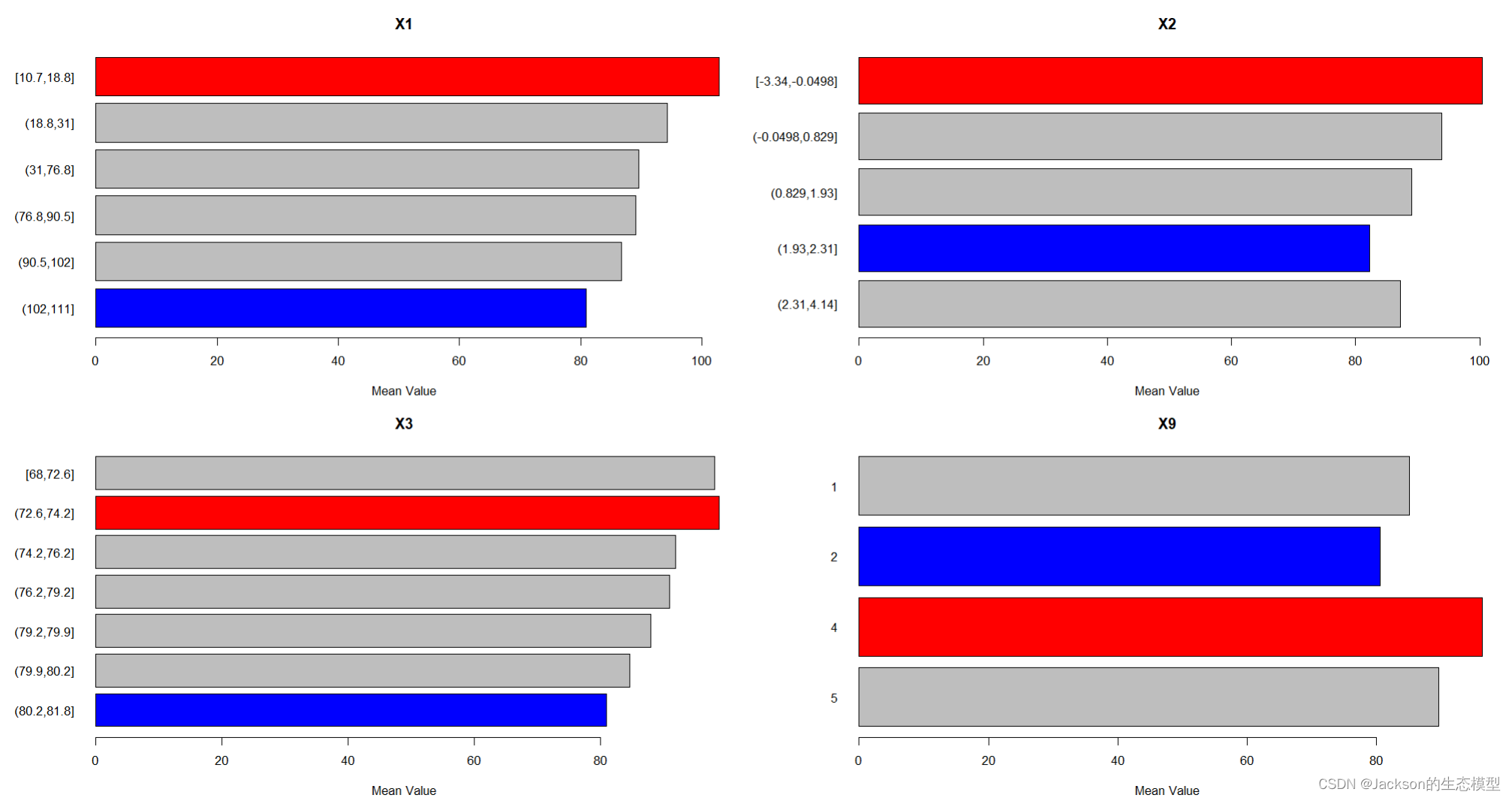
我们知道,当系统面对大流量、高并发的访问请求时,就可能会出现一系列性能问题,导致服务丧失了即时的响应性。如何时刻确保系统具有应对请求压力的能力,是架构设计的核心问题之一。
经典的服务隔离、限流、降级以及熔断等机制能够在一定程度上确保系统的响应性。但今天我们要介绍的是构建系统响应性的一种崭新的解决方案,这就是响应式编程(Reactive Programming)。响应式编程打破了传统的同步阻塞式(Blocking)请求响应过程,采用了异步非阻塞式(Non-Blocking)的编程模型,从而提高服务的响应能力。
这里提到了同步阻塞和异步非阻塞这两个核心概念,而正确理解这两个概念是掌握响应式编程的前提条件。接下来,我们首先对这两个概念做必要的展开,来引出响应式编程技术的诞生背景和解决的问题。
为什么需要响应式编程?
