第一篇:LLM greater scene summarize
第二篇:LLM simulation Test effect
第三篇:LLM simulation driving scenario flow work
第四篇:LLM Algorithm flow description
第五篇:Configure the environment and background rendering engine
第六篇:perception raw data train
第七篇:Process and analyze calibration data
第八篇:Use Blender 3D Assets
第九篇:Training and simulation model
第十篇:code and sum up
背景前言
自动驾驶中的场景仿真因其生成定制数据的巨大潜力而受到广泛关注。然而,现有的可编辑场景模拟方法在用户交互效率、多机位逼真渲染和外部数字资产集成方面存在局限性。 为了应对这些挑战,本文介绍了ChatSim,这是第一个通过自然语言命令和外部数字资产实现可编辑的逼真的3D驾驶场景模拟的系统。为了实现具有高度命令灵活性的编辑,ChatSim 利用了大型语言模型 (LLM) 代理协作框架。为了生成逼真的结果,ChatSim采用了一种新颖的多相机神经辐射场方法。此外,为了释放大量高质量数字资产的潜力,ChatSim 采用了一种新颖的多机位照明估计方法来实现场景一致的资产渲染。在Waymo Open Dataset上的实验表明,ChatSim可以处理复杂的语言命令,并生成相应的逼真的场景视频。
感知是自动驾驶汽车进入外部环境的窗口。为了确保车辆在训练和测试阶段的感知能力的鲁棒性,需要大量收集高质量的感知数据.然而,为获取真实世界数据而运营的车队往往会产生高昂的费用,特别是对于专业或定制的要求。例如,在涉及自动驾驶汽车的事故或干预之后,必须在一系列类似场景中测试车辆的感知系统。由于实际场景的不可控性,从真实世界的实例复制此类场景数据几乎是不可能的,定制场景模拟成为一种重要且可行的替代方案。它能够对特定条件进行精确建模,而无需支付高成本和真实世界数据收集的后勤复杂性.
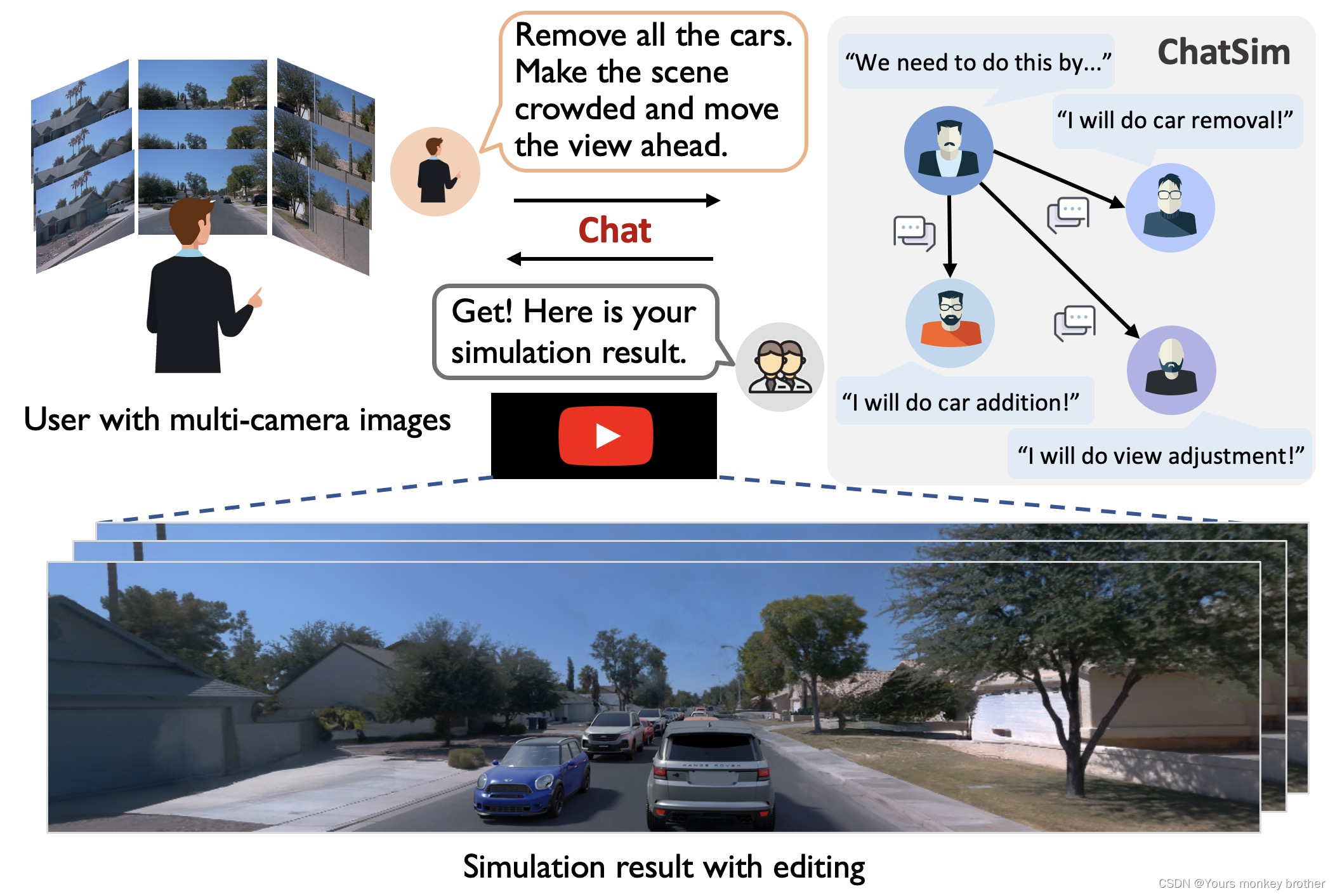
为了有效地模拟自定义驾驶场景,我们确定了三个关键属性作为基本属性。首先,仿真应该能够遵循复杂或抽象的要求,从而 促进生产。其次,仿真应生成逼真的照片、视图一致的结果,从而实现最接近真实场景中车辆观察的结果。第三,它应该允许外部数字资产的整合[48,6]具有逼真的纹理和材质,同时适合照明条件。这种能力将通过整合各种外部数字资产来释放数据扩展的潜力,从而满足定制需求。
