这里我们划分订单、库存与支付三个module来实践Seata的分布式事务。
依赖版本(jdk17):
<spring.boot.version>3.1.7</spring.boot.version>
<spring.cloud.version>2022.0.4</spring.cloud.version>
<spring.cloud.alibaba.version>2022.0.0.0-RC2</spring.cloud.alibaba.version>
<dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-parent</artifactId><version>${spring.boot.version}</version><type>pom</type><scope>import</scope>
</dependency><dependency><groupId>org.springframework.cloud</groupId><artifactId>spring-cloud-dependencies</artifactId><version>${spring.cloud.version}</version><type>pom</type><scope>import</scope>
</dependency>
<!--springcloud alibaba 2022.0.0.0-RC2-->
<dependency><groupId>com.alibaba.cloud</groupId><artifactId>spring-cloud-alibaba-dependencies</artifactId><version>${spring.cloud.alibaba.version}</version><type>pom</type><scope>import</scope>
</dependency>
【1】构建基础module
这里我们构建order、account和storage三个module,也就是演示订单的流程:创建订单、扣减库存、扣减账户余额。
Seata分TC、TM和RM三个角色,TC(Server端)为单独服务端部署,TM和RM(Client端)由业务系统集成。
整体module如下,module之间使用openfign进行调用。以订单模块为例进行说明,其他两个相似。
seata-account-service2003
seata-order-service2001
seata-storage-service2002
① pom依赖
<!-- nacos -->
<dependency><groupId>com.alibaba.cloud</groupId><artifactId>spring-cloud-starter-alibaba-nacos-discovery</artifactId>
</dependency>
<!--alibaba-seata-->
<dependency><groupId>com.alibaba.cloud</groupId><artifactId>spring-cloud-starter-alibaba-seata</artifactId>
</dependency>
<!--openfeign-->
<dependency><groupId>org.springframework.cloud</groupId><artifactId>spring-cloud-starter-openfeign</artifactId>
</dependency>
<!--loadbalancer-->
<dependency><groupId>org.springframework.cloud</groupId><artifactId>spring-cloud-starter-loadbalancer</artifactId>
</dependency>
② yml配置
server:port: 2001spring:application:name: seata-order-servicecloud:nacos:discovery:server-addr: localhost:8848 #Nacos服务注册中心地址# ==========applicationName + druid-mysql8 driver===================datasource:type: com.alibaba.druid.pool.DruidDataSourcedriver-class-name: com.mysql.cj.jdbc.Driverurl: jdbc:mysql://localhost:3306/seata_order?characterEncoding=utf8&useSSL=false&serverTimezone=GMT%2B8&rewriteBatchedStatements=true&allowPublicKeyRetrieval=trueusername: rootpassword: 123456
# ========================mybatis===================
mybatis:mapper-locations: classpath:mapper/*.xmltype-aliases-package: com.jane.cloud.entitiesconfiguration:map-underscore-to-camel-case: true# ========================seata===================
seata:registry:type: nacosnacos:server-addr: 127.0.0.1:8848namespace: ""group: SEATA_GROUPapplication: seata-servertx-service-group: default_tx_group # 事务组,由它获得TC服务的集群名称service:vgroup-mapping: # 点击源码分析default_tx_group: default # 事务组与TC服务集群的映射关系data-source-proxy-mode: ATlogging:level:io:seata: info
这里重点关注Seata的配置,相比1.0版本,Seata2.0版本无论是server端还是client端配置均进行了优化。
③ 创建undo_log表
undo_log建表、配置参数(仅AT模式)。SQL脚本 地址:https://github.com/apache/incubator-seata/blob/2.x/script/client/at/db/mysql.sql
-- for AT mode you must to init this sql for you business database. the seata server not need it.