如果你使用Spring框架开发过Web应用程序,那么你一定对下面这种开发方式非常熟悉。
public Order getRemoteOrder(String orderNumber) {
RestTemplate restTemplate = new RestTemplate();
ResponseEntity<Order> result= restTemplate.exchange(
"http://orderservice/orders/{orderNumber}", HttpMethod.GET, null, Order.class, orderNumber);
Order order= result.getBody();
processOrder(order);
return order;
}
这是一个查询订单(Order)信息的应用场景,我们使用了Spring中的RestTemplate模板工具类,通过该类所提供的exchange()方法对远程Web服务所暴露的HTTP端点发起了请求。上述实现方式在日常开发过程中非常具有代表性,基于Spring Cloud开发的微服务系统本质上也是通过这种方式完成服务与服务之间的远程调用。但是,上述实现方法实际上存在明显的缺陷,即处理过程是阻塞式的。正是因为同步阻塞的存在才导致了响应式编程技术的诞生和发展。那么,究竟什么是阻塞式呢?让我们首先来对上述代码中的线程模型做进一步分析,看看问题出在哪里。
为了更好的分析整个调用过程,我们假设服务的提供者为服务A,而服务的消费者为服务B,那么这两个服务的交互过程应该这样的。
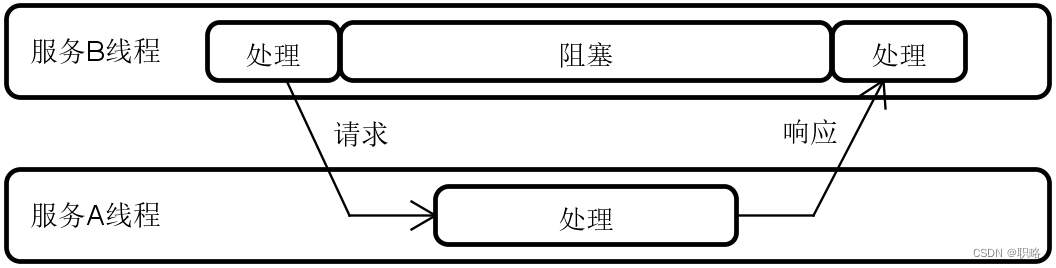
可以看到,当服务B向服务A发送HTTP请求时,线程B只有在发起请求和响应结果的一小部分时间内在有效使用CPU,而更多的时间则只是在阻塞式地等待来自服务A中线程的处理结果。显然,整个过程的CPU利用效率是很低的,很多时间被浪费在了I/O阻塞上,无法执行其他的处理过程。
更进一步,我们继续分析服务A中的处理过程。如果我们采用典型的三层架构,那么沿着Web服务层->业务逻辑层->数据访问层整个调用链路中,每一步的操作过程都存在着前面描述的线程等待问题。也就是说,整个技术栈中的每一个环节都可能是同步阻塞的。
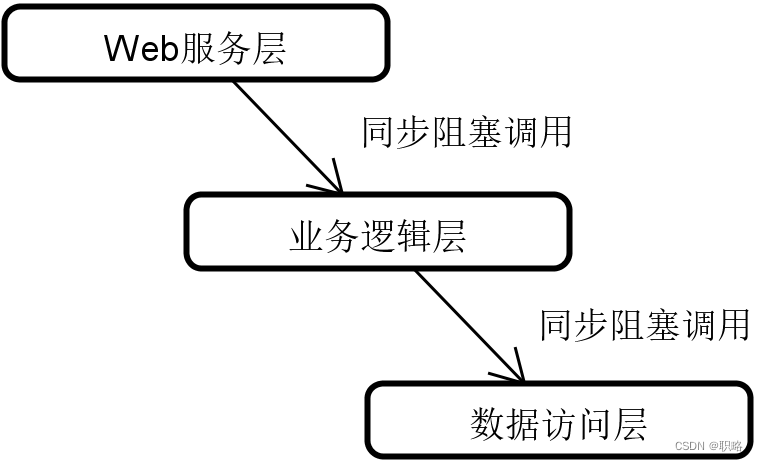
为了解决同步阻塞问题,可以引入异步非阻塞的相关技术。在Java世界中,一般会采用回调(Callback)和Future这两种机制,但这两种机制都存在一定局限性。回调的核心问题在于处理过程会形成一种嵌套结构,给代码的开发和调试带来很大的挑战。而Future机制本质上是一种多线程技术,大量线程之间的相互协作需要频繁进行上下文切换,同样会导致资源利用效率低下。
通过引入响应式编程技术,我们就可以很好的解决这种类型的问题。响应式编程采用全新的响应式数据流(Stream)来实现异步非阻塞式的网络通信和数据访问机制,能够减低不必要的资源等待时间。那么,所谓的响应式编程到底是什么样子的呢?接下来让我们一起来看一下。
什么是响应式编程?