已经提出了大量用于场景模拟的重要工作,但它们未能满足所有这三个要求。传统图形引擎,如 CARLA和 UE,提供具有外部数字资产的可编辑虚拟环境,但数据真实性受到资产建模和渲染质量的限制。基于图像生成的方法,例如 BEVContro, DriveDreame、MagicDrive,可以基于各种控制信号生成逼真的场景图像,包括BEV地图、边界框和相机姿势。然而,由于缺乏 3D 空间建模,他们难以保持视图一致性,并在导入外部数字资产时面临挑战。提出了基于渲染的方法,以获得逼真和视图一致的场景模拟。著名的例子,如UniSim和 MARS配备一套场景编辑工具。然而,这些系统需要用户通过代码实现广泛参与每个琐碎的编辑步骤,这在执行编辑时是无效的。此外,虽然它们在观察到的场景中有效地处理车辆,但它们无法支持外部数字资产,这限制了数据扩展和定制的机会。
为了满足已确定的要求,我们推出了 ChatSim,这是第一个通过自然语言命令和外部数字资产实现可编辑的逼真的 3D 驾驶场景模拟的系统。要使用 ChatSim,用户只需与系统进行对话,通过自然语言发出命令,而无需参与任何中间模拟步骤;有关说明,
为了有效地处理复杂或抽象的用户命令,ChatSim 采用了基于大型语言模型 (LLM) 的多智能体协作框架。其关键思想是利用多个 LLM 代理(每个代理都具有专门的角色)将整体模拟需求解耦到特定的编辑任务中,从而反映通常在人工运营公司的工作流程中建立的任务划分和执行。此工作流为场景模拟提供了两个关键优势。首先,LLM 代理处理人类语言命令的能力允许对复杂的驾驶场景进行直观和动态的编辑,从而实现精确的调整和反馈。其次,协作框架通过在专业代理之间分配特定的编辑任务来提高模拟效率和准确性,确保模拟的详细和逼真,并提高任务完成率。
为了生成逼真的结果,我们提出了 ChatSim 中的 McNeRF,这是一种新颖的神经辐射场方法,它结合了多相机输入,提供了更广泛的场景渲染。这种集成充分利用了车辆上的摄像头设置,但带来了两个重大挑战:由于触发时间不同步导致的摄像头姿势错位,以及由于摄像头曝光时间不同而导致的亮度不一致。为了解决摄像机姿势错位问题,McNeRF 使用多摄像机对齐来减少外部参数噪声,从而确保渲染质量。为了解决亮度不一致的问题,McNeRF集成了临界曝光时间,以恢复HDR中的场景亮度,从而显著缓解了具有不同曝光时间的两张相机图像交叉处的色彩差异问题。
