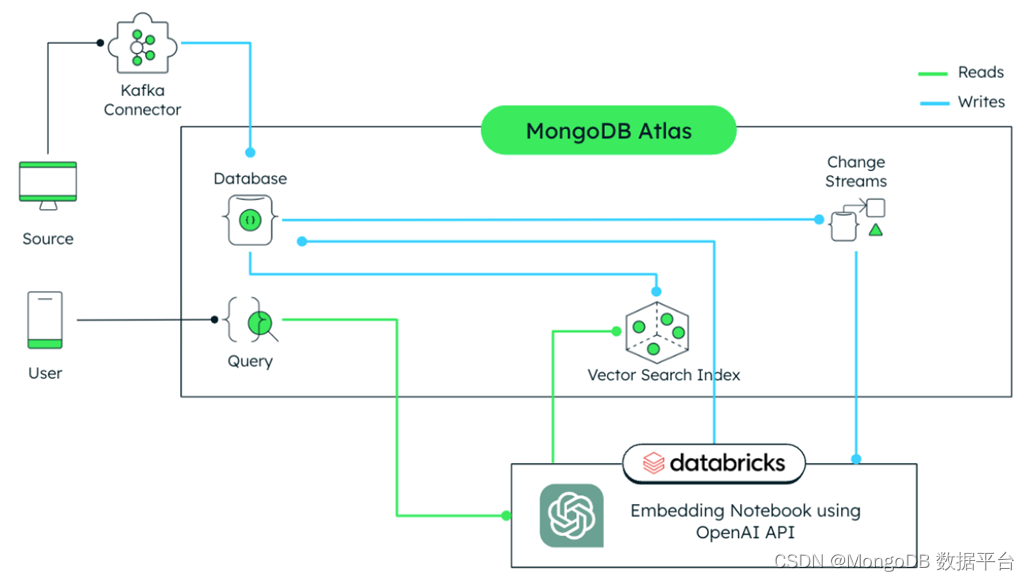
最近各大高校纷纷翻拍 Coincidence 抖肩舞,需要对这种流行现象进行数据分析。数据分析首先需要有数据,本文介绍了爬取 B 站相应视频的评论、弹幕、播放量、点赞数等数据的方法。爬虫有多种实现方法,大型的网络爬虫多基于成熟的爬虫框架(如:Scrapy 等)进行编写,代码量相对较大,且需要处理动态网页解析、应对反爬机制等,挑战较大。但如仅需爬取特定的网页数据,不要求动态更新,可以结合网页本身的特点,基于Requests请求和正则表达式即可快速获取需要的数据。本文以获取【中国人民大学抖肩舞】评论和监测数据为例,介绍基于 API 解析的数据爬取方法。
实验环境:chrome、python
一、实验原理介绍
首先简要介绍一下数据爬取的基本原理,浏览器打开一个网站,实际上是一个和网站服务器交互的过程,交互过程简要介绍如下:
-
浏览器从 URL 中获取 IP地址 和给定的端口号(HTTP 协议默认为端口 80,HTTPS 默认为端口 443),打开 TCP 连接,浏览器 和 服务器 建立连接;
-
浏览器向服务器发送 HTTP / HTTPS 请求,请求 URL 相应的页面 ;
-
服务器接收请求并查找相应 HTML 页面。如果页面存在,服务器 响应请求并将其发送回浏览器。如服务器找不到请求的页面,将发送一个 HTTP 404 错误消息,代表找不到页面;
-
浏览器接收到 HTML 页面,然后通过它从上到下解析寻找列出的其他资源,如图像,CSS 文件,JavaScript 文件等;
-
对于列出的每个资源,浏览器重复上述整个过程,向服务器发送 HTTP 请求;
-
浏览器完成加载 HTML 页面中列出的所有其他资源后,页面将最终加载到浏览器窗口中,且连接将被关闭。
待爬取的数据分为两种,一种是静态网页数据,这种数据隐藏在第 3 步请求得到的 HTML 中,我们只需通过 xpath、正则表达式等解析 HTML 网页抽取目标数据即可(注:静态网页数据可以通过鼠标右键 “显示网页源代码” ,如果在源代码里面找到目标数据,则为静态网页数据;如果未找到,则为动态网页数据);另外一种是动态网页数据,这种数据浏览器通过第 4 步解析需要的数据后,在第 5 步向服务器进行请求获取数据,这种请求大都被设计为 API( Application Programming Interface,应用程序编程接口 )供前端网页调用,动态网页数据获取可以采用多种方式解决,本文介绍的解析 API 模拟请求是其中一种。