响应式编程技术的核心是数据流,而数据流又是构建在传统的事件驱动架构与发布订阅模式之上。所以,在引入响应式编程技术之前,我们先来回顾一下发布订阅模式和事件处理相关的技术体系。
发布订阅模式和事件
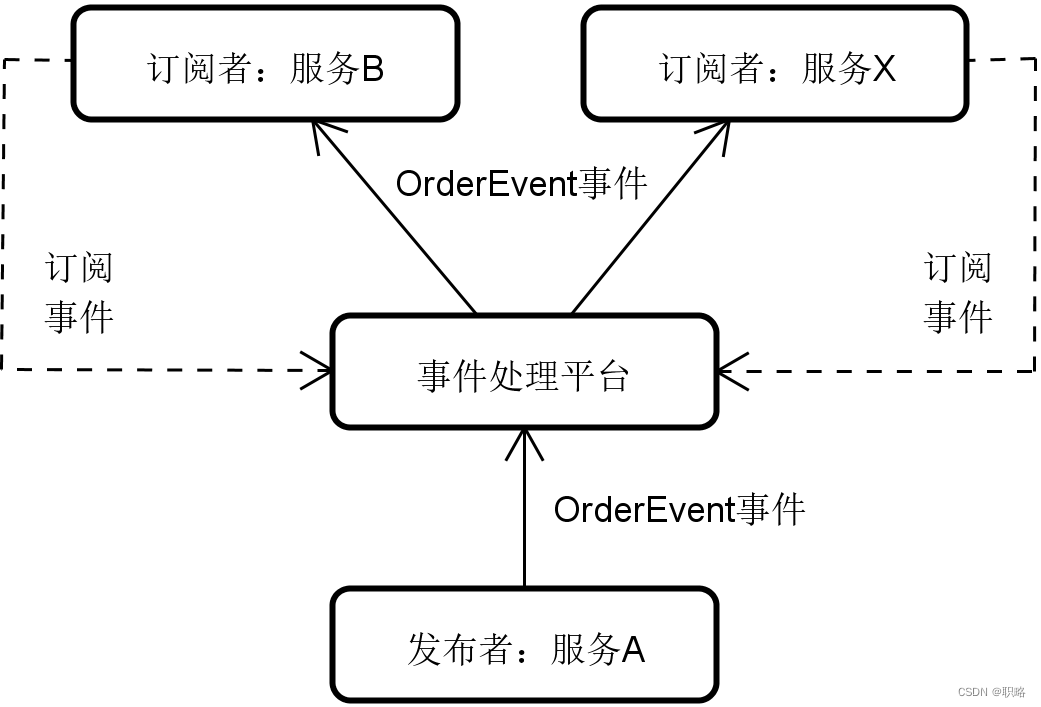
相信大家对设计模式中经典的观察者模式应该都不陌生。观察者模式拥有一个主题(Subject),以及针对这个主题的一个依赖者列表,这些依赖者被称为观察者(Observer)。而发布订阅(Publish-Subscribe)模式可以认为是对观察者模式的一种改进。在这种模式中,发布者和订阅者相互之间可以没有直接的依赖关系,而是通过发送事件到事件处理平台的方式来完成整合。针对今天开篇中提到的订单查询操作,我们可以基于发布订阅模式进行流程重构。
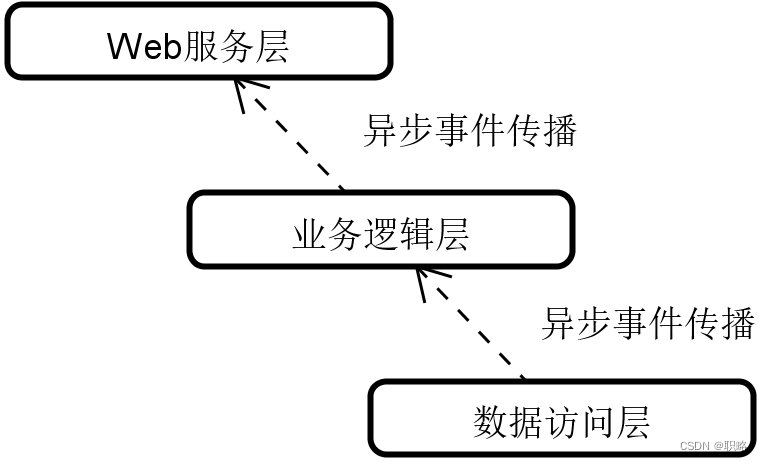
同样,让我们来到单个服务的内部。在三层架构中,从Web服务层到数据访问层再到数据库的整个调用链路同样可以采用发布订阅模式进行重构。这时候,数据库中的数据一有变化就会通知到上游组件,而不是上游组件通过主动拉取数据的方式来获取数据。
数据流和响应式
显然,上图中异步事件传播的思想可以扩展到整个系统。我们可以想象系统中会存在着很多类似OderEvent这样的事件。每一种事件会基于用户的操作或者系统自身的行为而被触发,并形成了一个事件的集合。我们可以把这个事件的集合看成是一串串连起来的数据流,而系统的响应能力就体现在对这些数据流的即时响应过程上。
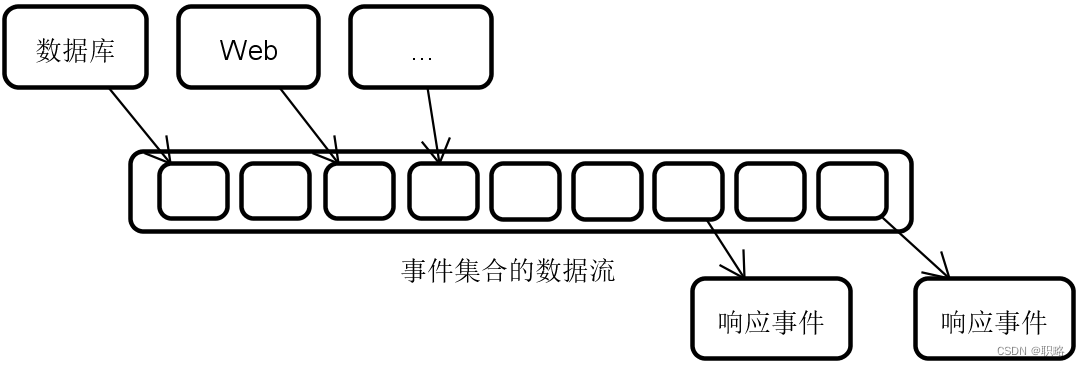
