《博主简介》
小伙伴们好,我是阿旭。专注于人工智能、AIGC、python、计算机视觉相关分享研究。
✌更多学习资源,可关注公-仲-hao:【阿旭算法与机器学习】,共同学习交流~
👍感谢小伙伴们点赞、关注!
《------往期经典推荐------》
一、AI应用软件开发实战专栏【链接】
| 项目名称 | 项目名称 |
|---|---|
| 1.【人脸识别与管理系统开发】 | 2.【车牌识别与自动收费管理系统开发】 |
| 3.【手势识别系统开发】 | 4.【人脸面部活体检测系统开发】 |
| 5.【图片风格快速迁移软件开发】 | 6.【人脸表表情识别系统】 |
| 7.【YOLOv8多目标识别与自动标注软件开发】 | 8.【基于YOLOv8深度学习的行人跌倒检测系统】 |
| 9.【基于YOLOv8深度学习的PCB板缺陷检测系统】 | 10.【基于YOLOv8深度学习的生活垃圾分类目标检测系统】 |
| 11.【基于YOLOv8深度学习的安全帽目标检测系统】 | 12.【基于YOLOv8深度学习的120种犬类检测与识别系统】 |
| 13.【基于YOLOv8深度学习的路面坑洞检测系统】 | 14.【基于YOLOv8深度学习的火焰烟雾检测系统】 |
| 15.【基于YOLOv8深度学习的钢材表面缺陷检测系统】 | 16.【基于YOLOv8深度学习的舰船目标分类检测系统】 |
| 17.【基于YOLOv8深度学习的西红柿成熟度检测系统】 | 18.【基于YOLOv8深度学习的血细胞检测与计数系统】 |
| 19.【基于YOLOv8深度学习的吸烟/抽烟行为检测系统】 | 20.【基于YOLOv8深度学习的水稻害虫检测与识别系统】 |
| 21.【基于YOLOv8深度学习的高精度车辆行人检测与计数系统】 | 22.【基于YOLOv8深度学习的路面标志线检测与识别系统】 |
| 23.【基于YOLOv8深度学习的智能小麦害虫检测识别系统】 | 24.【基于YOLOv8深度学习的智能玉米害虫检测识别系统】 |
| 25.【基于YOLOv8深度学习的200种鸟类智能检测与识别系统】 | 26.【基于YOLOv8深度学习的45种交通标志智能检测与识别系统】 |
| 27.【基于YOLOv8深度学习的人脸面部表情识别系统】 | 28.【基于YOLOv8深度学习的苹果叶片病害智能诊断系统】 |
| 29.【基于YOLOv8深度学习的智能肺炎诊断系统】 | 30.【基于YOLOv8深度学习的葡萄簇目标检测系统】 |
| 31.【基于YOLOv8深度学习的100种中草药智能识别系统】 | 32.【基于YOLOv8深度学习的102种花卉智能识别系统】 |
| 33.【基于YOLOv8深度学习的100种蝴蝶智能识别系统】 | 34.【基于YOLOv8深度学习的水稻叶片病害智能诊断系统】 |
| 35.【基于YOLOv8与ByteTrack的车辆行人多目标检测与追踪系统】 | 36.【基于YOLOv8深度学习的智能草莓病害检测与分割系统】 |
| 37.【基于YOLOv8深度学习的复杂场景下船舶目标检测系统】 | 38.【基于YOLOv8深度学习的农作物幼苗与杂草检测系统】 |
| 39.【基于YOLOv8深度学习的智能道路裂缝检测与分析系统】 | 40.【基于YOLOv8深度学习的葡萄病害智能诊断与防治系统】 |
| 41.【基于YOLOv8深度学习的遥感地理空间物体检测系统】 | 42.【基于YOLOv8深度学习的无人机视角地面物体检测系统】 |
| 43.【基于YOLOv8深度学习的木薯病害智能诊断与防治系统】 | 44.【基于YOLOv8深度学习的野外火焰烟雾检测系统】 |
| 45.【基于YOLOv8深度学习的脑肿瘤智能检测系统】 | 46.【基于YOLOv8深度学习的玉米叶片病害智能诊断与防治系统】 |