我们想要获取的评论数据通过 B 站 主页即可得到,但是对于监测数据,由于 B 站只显示当前的播放量、点赞量等,无法获取历史数据,历史数据的获取需要每天爬取并存入数据库中,幸好找到记录历史数据的第三方网站:BiliOB观测者,可以通过该网站获取历史数据,监测和评论数据介绍如下:
-
B 站视频监测数据获取:BiliOB观测者 是一个观测记录 B 站 UP主、视频历史数据的网站,可用于分析相关视频的历史数据,该网站数据为动态网页数据。
-
B 站视频评论数据获取:评论数据在 B 站视频主页下方,评论数据也是动态网页数据。
本文待爬取的监测和评论数据均为动态网页数据,浏览器对于动态网页数据是通过 API 向服务器请求得到,我们是否可以使用 python 模拟请求获取我们想要的数据呢?答案是肯定的,这就是本文爬取数据的原理,第一步分析网页的 API 请求格式,第二步使用 python 利用同样的格式向服务器请求获取目标数据并保存下来即可。
二、分析目标网页
使用 chrome 浏览器进入 BiliOB观测者 网站,人大抖肩舞监测链接为:https://www.biliob.com/author/11746163/video/75694361,进入该页面之后,按 F12 进行 Chrome 浏览器的控制台,点击 Network,刷新监测网页加载过程,可以通过在 Filter 中输入 “api” 进行过滤,我们可以找到该网页发给向服务器 API 请求,如下图所示:
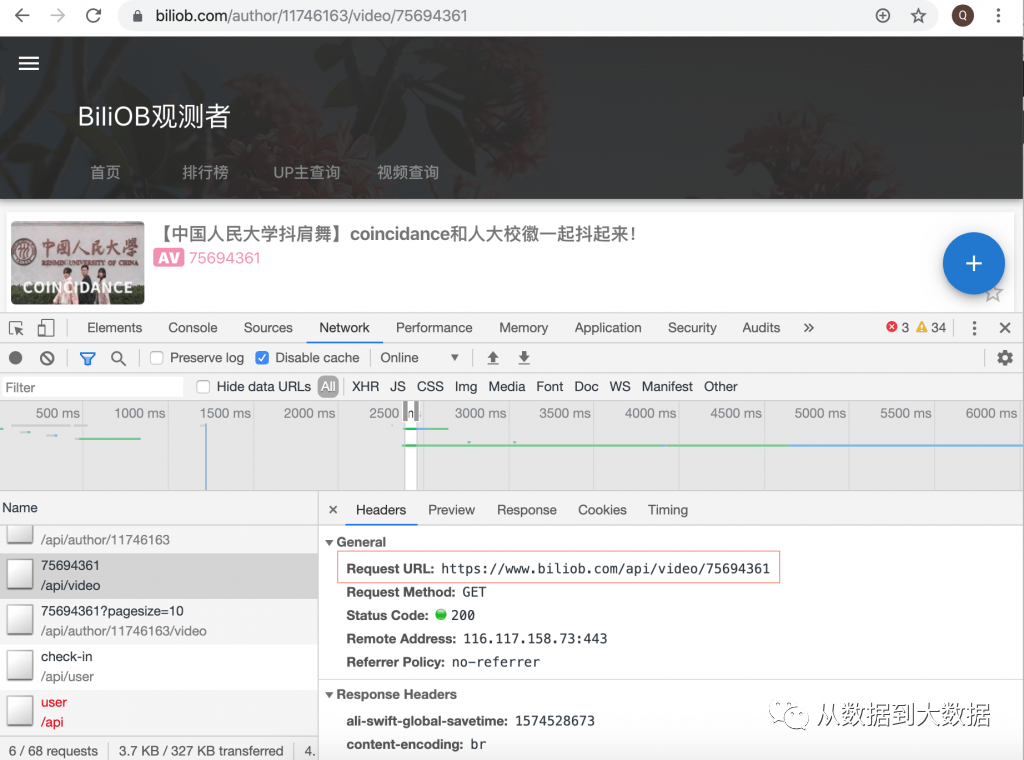
上图中红框中即为请求目标数据的 API,在浏览器中输入该 API 请求,可以得到 Json 格式的目标数据,这里面包含了本视频的历史观测数据,如下图所示:

至此,我们得到视频监测历史数据的 API,调用该 API 得到 Json 格式的目标数据,解析即可得到我们需要的数据,为了获取不同视频的监测数据,更换末尾的视频 ID 即可。
数据监测 API:https://www.biliob.com/api/video/ 75694361
