1.去除中断
传统的收发报文方式都必须采用硬中断来做通讯,每次硬中断大约消耗100微秒,这还不算因为终止上下文所带来的Cache Miss。
DPDK采用轮询模式驱动(PMD)。
PMD由用户空间的特定的驱动程序提供的API组成,用于对设备和它们相应的队列进行设置。
特点:去除中断,避免内核态和用户态内存拷贝,减少系统开销,从而提升I/O吞吐能力
2.处理数据包的环境
传统的处理数据包,数据必须从内核态用户态之间切换拷贝带来大量CPU消耗,全局锁竞争。
DPDK处理数据包在用户态进行。
3.收发包的开销
传统收发包都有系统开销。
DPDK采用Ring Queue(环形队列)和HUGEPAGE(大页内存)。
Ring Queue:针对单个或多个数据包生产者、单个数据包消费者的出入队列提供无锁机制,有效减少系统开销。
如果有多个核可能需要同时访问一个网卡,那DPDK中会为每个核准备一个单独的接收队列/发送队列,这样避免了竞争,也避免了cache一致性问题。
HUGEPAGE:利用内存大页HUGEPAGE降低TLB(Translation Lookaside Buffer) miss,利用内存多通道交错访问提高内存访问有效带宽,降低访存开销。
4.多核情况
传统方式,内核工作在多核上,为了可以全局一致,即使采用Lock Free,也避免不了锁总线、内存屏障带来的性能损耗。
DPDK处理多核情况:
①流分类(Flow Classificatio):为N元组匹配和LPM(最长前缀匹配)提供优化的查找算法。
②多队列实现:通过将网卡的某个接收队列分配给某个核,从该队列中收到的所有报文都应当在该指定的核上处理结束,不同的核操作不同的队列。
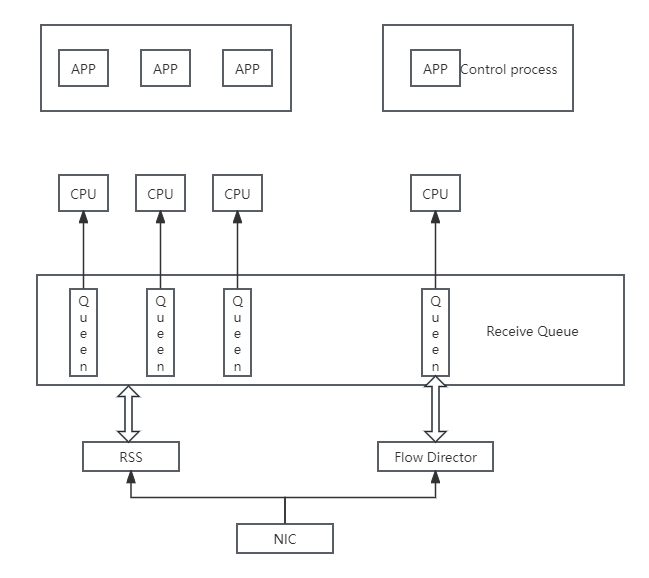
RSS(Receive Side Scaling,接收方扩展)机制:根据关键字,比如根据UDP的四元组srcIP、dstIP、srcPort、dstPort进行哈希。
Flow Director机制:可设定根据数据包某些信息进行精确匹配,分配到指定的队列与CPU核。