CREATE TABLE IF NOT EXISTS `undo_log`
(`branch_id` BIGINT NOT NULL COMMENT 'branch transaction id',`xid` VARCHAR(128) NOT NULL COMMENT 'global transaction id',`context` VARCHAR(128) NOT NULL COMMENT 'undo_log context,such as serialization',`rollback_info` LONGBLOB NOT NULL COMMENT 'rollback info',`log_status` INT(11) NOT NULL COMMENT '0:normal status,1:defense status',`log_created` DATETIME(6) NOT NULL COMMENT 'create datetime',`log_modified` DATETIME(6) NOT NULL COMMENT 'modify datetime',UNIQUE KEY `ux_undo_log` (`xid`, `branch_id`)
) ENGINE = InnoDB AUTO_INCREMENT = 1 DEFAULT CHARSET = utf8mb4 COMMENT ='AT transaction mode undo table';
ALTER TABLE `undo_log` ADD INDEX `ix_log_created` (`log_created`);
最终数据库效果如下图:
【2】不添加@GlobalTransactional进行测试
如下所示,我们在订单处理方法里面进行远程调用扣减库存、扣减账户。service方法未添加@GlobalTransactional注解,也就是不启用分布式事务。
public void create(Order order){//xid全局事务id的检查,重要String xid = RootContext.getXID();//1 新建订单log.info("---------------开始新建订单: "+"\t"+"xid: "+xid);//订单新建时默认初始订单状态是零order.setStatus(0);int result = orderMapper.insertSelective(order);// 插入订单成功后获得插入mysql的实体对象Order orderFromDB = null;if(result > 0){// 从mysql里面查出刚插入的记录orderFromDB = orderMapper.selectOne(order);log.info("-----> 新建订单成功,orderFromDB info: "+orderFromDB);System.out.println();//2 扣减库存log.info("-------> 订单微服务开始调用Storage库存,做扣减count");storageFeignApi.decrease(orderFromDB.getProductId(),orderFromDB.getCount());log.info("-------> 订单微服务结束调用Storage库存,做扣减完成");System.out.println();//3 扣减账户余额log.info("-------> 订单微服务开始调用Account账号,做扣减money");accountFeignApi.decrease(orderFromDB.getUserId(),orderFromDB.getMoney());log.info("-------> 订单微服务结束调用Account账号,做扣减完成");System.out.println();//4 修改订单状态//将订单状态从零修改为1,表示已经完成log.info("-------> 修改订单状态");orderFromDB.setStatus(1);Example whereCondition = new Example(Order.class);Example.Criteria criteria = whereCondition.createCriteria();criteria.andEqualTo("userId",orderFromDB.getUserId());criteria.andEqualTo("status",0);int updateResult = orderMapper.updateByExampleSelective(orderFromDB, whereCondition);log.info("-------> 修改订单状态完成"+"\t"+updateResult);log.info("-------> orderFromDB info: "+orderFromDB);}System.out.println();log.info("---------------结束新建订单: "+"\t"+"xid: "+xid);}
那么假设account抛了异常,此时应该插入了订单并扣减了库存,但是账户余额没有扣除。我们修改AccountServiceImpl 使其超时:
public class AccountServiceImpl implements AccountService
{@ResourceAccountMapper accountMapper;/*** 扣减账户余额*/@Overridepublic void decrease(Long userId, Long money){log.info("------->account-service中扣减账户余额开始");accountMapper.decrease(userId,money);myTimeOut();log.info("------->account-service中扣减账户余额结束");}/*** 模拟超时异常,全局事务回滚*/private static void myTimeOut(){try { TimeUnit.SECONDS.sleep(65); } catch (InterruptedException e) { e.printStackTrace(); }}
}
此时我们查看数据库,可以验证上述推测是正确的:插入了订单并扣减了库存,但是账户余额没有扣除。其实这也就是我们为什么要引入分布式事务处理的原因:在分布式体系中,@Transactional 注解只能控制本地事务,不能控制其他服务事务,故而会引起分布式事务问题。
【3】添加@GlobalTransactional进行测试
如下所示,我们修改create方法如下:
# 添加全局事务注解
@GlobalTransactional(name = "create-order",rollbackFor = Exception.class) //AT
public void create(Order order)
{//xid全局事务id的检查,重要String xid = RootContext.getXID();//1 新建订单log.info("---------------开始新建订单: "+"\t"+"xid: "+xid);//订单新建时默认初始订单状态是零order.setStatus(0);//...
