置搜索时显示通道地址
conda config --set show_channel_urls yes
1.2创建虚拟环境
安装好的Anaconda会自带一个基础环境。但是我们后续的项目每一个需要的安装包不同,为了避免冲突,所以我们可以为每一个项目配置一个虚拟环境,这样就不相互打扰了。使用Anaconda Prompt创建虚拟环境:
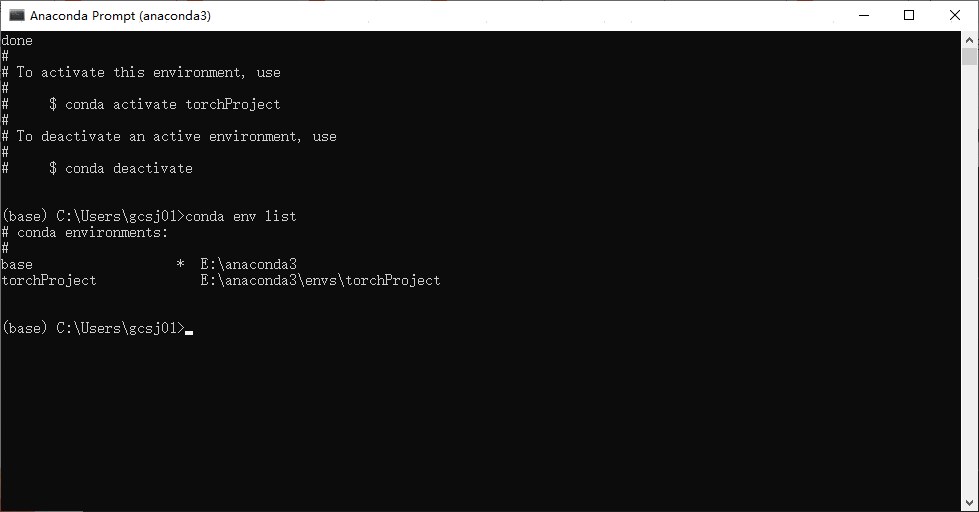
conda env list
conda create –n torchProject python=3.8
conda env list:查看当前虚拟环境列表。conda create –n 虚拟环境名字 python=版本:创建指定Python版本的虚拟环境。
查看已创建的虚拟环境:
1.3准备CUDA
使用任务管理器查看自己电脑GPU的型号:
进入官网安装最新的显卡驱动(可直接使用命令查看是否已安装驱动程序):

安装完后即可通过命令行查看电脑驱动的版本:
nvidia-smi
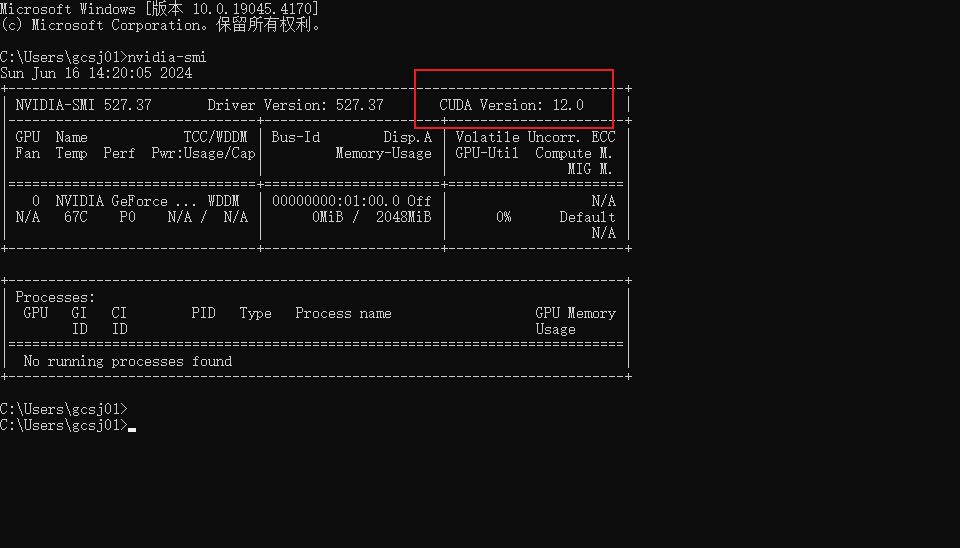
CUDA Driver版本就是12.0,表示的是驱动所能支持的最大运行API版本就是12.0。若要安装CUDA Runtime Version(运行版本),要保证CUDA Driver 版本 >= CUDA Runtime 版本,也就是12.0及以前的。
1.4安装pytorch
进入Pytorch官网:官网,若官网给出的版本符合电脑配置,复制指令到conda环境中运行即可 ,否则需自行寻找符合的版本:
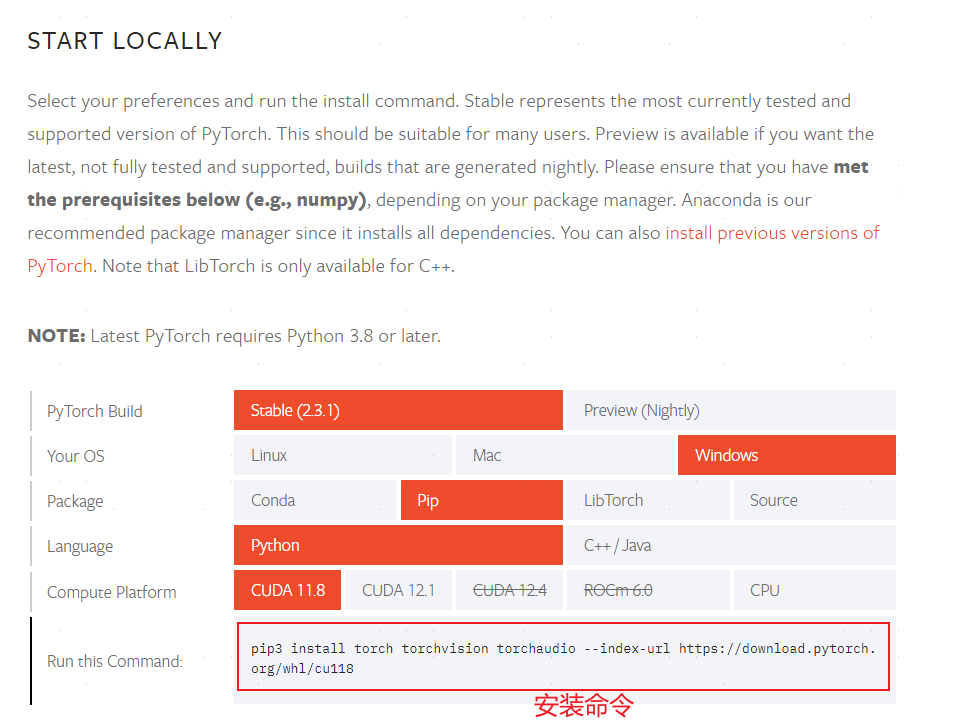
激活虚拟环境并进行安装:
1.3安装Pycharm
Pycharm官网: Pycharm官网
本机中安装路径为:E:\Pycharm,完成安装后即可新建项目编写代码:
二、全连接神经网络原理
神经网络(Neural Network,NN),是一种模仿生物神经网络的结构和功能的数学模型,用于对函数进行估计或近似。人脑可以看做是一个生物神经网络,由众多的神经元连接而成。当神经元“兴奋”时,就会向相连的神经元发送化学物质,从而改变这些神经元内的电位;如果某神经元的电位超过了一个“阈值”,那么它就会被激活,即“兴奋”起来,向其他神经元发送化学物质。
2.1整体结构
全连接神经网络,是指第 N 层的每个神经元和第 N-1 层的所有神经元相连,第 N-1 层神经元的输出就是第 N 层神经元的输入。整体结构由三部分组成:
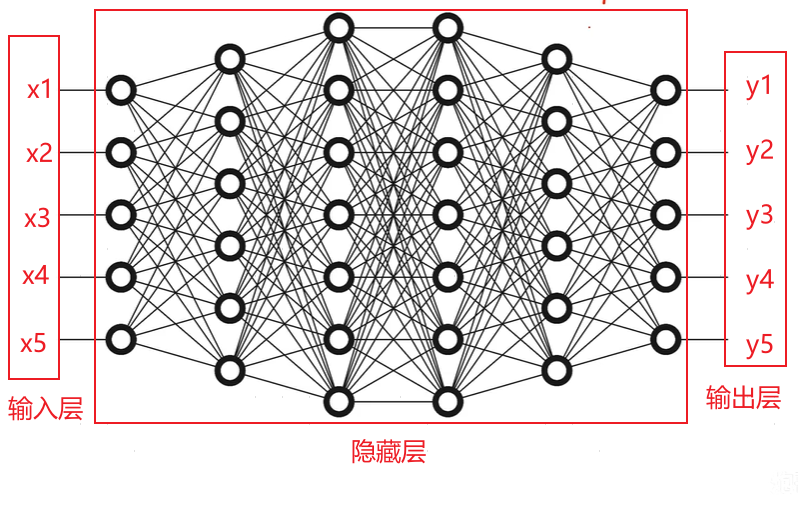
- 输入层:输入的数据,即x1、x2、x3,可以是图片、矩阵等。
- 隐藏层:对输入数据进行特征提取,对于不同的输入神经单元设置不同的权重与偏置,从而影响神经单元对输入信息敏感程度,可以形成输出结果的偏向)。事实上,隐藏层可看作是一层或多层神经网络连接而成。
- 输出层:输出的结果,即y1、y2、y3,可以是分类结果等。
通过输入层激活信号,再通过隐藏层提取特征,不同隐藏层神经单元对应不同输入层的神经单元权重和自身偏置均可能不同,输入层兴奋传递到隐藏层兴奋,最后输出层根据不同的隐藏层权重和自身偏置输出结果。举一个例子,目标是识别一个 4x3 的图像,下例中采用了12 神经节点来对应 4x3 个像素点(神经点属于隐藏层),在隐藏层中使用另外三个神经单元进行特征提取,最后输出层再使用两个神经节点标记识别结果是 0 或 1:
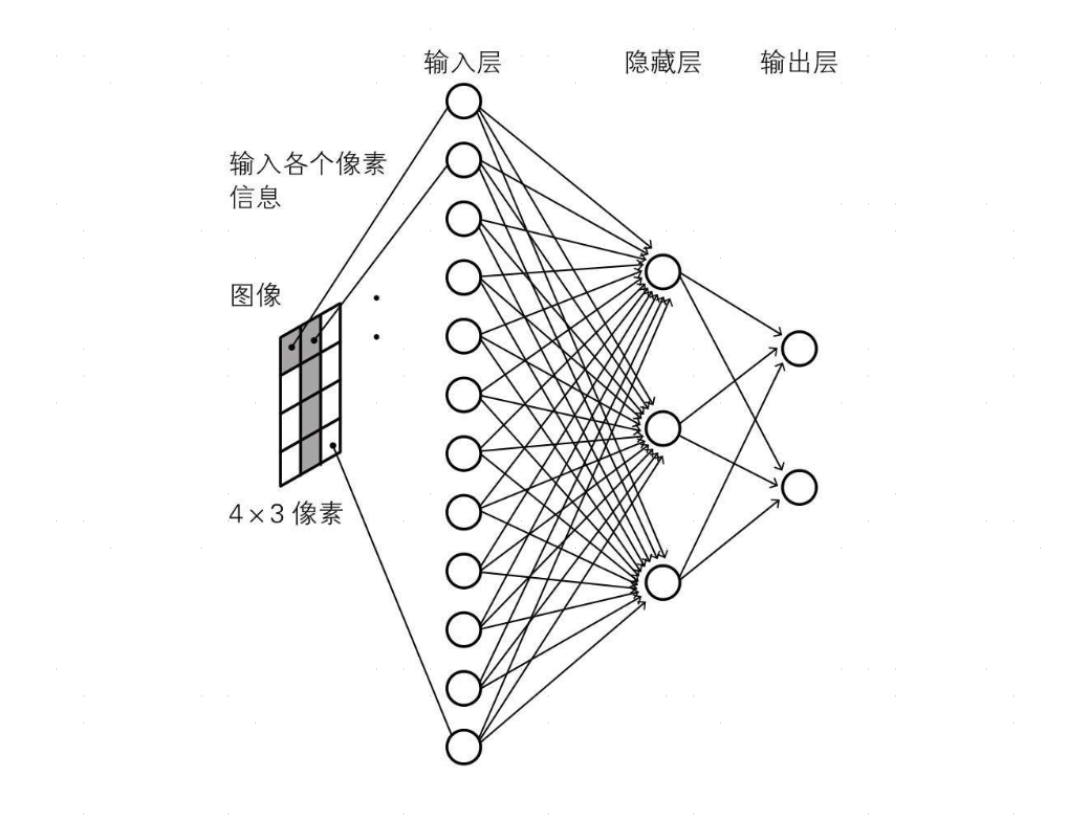
- 对于输入层,十二个神经单元对应 4 * 3 像素(黑白),如果该像素是黑的,则对应神经元兴奋,否则静息。
- 对于输出层的两个节点,如果识别结果偏向0,那么第一个节点兴奋度会高于第二个节点,反之识别结果偏向1。
- 对于隐藏层,每一个节点会对输入层的兴奋有不同的接收权重,从而更加偏向于某种识别模式。例如,隐藏层第一个神经单元对应下图模式A,也就是对应输入层 4、7号神经单元接收权重比较高,对其他神经单元接受权重比较低,如果超过了神经单元自身的偏置(阈值)则会引发隐藏层的兴奋,向输出层传递兴奋信息,隐藏层其他神经单元同理。
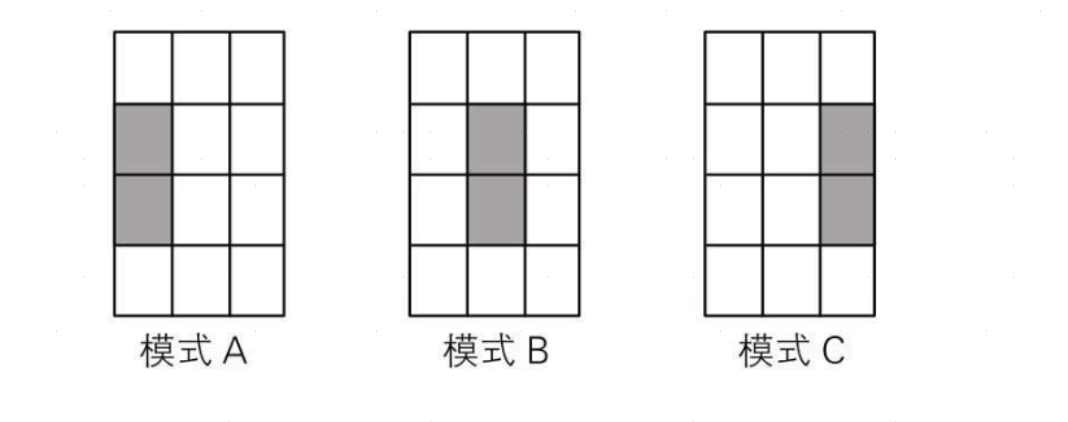
总之,模型的意义就在于找到最为合适的参数w、b,使得预测结果与真实情况最为接近。
2.2神经单元
神经网络本质是由多个神经单元组合而成,因此只要搞清楚神经元的本质就可以搞清楚全连接神经网络了。例如,一个全连接神经网络神经元的模型图:
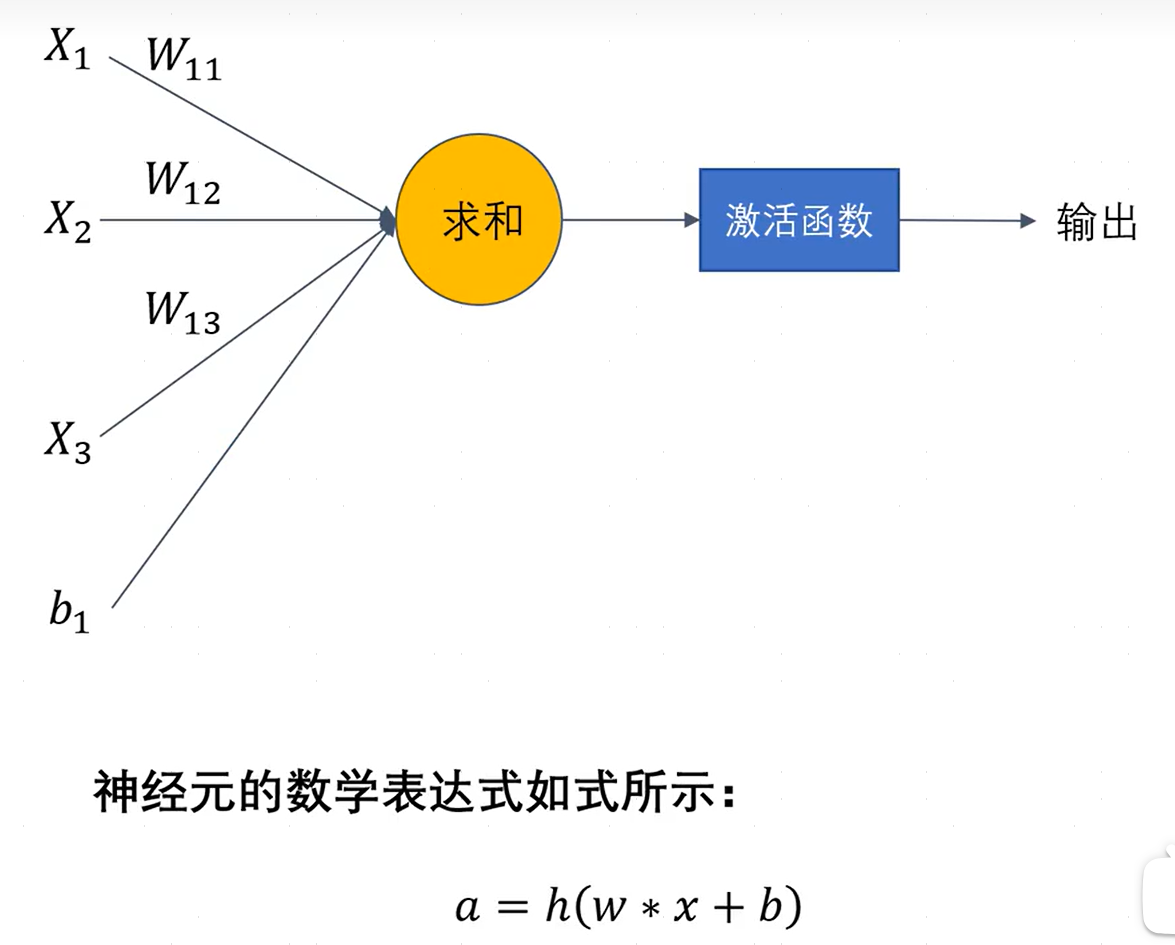
x:各个输入的分量。b:偏置,用于控制神经元被激活的容易程度。w:各个信号的权重的参数,用于控制各个信号的重要性,可以是一个数、向量、矩阵等。h:激活函数。a:神经元的输出。
可简写为:
a = h ( w T x + b ) a=h(w^{T}x+b) a=h(wTx+b)