接下来我们使用同样的方式进入 B 站【中国人民大学抖肩舞】的主页(https://www.bilibili.com/video/av75694361),找到视频评论所在区域,按 F12 进入 chrome 控制台,点击 Network ,刷新页面,可以看到所以的资源加载,由于该页面资源加载过多,难以定位目标 API ,可以在加载完成之后清除所以加载记录,然后点击网页中评论页面,仅重新加载评论区,即可定位的加载评论数据的 API,如图所示:
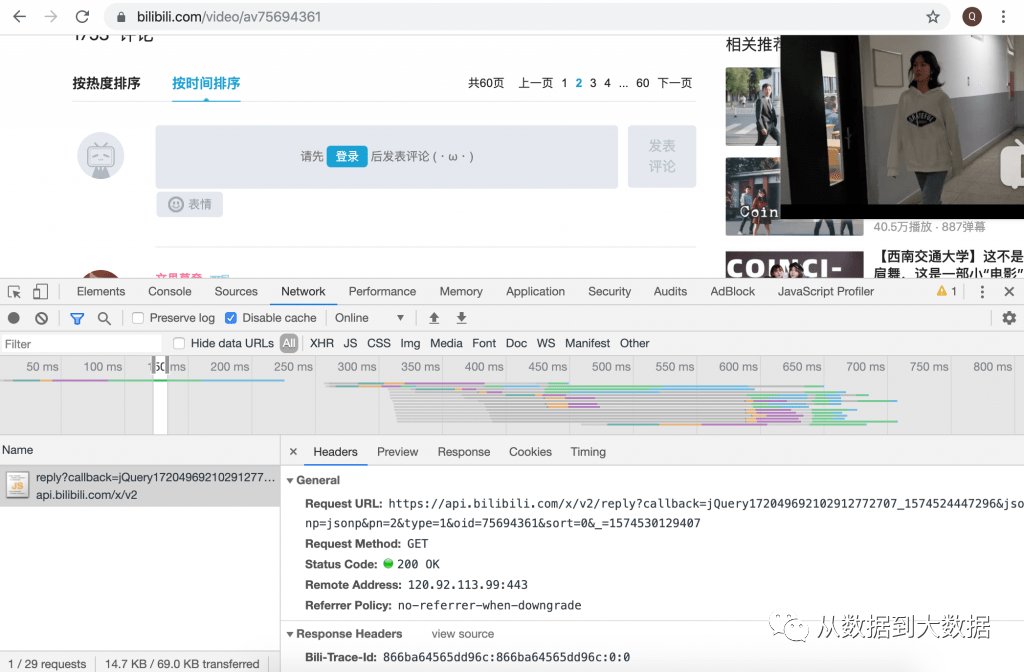
可以看到,评论区数据获取的 API 较为复杂,API 请求为 https://api.bilibili.com/x/v2/reply ,后面的为 API 请求所带参数,完整的 API 请求如下所示:
https://api.bilibili.com/x/v2/reply?callback=jQuery172049692102912772707_1574524447296&jsonp=jsonp&pn=2&type=1&oid=75694361&sort=0&_=1574530129407

容易知道部分参数的含义,pn 表示评论的页数、oid 表示视频的 ID,sort 表示评论的排序规则( 0 为按时间、2为按热度 ),其他参数意义不明,尝试仅使用已知含义的参数调用 API ,看能否成功获取数据,尝试成功,返回 Json 格式的数据,如图所示:
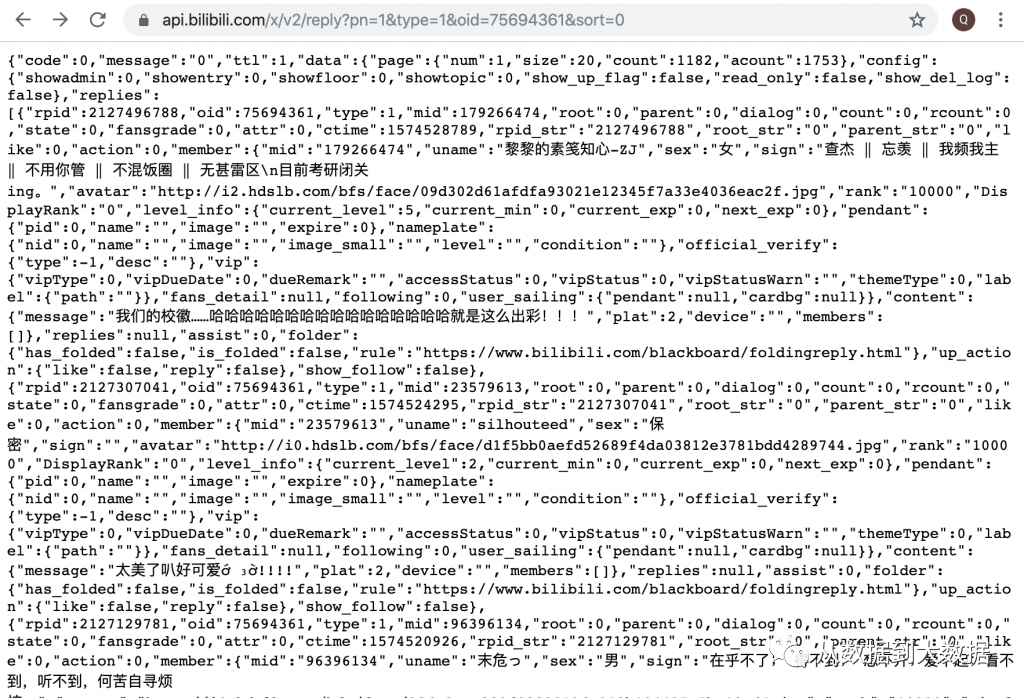
经过尝试,我们得到成功调用 API 获取评论数据的最少参数格式为:pn、type、oid,以 Json 格式返回该页面的评论的数据。更改这几个参数的值即可获取相应视频对于页面的评论。
视频评论API:https://api.bilibili.com/x/v2/reply?pn=1&type=1&oid=75694361
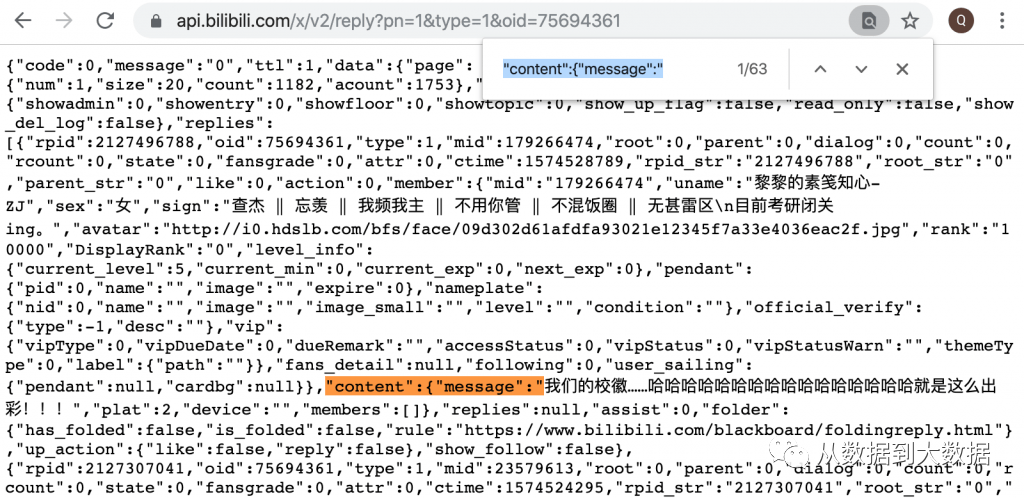
得到返回的 Json 文件后,使用 Ctrl + F(Mac 使用 Command + F),发现 “content”:{“message”:” 后面即为相应的评论文本,可以通过正则表达式方便抽取评论文本。
三、编写爬虫代码
