文章目录
- 第一章 概述
- 1.1 基本概念
- 1.1.1 分布式数据库
- 1.1.2 数据管理的透明性
- 1.1.3 可靠性
- 1.1.4 分布式数据库与集中式数据库的区别
- 1.2 体系结构
- 1.3 全局目录
- 1.4 关系代数
- 1.4.1 基操
- 1.4.2 关系表达式
- 1.4.3 查询树
- 第二章 分布式数据库的设计
- 2.1 设计策略
- 2.2 分布设计的目标
- 2.3 水平分片设计
- 2.3.1 需求分析
- 2.3.2 简单谓词集合的精炼处理
- 2.3.3 最小谓词集合处理
- 2.3.4 诱导分片
- 2.3.5 正确性检查
- 2.4 垂直分片设计
- 2.4.1 使用矩阵
- 2.4.2 亲密矩阵
- 2.4.3 聚集的属性亲密矩阵(理解即可,有点复杂)
- 2.4.5 正确性检查
- 2.5 分解树和重构树
- 2.6 分配
- 第三章 分布式查询
- 3.1 查询分解
- 3.1.1 规范化
- 3.1.2 规范化规则
- 3.1.3 逻辑规则
- 3.1.4 冗余消除
- 3.1.5 查询树优化
- 3.2 数据定位
- 3.2.1 合并重构树
- 3.2.2 水平分片的裁剪
- 3.2.3 垂直分片的裁剪
- 3.2.4 诱导分片的裁剪
- 3.2.5 混合分片的裁剪
- 3.3 全局优化
- 3.3.1 目标
- 3.3.2 代价的估算
- 3.3.3 主要优化问题
- 3.3.4 主要算法
- 3.4 局部优化
- 第四章 分布式并发控制
- 4.1 串行化理论
- 4.1.1 集中式可串行化
- 4.1.2 分布式可串行化
- 4.2 并发控制概况
- 4.3 基于锁的并发控制
- 4.3.1 基本概念
- 4.3.2 两段锁协议(2PL)
- 4.3.2.1 集中式数据库中2PL的可串行性
- 4.3.2.2 分布式数据库中2PL的可串行性
- 4.4 死锁问题
- 4.4.1 死锁的检测和恢复
- 4.4.2 死锁的预防
- 4.4.3 死锁的避免
- 第五章 分布式恢复
- 5.1 概述
- 5.1.1 事务模型
- 5.1.2 错误类型
- 5.1.3 稳定数据库与易失数据库
- 5.1.4 稳定日志与易失日志
- 5.1.5 错误例子
- 5.2 局部恢复
- 5.2.1 事务级与系统级错误恢复
- 5.2.2 检查点
- 5.2.3 日志的完整性
- 5.2.4 介质错误
- 5.3 全局恢复
- 5.3.1 全局事务
- 5.3.2 原子性
- 5.3.3 持久性
- 5.3.4 关键问题
- 5.4 两段提交协议
- 5.4.1 基本思想
- 5.4.2 2PC协议运行要点
- 5.4.3 运行状态转变图
- 5.4.3.1 协调者超时处理
- 5.4.3.2 参与者超时处理
- 5.4.3.3 提交过程开始后协调者站点错误
- 5.4.3.4 提交过程开始后参与者站点错误
- 第六章 区块链技术(理解即可)
- 6.1 比特币及其原理
- 6.1.1 比特币的诞生
- 6.1.2 比特币系统的特点
- 6.1.3 比特币来源
- 6.1.4 比特币交易
- 6.1.5 UTXO
- 6.1.6 账户余额
- 6.1.7 挖矿
- 6.2 区块链原理
- 6.2.1 区块链内容和区块间的链
- 6.2.2 数字签名验证交易
- 6.2.3 默克尔树组织块内交易
- 6.2.4 共识机制
- 6.2.5 P2P
- 6.2.6 智能合约
- 6.2.7 区块链类型
- 6.3 区块链与加密货币的关系
- 6.4 区块链主要框架
- 6.5 区块链与数据库的比较
- 第七章 NewSQL数据库
- 7.1 基本概念
- 7.2 类别
- 7.2.1 New Architecture
- 7.2.2 Transparent Sharding Middleware
- 7.2.3 Database-as-a-Service
- 7.3 研究热点
- 7.3.1 内存存储
- 7.3.2 数据分片
- 7.3.3 并发控制
- 7.3.3.1 基于时间印的MVCC
- 7.3.3.2 基于时间印的MVCC(改进——解决级联依赖问题)
- 7.3.3.3 基于时间印的MVCC(改进——提高系统效率)
- 7.3.4 辅助索引
- 7.3.5 复制
- 7.3.6 故障恢复
- 7.4 未来的趋势
- 第八章 NoSQL数据库(理解即可)
- 8.1 基本概念
- 8.2 GFS
- 8.2.1 Bigtable的存储基础
- 8.2.2 架构
- 8.2.3 特点
- 8.2.4 容错机制
- 8.3 Chubby
- 8.3.1 锁服务
- 8.3.2 Chubby单元
- 8.3.3 Chubby服务器
- 8.3.4 Chubby通信协议
- 8.4 Bigtable
- 8.4.1 特点
- 8.4.2 数据模型
- 8.4.3 系统架构
- 8.4.4 主服务器
- 8.4.5 子表结构
- 8.4.6 元数据表
- 8.4.7 读写操作
- 第九章 课程设计
- 9.1 需求
- 9.2 设计
- 9.2.0 类图
- 9.2.1 表及其结构
- 9.2.2 表间的关联(ER图)
- 9.2.3 表的分布设计
- 9.2.4 \<key, value\>存储及其与表之间的联系(索引)
- 9.2.5 关键事务的描述
- 9.2.6 主要的查询流程
- 第十章 OceanBase 数据库分布式事务的实现机制
- 10.1 概述(总结)
- 10.2 分布式事务的基本概念
- 10.2.1 基本概念
- 10.2.2 ACID特性
- 10.2.3 CAP理论
- 10.2.4 BASE理论
- 10.3 OceanBase分布式事务的协议
- 10.3.1 传统的2PC(Two-Phase Commit)
- 10.3.2 OceanBase的2PC
- 10.4 实现机制(其他关键技术)
- 10.4.1 全局一致性快照技术
- 10.4.2 锁机制
- 10.4.3 MVCC(多版本并发控制)
- 10.5 故障恢复
- 10.5.1 分布式数据库的问题
- 10.5.2 单机事务故障处理
- 10.5.3 分布式事务故障处理
- 10.6 性能优化
- 10.6.1 分布式事务类型的优化
- 10.6.2 分布式事务提交的优化
第一章 概述
1.1 基本概念
1.1.1 分布式数据库
分布式数据库——多个分布在计算机网络上的逻辑相关的数据库的集合。
分布式数据库中,存放在不同网络节点上的数据库称作局部数据库,由局部数据库构成的逻辑整体称为全局数据库。全局数据库中的关系称为全局关系,局部数据库中的关系称为逻辑片段,或简称片段。
全局关系与片段之间的映射关系称为分片。全局数据库与局部数据库之间的映射关系由一组分片模式来体现。一个逻辑片段可以保存在网络的一个节点上,也可以在网络的多个节点上保存多个副本,逻辑片段如何在网络上存放,称为分配。
1.1.2 数据管理的透明性
- 分片透明:用户使用数据库时,不需要知道全局数据库与多个局部数据库之间的逻辑关系。
- 复制(分配)透明:用户使用数据库时,不需要知道数据在网络上不同节点间的复制情况。
- 网络透明:用户使用数据库时,用全局唯一的对象名指代所要操作的对象,不需知道数据在网络上的位置。
- 数据独立性(无分布透明):用户应用不受数据库逻辑结构变化的影响,用户应用不需关注数据库数据保存的物理结构。集中式数据库就具有这样的特性。
1.1.3 可靠性
事务是数据库上的一致的可靠的计算单元,事务由一串具有原子性的数据库操作组成。
事务具有ACID四个特性。
- 原子性(Atomicity),组成一个事务的一串操作要么全部完成,要么全部没做。
- 一致性(Consistency),并发执行的事务总是使得数据库从一个一致的状态转变为另一个一致的状态。
- 隔离性(lsolation),一个事务执行过程中无法看到其他并发事务的中间结果。
- 持久性(Durability),已完成事务的结果将会被可靠地永久地保存,直至被另一个事务所更新。
事务的性质在分布式数据库中必须得到保证。在分布式环境中保障事务性质显然与集中式环境有很多不同。集中式数据库环境中若服务器节点失效,数据库系统将无法运转,而在分布式数据库环境中,在某些条件满足时,即使某个服务器节点失效,数据库系统仍能运转。
1.1.4 分布式数据库与集中式数据库的区别
集中式数据库中数据库存放在网络上的一个节点上,而分布式数据库数据库分布存放在网络上不同节点上。
1.2 体系结构
- 客户机/服务器模式:多客户机/单服务器、多客户机/多服务器
- 对等节点模式:
- 多数据库模式:含全局概念模式、不含全局概念模式。
1.3 全局目录
全局目录是分布式数据库中描述全局数据库与局部数据库关系的信息集合(分片模式和分配模式的集合)。只有分布式数据库有全局目录的问题。在分布式数据库中全局目录是目录的一部分。
目录本身也是一个数据库。目录可以集中存放在一个节点上,也可以分为全局目录和局部目录,分布存放在网络的不同节点上。
分布式数据库的设计技术同样适用于目录。分布式环境中,一个目录可以只在一个节点上存放一个拷贝,也可以在多个节点上存放多个拷贝。
1.4 关系代数
1.4.1 基操