即,一个神经元的功能是求得输入向量与权向量的内积后,经一个非线性传递函数得到一个标量结果。
观察上述数学表达式发现,该式子只是将线性模型的输出结果经过一个激活函数的计算再输出,激活函数的种类有很多,但有着一定是非线性函数的共同特征。而若使用线性函数作为激活函数,则不管如何加深神经网络的层数,隐藏层再怎么多,总是存在与之等效的“无隐藏层的神经网络”。
2.3激活函数
激活函数有助于将神经元输出的值限制在我们要求的某个限制内。 因为激活函数的输入是W * x + b,其中W是单元的权重(Weight),x是输入,然后在其上加上b偏差(Bias)。 如果不限制在某个值上,则此值的变动范围会非常大,此时可使用激活函数将输出值限定在一个范围(常用0~1),来表示神经元的兴奋程度(0表静默,1表活跃)。并且,激活函数为神经网络引入了非线性的能力,其本身是有非线性性。
2.3.1非线性性
上文中提到,激活函数必须是非线性(即,不仅仅只有加法、数量乘法的运算)的,否则不管如何加深神经网络的层数,隐藏层再怎么多,总是存在与之等效的“无隐藏层的神经网络”。借鉴博客:机器学习-神经网络为什么需要非线性(激活函数)。
由上文可知,每一层的参数操作对应的函数表达式为 a 1 = w 1 ∗ x + b 1 a_1=w_1*x+b_1 a1=w1∗x+b1。将x用向量表示,而w相当于一个矩阵,此时二者乘积相当于是矩阵x列向量的线性组合:
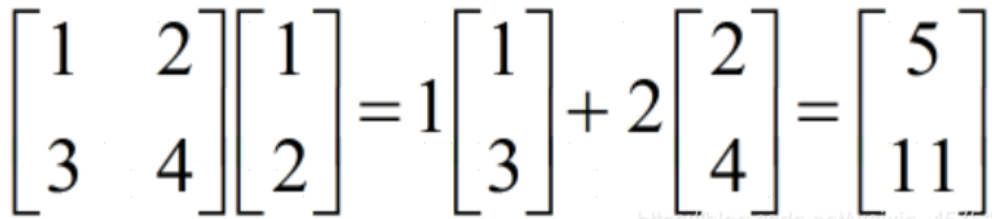
此时对应神经网络仅含一层隐藏层,若将输出结果作为下一隐藏层的输入,并继续使用线性(仅含有加法、数量乘法运算)的激活函数,即 a 2 = w 2 ∗ a 1 + b 2 a_2=w_2*a_1+b_2 a2=w2∗a1+b2,进行数学推导:
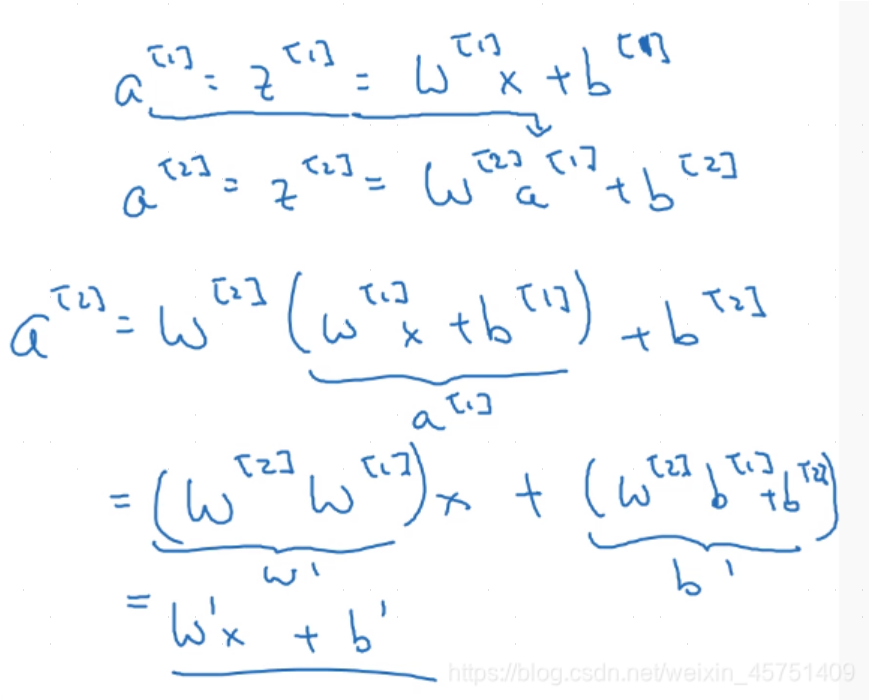
此时 a 2 a_2 a2相当于是一组新参数 w ′ 、 b ′ w'、b' w′、b′与输入向量 x x x运算得到,神经网络只含有一层隐藏层,即多层线性操作等价于一层线性操作。但真实世界有些原始数据本身就是线性不可分的,必须要对原始空间进行一定的非线性操作,比如上文中提及的限制输出范围,故而激活函数必须是非线性的,否则没有意义。
常见非线性函数有二次函数、分段函数、指数函数。
2.3.2Sigmoid函数