为了导入具有逼真纹理和材质的外部数字资产,我们提出了 McLight,这是一种新颖的多摄像机照明估计,它融合了天空穹顶和周围照明。我们的天幕估计通过峰值强度残差连接恢复准确的太阳行为,从而能够渲染突出的阴影。对于周围的照明,McLight 查询 McNeRF 以实现复杂的特定位置照明效果,例如在树荫下遮挡阳光的照明效果。这显著提高了集成 3D 资产的渲染真实感。
我们对Waymo自动驾驶数据集进行了广泛的实验,并表明ChatSim可以根据各种人类语言命令生成逼真的定制感知数据,包括危险的极端情况。我们的方法与混合、高度抽象和多轮命令兼容。我们的方法在广角渲染下实现了 4.5% 的 SoTA 性能。此外,我们证明了我们的照明估计在定性和定量上都优于 SoTA 方法,将强度误差和角度误差分别降低了 57.0% 和 9.9%。
2相关工作
自动驾驶场景仿真。目前的场景仿真方法一般可以分为三类:图形引擎、图像生成和场景渲染。图形引擎,例如 CARLA、AirSim、OpenScenario 编辑器, 51Sim-One和 RoadRunner,创建一个虚拟世界来模拟各种驾驶场景。然而,虚拟世界和现实之间存在着巨大的领域差距。图像生成方法可以基于不同的控制信号生成逼真的场景图像,例如高清地图、草图布局、边界框、文本编辑和驾驶行.然而,这些方法很难保持场景的一致性。 为了获得连贯的驾驶场景,需要基于场景渲染的方法对3D场景进行重构。使用点云并使用 U-Net 渲染图像。随着神经辐射场(NeRF)的快速发展,还利用 NeRF 在户外环境中对汽车和静态街道背景进行建模。此外,UniSim 等著名和MARS配备一套场景编辑工具。 然而,这些方法需要大量用户参与中间编辑步骤,并且它们不支持外部数字资产进行数据扩展。 在这项工作中,我们提出了ChatSim,它通过语言命令实现自动模拟编辑,并集成外部数字资产以增强真实感和灵活性。在 ChatSim 中,我们集成了 McNeRF,这是一种新型神经辐射场,旨在利用多摄像机输入实现高保真渲染。
照明估算。照明估算侧重于评估真实环境的照明条件,以无缝集成数字对象。早期方法对于户外环境,使用明确的提示,例如在地面上检测到的阴影。最近的工作通常采用基于学习的方法通过预测不同的光照表示,如球形波瓣、光探头环境 地图, HDR天空模型和照明量.但是,他们中很少有人考虑多摄像头输入,这在驾驶场景中很常见。在本文中,我们提出了一种新颖的多摄像机照明估计方法McLight,结合McNeRF,以估计更广泛的照明范围,并获得资产的空间变化照明效果。
| Method | Photo-realistic | Dim. | Multi-camera | Editable | Externalassets | Language | Open-source |