第二节的分析,已经分析完爬虫解析数据的逻辑,爬取评论数据只需要循环更改 pn 的值,使用 requests 请求即可得到 Json 格式的目标数据,然后使用正则表达式抽取评论文本即可,有一点需要注意,代码中使用 time.sleep(0.5) 在每次请求前休眠 0.5 秒,避免访问频率过高,导致被服务器禁掉本 IP 的请求,爬取得到数据后,保存到本地文件中。代码如下:
import osimport reimport requestsimport mathimport jsonimport timeimport pandas as pdschools = [{"name": "中国人民大学", "aid": 75694361},]# 获取指定视频的评论def get_reply(aid):# aid: URL中的视频的IDreply_url = "https://api.bilibili.com/x/v2/reply"replys = []# 计算评论页数req_json = requests.get("https://api.bilibili.com/x/v2/reply?pn=1&type=1&oid=" + aid).json()page_json = req_json["data"]["page"]page_num = math.ceil(page_json["count"] / page_json["size"])# 获取所有评论for i in range(page_num):para = {'pn': str(i), 'type': '1', 'oid': aid}time.sleep(0.5)reply_str = requests.get(reply_url, para)msgs = re.findall(r'\"content\":{\"message\":\"(.*?)\"', reply_str.text)replys += msgsreturn [r + "\n" for r in replys]# 爬取评论并保存数据def save_reply(schools):for school in schools:aid = school["aid"]replys = get_reply(str(aid))with open("./data/" + school["name"] + "_评论.txt", "w", encoding="utf-8") as f:f.writelines(replys)print(school["name"] + " 评论:爬取完成。")return
