欢迎来到 Papicatch的博客

文章目录
🍉TensorFlow高阶API使用
🍈示例1:使用tf.keras构建模型
🍍通过“序贯式”方法构建模型
🍍通过“函数式”方法构建模型
🍈示例2:编译模型关键代码
🍈示例3:训练模型关键代码
🍉高阶API标准化搭建实例:鸢尾花特征分类实验
🍈实验目标
🍈数据准备
🍈构建模型
🍈训练模型
🍈评估模型
🍉PyTorch的安装
🍈引言
🍈安装PyTorch
🍍使用conda安装
🍇安装Anaconda或Miniconda
🍇创建虚拟环境
🍇选择安装命令:
🍍使用pip安装
🍇确保已安装Python和pip
🍇选择安装命令
🍇执行安装命令
🍍通过源码安装
🍇安装依赖
🍇克隆PyTorch源码
🍇配置编译环境
🍈验证
上篇文章为TensorFlow的安装及中低API操作哦,感兴趣的同学可以看一下哦!!!
TensorFlow的安装与使用
🍉TensorFlow高阶API使用
🍈示例1:使用tf.keras构建模型
🍍通过“序贯式”方法构建模型
import tensorflow as tf
from tensorflow.keras import layers# 构建序贯式模型
model = tf.keras.Sequential([layers.Dense(64, activation='relu', input_shape=(4,)), # 输入层:4个输入节点layers.Dense(64, activation='relu'), # 隐藏层:64个节点layers.Dense(3, activation='softmax') # 输出层:3个输出节点(类别)
])model.summary()

🍍通过“函数式”方法构建模型
import tensorflow as tf
from tensorflow.keras import layers, Model# 输入层
inputs = layers.Input(shape=(4,))
# 隐藏层
x = layers.Dense(64, activation='relu')(inputs)
x = layers.Dense(64, activation='relu')(x)
# 输出层
outputs = layers.Dense(3, activation='softmax')(x)# 构建模型
model = Model(inputs=inputs, outputs=outputs)model.summary()

🍈示例2:编译模型关键代码
在编译模型时,我们需要指定优化器、损失函数和评估指标。
model.compile(optimizer='adam', # 优化器loss='sparse_categorical_crossentropy', # 损失函数metrics=['accuracy'] # 评估指标
)
🍈示例3:训练模型关键代码
在训练模型时,我们使用fit方法。
# 加载鸢尾花数据集
from sklearn.datasets import load_iris
iris = load_iris()
data = iris.data
labels = iris.target# 分割训练集和测试集
from sklearn.model_selection import train_test_split
train_data, test_data, train_labels, test_labels = train_test_split(data, labels, test_size=0.2, random_state=42)# 训练模型
model.fit(train_data, train_labels, epochs=50, batch_size=16, validation_split=0.2)

🍉高阶API标准化搭建实例:鸢尾花特征分类实验

🍈实验目标
使用三层的人工神经网络对鸢尾花数据集进行分类。
🍈数据准备
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
import tensorflow as tf# 加载数据集
iris = load_iris()
data = iris.data
labels = iris.target# 分割训练集和测试集
train_data, test_data, train_labels, test_labels = train_test_split(data, labels, test_size=0.2, random_state=42)
🍈构建模型
使用“序贯式”方法构建三层人工神经网络。
from tensorflow.keras import layers# 构建模型
model = tf.keras.Sequential([layers.Dense(64, activation='relu', input_shape=(4,)),layers.Dense(64, activation='relu'),layers.Dense(3, activation='softmax')
])# 编译模型
model.compile(optimizer='adam',loss='sparse_categorical_crossentropy',metrics=['accuracy']
)model.summary()
🍈训练模型
# 训练模型
model.fit(train_data, train_labels, epochs=50, batch_size=16, validation_split=0.2)
🍈评估模型
# 评估模型
test_loss, test_acc = model.evaluate(test_data, test_labels)
print(f"Test Accuracy: {test_acc}")

