目录
- 1 ChatGPT的时代
- 2 CSIG企业行
- 3 议题&嘉宾介绍
- 3.1 对生成式人工智能的思考
- 3.2 对话式大型语言模型研究
- 3.3 文档图像处理中的底层视觉技术
- 4 观看入口
1 ChatGPT的时代
2015年,马斯克、美国创业孵化器Y Combinator总裁阿尔特曼、全球在线支付平台PayPal联合创始人彼得·蒂尔等硅谷科技大亨创立了OpenAI,公司核心宗旨在于实现安全的通用人工智能(AGI),使其有益于人类。
2022年12 月 1 日,OpenAI的联合创始人山姆·奥特曼在推特上公布ChatGPT并邀请人们免费试用

ChatGPT可以与人类进行谈话般的交互,可以回答追问,连续性的问题,承认其回答中的错误,指出人类提问时的不正确前提,拒绝回答不适当的问题,其性能大大超乎人们对弱人工智能的想象。
ChatGPT对社会发展的影响非常广泛,以下是ChatGPT的自白:
大家好,我是
ChatGPT,接下来介绍我对社会的影响。
- 我可以提高信息获取的效率:回答各种问题,包括科技、医学、教育、商业等各个领域的问题,帮助人们更快速、准确地获取所需信息;
- 我可以推动智能客服的发展:模拟人类对话,提供智能客服服务,使得客户能够更方便、快捷地解决问题,提高客户满意度和忠诚度;
- 我可以帮助语言障碍者:用多种语言回答问题,帮助语言障碍者更方便地获取信息和解决问题;
- 我可以改善教育体验:回答学生的问题,帮助学生更好地理解知识点,促进教育效果的提高;
- 我可以促进科研进展:帮助科学家更快速地获取资料,进行数据分析和建模,从而推动科研进展;
- 我可以促进文化交流:帮助人们学习其他国家和地区的语言和文化,促进跨文化交流和理解;
- …

2 CSIG企业行
虽然以ChatGPT为代表的AI黑科技产品一路狂飙、大规模落地,但仍然有一系列问题值得思考:
- 国内生成式人工智能还有哪些前沿研究成果?
- 跨模态、异构数据爆发式增长,如何高效处理?
- 大型语言模型未来的优化趋势是怎样的?
- 牵动多个应用领域的底层视觉技术有哪些优化空间?
- …

2023年3月18日,由中国图象图形协会(CSIG)主办,合合信息、CSIG文档图像分析与识别专业委员会联合承办的“CSIG图像图形企业行”系列活动将正式举办,通过搭建学术界与企业交流合作平台,为企业创新发展提供科技支撑,为图像图形领域高校师生提供与企业互动机会,集结产学研力量,共同推动图像图形领域的发展。

此次活动以图文智能处理与多场景应用技术展望为主题,聚焦图像文档处理中的结构建模、底层视觉技术、跨媒体数据协同应用、生成式人工智能及对话式大型语言模型等热门话题,特邀来自上海交大、复旦、厦门大学、中科大等知名院校的学者与合合信息技术团队一道,以直播的形式分享文档处理实践经验及NLP发展趋势,探讨ChatGPT与文档处理未来。
活动干货多多,全程亮点,欢迎大家关注!
3 议题&嘉宾介绍
3.1 对生成式人工智能的思考

- 嘉宾介绍:上海交通大学人工智能研究院常务副院长,人工智能教育部重点实验室主任,长江学者、国家杰青、IEEE Fellow。主要研究图像处理与机器学习,获国家科技进步二等奖、上海市科技进步一等奖、国家研究生教育成果二等奖。任中国图像图形学会常务理事、上海市图像图形学会理事长。
- 报告题目:《生成式人工智能》