| CARLA | \usym 2613 | 3D | ✓ | ✓ | ✓ | \usym 2613 | ✓ |
| AirSim | \usym 2613 | 3D | ✓ | ✓ | ✓ | \usym 2613 | ✓ |
| OpenScenario | \usym 2613 | 3D | ✓ | ✓ | ✓ | \usym 2613 | ✓ |
| 51Sim-One | \usym 2613 | 3D | ✓ | ✓ | ✓ | \usym 2613 | \usym 2613 |
| RoadRunner | \usym 2613 | 3D | ✓ | ✓ | ✓ | \usym 2613 | ✓ |
| BEVGen | ✓ | 2D | ✓ | ✓ | \usym 2613 | \usym 2613 | ✓ |
| BEVControl | ✓ | 2D | ✓ | ✓ | \usym 2613 | \usym 2613 | \usym 2613 |
| DriveDreamer | ✓ | 2D | ✓ | ✓ | \usym 2613 | ✓ | \usym 2613 |
| DrivingDiffusion | ✓ | 2D | ✓ | ✓ | \usym 2613 | ✓ | \usym 2613 |
| GAIA-1 | ✓ | 2D | \usym 2613 | ✓ | \usym 2613 | ✓ | \usym 2613 |
| MagicDrive | ✓ | 2D | ✓ | ✓ | \usym 2613 | \usym 2613 | \usym 2613 |
| READ | ✓ | 3D | \usym 2613 | \usym 2613 | \usym 2613 | \usym 2613 | ✓ |
| Neural SG | ✓ | 3D | \usym 2613 | ✓ | \usym 2613 | \usym 2613 | ✓ |
| Neural PLF | ✓ | 3D | \usym 2613 | \usym 2613 | \usym 2613 | \usym 2613 | ✓ |
| S-NeRF | ✓ | 3D | ✓ | \usym 2613 | \usym 2613 | \usym 2613 | ✓ |
| UniSim | ✓ | 3D | \usym 2613 | ✓ | \usym 2613 | \usym 2613 | \usym 2613 |
