3.2.2 查看表
1) 展示所有表
(1) 语法:

语法:
SHOW TABLES [IN database_name] LIKE ['identifier_with_wildcards'];
In database_name 写的是查哪个数据库,一般不写默认是当前数据库
Like 后面跟通配符表达式
(2) 案例:

查看在 db_hive1 数据库里有没有以 stu 开头的表
2) 查看表信息
(1) 语法
DESCRIBE [EXTENDED | FORMATTED] [db_name.]table_name

(2) 案例:
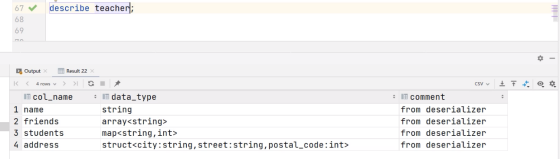
describe teacher;
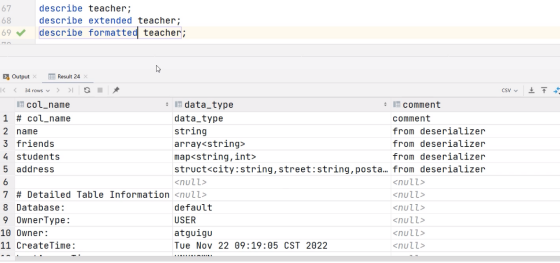
describe extended teacher;

describe formatted teacher;
3.2.3 修改表
1) 重命名表
(1)语法
ALTER TABLE table_name RENAME TO enw_table_name
(2)案例
alter table stu rename to stu1;
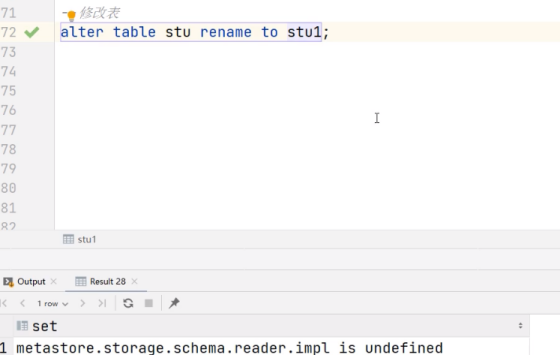
把stu表重命名为stu1
2) 修改列信息
(1)语法
1.增加列
该语句允许用户增加新的列,新增列的位置位于末尾。
ALTER TABLE table_name ADD COLMNS (col_name data_type [COMMENT col_comment], ...);
COMMENT 备注
2.更新列
该语句允许用户修改指定列的列名、数据类型、注释信息以及在表中的位置。
ALTER TABLE table_name CHANGE [COLUMN] col_old_name col_new_name column_type [COMMENT col_comment] [FIRST|AFTER column_name]
COMMENT 备注
FIRST|AFTER column_name 在column_name之前或之后
3.替换列
该语句允许用户用新的列集替换表中原有的全部列。
ALTER TABLE table_name REPLACE COLUMNS (col_name data_type) [COMMENT col_comment], ...)
替换列是一个比较灵活的语法
(2)案例
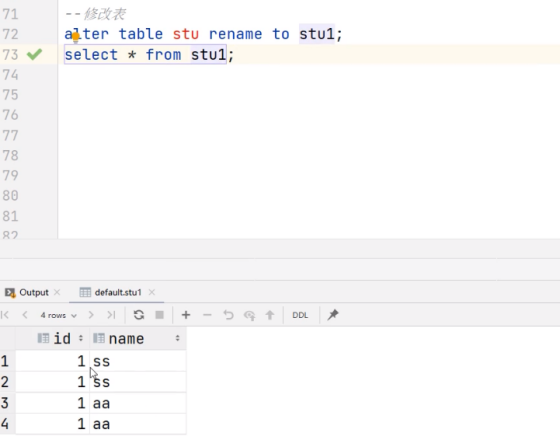
(1) 查询表结构
hive (default)> desc stu;