Sigmoid函数往往用于作为二分类问题输出层激活函数,输出值作为分类的概率,如,是种类A的概率为0.99,不是的概率为0.01。
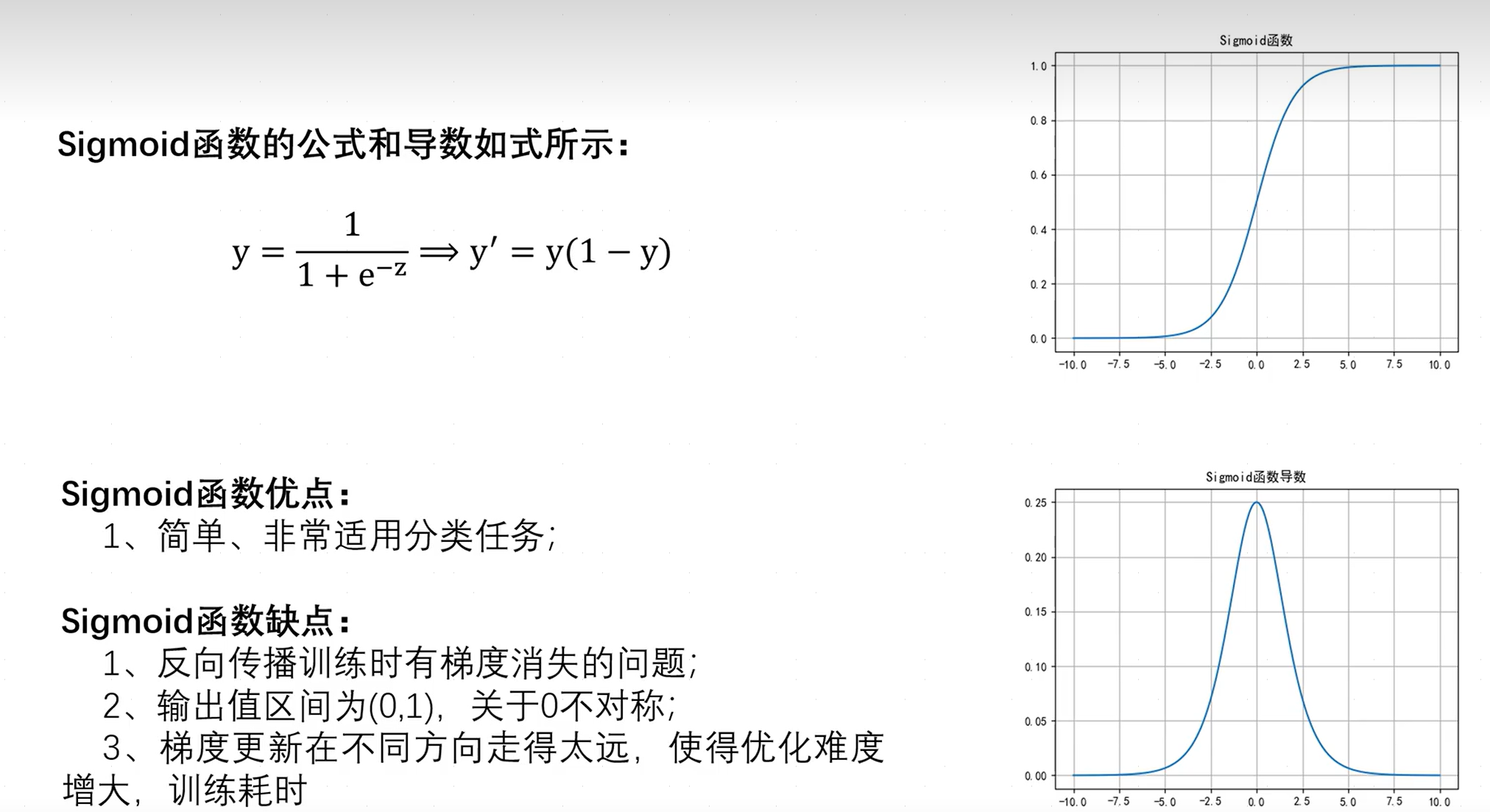
梯度,是指某一函数在该点处的方向导数沿着该方向取得最大值,对于一维函数指的就是某一点处的导数。Sigmoid函数存在梯度消失(梯度变小并不断接近0,但不为0)、梯度爆炸(梯度快速变为极大值)的情况,但在实际中,梯度值期望是一个平稳值,即不大不小,此时方便求出对应的参数值。
注意,导数往往由于求出参数w、b,而参数即用于使输出结果最接近于真实情况。
2.3.3Tanh函数
Tanh函数的输出结果在(-1~1)之间,是一个对称的值域。
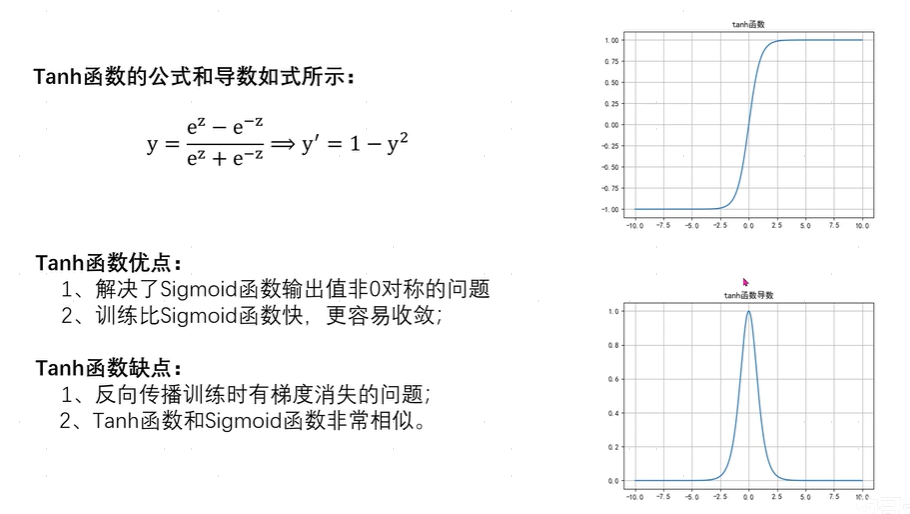
Tanh函数更容易收敛,是指相对于sigmoid函数,Tanh函数求出最佳参数所需的训练轮次更少,因为Tanh函数的导数在-1到1之间变化,具有较高的梯度(sigmoid函数最大梯度为0.25,而Tanh函数为1),有利于网络的快速训练。
2.3.4ReLU函数
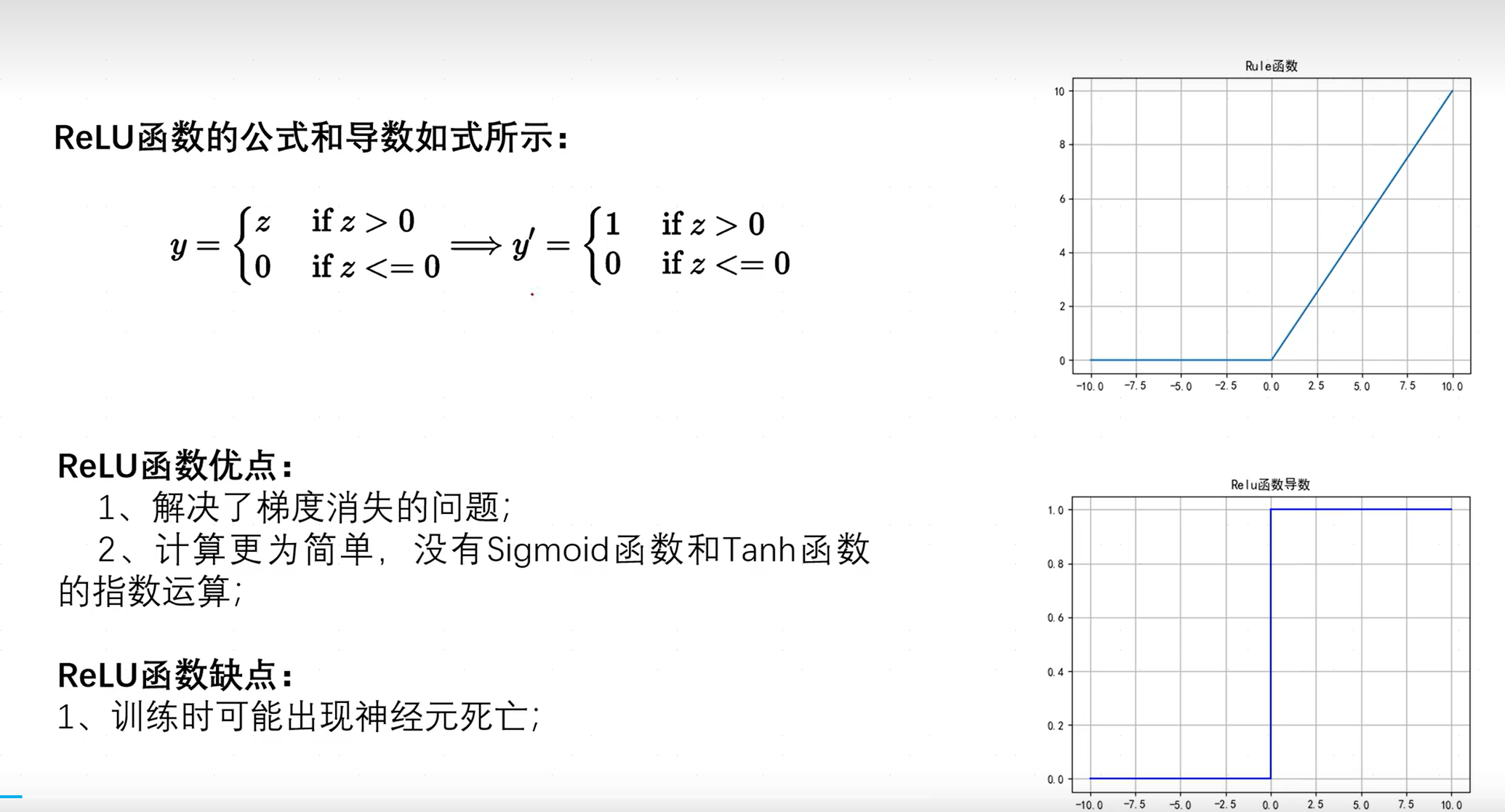
ReLU函数解决了梯度消失的问题,因为当输入值小于0时导数值等于0,此时神经元死亡,以后面内容可知,在计算参数时会利用损失函数来反向传播优化参数w、b,而激活函数ReLU直接使得输出为0,此时不再出现损失,不会再优化参数w、b(神经元死亡指的即是,神经元的参数再也不会更新),也就解决了梯度消失问题。
2.3.5Leaky ReLU函数
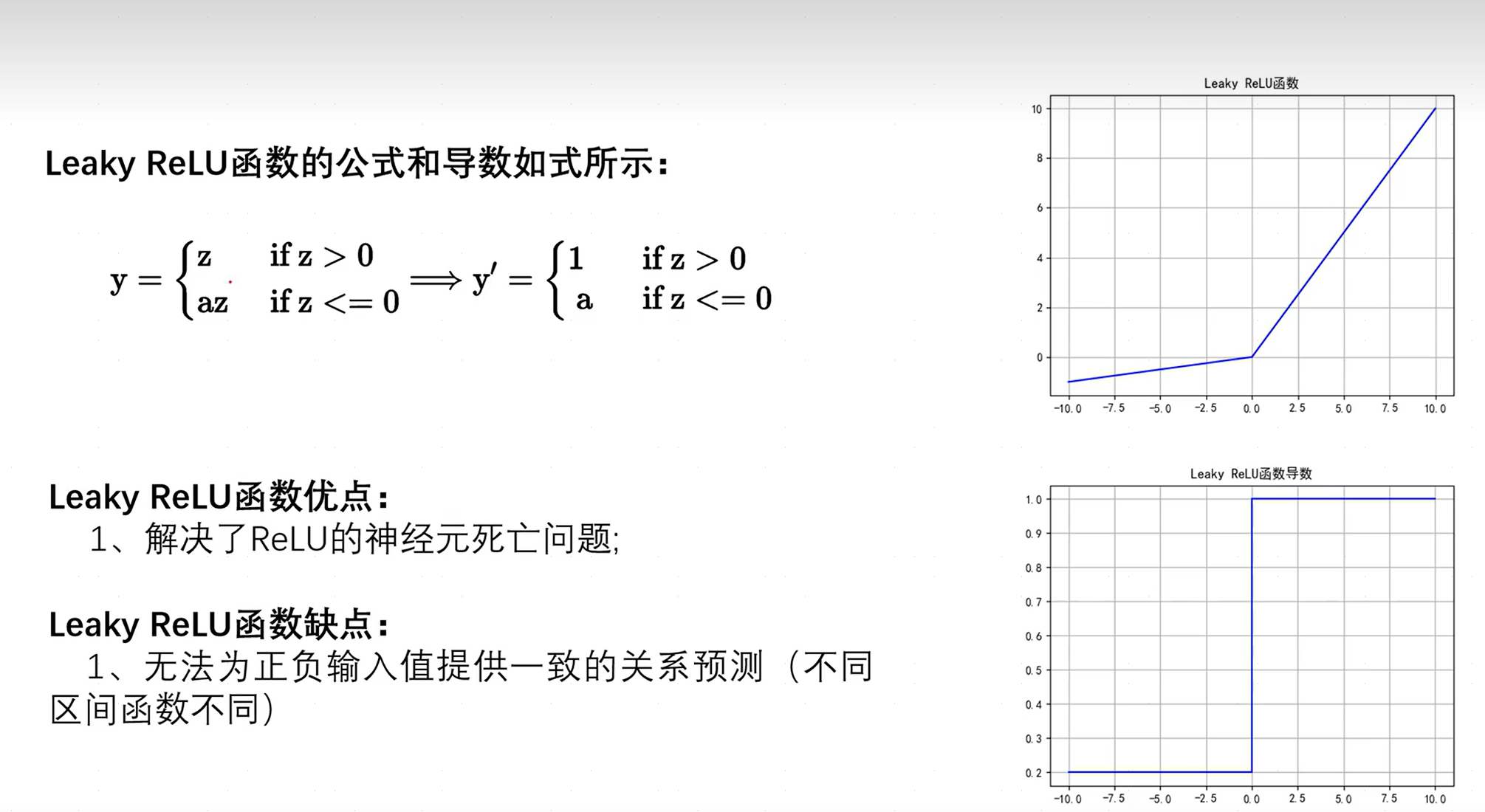
无法为正负输入值提供一致的关系预测是指,正、负区间函数运算并不对称,使得对正负输入值的预测方式不同。
2.4前向传播
前向传播,是指将数据特征作为输入,输入到隐藏层,将数据特征和对应的权重相乘同时再和偏置进行求和,将计算的结果通过激活函数进行激活,将经过激活函数激活的函数输出值作为下一层神经网络层的输入再和对应的权重相乘同时和对应的偏置求和,再将计算的结果通过激活函数进行激活,不断重复上述的过程直到神经网络的输出层,最终得到神经网络的输出值。
简单来说,输入数据输入到神经网络并通过隐藏层进行运算,最后输出结果的过程,就是神经网络的前向传播。一个简单的神经网络:
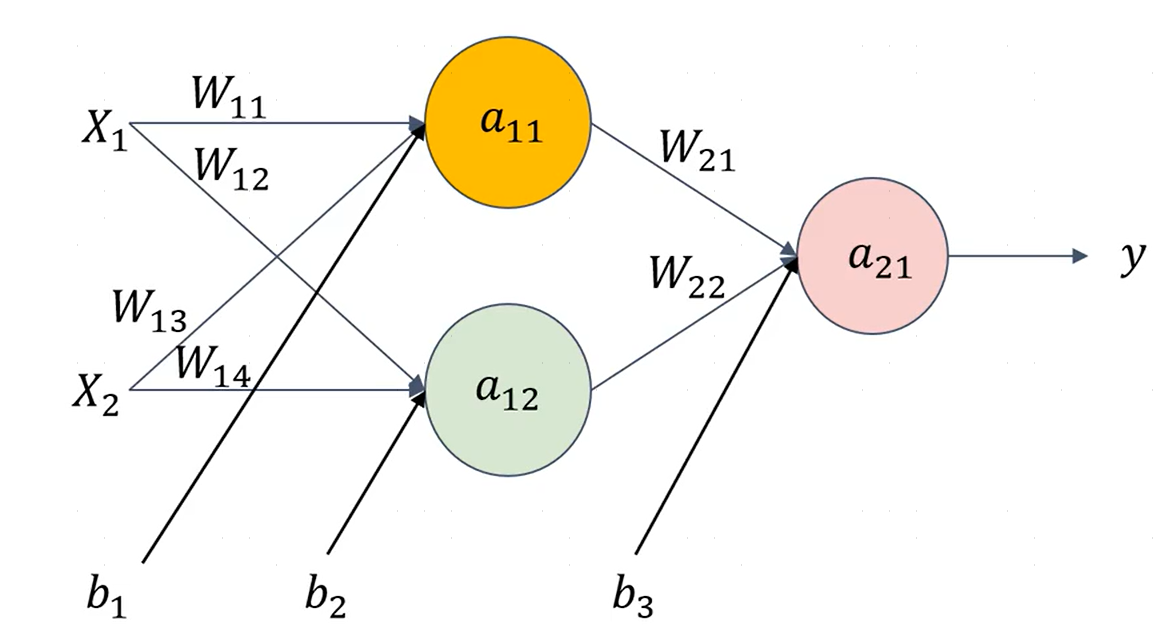
隐藏层两个神经元的计算:
a 11 = s i g m o i d ( w 11 x 1 + w 13 x 2 + b 1 ) a 12 = s i g m o i d ( w 12 x 1 + w 14 x 2 + b 2 ) a_{11}=sigmoid(w_{11}x_1+w_{13}x_2+b_1)\\ a_{12}=sigmoid(w_{12}x_1+w_{14}x_2+b_2) a11=sigmoid(w11x1+w13x2+b1)a12=sigmoid(w12x1+w14x2+b2)
传输层神经元的计算:
a 21 = r e l u ( w 21 a 11 + w 22 a 12 + b 3 ) a_{21}=relu(w_{21}a_{11}+w_{22}a_{12}+b_3) a21=relu(w21a11+w22a12+b3)
其中, w 11 、 w 13 、 b 1 、 w 12 、 w 14 、 b 2 、 w 21 、 w 22 、 b 3 w_{11}、w_{13}、b_1、w_{12}、w_{14}、b_2、w_{21}、w_{22}、b_3 w11、w13、b1、w12、w14、b2、w21、w22、b3隐藏层对应输入的权重和偏置,训练模型的目的在于,找到一种方法可以求出准确的w和b,使得前向传播计算出来的y无限接近于真实情况。常见方法,如,梯度下降法,反向传播法就是梯度下降法在深度神经网络上的具体实现方式。
2.5损失函数与反向传播
在模型确定后(本质是确定了一组参数),就希望训练结果接近于真实值,此时可设置损失函数来计算前向传播的输出值和真实的label值之间的损失误差,来对模型性能进行评估。目前常见的损失函数有均方误差、交叉熵误差。对于不同类型的问题,如:
- 回归问题:输出的是物体的值,如预测当前温度等,是对真实值的一种逼近预测,输出值是连续的。
- 分类问题:输出的是物体所属的类别,输出值是离散的。
对于不同类型的问题就有着不同的常用损失函数。
2.5.1均方误差函数与交叉熵函数
1.均方误差函数
&emsp在回归问题中使用较多的是均方误差函数:
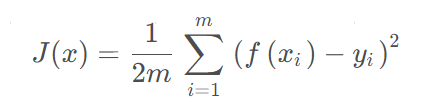
其中, f ( x i ) 、 y i f(x_i)、y_i f(xi)、yi分别表示输入数据对应的前向传播输出值、真实值,均方误差函数求出所有误差的平方和,并除以 2 m 2m 2m, m m m是输入数据的个数。事实上,是所有误差的平方和的平均值并除以2,除以2目的在于更好计算 J ( x ) J(x) J(x)的导数,2的有无对模型性能的评估并无影响。