1.4.2 关系表达式
由关系代数运算经有限次复合而成的式子称为关系代数表达式。这种表达式的运算结果仍然是一个关系。可以用关系代数表达式表示对数据库的查询和更新操作。
例如:
数据库中有三个关系如下:
学生关系 Stu1(sid, sname, sage, sgender),Stu2(sid, sname, sage, sgender)
选课关系 SC(sid, cid, grade)
课程关系 Cou(cid, cname, cteacher)
- 查询学号为112的学生年龄
π s a g e ( σ s i d = ′ 11 2 ′ ( S t u 1 ) ) \pi_{sage}(\sigma_{sid='112'}(Stu1)) πsage(σsid=′112′(Stu1)) - 查询学号为112或者212的学生性别
π s g e n d e r ( σ s i d = ′ 11 2 ′ ∨ s i d = ′ 21 2 ′ ( S t u 1 ∪ S t u 2 ) ) \pi_{sgender}(\sigma_{sid='112' \vee sid='212'}(Stu1\cup Stu2)) πsgender(σsid=′112′∨sid=′212′(Stu1∪Stu2)) - 查询同时出现在两个学生关系中的学生学号和姓名
π s i d , s n a m e ( S t u 1 ∩ S t u 2 ) \pi_{sid, sname}(Stu1\cap Stu2) πsid,sname(Stu1∩Stu2) - 查询出现在学生关系1且不在学生关系2中的学生学号和姓名
π s i d , s n a m e ( S t u 1 − S t u 2 ) \pi_{sid, sname}(Stu1-Stu2) πsid,sname(Stu1−Stu2) - 查询学号为112的学生的数据库课程成绩
π g r a d e ( σ s i d = ′ 11 2 ′ ∧ c n a m e = ′ 数据 库 ′ ( C o u ⋈ C o u . c i d = S C . c i d S C ) ) \pi_{grade}(\sigma_{sid='112'\wedge cname='数据库' }(Cou\Join_{Cou.cid=SC.cid} SC)) πgrade(σsid=′112′∧cname=′数据库′(Cou⋈Cou.cid=SC.cidSC)) - 查询学生关系1中选过课的学生学号和姓名
π s i d , s n a m e ( S t u 1 ⋉ S t u 1. s i d = S C . s i d S C ) \pi_{sid, sname}(Stu1\ltimes_{Stu1.sid=SC.sid} SC) πsid,sname(Stu1⋉Stu1.sid=SC.sidSC)
【注:半连接返回左表中与右表至少匹配一次的数据行,通常体现为 EXISTS 或者 IN 子查询】
1.4.3 查询树
关系表达式可进一步转换为查询树,查询树包含关系操作的先后顺序,数据库系统可依据查询树控制查询操作。
例如:
-
查询学号为112的学生年龄
π s a g e ( σ s i d = ′ 11 2 ′ ( S t u 1 ) ) \pi_{sage}(\sigma_{sid='112'}(Stu1)) πsage(σsid=′112′(Stu1))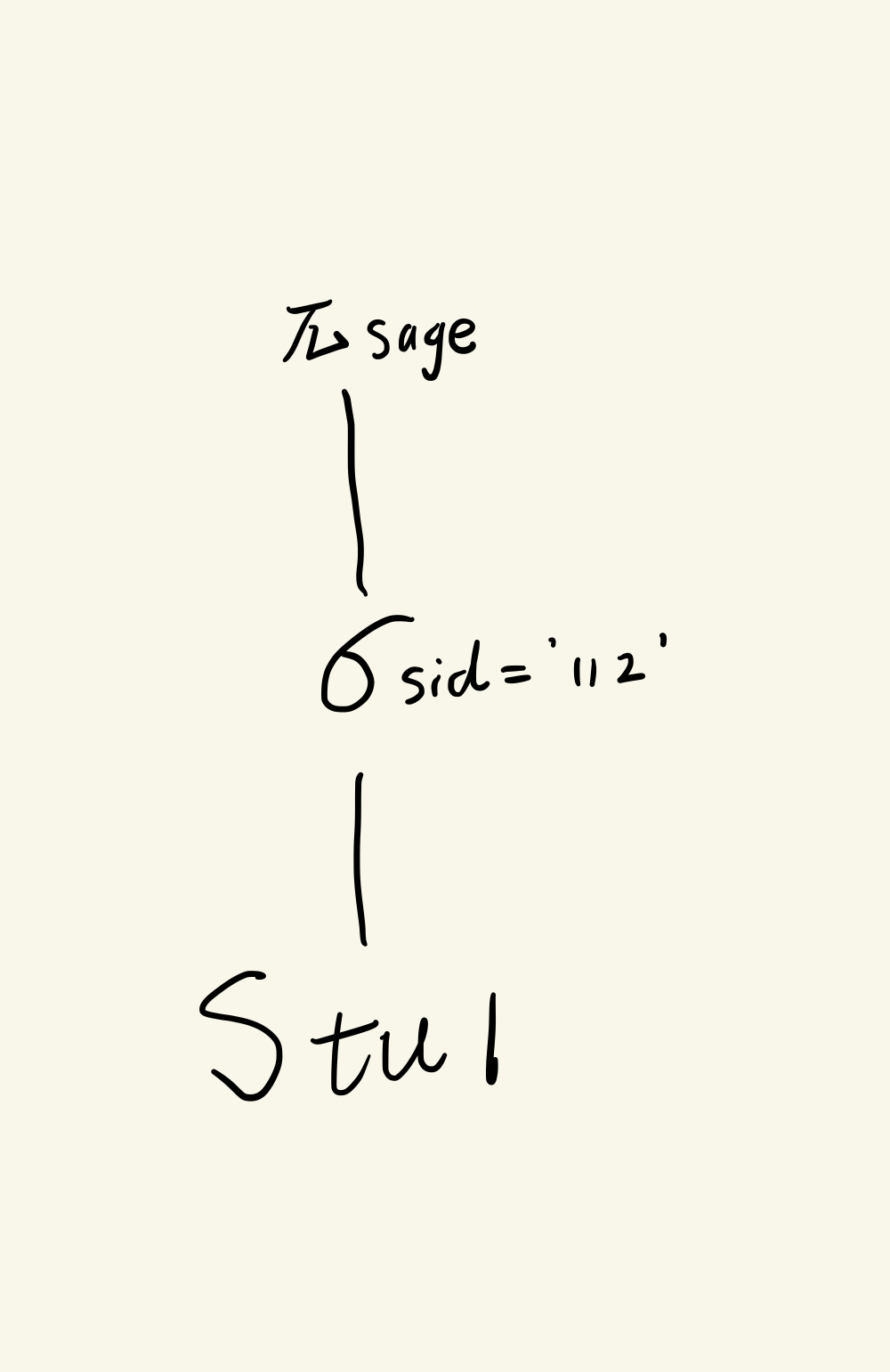
-
查询学号为112或者212的学生性别
π s g e n d e r ( σ s i d = ′ 11 2 ′ ∨ s i d = ′ 21 2 ′ ( S t u 1 ∪ S t u 2 ) ) \pi_{sgender}(\sigma_{sid='112' \vee sid='212'}(Stu1\cup Stu2)) πsgender(σsid=′112′∨sid=′212′(Stu1∪Stu2))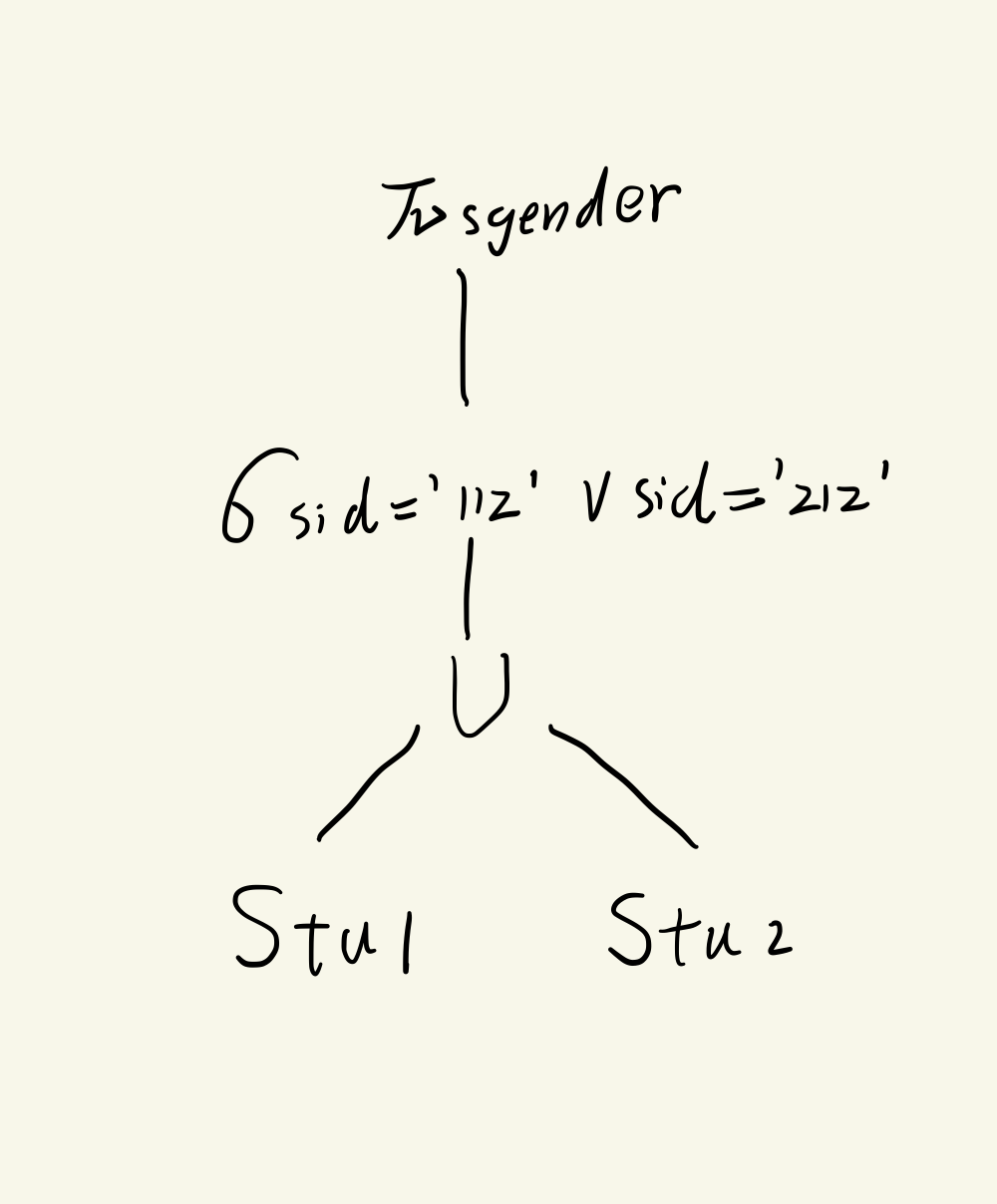
-
查询同时出现在两个学生关系中的学生学号和姓名
π s i d , s n a m e ( S t u 1 ∩ S t u 2 ) \pi_{sid, sname}(Stu1\cap Stu2) πsid,sname(Stu1∩Stu2)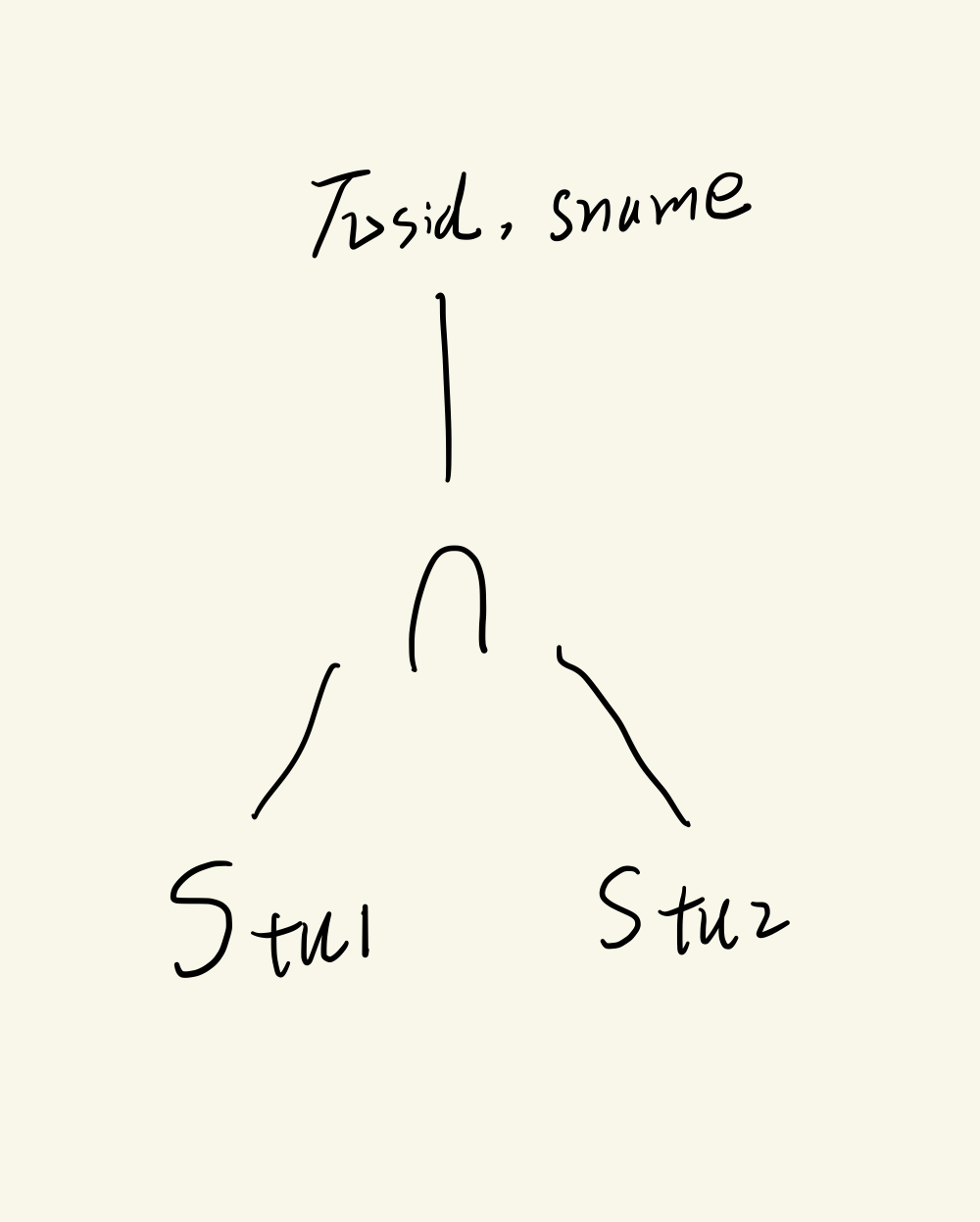
-
查询出现在学生关系1且不在学生关系2中的学生学号和姓名
π s i d , s n a m e ( S t u 1 − S t u 2 ) \pi_{sid, sname}(Stu1-Stu2) πsid,sname(Stu1−Stu2)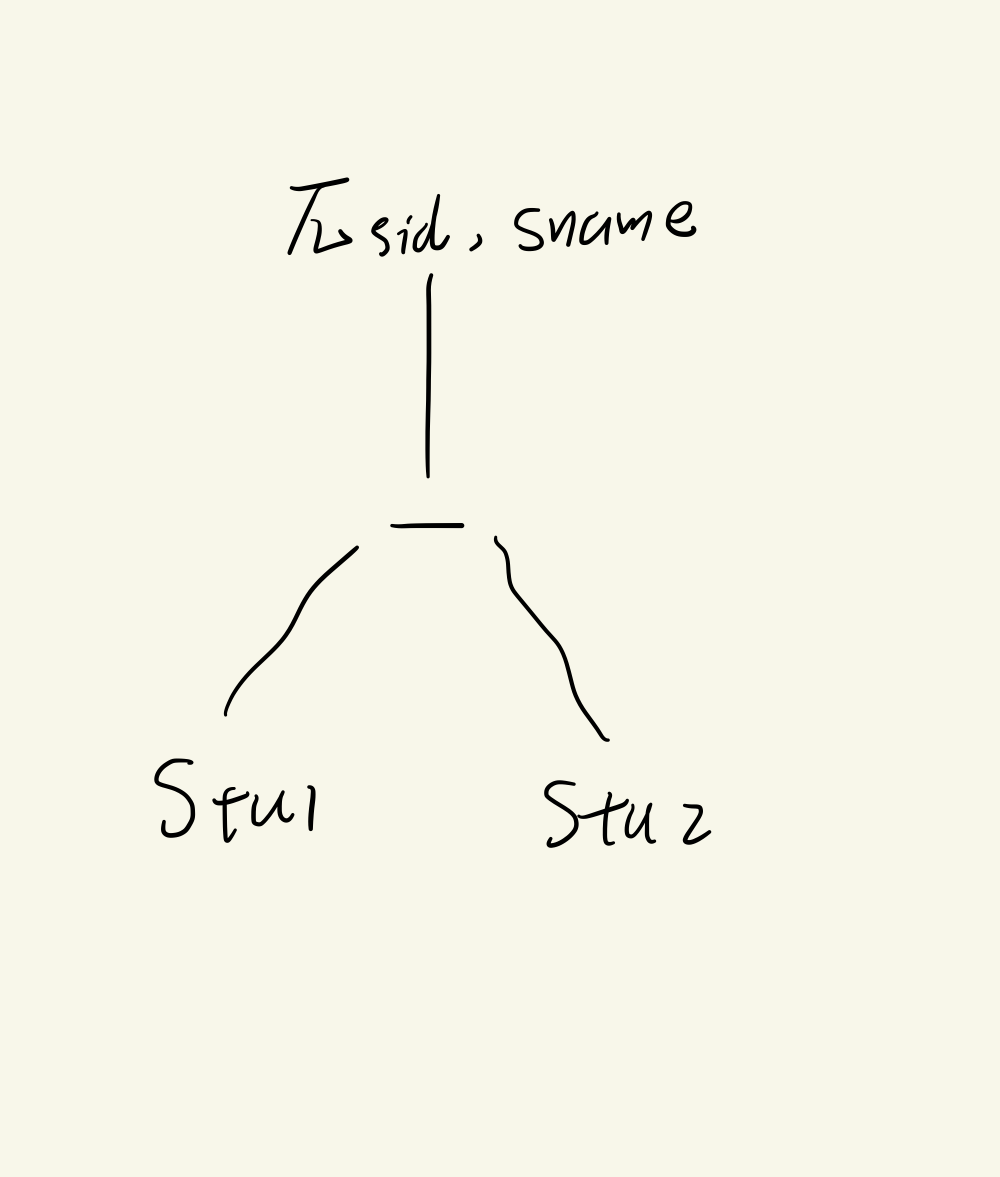
-
查询学号为112的学生的数据库课程成绩
π g r a d e ( σ s i d = ′ 11 2 ′ ∧ c n a m e = ′ 数据 库 ′ ( C o u ⋈ C o u . c i d = S C . c i d S C ) ) \pi_{grade}(\sigma_{sid='112'\wedge cname='数据库' }(Cou\Join_{Cou.cid=SC.cid} SC)) πgrade(σsid=′112′∧cname=′数据库′(Cou⋈Cou.cid=SC.cidSC))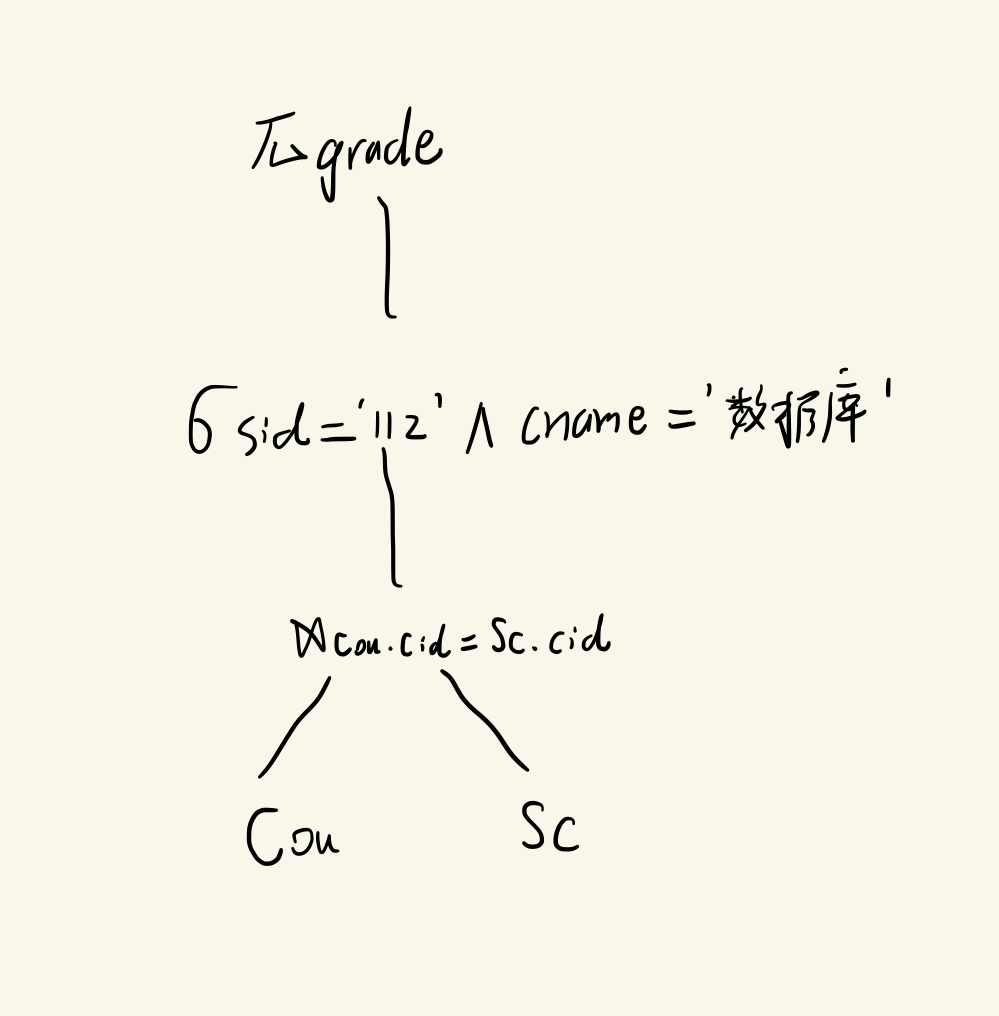
-
查询学生关系1中选过课的学生学号和姓名
π s i d , s n a m e ( S t u 1 ⋉ S t u 1. s i d = S C . s i d S C ) \pi_{sid, sname}(Stu1\ltimes_{Stu1.sid=SC.sid} SC) πsid,sname(Stu1⋉Stu1.sid=SC.sidSC)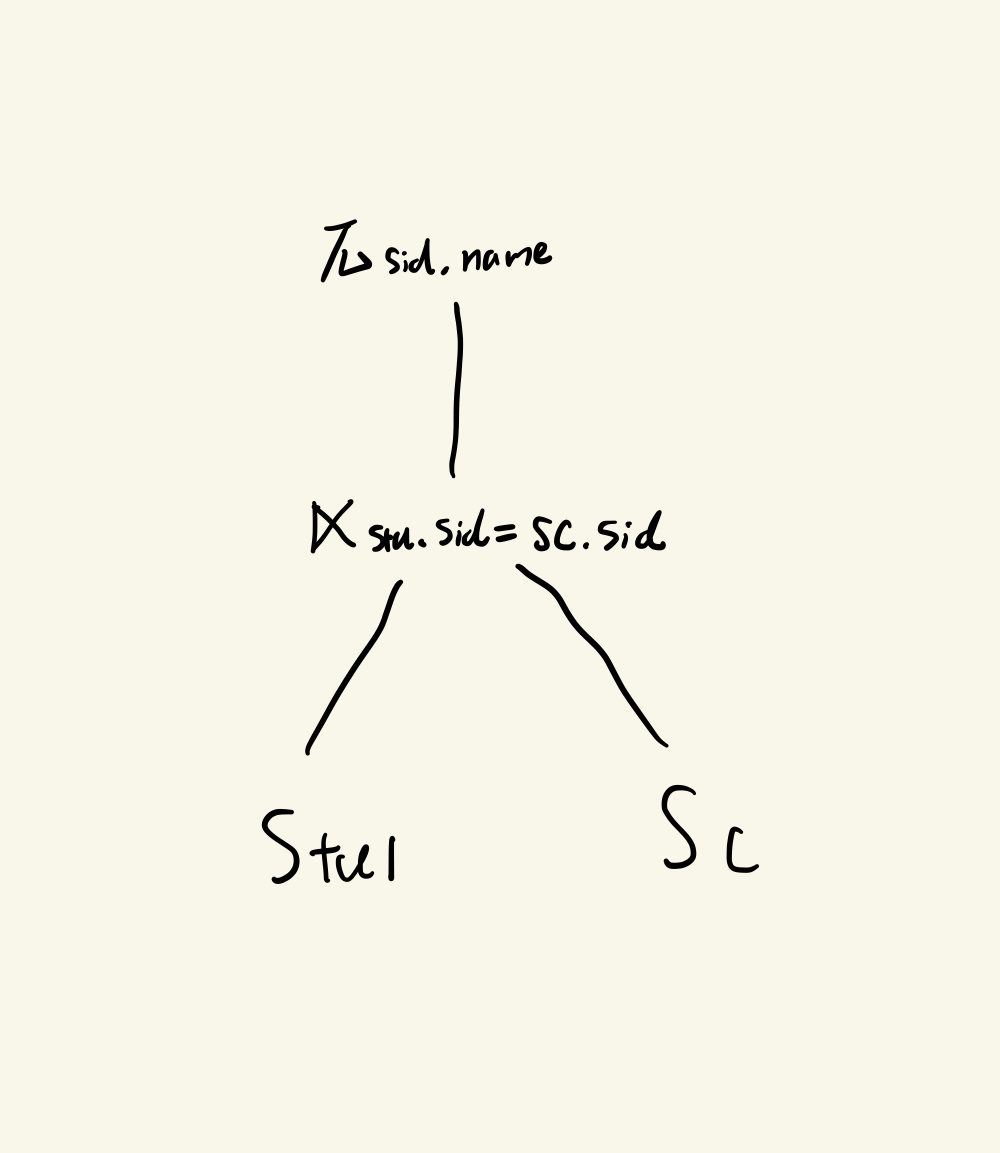
第二章 分布式数据库的设计
2.1 设计策略
当数据库的设计是从头开始时,自顶向下的设计是合适的。然而有时一些数据库已经存在,设计是为了集成已存在的一些数据库,这时需要自底向上的设计方法。
自底向上的设计方法所涉及的需要集成的多个数据库常常是异构的。
2.2 分布设计的目标
- 分布设计的多个子目标之间相互矛盾,只能进行平衡折中的处理。
- 分布设计应使每个应用访问的局部数据库尽可能少。
- 分布设计应尽可能提高应用的并发程度。
- 分布设计应尽可能减少应用执行过程中的网络通信量。
- 分布设计应尽可能让用户应用在网络上就近访问。
2.3 水平分片设计
2.3.1 需求分析
- 收集用户查询所用的谓词。
- 用户查询无穷无尽,无法全部收集,通常在80/20规则的指导下进行。即:20%的最活跃的查询可以反映80%的数据访问情况。
2.3.2 简单谓词集合的精炼处理
谓词: P i : A i θ V a l u e θ ∈ { = , < , > , ≠ , ≤ , ≥ } P_i: A_i \;\theta\; Value\;\;\; \theta \in \{=,<,>,\not=,\le,\ge\} Pi:AiθValueθ∈{=,<,>,=,≤,≥}
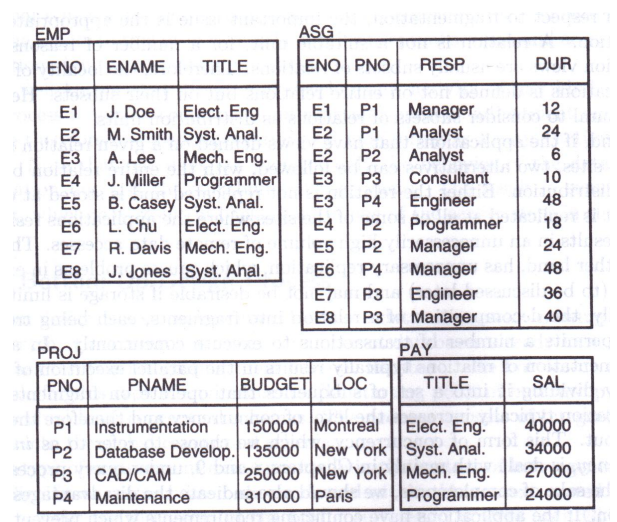
例如: P 1 : L O C = " M o n t r e a l " P_1:LOC\; = \; "Montreal" P1:LOC="Montreal"
P r i = { p i 1 , P i 2 , . . . , p i m } P_{ri} = \{p_{i1}, P_{i2},. . ., p_{im}\} Pri={pi1,Pi2,...,pim} 是针对关系 r i r_i ri 收集的简单谓词集合。
P r i P_{ri} Pri 经算法COM-MIN处理后得到 P r i ′ P'_{ri} Pri′。对于关系 r i r_i ri , P r i ′ P'_{ri} Pri′ 是满足分布设计要求的最小简单谓词集合。
例如,针对关系PROJ得到了 P ′ = { p 1 , P 2 , P 3 , P 4 , P 5 } P'= \{p1, P2, P3, P4, P5\} P′={p1,P2,P3,P4,P5}
p1:LOC = “Montreal”
p2:LOC = “New York”
p3:LOC = "Paris’
p4:DUDGET ≤200000
p5:DUDGET > 200000
2.3.3 最小谓词集合处理
M i = { m i j ∣ m j j = ∧ p i k ∗ , 1 < j < z , p i k ∗ = p i k ∣ ¬ p i k , p i k ∈ P r i ′ } M_i = \{m_{ij}|m_{jj} = \wedge p^*_{ik}, \; 1<j<z, \;p^*_{ik}=p_{ik}|\neg p_{ik},\; p_{ik}∈P'_{ri} \} Mi={mij∣mjj=∧pik∗,1<j<z,pik∗=pik∣¬pik,pik∈Pri′} M i M_i Mi是关于关系 r i r_i ri最小项谓词集合从 P r i ′ P'_{ri} Pri′中得到,是进行水平分片的依据。
例如,由 P ′ = { p 1 , p 2 , p 3 , p 4 , p 5 } 可得 M = { m j } ( 1 ≤ j ≤ 2 5 ) P'=\{p_1,p_2,p_3, p_4, p_5\}可得M=\{m_j\}\;(1≤j≤2^5) P′={p1,p2,p3,p4,p5}可得M={mj}(1≤j≤25)。然而,谓词间隐含着一些语意。
i 1 : p 1 ⇒ ¬ p 2 ∧ ¬ p 3 i_1:\; p1\Rightarrow \neg p2 \wedge \neg p_3 i1:p1⇒¬p2∧¬p3
i 2 : p 2 ⇒ ¬ p 1 ∧ ¬ p 3 i_2:\; p2\Rightarrow \neg p1 \wedge \neg p_3 i2:p2⇒¬p1∧¬p3
i 3 : p 3 ⇒ ¬ p 1 ∧ ¬ p 2 i_3:\; p3\Rightarrow \neg p1 \wedge \neg p_2 i3:p3⇒¬p1∧¬p2
i 4 : p 4 ⇒ ¬ p 5 i_4:\; p4\Rightarrow \neg p5 i4:p4⇒¬p5
i 5 : p 5 ⇒ ¬ p 4 i_5:\; p5\Rightarrow \neg p4 i5:p5⇒¬p4
i 6 : ¬ p 4 ⇒ p 5 i_6:\; \neg p4\Rightarrow p5 i6:¬p4⇒p5
i 7 : ¬ p 5 ⇒ p 4 i_7:\; \neg p5\Rightarrow p4 i7:¬p5⇒p4
由 i 1 − 7 i_{1-7} i1−7可知, p 1 − 3 p_{1-3} p1−3不可能同时存在, p 4 − 5 p_{4-5} p4−5不可能同时存在,删除非法和重复的最小谓词项后,得到 M = { m i , 1 ≤ i ≤ 6 } M=\{m_i, 1 \le i \le 6\} M={mi,1≤i≤6}
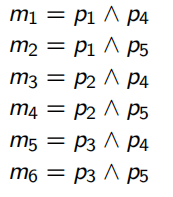
最后根据最小谓词集合M进行水平分片:
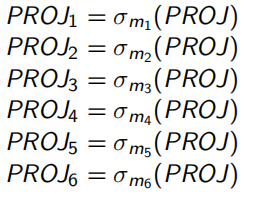
分片结果如下:
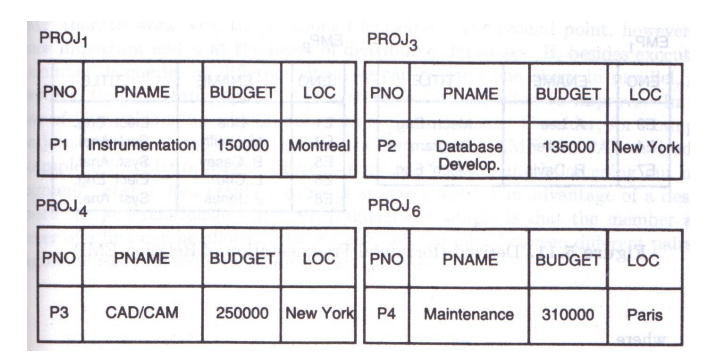
其中 P R O J 2 , P R O J 5 PROJ_2, PROJ_5 PROJ2,PROJ5为空,那是由PROJ的当前值决定的,数据库是动态的,PROJ的值也是动态的。
2.3.4 诱导分片
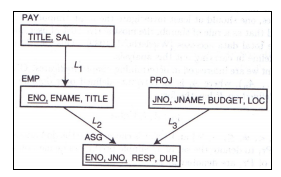
水平分片可以直接对一个关系搜集应用信息,设计分片,也可以从另一个关系诱导其分片方案。如图所示,关系间存在着link ,如L1,L2,L3。用关系代数的术语来讲,link表示一个关系的外键是另一个关系的主键。例如,L3表示ASG的外键JNO是PROJ的主键。
对于owner关系直接设计其水平分片,对于member关系从owner关系诱导出水平分片的设计。诱导分片的设计方法是半连接。例如,关于ASG的水平分片可如下设计:
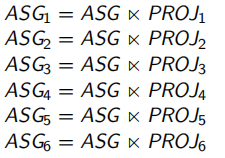
有的member有多个owner,例如,EMP和PROJ都是ASG的owner。这种情况下,从不同的owner诱导出不同的水平分片方案。最终由设计者根据系统分配的需求选取一种。
2.3.5 正确性检查
- 完整性:全局关系的任何数据至少可在一个分片中找到,并且每个分片被访问的概率相同。
- 重构性: R = ∪ R i , ∀ R i ∈ F R 。 R=\cup R_i,\forall R_i ∈ F_R。 R=∪Ri,∀Ri∈FR。
- 不相交性: R i ∩ R j = ∅ , ∀ i , j R i , R j ∈ F R 。 R_i∩R_j=\empty ,\forall i,j\; R_i, R_j ∈ F_R。 Ri∩Rj=∅,∀i,jRi,Rj∈FR。
2.4 垂直分片设计
在分布式数据库中可采用垂直分片分割全局关系,在集中式数据库中也可采用垂直分片设计存储结构,把经常一起被访问的列聚集存放在一起,提高存储效率。
垂直分片可选方案非常多。m个非主键属性可能的垂直分片方案的数量是B(m),当m = 10时,B(m) ≈ 115000,当m = 15时,B(m) ≈ 1 0 9 10^9 109,当m = 30时,B(m) ≈ 1 0 23 10^{23} 1023。因此,垂直分片的设计是非常困难的。
两种启发式的途径:成组和切分。
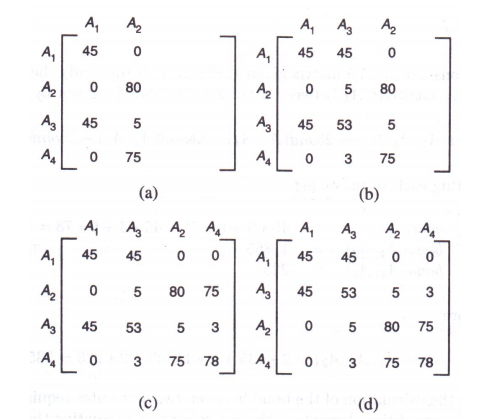
2.4.1 使用矩阵