生成式人工智能(Generative AI)是指一类可以自主创造新的数据、文本、图像、音频等内容的人工智能算法。
从 2017 年开始,GAI的主流技术生成对抗网络的应用陆续被人提出并不断完善。
GAN网络由生成器网络与判别器网络两部分共同构成。其核心思想是通过两个子网各自的最优变化,达到全局的最优效果。生成器网络的核心作用是通过一系列的网络结构生成可以骗过判别器网络的数据,判别器网络的核心作用是通过网络设计可以不被生成器网络生成的数据所骗过。生成器网络与判别器网络二者互相制约,共同成长,形成表现良好的网络结构。有时,网络内部还借助空洞卷积、注意力机制、特征融合、编码器等方法的一个或多个特性进行优化。生成器网络与判别器网络共同训练的过程如图所示
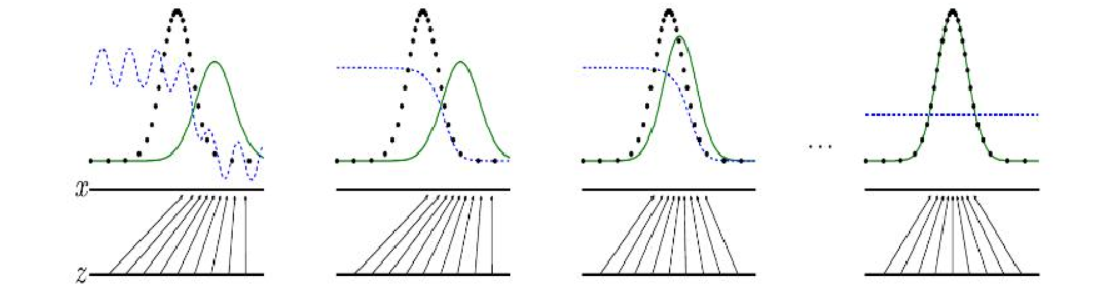
图中蓝色虚线代表判别器分布,黑色虚线代表真实数据,绿线实线代表生成器生成的数据。从左往右依次展示了生成对抗网络模型训练的过程中,生成器网络与判别器网络的变化过程。可见随着训练迭代次数的增加,生成器网络生成的数据逐渐接近数据库中原始的真实数据。直到判别器网络已经不能很好的判断出,它接收到的两种数据,哪个是生成器生成的数据,哪个是数据库中真实的数据,此时,生成对抗网络达到最佳效果,停止迭代。
生成式人工智能技术的出现,为我们创造更多样、更富创意的内容提供了新的可能性。举例而言
- 图像/视频生成:生成对抗网络(GAN)可以用于生成逼真的图像,如 Deepfake 与 NVIDIA 的 StyleGAN就是一种应用 GAN 的技术,可以生成高分辨率的逼真虚假视频;
- 文本生成:自回归模型可以用于生成连续文本,如 OpenAI 的 GPT 模型可以生成类似于自然语言的文本,可以用于自动生成文章、小说等;
- 音频生成:WaveNet 是一种基于神经网络的音频合成模型,可以用于合成逼真的语音、音乐等;
- 艺术创作:GAN 可以被用于生成逼真的艺术作品,如 NVIDIA 的 GauGAN 可以将简单的手绘图转换为逼真的景观照片;
- 游戏设计:生成式人工智能可以用于游戏设计,自动生成游戏地图、角色等元素,如《MineRL》等游戏就使用了生成式人工智能技术。
总而言之,生成式人工智能技术的出现,为电影、游戏、音乐、小说等领域的创作提供了新的可能性。随着技术的不断发展,我们可以期待更多的应用场景出现。

然而,生成式人工智能技术也存在着一些潜在的风险和挑战:生成式模型可能会被用于制造虚假信息、混淆公众视听,影响社会稳定等。因此,我们需要在使用生成式人工智能技术时保持警惕,同时积极探索如何加强对这种技术的监管和管理,确保其能够为社会带来更多正面的价值。