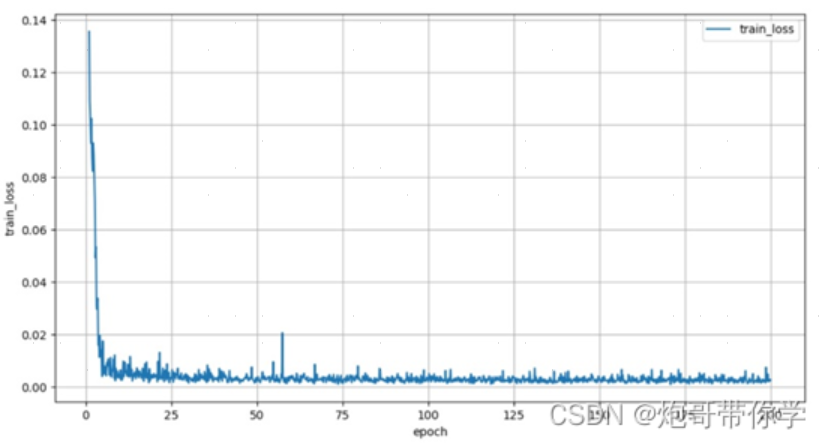
以上图为例(tain_loss,训练集损失函数图),在初始训练时(训练轮次较低),误差往往较大,而随着训练轮次的增加,模型参数的不断迭代使得误差不断降低(指针对训练集的误差),在 e p o c h = 75 epoch=75 epoch=75左右时,误差接近0。
2.交叉熵函数
在分类问题中使用较多的是交叉熵函数:
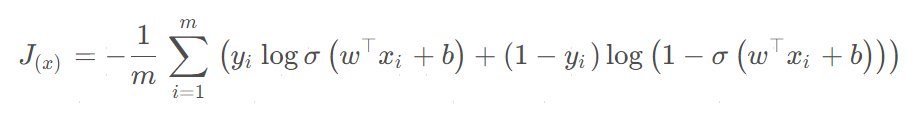
2.5.2反向传播
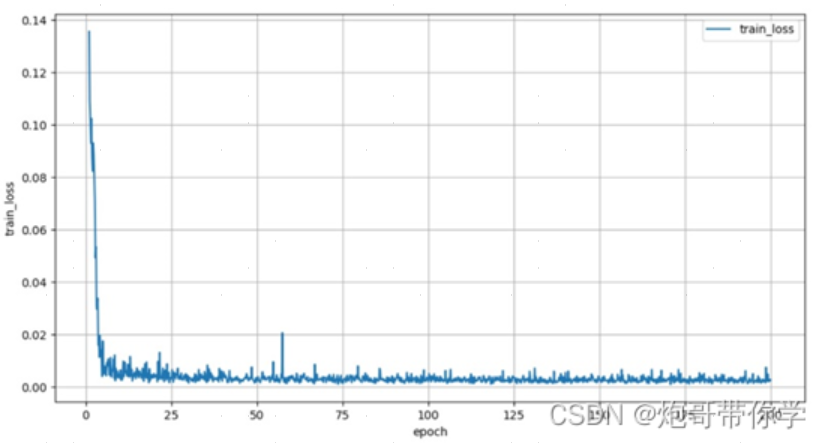
事实上,模型训练的流程为,将数据输入模型并通过前向传播得到输出数据,利用损失函数计算输出数据与真实数据之间的误差,并利用反向传播更新参数(这一过程需使用梯度)使损失函数变低(神经网络的输出和真实值更加逼近),最后不断重复这一过程,直到损失函数接近于0。
但是实际项目中,由于数据中存在噪声,因此损失值在参数不断的更新下会不断接近0,但是不可能等于0,所以我们往常将模型的训练轮次和损失值变化画图显示出来,如果损失值在一定的轮次后趋于平缓不再下降,那么就认为模型的训练已经收敛了。例如:
2.6梯度下降法
2.6.1基本原理
上文中的反向传播,正是基于梯度下降法实现的。

梯度下降法正是基于此思想,只是从追求不同方向上最陡的山体梯度,变为追求如何修改参数可使损失函数值下降最快。反之,就是梯度上升法。需要注意的是,梯度下降法只是一种局部搜索优化算法,即它无法保证得到全局最优解。因此,有时需要运用其他优化算法来搜索全局最优解。
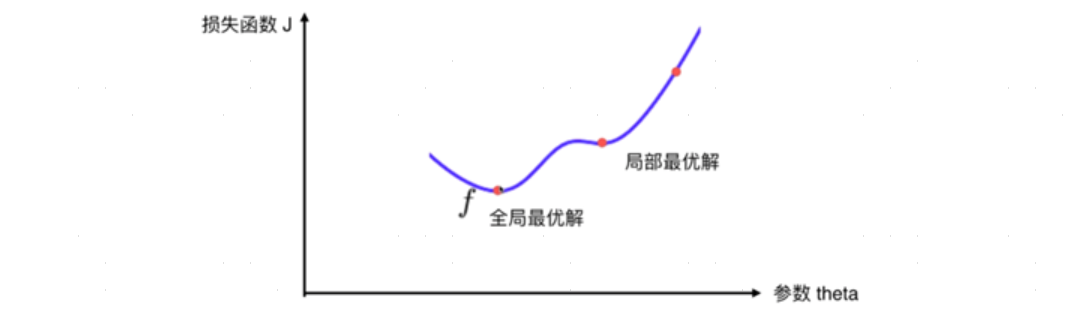
1.一元函数:模型仅有一个参数
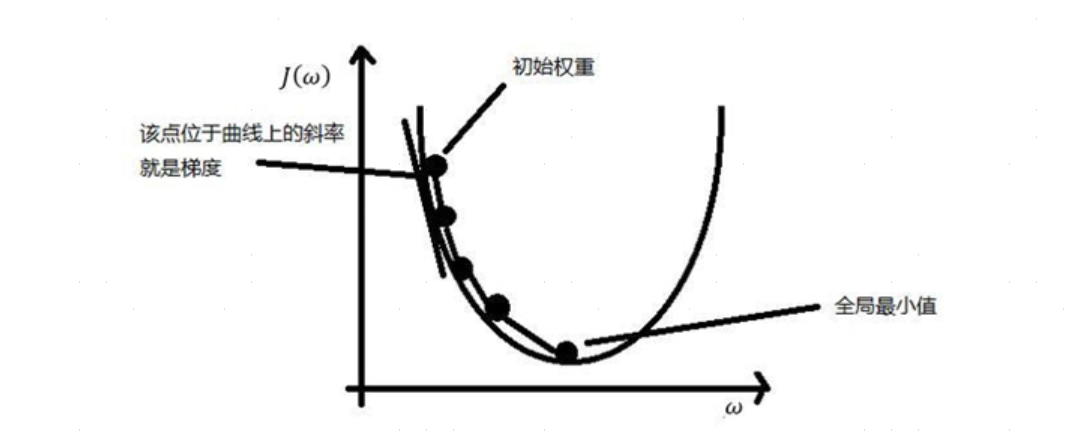
函数 J ( w ) J(w) J(w)即为损失函数,横坐标 w w w表示模型参数,问题转化为如何求出函数极小值处参数 w w w的值。
思路:在当前位置求偏导,即梯度,负梯度不断增大接近零的方向( w w w的变化方向),就是不断逼近函数极小值的方向。有时得到的是函数最小值的局部最优解,如果损失函数是凸函数,梯度下降法得到的解就是全局最优解。
一元函数的梯度(导数)公式:
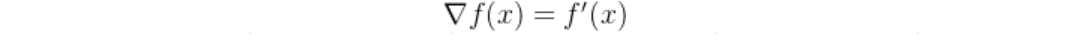