}
再次进行测试,仍然让account抛出异常。此时我们看控制台发现均已进行了回滚:



数据库订单表、账户表以及库存表并没有产生脏数据,说明分布式事务生效。
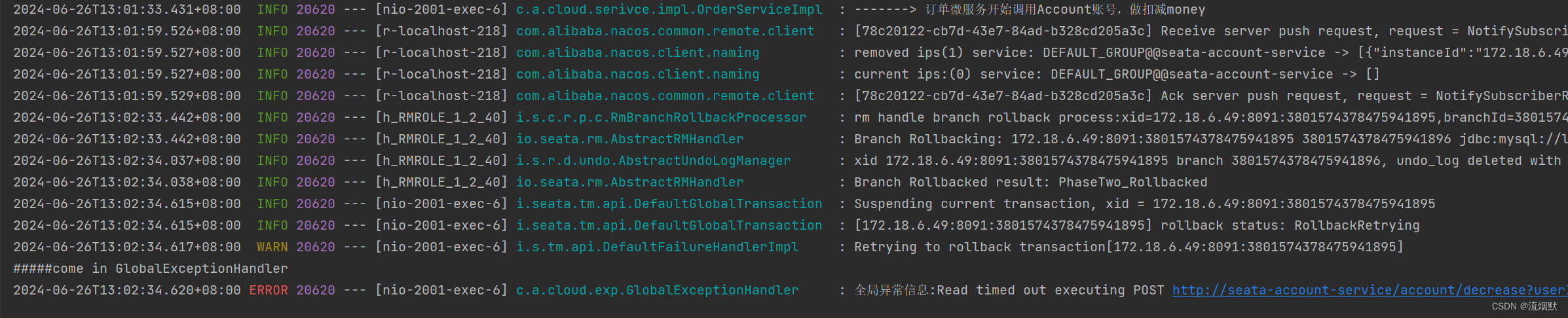
我们再次测试,在account方法处打上断点,那么order模块会抛出超时异常:feign.RetryableException: Read timed out 。
这时TC就会让各个分支事务进行回滚,比如库存模块:

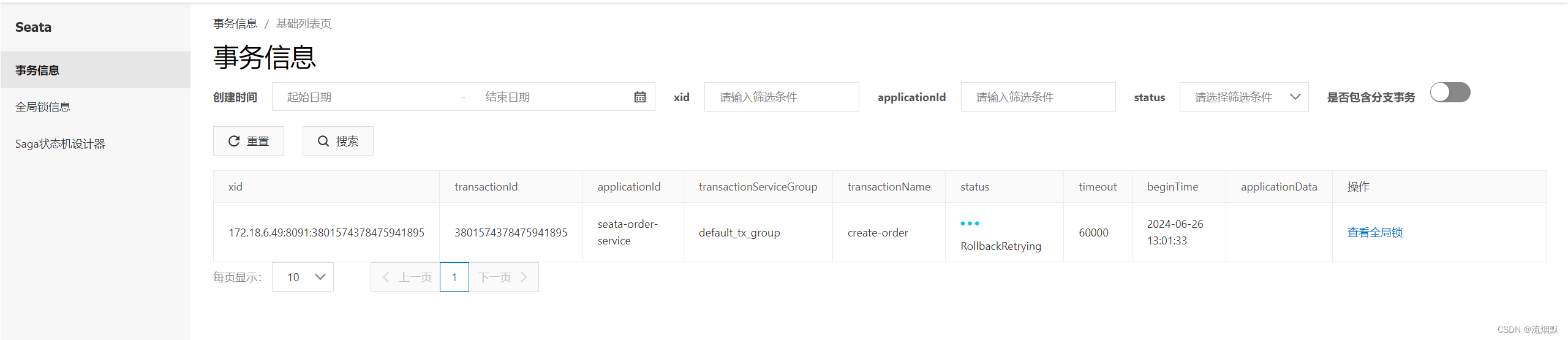
在Seata的控制台,我们可以看到目前只有account持有全局锁:

事务信息界面目前状态为RollbackRetrying,也就是重复尝试回滚(因为我们debug中)。
此时order分支二阶段回滚也已成功,但是全局事务回滚还未成功。
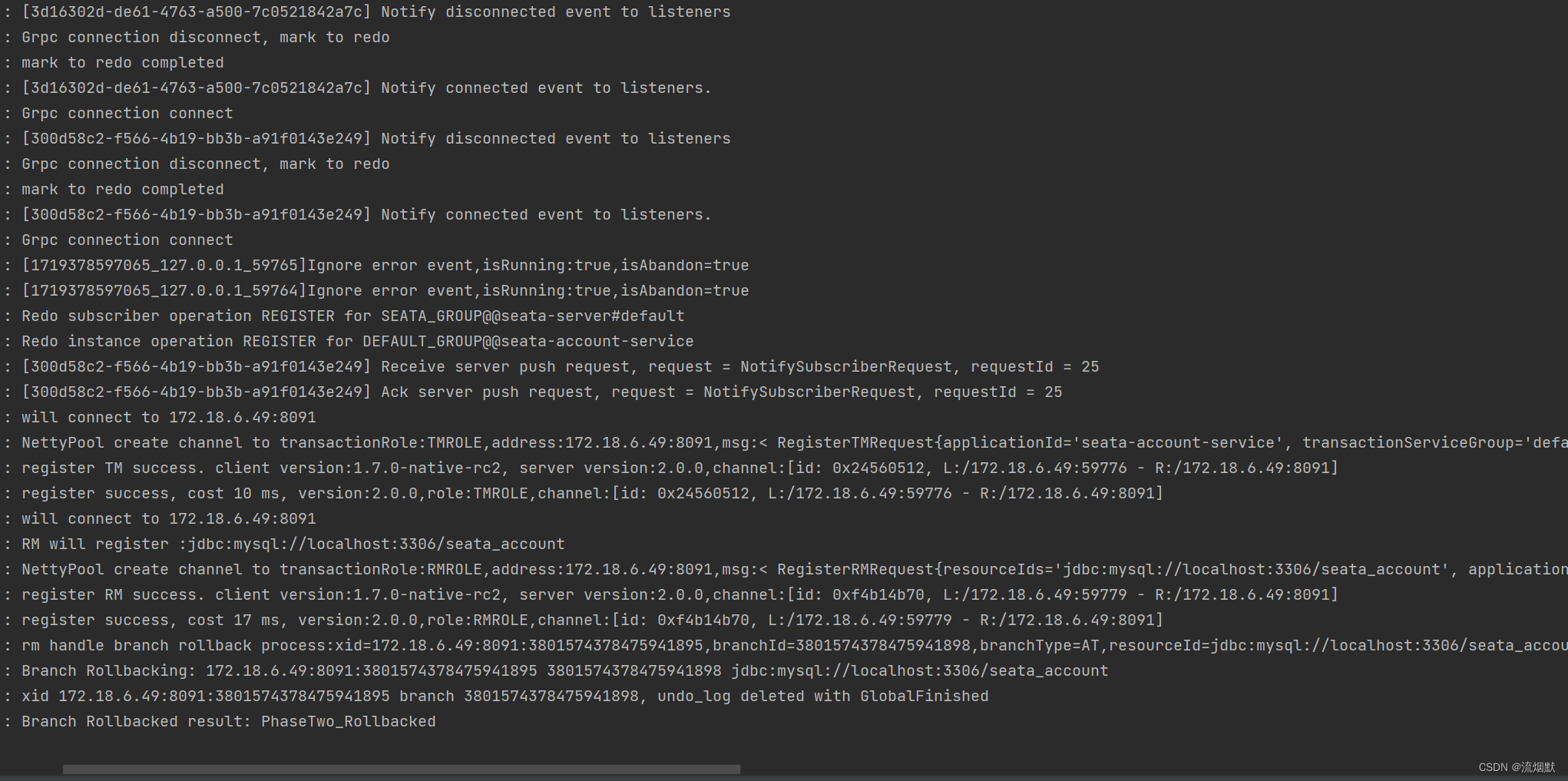
我们释放account的断点,使其二阶段回滚成功,此时全局事务也会回滚成功。
【4】AT模式如何做到对业务的无侵入
官网地址:Seata 是什么? Seata默认是AT模式,两阶段提交协议的演变:
-
一阶段:业务数据和回滚日志记录在同一个本地事务中提交,释放本地锁和连接资源。
-
二阶段:
- 提交异步化,非常快速地完成。
- 回滚通过一阶段的回滚日志进行反向补偿。
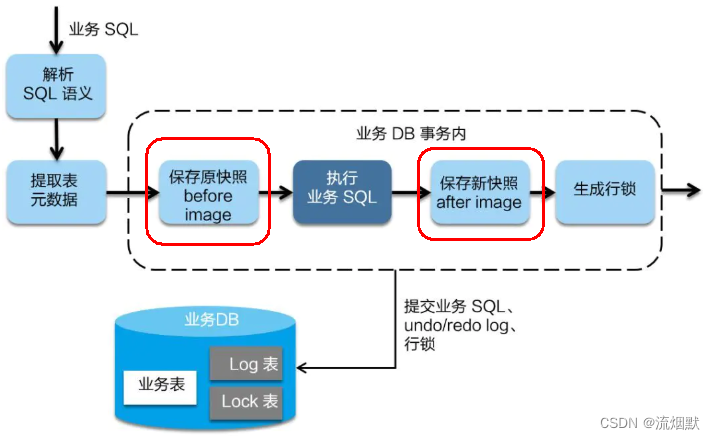
① 一阶段加载
在一阶段,Seata 会拦截“业务 SQL”,
- 1 解析 SQL 语义,找到“业务 SQL”要更新的业务数据,在业务数据被更新前,将其保存成“before image”,
- 2 执行“业务 SQL”更新业务数据,在业务数据更新之后,
- 3 其保存成“after image”,最后生成行锁。
以上操作全部在一个数据库事务内完成,这样保证了一阶段操作的原子性。
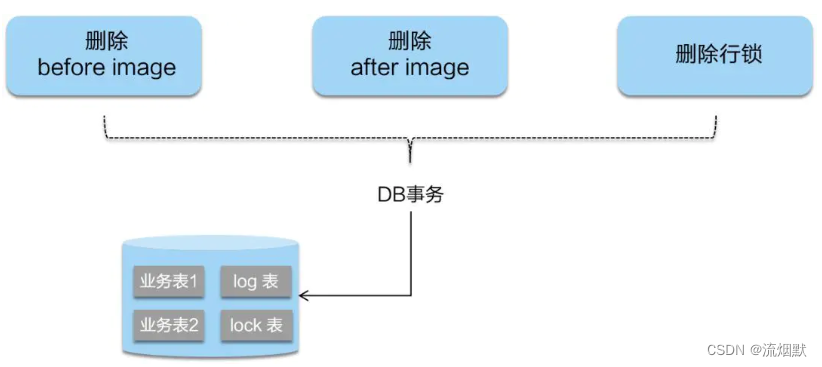
② 二阶段提交
二阶段如是顺利提交的话,因为“业务 SQL”在一阶段已经提交至数据库,所以Seata框架只需将一阶段保存的快照数据和行锁删掉,完成数据清理即可。
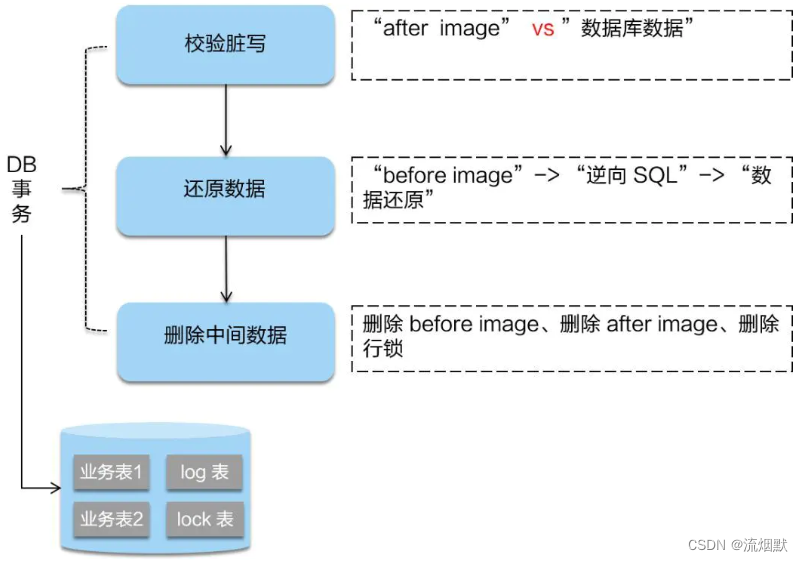
③ 二阶段回滚
