为了最大程度降低 PX 使用难度,OceanBase 3.1 版起,parallel_max_servers 参数废弃。
用户只需用好 parallel_servers_target 即可。
target 的用途
用一个酒吧的例子来粗略理解下 parallel_servers_target 的意思:
target 先生开了一个酒吧。来这个酒吧里喝酒的都是一群一群的人。酒吧最多容纳100个人 (parallel_servers_target = 100)。
如果酒吧里面一个人都没有(比如刚刚开门),那么来的第一群人总是让他们进去,并且:
- 如果他们的人数多于100人,则放100人进去。
- 如果小于100人,例如 30 个人( /*+ parallel(30) */),则有多少放进去多少。
如果酒吧里已经有人在喝酒了,那么新来的一群人,target 会数一数:
- 如果进去后酒吧装不下,则不让他们进去。
- 反之,只要装得下,就放进去。
通过这种方式,target 先生可以保证:
- 酒吧不会空闲:即使来的每一群人都超过100人,他也有生意做。
- 酒吧不会太挤:他的策略可以保证酒吧里的人总是不会超过100人。
真实线程数计算
最简单的 select 场景
select /*+ parallel(30) */ * from t1;
假设 parallel_servers_target = 100, /*+ parallel(30) */,那么会启动 30 个线程来执行 SQL。
多个 dfo 的复杂场景
select /*+ parallel(30) / count() from t1, t2 group by t1.c1, t2.c1;
假设 parallel_servers_target = 100, /*+ parallel(30) */,那么一般来说会启动 60 个线程来执行 SQL。下面的 dfo 使用 30 个线程,上面的 dfo 使用 30 个线程,他们之间形成 producer-consumer 关系。
target 相对较小的场景
select /*+ parallel(30) */ * from t1;
假设 parallel_servers_target = 10, /*+ parallel(30) */,那么会启动 10 个线程来执行 SQL,而不是启动 30 个线程来执行 SQL!
复杂 SQL里,假设 parallel_servers_target = 10, /*+ parallel(30) */,那么会启动 10 个线程来执行 SQL,并且下面的 dfo 使用 5 个线程,上面的 dfo 使用 5 个线程(并不是每个 dfo 使用 10 个线程,没那么多资源)
更特殊的场景
- 某些计划形态,会同时调度 3 个 dfo 起来,假设
parallel_servers_target = 12, /*+ parallel(30) */,那么 dfo1 使用 4 个线程,dfo2 使用 4 个线程,dfo3 使用 4 个线程。 - 某些 dfo 只能用一个线程执行(计划上会有 local 标记,如2阶段聚集计算的第二阶段),线程的分配就更复杂了
复杂例子
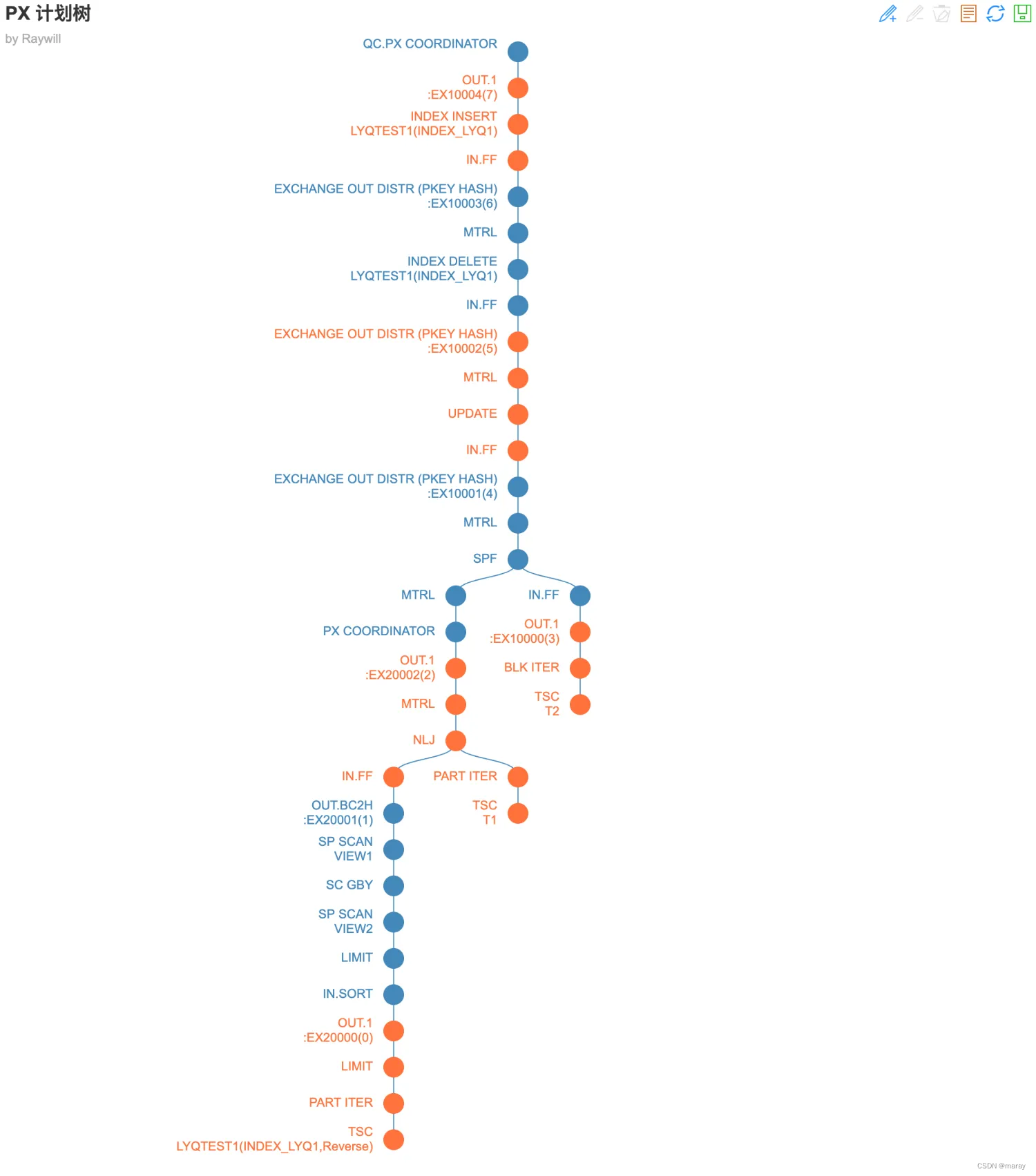
update /*+ parallel(10) enable_parallel_dml */ lyqtest1 t1 set t1.num = (select num from lyqtest t2 where t2.num=3) + t1.num where pk_id < (select max(num) from lyqtest1) +1000========================================================================================================
|ID|OPERATOR |NAME |EST. ROWS|COST |
--------------------------------------------------------------------------------------------------------
|0 |PX COORDINATOR | |999 |38008|