| MARS | ✓ | 3D | \usym 2613 | ✓ | \usym 2613 | \usym 2613 | ✓ |
| ChatSim (Ours) | ✓ | 3D | ✓ | ✓ | ✓ | ✓ | ✓ |
3用于编辑的协作 LLM-Agents
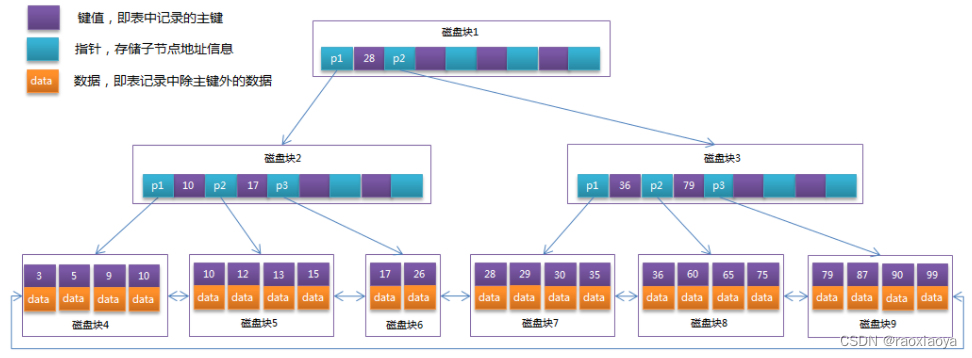
ChatSim系统分析特定的用户命令,返回满足定制需求的视频;请参阅图 。由于用户命令可以是抽象的和复杂的,因此它要求系统具有灵活的任务处理能力。直接应用单个 LLM 代理在多步骤推理和交叉引用方面存在困难。为了解决这个问题,我们设计了一系列协作式 LLM 代理,其中每个代理负责编辑任务的一个独特方面。
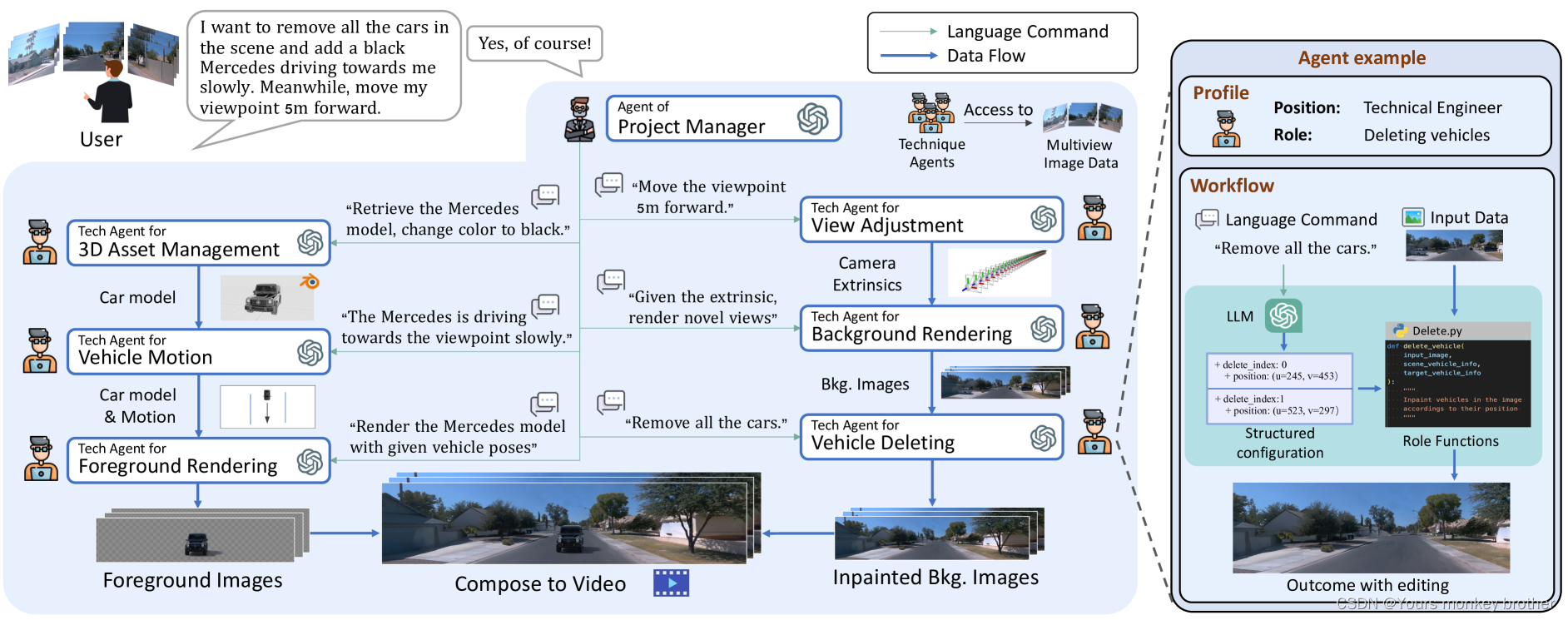
大型语言模型和协作框架。大型语言模型 (LLM) 是在大量数据上训练的 AI 系统,用于理解、生成和响应人类语言。GPT是生成类似人类内容的开创性工作。以下更新版本 GPT-3.5和 GPT-4,提供聊天、浏览、编码等更智能的功能。其他值得注意的大型语言模型包括 InstructGPT、骆马和 PaLM基于LLM,许多作品通过整合多个智能体之间的沟通来提高解决问题的能力。和定义一组组织良好的代理,以形成具有对话和代码编程的操作过程。 在本文中,我们利用协作式 LLM 代理在仿真中的强大功能来 自动驾驶,通过语言命令对3D场景进行各种编辑。
hatSim 系统概述。该系统利用多个具有专门角色的协作 LLM 代理将总体需求解耦到特定的编辑任务中。每个代理都配备了一个 LLM 和相应的角色功能来解释和执行其特定任务。

3.1特定代理的功能
ChatSim 中的代理包括两个关键组件:大型语言模型 (LLM) 和相应的角色功能。LLM 负责理解接收到的命令,而角色函数处理接收到的数据。每个代理都配备了独特的 LLM 提示和角色功能,这些提示和角色功能是根据他们在系统中的特定职责量身定制的。为了完成任务,代理首先在提示的帮助下使用 LLM 将收到的命令转换为结构化配置。 然后,角色函数利用结构化配置作为参数来处理接收到的数据并产生所需的结果;请参阅图 2 右侧的代理示例。此工作流赋予座席语言解释能力和精确执行能力。
项目经理代理。项目经理代理将直接命令分解为清晰的自然语言指令,并分派给其他编辑代理。 为了让项目经理代理具备命令分解的能力,我们为其 LLM 设计了一系列提示。提示的核心思想是描述动作集,给出总体目标,并用示例定义输出形式; 角色函数将分解后的指令发送给其他代理进行编辑。项目经理代理的存在增强了系统在解释各种输入方面的稳健性,并简化了操作,以实现清晰和精细的粒度。