二阶段如果是回滚的话,Seata 就需要回滚一阶段已经执行的“业务 SQL”,还原业务数据。
回滚方式便是用“before image”还原业务数据。但在还原前要首先要校验脏写,对比“数据库当前业务数据”和 “after image”:
- 如果两份数据完全一致就说明没有脏写,可以还原业务数据,
- 如果不一致就说明有脏写,出现脏写就需要转人工处理。
【5】复习:@Transactional事务注解什么时候失效
@Transactional 注解可能会在以下几种情况下失效:
-
非public方法:当
@Transactional注解应用在非public修饰的方法上时,事务管理将不会生效。这是因为在Spring AOP(面向切面编程)代理机制中,事务拦截器仅对public方法进行拦截处理。 -
自我调用:在一个类的内部,一个带有
@Transactional注解的方法直接被另一个没有事务注解的方法调用时,事务可能不会生效。因为在这种情况下,调用是直接发生的,没有经过Spring的代理对象,从而不会触发事务管理。 -
未被Spring管理的类:如果带有
@Transactional注解的类没有被Spring容器管理(例如,没有使用@Component、@Service等注解标记,或者没有在Spring配置中声明),事务注解将不起作用。 -
异常处理不当:如果在事务方法中捕获并吞没了应导致事务回滚的异常(通常是未检查异常,如
RuntimeException),事务可能不会回滚。除非在@Transactional注解中明确指定了rollbackFor属性来捕获特定类型的异常。 -
代理模式问题:使用基于Java接口的代理时(Spring默认的代理方式),只有通过接口调用的方法才会被代理增强,如果直接在实现类上调用方法(而不是通过接口),事务可能不会生效。
-
事务传播行为设置不当:如果方法的事务传播行为配置不当(例如,一个事务方法调用另一个事务方法时,传播行为设置为
PROPAGATION_NOT_SUPPORTED或PROPAGATION_NEVER),可能导致事务不生效或被挂起。 -
缺少数据库事务支持:如果底层数据访问技术不支持事务管理,如使用了非事务性的JDBC连接或某些NoSQL数据库操作,即使
@Transactional注解正确使用,也无法实现事务管理。
要确保@Transactional注解能正常工作,需要确保遵循正确的使用方式,并注意上述可能引起事务失效的情况。