|1 | EXCHANGE OUT DISTR |:EX10004 |999 |31276|
|2 | INDEX INSERT |LYQTEST1(INDEX_LYQ1) |999 |30603|
|3 | EXCHANGE IN DISTR | |999 |30465|
|4 | EXCHANGE OUT DISTR (PKEY HASH) |:EX10003 |999 |29792|
|5 | MATERIAL | |999 |29119|
|6 | INDEX DELETE |LYQTEST1(INDEX_LYQ1) |999 |28577|
|7 | EXCHANGE IN DISTR | |999 |28439|
|8 | EXCHANGE OUT DISTR (PKEY HASH) |:EX10002 |999 |27766|
|9 | MATERIAL | |999 |27093|
|10| UPDATE | |999 |26551|
|11| EXCHANGE IN DISTR | |999 |26413|
|12| EXCHANGE OUT DISTR (PKEY HASH) |:EX10001 |999 |25740|
|13| MATERIAL | |999 |19008|
|14| SUBPLAN FILTER | |999 |13593|
|15| MATERIAL | |999 |13451|
|16| PX COORDINATOR | |999 |8035 |
|17| EXCHANGE OUT DISTR |:EX20002 |999 |1303 |
|18| MATERIAL | |999 |630 |
|19| NESTED-LOOP JOIN | |999 |88 |
|20| EXCHANGE IN DISTR | |1 |16 |
|21| EXCHANGE OUT DISTR (BC2HOST) |:EX20001 |1 |15 |
|22| SUBPLAN SCAN |VIEW1 |1 |13 |
|23| SCALAR GROUP BY | |1 |13 |
|24| SUBPLAN SCAN |VIEW2 |1 |13 |
|25| LIMIT | |1 |13 |
|26| EXCHANGE IN MERGE SORT DISTR| |1 |13 |
|27| EXCHANGE OUT DISTR |:EX20000 |1 |12 |
|28| LIMIT | |1 |12 |
|29| PX PARTITION ITERATOR | |1 |11 |
|30| TABLE SCAN |LYQTEST1(INDEX_LYQ1,Reverse)|1 |11 |
|31| PX PARTITION ITERATOR | |999 |93 |
|32| TABLE SCAN |T1 |999 |79 |
|33| EXCHANGE IN DISTR | |1 |5 |
|34| EXCHANGE OUT DISTR |:EX10000 |1 |4 |
|35| PX BLOCK ITERATOR | |1 |4 |
|36| TABLE SCAN |T2 |1 |4 |
========================================================================================================Outputs & filters:
-------------------------------------0 - output(nil), filter(nil)1 - output(nil), filter(nil), dop=102 - output(nil), filter(nil), columns([{LYQTEST1: ({INDEX_LYQ1: (T1.NUM, T1.PK_ID, T1.__pk_increment)})}]), partitions(p[0-2]), conv_exprs([column_conv(NUMBER,PS:(38,0),NOT NULL,? + T1.NUM)], [T1.PK_ID], [T1.__pk_increment])3 - output([T1.NUM], [T1.PK_ID], [T1.