假设损失函数为 J ( θ ) J(θ) J(θ),其中 θ θ θ是模型参数,从一个初始点 θ 0 θ_0 θ0开始迭代,每次迭代更新 θ θ θ的值,直至损失函数值下降到一定程度,或者达到固定次数的迭代次数。每次迭代的更新公式:
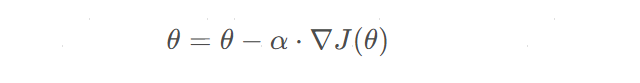
其中, α α α是学习率,控制每一步迭代的步长。学习率太小会导致收敛速度慢,而学习率太大会导致算法发散。因此,学习率是梯度下降法中需要调整的一个超参数。
注意,超参数是指算法运行之前手动设置的参数,用于控制模型的行为和性能。这些超参数的选择会影响到模型的训练速度、收敛性、容量和泛化能力等方面,常见的超参数如学习率、迭代次数、正则化参数、隐藏层的神经元数量等。
2. 多元函数:模型含多个参数
对于不同参数 θ i θ_i θi,其梯度定义为:
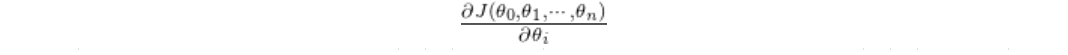
其中,函数 J ( θ ) J(θ) J(θ)即为损失函数,此时每次迭代的更新公式为:
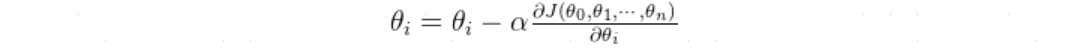
直至损失函数值下降到一定程度,或者达到固定次数的迭代次数时,算法终止。
2.6.2案例:梯度下降法更新网络参数
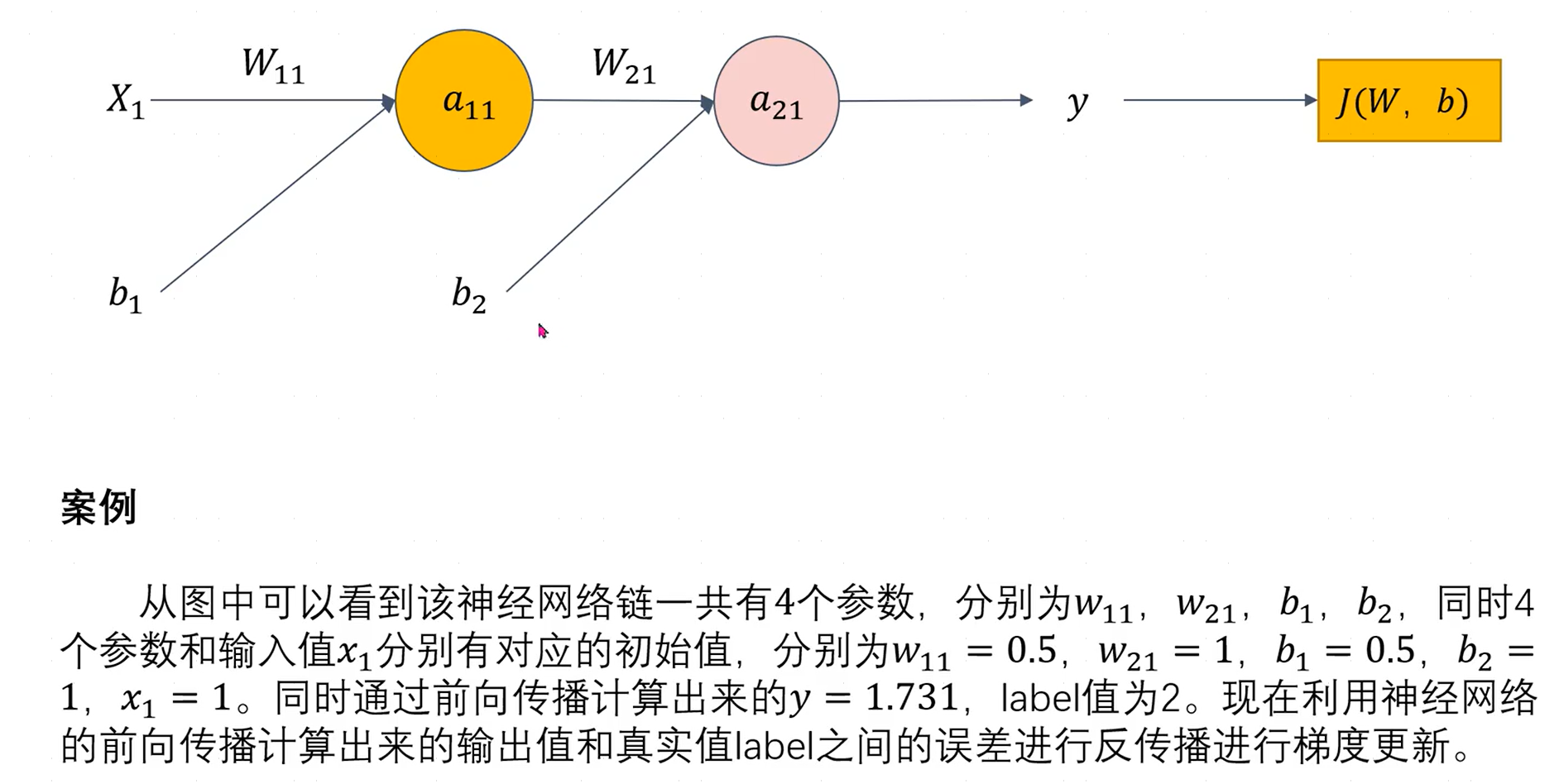
初始误差(使用均方误差函数): J ( x 1 ) = ( 2 − 1.731 ) 2 / 2 J(x_1)=(2-1.731)^2/2 J(x1)=(2−1.731)2/2




完成一轮更新后,损失函数的值更加逼近0,代表预测结果更加接近真实情况。
2.7模型训练大致流程梳理
在完成上文的学习后,可大致梳理出模型训练的大致流程:
- 1.以 N N N份的输入数据 X X X及其对应的结果 Y Y Y(同样为 N N N)份来搭建模型,常见模型如卷积神经网络。
- 2.开始训练,并设置模型训练的超参数,如学习率、训练轮次等。
- 2.1输入数据集 X X X,前向传播得到训练结果 Y ′ Y' Y′。
- 2.2根据真实结果 Y Y Y计算损失函数 J ( Θ ) J(Θ) J(Θ),其中,训练结果 Y ′ Y' Y′是关于参数集合 Θ Θ Θ的函数。
- 2.3利用梯度下降法进行反向传播,更新参数值,并重新进行预测。
- 2.4重复上述过程直到满足终止条件,从而得到模型。