(2) 添加列
hive (default)> alter table stu add columns(age int);
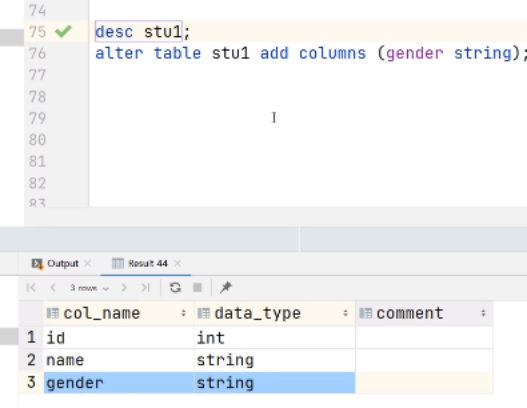
(3) 查询表结构
hive (default)> desc stu;
(4) 更新列
hive (default)> alter table stu change column age ages double;
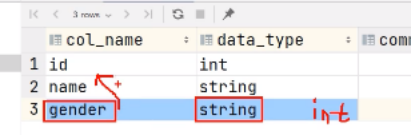
执行代码出错:
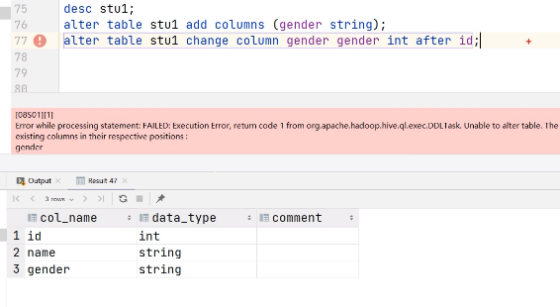
因为在更新列之前他会先检验一下,检验我们更新前后的类型是否一致,我们需要关闭一下他的检验0
使用set关闭检验并查看表:
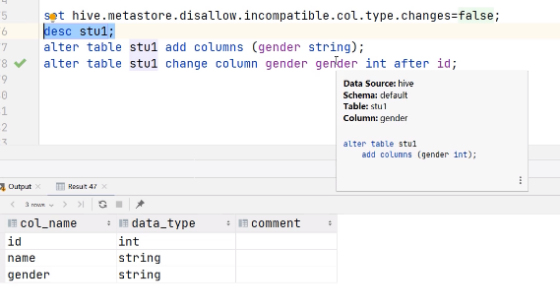
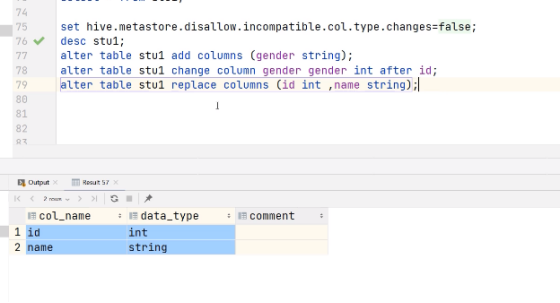
(5) 替换列
hive (default)> alter table stu replace columns(id int, name string);
3.2.4 删除表
1) 语法
DROP TABLE [IF EXISTS] table_name;
2) 案例
hive (default) > drop table stu;
3.2.5 清空表
清空表,只清除表中的数据.
1) 语法
TRUNCATE [TABLE] table_name
2) 案例
hive (default) > truncate table student;
第 4 章 DML (Data Manipulation Language) 数据操作
4.1 Load
Load 语句可将文件导入到Hive表中
1) 语法
hive >
LOAD DATA [LOCAL] INPATH 'filepath' [OVERWRITE] INTO TABLE
tablename [PARTITION (partcol1=val1,partcol2=val2 ...)];
关键字说明:
(1) local : 表示从本地加载数据到Hive表;否则从HDFS加载数据到Hive表。
(2) overwrite : 表示覆盖表中已有的数据,否则表示追加。
(3) partition : 表示上传到指定分区,若目标是分区表,需指定分区。
2) 实操案例
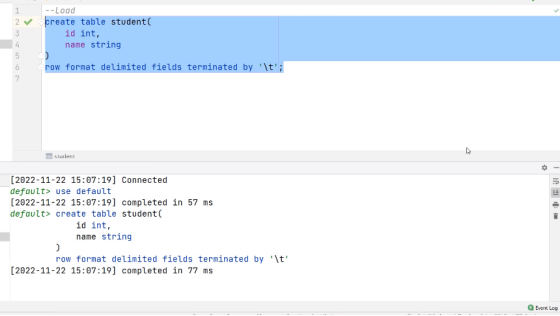
(1) 创建一张表
hive (default)>
create table student(
id int,
name string
)
row format delimited fields terminated by '\t';
创建一张表:
(2) 加载本地文件到hive
hive (default)> load data local inpath '/opt/module/datas/student.txt' into table student;
vim打开文件:

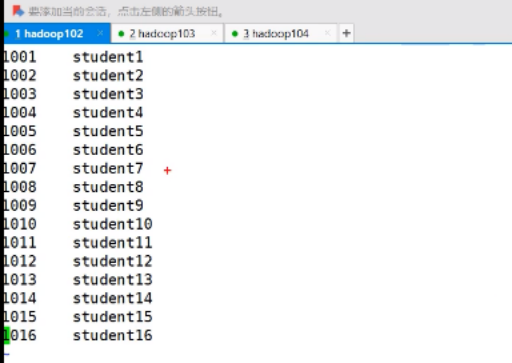
开始Load一下:

因为 into 前面 没有 overwrite 关键字 , 所以是追加模式
没有partition,默认不上传分区
1. 上传文件到HDFS
[atguigu@hadoop102 ~]$ hadoop fs -put
/opt/module/datas/student.txt /user/atguigu
![]()
![]()
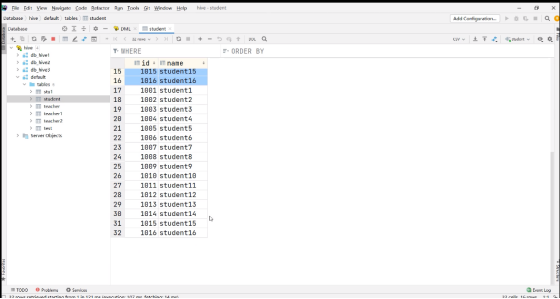
2. 加载HDFS 上的数据, 导入完成后去HDFS上查看文件是否还存在
hive (default)>
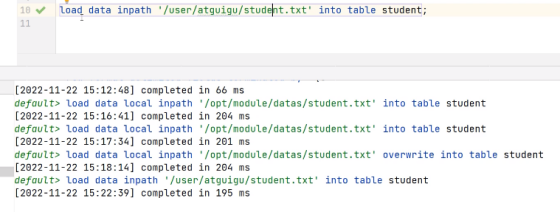
load data inpath '/user/atguigu/student.txt'
into table student;
检查一下student表:
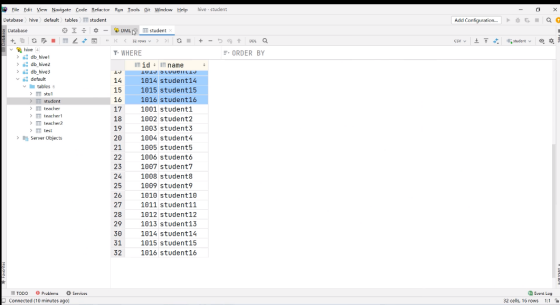
(3) 加载数据覆盖表中已有的数据
1. 上传文件到HDFS
hive (default)> dfs -put
/opt/module/datas/student.txt /user/atguigu;
2. 加载数据覆盖表中已有的数据
hive (default)>
load data inpath '/user/atguigu/student.txt'
overwrite into table student;