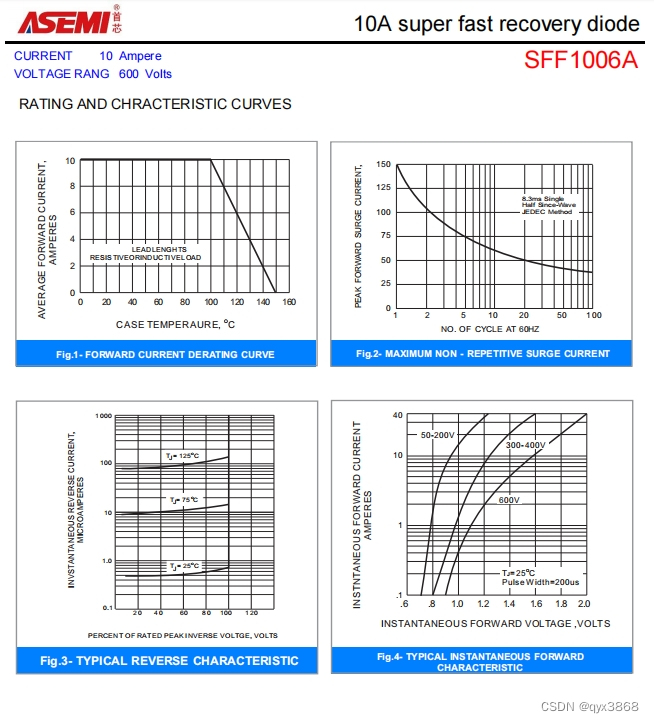
Inception_V2_V3
CNN卷积网络的发展史
1. LetNet5(1998)
2. AlexNet(2012)
3. ZFNet(2013)
4. VGGNet(2014)
5. GoogLeNet(2014)
6. ResNet(2015)
7. DenseNet(2017)
8. EfficientNet(2019)
9. Vision Transformers(2020)
10. 自适应卷积网络(2021)
上面列出了发展到现在CNN的一些经典的网络模型,我将持续不断更新学习上述神经网络的笔记。共勉!
原论文地址Rethinking the Inception Architecture for Computer Vision
目录
文章目录
- Inception_V2_V3
- CNN卷积网络的发展史
- 目录
- 主要知识点
- 1. [通用设计原则:](#2-general-design-principles通用设计原则)
- 2. [分解卷积和非对称分解卷积:](#3-factorizing-convolutions-with-large-filter-size分解大卷积核的卷积)
- 3. [高效下采样](#5-efficient-grid-size-reduction高效下采样)
- 4. [Label Smooth(标签平滑)](#7-model-regularization-via-label-smoothing使用标签平滑进行模型正则化)
- Abstract(摘要)
- 1. 介绍
- 2. General Design Principles(通用设计原则)
- 1. `避免过度降维或收缩特征而导致表示瓶颈特别是在网络浅层`
- 2. `特征越多收敛越快,相互独立的特征越多输入的信息分解的越彻底`
- 3. `3 * 3和5 * 5大卷积核卷积之前可以用1 * 1 卷积核进行降维,信息不会损失`
- 4. `均衡网络的宽度和深度,两者同时提升既能提高性能又能提高计算效率`
- 3 Factorizing Convolutions with Large Filter Size(分解大卷积核的卷积)
- 3.1 Factorization into smaller convolutions(分解成更小的卷积)
- 灵魂二问:
- 3.2 Spatial Factorization into Asymmetric Convolutions(非对称分解卷积)
- 4. Utillity of Auxiliary Classifiers(辅助分类器的作用)
- 5. Efficient Grid Size Reduction(高效下采样)
- `目的: `
- `传统降维方法`
- 7. Model Regularization via Label Smoothing(使用标签平滑进行模型正则化)
- one-hot独热编码:
- 极大似然估计:
- 对数似然估计:
- 交叉熵损失函数:
- Label Smooth:
- 8. Training Methodology(训练方法)
- 10. Experimental Results and Comparisons(实验结果比较)
- 11. Conclusions(总结)
- 时人不识凌云木,直待凌云始道高!
主要知识点
1. 通用设计原则:
- (1) 避免过度降维或收缩特征而导致表示瓶颈
- (2) 特征越多收敛越快,相互独立的特征越多输入的信息分解的越彻底
- (3) 3 * 3和5 * 5 卷积之前可以使用1 * 1卷积进行降维,不会损失太多信息
- (4) 均衡网络的深度和宽度,两者同时提升可以即提高计算效率又提高模型性能
2. 分解卷积和非对称分解卷积:
- 分解卷积:将5 * 5分解为2个 3 * 3卷积核,7 * 7卷积核分解为3个3 * 3卷积核
- 非对称分解卷积:将5 * 5分解为1 * 5卷积核和5 * 1卷积核
3. 高效下采样
为了解决池化后出现模型表示瓶颈的问题,需要扩展特征维度。
4. Label Smooth(标签平滑)
目的: 减少过拟合,提高模型泛化能力!