- 3.利用模型对测试集进行测试,满足条件即可正常使用,否则调整超参数、模型类别等,重新训练模型。
三、线性回归
3.1基本原理
回归问题:预测数值型的目标值,本质是寻找自变量和因变量之间的关系,以便能够预测新的、未知的数据点的输出值。例如,根据房屋的面积、位置等特征预测其价格(房价预测、股票价价格预测、温度预测等)。

其中, x x x表示特征向量,而 y y y表示某一标签,即,通过特征对标签进行预测。
3.2案例
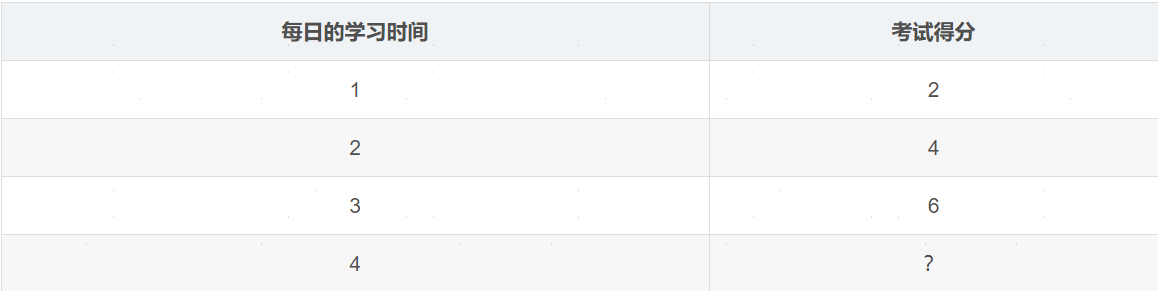
下图是小明每天学习的时间和最后考试的分数的数据。数据如下表所示,同时想知道小明假设学习4个小时最后考试会得多少分?
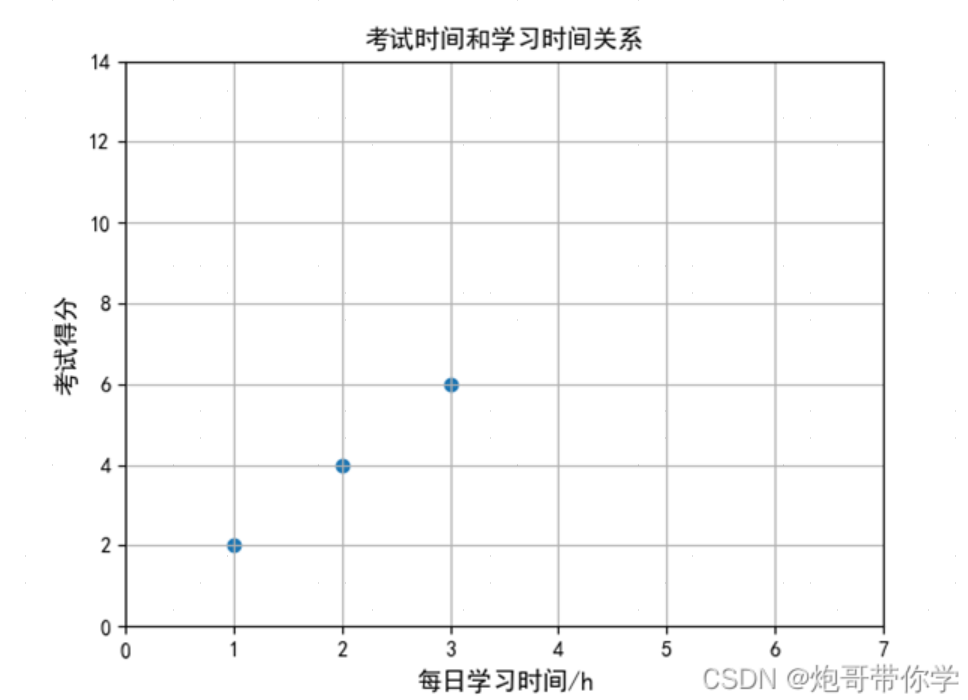
这是预测一个具体的数值的回归任务,将每日学习的时间和考试的得分用图画出来,大致可得出随着学习时间的增长,那么最后的考试的得分就会越高:
数据的输入只有一个,即为小明的学习时间,输出是考试的得分。因此可使用单特征线性模型进行预测,模型为:
f ( x ) = w x + b f(x)=wx+b f(x)=wx+b
此时的目的变为,求出最优的 w 、 b w、b w、b来表示输入与输出之间的关系,而最优指的即是输出的考试得分和真实的考试得分(也可以称为真实值或者标签)之间的差值越小越好,最好是0(显示生活中获取的数据存在噪声影响,数据之间的关系也存在一定误差,故而只能逼近0)。线性回归模型使用的损失函数即为上文中的均方误差函数:
此时问题转化为求出最优的 w 、 b w、b w、b来使得均方误差函数值最小。
此处采用最为原始的穷举法,即穷举 w 、 b w、b w、b的值并不断计算损失函数,使之最小:
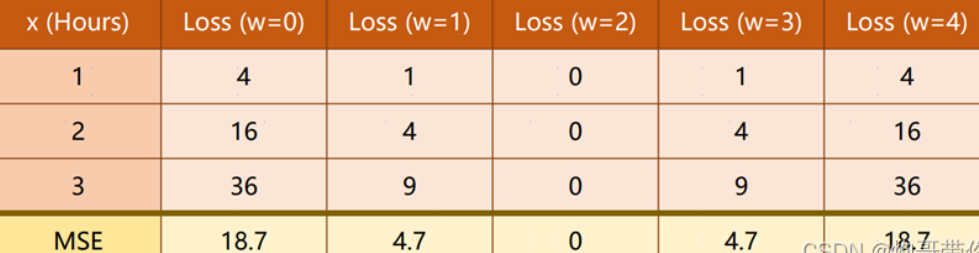
可得出,当 w = 2 、 b = 0 w=2、b=0 w=2、b=0时,误差函数为零,此时最优。而在现实生活中,处理问题是很复杂的,往往输入的特征也是多个的,那么就意味着有多个 w 、 b w、b w、b来表达输入和输出之间的关系,利用穷举法找到最优的 w w w是不现实的,此时可使用最小二乘法、梯度下降法。

![[Shell编程学习路线]——if条件语句(单,双,多分支结构)详细语法介绍](https://img-blog.csdnimg.cn/direct/be4467ce207541fdb175c897344aeb68.png)