前言
近年来,大语言模型(Large Models, LLMs)受到学术界和工业界的广泛关注,得益于其在各种语言生成任务上的出色表现,大语言模型推动了各种人工智能应用(例如ChatGPT、Copilot等)的发展。然而,大模型的落地应用受到其较大的推理开销的限制,对部署资源、用户体验、经济成本都带来了巨大挑战。大模型压缩,即将大模型“瘦身”后塞进资源受限的场景,以减少模型存储、访存和计算开销。在尽量不损失模型性能的前提下,提高大模型推理吞吐速度,使大模型在物联网边缘设备、嵌入式机器人、离线移动应用等边、端场景中保持优秀的推理性能和功耗表现。就在最近,来自清华大学电子工程系、无问芯穹和上海交通大学的研究团队展开了一次量化方案的“大摸底”,在《Evaluating Quantized Large Language Models 》(Qllm-Eval)这项工作中评估了不同模型、量化不同张量类型、使用不同量化方法、在不同任务上的性能,本篇工作已被ICML'24接收。Qllm-Eval列举出很多大模型落地环节应当关注的模型能力,对产业中的模型量化工作实践,比如如何选取量化方法、针对哪些层或组件进行优化等问题具有指导意义,下图是罗列的一些重要知识点。 添加图片注释,不超过 140 字(可选)
添加图片注释,不超过 140 字(可选)
训练后量化(Post-Training Quantization,PTQ)
大模型推理过程包括两个阶段:Prefill阶段和Decoding阶段:
- Prefill阶段的主要算子为矩阵-矩阵乘(GEMM),其推理速度受限于计算速度。
- Decoding阶段的主要算子为矩阵-向量乘(GEMV),其推理速度主要受限于访存速度。
- 当处理涉及长文本或大批量大小的任务时,KV Cache的存储开销会超过权重的存储开销。
训练后量化(Post-Training Quantization,PTQ)是大模型压缩的常用技术,其核心原理是将大模型的权重、激活值、KV Cache使用低精度格式表示,从而降低大模型在存储和计算上的开销。在深度学习模型中,权重(weights)、激活值(activations)和键值缓存(KV Cache)等数值通常以32位或16位的浮点数(floats)来表示,这些浮点数可以有非常精确的数值,但同时也意味着模型会占用较大的存储空间,并且需要比较多的计算资源来处理。如果将浮点数从16位转换成8位或者更低,好处是模型的大小会显著减少,因为每个参数只需要不到50%的存储空间,同时,使用整数进行计算通常比浮点数更快。
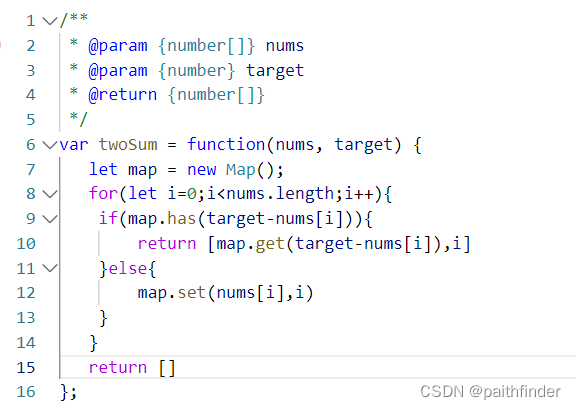
不同量化方式给大模型带来的影响
但量化压缩通常是有损的,不同量化方式的设计会对模型性能带来不同的影响。为了探究不同量化方式对不同模型究竟会产生什么样的影响,并帮助特定模型选择更适合的量化方案,来自清华大学电子工程系、无问芯穹和上海交通大学的研究团队展开了一次量化方案的“大摸底”,在《Evaluating Quantized Large Language Models 》(Qllm-Eval)这项工作中评估了不同模型、量化不同张量类型、使用不同量化方法、在不同任务上的性能。Qllm-Eval评测的量化张量类型包括权重(W)、权重-激活(WA)、KV Cache(KV),通过评估 PTQ 对 11 个系列模型(包括 OPT、LLaMA2、Falcon、Bloomz、Mistral、ChatGLM、Vicuna、LongChat、StableLM、Gemma 和 Mamba)的权重、激活和 KV 缓存的影响,对这些因素进行了全面评估,覆盖了从 125M 到 180B的参数范围。另外还评估了最先进的 (SOTA) 量化方法,以验证其适用性。同时在大量实验的基础上,系统总结了量化的效果,提出了应用量化技术的建议,并指出了大模型量化工作未来的发展方向。
大模型推理效率瓶颈分析
目前主流的大语言模型都是基于Transformer架构进行设计。通常来说,一个完整的模型架构由多个相同结构的Transformer块组成,每个Transformer块则包含多头自注意力(Multi-Head Self-Attention, MHSA)模块、前馈神经网络(Feed Forward Network, FFN)和层归一化(Layer Normalization,LN)操作。大语言模型通常自回归(Auto-regressive)的方式生成输出序列,即模型逐个词块生成,且生成每个词块时需要将前序的所有词块(包括输入词块和前面已生成的词块)全部作为模型的输入。因此,随着输出序列的增长,推理过程的开销显著增大。为了解决该问题,KV缓存技术被提出,该技术通过存储和复用前序词块在计算注意力机制时产生的Key和Value向量,减少大量计算上的冗余,用一定的存储开销换取了显著的加速效果。基于KV缓存技术,通常可以将大语言模型的推理过程划分为两个阶段(分别如下左图和右图所示): 添加图片注释,不超过 140 字(可选)
添加图片注释,不超过 140 字(可选)