A 1 = P N O , A 2 = P N A M E , A 3 = B U D G E T , A 4 = L O C A_1=PNO, A_2=PNAME, A_3=BUDGET, A4=LOC A1=PNO,A2=PNAME,A3=BUDGET,A4=LOC
u s e ( q i , A j ) = ( 1 0 1 0 0 1 1 0 0 1 0 1 0 0 1 1 ) use(q_i,A_j)= \begin{pmatrix} 1 & 0 & 1 & 0 \\ 0 & 1 & 1 & 0 \\ 0 & 1 & 0 & 1 \\ 0 & 0 & 1 & 1 \end{pmatrix} use(qi,Aj)= 1000011011010011
2.4.2 亲密矩阵
使用矩阵没有包含应用调用查询的频率信息,不能足够反应出属性之间的亲密程度。为此,进一步给出属性间的亲密度定义:
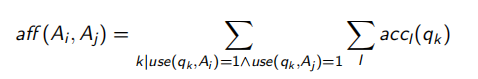
其中, a c c l ( q k ) acc_l(q_k) accl(qk)是应用 I 调用查询 q k q_k qk的频率。

计算方法:
- 先计算 a c c ( q k ) = ∑ l = 1 3 a c c l ( q k ) acc(q_k)=\sum^3_{l=1} acc_l(q_k) acc(qk)=∑l=13accl(qk)
a c c ( q 1 ) = 15 + 20 + 10 = 45 acc(q_1)=15+20+10=45 acc(q1)=15+20+10=45
a c c ( q 2 ) = 5 + 0 + 0 = 5 acc(q_2)=5+0+0=5 acc(q2)=5+0+0=5
a c c ( q 3 ) = 25 + 25 + 25 = 75 acc(q_3)=25+25+25=75 acc(q3)=25+25+25=75
a c c ( q 4 ) = 3 + 0 + 0 = 3 acc(q_4)=3+0+0=3 acc(q4)=3+0+0=3 - 再计算亲密矩阵的上三角元素 a i j = ∑ k = 1 4 a c c ( q k ) ∗ ( u s e ( q k , A i ) ∧ u s e ( q k , A j ) ) a_{ij}=\sum_{k=1}^4 acc(q_k)*(use(q_k,A_i)\wedge use(q_k,A_j)) aij=∑k=14acc(qk)∗(use(qk,Ai)∧use(qk,Aj)),其中 u s e ( q k , A i ) ∧ u s e ( q k , A j ) use(q_k,A_i)\wedge use(q_k,A_j) use(qk,Ai)∧use(qk,Aj)的值为使用矩阵 use 对应元素“与”的结果。
a 11 = 45 ∗ ( 1 ∧ 1 ) + 5 ∗ ( 0 ∧ 0 ) + 75 ∗ ( 0 ∧ 0 ) + 3 ∗ ( 0 ∧ 0 ) = 45 a_{11}=45*(1\wedge 1)+5*(0\wedge 0)+75*(0\wedge 0)+3*(0\wedge 0)=45 a11=45∗(1∧1)+5∗(0∧0)+75∗(0∧0)+3∗(0∧0)=45
a 12 = 45 ∗ ( 1 ∧ 0 ) + 5 ∗ ( 0 ∧ 1 ) + 75 ∗ ( 0 ∧ 1 ) + 3 ∗ ( 0 ∧ 0 ) = 0 a_{12}=45*(1\wedge 0)+5*(0\wedge 1)+75*(0\wedge 1)+3*(0\wedge 0)=0 a12=45∗(1∧0)+5∗(0∧1)+75∗(0∧1)+3∗(0∧0)=0
a 13 = 45 ∗ ( 1 ∧ 1 ) + 5 ∗ ( 0 ∧ 1 ) + 75 ∗ ( 0 ∧ 0 ) + 3 ∗ ( 0 ∧ 1 ) = 45 a_{13}=45*(1\wedge 1)+5*(0\wedge 1)+75*(0\wedge 0)+3*(0\wedge 1)=45 a13=45∗(1∧1)+5∗(0∧1)+75∗(0∧0)+3∗(0∧1)=45
a 14 = 45 ∗ ( 1 ∧ 0 ) + 5 ∗ ( 0 ∧ 0 ) + 75 ∗ ( 0 ∧ 1 ) + 3 ∗ ( 0 ∧ 1 ) = 45 a_{14}=45*(1\wedge 0)+5*(0\wedge 0)+75*(0\wedge 1)+3*(0\wedge 1)=45 a14=45∗(1∧0)+5∗(0∧0)+75∗(0∧1)+3∗(0∧1)=45
a 22 = 45 ∗ ( 0 ∧ 0 ) + 5 ∗ ( 1 ∧ 1 ) + 75 ∗ ( 1 ∧ 1 ) + 3 ∗ ( 0 ∧ 0 ) = 80 a_{22}=45*(0\wedge 0)+5*(1\wedge 1)+75*(1\wedge 1)+3*(0\wedge 0)=80 a22=45∗(0∧0)+5∗(1∧1)+75∗(1∧1)+3∗(0∧0)=80
a 23 = 45 ∗ ( 0 ∧ 1 ) + 5 ∗ ( 1 ∧ 1 ) + 75 ∗ ( 1 ∧ 0 ) + 3 ∗ ( 0 ∧ 1 ) = 5 a_{23}=45*(0\wedge 1)+5*(1\wedge 1)+75*(1\wedge 0)+3*(0\wedge 1)=5 a23=45∗(0∧1)+5∗(1∧1)+75∗(1∧0)+3∗(0∧1)=5
a 24 = 45 ∗ ( 0 ∧ 0 ) + 5 ∗ ( 1 ∧ 0 ) + 75 ∗ ( 1 ∧ 1 ) + 3 ∗ ( 0 ∧ 1 ) = 75 a_{24}=45*(0\wedge 0)+5*(1\wedge 0)+75*(1\wedge 1)+3*(0\wedge 1)=75 a24=45∗(0∧0)+5∗(1∧0)+75∗(1∧1)+3∗(0∧1)=75
a 33 = 45 ∗ ( 1 ∧ 1 ) + 5 ∗ ( 1 ∧ 1 ) + 75 ∗ ( 0 ∧ 0 ) + 3 ∗ ( 1 ∧ 1 ) = 53 a_{33}=45*(1\wedge 1)+5*(1\wedge 1)+75*(0\wedge 0)+3*(1\wedge 1)=53 a33=45∗(1∧1)+5∗(1∧1)+75∗(0∧0)+3∗(1∧1)=53
a 34 = 45 ∗ ( 1 ∧ 0 ) + 5 ∗ ( 1 ∧ 0 ) + 75 ∗ ( 0 ∧ 1 ) + 3 ∗ ( 1 ∧ 1 ) = 3 a_{34}=45*(1\wedge 0)+5*(1\wedge 0)+75*(0\wedge 1)+3*(1\wedge 1)=3 a34=45∗(1∧0)+5∗(1∧0)+75∗(0∧1)+3∗(1∧1)=3
a 44 = 45 ∗ ( 0 ∧ 0 ) + 5 ∗ ( 0 ∧ 0 ) + 75 ∗ ( 1 ∧ 1 ) + 3 ∗ ( 1 ∧ 1 ) = 78 a_{44}=45*(0\wedge 0)+5*(0\wedge 0)+75*(1\wedge 1)+3*(1\wedge 1)=78 a44=45∗(0∧0)+5∗(0∧0)+75∗(1∧1)+3∗(1∧1)=78 - 亲密矩阵 aff 为对称矩阵,根据对称性补完剩下的下三角元素

2.4.3 聚集的属性亲密矩阵(理解即可,有点复杂)
属性亲密度矩阵显然让垂直分片设计工作前进了一步。但是仍然无法直接给出垂直分片方案。如果亲密的属性聚集在一起,设计垂直分片将会比较容易。聚集的属性亲密度矩阵就是亲密属性聚集在一起的属性亲密度矩阵。聚集的属性亲密度矩阵是由属性亲密度矩阵经过行间交换以及对应的列间交换得到的。为通过算法得到这样的矩阵,定义全局亲密度度量:
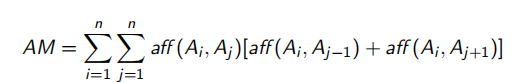




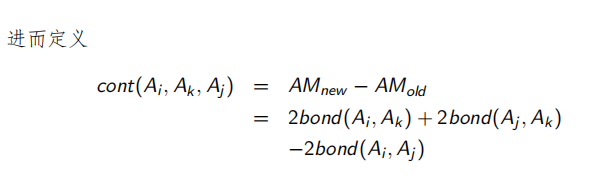

具体例子:
确定分割点
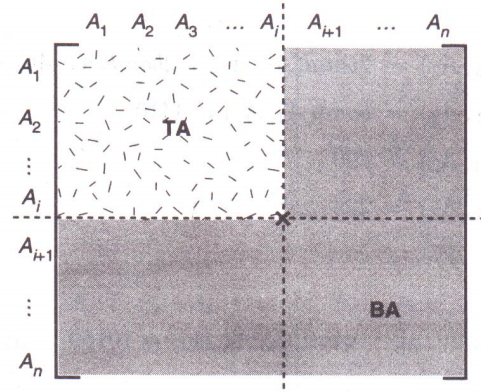

对于n个属性,在CA中有n-1个分割点。每个分割点可以计算一个z值,选取z值最大的那个分割点对属性集合进行划分。这样的划分可迭代进行下去,直到给定的条件满足为止。
假设AS1,AS2,.…. ,ASx是通过上述方法对一个关系进行属性集划分得到的k个属性子集。然后,对这些属性集进行如下处理:

2.4.5 正确性检查
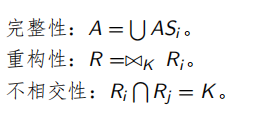
2.5 分解树和重构树
水平分片和垂直分片可以混合使用,如图所示:

上图的树被称作分解树,描述了全局关系与逻辑片段之间的关系。全局关系可由逻辑片段通过重构树(下图所示)的操作序列重构出来。

2.6 分配
每个逻辑片段可以保存在一个节点上,也可以在多个节点上保存多个副本。保存多个副本有利于提高查询的效率,但是却会增加更新的代价。分配是一个非常复杂的优化问题。可简单表述如下:

第三章 分布式查询
3.1 查询分解
3.1.1 规范化
查询条件可由谓词表达式表示,将查询的谓词表达式进行规范化处理有助于删除冗余操作。规范化形式有合取规范化和析取规范化。
- 合取规范化【 ( a + b ) ∗ ( b + c ) ∗ ( c + d ) ∗ . . . (a+b)*(b+c)*(c+d)*... (a+b)∗(b+c)∗(c+d)∗...】
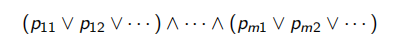
- 析取规范化【 a b + b c + c d + . . . ab+bc+cd+... ab+bc+cd+...】

3.1.2 规范化规则
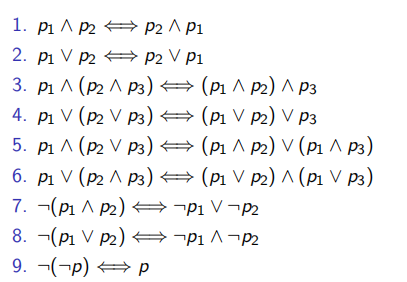
3.1.3 逻辑规则

3.1.4 冗余消除



3.1.5 查询树优化
查询经前述处理后被写成一颗查询树,为减少计算量,需对查询树进行优化处理,优化处理所依据的规则如下。R,S,T表示不同的关
系,A= {A1,A2,……. ,An} 和 B={B1,B2,… ,Bn} 分别表示R, S的属性集。
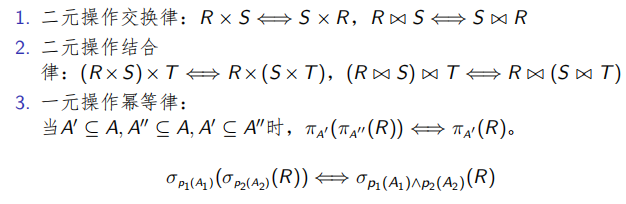

下页左图是一颗查询树,查询树优化的目标就是从等价的查询树中找出代价最小的那一颗。但是等价的查询树数量太多,无法比较所有的查询树代价。可行的办法就是采用启发式的方法寻找较优的查询树。一个启发式途径是:采用下移一元操作的方式优化查询树。
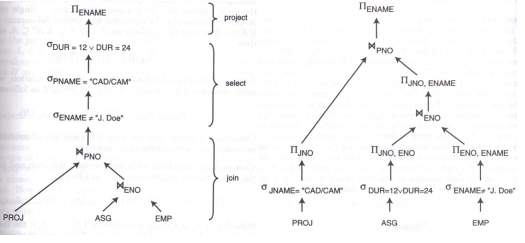
3.2 数据定位
3.2.1 合并重构树
优化后的查询树的叶节点是全局关系,在分布式数据库中全局关系是虚拟的,如果操作没有定位到逻辑片段,查询是无法进行的。将查询操作落实到具体的逻辑片段上,这一工作称为数据定位。数据定位最简单的做法是:用全局关系的重构树代替查询树中的全局关系,把重构树合并到查询树中来。
但是,合并重构树是不够的。因为,对于一个具体的查询有的逻辑片段是不可能有结果,针对这样的逻辑片段进行计算完全是浪费。这里把查询树中不可能有结果的逻辑片段称为无用节点,删除无用节点是需要开展的下一步优化工作。
3.2.2 水平分片的裁剪
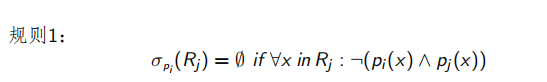
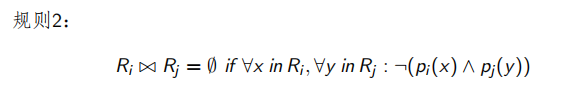
例如:
EMP(ENO, ENAME, TITLE) 和 ASG 被如下分片:
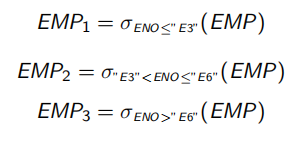
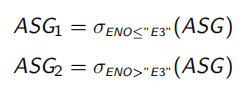
对于查询1:

该查询经初步优化和合并重构树后得到左图所示的查询树,根据规则1裁剪无用节点,得到右图所示的查询树。显然,右图的查询树与左图的查询树相比,可以省掉很多计算,却能够得到同样的结果。
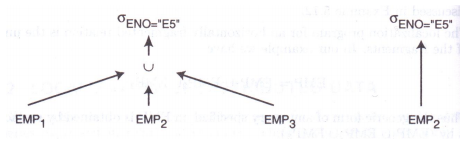
对于查询2:
S E L E T E ∗ F R O M E M P , A S G W H E R E E M P . E N O = A S G . E N O \begin{align} & SELETE\; * \\ & FROM \; EMP,ASG \\ & WHERE \; EMP.ENO=ASG.ENO \end{align} SELETE∗FROMEMP,ASGWHEREEMP.ENO=ASG.ENO
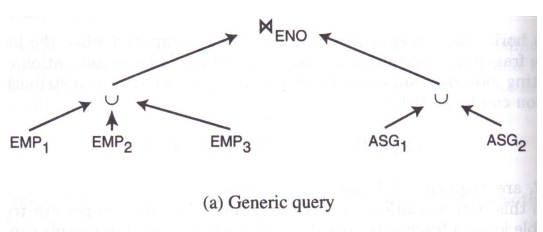
上图的查询树可经过并与连接转换,规则2的转换,变换为下图的查询树。下图的查询树计算量远低于上图。
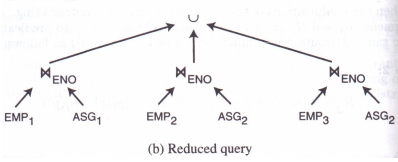
3.2.3 垂直分片的裁剪