用于视图调整的技术代理。视图调整代理生成合适的外部相机参数。代理中的 LLM 将用于视点调整的自然语言指令转换为目标视点位置和角度的运动参数。在角色函数中, 这些运动参数被转换为外在所需的变换矩阵,然后将其乘以原始参数以产生新的视点。
用于后台渲染的技术代理。后台渲染代理根据多机位图像渲染场景背景。LLM 接收 rendering 命令,然后操作角色函数进行 rendering。值得注意的是,在角色函数中,我们专门集成了一种新颖的神经辐射场法 (McNeRF),该方法采用多摄像机输入并考虑曝光时间,解决了多摄像机渲染中的模糊和亮度不一致问题。
车辆拆卸技术代理。车辆删除代理从背景中删除指定的车辆。它首先从给定的场景信息或场景感知模型(如)中识别当前车辆属性,如 3D 边界框和颜色,例如LLM 收集车辆的属性并执行与用户请求的匹配。在确认目标载体后,它采用每帧修复模型作为角色函数,例如潜在扩散方,以有效地将它们从场景中删除。
用于 3D 资产管理的技术代理。3D资产管理代理根据用户规格选择和修改3D数字资产。它构建并维护一个 3D 数字资产库;请参阅附录中的银行详细信息。为了方便添加各种对象,代理首先使用 LLM 通过匹配需求的关键属性(例如颜色和类型)来选择最合适的资产。如果匹配不完美,代理可以通过其角色函数(如更改颜色)修改资产。
车辆运动的技术代理。车辆运动代理根据请求创建车辆的初始位置和后续运动。现有的车辆运动生成方法不能纯粹从文本和场景地图直接生成运动。为了解决这个问题,我们提出了一种新颖的文本到动态方法。其关键思想是将作为角色函数的放置和规划模块与 LLM 链接起来,以提取运动属性并将其转换为坐标。 运动属性包括位置属性(例如距离、方向)和运动属性(例如速度、动作)。 对于放置模块,我们赋予车道地图中的每个车道节点以匹配其属性以匹配位置属性。规划模块规划车辆的近似目的地车道节点,然后通过拟合贝塞尔曲线来规划中间轨迹。 我们还添加了轨迹跟踪适应车辆动力学;更多详细信息请参阅附录。
前景渲染的技术代理。前景渲染代理集成了摄像机外部信息、3D 资源和运动信息,以渲染场景中的前景对象。值得注意的是,为了将外部资产与当前场景无缝集成,我们设计了一种多摄像机照明估计方法(McLight)到角色函数中,并与McNeRF耦合。然后,Blender API 利用估计的照明来生成前景图像。
![[AI开发配环境]VSCode远程连接ssh服务器](https://img-blog.csdnimg.cn/direct/c5304e9f50c948aca5b37bb6c49865ae.png)