__pk_increment], [column_conv(NUMBER,PS:(38,0),NOT NULL,? + T1.NUM)], [PARTITION_ID]), filter(nil)4 - (#keys=1, [column_conv(NUMBER,PS:(38,0),NOT NULL,? + T1.NUM)]), output([T1.NUM], [T1.PK_ID], [T1.__pk_increment], [column_conv(NUMBER,PS:(38,0),NOT NULL,? + T1.NUM)], [PARTITION_ID]), filter(nil), dop=105 - output([T1.NUM], [T1.PK_ID], [T1.__pk_increment], [column_conv(NUMBER,PS:(38,0),NOT NULL,? + T1.NUM)]), filter(nil)6 - output([T1.NUM], [T1.PK_ID], [T1.__pk_increment], [column_conv(NUMBER,PS:(38,0),NOT NULL,? + T1.NUM)]), filter(nil), table_columns([{LYQTEST1: ({INDEX_LYQ1: (T1.NUM, T1.PK_ID, T1.__pk_increment)})}])7 - output([T1.NUM], [T1.PK_ID], [T1.__pk_increment], [column_conv(NUMBER,PS:(38,0),NOT NULL,? + T1.NUM)], [PARTITION_ID]), filter(nil)8 - (#keys=1, [T1.NUM]), output([T1.NUM], [T1.PK_ID], [T1.__pk_increment], [column_conv(NUMBER,PS:(38,0),NOT NULL,? + T1.NUM)], [PARTITION_ID]), filter(nil), dop=109 - output([T1.NUM], [T1.PK_ID], [T1.__pk_increment], [column_conv(NUMBER,PS:(38,0),NOT NULL,? + T1.NUM)]), filter(nil)10 - output([T1.NUM], [T1.PK_ID], [T1.__pk_increment], [column_conv(NUMBER,PS:(38,0),NOT NULL,? + T1.NUM)]), filter(nil), table_columns([{LYQTEST1: ({LYQTEST1: (T1.PK_ID, T1.__pk_increment, T1.NUM, T1.NAME, T1.MONEY)})}]),update([T1.NUM=column_conv(NUMBER,PS:(38,0),NOT NULL,? + T1.NUM)])11 - output([T1.PK_ID], [T1.__pk_increment], [T1.NUM], [T1.NAME], [T1.MONEY], [column_conv(NUMBER,PS:(38,0),NOT NULL,? + T1.NUM)], [PARTITION_ID]), filter(nil)12 - (#keys=1, [T1.PK_ID]), output([T1.NUM], [T1.PK_ID], [T1.__pk_increment], [column_conv(NUMBER,PS:(38,0),NOT NULL,? + T1.NUM)], [T1.NAME], [T1.MONEY], [PARTITION_ID]), filter(nil), is_single, dop=113 - output([T1.NUM], [T1.PK_ID], [T1.__pk_increment], [column_conv(NUMBER,PS:(38,0),NOT NULL,? + T1.NUM)], [T1.NAME], [T1.MONEY]), filter(nil)14 - output([T1.NUM], [T1.PK_ID], [T1.