对于查询:

该查询经初步优化和合并重构树后得到下图所示的查询树。
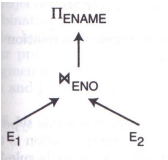
上图的查询树经一元操作幂等律、投影与连接的交换、垂直分片的裁剪转换为下图的查询树。

3.2.4 诱导分片的裁剪

对于查询:
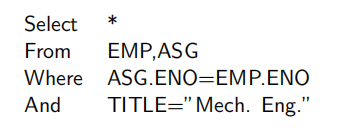
查询树如下:
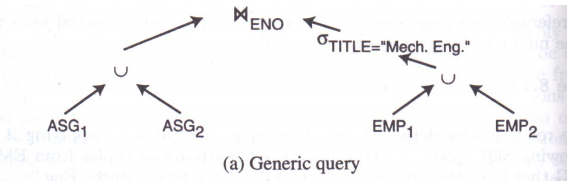
优化【删除空选择】
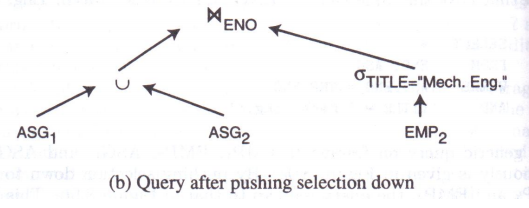
优化【交换连接与并】
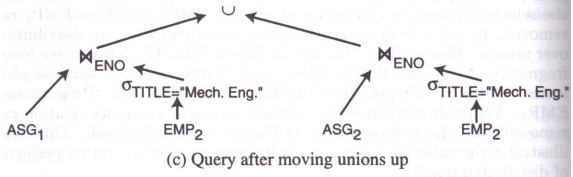
优化【根据诱导分片,删除空子树】
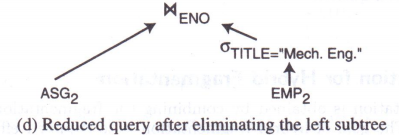
3.2.5 混合分片的裁剪

查询树为:
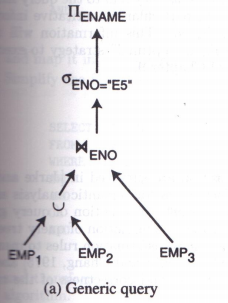
优化后
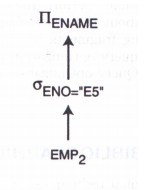
3.3 全局优化
3.3.1 目标
- 在查询操作落实到逻辑片段并裁剪了无用节点之后,查询还需要进一步优化。进一步优化需要考虑执行操作的位置,执行操作的顺序,执行操作的代价等问题。
- 目标是:寻找一个代价最小且与原查询树等价的查询树。
- 代价包括数据通信量、CPU时间、I/O时间等。
这仍然是一个NP困难问题,只能采用启发式方法寻求较优的方案。
3.3.2 代价的估算
查询的代价可以是查询所消耗的总时间,也可以是查询的响应时间。总时间指执行查询的各个操作所消耗的时间总和,响应时间指查询开始到查询完成所经历的时间。
无论是总时间还是响应时间,都需通过数据库的统计数据来估算。
常用的统计量
关系R的属性集为 A = { A 1 , A 2 , … , A n } A= \{A_1,A_2,…,A_n\} A={A1,A2,…,An},被分片为 R 1 , R 2 , … , R n R_1,R_2,…,R_n R1,R2,…,Rn

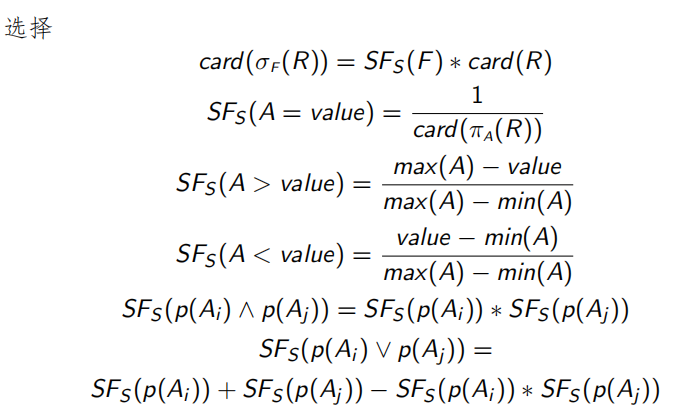

3.3.3 主要优化问题
前面的优化处理已经把操作落实到了逻辑片段上并尽可能下推了一元运算,这时的主要问题是选择连接运算的场地和运算次序。



半连接处理

3.3.4 主要算法
- Distributed INGRES Algorithm
- R* Algorithm
- SDD-1 Algorithm
3.4 局部优化
对那些已经定位到一个场地上的一系列操作采用集中式数据库中的优化方法继续进行局部优化。
局部优化有动态优化和静态优化两种策略,大多数商业关系型数据库系统采用静态优化的策略。
第四章 分布式并发控制
4.1 串行化理论
- 并发控制关系到事务的隔离性和一致性。
- 串行化理论是被广泛接受的判断并发控制正确性的标准。
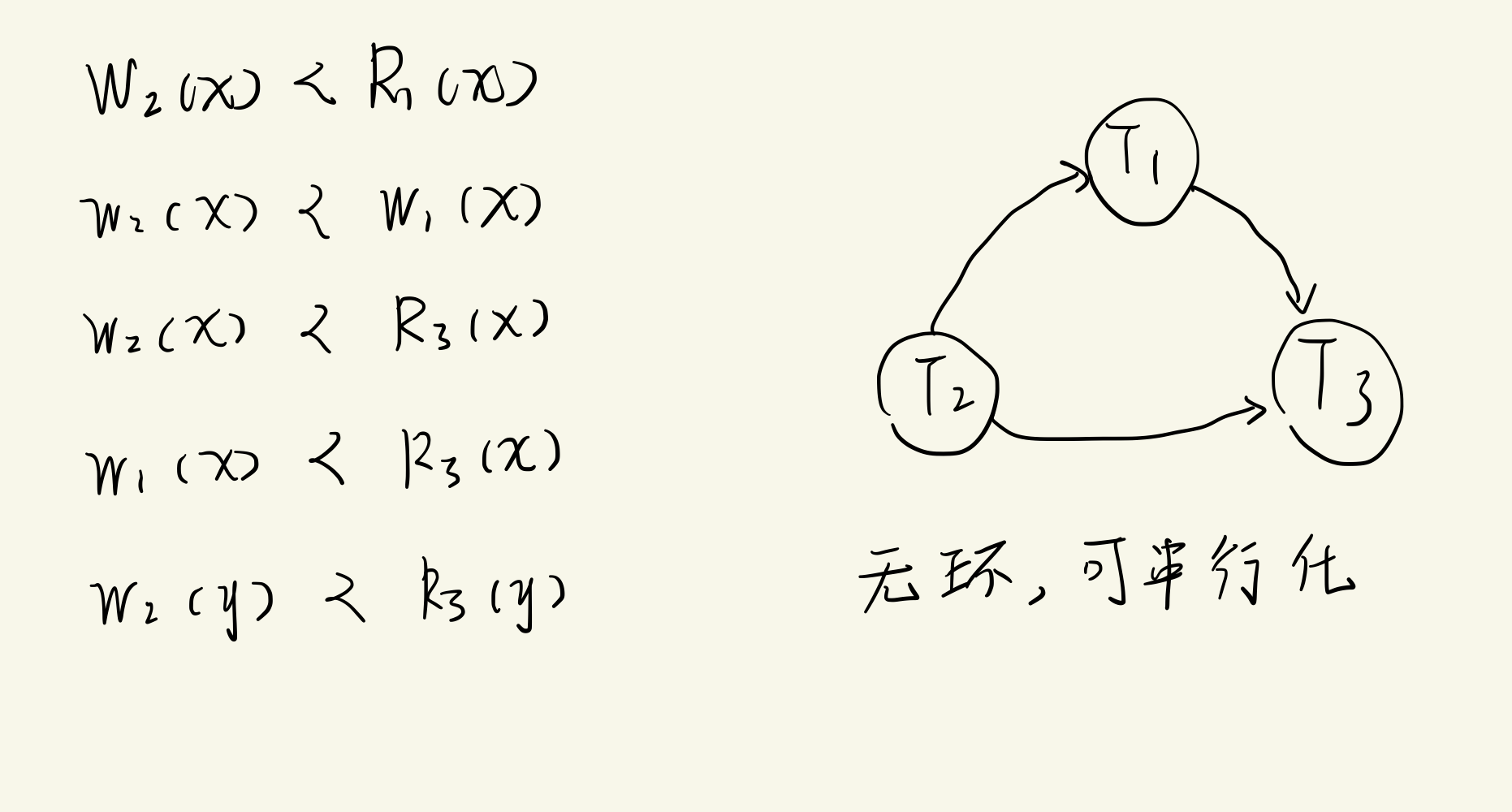
例如,有以下事务及其之上的调度:
T 1 = { R 1 ( x ) , W 1 ( x ) , G 1 } T_1=\{R_1(x), W_1(x),G_1\} T1={R1(x),W1(x),G1}
T 2 = { W 2 ( x ) , W 2 ( y ) , R 2 ( z ) , C 2 } T2= \{W_2(x),W_2(y), R_2(z),C_2\} T2={W2(x),W2(y),R2(z),C2}
T 3 = { R 3 ( x ) , R 3 ( y ) , R 3 ( z ) , C 3 } T3=\{R_3(x),R_3(y),R_3(z),C_3\} T3={R3(x),R3(y),R3(z),C3}
S = { W 2 ( x ) , W 2 ( y ) , R 2 ( z ) , C 2 , R 1 ( x ) , W 1 ( x ) , C 1 , R 3 ( x ) , R 3 ( y ) , R 3 ( z ) , C 3 } S=\{W_2(x), W_2(y),R_2(z),C_2,R_1(x), W_1(x),C_1, R_3(x), R_3(y),R_3(z),C_3\} S={W2(x),W2(y),R2(z),C2,R1(x),W1(x),C1,R3(x),R3(y),R3(z),C3}
S是对事务T1,T2,T3的一个调度。s是一个串行调度,执行的顺序是T2→T1→T3。串行调度可以保证事务的隔离性和一致性,串行调度是正确的调度。但是串行调度完全排斥事务的并发性,效率太低,不可接受。
串行化理论提供了判断并发调度等价于串行调度的方法,把等价于串行调度的调度称为可串行化调度。
4.1.1 集中式可串行化
对同一数据项的读写操作、写写操作被称为冲突操作。例如 W 2 ( x ) , W 1 ( x ) W_2(x),W_1(x) W2(x),W1(x)是一对冲突操作, W 2 ( y ) , R 3 ( y ) W_2(y),R_3(y) W2(y),R3(y)是另一对冲突操作。冲突操作 W 2 ( x ) , W 1 ( x ) W_2(x),W_1(x) W2(x),W1(x)中 W 2 ( x ) W_2(x) W2(x)先于 W 1 ( x ) W_1(x) W1(x),记为 W 2 ( x ) ≺ W 1 ( x ) W_2(x)\prec W_1(x) W2(x)≺W1(x)。同样地, W 2 ( y ) ≺ R 3 ( y ) W_2(y)\prec R_3(y) W2(y)≺R3(y)。根据调度冲突关系绘制调度冲突图,图中无环则为可串行化调度,否则不能判定为可串行化调度
。
调度S本身是串行调度,判断为可串行化调度理所当然。调度S’是一个并发调度,用上述方法判断一下其是否为可串行化的。
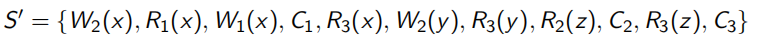
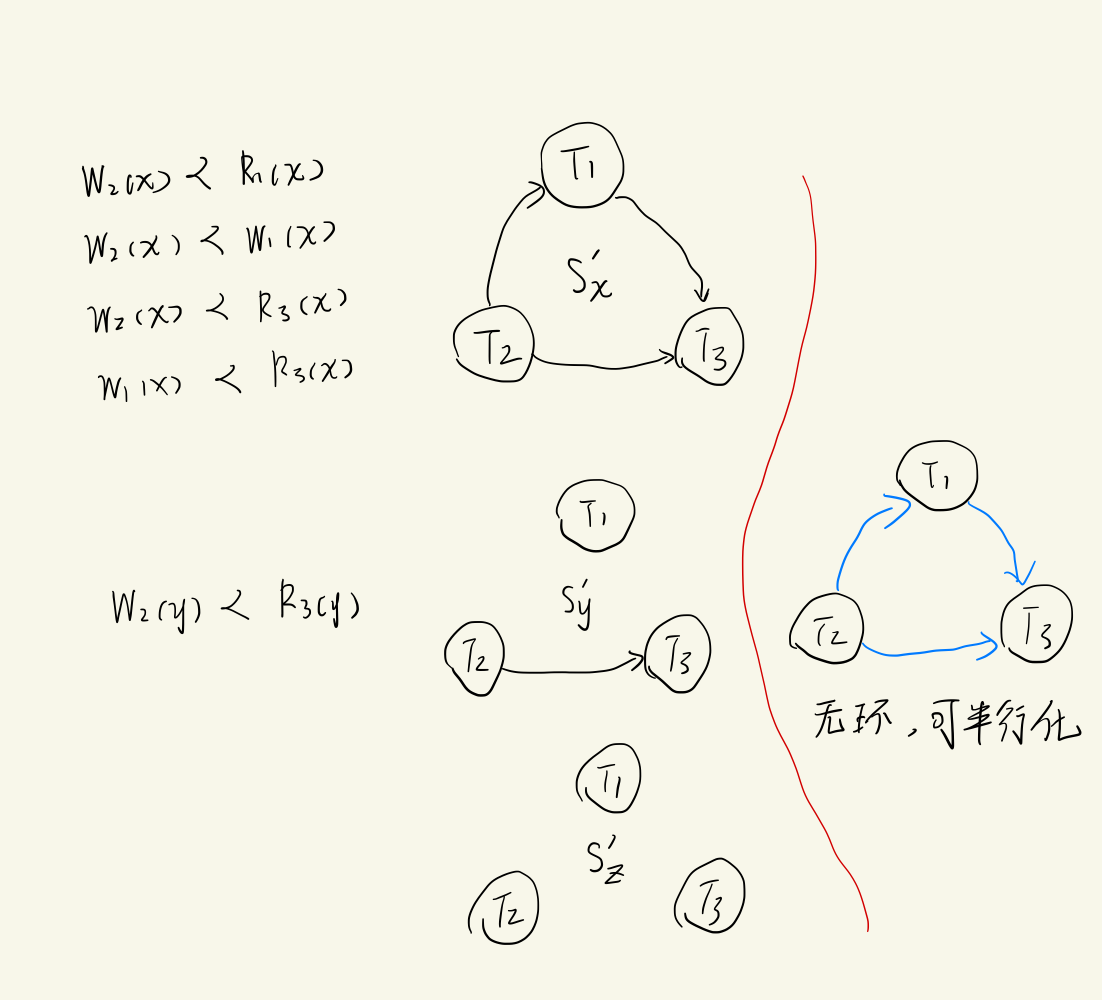
4.1.2 分布式可串行化
串行化理论扩展到分布式环境上才能解决分布式数据库中的调度问题。
假设调度S’中与x数据项有关的操作以及C1操作发生在场地x上,与y数据项有关的操作以及C2操作发生在场地y上,与z数据项有关的操作以及C3操作发生在场地z上,则S’可改写成:
S x ′ = { W 2 ( x ) , R 1 ( x ) , W 1 ( × ) , C 1 , R 3 ( x ) } S'_x=\{W_2(x),R_1(x), W_1(×),C_1, R_3(x)\} Sx′={W2(x),R1(x),W1(×),C1,R3(x)}
S y ′ = { W 2 ( y ) , R 3 ( y ) , C 2 } S'_y = \{ W_2(y),R_3(y),C_2\} Sy′={W2(y),R3(y),C2}
S z ′ = { R 2 ( z ) , R 3 ( z ) , C 3 } S'_z=\{R_2(z),R_3(z),C_3\} Sz′={R2(z),R3(z),C3}
可分别为 S x ′ , S y ′ , S z ′ S'_x ,S'_y,S'_z Sx′,Sy′,Sz′ 绘制冲突调度图,然后合并为一张图,若无环则为可串行化调度,否则不能作出此判断。
4.2 并发控制概况
现有的并发控制 ⊂ \subset ⊂可串行化的并发控制 ⊂ \subset ⊂正确的并发控制 ⊂ \subset ⊂并发控制
4.3 基于锁的并发控制
4.3.1 基本概念
| R L i ( x ) RL_i(x) RLi(x) | W L i ( x ) WL_i(x) WLi(x) | |
|---|---|---|
| R L j ( x ) RL_j(x) RLj(x) | 兼容 | 互斥 |
| W L j ( x ) WL_j(x) WLj(x) | 互斥 | 互斥 |
WL为写锁,RL为读锁。在对数据项进行操作前要上锁,如果没有遇到不兼容的锁,上锁成功才能进行实际操作,否则只有等拥有该锁的事务释放该锁时才会有机会上锁成功。
例如:

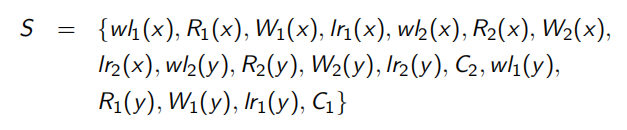
S是关于事务T1,T2的一个基于锁的调度,其中 l r i ( z ) lr_i(z) lri(z)表示释放事务 T i T_i Ti对数据项z的锁。
- 假设在两个事务执行之前x、y的值分别为 50 和 20,T1, T2串行的结果是多少?
102和38,或者101和39 - 依据调度S的执行结果是多少?
102和39 - 这说明S并不是一个可串行化的调度。请用可串行化理论对此作一判断。【并不是基于锁的调度就是可串行化调度】

4.3.2 两段锁协议(2PL)
2PL指2-phase locking,意指把事务的加锁和解锁过程分成两个阶段,加锁阶段和解锁阶段。加锁阶段只加锁不解锁,解锁阶段只解锁不加锁。


4.3.2.1 集中式数据库中2PL的可串行性
可串行化理论证明集中式数据库中2PL的可串行性
假设存在一个环,则意味着存在一组事务T1, T2, …, Tn,使得T1依赖于T2, T2依赖于T3,…,Tn依赖于T1。但是根据2PL协议的规则,事务一旦进入收缩阶段就不会再获取新锁,因此不可能形成这样的环,因为一旦一个事务开始释放锁,它不会再阻塞其他事务的锁请求。
因此,冲突调度图中不可能存在环。
4.3.2.2 分布式数据库中2PL的可串行性
可串行化理论证明分布式数据库中2PL的可串行性

4.4 死锁问题
采用基于锁的调度,事务因为等待锁而形成的一种互相等待关系称为死锁。
在没有外在干预的情况下,陷入死锁的事务将永远等待下去。无论是集中式数据库系统,还是分布式数据库系统,只要采用基于锁的并发控制,就有可能出现死锁的情况。
对于采用2PL的数据库系统,必须处理有可能出现的死锁问题。
4.4.1 死锁的检测和恢复
(1)检测
利用资源分配图,进行检测死锁。