对于技术实现过程而言,数据流是一个全流程的概念。也就是说,无论是从底层数据库,到服务层,最后到Web服务层,抑或是在这个流程中所包含的任意中间层组件,整个数据传递链路都应该是采用事件驱动的方式来进行运作。这样,我们就可以不采用传统的同步调用方式来处理数据,而是由处于全流程中的各层组件自行来执行事件。这就是响应式编程的核心特点。
相较传统开发所普遍采用的“拉”模式,在响应式编程下,基于事件的触发和订阅机制,这就形成了一种类似“推”的工作方式。
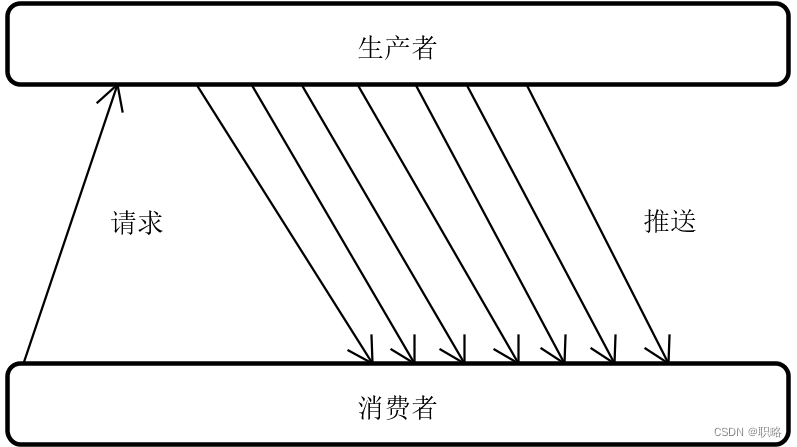
这种工作方式的优势就在于,生成事件和消费事件的过程是异步执行的,所以线程的生命周期都很短,也就意味着资源之间的竞争关系较少,服务器的响应能力也就越高。这就是响应式编程的精髓,也是解决系统性能问题的关键所在。
讲到这里,你可以会问,我们如何来使用响应式编程技术来开发业务系统呢?不用担心,到目前为止,业界已经诞生了诸如RxJava、Project Reactor、Akka等一大批优秀的响应式编程框架。而在Spring 5中,也引入了WebFlux、Reactive Spring Data等新一代的编程组件来实现响应式Web服务和响应式数据访问。通过这种框架和工具,可以很好的解决传统同步阻塞式处理方式所存在的性能问题。
今天的内容系统分析了传统服务调用存在的问题,从而引出响应式编程概念和实现方法。从技术演进的过程和趋势而言,响应式编程的出现有其必然性。另一方面,响应式编程也不是一种完全颠覆式的技术体系,而是在现有的异步调用、观察者模式、发布订阅模式等的基础上发展起来的一种全新的编程模式,能够会系统带来即时响应性。