| 47.【基于YOLOv8深度学习的橙子病害智能诊断与防治系统】 | 48.【车辆检测追踪与流量计数系统】 |
| 49.【行人检测追踪与双向流量计数系统】 | 50.【基于YOLOv8深度学习的反光衣检测与预警系统】 |
| 51.【危险区域人员闯入检测与报警系统】 |
二、机器学习实战专栏【链接】,已更新31期,欢迎关注,持续更新中~~
三、深度学习【Pytorch】专栏【链接】
四、【Stable Diffusion绘画系列】专栏【链接】
五、YOLOv8改进专栏【链接】,持续更新中~~
六、YOLO性能对比专栏【链接】,持续更新中~
基本功能演示
基于YOLOv10深度学习的高密度人脸智能检测与统计系统【python源码+Pyqt5界面+数据集+训练代码】
摘要:
高密度人脸智能检测与统计系统在当今越来越注重实时监测和数据分析的社会中扮演着关键角色。该系统能够快速有效地检测和统计出特定场景中的人脸数量,为人流管理、安全监控和资源配置提供了重要信息。本文基于YOLOv10深度学习框架,通过16102张人脸相关图片,训练了一个进行人脸目标检测的模型,可以对密集人群的人脸进行实时检测。并基于此模型开发了一款带UI界面的高密度人脸智能检测与统计系统,更便于进行功能的展示。该系统是基于python与PyQT5开发的,支持图片、视频以及摄像头进行目标检测,并保存检测结果。本文提供了完整的Python代码和使用教程,给感兴趣的小伙伴参考学习,完整的代码资源文件获取方式见文末。
文章目录
- 基本功能演示
- 前言
- 一、软件核心功能介绍及效果演示
- 软件主要功能
- 界面参数设置说明
- 检测结果说明
- 主要功能说明
- (1)图片检测说明
- (2)视频检测说明
- (3)摄像头检测说明
- (4)保存图片与视频检测说明
- 二、模型的训练、评估与推理
- 1.YOLOv10简介
- YOLOv10优化点
- 双标签分配
- 模型设计改进
- 2. 数据集准备与训练
- 数据下载
- 数据处理
- 模型训练
- 3. 训练结果评估
- 4. 检测结果识别
- 【获取方式】
- 结束语
点击跳转至文末《完整相关文件及源码》获取
前言
高密度人脸智能检测与统计系统在当今越来越注重实时监测和数据分析的社会中扮演着关键角色。该系统能够快速有效地检测和统计出特定场景中的人脸数量,为人流管理、安全监控和资源配置提供了重要信息。在大数据和智能化管理趋势的推动下,此类系统对于优化人员布局、提高安全水平、加强对公共空间等高人流密集区域的管控等方面起到了积极作用。
其主要应用场景包括:
教育领域:自动统计课堂或考场中的在座学生人数,以便进行出勤管理。
商业零售:监测商场、店铺内的顾客数量,分析人流高峰,优化店内布局和工作人员配置。
交通枢纽:在机场、车站等人流量大的交通枢纽进行人脸统计,用于安全监控和人流疏导。
大型活动:在音乐会、体育赛事等大型活动中监测入场的观众人数,确保安全容量限制。
公共安全:辅助公共安全监控,在重要场合或特定时段对特定区域进行人脸计数和跟踪。
总结来说,高密度人脸智能检测与统计系统是一个多功能的智能化工具,它可以在不同的场景下提供人脸检测和人数统计服务。系统的引入,不仅提高了数据收集的准确性和工作效率,还在安全监控、资源规划和服务优化等方面提供了可靠的数据支持。随着社会对智能监控和分析需求的日益增长,此类系统的应用范围和技术将不断拓展和完善。
模型是基于Wider Face数据集【数据集介绍见下文】进行处理后,根据YOLOv10的目标检测技术训练的。最终基于python与Pyqt5开发了一款界面简洁的高密度人脸智能检测与统计系统,可支持图片、视频以及摄像头检测,同时可以将图片或者视频检测结果进行保存。
软件初始界面如下图所示:

检测结果界面如下:



一、软件核心功能介绍及效果演示
软件主要功能
1. 可用于实际场景中的人脸检测与数目统计;
2. 支持图片、视频及摄像头进行检测,同时支持图片的批量检测;
3. 界面可实时显示目标位置、目标总数、置信度、用时等信息;
4. 支持图片或者视频的检测结果保存;
界面参数设置说明

置信度阈值:也就是目标检测时的conf参数,只有检测出的目标置信度大于该值,结果才会显示;
交并比阈值:也就是目标检测时的iou参数,只有目标检测框的交并比大于该值,结果才会显示;
检测结果说明

显示标签名称与置信度:表示是否在检测图片上标签名称与置信度,显示默认不勾选,如果勾选则会在检测图片上显示标签名称与置信度;
显示标签名称与置信度结果如下:

不显示标签名称与置信度结果如下:

总目标数:表示画面中的人脸数目,可用于人数统计;
目标选择:可选择单个人脸目标进行位置信息、置信度查看。
目标位置:表示所选择目标的检测框,左上角与右下角的坐标位置。默认显示的是置信度最大的一个人脸目标信息;
主要功能说明
功能视频演示见文章开头,以下是简要的操作描述。
(1)图片检测说明
点击打开图片按钮,选择需要检测的图片,或者点击打开文件夹按钮,选择需要批量检测图片所在的文件夹,操作演示如下:
点击目标下拉框后,可以选定指定目标的结果信息进行显示。
点击保存按钮,会对检测结果进行保存,存储路径为:save_data目录下。
注:1.右侧目标位置默认显示置信度最大一个目标位置,可用下拉框进行目标切换。所有检测结果均在左下方表格中显示。
(2)视频检测说明
点击视频按钮,打开选择需要检测的视频,就会自动显示检测结果,再次点击可以关闭视频。
点击保存按钮,会对视频检测结果进行保存,存储路径为:save_data目录下。
(3)摄像头检测说明
点击打开摄像头按钮,可以打开摄像头,可以实时进行检测,再次点击,可关闭摄像头。
(4)保存图片与视频检测说明
点击保存按钮后,会将当前选择的图片【含批量图片】或者视频的检测结果进行保存。检测的图片与视频结果会存储在save_data目录下。
保存的检测结果文件如下:

二、模型的训练、评估与推理
1.YOLOv10简介

YOLOv10是YOLO最新一代版本的实时端到端目标检测算法。该算法在YOLO系列的基础上进行了优化和改进,旨在提高性能和效率之间的平衡。首先,作者提出了连续双分配方法,以实现NMS-free训练,从而降低了推理延迟并提高了模型的性能。其次,作者采用了全面的效率-准确性驱动的设计策略,对YOLO的各种组件进行了综合优化,大大减少了计算开销,并增强了模型的能力。实验结果表明,YOLOv10在各种模型规模下都取得了最先进的性能和效率表现。例如,YOLOv10-S比RT-DETR-R18快1.8倍,同时拥有更小的参数数量和FLOPs;与YOLOv9-C相比,YOLOv10-B的延迟减少了46%,参数减少了25%,但保持了相同的性能水平。
YOLOv10优化点
双标签分配