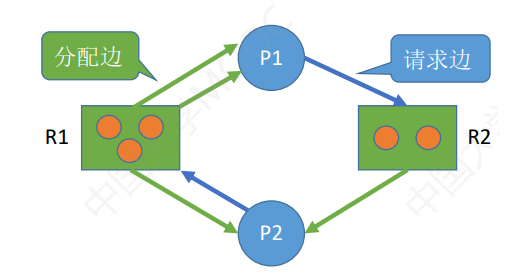
简化:找到可以运行的进程,删去其所有边。
死锁定理:当且仅当系统状态的资源分配图不可以完全简化,则系统处于死锁状态。
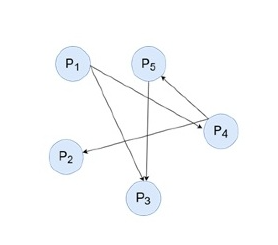
等待图(WFG)
死锁的检测依靠WFG ( wait-for graph), WFG中有环即为存在死锁。
分布式环境中,分别为每个节点绘制WFG,然后把所有节点的IWFG合并为一个gWFG,gWFG中有环即为存在死锁。检测到死锁后,任选一个事务,回滚该事务。
WFG 是进程及其等待的资源之间的依赖关系的图形表示。在WFG中,节点表示进程,资源表示为边。每个边缘都从正在等待资源的进程指向当前持有该资源的进程。
(2)恢复
- 资源剥夺法。挂起(暂时放到外存上)某些死锁进程,并抢占它的资源,将这些资源分配给其他的死锁进程。但是应防止被挂起的进程长时间得不到资源而饥饿。
- 撤销进程法(或称终止进程法)。强制撤销部分、甚至全部死锁进程,并剥夺这些进程的资源。这种方式的优点是实现简单,但所付出的代价可能会很大。因为有些进程可能已经运行了很长时间,已经接近结束了,一旦被终止可谓功亏一篑,以后还得从头再来。
- 进程回退法。让一个或多个死锁进程回退到足以避免死锁的地步。这就要求系统要记录进程的历史信息,设置还原点。
超时法
为每个事务设定一个执行时限。若某个事务超过了执行时限,数据库系统回滚该事务。该方法非常简单,实现较容易。由于事务的的执行时间通常较短,一般来讲,该方法是可行的。
4.4.2 死锁的预防
- 破坏互斥条件:部分互斥资源可以改造为共享资源,如:利用Spooling技术将打印机逻辑上改造为共享资源。(大部分资源不能破坏)
- 破坏不剥夺条件:但进程无法获得新的资源时,该进程必须释放已经占有的资源。(会增加系统开销,降低系统吞吐量)
- 破坏请求和保持条件:进程在运行前一次性申请完所需要的资源。(系统资源严重浪费,可能会导致“饥饿”现象)
- 破坏循环等待条件:给资源编号,进程申请资源必须安照编号递增的顺序申请,且后面的申请编号不能小于前面。(造成资源浪费,用户编程麻烦,不利于系统增加新资源)
4.4.3 死锁的避免
(1)系统安全状态
所谓系统安全状态,是指系统能安照某种进程推进序列为每个进程分配其所需的资源,直至满足每个进程对资源的最大需求,使每个进程都可以完成。此时,该序列为安全序列。若系统无法找到一个安全序列,则系统处于不安全状态。
(2)银行家算法
- 可利用资源向量(Available):向量中的每一个元素代表一类可利用资源数目。
- 最大需求矩阵(Max):表示每个进程最每类资源的最大需求数目。
- 分配矩阵(Allocation):表示每类资源当前已经分配给每个进程的资源数。
- 需求矩阵(Need):表示每个进程接下来最多还需要多少资源。
(3)WFG
在每次事务加锁失败时,先假设该事务转入等待状态,绘制WFG(IWFG,gWFG),检测是否有死锁。如果有,回滚该事务。否则让该事务真正进入到等待状态。
第五章 分布式恢复
5.1 概述
- 事务的原子性和持久性依靠数据库系统的恢复机制来解决。
- 在数据库系统运行时,有可能遇到各种错误,即便这些错误发生,数据库系统也应保证事务的原子性和持久性。
- 在分布式数据库系统中有些问题是新问题。
5.1.1 事务模型
- 分布式数据库中的一个事务被称为全局事务。
- 全局事务涉及多个站点,涉及一个站点的那一部分被称为一个子事务。
- 一个全局事务由一个或多个子事务组成。每个子事务由所在站点的数据库系统所启动的一个进程或线程来执行。
- 原子性要求,构成一个全局事务的所有子事务要么全部提交,要么全部回滚。
5.1.2 错误类型
- 事务级错误。错误的数据导致事务执行过程中出现除0等错误。事务由于陷入死锁或可能陷入死锁导致事务无法正常执行完成。事务级错误在集中式数据库和分布式数据库中都有可能出现。
- 站点级(系统级)错误。(非存储介质)硬件错误、操作系统错误、数据库系统错误、应用程序错误等错误导致系统瘫痪。系统级错误在集中式数据库和分布式数据库中都有可能出现。
- 介质错误。保存数据库的介质(大多数指硬盘)失效,导致数据丢失。介质错误在集中式数据库和分布式数据库中都有可能出现。
- 通讯故障。网络通讯发生故障,致使网络被分割为几个互相不能联通的区域,分布式数据库的节点在不同的区域之中,互相无法知晓其他区域的情况。通讯故障是分布式数据库中特有的情况。
5.1.3 稳定数据库与易失数据库
对数据库的任何操作都首先在内存中进行,然后才会写到外存。
- 外存是稳定的存储,不会因为断电而消失,把DBMS在外存上维持的数据集合称为稳定数据库。
- 内存中保存的数据会因为断电而消失,把DBMS在内存上维持的数据集合称为易失数据库。
5.1.4 稳定日志与易失日志
写日志也是先在内存中完成写操作,再写到外存上。
- 外存上的日志内容称为稳定日志。
- 内存中的日志内容称为易失日志。
5.1.5 错误例子
DBMS在0时刻开始运行,在t时刻发生系统故障。

持久性要求稳定数据库中包含T的全部操作结果。当故障发生时,若T的操作结果还未写入到稳定数据库中,则需要把这些操作“Redo”到稳定数据库中。
原子性要求稳定数据库中不包含T2的任何操作结果。当故障发生时,若T2的操作结果已写入到稳定数据库中,则需要关于这些操作对稳定数据库进行“Undo”操作。
5.2 局部恢复

全局数据库由多个节点构成,每个节点支持一个局部数据库,局部数据库系统如上图所示。每个局部数据库系统负责本地的恢复,同时要保持与其他局部数据库在恢复上的一致性。
基本原理
恢复的依据是日志,DBMS对数据库作任何更新操作前都先写日志。
5.2.1 事务级与系统级错误恢复
- 当发生事务级错误,根据日志的内容对该事务执行“Undo”操作。“Undo”操作确保数据库恢复到事务执行以前的状态。
- 对数据库的任何操作都首先在内存中进行,然后才会写到外存,两者之间一定存在一个时间差。一般情况下,当发生系统级错误时,易失数据库丢失,稳定数据库未包含易失数据库中的最新版本的更新,需要对数据库进行恢复处理。恢复包含对日志的两遍扫描:
- 第一遍,从头到尾扫描日志,把日志中记录的操作“Redo”到稳定数据库中,并记录下未完成的事务。
- 第二遍,从尾到头扫描日志,关于未完成事务的操作对稳定数据库进行“Undo”操作。
5.2.2 检查点
每次都从头开始扫描日志,代价太大,在数据库系统运行一段时间后,基本上不可能这样做。
数据库系统通过设置检查点解决该问题。检查点协议如下:
- 在日志中写入一条begin_checkpoint记录。
- 将检查点数据收集到稳定的存储器中。
- 将end_checkpoint记录写入日志。
其中,第2步有多种不同的做法,事务一致检查点是多种做法之一。事务一致检查点不允许系统接收新事务,等所有活动事务全部完成后,把易失数据库中所有的更新写入到稳定数据库中。
事务一致检查点使得日志中的end_checkpoint record对应着稳定数据库的一个一致的状态。数据库系统周期性地运行检查点协议。当遇到系统级错误时,从最新的那个end_checkpoint record开始扫描日志即可。
5.2.3 日志的完整性
当发生系统级错误时,内存中的易失日志也丢失了。恢复时只有稳定日志可用,对于恢复而言,是否充分?
只要合理安排将易失日志写为稳定日志的时机,就能保证恢复的正确性。如果每次把易失数据库中的更新写到稳定数据库前,以及在每次事务结束前(含事务提交完成和事务回滚完成),都把易失日志中的内容全部写到稳定日志中,则可保证日志对恢复是充分的。
例如:
- t 1 t_1 t1 时刻 T 1 T_1 T1 事务提交完成,数据库系统把易失日志的内容写到稳定曰志中。
- t 2 t_2 t2 时刻,易失数据库中的更新写到稳定数据库前,数据库系统把易失日志的内容写到稳定日志中。
- t 3 t_3 t3 时刻,发生系统级错误,易失数据库和易失日志的内容全部丢失。

数据库系统根据稳定日志的内容对稳定数据库进行“Redo”操作,可以把稳定数据库恢复到 t 2 t_2 t2 时刻的状态,无法恢复到 t 3 t_3 t3 时刻的状态。是否有问题?
无论是 t 2 t_2 t2 时刻的状态还是 t 3 t_3 t3 时刻的状态,都不是一个一致的状态,都要通过对事务 T 2 T_2 T2 的“Undo”操作继续把稳定数据库恢复一个一致的状态( T 1 T_1 T1 完成 T 2 T_2 T2 未做的状态)。尽管 t 2 t_2 t2 时刻的状态不是 t 3 t_3 t3 时刻的状态,也能最终达到这个一致的状态。因此,那些易失日志的丢失对最终的恢复没有影响。
5.2.4 介质错误
数据库系统应对介质错误的方法是归档备份。
- 数据库管理员用数据库系统的备份功能周期性地把数据库和日志备份到脱机存储设备上(一般是磁带或光盘)。
- 一旦出现介质错误,先修复硬件,再用数据库的恢复功能根据脱机设备上的备份把数据库恢复到一个一致的状态。这一恢复过程需要先把备份的数据库(有时也包括日志)复制到硬盘上,后面的处理在原理上与处理系统错误相同。
- 通常,稳定数据库和日志是存放在不同的硬盘上的,并且日志还在多个硬盘上同时保存相同的映像。
- 一般情况下,运行中的日志总会有可用的一个映像。这时只需把备份的数据库复制到硬盘上即可进行后续的恢复工作。
- 在运行中的日志也被破坏了的情况下,需要把备份的数据库和日志都复制到硬盘上才可进行后续的恢复工作。这种情况下,由于归档备份是周期性进行的,归档备份的日志很可能未包含系统最新的更新,因此很可能无法把数据库恢复到最新的一致状态。
5.3 全局恢复
5.3.1 全局事务
用户提交给分布式数据库系统的事务是全局事务,关于事务的ACID是针对全局事务而言的。
用户把全局事务提交给某个节点,该节点上的数据库系统把该全局事务分解为若干子事务,交给不同的节点去处理。每个节点由数据系统启动一个进程或线程来执行子事务。
就一个全局事务而言,有分布在多个节点上的进程或线程共同处理这一全局事务。在发起该事务的那个节点上的进程或线程被称为协调者,其他节点上的进程或线程被称为参与者。
5.3.2 原子性
- 事务级错误
事务级错误发生在参与全局事务的某个节点上。发生错误的那个节点上的子事务首先依据局部恢复的方法进行处理(“回滚”)。事务的原子性要求:无论其它子事务是否有错,这时都必须回滚。 - 系统级错误
当某个节点发生系统级错误时,该节点要进行系统级的局部恢复。局部恢复回滚了在该节点上正在运行的未完成子事务。事务的原子性要求:与这些子事务同属于一个全局事务的其他子事务都应该回滚。 - 介质错误
当某个节点发生介质错误时,该节点要进行介质错误的局部恢复。局部恢复回滚了在该节点上正在运行的未完成子事务。事务的原子性要求:与这些子事务同属于一个全局事务的其他子事务都应该回滚。 - 通讯故障
通讯故障导致网络分割,有些节点的状况无法知晓。事务的原子性要求,一个全局事务的所有子事务要么全部提交要么全部回滚。只有所有子事务都成功完成才能提交所有子事务,否则就要全部回滚。通讯故障导致有些子事务的情况无法知晓,只能让全部子事务回滚。
5.3.3 持久性
只要每个节点都能提供对局部数据库的持久性保障,全局数据库的持久性就得到了保障。
每个节点的局部恢复保障了每个节点的持久性,因此全局数据库的持久性有保障。
5.3.4 关键问题
分布式数据库系统要确保:
- 当任一子事务无法正常完成时或任一子事务的执行情况无法知晓
时,回滚所有子事务. - 当分布式数据库系统知晓所有子事务都正常完成时,所有子事务都
要提交。由于提交过程是不可逆的,所有子事务都不可自行提交。
5.4 两段提交协议
5.4.1 基本思想
两段提交协议简称2PC
- 全局事务的提交过程分为两个阶段:决策阶段和执行阶段。
- 协调者负责决策,参与者依据决策执行。
5.4.2 2PC协议运行要点
- 2PC允许参与者在投票前自行回滚子事务。一旦一个参与者投票了,就不能再改变。
- 参与者处于Ready状态后,既可能转入提交状态,也可能转入回滚状态,这由协调者发来的消息决定。
- 全局事务提交或回滚由协调者决定。协调者决定的原则是:所有参与者投票提交则决定提交,否则决定回滚。
- 协调者和参与者进入某一状态时,必须等待对方的消息。
- 为保证协调者和参与者的进程(或线程)能够最终从这些状态退出并终止,需要为每个进程(或线程)设置计时器。计时器的使用将在失效的情况下讨论。
5.4.3 运行状态转变图

- 协调者的“INITIAL”状态指协调者还未执行到事务的commit命令前的状态。
协调者处于“INITIAL”状态时发生错误,无论哪种错误,协调者的子事务被回滚,协调者直接进入“ABORT”状态,然后每隔一段时间向参与者发一个全局回滚命令,直到收到所有参与者的完成回滚的确认消息后,向日志写入事务完成记录。 - 参与者的“INITIAL”状态指参与者还未收到预提交命令前的状态。
参与者处于“INITIAL”状态时发生错误,无论哪种错误,参与者的子事务被回滚,参与者直接进入“ABORT”状态,等收到协调者的全局回滚命令后向协调者发送执行完回滚的确认消息。
5.4.3.1 协调者超时处理
协调者处于“WAIT”状态超时,可能是由于某个参与者节点发生事务级错误、系统级错误或介质错误,或者是由于网络通讯故障导致报文无法送达。这时,协调者作出“回滚”决定并向所有参与者发送全局回滚命令,转入“ABORT”状态。
协调者处于“COMMIT”和“ABORT”状态超时,协调者不能确定是否所有的参与者都完成了提交或回滚,协调者再次重发全局提交或全局回滚命令。协调者只有在收到所有参与者的执行确认消息之后,才向日志中写入“end-of-transaction”记录。
5.4.3.2 参与者超时处理
参与者处于“INITIAL”状态超时,可能是协调者发生事务级错误、系统级错误或介质错误,或者是由于网络通讯故障导致报文无法送达。这时,参与者自行回滚,转入到“ABORT”状态。如果在这之后,协调者的预提交命令又到达了,参与者可以根据日志记录回复投票回滚,也可以不予回答。两种处理都将导致协调者作出回滚的决定。
参与者处于“READY”状态超时。这时,参与者已投票提交,但是并不知道协调者的决定,参与者只能保持阻塞,等待协调者的全局命令。由于协调者处于“COMMIT”和“ABORT”状态超时会再次重发全局提交或全局回滚命令,参与者一定能够收到协调者的全局命令。
参与者处于“READY”状态超时会被阻塞,直至收到协调者的命令为止。如果参与者暂时收不到全局命令的原因是:协调者站点的系统级错误、介质错误,或者是通讯故障导致网络分割,那么,故障修复是很耗时的。在故障修复之前,参与者是不可能收到全局命令的,因此参与者有可能较长时间被阻塞。有可能较长时间被阻塞的现象是2PC的不利因素。
5.4.3.3 提交过程开始后协调者站点错误
协调者处于“WAIT”状态时协调者站点出错,系统局部恢复后,协调者将按照处于“WAIT”状态超时来继续处理。
协调者处于“COMMIT”或“ABORT”状态时协调者站点出错,系统局部恢复后,协调者将按照处于“COMMIT”和“ABORT”状态超时继续处理。
5.4.3.4 提交过程开始后参与者站点错误
参与者处于“READY”状态时参与者站点出错,系统局部恢复后,参与者将按照处于“READY”状态超时来继续处理。
参与者处于“COMMIT”或“ABORT”状态时参与者站点出错,系统局部恢复后,参与者无需任何处理。
第六章 区块链技术(理解即可)
6.1 比特币及其原理
6.1.1 比特币的诞生

6.1.2 比特币系统的特点
- 比特币系统软件全部开源
- 无中央管理服务器
- 无任何负责的主体,无外部信用背书。
6.1.3 比特币来源
- 挖矿获得
- 交易获得
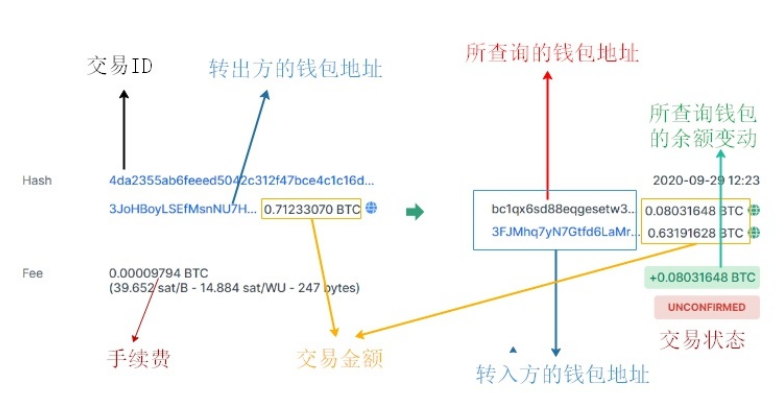
6.1.4 比特币交易
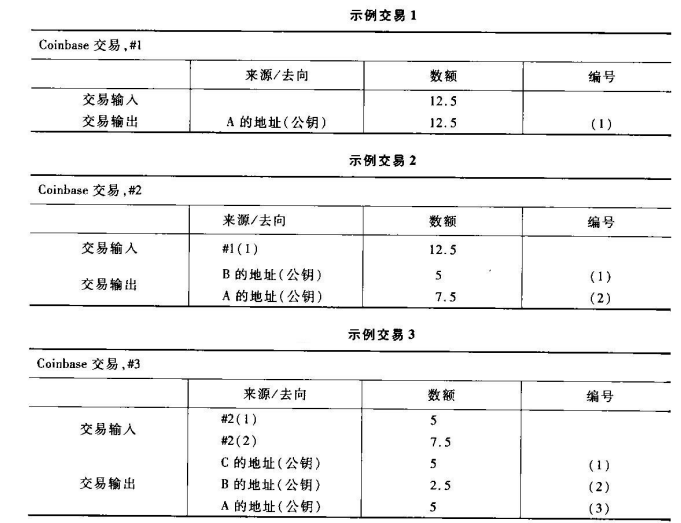
6.1.5 UTXO
6.1.6 账户余额
- 比特币账户与一对公私钥对应,公钥的哈希值为账户地址。
- 比特币系统与普通的账务系统不同,没有记录账户余额,只记录交易信息。
- 一个账户的余额每次都是通过搜索区块链中该账户的所有交易,累加所有交易的增减得到的。
6.1.7 挖矿
比特币系统是一个参与节点互相验证的公开记账系统,挖矿本质上是争夺某一区块的记账权。获得记账权的节点获得一定数量的比特币奖励,包括系统奖励和交易手续费两部分。
系统奖励是比特币发行的手段,最初每获得一次记账权可得50个比特币的系统奖励,每隔4年减半。2140年前后发行完毕,最终整个系统有2100万。
争夺记账权的方式是工作量证明算法(Proof of Work,PoW),其含义是:把上一个区块的哈希值、本区块交易信息默克尔树根和一个未知的随机数拼在一起计算一个新的哈希值,要求这个哈希值以若干个0开头。最先算出符合要求的结果的节点获得记账权。
每个节点收集这段时间内(约10分钟)的全网交易信息(部分或全部)进行检验确认打包成一个新区块,取得记账权(挖矿成功)后向所有的节点广播。其他节点收到广播后,对交易信息的合法性和记账权进行验证。如果通过则接受这个区块,并停止自己的挖矿行为,否则继续挖矿至收到一个可接受的广播或自己挖矿成功。
6.2 区块链原理
6.2.1 区块链内容和区块间的链