Abstract(摘要)
卷积神经网络在计算机领域大放异彩,但是在加深加宽网络的同时也要考虑计算效率。
- 引出下文通过
可分离卷积和正则化去提升计算效率



1. 介绍
- 好的分类模型可以迁移应用到其他计算机视觉任务上,共同特点:都需要CNN提取到的高质量视觉特征(visual features)
- GoogLeNet在参数量上取得了很好的优势(AlexNet:6000w, GoogLeNet:500w, VGG16:1.3e)
- 一味的叠加Inception模块会导致参数量过大换来的精度提升,得不偿失。


2. General Design Principles(通用设计原则)
这一章主要是介绍了作者想到的四种设计原则,论文中说道,这几种设计原则虽然没有严格的证明或者实验加持,但你要大致上遵守,如果你背离这几个原则太多,则必然会造成较差的实验结果。
做法:feature map长宽大小随网络的深度慢慢减小
原因:过度的降维或者收缩特征将造成一定程度的信息丢失(信息相关性丢失)
为何特别是网络的浅层?
因为在网络的浅层丢失的原图信息还不是很多,仍然保留信息的稀疏性。如果在浅层就进行过度地压缩和降维,会对后面提取特征等工作是有负面影响的。
赫布原理:fire together,wire together
人脸特征分解成人脸、人左眼、人右眼、鼻子、嘴巴、眉毛等等独立特征会比单纯的一张大脸特征收敛的快。(赫布原理)
原因: 我们知道feature map上每一个像素的感受野是仅隔一个步长的是具有相关性的,而1 * 1卷积将这些跨通道的信息进行交融、汇总、降维、嵌入,它们任然能保持相关性的。
深度: 网络层数。
宽度: 网络每层卷积核个数。

3 Factorizing Convolutions with Large Filter Size(分解大卷积核的卷积)
GoogLeNet成功的原因就是大量使用了1 * 1卷积进行降维。1 ×1 卷积核可以看作一个特殊的大卷积核分解过程,它损失少,大大降低计算量,增加非线性,跨通道交流。
原因:相邻感受野的卷积结果是高度相关的,在传入大卷积核聚合感受野之前可以先进行降维。


3.1 Factorization into smaller convolutions(分解成更小的卷积)
我们可以将5 * 5卷积核分解为2个3 * 3卷积核,7 * 7卷积核分解为3个3 * 3卷积核。这样可以有效的减少计算量。
原因:相邻感受野的权值共享。


灵魂二问:
- 分解卷积是否会影响模型表达能力?
直观的看是可行的,从结果看也是可行的。但是要问严谨的数学原理,确实难以解释。
- 是否需保留第一层的非线性激活函数?
对于分解后的激活函数,作者通过实验证明,保留对于原图的第一次3 ×3卷积的激活函数有较好效果(一层卷积变成两层了,增加了非线性变换,增强模型非线性表达能力),用BN后效果更好。


3.2 Spatial Factorization into Asymmetric Convolutions(非对称分解卷积)
将3 * 3卷积分解为1 * 3和3 * 1两个不对称卷积(空间可分离卷积)



结果
在输入和输出等同的情况下,参数降低33%(将3x3卷积核分解为两个2x2卷积核,只是降低了11%)
结论
- 不对称卷积分解 (n ×n 分解成了 n×1 和1 ×n) ,n 越大节省的运算量越大。
- 不对称卷积分解在靠前的层效果不好feature map尺寸在12-20之间

可以理解成上图中左边这个是在深度上分解,而右边这个扩展滤波器组(增大特征个数)是在宽度上分解。 应用在最后的输出分类层之前,用该模块扩展特征维度生成高维稀疏特征(增加特征个数,符合原则二)。


4. Utillity of Auxiliary Classifiers(辅助分类器的作用)
在GoogLeNet里面用了两个辅助分类器(4a和4b两个模块后面),但是事后实验证明,辅助分类器并未在训练初期改善收敛性,第一个没什么用,在v2,v3里面去掉了
提问:
- 为什么在训练快结束时带有辅助分类器的模型精度更高?
因为辅助分类器也起到了正则化的作用。

这里解释一下:步长为2就已经达到了下采样的目的

5. Efficient Grid Size Reduction(高效下采样)
目的:
传统上,卷积网络使用一些池化操作来缩减特征图的网格大小。为了避免表示瓶颈,在应用最大池化或平均池化之前,需要扩展网络滤波器的激活维度。
传统降维方法
-
方法一:先对feature map进行池化,再卷积会导致表征瓶颈,丢失很顶信息(先池化 -> 再卷积)
-
方法二:信息保留了但是计算量过大(先卷积 -> 再池化)

这里我们进行:
并行执行(卷积C+池化P),再进行feature map的堆叠。

可以在不丢失信息的情况下减少参数量!