与一对一配对不同,一对多配对为每个真实标签分配一个预测标签,避免了后处理中的非极大抑制(NMS)。然而,它会导致弱监督,从而导致较低的准确度和收敛速度[75]。幸运的是,这种缺陷可以通过一对多配对进行补偿[5]。为了实现这一目标,我们在YOLO中引入了双标签分配来结合这两种策略的优点。具体来说,如上图所示,我们为 YOLO 添加了一个额外的一对一头部。它保留了一致的结构,并采用与原始的一对多分支相同的学习目标,但利用一对一匹配获得标签分配。在训练过程中,两个头与模型一起联合优化,允许骨干网络和脖子从一对多分支提供的丰富监督信号中受益。在推理过程中,我们丢弃一对多头,并使用一对一头进行预测。这使得 YOLO 能够端到端部署,而无需付出任何额外的推断成本。此外,在一对一匹配中,我们采用了顶部选择,实现了与匈牙利匹配[4]相同的性能,同时减少了额外的训练时间。
模型设计改进
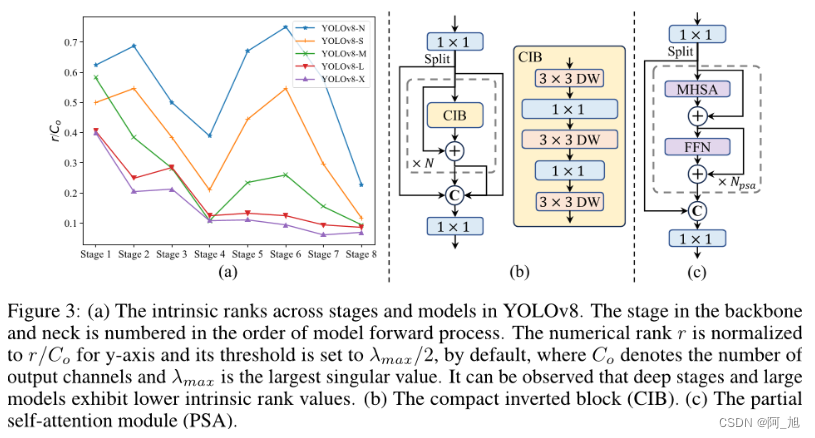
在模型设计方面,提出了以下几种改进点:
轻量级分类头: 通过对分类头进行轻量化设计,可以减少计算成本,而不会显著影响性能。
空间通道解耦降采样: 该方法通过分离空间和通道维度上的操作,提高了信息保留率,从而实现了更高的效率和竞争力。
排名引导块设计: 该方法根据各个阶段的冗余程度,采用不同的基本构建块,以实现更高效的模型设计。
大核深度卷积和部分自注意力模块: 这些模块可以在不增加太多计算开销的情况下提高模型的表现力。
2. 数据集准备与训练
数据下载
本文使用的是Wider Face数据集,数据集地址:http://shuoyang1213.me/WIDERFACE/
我们直接下载训练集(Training Images),验证集(Validation Images)以及标注文件(Face annotations)。下载好后进行解压,并按照如下结构配置文件:
├── wider_face: 存放数据集根目录├── WIDER_train: 训练集解压后的文件目录│ └── images: │ ├── 0--Parade: 对应该类别的所有图片│ ├── ........│ └── 61--Street_Battle: 对应该类别的所有图片│├── WIDER_val: 验证集解压后的文件目录│ └── images: │ ├── 0--Parade: 对应该类别的所有图片│ ├── ........│ └── 61--Street_Battle: 对应该类别的所有图片│└── wider_face_split: 标注文件解压后的文件目录├── wider_face_train.mat: 训练集的标注文件,MATLAB存储格式├── wider_face_train_bbx_gt.txt: 训练集的标注文件,txt格式├── wider_face_val.mat: 验证集的标注文件,MATLAB存储格式├── wider_face_val_bbx_gt.txt: 验证的标注文件,txt格式├── wider_face_test.mat: 测试集的标注文件,MATLAB存储格式├── wider_face_test_filelist.txt: 测试的标注文件,txt格式└── readme.txt: 标注文件说明
数据处理
其标注文件中分.mat和.txt两个版本,我们直接对txt格式文件进行处理,保存为YOLO模型需要的格式文件。
txt文件的标注格式说明如下:
Attached the mappings between attribute names and label values.blur:clear->0normal blur->1heavy blur->2expression:typical expression->0exaggerate expression->1illumination:normal illumination->0extreme illumination->1occlusion:no occlusion->0partial occlusion->1heavy occlusion->2pose:typical pose->0atypical pose->1invalid:false->0(valid image)true->1(invalid image)The format of txt ground truth.
File name
Number of bounding box
x1, y1, w, h, blur, expression, illumination, invalid, occlusion, pose
在txt说明文件中,给出了详细的标签格式说明:
第一行File name为图片的路径名称
第二行Number of bounding box为该图片中标注人脸的个数
接下来的Number of bounding box行信息为每个人脸的详细信息x1, y1, w, h, blur, expression, illumination, invalid, occlusion, pose
x1, y1, w, h, blur, expression, illumination, invalid, occlusion, pose的说明如下:
其中x1, y1, w, h代表人脸边界框的左上角x、y坐标,以及宽、高信息,注意这里是绝对坐标。
blur代表人脸的模糊程度,0代表清晰,1代表有点模糊,2代表很模糊。
expression代表表情,0代表正常的表情,1代表夸张的表情。
illumination代表光照条件,0代表正常光照,1代表极端的光照条件。
invalid这个参数其实有点迷,我通过绘制了一些invalid人脸图片发现,基本都是很小,很难分辨的人脸(不仔细看,看不出来的那种),个人觉得在使用时可以忽略掉invalid的人脸即为1的情况。
occlusion代表人脸的遮挡程度,0代表没有遮挡,1代表部分遮挡(1%-30%),2代表严重遮挡(30%以上)。