按区块存储交易记录,下一个区块存储上一个区块的哈希值,形成链接的关系。
6.2.2 数字签名验证交易
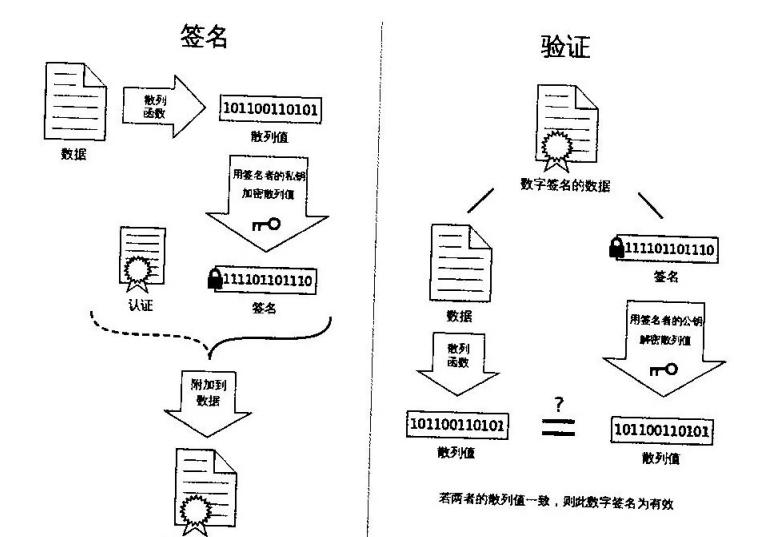
数字签名依赖于公钥和私钥的配对。每个人都有一对唯一的公钥和私钥。公钥用于验证签名,而私钥用于创建签名。当发送方使用私钥对信息进行签名时,接收方可以使用公钥来验证签名的有效性。如果签名有效,这意味着信息在传输过程中没有被篡改,并且确实来自拥有相应私钥的人。
在区块链中,数字签名确保了交易的来源和不可否认性。每个交易都会被发送者的私钥签名,然后广播到网络中。一旦交易被确认并添加到区块链中,它就不能被撤销或更改。这确保了交易的不可否认性,为双方提供了安全保障。
6.2.3 默克尔树组织块内交易
参考来源:区块链中的Merkle树
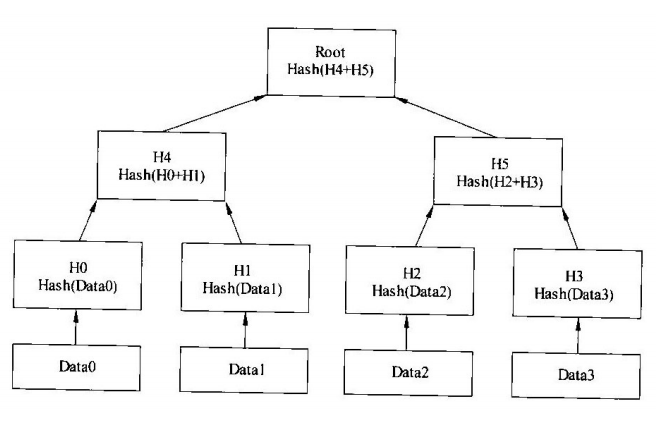
每条交易的哈希值就是一个叶子节点,从下往上将两个相邻叶子节点的组合哈希作为新的哈希值,新的哈希值成为树节点继续与相邻的树节点组合成新的哈希值。在重复一定次数后直到形成唯一的根节点。最后得到的Merkle根需要保存到区块头中,以便仅需通过区块头就可以对交易进行简单支付验证,这一过程也成为SPV(Simplified Payment Verification)。
对于Merkle树而言,并不需要知道整棵Merkle树中每个节点的值,可以通过节点的值、Merkle根的值和相关路径来快速验证该节点是否属于该Merkle树,从而快速验证该区块中是否包含了某条交易。
此外,时间戳用于标记区块顺序。时间戳表示自格林威治时间 1970 年 1 月 1 日 0 时 0 分 0 秒到当前时刻的总秒数,是一种完整且可验证的电子证据,能够为某一数据提供特定时间点的存在性证明。区块链根据时间戳的先后顺序通过链式结构将一个个区块关联起来,因此篡改区块数据的难度以时间的指数倍增加,区块链越长篡改难度就越高,这也是确保区块链不可更改性的重要因素之一。
默克尔树作用:
- 快速比较大量数据:当两个Merkle树的根哈希值相同时,说明所代表的的数据都相同。
- 快速定位修改:当两个Merkle树的根哈希值相同时,说明所代表的的数据都相同快速定位修改:如下图,如果交易C发生改变,那么就会导致N2、N5和Merkle根发生改变。所以,我们想要快速定位,只需要沿着Merkle根→N5→N2就可以定位到交易C发生改变。
 3. 零知识证明:例如,想要证明一组交易中包含某个交易A,但又不想让对方知道交易A的具体内容,那么就可以构建Merkle树,如上图,向对方公布N0、N1、N4和根节点,对方就可以确认交易A的存在,但无法知道交易A的具体内容。
3. 零知识证明:例如,想要证明一组交易中包含某个交易A,但又不想让对方知道交易A的具体内容,那么就可以构建Merkle树,如上图,向对方公布N0、N1、N4和根节点,对方就可以确认交易A的存在,但无法知道交易A的具体内容。
6.2.4 共识机制
区块链由参与节点共同维护,参与节点互不隶属,每个节点都保存区块链的一个副本。每个参与节点都收集验证最近一段时间的交易信息,不同节点收集验证的交易信息可能不一致,也有可能有的节点被恶意操纵收集了非法交易。共识机制保证所有节点最终能够保存一致且正确的副本。
比特币系统采用工作量证明算法(PoW),不同的区块链系统采用的共识算法有所不同。PoW是一个数学难题,只能通过枚举法逐一尝试,只有具备较强算力的节点才可能更快求解。最先得到解的节点获得当前区块的记账权,将当前区块广播给所有节点。其他节点验证被广播来的区块交易信息和记账权的合法性,只有确认合法才接受该区块,否则继续求解PoW,直至自己获得记帐权或收到一个合法的广播来的区块。
6.2.5 P2P
- 交易信息需广播给所有节点,新生成的区块也需要广播给所有节点,直接广播很容易产生广播风暴,网络将不堪重负。
- 区块链系统采用P2P ( Peer to Peer Network)组织参与节点,广播依据P2P协议采取一传十、十传百的方式进行。
6.2.6 智能合约
- 比特币系统的交易脚本可视为智能合约的雏形,由Vitalik Buterin(V神)提出并在以太坊中实现。
- 智能合约的引入是区块链的一个里程碑,使得区块链的应用拓展到了金融、政务、供应链、医疗保健、物流、能源、游戏等各个领域。

- 智能合约是一种在一定条件下自动执行的计算机程序。
- 智能合约保存在区块链中不可更改。
- 区块链系统中的节点通过共识机制验证智能合约的执行结果,保证智能合约的执行结果不会被篡改。
6.2.7 区块链类型
- 公有链
公共区块链网络是一种向公众开放且不需要任何许可即可进入网络的无限制交易网络。如果您有有效的互联网连接,您可以加入任何公共区块链网络并成为该网络的授权成员。作为授权成员或节点,您拥有查看网络上进行的操作的最新和过去信息、真实交易、甚至进行数据挖掘工作量证明的所有权限。谈到安全和隐私,如果成员严格遵守规则和准则,公共区块链网络就是安全的。
公共区块链网络主要用于 密码学开发 及交流活动。您还可以使用它来获取由可审核的操作链组成的永久数据记录。法律宣誓书或财产记录的电子认证是公共区块链技术的几个例子。 - 私有链
私有区块链基本上是一个受限制的网络,需要特殊许可才能进入。此类区块链网络多用于那些需要一小部分成员参与网络交易的行业和领域。网络管理员有责任管理安全级别、用户数量、授权以及进入网络的特殊权限。与公共区块链网络相比,私有区块链也提供相同的功能,但它使网络仅限于授权用户。
私有区块链网络主要用于需要保护网络免受外部实体侵害的情况。私有区块链的一些常见用例包括公共投票、资产所有权、供应链管理等等。 - 联盟链
联盟链是一个半去中心化的网络,由多个网络管理员组成。这种类型的区块链网络与私有区块链网络完全相反,在私有区块链网络中,单个网络管理员管理整个网络。在联盟链网络中,多个组织可以作为节点运行,成功完成交易和交换信息。这种类型的区块链通常用于银行和政府机构。
联盟区块链网络用于银行、支付、食品或送货跟踪以及研究。
6.3 区块链与加密货币的关系
- 区块链是比特币的底层技术和基础构架。
- 区块链是技术,加密货币是区块链支持的应用。
- 区块链技术源自加密货币,但其应用可以拓展到其他领域。
6.4 区块链主要框架
- 比特币系统
- 以太坊系统
- 超级账本——由Linux基金会牵头并创立的分布式账本平台。
6.5 区块链与数据库的比较
- 数据库系统和区块链系统都支持记账,但记账的方式不一样。数据库系统以账户余额为核心记账,区块链系统以交易记录为中心记账。
- 数据库系统在交易记录累积到一定量时,可以让交易记录离线,区块链系统把区块链视为一个整体,不可能剥离任何已经入链的交易记录。
- 数据库系统处理交易的效率很高,吞吐量很大;区块链系统处理交易的效率很低,吞吐量很低。
- 区块链系统能够保证交易信息不能被篡改不能被伪造,数据库系统不能提供这样的保证。
- 数据库系统的故障恢复机制主要依靠日志来实现,区块链系统的故障恢复主要依靠节点间的相互复制来实现。
- 区块链系统处理的数据规模远小于数据库系统。比特币系统运行至今(十年多),整个区块链大约185G大小。
第七章 NewSQL数据库
7.1 基本概念
- NewSQL是对各种新的可扩展高性能数据库的简称,这类数据库不仅具有NoSQL对海量数据的存储管理能力,还保持了传统数据库支持ACID和SQL的特性。
- NewSQL数据库支持关系数据模型和SQL。
- NewSQL针对数据量庞大且包含大规模事务处理的应用。NewSQL不同于数据仓库,数据仓库虽然能够存储大规模数据,但针对的是OLAP。OLAP的焦点是在大规模数据集上执行复杂的只读查询。
- NewSQL执行的读写事务具有以下特点:①时间短,②通过索引定位到一个很小的数据子集上,③同一事务会被反复执行。
- NewSQL的实现应基于非锁的并发控制和shared-nothing的分布式体系结构。
7.2 类别
7.2.1 New Architecture
- DBMS不是对旧系统的扩展,而是全新开发的。网络连接起来的众多节点间shared-nothing,数据库在DBMS的管理下分布在这些节点上,DBMS支持跨节点的并发控制、分布式查询处理、容错处理和流控制。
- DBMS实现分布式的查询优化和节点间的通信协议。无论数据保存在内存还是盘上,DBMS都自己管理存储空间,而不依赖分布式文件系统。
- 例子:Clustrix,CockroachDB, Google Spanner,H-Store, HyPer, MemSQL, NuoDB, SAP HANA, VoltDB.
7.2.2 Transparent Sharding Middleware
- 中间件允许数据库被划分成若干子集,每个子集存储在一个单节点DBMS实例中,中间件把这个单节点DBMS实例的集群集成为一个逻辑整体。
- 中间件将查询定位到具体的节点上,协调事务的执行,管理数据在节点间的分片、存储和复制。
- 对于已使用旧的单节点数据库的应用,中间件类别具有优势。
- 通常,中间件支持MySQL的wire协议,便于集成单节点MySQL实例。单节点上的传统DBMS是面向磁盘存储的,无法利用面向内存存储的存储管理和并发控制优化方法。
- 例子:AgilData Scalable Cluster, MariaDB MaxScale, ScaleArc, ScaleBase.
7.2.3 Database-as-a-Service
- 云计算提供的一种Database-as-a-Service的产品。
- 用户不用维护DBMS,DBaaS提供者负责DBMS安装、升级和配置,负责数据库的创建、物理配置、复制和备份等任务,用户付费即可。
- DBMS采用不同于传统DBMS的体系结构。
- 例子:Amazon Auora,ClearDB.
7.3 研究热点
7.3.1 内存存储
传统数据库都是面向盘存储的,这在以前的确是必要的,内存的容量和费用都不允许把整个数据库存放在内存中。现在,内存的容量已经足够存储几乎最大的OLTP数据库了,费用也不是问题了。内存存储将使得数据库操作更加优化,数据库访问更加快捷。
内存数据库并非新技术,NewSQL需处理的新问题是: NewSQL应有能力选出不常用的数据子集,将其移出到永久存储介质上,从而能够支持数据量大于内存容量的数据库。实现的途径通常就是一种内部的数据访问跟踪机制。
内存存储的NewSQL DBMS有: H-Store、HyPer、MemSQL、 VoltDB。
7.3.2 数据分片
- 数据库被划分成不相交的数据子集,分散存放在不同的节点上。这其实就是分布式数据库的理念。分布式数据库并未流行起来的原因有两个:第一,20世纪的硬件太昂贵,一般的机构承受不了把数据库部署在计算机集群上的费用;第二,那时也没有强烈的对高性能分布式数据库的应用需求,那时所期望的数据库峰值吞吐量一般是每秒几十到几百个事务。
- NewSQL系统把查询分解成对分片的查询,把各节点的查询果组合成一个单一的结果交给用户。许多OLTP数据库应用中,数据库中的表由外键关系形成了一个树状的结构,这样的结构利于水平分片,诱导分片,分片使得同一实体的相关记录存放在同一个结点上。这样的数据分片也使得多数事务只用访问一个节点,从而降低系统运行的通信代价。
- 有的NewSQL DBMS采用了异构的节点体系结构。例如 MemSQL 和NuoDB,它们的节点分为存储管理节点和事务引擎节点。这样的做法,可以在不进行重新分片的情况下,向DBMS集群中增加计算资源。
- NewSQL的一个新特点是,DBMS支持数据的动态迁移,数据迁移可以解决负载平衡的问题。在服务不中断并且保障事务的ACID特性的前提下,在存储节点间迁移数据是很困难的。
7.3.3 并发控制
分布式数据库基本上采用2PL进行并发控制。由于处理死锁问题太复杂,NewSQL基本上不采用2PL。当前的趋势是使用Multi-Version Concurrency Control(MVCC)。MVCC既可以基于锁实现,也可以基于时间印实现,大多数NewSQL使用基于时间印的MVCC。
7.3.3.1 基于时间印的MVCC
每个事务T有一个由系统赋予的唯一的时间印TS(T),后启动的事务的时间印大于先启动的事务的时间印。每个数据项O有一个读时间印RTS(O)和一个写时间印WTS(O)。
执行情况:
- 如果事务T想要读数据项O:
- 如果TS(T)小于WTS(O),则比T后启动的事务已改变了O的值,T已经无法读到它想要的那个值,T被回滚并被重新启动。
- 如果TS(T)不小于WTS(O),则T读О的值是安全的,允许该操作,并用max(RTS(O), TS(T))更新RTS(O)。
- 如果事务T想要写数据项О:
- 如果TS(T)小于RTS(O),则有一个比T后启动的事务正在使用О的当前值,该写操作将破坏数据一致性,不被允许,T被回滚并被重新启动。
- 如果TS(T)小于WTS(O),则有一个比T后启动的事务已更改О的值,依据Thomas写规则,该写操作被忽略。(为什么)【因为比T后启动的事务要修改O的值,它会修改事务T修改后的数据,所以此时事务T的写操作被忽略】
- 否则,该写操作被允许,并用TS(T)更新WTS(O)。
7.3.3.2 基于时间印的MVCC(改进——解决级联依赖问题)
问题:
- 事务由一组有序的读写操作组成,事务 T i T_i Ti写的数据被事务 T j T_j Tj读取使用后,事务 T i T_i Ti被回滚了,事务 T i T_i Ti要怎么办?
答:事务 T j T_j Tj也只能被回滚。事务之间存在依赖关系,一个事务被回滚,依赖它的一系列事务都要被回滚。级联依赖将导致级联回滚。 - 事务 T i T_i Ti写的数据被事务 T j T_j Tj读取使用后,事务 T j T_j Tj先执行至commit,事务 T j T_j Tj可以先提交吗?
答:不能。事务 T i T_i Ti在没有提交前都有可能回滚,如果事务 T j T_j Tj先提交了,当 T i T_i Ti被回滚时,就无法回滚 T j T_j Tj了。而在这种情况下,是必须回滚 T j T_j Tj的。事务 T j T_j Tj必须等待事务 T i T_i Ti提交之后才能提交。级联依赖关系也会导致事务提交的级联等待。
执行情况:
- 如果事务T想要读数据项O:
- 如果TS(T)小于WTS(O),则比T后启动的事务已改变了O的值,T已经无法读到它想要的那个值,T被回滚并被重新启动。
- 如果TS(T)不小于WTS(O),则T读О的值是安全的,允许该操作,DEP(T).add(WTS(O)), 并用max(RTS(O), TS(T))更新RTS(O)。
- 如果事务T想要写数据项О:
- 如果TS(T)小于RTS(O),则有一个比T后启动的事务正在使用О的当前值,该写操作将破坏数据一致性,不被允许,T被回滚并被重新启动。
- 如果TS(T)小于WTS(O),则有一个比T后启动的事务已更改О的值,依据Thomas写规则,该写操作被忽略。(为什么)【因为比T后启动的事务要修改O的值,它会修改事务T修改后的数据,所以此时事务T的写操作被忽略】
- 否则,该写操作被允许,并用TS(T)更新WTS(O)。
- 若DEP(T)中的事务还有未提交的,T必须等待,不能提交,当若DEP(T)中的所有事务都提交了,T可以提交。若DEP(T)中的某个事务被回滚,T也必须被回滚。
7.3.3.3 基于时间印的MVCC(改进——提高系统效率)
问题:
- 一般情况,对数据库的读操作和写操作,哪个更多?
答:读操作要多得多。很多事务是只读事务,有的只读事务读取大量数据项。 - 时间印调度是否可能导致事务频繁被回滚?
答:有可能。频繁的事务回滚也会降低系统效率,还有可能导致长的只读事务出现饥饿现象。
基于TO的MVCC仍然使用时间印调度,但保存数据项的多个版本,从而使得所有的读操作都不会失败。
每个数据项О都保存多个版本,O的任一版本 O i O_i Oi都有它的读时间印RTS( O i O_i Oi)和写时间印WTS( O i O_i Oi)。
执行情况:
- 如果事务T想要读数据项О:
- 若WTS( O i O_i Oi)是O各个版本中写时间印小于等于TS(T)中的最大者,返回 O i O_i Oi的值。DEP(T).add(WTS( O i O_i Oi)),并用max(RTS( O i O_i Oi), TS(T))更新RTS( O i O_i Oi)。
- 如果事务T想要写数据项O:
- 在О的各个版本中,WTS( O i O_i Oi)是最大的写时间印,如果TS(T)大于或等于WTS( O i O_i Oi)且TS(T)小于RTS( O i O_i Oi),T被回滚并被重新启动。否则,创建O的一个新版本,其读时间印和写时间印都置为TS(T)。
- 若DEP(T)中的事务还有未提交的,T必须等待,不能提交,当若DEP(T)中的所有事务都提交了,T可以提交。若DEP(T)中的某个事务被回滚,T也必须被回滚。
问题:
- MVCC的事务回滚应怎么处理?
答:逐一删除被回滚事务所创建的数据版本。 - MVCC导致数据版本一直累积,是否有必要保存所有的数据版本。
答:没必要。过多的数据版本也会浪费存储资源。数据库系统每隔一段时间运行垃圾处理程序删除无用的数据版本。判定无用的规则:在写时间印小于系统当前最老事务的时间印的数据版本中,WTS( O i O_i Oi)最大,保留 O i O_i Oi,写时间印小于WTS( O i O_i Oi)的数据版本均无用。
7.3.4 辅助索引
- 辅助索引指建立在非主键属性或非分区键属性上的索引。辅助索引能够加快查询条件涉及非主键属性或非分区键属性的那些查询。当数据库面临很多这样的查询时,辅助索引能够非常有效地提升查询性能。
- 建立辅助索引面临两个问题:①如何保存索引;②如何更新索引。
- 构建在新构架上的NewSQL都在每个节点上建立局部辅助索引。这种做法,查询需要多个节点配合互相配合,但事务对一个数据项的写操作引起的辅助索引更新只要在一个节点上处理即可。
7.3.5 复制
- 确保高可用性和高可靠性的最好方法就是节点间的复制。对于强一致性的DBMS必须保证在事务提交前在事务的所有副本上完成事务的更新处理。维持副本间的同步要求DBMS使用原子性的提交协议(例如2PC)。
- 所有的NewSQL都支持强一致性,而NoSQL通常仅支持弱一致性(最终一致性)。NoSQL系统通知应用写完成时,并非所有的副本都确认了更新。
- 副本间的更新传播可以采用主从式结构来实现,如果采用对等结构则需要使用以Paxos算法为代表的一类方法进行协调。
7.3.6 故障恢复
- 传统数据库系统关注的焦点是更新不能丢失,NewSQL除了这个焦点外,还希望最小化数据库系统的服务中断时间。
- NewSQL建构在集群之上,基本上每个节点都有若干同步复制的节点,当一个节点崩溃了,与之同步的节点可以替代它的作用(数据库服务几乎没有中断),崩溃的节点依靠自身的日志恢复到的状态已经不是数据库的最新状态,还需要与替代它的节点同步才能恢复到数据库的最新状态。
7.4 未来的趋势
- 在新数据和历史数据上的混合分析处理。有的数据在最新的时候价值最高。
- 支持机器学习算法的运行。
- OLTP与OLAP合二为一避免数据库向数据仓库的数据迁移。
第八章 NoSQL数据库(理解即可)
8.1 基本概念
- NoSQL=Not Only SQL。
- 非关系型的数据存储。不需要预定义数据模式。
- 将数据进行划分,分散在多个节点上存储。
- 弹性可扩展:可以在系统运行的时候,动态增加或者删除结点,不需要停机维护,数据可以自动迁移。
- NoSQL数据库并不严格保证事务的ACID特性,仅保证最终一致性和软事务。
- NoSQL数据库并没有统一的架构。
8.2 GFS
8.2.1 Bigtable的存储基础
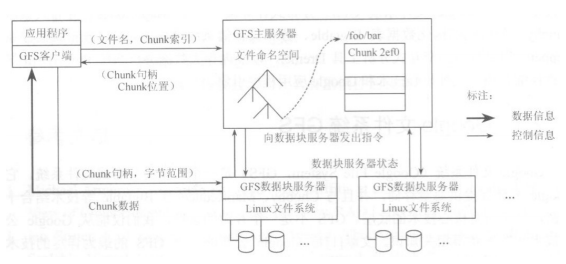
Bigtable的一个表往往需要占用集群中多台服务器的存储空间。GFS ( Google File System)是一个分布式文件系统,统一管理集群中众多服务器的存储空间。Bigtable 以GFS为存储基础,无需处理存储位置与物理服务器间的关系。
8.2.2 架构
8.2.3 特点
- 采用中心服务器模式: Master服务器管理文件系统的所有元数据,文件被划分成Chunk(默认64MB,对应为本地文件系统的一个文件),Chunk服务器管理Chunk 为文件提供存储空间。客户端的所有操作都先经过Master服务器,获取Chunk句柄和位置,客户端直接与Chunk服务器交互来存
取Chunk。Chunk服务器之间没有任何关系,可随时向Master服务器注册加入到文件系统中,也可随时退出文件系统。Chunk服务器之间的负载均衡由Master服务器负责。 - 不缓存数据
- 用户态下实现,Master服务器和Chunk服务器都以进程的方式运行。
- 只提供专用接口,与POSIX规范不兼容。
8.2.4 容错机制
- Master服务器保存的元数据包括命名空间(整个文件系统的目录结构)、Chunk与文件名的映射表和Chunk副本的位置信息。
- Master服务器依靠日志和远程备份两种机制容错。
- 每一个Chunk有多个存储副本(默认3个),分布存储在不同的Chunk服务器上。一旦某个Chunk服务器宕机,Master服务器可启动一台新的Chunk服务器替代它。
8.3 Chubby
8.3.1 锁服务
- Chubby是一个提供粗粒度锁服务的文件系统。
- Chubby锁是一种建议性的锁,而非强制性的锁。
- GFS使用Chubby选取一个Master服务器。
- Bigtable使用Chubby指定一个主服务器并发现、控制与其相关的子表服务器。
8.3.2 Chubby单元