接下来是获取监测数据的函数,模拟调用API的方式和上文类似,在解析完监测数据后,本函数使用 pandas 保存到 excel 文件中。
# 获取相应视频的监测数据def get_biliDB():for school in schools:name = school["name"]aid = school["aid"]biliDB_url = "https://www.biliob.com/api/video/"time.sleep(0.5)req_json = requests.get(biliDB_url + str(aid)).json()try:bilidb_data = [[0,0,0,0,0,0,None,req_json['datetime']]]bilidb_data += [d.values() for d in req_json['data']]df_bilidb = pd.DataFrame(bilidb_data, columns = ['view','favorite','danmaku','coin','share','like','dislike','datetime'])df_bilidb = df_bilidb.sort_values(by='datetime')df_bilidb = df_bilidb.reset_index(drop=True)df_bilidb.to_excel("./data/监测_" + name + ".xlsx")except:print("数据爬取错误:" + name)return
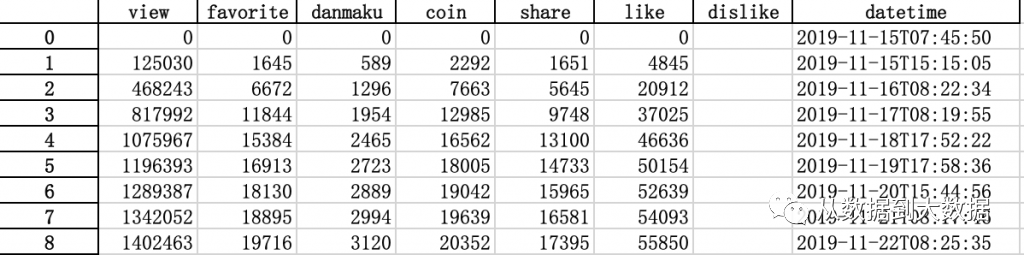
至此,已可成功获取人大抖肩舞的监测和评论数据,如果需要扩展到其他高校,仅需提供对应高校的视频 ID 即可。部分爬取数据如图所示:

总结
本文以爬取 B 站数据为案例,介绍了基于 API 解析爬取动态网页数据的原理和技巧,使用 Chrome 分析得到动态数据的 API,然后使用 Python 获取相应数据。