__pk_increment], [?], [T1.NAME], [T1.MONEY]), filter(nil), exec_params_(nil), onetime_exprs_([subquery(1)]), init_plan_idxs_(nil)15 - output([T1.NUM], [T1.PK_ID], [T1.__pk_increment], [T1.NAME], [T1.MONEY]), filter(nil)16 - output([T1.NUM], [T1.PK_ID], [T1.__pk_increment], [T1.NAME], [T1.MONEY]), filter(nil)17 - output([T1.NUM], [T1.PK_ID], [T1.__pk_increment], [T1.NAME], [T1.MONEY]), filter(nil), dop=1018 - output([T1.NUM], [T1.PK_ID], [T1.__pk_increment], [T1.NAME], [T1.MONEY]), filter(nil)19 - output([T1.NUM], [T1.PK_ID], [T1.__pk_increment], [T1.NAME], [T1.MONEY]), filter(nil), conds(nil), nl_params_([VIEW1.MAX(NUM) + 1000])20 - output([VIEW1.MAX(NUM)]), filter(nil)21 - output([VIEW1.MAX(NUM)]), filter(nil), is_single, dop=122 - output([VIEW1.MAX(NUM)]), filter(nil), access([VIEW1.MAX(NUM)])23 - output([T_FUN_MAX(VIEW2.NUM)]), filter(nil), group(nil), agg_func([T_FUN_MAX(VIEW2.NUM)])24 - output([VIEW2.NUM]), filter(nil), access([VIEW2.NUM])25 - output([LYQTEST1.NUM]), filter(nil), limit(1), offset(nil)26 - output([LYQTEST1.NUM]), filter(nil), sort_keys([LYQTEST1.NUM, DESC])27 - output([LYQTEST1.NUM]), filter(nil), dop=1028 - output([LYQTEST1.NUM]), filter(nil), limit(1), offset(nil)29 - output([LYQTEST1.NUM]), filter(nil)30 - output([LYQTEST1.NUM]), filter(nil), access([LYQTEST1.NUM]), partitions(p[0-2]), limit(1), offset(nil)31 - output([T1.PK_ID], [T1.NUM], [T1.__pk_increment], [T1.NAME], [T1.MONEY]), filter(nil)32 - output([T1.PK_ID], [T1.NUM], [T1.__pk_increment], [T1.NAME], [T1.MONEY]), filter(nil), access([T1.PK_ID], [T1.NUM], [T1.__pk_increment], [T1.NAME], [T1.MONEY]), partitions(p[0-2])33 - output([T2.NUM]), filter(nil)34 - output([T2.NUM]), filter(nil), dop=1035 - output([T2.NUM]), filter(nil)36 - output([T2.NUM]), filter([T2.NUM = 3]), access([T2.NUM]), partitions(p0)