以上是一个完整的使用TensorFlow高阶API构建、编译和训练神经网络模型的实例,通过对鸢尾花数据集的特征进行分类展示了这些步骤的具体实现。
🍉PyTorch的安装
🍈引言
TensorFlow之后用于深度学习的主要框架是PyTorch。PyTorch框架是Facebook开发的,Twitter和Salesforce等公司都使用PyTorch框架。与TensorFlow不同,PyTorch使用动态更新的图形进行操作,意味着它可以在流程中更改体系结构。在PyTorch中,可以使用标准调试器,如pdb或PyCharm。
PyTorch训练神经网络的过程简单明了,同时,PyTorch支持数据并行和分布式学习模型,还包含很多预先训练的模型。
🍈安装PyTorch
PyTorch可以作为PyTorch包使用,用户可以使用pip或者conda来构建,或者从源码构建等。
🍍使用conda安装
🍇安装Anaconda或Miniconda
如果没有安装,可以从 Anaconda官网 或 Miniconda官网 下载并安装。
🍇创建虚拟环境
为了避免依赖冲突,建议在虚拟环境中安装PyTorch
conda create -n pytorch_env python=3.9
conda activate pytorch_env
🍇选择安装命令:
根据 PyTorch官网 提供的配置选择适合的命令。例如:
- 安装CPU版本
conda install pytorch torchvision torchaudio cpuonly -c pytorch
- 安装带CUDA支持的版本(例如CUDA 11.7)
conda install pytorch torchvision torchaudio cudatoolkit=11.7 -c pytorch -c nvidia
🍇执行安装命令
在终端或命令提示符中输入上述命令进行安装。
PyTorch官网地址为:Start Locally | PyTorch 。
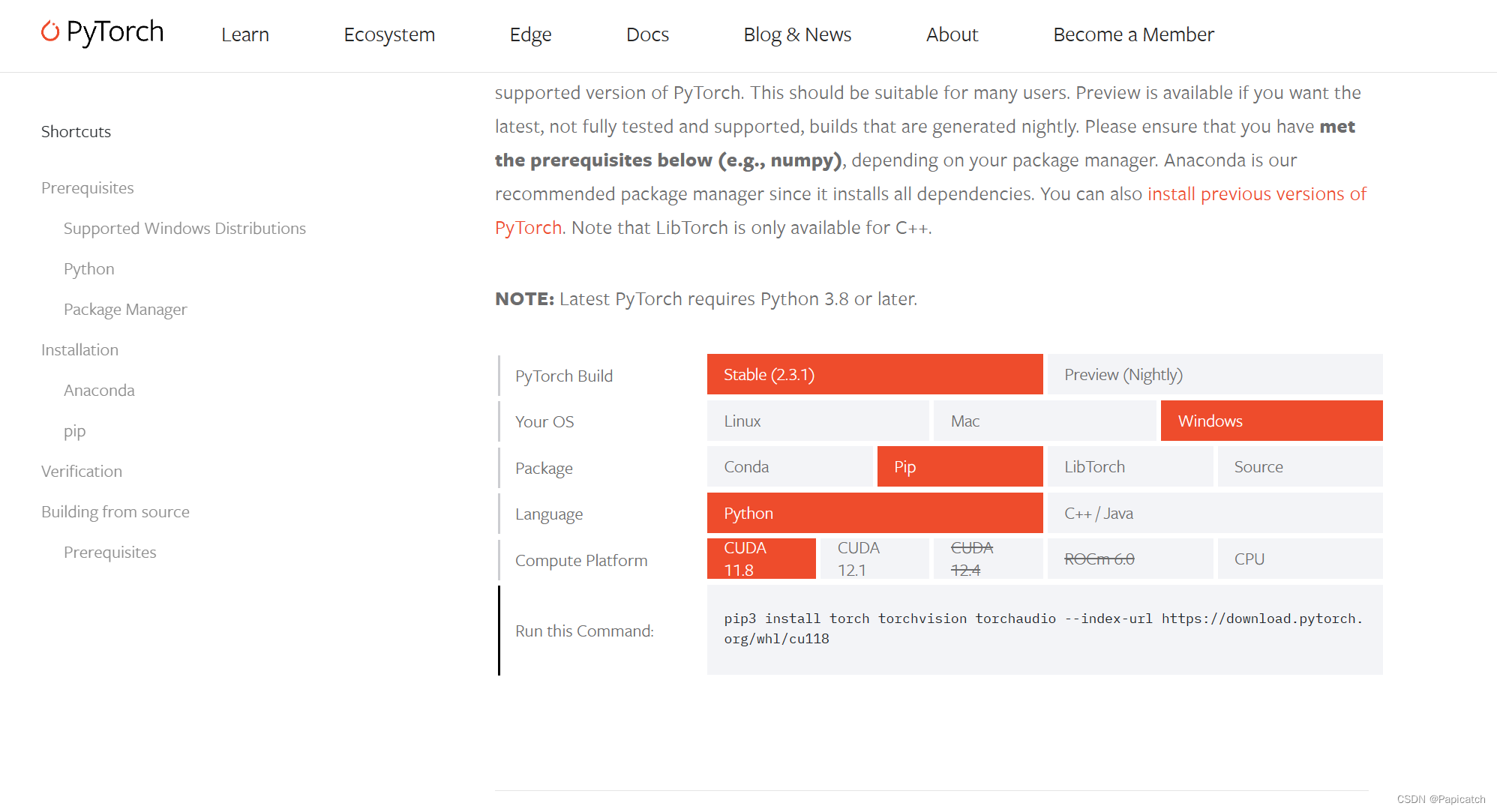
🍍使用pip安装
pip是Python的包管理工具。以下步骤适用于Windows、macOS和Linux。
🍇确保已安装Python和pip
确认已安装Python和pip。可以通过以下命令检查
python --version
pip --version


上图为我电脑安装的Python版本及pip版本。
🍇选择安装命令
根据官方PyTorch网站的推荐,选择适合自己系统和需求的命令。可以访问 PyTorch官网 选择具体配置。
以下是一些常见的命令:
- 安装CPU版本
pip install torch torchvision torchaudio
- 安装带CUDA支持的版本(例如CUDA 11.7)
pip install torch torchvision torchaudio --extra-index-url https://download.pytorch.org/whl/cu117
🍇执行安装命令
打开终端或命令提示符,输入上述命令进行安装。
🍍通过源码安装
有时需要从源码编译安装PyTorch,适用于自定义需求或开发者。
🍇安装依赖
在安装PyTorch源码之前,需要安装一些必要的依赖项。以Ubuntu为例:
sudo apt-get update
sudo apt-get install cmake git libopenblas-dev liblapack-dev libjpeg-dev libpng-dev
🍇克隆PyTorch源码
git clone --recursive https://github.com/pytorch/pytorch
cd pytorch
🍇配置编译环境
设置Python环境,并确保安装了所需的Python包(如numpy和pillow)。
conda create -n pytorch_from_source python=3.9
conda activate pytorch_from_source
pip install numpy pyyaml mkl mkl-include setuptools cmake cffi typing_extensions future six requests dataclasses
🍇编译和安装PyTorch
python setup.py install
🍈验证
以上是几种安装PyTorch的方法,根据您的具体需求和系统环境选择合适的方法进行安装。安装完成后,可以通过以下代码测试安装是否成功:
import torch
print(torch.__version__)
print(torch.cuda.is_available()) # 如果安装了CUDA支持的版本,检查CUDA是否可用