Data Buffer:
DPDK将内存封装在Mbuf结构体内,Mbuf主要用来封装网络帧缓存,所有的应用使用Mbuf结构来传输网络帧。
对网络帧封装和处理时,将网络帧元数据和帧本身存放在固定大小的同一段缓存中,网络帧元数据的一部分内容由DPDK的网卡驱动写入。
网络包的分析和处理:
当网络数据包(帧)被网卡接收后,DPDK网卡驱动将其存储在一个高效缓冲区中,并在MBUF缓存中创建MBUF对象与实际网络包相连,对网络包的分析和处理都会基于该MBUF,必要的时候才会访问缓冲区中的实际网络包。
③多线程
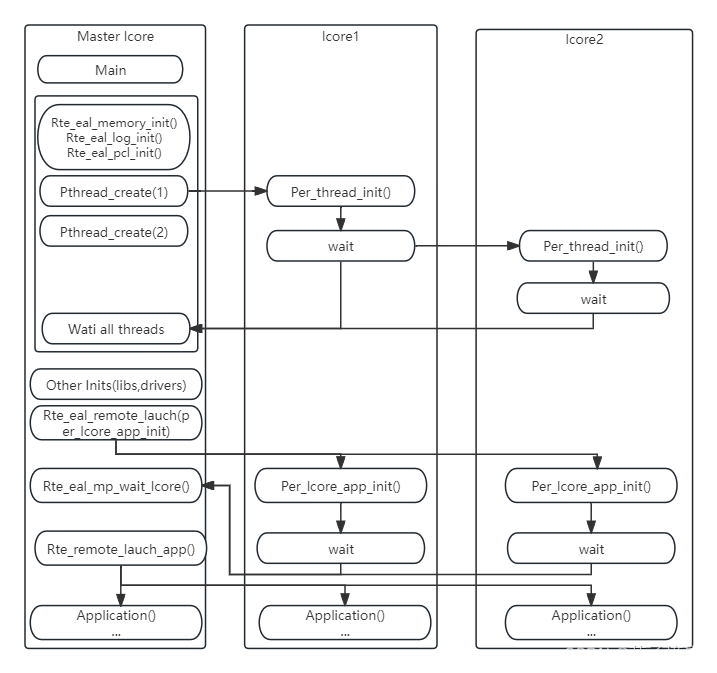
DPDK线程基于pthread接口创建,属于抢占式线程模型,受内核调度支配。通过在多核设备上创建多个线程,每个线程绑定到单独的核上,减少线程调度的开销,以提高性能。控制线程一般绑定到MASTER核上,接受用户配置,并传递配置参数给数据线程等;数据线程分布在不同核上处理数据包。
④数据包转发模型
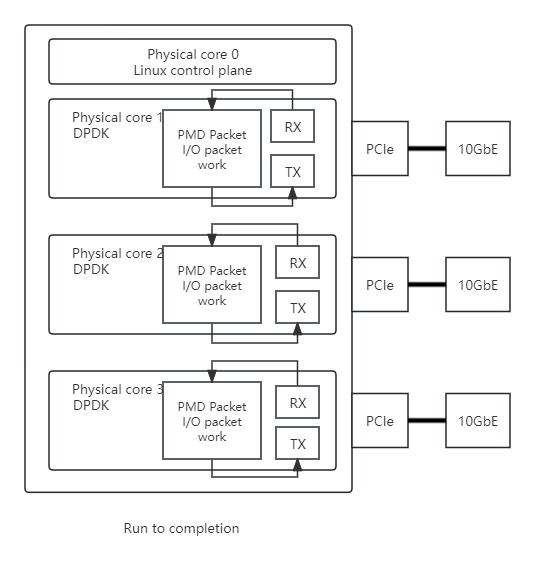
运行至完成(run-to-completion)模型:
特点:同步模型,每个报文的生命周期只能在一个线程中出现,每个物理核都负责处理整个报文的生命周期从RX到TX。
每个指派给DPDK的逻辑核心执行如下所示的循环:
(1) 通过PMD接收用API来提取输出数据包;
(2) 根据转发,一一处理收到的数据包;
(3) 通过PMD发送用API发送输出数据包。
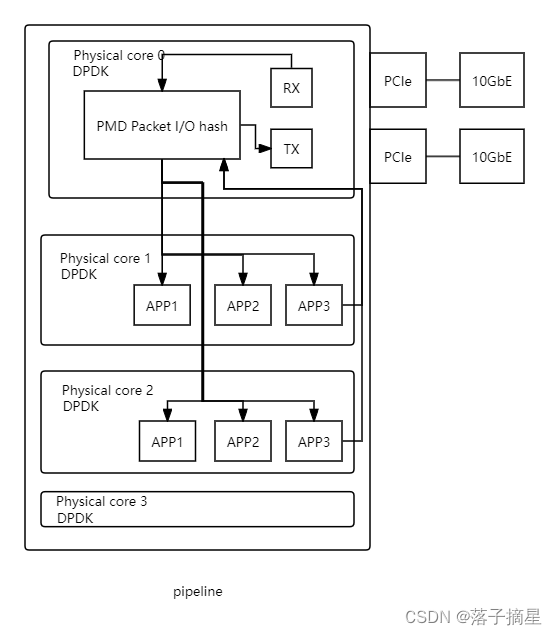
管道(pipeline)模型:
特点:异步模型,有的逻辑核心只执行数据包提取,而有的只执行处理,收到的数据包在这些逻辑核心之间通过环来传递。
提取核心执行循环:
(1) 通过PMD接收用API来提取输出数据包;
(2) 通过队列提供数据包给处理核心.
处理核心执行循环:
(1) 从队列中提取数据包;
(2) 根据重传(如果被转发)处理数据包。