pose代表人脸的姿态,0代表典型姿态,1代表非典型姿态。
为了进一步方便理解,我们打开wider_face_train_bbx_gt.txt文件,比如第一行0–Parade/0_Parade_marchingband_1_849.jpg代表图片的路径,第二行的1代表在该图片中人脸的数量为1个。第三行449 330 122 149 0 0 0 0 0 0为人脸的详细信息。从第四行开始又是另一张图片,以此类推。
0--Parade/0_Parade_marchingband_1_849.jpg
1
449 330 122 149 0 0 0 0 0 0
0--Parade/0_Parade_Parade_0_904.jpg
1
361 98 263 339 0 0 0 0 0 0
0--Parade/0_Parade_marchingband_1_799.jpg
21
78 221 7 8 2 0 0 0 0 0
78 238 14 17 2 0 0 0 0 0
113 212 11 15 2 0 0 0 0 0
134 260 15 15 2 0 0 0 0 0
163 250 14 17 2 0 0 0 0 0
201 218 10 12 2 0 0 0 0 0
182 266 15 17 2 0 0 0 0 0
245 279 18 15 2 0 0 0 0 0
304 265 16 17 2 0 0 0 2 1
328 295 16 20 2 0 0 0 0 0
389 281 17 19 2 0 0 0 2 0
406 293 21 21 2 0 1 0 0 0
436 290 22 17 2 0 0 0 0 0
522 328 21 18 2 0 1 0 0 0
643 320 23 22 2 0 0 0 0 0
653 224 17 25 2 0 0 0 0 0
793 337 23 30 2 0 0 0 0 0
535 311 16 17 2 0 0 0 1 0
29 220 11 15 2 0 0 0 0 0
3 232 11 15 2 0 0 0 2 0
20 215 12 16 2 0 0 0 2 0
对于YOLO的目标检测,我们只需人脸的位置信息来进行目标检测模型训练即可,即上述的x1, y1, w, h信息,我们需要将其提取出来,并转换成YOLO格式的标注文件,转换代码如下:
import os
from tqdm import tqdm
import cv2def parse_wider_txt(data_root: str, split: str):"""refer to: torchvision.dataset.widerface.py:param data_root::param split::return:"""assert split in ['train', 'val'], f"split must be in ['train', 'val'], got {split}"txt_path = os.path.join(data_root, 'wider_face_split', f'wider_face_{split}_bbx_gt.txt')img_root = os.path.join(data_root, f'WIDER_{split}', 'images')with open(txt_path, "r") as f:lines = f.readlines()file_name_line, num_boxes_line, box_annotation_line = True, False, Falsenum_boxes, box_counter, idx = 0, 0, 0labels = []progress_bar = tqdm(lines)for line in progress_bar:line = line.rstrip()if file_name_line:img_path = linefile_name_line = Falsenum_boxes_line = Trueelif num_boxes_line:num_boxes = int(line)num_boxes_line = Falsebox_annotation_line = Trueelif box_annotation_line:box_counter += 1line_split = line.split(" ")line_values = [x for x in line_split]labels.append(line_values)if box_counter >= num_boxes:box_annotation_line = Falsefile_name_line = Trueif num_boxes == 0:print(f"in {img_path}, no object, skip.")else:# 根据个人意愿,在此加上对应处理方法print(img_path)print(labels)pass# 根据个人意愿,在此加上对应处理方法box_counter = 0labels.clear()idx += 1progress_bar.set_description(f"{idx} images")else:raise RuntimeError("Error parsing annotation file {}".format(txt_path))parse_wider_txt("/data/wider_face/","val")
调用parse_wider_txt时,传入data_root指向wider_face的路径,split表示要解析训练集还是验证集的标签文件(传入train或val)。
最终通过处理并剔除无用图片,并对图片进行数字编号重命名,得到一共包含16102张图片,其中训练集包含12881张图片,验证集包含3221张图片。
部分图像及标注如下图所示:



模型训练
图片数据的存放格式如下,在项目目录中新建datasets目录,同时将检测的图片分为训练集与验证集放入Data目录下。

同时我们需要新建一个data.yaml文件,用于存储训练数据的路径及模型需要进行检测的类别。YOLOv8在进行模型训练时,会读取该文件的信息,用于进行模型的训练与验证。data.yaml的具体内容如下:
train: D:\2MyCVProgram\5.YOLOv10Program\FaceDetectionV10\datasets\Data\train
val: D:\2MyCVProgram\5.YOLOv10Program\FaceDetectionV10\datasets\Data\valnc: 1
names: ['face']
注:train与val后面表示需要训练图片的路径,建议直接写自己文件的绝对路径。
数据准备完成后,通过调用train.py文件进行模型训练,epochs参数用于调整训练的轮数,batch参数用于调整训练的批次大小【根据内存大小调整,最小为1】,代码如下:
#coding:utf-8
from ultralytics import YOLOv10
import matplotlib
matplotlib.use('TkAgg')#模型配置文件
model_yaml_path = "ultralytics/cfg/models/v10/yolov10n.yaml"
#数据集配置文件
data_yaml_path = 'datasets/Data/data.yaml'
#预训练模型
pre_model_name = 'yolov10n.pt'
if __name__ == '__main__':#加载预训练模型model = YOLOv10(model_yaml_path).load(pre_model_name)#训练模型results = model.train(data=data_yaml_path,epochs=100,batch=8,name='train_v10')
3. 训练结果评估
在深度学习中,我们通常用损失函数下降的曲线来观察模型训练的情况。YOLOv8在训练时主要包含三个方面的损失:定位损失(box_loss)、分类损失(cls_loss)和动态特征损失(dfl_loss),在训练结束后,可以在runs/目录下找到训练过程及结果文件,如下所示:

各损失函数作用说明:
定位损失box_loss:预测框与标定框之间的误差(GIoU),越小定位得越准;
分类损失cls_loss:计算锚框与对应的标定分类是否正确,越小分类得越准;
动态特征损失(dfl_loss):DFLLoss是一种用于回归预测框与目标框之间距离的损失函数。在计算损失时,目标框需要缩放到特征图尺度,即除以相应的stride,并与预测的边界框计算Ciou Loss,同时与预测的anchors中心点到各边的距离计算回归DFLLoss。
本文训练结果如下:

我们通常用PR曲线来体现精确率和召回率的关系,本文训练结果的PR曲线如下。mAP表示Precision和Recall作为两轴作图后围成的面积,m表示平均,@后面的数表示判定iou为正负样本的阈值。mAP@.5:表示阈值大于0.5的平均mAP,可以看到本文模型目标检测的mAP@0.5值为0.673,结果还是可以的。

4. 检测结果识别
模型训练完成后,我们可以得到一个最佳的训练结果模型best.pt文件,在runs/train/weights目录下。我们可以使用该文件进行后续的推理检测。
图片检测代码如下:
#coding:utf-8
from ultralytics import YOLOv10
import cv2# 所需加载的模型目录
path = 'models/best.pt'
# 需要检测的图片地址
img_path = "TestFiles/000215.jpg"# 加载预训练模型
model = YOLOv10(path, task='detect')# 检测图片
results = model(img_path)
print(results)
res = results[0].plot(labels=False,conf=False)
# res = cv2.resize(res,dsize=None,fx=0.5,fy=0.5,interpolation=cv2.INTER_LINEAR)
cv2.imshow("YOLOv8 Detection", res)
cv2.waitKey(0)
执行上述代码后,会将执行的结果直接标注在图片上,结果如下:

以上便是关于此款高密度人脸智能检测与统计系统的原理与代码介绍。基于此模型,博主用python与Pyqt5开发了一个带界面的软件系统,即文中第二部分的演示内容,能够很好的支持图片、视频及摄像头进行检测,同时支持检测结果的保存。
关于该系统涉及到的完整源码、UI界面代码、数据集、训练代码、测试图片视频等相关文件,均已打包上传,感兴趣的小伙伴可以通过下载链接自行获取。
【获取方式】
关注下方名片G-Z-H:【阿旭算法与机器学习】,并发送【源码】即可获取下载方式
本文涉及到的完整全部程序文件:包括python源码、数据集、训练好的结果文件、训练代码、UI源码、测试图片视频等(见下图),获取方式见文末:

注意:该代码基于Python3.9开发,运行界面的主程序为
MainProgram.py,其他测试脚本说明见上图。为确保程序顺利运行,请按照程序运行说明文档txt配置软件运行所需环境。
关注下方名片GZH:【阿旭算法与机器学习】,并发送【源码】即可获取下载方式
结束语
以上便是博主开发的基于YOLOv10深度学习的高密度人脸智能检测与统计系统的全部内容,由于博主能力有限,难免有疏漏之处,希望小伙伴能批评指正。
关于本篇文章大家有任何建议或意见,欢迎在评论区留言交流!
觉得不错的小伙伴,感谢点赞、关注加收藏哦!