作者将上述信息进行汇总提出了Inception_V2架构。

如上图所示:
相比于Inception_V1的区别,Inception_V2将:
- 5 * 5卷积分解为两个3 * 3卷积(figure 5)
- 第二部分分解为不对称卷积(figure 6)
- 使用滤波器组(增大特征个数figure 7)
结果:
计算量是GoogLeNet的2.5倍但仍比VGGNet高效!

7. Model Regularization via Label Smoothing(使用标签平滑进行模型正则化)
独热编码即 One-Hot 编码,又称一位有效编码,其方法是使用N位状态寄存器来对N个状态进行编码,每个状态都由他独立的寄存器位,并且在任意时候,其中只有一位有效。(简单地说,就是对于多分类向量,计算机中往往用[0, 1, 3]等此类离散的、随机的而非有序(连续)的向量表示,而one-hot vector 对应的向量便可表示为[0, 1, 0],即对于长度为n 的数组,只有一个元素是1,其余都为0。因此表征我们已知样本属于某一类别的概率是为1的确定事件,属于其他类别的概率则均为0。
弊端:
- 模型泛化能力变差
- 过拟合(正确类别对应的分数logit会一味增大直达正无穷)
极大似然估计(Maximum Likelihood Estimation,MLE)是一种统计方法,用于估计模型参数。它通过寻找使得数据出现概率最大的模型参数来估计真实参数。
对数似然估计(Log-Likelihood)是统计学中一种常用的方法,用于评估模型与数据的拟合程度。对数似然估计通过对
似然函数取对数来简化计算,并衡量模型对数据的拟合程度。
最小化交叉熵损失函数等效于最大化正确类别的对数似然函数


标签平滑的实质就是促使神经网络中进行softmax激活函数激活之后的分类概率结果向正确分类靠近,即正确的分类概率输出大(对应的one-hot标签为1位置的softmax概率大),并且同样尽可能的远离错误分类(对应的one-hot标签为0位置的softmax概率小),即错误的分类概率输出小。
采用Label Smooth可以使网络精度提高0.2%

8. Training Methodology(训练方法)
最优模型的优化方法:RMSProp + learning rate decay(0.9) , 同时使用了阈值为2的梯度截断使得训练更加稳定。

目标检测难点:
图像中低分辨率的目标难以检测,如何处理低分辨率输入?如何保证计算量不变的情况下增加感受野从而增加对低分辨率目标的检测。
实验如下图所示:

结论:实验表明虽然感受野增大,但是在保持计算量不变的情况下模型性能相差不大
10. Experimental Results and Comparisons(实验结果比较)

对Inception_V2进行改进:
- InceptionV2 加入RMSProp(一种计算梯度的方法)
- 在上面的基础上加入Label Smoothing(LSR,标签平滑正则化)
- 在上面的基础上再加入7×7的卷积核分解(分解成3×3)
- 在上面的基础上再加入含有BN的辅助分类器
所以本文最终提出的InceptionV3=inceptionV2+RMSProp优化+LSR+BN-auxilary

进一步进行模型集成加多裁剪

通过上图可以看到InceptionV3在分类上取得了很好的效果!

11. Conclusions(总结)
我们提供了几个设计原则来扩展卷积网络,并在Inception体系结构的背景下进行研究。这个指导可以导致高性能的视觉网络,与更简单、更单一的体系结构相比,它具有相对适中的计算成本。Inception-v3的最高质量版本在ILSVR 2012分类上的单裁剪图像评估中达到了21.2%的top-1错误率和5.6%的top-5错误率,达到了新的水平。与Ioffe等[7]中描述的网络相比,这是通过增加相对适中(2.5/times)的计算成本来实现的。尽管如此,我们的解决方案所使用的计算量比基于更密集网络公布的最佳结果要少得多:我们的模型比He等[6]的结果更好——将top-5(top-1)的错误率相对分别减少了25%(14%),然而在计算代价上便宜了六倍,并且使用了至少减少了五倍的参数(估计值)。我们的四个Inception-v3模型的组合效果达到了3.5%,多裁剪图像评估达到了3.5%的top-5的错误率,这相当于比最佳发布的结果减少了25%以上,几乎是ILSVRC 2014的冠军GoogLeNet组合错误率的一半。
我们还表明,可以通过感受野分辨率为79×79的感受野取得高质量的结果。这可能证明在检测相对较小物体的系统中是有用的。我们已经研究了在神经网络中如何分解卷积和积极降维可以导致计算成本相对较低的网络,同时保持高质量。较低的参数数量、额外的正则化、标准化的辅助分类器和标签平滑的组合允许在相对适中大小的训练集上训练高质量的网络
参考文章路人贾’ω’
参考视频【精读AI论文】Inception V3深度学习图像分类算法