左:预填充(Prefilling)阶段:大语言模型计算并存储输入序列中词块的Key和Value向量,并生成第一个输出词块。右:解码(Decoding)阶段:大语言模型利用KV缓存技术逐个生成输出词块,并在每步生成后存储新词块的Key和Value向量。
数据层优化技术
数据层优化技术可以划分为两大类:输入压缩(Input Compression)和输出规划(Output Organization)。
输入压缩技术
在实际利用大语言模型做回答时,通常会在输入提示词中加入一些辅助内容来增强模型的回答质量,例如,上下文学习技术(In-Context Learning,ICL)提出在输入中加入多个相关的问答例子来教模型如何作答。然而,这些技术不可避免地会增长输入词提示的长度,导致模型推理的开销增大。为了解决该问题,输入压缩技术通过直接减小输入的长度来优化模型的推理效率。本综述将该类技术进一步划分为四个小类,分别为:
- 提示词剪枝(Prompt Pruning):通常根据设计好的重要度评估指标删除输入提示词中不重要的词块、句子或文段,对被压缩的输入提示词执行在线压缩。
- 提示词总结(Prompt Summary):通过对输入提示词做文本总结任务,在保证其语义信息相同地情况下缩短输入的长度。该压缩过程通常也是在线执行的。
- 基于软提示词的压缩(Soft Prompt-based Compression):通过微调训练的方式得到一个长度较短的软提示词,代替原先的输入提示词(在线执行)或其中固定的一部分内容(离线执行)。其中,软提示词指连续的、可学习的词块序列,可以通过训练的方式学习得到。
- 检索增强生成(Retrieval-Augmented Generation):通过检索和输入相关的辅助内容,并只将这些相关的内容加入到输入提示词中,来降低原本的输入长度(相比于加入所有辅助内容)。
输出规划技术
传统的生成解码方式是完全串行的,输出规划技术通过规划输出内容,并行生成某些部分的的输出来降低端到端的推理延时。以该领域最早的工作“思维骨架”(Skeleton-of-Thought,以下简称SoT)为例,SoT技术的核心思想是让大语言模型自行规划输出的并行结构,并基于该结构进行并行解码,提升硬件利用率,减少端到端生成延时。具体来说,如下图所示,SoT将大语言模型的生成分为两个阶段:在提纲阶段,SoT通过设计的提示词让大语言模型输出答案的大纲;在分点扩展阶段,SoT让大语言模型基于大纲中的每一个分点并行做扩展,最后将所有分点扩展的答案合并起来。SoT技术让包含LLaMA-2、Vicuna模型在内的9种主流大语言模型的生成过程加速1.9倍以上,最高可达2.39倍。在SoT技术发布后,一些研究工作通过微调大语言模型、前后端协同优化等方式优化输出规划技术,达到了更好的加速比和回答质量之间的权衡点。 添加图片注释,不超过 140 字(可选)
添加图片注释,不超过 140 字(可选)
未来方向
本文进一步总结了未来的四个关键应用场景,并讨论了高效性研究在这些场景中的重要性:
- 智能体和多模型框架。在最近的研究中,大语言模型智能体和多模型协同框架受到了许多关注,这类技术可以提升大语言模型的应用能力,使得模型能更好地服务于人类。然而模型的数量增多,以及输入到模型中的指令变长,都会使得智能体或框架系统的推理效率变低。因此需要面向这些框架和场景进行大模型的推理效率优化。
- 长文本场景。随着输入模型文本变得越来越长,大语言模型的效率优化需求变得愈发提升。目前在数据层、模型层和系统层均有相关的技术来优化长文本场景下大语言模型的推理效率,其中设计Transformer的替代新架构受到了许多关注,然而这类架构还未被充分探索,其是否能匹敌传统的Transformer模型仍未清楚。
- 边缘端部署。最近,许多研究工作开始关注于将大语言模型部署到边缘设备上,例如移动手机。一类工作致力于设计将大模型变小,通过直接训练小模型或模型压缩等途径达到该目的;另一类工作聚焦于系统层的优化,通过算子融合、内存管理等技术,直接将70亿参数规模的大模型成功部署到移动手机上。
- 安全-效率协同优化。除了任务精度和推理效率外,大语言模型的安全性也是一个需要被考量的指标。当前的高效性研究均未考虑优化技术对模型安全性的影响。若这些优化技术对模型的安全性产生了负面影响,一个可能的研究方向就是设计新的优化方法,或改进已有的方法,使得模型的安全性和效率能一同被考量。
高性价比GPU算力:https://www.ucloud.cn/site/active/gpu.html?ytag=gpu_wenzhang_0619_zhihu
![【2024最新华为OD-C/D卷试题汇总】[支持在线评测] LYA 的幸运游戏(100分) - 三语言AC题解(Python/Java/Cpp)](https://img-blog.csdnimg.cn/direct/ffb92a99a05d49d6acc4fac759b84a66.png)
![【2024最新华为OD-C/D卷试题汇总】[支持在线评测] 部门组队编程(200分) - 三语言AC题解(Python/Java/Cpp)](https://img-blog.csdnimg.cn/direct/3fdc1bec4c6f4205b6d3a0d646eb4d01.png)