杨小康教授正是着力于生成式人工智能技术,分享团队对元宇宙和生成式人工智能发展趋势的思考,并对团队在流体现象模拟推理、物理环境持续预测学习、强化学习中世界模型表征解耦、虚拟数字人重建与驱动等方面的生成式人工智能初步成果进行介绍,欢迎大家进一步了解。
3.2 对话式大型语言模型研究

- 嘉宾介绍:复旦大学计算机学院教授,担任中国中文信息学会理事、上海市计算机学会自然语言处理专委会主任等,主要研究方向为自然语言处理基础技术和基础模型,发表CCF A/B类论文80余篇,被引用1万余次,获得ACL 2017杰出论文奖(CCF A类)、CCL 2019最佳论文奖、《中国科学:技术科学》2021年度高影响力论文奖,有5篇论文入选ACL/EMNLP等会议的最有影响力论文,主持开发了开源框架FudanNLP和FastNLP,已被国内外数百家单位使用,发布了CPT、BART-Chinese、ElasticBERT等中文预训练模型,在中文模型中下载量排名前列。
- 报告题目:《对话式大型语言模型》
对话式大型语言模型是一种非常有用的技术,可以模拟人类对话的能力。它们能够理解自然语言,以及根据给定的上下文和语境生成自然的响应。这些模型的一个很大的优点是,它们可以大大减少人类与机器之间的沟通障碍。这对于许多应用程序都非常有用,例如:
- 智能助手:Apple Siri、Amazon Alexa、Google Assistant等,它们能够与用户进行自然语言对话,回答问题,执行任务,提供信息等等。

- 在线客服:许多企业都使用聊天机器人来与客户进行对话,解答问题,提供支持等等,从而提高客户满意度和效率;
- 聊天机器人:微软的 XiaoIce、OpenAI的 GPT 等,它们可以与用户进行自然对话,提供有趣的聊天体验。
此外,对话式大型语言模型还在情感分析、文本摘要、自然语言理解等方面都具有非常广泛的应用。最近大家关注的ChatGPT,就是专门用于聊天和对话的语言模型。ChatGPT是基于GPT-3开发的,具有强大的对话能力,能够理解语言上下文,并能够生成富有表现力和连贯的响应。所谓GPT,全称是Generative Pre-trained Transformer,这是一种基于Transformer的语言模型。
Transformer又是什么呢?它是一种用于自然语言处理和其他序列到序列(sequence-to-sequence)任务的神经网络架构。它于2017年由谷歌的研究人员提出,被认为是自然语言处理领域的一项重大突破。
Transformer基于注意力机制(Attention Mechanism)构建,其核心思想是在序列中进行全局信息的交互和捕捉,而不是像以往的循环神经网络(RNN)一样在序列中逐个位置处理信息。Transformer通过多个自注意力层(Self-Attention Layer)进行信息的交互和表示,而每个自注意力层包含了注意力机制的三个部分:查询(query)、键(key)和值(value)。

具体来说,对于一个输入序列,Transformer将其转换为多个词向量(word embeddings),然后通过自注意力层进行特征提取。在自注意力层中,查询向量通过与所有键向量的相似度计算来计算注意力分数,这些分数用于加权求和值向量,最终得到每个位置的输出向量。然后,这些输出向量被馈送到下一个自注意力层或全连接层进行后续处理。
相比于传统的序列模型,Transformer的优点在于可以并行处理输入序列,从而加速模型的训练和推断。此外,Transformer还能够有效地处理长序列,因为它可以在不受时间限制的情况下一次性处理整个序列,而不需要像RNN那样进行逐个位置的处理。
更多技术方面的内容可以期待一下邱锡鹏教授的报告,报告里,邱教授将以ChatGPT为例介绍其强大的意图理解能力、流畅的对话能力和丰富的世界知识,并讲解通用人工智能助手广阔的研究和应用前景。同时,阐述对话式大型语言模型的能力评测、能力演化路线分析以及如何在下游任务中更高效利用大模型的能力。欢迎感兴趣的同学参加!
3.3 文档图像处理中的底层视觉技术