一个Google数据中心仅运行一个Chubby单元,一个Chubby单元一般由5个配置完全相同的服务器组成,向客户端提供高度可靠的服务。Chubby单元的多个服务器维持一致的副本,任意一个服务器都可以向客户端提供服务,提供服务的过程中宕机,Chubby单元可以自动选择另一服务器接替其工作。
8.3.3 Chubby服务器

最底层是一个容错日志,副本之间通过Paxos协议进行通信保障数据一致性,中间层是一个容错的数据库,Chubby构建在这个数据库之上,所有的数据都存储在设个数据库中。Chubby是一个存储大量小文件的文件系统,每个文件代表一个锁,用户通过打开或关闭文件获得或释放锁,通过读取文件获取相关信息。
8.3.4 Chubby通信协议
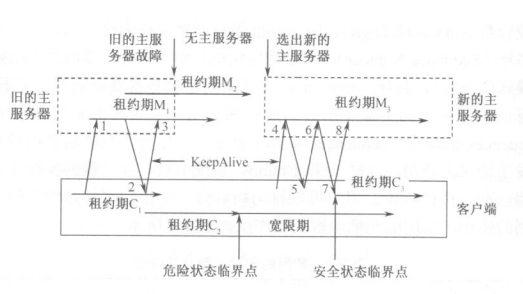
初始时,客户端向主服务器发出KeepAlive请求(1),如果有需要通知的时间则主服务器会立刻回应,否则主服务器并不立刻回应,而是等到客户端的租约期C1快结束时才回应(2),并更新主服务器的租约期为M2。客户端接到回应后认为主服务器仍处于活跃状态,将租约期更新为C2,并向主服务器发出新的KeepAlive请求(3)。同样地,主服务器可能不是立刻回应而是等待C2接近结束,但是这个过程中主服务器出现故障停止使用。一段时间后C2到期,客户端清空并暂停使用自己的缓存,进入宽限期(默认45秒),在宽限期内客户端不断探询服务器的状态。新的主服务器会很快被重新选出,当它接到客户端的第一个KeepAlive请求(4)时,由于这个请求带有旧服务器的标识,发出带有新服务器标识的拒绝回应(5)。
客户端收到后用新服务器标识再次发送KeepAlive请求(6)。新的主服务器接受这个请求并立刻回应(7)。如果客户端在宽限期内收到这个回应,恢复到安全状态,租约期更新为C3。如果客户端没有在宽限期内收到这个回应,客户端终止会话。
通常,遇到主服务器宕机时Chubby单元可以在宽限期内完成新旧主服务器的替换,用户感觉不到主服务器宕机了。
8.4 Bigtable
8.4.1 特点
- Bigtable构建在GFS和Chubby的基础上。
- 支持处理各种数据类型。
- 支持海量的服务请求,可用性高。
- 可以部署在大量的服务器之上,并且可以随时加入或撤销服务器。
8.4.2 数据模型
- Bigtable的存储逻辑可以表示为:
(row:string, column:string, time: int64)—>string - Bigtable的存储格式如下:

- Bigtable的行
- Bigtable是一个分布式多维映射表,表中的数据通过行关键字、列关键字和时间戳来索引。Bigtable对数据不做解析,一律看作字符串,具体数据结构的实现需用户自行处理。
- 行关键字可以是任意字符串,大小不超过64KB。Bigtable不支持一般意义的事务,但能保证对行读写操作的原子性。
- 表中的数据按照行关键字排序。Bigtable把一个表分成多个子表,每个子表包含多个行,子表是Bigtable中数据划分和负载均衡的基本单位。
- Bigtable的列
- 包含哪些列无需事先定义。
- 类型相同的列组成列族,同族的数据会被压缩在一起保存(相当于垂直分片)。
- 列关键词的形式为,族名: 限定词( family: qualifier )
- Bigtable的时间戳
- Bigtable的时间戳是一个由系统生成的代表当前时刻的64位整数。
- 时间戳的作用是区分同一数据的不同版本。
- Bigtable处理数据版本有两个不同策略。一种是保存最近的N个不同版本,另一种是保存最近一段时间的所有版本。
8.4.3 系统架构

Bigtable在Google WorkQueue、GFS和Chubby三个组件基础上构建。Google WorkQueue处理分布式队列分组和任务调度,Google未公布其细节。GFS用来存储数据和日志。Chubby的主要作用包括:1.选取并保证同一时间内只有一个主服务器;2.索引子表位置信息;3.保存Bigtable 模式信息及访问控制列表。
Bigtable由客户端程序库、一个主服务器和多个子表服务器三部分组成。客户端访问Bigtable服务与主服务器的交互极少,客户端通过Open()操作从Chubby那里取得一个锁后直接与子表服务器交互。
主服务器负责元数据操作和子表服务器之间的负载调度。一个表被划分为多个子表(相当于水平分片),子表大小一般在100M至200M之间,运行过程中子表大小变化后,系统兵动分割或合并子表。一个子表服务器通常保存多个子表。
8.4.4 主服务器
- 当一个新的子表产生时,主服务器通过一个加载命令将其分配给一个空间足够的子表服务器。
- 创建新表和表合并都会产生新的子表,主服务器自动检测并进行处理。
- 较大子表的分裂由子表服务器发起并完成,子表服务器完成后通过Chubby通知主服务器为新的子表分配子表服务器。
- 子表服务器的基本信息保存在Chubby中一个称为服务器目录的特殊目录中,主服务器通过检测这个目录可以了解子表服务器的状态,子表服务器包含哪些子表等信息。
- 主服务器一旦检测到某个子表服务器出现问题,将中止该子表服务器,将其上的子表移到其他子表服务器上。
- 主服务器一旦检测到某个子表服务器负载过重会自动进行负载均衡操作。
- 主服务器自身也有可能出现故障,系统启动新的主服务器的过程包含4个步骤:
- 从Chubby中获得一个独占锁,确保同一时间只有一个主服务器。
- 扫描Chubby上的服务器目录,发现当前活跃的子表服务器。
- 与所有活跃子表服务器取得联系。
- 扫描元数据表,发现未分配的子表并将其分配给合适的子表服务器。
8.4.5 子表结构
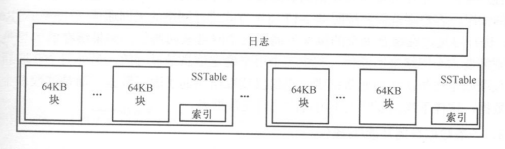
- 每个子表都由多个存储在GFS上的SSTable文件组成,SSTable被分成若干个块(一般64K,可调整),结尾处有一个索引保存块的位置信息。
- 每个子表服务器维持一个日志文件,日志的内容按键值排序,与子表形成分段对应关系。
8.4.6 元数据表
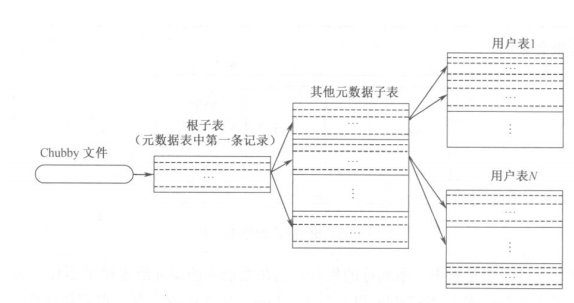
所有的子表地址存储在元数据表中,元数据表由一个个元数据子表组成,其结构与B+树类似。Chubby中的一个文件存储根子表信息。根子表是元数据表的第一条记录,也保存其他元数据子表的地址。
8.4.7 读写操作
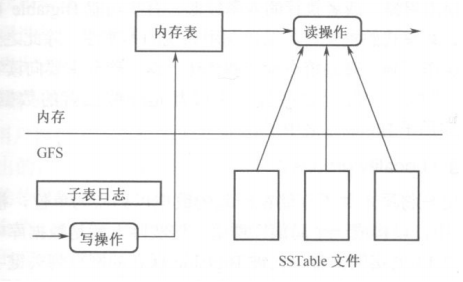
- Bigtable把较新的数据存储在内存中,称为内存表,把较早的数据以SSTable 格式保存在GFS中。
- 写数据时先写日志,再写内存表,即完成写操作,并不急于马上写入GFS。
- 读数据时,需合并读出的SSTable和内存表。
- 内存表容量超过一个阈值时,旧的内存表会被压缩成SSTable格式存入GFS。
第九章 课程设计
9.1 需求
- 单车信息应按城市水平分片
- 用户量大,用户描述信息(包含用户余额)需分片。
- 行程信息量更大,还需记录行程轨迹(用 bigtable 类似存储)。
- 用户的优惠卷信息,到期自动删除。
- 公司的充值活动、优惠卷活动,活动结束自动删除。
- 充值、兑现、购买优惠卷的支付处理(跨数据库的一致性提交)。
- 开锁处理(含判断是否有钱)
- 上锁处理(含付费)
设计文档包括表及其结构、表间的关联、表的分布设计、<key, value>存储及其与表之间的联系、关键事务的描述、主要的查询流程。
9.2 设计
9.2.0 类图
9.2.1 表及其结构
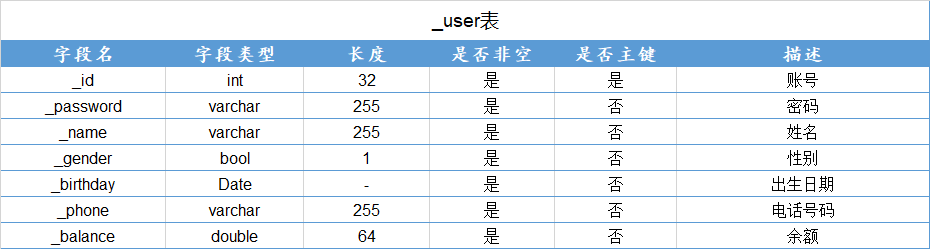
- 用户表
- 优惠卷表

- 活动表
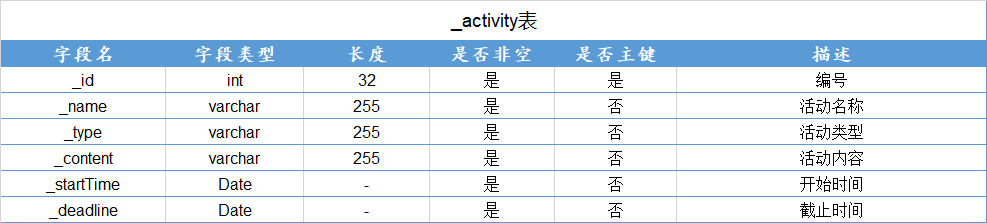
- 单车表

- 行程表

- 轨迹表

- 持有优惠卷表

- 参与活动表

- 骑行表

9.2.2 表间的关联(ER图)
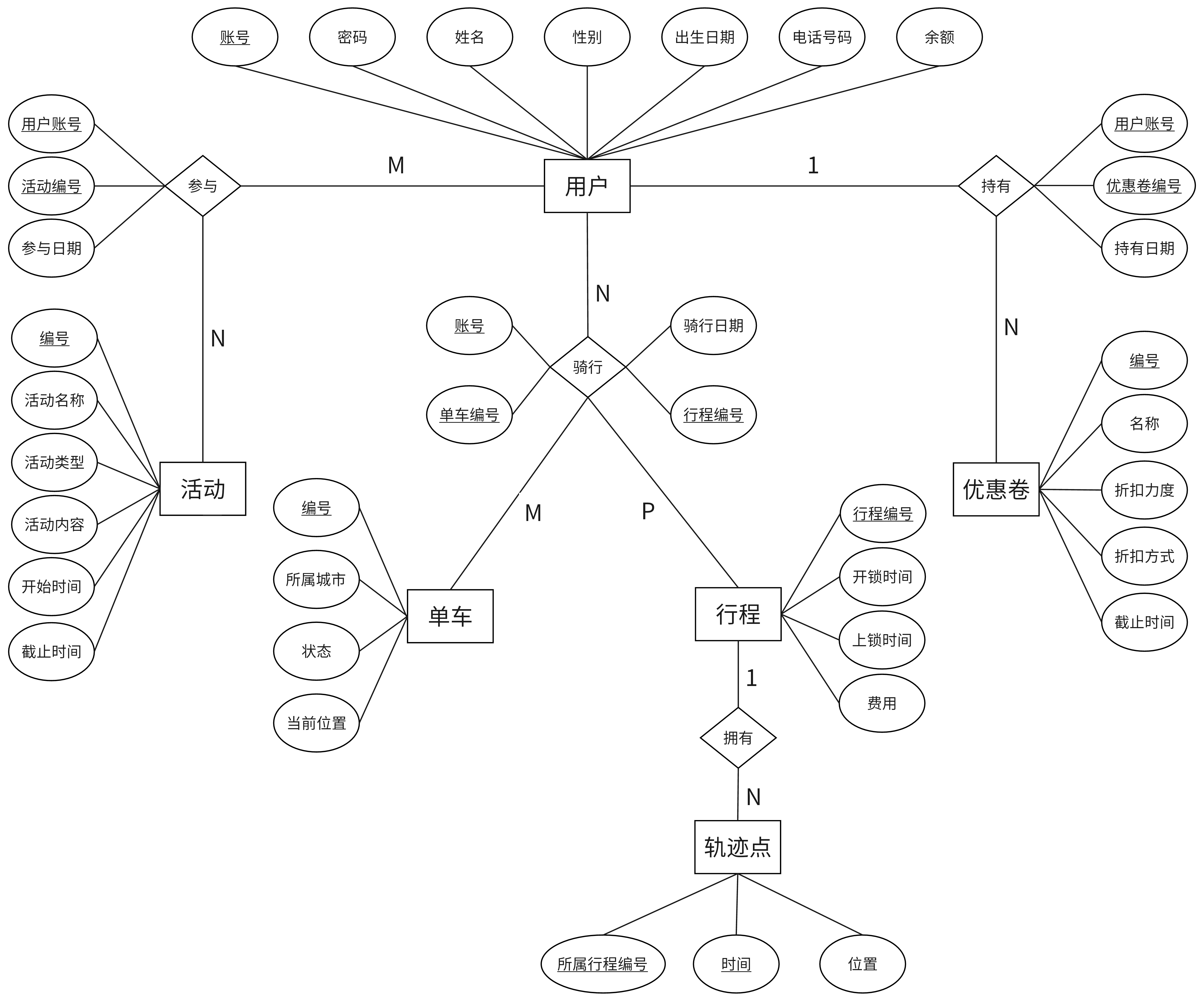
9.2.3 表的分布设计
- 考虑到单车基本不会跨城市骑行,所以单车表按城市进行水平分片;相应的的,骑行表、行程表和用户表也按城市进行水平分片
- 考虑到大部分情况下用户表经常访问账号和余额这两个属性,所以可以将用户表进行垂直分片,分为user1(账号,余额)和user2(账号,密码,姓名,性别,出生日期,电话号码)
9.2.4 <key, value>存储及其与表之间的联系(索引)
9.2.5 关键事务的描述
- 登录
- 注册
- 优惠卷到期自动删除
- 活动结束自动删除
- 充值
- 兑现
- 购买优惠卷
- 开锁
- 骑行
- 上锁
9.2.6 主要的查询流程
- 查询用户信息
- 查询余额
- 查询优惠卷信息
- 查询活动
- 查询单车状态
- 查询单车位置
- 查询行程轨迹
第十章 OceanBase 数据库分布式事务的实现机制
10.1 概述(总结)
我们详细介绍了 OceanBase 数据库的分布式事务实现机制,核心是通过优化的两阶段提交协议(2PC)来确保分布式事务的一致性和可靠性。并解释了分布式事务的基本概念、ACID特性(原子性、一致性、隔离性、持久性)、CAP理论(一致性、可用性、分区容错性)和 BASE理论(基本可用、软状态、最终一致性)。
在传统 2PC 的基础上,OceanBase 进行了延迟优化,通过异步提交协调者日志和提前决策提交点来减少提交延迟,同时每个参与者需持久化参与者列表以便异常恢复。OceanBase数据库的分布式事务实现的关键技术点还包括全局一致性快照技术,通过快照隔离级别和多版本并发控制 (MVCC) 提供一致的版本号,确保跨节点事务操作的一致性;锁机制采用行级锁粒度,多版本两阶段锁和锁的存储在行上,减少内存开销并提高并发处理能力。
通过这些技术和优化,OceanBase 确保了分布式环境下的数据一致性和事务处理的高效性,适应各种复杂的分布式应用场景。
10.2 分布式事务的基本概念
10.2.1 基本概念
分布式事务就是指事务的参与者、支持事务的服务器、资源服务器以及事务管理器分别位于不同的分布式系统的不同节点之上。以上是百度百科的解释,简单的说,就是一次大的操作由不同的小操作组成,这些小的操作分布在不同的服务器上,且属于不同的应用,分布式事务需要保证这些小操作要么全部成功,要么全部失败。本质上来说,分布式事务就是为了保证不同数据库的数据一致性。
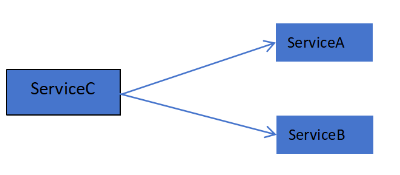
分布式事务主要有两种场景,一种仅仅是服务内操作涉及到对多个数据库资源的访问。当一个服务操作访问不同的数据库资源,又希望对它们的访问具有事务特性时,就需要采用分布式事务来协调所有的事务参与者。如下图:

上面介绍的分布式事务应用场景管一个服务操作会访问多个数据库资源,但是毕竟整个事务还是控制在单一服务的内部。如果一个服务操作需要调用另外一个服务,这时的事务就需要跨越多个服务了。在这种情况下,起始于某个服务的事务在调用另外一个服务的时候,需要以某种机制流转到另外一个服务,从而使被调用的服务访问的资源也自动加入到该事务当中来。下图反映了这样一个跨越多个服务的分布式事务:
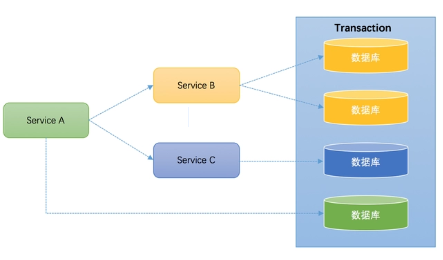
如果将上面这两种场景(一个服务可以调用多个数据库资源,也可以调用其他服务)结合在一起,对此进行延伸,整个分布式事务的参与者将会组成如下图所示的树形拓扑结构。在一个跨服务的分布式事务中,事务的发起者和提交均系同一个,它可以是整个调用的客户端,也可以是客户端最先调用的那个服务。
10.2.2 ACID特性
分布式事务页需具备事务的基本属性:原子性、一致性、隔离性、持久性。这四个属性通常称为ACID特性。
- 原子性(atomicity):个事务是一个不可分割的工作单位,事务中包括的诸操作要么都做,要么都不做。
- 一致性(consistency):事务必须是使数据库从一个一致性状态变到另一个一致性状态,事务的中间状态不能被观察到的。
- 隔离性(isolation):一个事务的执行不能被其他事务干扰。即一个事务内部的操作及使用的数据对并发的其他事务是隔离的,并发执行的各个事务之间不能互相干扰。隔离性又分为四个级别:
- 读未提交(read uncommitted)
- 读已提交(read committed,解决脏读)
- 可重复读(repeatable read,解决虚读)
- 串行化(serializable,解决幻读)
- 持久性(durability):持久性也称永久性(permanence),指一个事务一旦提交,它对数据库中数据的改变就应该是永久性的。接下来的其他操作或故障不应该对其有任何影响。
10.2.3 CAP理论
CAP原则又称CAP定理,指的是在一个分布式系统中,一致性(Consistency)、可用性(Availability)、分区容错性(Partition tolerance)。CAP 原则指的是,这三个要素最多只能同时实现两点,不可能三者兼顾。
- 一致性(C):在分布式系统中的所有数据备份,在同一时刻是否同样的值。(等同于所有节点访问同一份最新的数据副本)
- 可用性(A):保证每个请求不管成功或者失败都有响应。
- 分区容忍性(P):系统中任意信息的丢失或失败不会影响系统的继续运作
CAP原则的精髓就是要么AP,要么CP,要么AC,但是不存在CAP。如果在某个分布式系统中数据无副本, 那么系统必然满足强一致性条件, 因为只有独一数据,不会出现数据不一致的情况,此时C和P两要素具备,但是如果系统发生了网络分区状况或者宕机,必然导致某些数据不可以访问,此时可用性条件就不能被满足,即在此情况下获得了CP系统,但是CAP不可同时满足。
10.2.4 BASE理论
BASE是Basically Available(基本可用)、Soft state(软状态)和Eventually consistent(最终一致性)三个短语的简写,BASE 理论是对 CAP 中的一致性和可用性进行一个权衡的结果,理论的核心思想就是:我们无法做到强一致,但每个应用都可以根据自身的业务特点,采用适当的方式来使系统达到最终一致性。
- 基本可用:分布式系统在出现不可预知故障的时候,允许损失部分可用性—-注意,这绝不等价于系统不可用。
- 软状态:允许系统中的数据存在中间状态,并认为该中间状态的存在不会影响系统的整体可用性,即允许系统在不同节点的数据副本之间进行数据同步的过程存在延时。
- 最终一致性:所有的数据副本,在经过一段时间的同步之后,最终都能够达到一个一致的状态。因此,最终一致性的本质是需要系统保证最终数据能够达到一致,而不需要实时保证系统数据的强一致性。
10.3 OceanBase分布式事务的协议
10.3.1 传统的2PC(Two-Phase Commit)
二阶段提交协议(Two-phase Commit,即 2PC)是常用的分布式事务解决方案,即将事务的提交过程分为准备阶段和提交阶段两个阶段来进行处理。
参与角色
- 协调者:事务的发起者
- 参与者:事务的执行者
第一阶段
- 协调者向所有参与者发送事务内容,询问是否可以提交事务,并等待答复
- 各参与者执行事务操作,将 undo 和 redo 信息记入事务日志中(但不提交事务)
- 如参与者执行成功,给协调者反馈同意,否则反馈中止
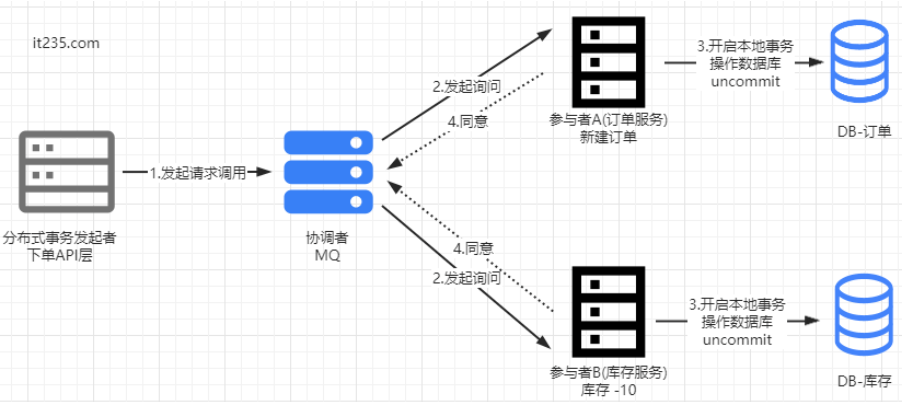
第二阶段
- 当协调者节点从所有参与者节点获得的相应消息都为同意时:
协调者节点向所有参与者节点发出正式提交(commit)的请求。
参与者节点正式完成操作,并释放在整个事务期间内占用的资源。
参与者节点向协调者节点发送ack完成消息。
协调者节点收到所有参与者节点反馈的ack完成消息后,完成事务。 - 如果任一参与者节点在第一阶段返回的响应消息为中止,或者协调者节点在第一阶段的询问超时之前无法获取所有参与者节点的响应消息时:
协调者节点向所有参与者节点发出回滚操作(rollback)的请求。
参与者节点利用阶段1写入的undo信息执行回滚,并释放在整个事务期间内占用的资源。
参与者节点向协调者节点发送ack回滚完成消息。
协调者节点受到所有参与者节点反馈的ack回滚完成消息后,取消事务。
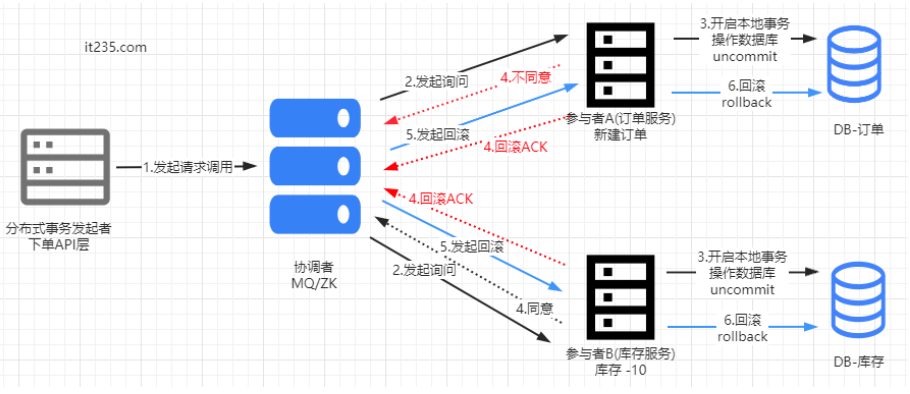
优点:状态简单,只依靠协调者状态即可确认和推进整个事务状态
缺点:协调者写日志,commit延时高
10.3.2 OceanBase的2PC
用户能够感知到的最明显的一点,就是事务提交的延迟。OceanBase从两方面入手优化。一方面,协调者的 Prepare 日志可以异步提交,参与者列表可以由所有参与者携带以解除对其的依赖;另一方面,两阶段提交的提交点完全是可以提前的,一个事务是否提交除了可以由单个协调者来决定,还可以由所有参与者分布式地决定,即提交点可以提前为所有参与者将 Prepare 日志同步成功来决定。
基于上述两个思路,OceanBase进行了下列改进:
- 协调者不写日志,变成了一个无持久化状态的状态机。
- 事务的状态由参与者的持久化状态决定所有参与者都prepare成功即认为事务进入提交状态,立即返回客户端commit
- 每个参与者都需要持久化参与者列表,方便异常恢复时构建协调者状态机,推进事务状态
- 参与者增加clear阶段,标记事务状态机是否终止
OceanBase 还对两阶段提交协议的时延进行了优化,将事务提交回应客户端的时机提前到 Prepare 阶段完成后(标准两阶段提交协议中为 Commit 阶段完成后)。

在上图中(绿色部分表示写日志的动作),左侧为标准两阶段提交协议,用户感知到的提交时延是4次写日志耗时以及2次 RPC 的往返耗时;右侧图中 OceanBase 的两阶段提交实现,由于少了协调者的写日志耗时以及提前了应答客户端的时机,用户感知到的提交时延是1次写日志耗时以及1次 RPC 的往返耗时。
在 OceanBase 两阶段提交中通过协调者不写日志的思路,在原子提交延时上直接省去了两条日志同步的延时,并且在资源回收过程中也省去了 2 次日志同步。不过,我们也增加了一些负担:在资源回收过程中多了 2 次消息传输,以及在资源损耗上多了 2N 条消息传输和 N 条日志同步。
考虑到在分布式数据库场景中,日志同步负担远大于消息传输(一般部署会把 leader 部署在靠近的区域,而副本必须承受多地的容灾),而且延时的效应远大于资源回收和资源消耗,因此,我们认为本次优化确实带了了不少的进步。
10.4 实现机制(其他关键技术)
10.4.1 全局一致性快照技术
源于数据库中的两个传统概念:“快照隔离级别(Snapshot Isolation)”和“多版本并发控制(Multi-VersionConcurrency Control,简称MVCC)”。这两种技术的大致含义是:为数据库中的数据维护多个版本号(即多个快照),当数据被修改的时候,可以利用不同的版本号区分出正在被修改的内容和修改之前的内容,以此实现对同一份数据的多个版本做并发访问,避免了经典实现中“锁”机制引发的读写冲突问题。
因此,这两种技术被很多数据库产品(如Oracle、SQL Server、MySQL、PostgreSQL)所采用,而OceanBase数据库也同样采用了这两种技术以提高并发场景下的执行效率。但和传统的数据库的单点全共享(即Shared-Everything)架构不同,OceanBase是一个原生的分布式架构,采用了多点无共享(即Shared-Nothing)的架构,在实现全局(跨机器)一致的快照隔离级别和多版本并发控制时会面临分布式架构所带来的技术挑战。为了应对这些挑战,OceanBase数据库在2.0版本中引入了“全局一致性快照”技术。
OceanBase数据库是利用一个集中式服务来提供全局一致的版本号。事务在修改数据或者查询数据 的时候,无论请求源自哪台物理机器,都会从这个集中式的服务处获取版本号,OceanBase则保证 所有的版本号单调向前并且和真实世界的时间顺序保持一致。

有了这样全局一致的版本号,OceanBase就能根据版本号对全局(跨机器)范围内的数据做一致性快照,因此我们把这个技术命名为“全局一致性快照”。有了全局一致性快照技术,就能实现全局范围内一致的快照隔离级别和多版本并发控制,而不用担心发生外部一致性被破坏的情况。
10.4.2 锁机制
OceanBase 数据库的锁机制使用了以数据行为级别的锁粒度。同一行不同列之间的修改会导致同一把锁上的互斥;而不同行的修改是不同的两把锁,因此是无关的。OceanBase 数据库的读取是不上锁的,因此可以做到读写不互斥从而提高用户读写事务的并发能力。对于锁的存储模式,选择将锁存储在行上(可能存储在内存与磁盘上)从而避免在内存中维护大量锁的数据结构。其次,会在内存中维护锁之间的等待关系,从而在锁释放的时候唤醒等待在锁上面的其余事务。
- 锁机制的粒度
OceanBase 数据库现在不支持表锁,只支持行锁,且只存在互斥行锁。在更新同一行的不同列时,事务依旧会互相阻塞,如此选择的原因是为了减小锁数据结构在行上的存储开销。而更新不同行时,事务之间不会有任何影响。 - 锁机制的互斥
OceanBase 数据库使用了多版本两阶段锁,事务的修改每次并不是原地修改,而是产生新的版本。因此读取可以通过一致性快照获取旧版本的数据,因而不需要行锁依旧可以维护对应的并发控制能力,因此能做到执行中的读写不互斥,这极大提升了 OceanBase 数据库的并发能力。 - 锁机制的存储
OceanBase 数据库的锁存储在行上,从而减少内存中所需要维护的锁数据结构带来的开销。在内存中,当事务获取到行锁时,会在对应的行上设置对应的事务标记,即行锁持有者。当事务尝试获取行锁时,会通过对应的事务标记发现自己不是行锁持有者而放弃并等待或发现自己是行锁持有者后获得行的使用能力。当事务释放行锁后,就会在所有事务涉及的行上解除对应的事务标记,从而允许之后的事务继续尝试获取。 - 锁机制的释放
OceanBase 数据库的锁在事务结束(提交或回滚)的时候释放的,从而避免数据不一致性的影响。OceanBase 数据库还存在其余的释放时机,即 SAVEPOINT,当用户选择回滚至 SAVEPOINT 后,事务内部会将 SAVEPOINT 及之后所有涉及数据的行锁,全部根据 OceanBase 数据库锁机制的互斥 中介绍的机制进行释放。
10.4.3 MVCC(多版本并发控制)
事务对数据库的任何修改的提交都不会直接覆盖之前的数据,而是产生一个新的版本与老版本共存,使得读取时可以完全不加锁。
MVCC的实现主要包括以下几个关键点:
- 版本管理
每个数据行都会有多个版本,每个版本都有一个时间戳或者序列号来标识其创建时间。当一个事务对数据行进行更新时,实际上是创建了该数据行的一个新版本。
旧版本的数据行在更新后不会立即被删除,而是标记为过期(或称为失效),这样已经开始的读事务仍然可以读取到旧版本的数据行,保证了事务的一致性和隔离性。 - 读操作
读事务可以在不受写事务影响的情况下读取数据行的旧版本,从而实现了读写并发。
读事务只能读取在其开始之前已经提交的事务所写入的数据版本,而不能读取未提交或者已经回滚的事务所写入的数据版本,这样保证了读事务读取到的数据是一致的。 - 写操作
写事务在执行更新操作时,会为被更新的数据行创建一个新版本,并且在新版本的数据行上进行修改。这样可以保证在写事务执行过程中,其他并发的读事务仍然可以读取到该数据行的旧版本,从而实现了读写并发。
写事务在提交之前,会将更新后的新版本数据行的变更信息持久化到磁盘上的日志中,以确保事务的持久性。
10.5 故障恢复
10.5.1 分布式数据库的问题
在分布式数据库中,事务故障恢复的目的仍然是要保证事务的原子性和持久性。和单机数据库的不同在于,在分布式数据库中,数据的修改位于不同的节点。
10.5.2 单机事务故障处理
OceanBase 采用基于 MVCC 的事务并发控制,这意味着事务修改会保留多个数据版本,并且单个数据分片上的存储引擎基于 LSM-tree 结构,会定期进行转储(compaction)操作。
事务的修改会以新版本数据的形式写入到内存中最新的活跃 memtable 上,当 memtable 内存使用达到一定量时,memtable 冻结并生成新的活跃 memtable,被冻结的 memtable 会执行转储转变为磁盘上的 sstable。数据的读取通过读取所有的 sstable 和 memtable 上的多版本进行合并来得到所需要的版本数据。

单机事务故障恢复采用了 Undo/Redo 日志的思路实现。事务在写入时会生成 Redo 日志,借助 MVCC 机制的旧版本数据作为 Undo 信息,实现了 Steal & No-Force 的数据落盘策略。在事务宕机恢复过程中,通过 Redo日志进行重做恢复出已提交未落盘的事务,并通过恢复保存的旧版本数据来回滚已经落盘的未提交事务修改。
10.5.3 分布式事务故障处理
当事务操作多个数据分片时,OceanBase 通过两阶段提交来保证分布式事务的原子性。

如上图所示,当分布式事务提交时,会选择其中的一个数据分片作为协调者在所有数据分片上执行两阶段提交协议。还记得前文提到过的协调者宕机问题么?在 OceanBase 中,由于所有数据分片都是通过 Paxos 复制日志实现多副本高可用的,当主副本发生宕机后,会由同一数据分片的备副本转换为新的主副本继续提供服务,所以可以认为在 OceanBase 中,参与者和协调者都是保证高可用不宕机的(多数派存活),绕开了协调者宕机的问题。
在参与者高可用的实现前提下,OceanBase 对协调者进行了“无状态”的优化。在标准的两阶段提交中,协调者要通过记录日志的方法持久化自己的状态,否则如果协调者和参与者同时宕机,协调者恢复后可能会导致事务提交状态不一致。但是如果我们认为参与者不会宕机,那么协调者并不需要写日志记录自己的状态。

上图是两阶段提交协议协调者的状态机,在协调者不写日志的前提下,协调者如果发生切主或宕机恢复,它并不知道自己之前的状态是 Abort 还是 Commit。那么,协调者可以通过询问参与者来恢复自己的状态,因为参与者是高可用的,所以一定可以恢复出整个分布式事务的状态。
10.6 性能优化
10.6.1 分布式事务类型的优化
对于分布式事务的优化,不同类型的事务提交耗时不同,性能调优应尽量降低跨机分布式事务的比例。事务模型可以从以下几个方面入手:业务整体逻辑,细化到具体的事务和了解多表、单表事务的比例以及各类 SQL 的执行频率。
SQL 的执行计划分为四种:
- Local 表示当前语句所涉及的分区 Leader 与 Session 所在的机器相同;
- Remote表示当前语句所涉及的分区 Leader 与 Session 所在的机器不同;
- Distribute 和 Uncertain 表示不能确定 Leader 和 Session 的关系,可能在同一个机器,也可能跨多机。
对于事务的性能而言,优先使用单机事务,其次才是分布式事务;根据执行计划的类型统计信息,可以大致估算出分布式事务的比例,进而为调优提供数据支持。相关的 SQL 语句如图所示。

其中,plan_type = 1、2、3 分别表示 Local 、Remote 、Distribute 执行计划。一般来讲,0 代表无 plan 的 SQL 语句,比如:set autocommit=0/1,commit 等。
非 Local 计划的请求(0除外),大概率会导致事务跨机,相对于单机事务,性能会有一定的影响。可按照以下几种情况进行检查,Primary Zone 为单 Zone & 单 Unit,Primary Zone 为单 Zone & 多 Unit 和 Primary Zone 为 RANDOM。
- 对于Primary Zone 为单 Zone & 单 Unit 来说,单 Unit 部署的场景如果出现 Remote、Uncertain 计划,是不符合预期的,原因大概有几种:一是直连了该租户的 Follower。可根据执行计划的类型统计信息确认;二是应用连接了 OBProxy,但事务的第一条 SQL 无法被 OBProxy 进行正确的转发,导致 Session 和事务所涉及的分区 Leader 跨机。此时需要去检查本集群所有 OBProxy 的日志,关键日志信息如图;三是部分分区刚刚切主,OBServer 或者 OBPoxy 维护的 Location Cache 尚未刷新到最新。如果是情况 1,需要让应用改成连接 OBProxy;如果是情况 2,说明当前 SQL 较为复杂,OBProxy 在 Parser 过程中无法计算出需要访问的分区,因此随机做了发送。此时需要对 SQL 写法进行调整,带上分区键;如果是情况 3,则不需要处理。
- 对于Primary Zone 为单 Zone & 多 Unit ,该场景下,同 Zone 的 OBServer 会自动进行分区负载均衡,事务跨机大概率是可能的。为了避免跨机事务,结合事务内语句执行情况,进行 Table Group 划分,尽量保证事务单机执行。Table Group 的用法如图所示。
- 最后是Primary Zone 为 RANDOM ,RANDOM 部署,该租户的表 Leader 随机打散,分布式跨机事务同样是大概率的。
10.6.2 分布式事务提交的优化
对于单表或多表的单机事务,OceanBase 数据库 V4.0 版本由于做了单日志流架构的调整,只要事务涉及的日志流 Leader 在同一个机器,默认会走单日志流事务。这种事务模型性能最高,因此不需要任何配置项的调整。而对于跨机事务的处理,主要有两个问题,尽可能利用多机能力和OBServer 流量负载均衡。具体手段有
- 结合事务内语句执行情况,进行 Table Group 划分,尽量保证事务单机执行,也就是前面讲到的Primary Zone 为单 Zone & 多 Unit;
- 对于批量导入的场景,尽可能利用 PDML 并行执行的能力,这是Ocean Base 3.2 及之后的版本才具备的;
- 根据负载情况调整网络线程数量,即net_thread_count,该配置项默认为 0,进程启动之后,根据当前机器 CPU 核数,自适应计算出本机需要的数量,公式为min( 6, cpu_core/8 ),根据实际的情况,手动调整预期值,进程重启生效。