- 嘉宾介绍:上海交通大学模式识别与智能系统博士。长期从事文字识别(包括手写/OCR),图像处理研究,CSIG文档图像分析与识别专委会常务委员。近年来,带领团队获得过ICDAR19大会表格检测竞赛冠军,中国图象图形学会2021年度科技进步二等奖等奖项,现任合合信息图像算法研发总监。
- 报告题目:《文档图像处理中的底层视觉技术》
底层视觉(Low-level vision)主要研究如何提高或恢复各类场景下的图像/视频内容,如
- 图像去噪:主要解决图像中存在的噪声问题,使图像更加清晰和易于处理,广泛应用于图像处理、计算机视觉、医学成像、遥感图像处理等领域。
- 图像超分辨率:指通过一系列的算法和技术将低分辨率图像转换为高分辨率图像的过程。超分辨率技术的原理可以简单地概括为利用算法将低分辨率图像转换为高分辨率图像。这个过程中,需要根据一些规则和约束条件来进行图像重建,以尽可能地提高重建后图像的质量。如下图所示

超分辨率也是近年来视觉方向非常热门的话题。在实际应用中,超分辨率技术的实现通常分为两个步骤:训练阶段——利用大量的低分辨率和高分辨率图像对来训练一个神经网络模型,以学习图像间的映射关系;测试阶段——输入低分辨率图像后,通过训练好的模型进行重建,输出高分辨率图像。
超分辨率技术还包含大量的图像处理方法,例如
-
图像插值
图像插值是超分辨率技术中最基本的方法,它通过在像素之间插值来增加图像的分辨率。常见的插值算法包括双线性插值、双三次插值等,它们可以通过计算周围像素的加权平均值来填充新的像素值。虽然图像插值可以增加图像的分辨率,但是它并不能提高图像的质量,只是增加了图像的大小。
-
图像重建
图像重建是超分辨率技术中更高级的方法,它利用多张低分辨率图像来重建出一张高分辨率图像。常见的图像重建算法包括基于插值的重建、基于统计的重建、基于边缘的重建等。这些算法利用低分辨率图像中的一些特征来推断高分辨率图像中的信息,从而实现图像的重建。
-
神经网络
近年来,神经网络模型成为超分辨率技术中最常用的方法。通过训练神经网络模型,可以学习到图像之间的映射关系,从而实现低分辨率图像到高分辨率图像的转换。常见的神经网络模型包括卷积神经网络(CNN)、循环神经网络(RNN)等。这些模型可以通过反向传播算法进行训练,并在测试阶段进行图像重建。
更多相关的技术理论将在郭丰俊博士的报告中展开,同时,郭丰俊博士将分享合合信息在文档图像处理系统中所做的底层视觉技术研发工作,从技术本身的应用和对下游任务的影响的角度,阐述底层视觉技术的价值与思考。
4 观看入口
合合信息视频号18号下午14:00直播,欢迎感兴趣的同学来交流

议程
| 时间 | 议题 | 发言人 |
|---|---|---|
| 14:00-14:05 | 《合合信息 欢迎致词》 | 合合信息 领导 Micheal |
| 14:05-14:10 | 《CSIG文档图像分析与识别专委会主任 致词》 | 华南理工大学 金连文教授 |
| 14:10-14:40 | 《生成式人工智能》 | 上海交通大学 杨小康教授 |
| 14:40-15:10 | 《对话式大型语言模型》 | 复旦大学 邱锡鹏教授 |
| 15:10-15:40 | 《复杂跨媒体数据协同分析与应用》 | 厦门大学 纪荣嵘教授 |
| 15:40-16:10 | 《面向图像文档的复杂结构建模研究》 | 中国科学技术大学 杜俊 |
| 16:10-16:40 | 《文档图像处理中的底层视觉技术》 | 合合信息 郭丰俊 |
| 16:40-17:15 | 15分钟答疑 |